【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.线性分类
如果我们使用一个线性分类器去进行图像分类该怎么做呢?假设现在我们有一张$2\times2\times1$的图像(即图像大小为$2\times 2$,通道数为1),像素值见下:
\[\begin{bmatrix} 56 & 231 \\ 24 & 2 \\ \end{bmatrix}\]此时我们构建一个线性分类器去判断该幅图像属于哪一种类别:
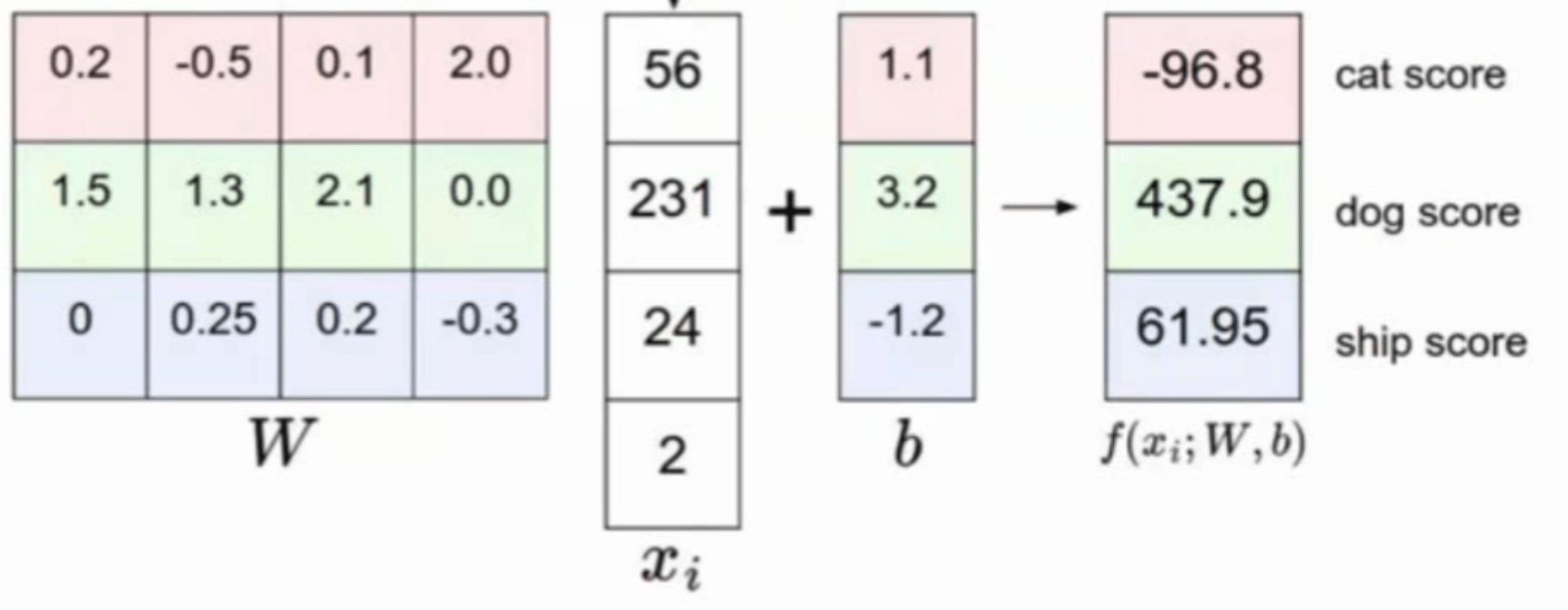
用一张图表示就是:
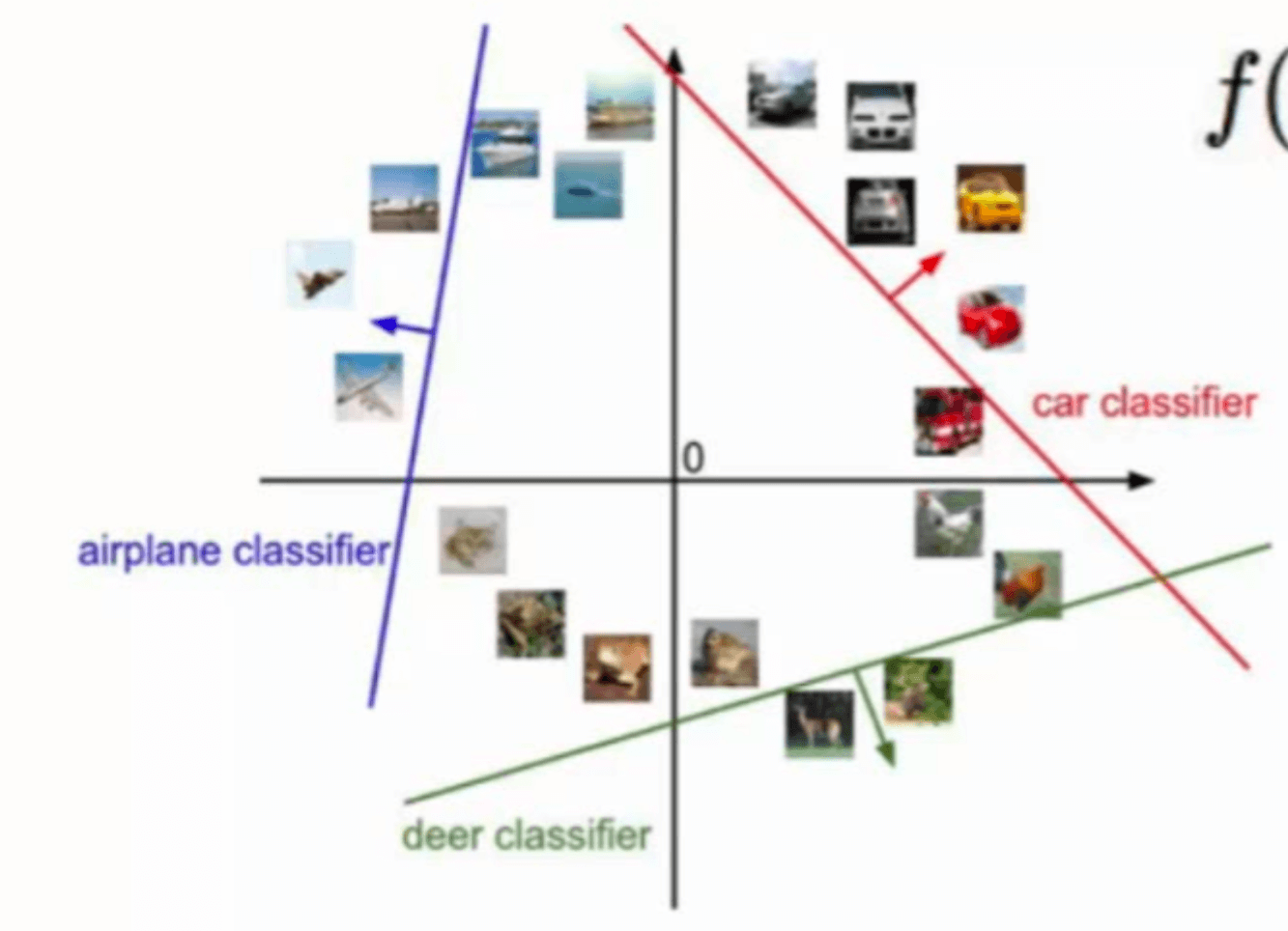
此时增加一下难度,如果我们的训练数据是$64\times 64 \times 3$的RGB图像呢?同理,这时我们的$\mathbf x$就是一个$12288\times 1$的向量($64\times 64 \times 3=12288$):

那么模型的参数是怎么来的呢?可以通过最小化损失\代价函数(线性模型通常选择“均方误差”作为损失\代价函数,详见【机器学习基础】第六课)来估计$\mathbf w,\mathbf b$的值。
2.softmax分类器
如果使用线性模型进行分类的话,得到的是一个具体的数值,并不直观。我们更希望可以直接得到某一样本属于各个类别的概率。
对于二分类任务来说,我们可以采用对数几率回归来输出样本属于正类的概率。
那么对于多分类该怎么办呢?答案就是softmax分类器。
在对数几率回归中,我们使用sigmoid函数使得输出限制在0~1之间,即样本属于正类的概率。类似的,在多分类任务中,我们使用softmax函数使得输出限制在0~1之间,并且每个样本属于各个类别的概率相加刚好为1(❗️sigmoid就是极端情况(类别数为2)下的softmax)。
