本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
传统的模式识别(traditional pattern recognition)通常分为两步:

即:1)从原始数据中提取特征;2)用提取的特征训练分类器。
在LeNet-5发表的那个年代,提取特征需要大量的先验知识,并且需要人为设计,这是一个非常耗时耗力的工作。除此之外,分类器的精度也很大程度上受到所提取的特征的影响。因此,那个时候的论文大都在讨论不同特征集之间的优劣。
随着时代的发展,因为数据量的增多和机器学习技术的进步等原因,使得多层神经网络可以用来解决模式识别问题,例如语音或手写文字的识别。这样就避免了人为选择特征这一繁琐的工作,特征的选择由网络自行完成,也就是说可以将原始数据(或稍做简单处理)直接作为网络的输入。
因此该论文提出了一种基于多层神经网络的手写数字识别模型(见本博客第2部分)。
本博客主要介绍文章的I,II.B部分,其中II.B部分最为重要,详细描述了LeNet-5的实现。文章的后几部分属于进一步的延伸内容,有兴趣的同学可以自行阅读原文(原文链接见本文末尾),本博客不再赘述。
此外,论文中含有大量对基础概念的解释,例如loss function、梯度、卷积等,在此也不再赘述。有不了解的可在本站阅读【深度学习基础】系列博客。
2.LeNet-5
2.1.详细结构
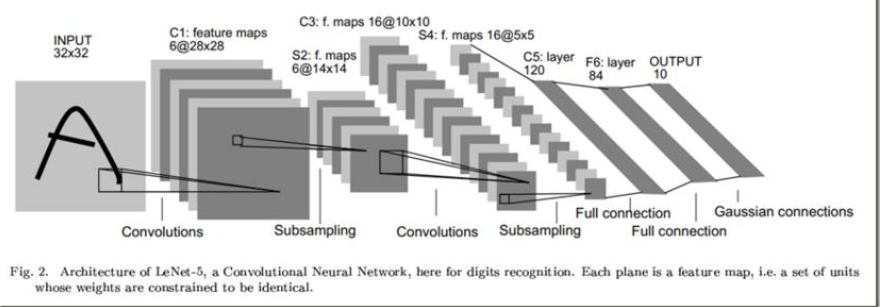
LeNet-5不算输入层,一共有7层。卷积层用$C_x$表示,下采样层用$S_x$表示,全连接层用$F_x$表示,其中$x$为层数。
但是下采样层通常不算在内,因此一共是有5层,所以称为LeNet-5。
神经网络层数的计算:【深度学习基础】第六课:浅层神经网络。
👉【INPUT】
输入大小为$32 \times 32 \times 1$的灰度图像,对输入做标准化(normalized)处理,将像素值标准化至$[-1,1.175]$,使得像素值的均值大约为0,方差大约为1,这样可以加速学习。
👉【$C_1$】
使用的卷积核大小为$5 \times 5 \times 1$,数量为6,步长为1(LeNet-5被创作的那个年代,人们不使用padding)。得到的feature map的维度为$28\times 28$,feature map的数量为6。本层共包含156个参数:$5\times 5\times 1\times 6+6=156$。本层共有122304次连接(connection):$5\times 5\times 28\times 28\times 6+28\times 28\times 6=122304$。
👉【$S_2$】
这里的下采样层类似于我们现在的pooling层,但是做法稍有不同。本层所用的核大小为$2\times 2$(步长为2),因此得到的feature map为$14\times 14\times 6$。常见的pooling层是直接取最大值或者平均,而这里的$S_2$是先将四个格子($2\times 2$)的输入求和(z),然后乘上一个系数(w),再加上一个偏置值(b),最后通过sigmoid函数(即$sigmoid(wz+b)$)。即相当于average pooling(只不过这里是加权平均)之后通过一个sigmoid激活函数。本层一共有12个参数:6个$2\times 2$的核,每个核有2个参数(w,b),所以有$6\times 2=12$。本层一共有5880次连接:$14\times 14\times 5\times 6=5880$。解释下式子里的5,假设四个格子里的值分别为$x_1,x_2,x_3,x_4$,一次下采样为$w\times (x_1+x_2+x_3+x_4)+b$,刚好是5次连接。
👉【$C_3$】
使用的卷积核数量为16。如果想要得到$10\times 10\times 16$的feature map,按照现在普遍的做法,每个卷积核的大小应该为$5\times 5\times 6$(步长为1),但是LeNet-5并不是这么做的。在LeNet-5中,每个卷积核的大小并不完全一样,如下图所示:
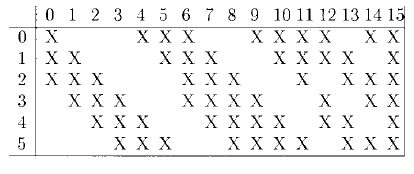
上图中,每一列可以看成每一个卷积核(一共16个),每一行为$S_2$层的每一个feature map(一共6个)。以第0列为例:第0个卷积核只和$S_2$层的前3个feature map进行了卷积运算,因此该卷积核大小应该为$5\times 5\times 3$。因此该层的参数数量为:$5\times 5\times 3\times 6+5\times 5\times 4\times 9+5\times 5\times 6\times 1+16=1516$。
总的连接数($150000+6000=156000$):
- 卷积部分:$5\times 5\times 3\times 6\times 10\times 10+5\times 5\times 4\times 9\times 10\times 10+5\times 5\times 6\times 1\times 10\times 10=150000$
- 偏置项部分:$3\times 6\times 10\times 10+4\times 9\times 10\times 10+6\times 1\times 10\times 10=6000$(一个$5\times 5\times 3$的卷积核进行一次卷积运算,会进行3次偏置项的加法运算,但是这三次加法运算使用的偏置项是同一个)
该层最终得到$10\times 10\times 16$的feature map。
👉【$S_4$】
和$S_2$层一样。使用$2\times 2\times 16$的核(步长为2),得到的feature map为$5\times 5\times 16$。可训练的参数数量为:$2\times 16=32$。总的连接数为:$5\times 5\times 5\times 16=2000$。
👉【$C_5$】
卷积核共120个,大小为$5\times 5\times 16$。得到的feature map为$1\times 1\times 120$。参数数量:$5\times 5\times 16\times 120+120=48120$。这一层相当于就是$S_4$和$C_5$之间的全连接。之所以没有把$C_5$命名为全连接层$F_5$,是因为如果其他条件都不变,只是增大输入的维度,那么$C_5$得到的feature map的维度会大于$1\times 1$。
👉【$F_6$】
含有84个神经元的全连接层。参数数量:$84\times 120+84=10164$。$ F_6$层及之前层的激活函数为tanh函数,详细形式见下:
\[f(a)=A tanh(Sa)\]此处多了两个超参数:A和S。A控制tanh函数的振幅,即f(a)的取值范围在-A到+A之间。论文中设A=1.7159。S控制tanh函数在原点处的斜率(倾斜程度),论文中设S=2/3。
将$F_6$层设置为84个神经元的原因:标准的字符比特图(bitmap)是$7\times 12$像素的,共有$16\times 6$个标准的字符比特图:

