本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.前言
本文主要介绍pandas中DataFrame格式数据的相关操作。
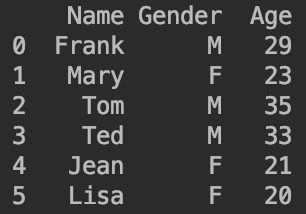
接下来的讲解都以下面的数据为例:
1
2
3
import pandas as pd
df=pd.DataFrame([['Frank','M',29],['Mary','F',23],['Tom','M',35],['Ted','M',33],['Jean','F',21],['Lisa','F',20]])
df.columns=['Name','Gender','Age']
2.数据的选取
和【Python基础】第六课:处理CSV、Excel格式的数据中读取csv、excel的数据一样,我们可以使用.loc和.iloc来选取数据。
2.1.选择特定条件下的数据
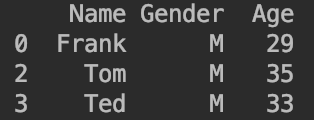
比如现在我们需要挑选出所有男性的数据df[df['Gender']=='M']:
其中df['Gender']=='M'为:
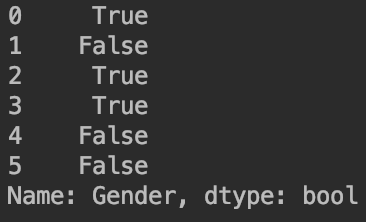
里面的元素均为布尔值,并且行的索引号得以保留。
如果我们需要选取非男性的所有数据:df[df['Gender']!='M']。
类似的,我们可以得到:
- 女性并且年龄大于等于21的数据:
df[(df['Gender']=='F') & (df['Age']>=21)] - 女性或者年龄大于22的数据:
df[(df['Gender']=='F') | (df['Age']>22)]
3.数据的新增和删除
3.1.新增数据
3.1.1.新增列
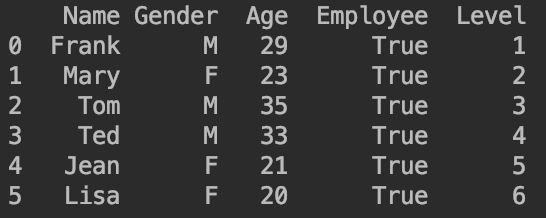
df['Employee']=True:新增Employee列,该列的值全部为True。
df['Level']=[1,2,3,4,5,6]:新增Level列,该列的值依次为1,2,3,4,5,6。
3.1.2.新增行
df.loc[6]={'Name':'Wade','Gender':'M','Age':28,'Employee':True,'Level':7}:原DataFrame的列标签必须都被赋值,但是顺序不必一致。
也可以简写为df.loc[6]=['Wade','M',28,True,7]。但是得与原DataFrame的列标签的顺序一致。
⚠️这里不能用df.iloc[6]={'Name':'Wade','Gender':'M','Age':28,'Employee':True,'Level':7}。
除了使用.loc,也可以类似于列表,使用.append添加新的行:
1
df = df.append(pd.DataFrame([{'Name':'James','Gender':'M','Age':32,'Employee':True,'Level':8}]),ignore_index=True,sort=False)
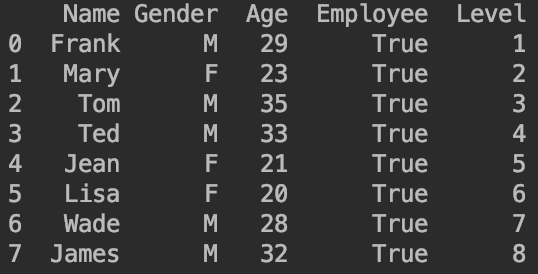
⚠️sort=False指的是列标签不用重新排序(按照首字母排序)。ignore_index=True指的是新增的行的索引号不重新排序。
1
df = df.append(pd.DataFrame([{'Name':'James','Gender':'M','Age':32,'Employee':True,'Level':8}]),ignore_index=False,sort=True)
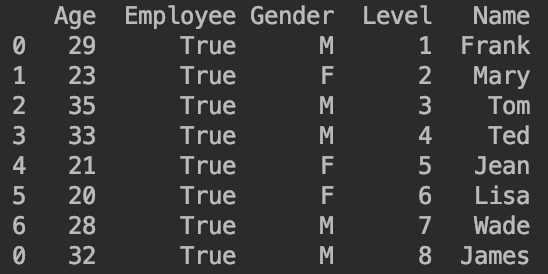
3.2.删除数据
3.2.1.方法一:del
假如我们要删除Employee这一列,只需del df['Employee']即可。
3.2.2.方法二:.drop
删除列:df=df.drop('Employee',1)。
删除行:df=df.drop(7,0)。
⚠️axis=1对列操作;axis=0对行操作。这个设定和Numpy中刚好相反。
4.数据的索引
数据的索引即为DataFrame中的行标签。我们可以自行定义。
1
2
df['UserID']=range(101,108)
df.set_index('UserID',inplace=True)
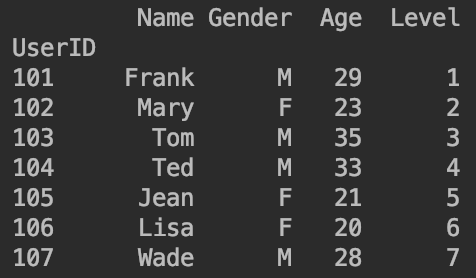
❗️可以用df.loc[101]或者df.iloc[0]进行取值。
关于
range的用法:
range(a,b)可以生成:a,a+1,a+2,…,b-1。其中,a,b必须为整数。
range(a,b,step)中step指的是步长。例如range(1,11,2)生成的数为1,3,5,7,9。
