【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.算法原理
以汽车检测为例,我们需要检测出图片中汽车的位置,如下图所示:

首先,创建一个带标签的训练集,如下图所示:

在训练集中,我们对原始图片进行了适当的裁剪。使得正样本中,整张图片几乎都被汽车占据。然后我们就可以用这些训练集来训练一个卷积神经网络,输入为这些适当裁剪过的图片,输出为二分类,即图片中有汽车或没有汽车。
当我们拿到如下待检测图片时:

首先选定一个特定大小的窗口,将窗口内的图像输入网络,得到输出结果,如下图所示:

然后以特定的stride滑动该窗口,将窗口内的图像输入网络,得到输出结果,如下图所示:

重复上述步骤,直至该窗口遍历整个图像。这就是所谓的窗口滑动操作。此外,我们可以尝试多个大小不同的窗口:

以上便是基于滑动窗口的目标检测算法(sliding windows detection)的原理。该算法有一个明显的缺点就是计算成本太高。因为我们在图片中裁剪出了太多的小方块,卷积网络要一个个的处理。接下来的部分,我们来讲解下如何解决这个问题。
2.卷积的滑动窗口实现
参考OverFeat。
首先,我们先来了解下如何将全连接层转换为卷积层。假设我们有如下网络:
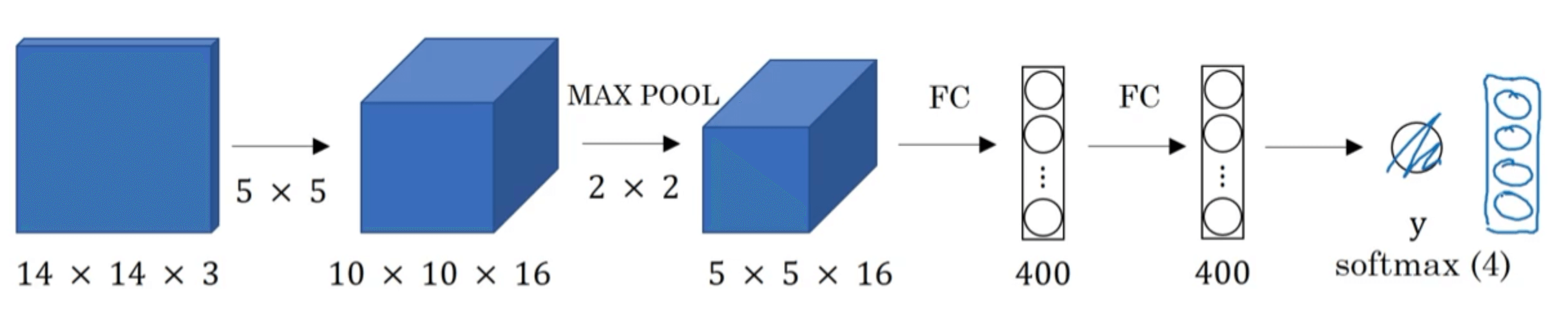
接下来将网络中的全连接层转化为卷积层:

上述两个网络结构完全是等价的。
假设我们通过滑动窗口得到的图片大小为$14 \times 14 \times 3$(即卷积网络的输入),网络结构和上述例子中的一样。为了方便画图,这里我们只画出来其中一个channel:

假设待检测图像大小为$16\times 16 \times3$,如果滑动窗口的stride=2,那么我们需要进行4次检测才能遍历整幅图像:
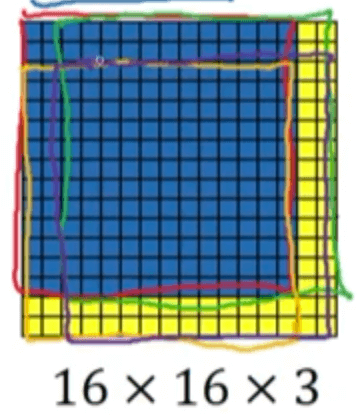
可以看到,四个窗口有很大的重叠部分,意味着我们进行了很多重复的计算。如果我们直接将待检测图片作为输入:
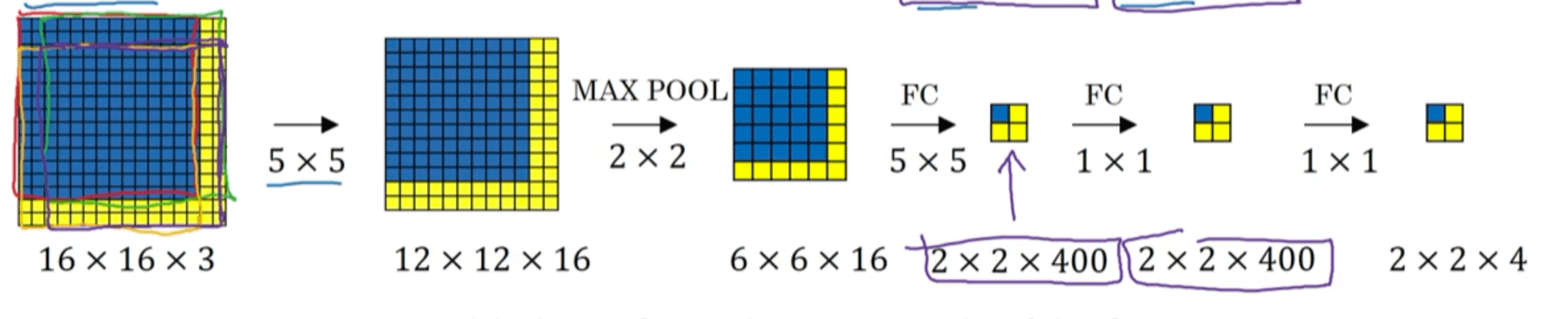
我们可以发现,输出层的四个子方块刚好对应是四个滑动窗口的结果。这样我们相当于只进行了一次检测就得到了该窗口尺寸下所有滑动窗口的结果,大大提高了算法效率。
