本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.侦测缺失值
1.1.缺失值的产生
通常缺失值的产生有两个原因:
- 机械缺失:例如机械故障,导致数据无法被完整保存。
- 人为缺失:例如受访者拒绝透漏部分信息。
缺失值通常不设置为空值,而表示为NaN。
1.2.缺失值的表示
通常可用numpy.nan表示缺失值。
1
2
import numpy as np
print(np.nan)#nan
1.3.检测缺失值
按照上一课【Python基础】第十课:DataFrame的相关操作中的方法,构建一组含有缺失值的数据:
1
2
3
4
5
6
7
import numpy as np
import pandas as pd
#构建一组含有缺失值的数据
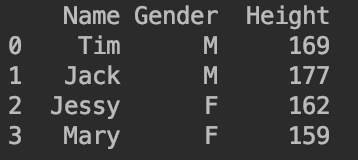
df=pd.DataFrame([["Tim","M",24,169,100],["Jack","M",np.nan,177,140],["Jessy","F",21,162,np.nan],["Mary","F",23,159,87]])
#赋予列名
df.columns=["Name","Gender","Age","Height","Weight"]
print(df)
![]()
👉检查是否存在缺失值:.isnull().values.any()。
1
2
3
4
5
6
7
#检查第1行是否存在缺失值
print(df.loc[0].isnull().values.any())#返回False说明无缺失值
print(df[0:1].isnull().values.any())#另一种表达方式,也是检查第1行是否有缺失值
#检查第3列是否存在缺失值
print(df["Age"].isnull().values.any())#返回True说明存在缺失值
#判断整个DataFrame中是否存在缺失值
print(df.isnull().values.any())#返回True说明DataFrame中存在缺失值
但是上述只能输出是否有缺失值,而不能知道缺失值的具体位置。
👉输出缺失值的具体位置:.isnull()或.notnull()。
1
2
3
4
5
6
7
8
9
10
11
#判断第4行缺失值的具体位置
print(df.loc[3].isnull())#False为非缺失值,True为缺失值
print(df.loc[3].notnull())#False为缺失值,True为非缺失值
#判断第5列缺失值的具体位置
print(df["Weight"].isnull())
print(df["Weight"].notnull())
#判断整个DataFrame中是否存在缺失值
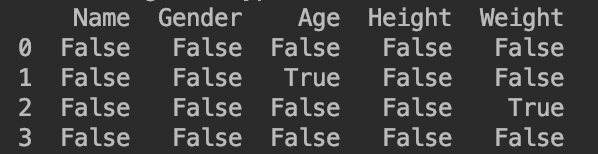
print(df.isnull())
print(df.notnull())
#同时检查所有列是否存在缺失值
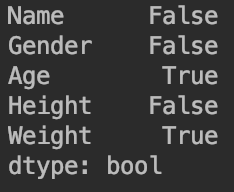
print(df.isnull().any())
以print(df.isnull())为例,其输出为:
print(df.isnull().any())输出为:
👉统计缺失值的数量:.isnull().sum()。
1
2
3
4
5
6
7
#统计第2行缺失值的数量
print(df.loc[1].isnull().sum())#output:1
#统计第3列缺失值的数量
print(df["Age"].isnull().sum())#output:1
#整个DataFrame缺失值的数量
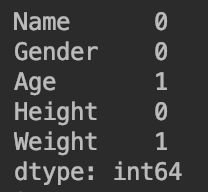
print(df.isnull().sum())#按列统计
print(df.isnull().sum().sum())#总计;output:2
例如print(df.isnull().sum())的输出为:
2.处理缺失值
2.1.舍弃缺失值
当缺失值占数据比例很低时,可以直接舍弃缺失值。
新建一个DataFrame:
1
2
3
4
5
6
import pandas as pd
import numpy as np
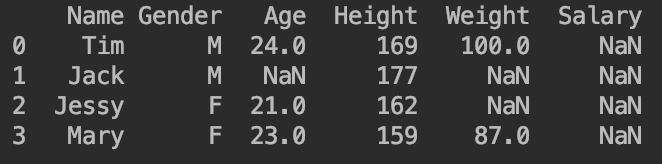
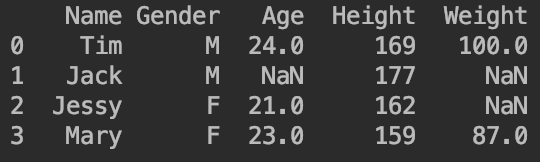
df=pd.DataFrame([["Tim","M",24,169,100],["Jack","M",np.nan,177,np.nan],["Jessy","F",21,162,np.nan],["Mary","F",23,159,87]])
df.columns=["Name","Gender","Age","Height","Weight"]
df["Salary"]=np.nan
print(df)
舍弃缺失值用到的函数:.dropna()。
👉舍弃含有缺失值(缺失值数量>0)的行/列:
1
2
3
4
#舍弃含有缺失值的行
print(df.dropna(axis=0,how="any"))#默认参数
#舍弃含有缺失值的列
print(df.dropna(axis=1,how="any"))