softmax函数又称归一化指数函数,它能将一个含任意实数的K维向量$\mathbf z$“压缩”到另一个K维实向量$\sigma (\mathbf z)$中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。该函数的形式通常按下面的式子给出:
\[\sigma (\mathbf z)_j=\frac{e^{z_j}}{\sum^K_{k=1}e^{z_k}}\]在多分类任务中,softmax函数的输入是从K个不同的线性函数得到的结果(即$\mathbf x^T \mathbf w$),而样本向量$\mathbf x$属于第j个类别的概率为:
\[P(y=j \mid \mathbf x)=\frac{e^{\mathbf x^T \mathbf w_j}}{\sum^K_{k=1}e^{\mathbf x^T \mathbf w_k}}\]例如:

2.1.hardmax分类器
与softmax相对应的是hardmax,hardmax会将最大的值置为1,其他置为0。
例如有:
\[\begin{bmatrix} 5 \\ 2 \\ -1 \\ 3 \end{bmatrix}\]softmax将其转换为:
\[\begin{bmatrix} 0.842 \\ 0.042 \\ 0.002 \\ 0.114 \end{bmatrix}\]而hardmax会将其转换为:
\[\begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}\]显然,softmax的转换更为温和。
3.交叉熵损失函数
在对数几率回归一文中,我们采用最大似然法进行参数估计,其中式(3.8)其实就是交叉熵损失函数的应用。
以softmax分类器为例,利用交叉熵损失函数,对softmax求得概率取-ln,最后相加即可得到最后的总损失:

对于单个样本来说,其交叉熵损失值为:
- 二分类情况下:
- $loss=-[y\cdot \log(p)+(1-y)\cdot \log(1-p)]$
- y为样本的标记,正类为1,负类为0
- p表示样本预测为正的概率
- $loss=-[y\cdot \log(p)+(1-y)\cdot \log(1-p)]$
- 多分类情况下:
- $loss=-\sum_{c=1}^M y_c \log(p_c)$
- M为类别的数量
- $y_c$等于0或1,如果预测出的类别和样本标记相同就是1,否则是0
- $p_c$为样本属于类别c的概率
- $loss=-\sum_{c=1}^M y_c \log(p_c)$
将训练集中所有样本的loss值加起来便可得到最终的总loss。
例如一个三分类问题,假设训练集中共有3个样本,通过softmax分类器我们得到了3个样本分别属于三个类别的概率:
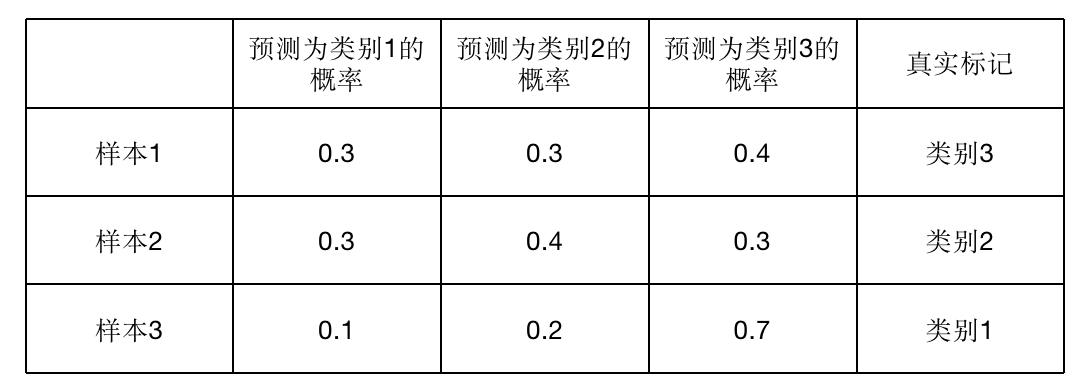
采用交叉熵损失函数,求得该参数下的softmax分类器的总loss:
\[\begin{align} total\_loss & = -[0\times \log 0.3+0\times \log 0.3 +1\times \log 0.4] \\ & -[0\times \log 0.3 +1\times \log 0.4 +0\times \log 0.3] \\ & -[1\times \log 0.1 + 0\times \log 0.2 +0\times \log 0.7] \\ & = 0.397+0.397+1 \\ & =1.8 \end{align}\]然后可以通过优化分类器参数来降低总loss(例如可通过梯度下降法或牛顿法求得loss最小时所对应的模型参数)。
