【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.前言
在自然语言处理(Natural Language Processing,NLP)任务中,文本是一种非结构化的数据信息,模型无法直接使用,需要对其进行转换。之前我们一直用one-hot编码表示词汇表中的单词(one-hot representation),例如:

使用符号$o_{5391}$表示单词man的one-hot编码(5391为单词man在词汇表中的位置),其余类似。这种表示方法的一大缺点就是每个单词都是孤立的。举个例子,假如我们已经训练了一个语言模型,其可以预测句子:“I want a glass of orange __”中的空白位置应该为单词juice。此时如果有另外一个句子:“I want a glass of apple __”,因为算法并不能判断orange和apple都属于水果,两者有着很高的相似性,因此算法很难从前一个句子推断出后一个句子中的空白位置也应该是单词juice。
因此本文介绍另外一种方法:词嵌入(word embeddings)。词嵌入和one-hot编码类似,也是一种将文本中的词转换成数字向量的方法。但是词嵌入可以让模型更好的理解词与词之间的类比,比如:男人和女人,国王和王后。
之所以叫“词嵌入”是因为每个单词对应的向量就如同一个点被“嵌入”在了特征空间内。
常见的词嵌入方法:
- Word2Vec
- GloVe
词嵌入的可视化方法:
- t-SNE
2.词嵌入
首先,我们尝试不用one-hot编码表示单词,而是用特征编码表示单词(featurized representation)。比如分别计算每个单词和gender、royal、age、food等特征的关系:
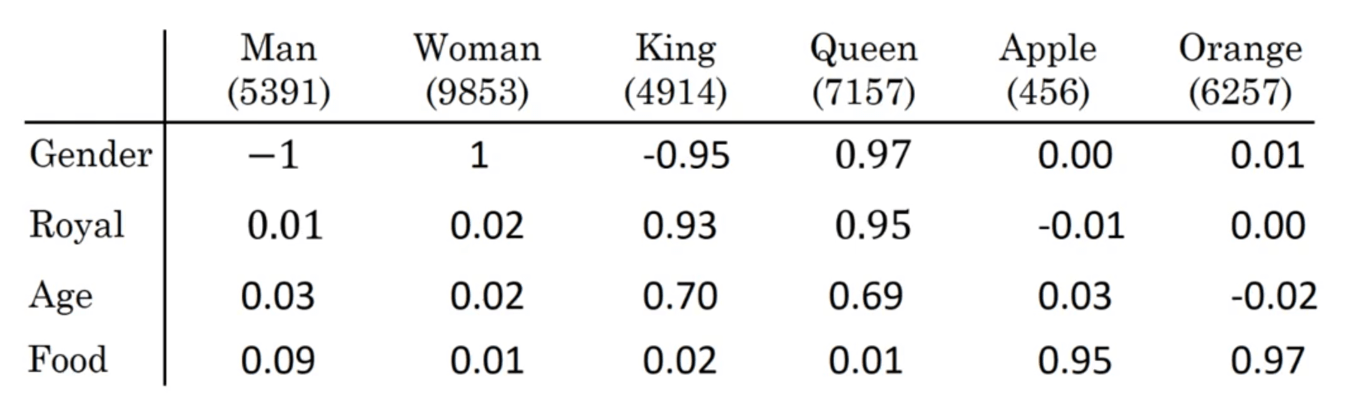
在实际应用中,特征通常并不能被解释的这么具体。
假设我们使用了300个特征,即每个单词可用一个300维的向量表示。类似的,使用符号$e_{5391}$或$e_{man}$表示单词man的特征编码。
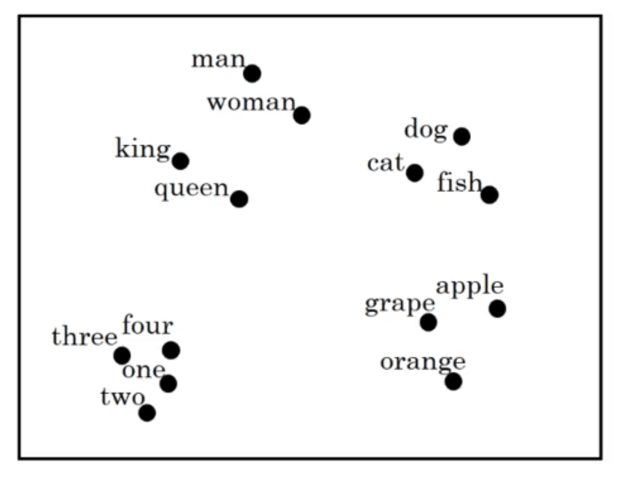
使用t-SNE技术将每个单词对应的300维向量通过非线性的方式映射到二维上进行可视化:
t-SNE技术出自论文:Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of machine learning research, 2008, 9(Nov): 2579-2605.
