【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.深度学习与机器学习
深度学习是由机器学习算法中的人工神经网络扩展而来的,在数据规模比较大的情况下,深度学习往往比传统机器学习算法的性能更加优越。
尤其是在计算机视觉领域,深度学习的应用更加广泛且更为高效。
以图像分类任务为例,在开始深度学习之前,我们先来看下传统机器学习是怎么完成图像分类的,假如我们这里采用K近邻算法(k-Nearest Neighbor,KNN)。
2.KNN算法
KNN算法的核心思想其实就是:物以类聚,人以群分。其中K就是邻居数。
![]()
如上图所示,假设有两个类别:蓝色方块和红色三角,现在新来了一个绿色圆圈,那么我们怎么判断绿色圆圈属于哪个类别呢?
根据KNN算法的思想:
- 如果有$K=3$,离绿色圆圈最近的三个邻居中有2个是红色三角,1个是蓝色方块,所以我们判断绿色圆圈属于红色三角的类别。
- 如果有$K=5$,离绿色圆圈最近的五个邻居中有2个是红色三角,3个是蓝色方块,所以我们判断绿色圆圈属于蓝色方块的类别。
KNN算法的步骤总结出来就是:
- 计算当前点和每一个已知类别的点之间的距离。
- 按照距离远近进行排序。
- 选取与当前点距离最近的K个点。
- 确定这K个点所在类别的出现概率。
- 返回前K个点出现频率最高的类别作为当前点预测分类。
那KNN如何完成图像分类呢?首先,我们得要有用于图像分类的数据集才能继续进行下去,接下来介绍一个带有标签的图像分类的数据集。
3.CIFAR-10数据集
该数据集共有60000张彩色图像,图像大小均为32*32,共分为10个类别,每个类别均含有6000张图像,类别见下:

其中50000张图像带有标签,可作为训练集,剩余的10000张图像没有标签,作为测试集。
4.KNN与图像分类
根据第2部分介绍的KNN的步骤,第一步需要先计算距离,假设这里采用曼哈顿距离,即待检测图像和训练集中每一幅图像对应像素点的像素值差值的绝对值之和:
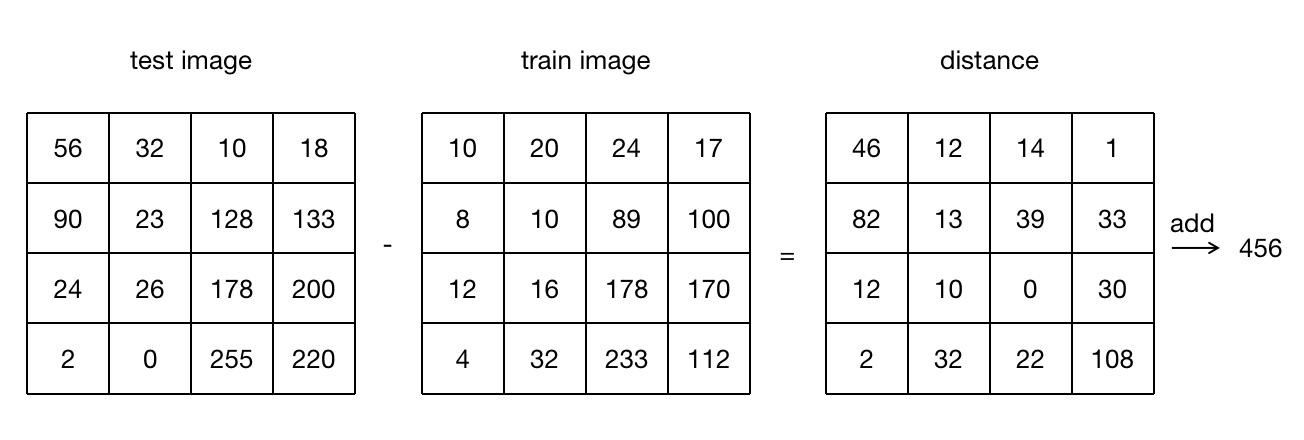
4.1.超参数
上文中我们所用的距离计算方式就是一个超参数。
在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。例如在上文中,除了使用曼哈顿距离,我们也可以用欧式距离。
超参数的一些示例:
- 树的数量或树的深度
- 矩阵分解中潜在因素的数量
- 学习率
- 深层神经网络隐藏层数
- k均值聚类中的簇数
那么在knn算法中,我们如何确定采用何种距离以及k值等超参数的值呢?
交叉验证是一种很好的确定最优超参数值的方法。
但是因为knn算法中距离的计算是计算两幅图像对应像素点的差异,因此会受到背景影响比较大。所以knn算法对图像的分类效果并不理想。
其实不止knn算法,传统的机器学习算法对图像的处理并不优秀,因此这个时候就需要引入深度学习了。