$F_6$层中84个神经元的值只有-1(白色)或+1(黑色)两种选择,因此这84个神经元便可看作一个$7\times 12$像素的比特图,然后计算该比特图和上图中标准的字符比特图的接近程度,最接近哪个字符比特图,预测结果便可判定为该字符。
因此LeNet-5也可以通过修改输出层使其可以预测所有的上述字符,而不仅仅只是预测数字。
👉【OUTPUT】
输出层共有10个神经元,分别表示数字0~9。使用径向基函数 (Radial Basis Function 简称 RBF)。每个神经元的计算方式如下:
\[y_i=\sum_j(x_j-w_{ij})^2\]公式含义图解见下:

权重矩阵大小为$84 \times 10$,每一行为一个字符比特图,共10行(0-9)。上式的意义其实就是相当于将$F_6$层预测出来的$7 \times 12 =84$像素的比特图与标准的0-9字符比特图做比较,求其对应位置上像素值的均方误差。
2.2.预测流程
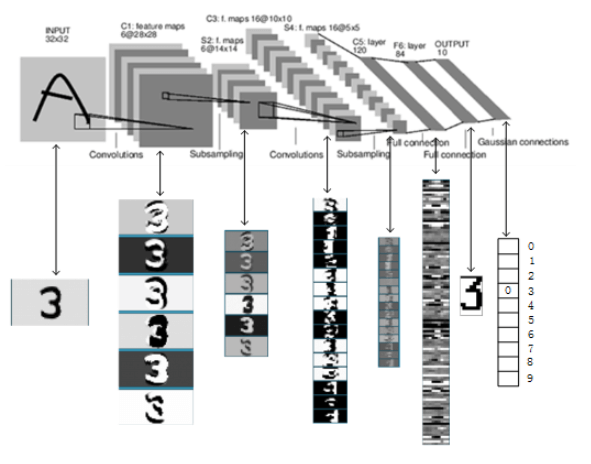
LeNet-5完整的预测流程(以数字“3”为例,输出层vector为1110111111):
2.3.loss function
使用均方误差或者交叉熵损失函数均可。
3.原文链接
👽Gradient-Based Learning Applied to Document