通过可视化的结果,我们可以发现相似的单词距离更近。
此外,词嵌入还有一些其他的性质,例如:
\[e_{man}-e_{woman} \approx e_{king} - e_{queen} \approx \begin{bmatrix} -2 \\ 0 \\ 0 \\ 0 \\ \end{bmatrix}\]这个结果表示man和woman的主要差别在于性别,而king和queen的主要差别也在于性别。
这一成果引自论文:Mikolov T, Yih W, Zweig G. Linguistic regularities in continuous space word representations[C]//Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies. 2013: 746-751.
假设我们知道了man,woman,king的词向量,想推倒出和king(在性别方面)对应的词(设其词向量为$e_w$)是什么。那么我们就需要最大化以下相似度:
\[\mathop{\arg\max}_{w} sim(e_w,e_{king}-e_{man}+e_{woman})\]相似度$sim$的计算通常使用cosine similarity。cosine similarity定义如下:
\[sim(u,v)=\frac{u^T v}{\lVert u \rVert _2 \lVert v \rVert _2}\]即向量$u,v$夹角的余弦值,也就是相关系数。
除了cosine similarity,我们还可以用欧氏距离定义$sim$(注意此时应该最小化$sim$):
\[sim(u,v)=\lVert u-v \rVert ^2\]3.嵌入矩阵
假设我们词汇表中有10000个单词,每个单词使用300个特征进行描述,那么我们便可得到一个$300 \times 10000$的嵌入矩阵$E$。
如何从嵌入矩阵$E$中取出某一单词的特征向量(或称“嵌入向量”)呢?答案是乘上其对应的one-hot编码(列向量)即可。例如取$e_{6257}$:
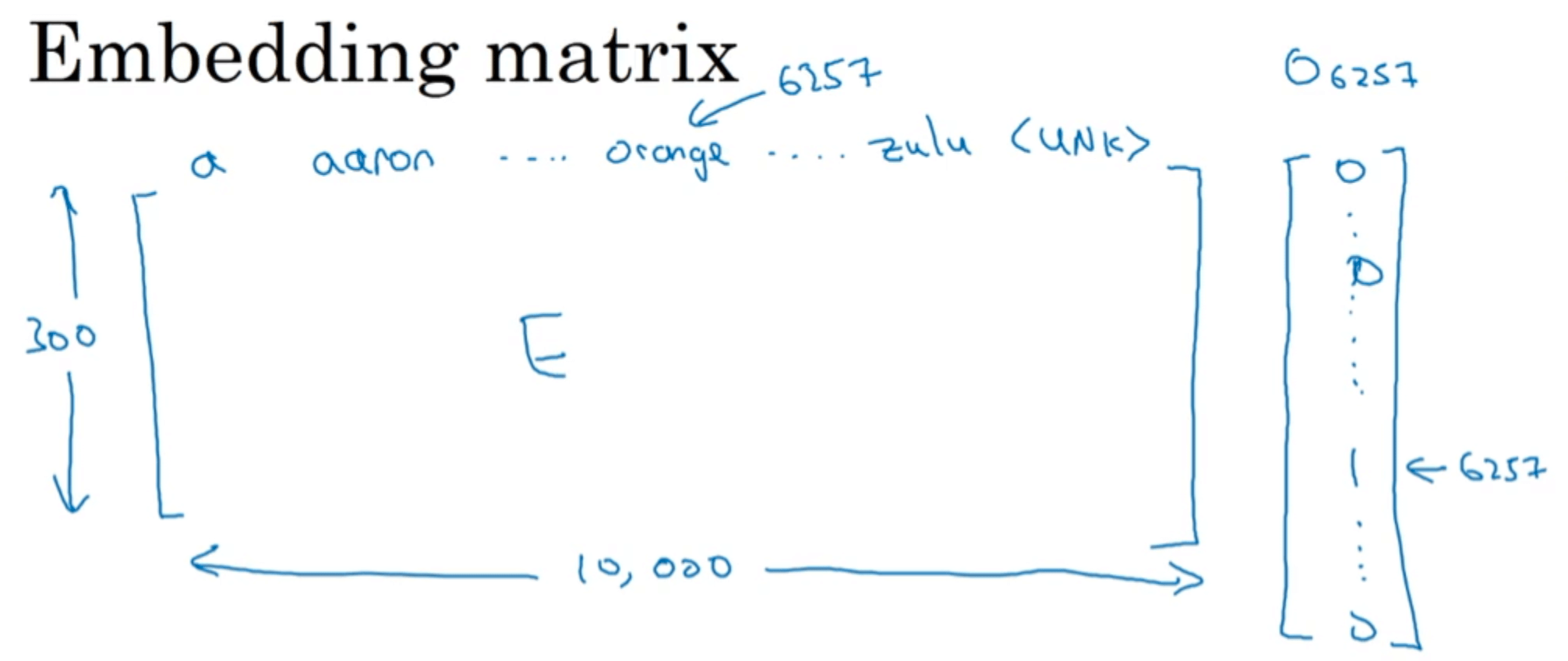
但是在实际实现时,因为矩阵维数通常很大,所以矩阵乘法的效率会很低。因此我们通常会使用某些接口函数直接提取矩阵$E$中的某一列。
那么我们该如何学习这个嵌入矩阵呢?建立一个语言模型是学习嵌入矩阵的一个好方法。
该观点来自论文:Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of machine learning research, 2003, 3(Feb): 1137-1155.