例如print(df.dropna(axis=1,how="any"))的输出为:
👉舍弃全部为缺失值的行/列:
1
2
#以列为例:axis=1
print(df.dropna(axis=1,how="all"))
输出为:
👉仅保留非缺失值数量大于等于一定阈值的行/列:
1
2
#以行为例:axis=0
print(df.dropna(axis=0,thresh=4))
参数thresh=4指的是仅保留非缺失值数量大于等于4的行/列。因此上述代码的输出为:

2.2.填补缺失值
除了舍弃缺失值,也可以对缺失值进行人为的估计并填补。可以使用函数.fillna()。
主要有两种方法:
- 使用叙述性统计填补缺失值。
- 使用内插法填补缺失值。
2.2.1.叙述性统计填补缺失值
使用平均数、中位数、众数等叙述性统计填补缺失值。
本部分如无特殊说明,默认使用2.1部分的DataFrame。
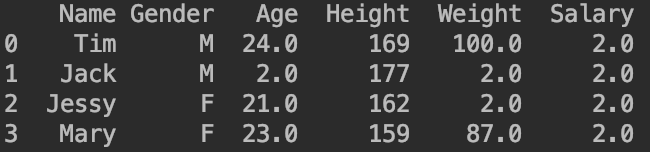
2.2.1.1.用某个具体数值填补缺失值
例如print(df.fillna(2))使用数值“2”来填补缺失值,其输出为:
2.2.1.2.用平均值填补缺失值
1
2
df["Age"].fillna(df["Age"].mean(),inplace=True)
print(df)
输出为:
![]()
参数inplace=True表示直接替换为修改后的结果。
2.2.1.3.用分层平均值填补缺失值
在2.1部分的例子的基础上再添加一条数据:
![]()
现在我们用各性别年龄平均值填补缺失值:
1
2
3
4
5
6
#方式一
df["Age"].fillna(df["Age"].groupby(df["Gender"]).transform("mean"),inplace=True)
print(df)
#方式二
df["Age"].fillna(df.groupby("Gender")["Age"].transform("mean"),inplace=True)
print(df)
两种方式的输出是一样的,均为:
![]()
groupby和transform的详细用法见第3部分。
2.2.1.4.向前/后填值
以2.2.1.3部分的DataFrame为例,去掉Salary列:
![]()
👉向后填补缺失值:第二行参照第一行,第三行参照第二行,以此类推。
1
2
#向后填补缺失值
df.fillna(method="pad",inplace=True)
![]()
👉向前填补缺失值:倒数第二行参照最后一行,倒数第三行参照倒数第二行,以此类推。
1
2
#向前填补缺失值
df.fillna(method="bfill",inplace=True)
![]()
此外也可以限制填补的行数,例如在向前填补缺失值时,只填补一行(从有缺失值的行开始算,不包含最后一行):
1
2
#在向前填补缺失值时,只填补一行
df.fillna(method="bfill",inplace=True,limit=1)
![]()
2.2.2.内插法填补缺失值
如果字段数据成规律分布(例如线性分布),可以使用内插法填补缺失值。
新建一个DataFrame:
1
2
3
df=pd.DataFrame([[1,870],[2,900],[np.nan,np.nan],[4,950],[5,1000],[6,1200]])
df.columns=["Time","Value"]
print(df)
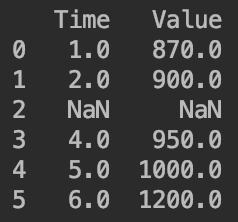
使用内插法填补缺失值:
1
2
#使用内插法填补缺失值
print(df.interpolate())
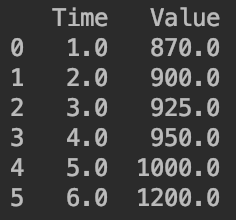
函数.interpolate()包含有很多方法,默认的是method="linear"。
3.groupby和transform
我们构建一个新的DataFrame,这次我们不用之前df=pandas.DataFrame([[...],[...],[...]])的这种方法,介绍一种新的构建DataFrame的方法:
1
2
3
np.random.seed(1)
df=pd.DataFrame({"key1":list('aabba'),"key2":["one","two","one","two","one"],"data1":np.random.randn(5),"data2":np.random.randn(5)})
print(df)
![]()
比如我们现在要分别求key1=’a’和key1=’b’时,对应的data1的平均数:
1
2
grouped=df["data1"].groupby(df["key1"])
print(grouped.mean())
![]()
通常transform和groupby会结合起来用。假设我们现在需要将求得的分层平均值对应放入data1中,就可以使用transform函数:
- 方式一:
df["data1"]=df["data1"].groupby(df["key1"]).transform("mean") - 方式二:
df["data1"]=df.groupby("key1")["data1"].transform("mean")
两种写法的结果都为:
![]()