假设现在有一个句子如下(每个单词下面的数字为其在词汇表中的索引),我们想要建立一个语言模型预测句子的最后一个单词:

我们使用一个普通的两层全连接神经网络来构建这个语言模型,输入为句子中所有单词的嵌入向量,即输入层的神经元数为$6\times 300$(假设嵌入矩阵的维度为$300 \times 10000$且被随机初始化)。输出层使用softmax激活函数:
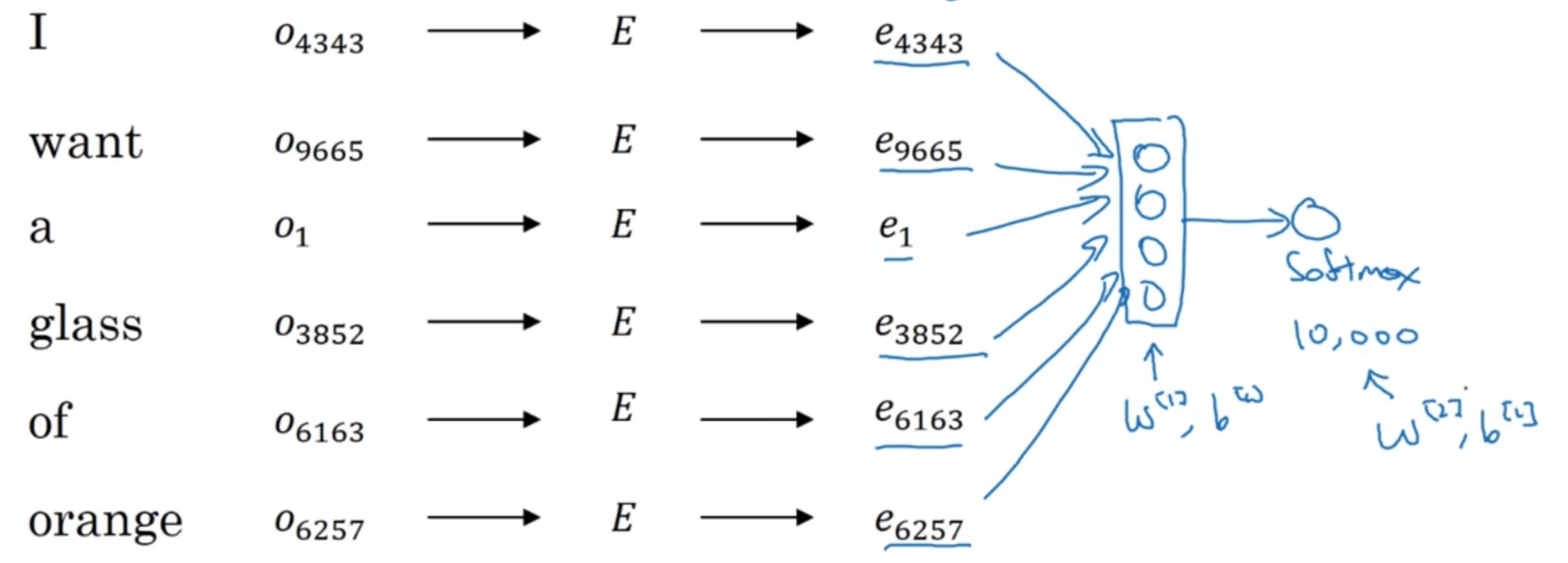
然后便可通过反向传播来更新嵌入矩阵$E$。
作为网络输入的单词也被称为context。本例中我们使用了句子中的所有单词作为context,但是如果训练集中的句子长短不一,则会导致网络的输入维度不固定。因此,我们可以取目标单词(即待预测的单词)的前面四个单词作为context以避免这个问题(这里的4是一个超参数):
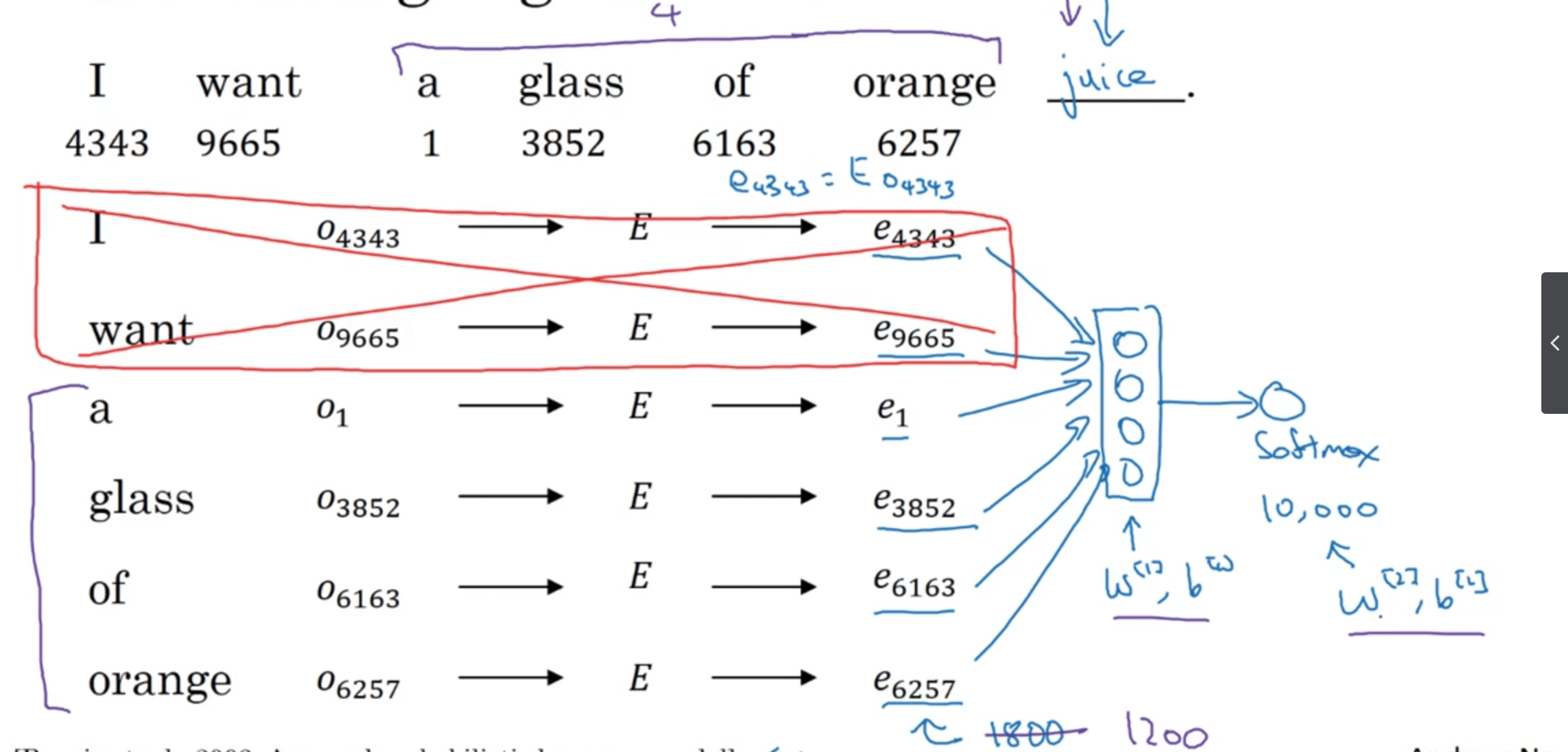
context的设定并不是固定的。例如,有句子:“I want a glass of orange juice to go along with my cereal.”,假设目标单词为“juice”,context可以是:
- 前面的4个单词:a,glass,of,orange。
- 前面以及后面各4个单词:a,glass,of,orange,to,go,along,with。
- 前面的1个单词:orange。
- 附近的一个单词(不一定紧邻目标单词):glass(也可能是其他附近的词,这里只是举个例子)。这是一种skip-gram模型的思想(下文会有详细介绍)。
如果单纯的只是想创建一个语言模型,那么第1种context是一个不错的选择。剩余的3种context比较适合于学习嵌入矩阵。
4.Word2Vec
原始论文:Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
Word2Vec是一种更为高效的学习词嵌入的方法。Word2Vec 的训练模型本质上是只具有一个隐含层的神经元网络:
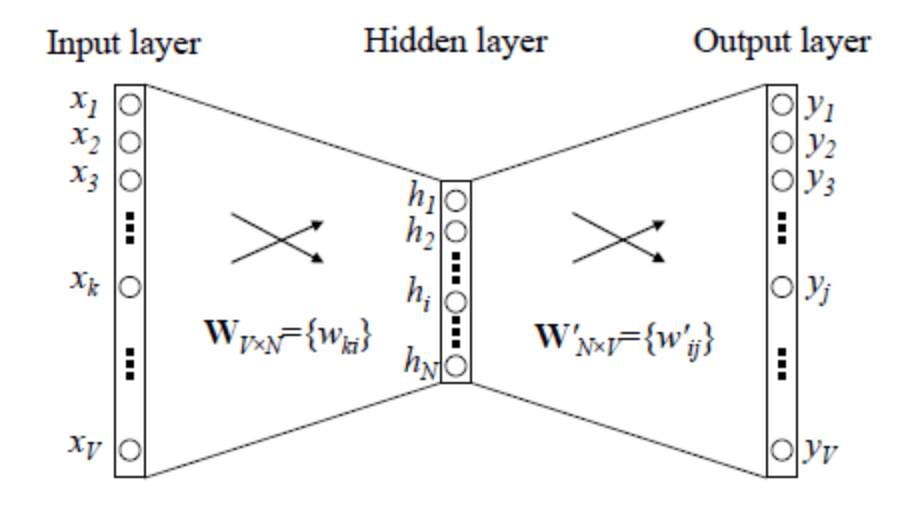
$V$为词汇表中单词数量,即one-hot编码的维数。$N$为经过嵌入矩阵转换后单词编码的维数,即嵌入矩阵的行数。网络输入是一个或多个单词的one-hot编码,输出为另一个或多个单词的one-hot编码。参数矩阵$W_{V\times N}$的转置即为嵌入矩阵E。
Word2Vec主要分为两个模型:
- skip-gram模型:在大数据集中表现更好。target word为网络输入,context word为网络输出。例如有句子“There is an apple on the table.”,输入可为apple,输出可为is,an,on,the。
- CBOW模型(the Continuous Bag Of Words Model):在小数据集中表现更好。context word为网络输入,target word为网络输出。例如有句子“There is an apple on the table.”,输入可为is,an,on,the,输出可为apple。
提升Word2Vec效率的两个办法:
- Hierarchical Softmax。
- Negative Sampling。
4.1.skip-gram模型
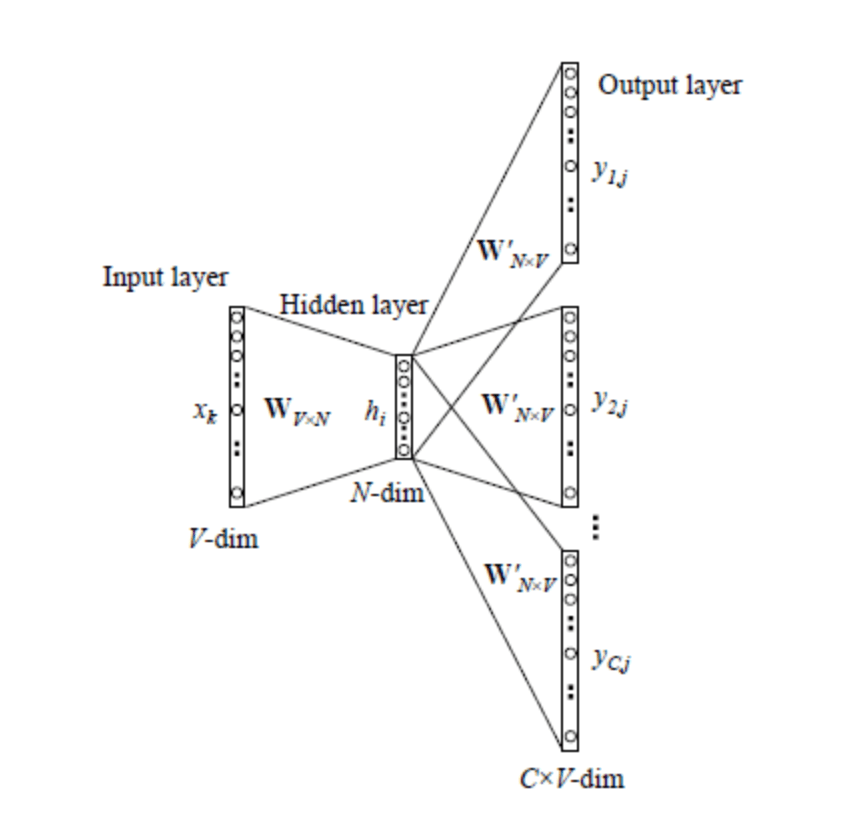
输出的context word由两个参数决定:
skip_window:选取输入单词两侧的单词放进window。例如skip_window=2,则window内的词为is,an,on,the。num_skips:从window中选取多少个不同的词作为context word。例如skip_window=2, num_skips=2,则context word为an,on。
4.2.CBOW模型
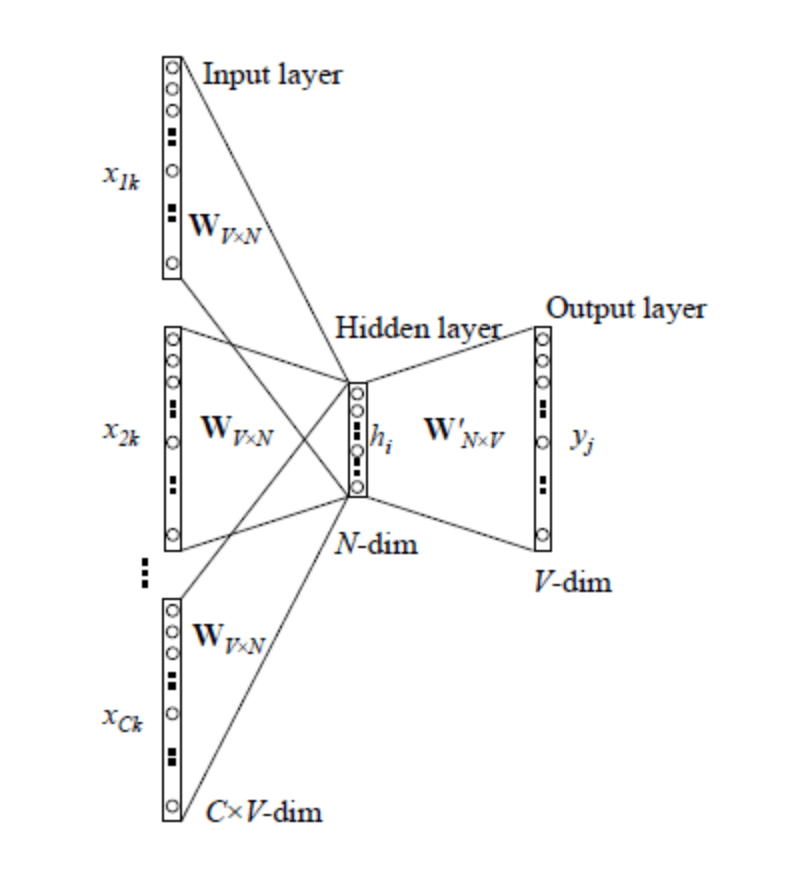
$C$为context word的个数。
4.3.Hierarchical Softmax
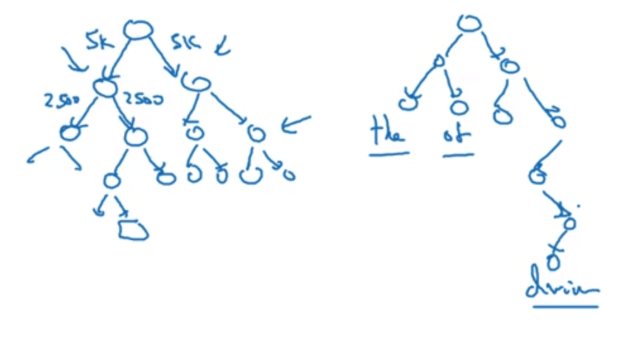
Word2Vec输出层的激活函数为softmax函数。但是通常词汇表中的单词会非常的多(十万或者百万级别),所以one-hot编码的维度非常大,导致softmax函数的计算效率非常低。因此使用Hierarchical Softmax来解决这个问题。即先判断输出的单词在词汇表中的前50%还是后50%,如果在前50%,则继续判断是在前50%的前50%,还是在前50%的后50%,剩余的以此类推。但通常会有一个更高效的办法,即不是一个平衡的二叉树,会把常见词放在树的上层,而生僻词放在树的下层:
4.4.Negative Sampling
原始论文:Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in neural information processing systems, 2013, 26: 3111-3119.
假设有句子:“I want a glass of orange juice to go along with my cereal.”。我们选择单词“orange”作为context word,单词“juice”作为target word,即<orange,juice>作为正样本。然后随机选择词汇表中的其他单词和“orange”组成<context,word>词对,即负样本。比如:

如何选择构成负样本的word?方法一:根据词频进行选择,词频越高的单词越容易被选择。但这样做最后选出来的单词大多都是like,the,of,and这种没有实际意义的单词。方法二:均匀随机选择,即每个单词被选择到的概率都是均等的。但是这样选出来的单词缺少代表性。因此,论文作者Mikolov提出了一种中和的办法:
\[P(w_i)=\frac{f(w_i)^{3/4}}{\sum_{j=0}^n(f(w_j)^{3/4})}\]这样做适当的降低了高频词被选择的概率且增加了低频词被选择的概率。
$f(w)$为单词的词频,$n$为词汇表中单词的总数目,$P(w)$为单词被选择的概率。$\frac{3}{4}$是一个经验值。
关于负样本的数量$K$:对于小数据集,$K$一般取5到20之间;对于大数据集,$K$一般取2到5之间。每一个正样本都对应$K$个负样本。数据集越小,$K$就越大。本例中,$K=4$。使用逻辑回归模型预测每个词对是否为目标词对。这样的话,网络的输出层就改为了10000个(假设词汇表中共有10000个单词)二分类逻辑回归模型。但并不是每次都迭代这10000个二分类模型,我们只训练其中的$K+1$个(在本例中为列出的5个词对)。相比训练一个10000维度的softmax函数,计算成本降低很多。
5.GloVe
GloVe全称为Global Vectors for Word Representation。
原始论文:Pennington J, Socher R, Manning C D. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
5.1.共现矩阵
首先构建词与词之间的共现矩阵$X$。矩阵$X$中的元素$X_{ij}$是语料库中单词$j$出现在单词$i$上下文中的次数。定义以下公式:
\[X_i=\sum_k X_{ik}\] \[P_{ij}=P(j \mid i)=\frac{X_{ij}}{X_i}\] \[ratio_{i,j,k}=\frac{P_{ik}}{P_{jk}}\]论文的作者发现$ratio_{i,j,k}$是有一定规律的:

可以看出,$ratio_{i,j,k}$能够反映出单词之间的相关性,而GloVe模型便是利用了$ratio_{i,j,k}$。
5.2.代价函数
GloVe模型的最终目的和Word2Vec是一样的,即得到每个单词对应的词嵌入向量。假设我们已经得到了单词$i,j,k$的词嵌入向量$v_i,v_j,v_k$,如果存在函数$g$使得:
\[g(v_i,v_j,v_k)=ratio_{i,j,k}=\frac{P_{ik}}{P_{jk}}\]那么我们便可以认为我们学得的词嵌入向量与共现矩阵具有很好的一致性,也就说明我们的词嵌入向量中蕴含了共现矩阵中所蕴含的信息。
因此,很容易想到用二者差的平方作为代价函数($N$为语料库中的单词数目):
\[J=\sum_{i,j,k}^N (\frac{P_{ik}}{P_{jk}} - g(v_i,v_j,v_k))^2\]但是模型中包含3个单词,这就意味着要在$N\times N\times N$的复杂度上进行计算,太复杂了,尝试对其进行简化。
👉论文作者的思考过程:
要考虑单词$i$和单词$j$之间的关系,那$g(v_i,v_j,v_k)$中可能得有一个$(v_i - v_j)$,这是一个非常合理的猜测。$ratio_{i,j,k}$是个标量,那么$g(v_i,v_j,v_k)$的结果也应该是一个标量,但是其输入都是向量,因此通过计算得到一个标量:$(v_i - v_j)^T v_k$。
$\frac{P_{ik}}{P_{jk}}$是一个比值,我们希望$g(v_i,v_j,v_k)$的结果也可以是一个比值,所以作者又加上了一层指数运算:
\[\frac{P_{ik}}{P_{jk}} = exp((v_i - v_j)^T v_k)\]即:
\[\frac{P_{ik}}{P_{jk}} = exp(v_i^T v_k - v_j^T v_k)\]即:
\[\frac{P_{ik}}{P_{jk}} = \frac{exp(v_i^T v_k)}{exp(v_j^T v_k)}\]此时我们只需尽量让上述等式尽量成立即可。又因为上式的分子和分母形式一样,所以等式可以简化为:
\[P_{ij}=exp(v_i^T v_j)\]两边取个对数:
\[\log (P_{ij})=v_i^T v_j\]然而这里存在一个问题,仔细看以下两个式子:
\[\log (P_{ij})=v_i^T v_j\] \[\log (P_{ji})=v_j^T v_i\]$\log (P_{ij})$不等于$\log (P_{ji})$,但是$v_i^T v_j$等于$v_j^T v_i$。那么如何解决这个问题呢?我们可以将$P_{ij}$展开:
\[\log (P_{ij})=\log (\frac{X_{ij}}{X_i})=\log (X_{ij})-\log(X_i)=v_i^T v_j\]将$\log(X_i)$移到等式的另一边:
\[\log (X_{ij})=v_i^T v_j+\log(X_i)=v_i^T v_j + b_i + b_j\]上式中添加了一个偏差项$b_j$,并将$\log (X_i)$吸收到偏差项$b_i$中。
因此,代价函数就变成了:
\[J=\sum_{i,j}^N (v_i^T v_j + b_i + b_j -\log (X_{ij}) )^2\]然后基于出现频率越高的词对权重应该越大的原则,在代价函数中添加权重项,于是代价函数进一步完善:
\[J=\sum_{i,j}^N f(X_{ij}) (v_i^T v_j + b_i + b_j -\log (X_{ij}) )^2\]👉那么该如何定义权重函数$f(x)$呢?
作者认为权重函数应该符合以下三个特点:
- $f(0)=0$,即如果两个词没有共同出现过,权重就是0。
- $f(x)$必须是非减函数。如果两个词共同出现的次数多,反而权重变小了,这违反了设置权重项的初衷。
- $f(x)$对于较大的$x$不能取太大的值。因为停用词的词频都会很高,但是并没有什么重要意义。
综上,$f(x)$定义如下:
\[f(x) = \begin{cases} (\frac{x}{x_{max}})^{\alpha}, & x<x_{max} \\ 1, & \text{otherwise} \end{cases}\]
根据经验,GloVe作者认为$x_{max}=100,\alpha=\frac{3}{4}$是一个比较好的选择。
GloVe模型并没有用到神经网络。
6.NLP应用:情感分类
假设我们有训练集为顾客对一个餐馆的评价以及对应的评级:

训练集规模可能并不会太大,对于情感分类问题来说,训练集大小从10000到100000都是很常见的。但是我们可以通过一个一百亿大小的语料库训练词嵌入矩阵,这样的话,尽管情感分类任务的训练集的规模不大,但是我们依然可以训练出一个不错的情感分类模型。例如构建模型如下:
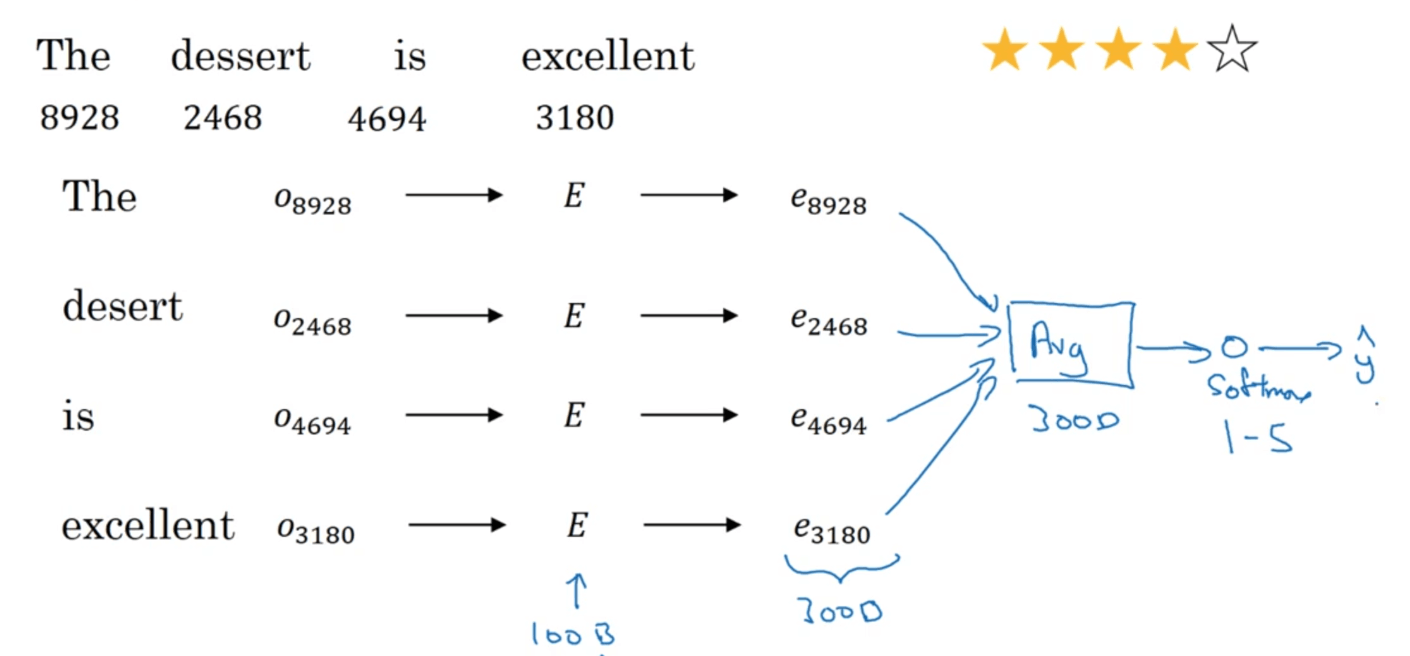
模型中对多个单词的嵌入向量求了平均,使其维度保持为$300\times 1$(假设嵌入向量的维度为$300\times 1$),这样就无所谓输入句子的长短了。但是这样做有个弊端,即没有考虑到词序。如果有句子“Completely lacking in good taste, good service, and good ambience.”,句子中多次出现“good”这个单词,在求平均之后,模型可能会误将该条评论预测为高评级,其实该评论的评级是很低的。因此,我们可以改用RNN模型:

由于我们使用了一个不错的词嵌入矩阵,因此对于句子“Completely absent of good taste, good service, and good ambience.”,模型也同样可以预测出其评级为一颗星,尽管有可能单词“absent”压根就没在训练集中。
7.词嵌入除偏
我们应该尽量减少或消除在学习词嵌入矩阵时引入人为的偏见,比如性别歧视,种族歧视等。
相关研究论文:Bolukbasi T, Chang K W, Zou J Y, et al. Man is to computer programmer as woman is to homemaker? debiasing word embeddings[J]. Advances in neural information processing systems, 2016, 29: 4349-4357.
以性别歧视为例,存在性别歧视的词嵌入的例子:
- Man:Computer Programmer as Woman:Homemaker
- Father:Doctor as Mother:Nurse
怎么解决这个问题呢?假设我们现在已经学得了一个存在性别歧视的词嵌入矩阵,其中某些词的分布可能如下所示:
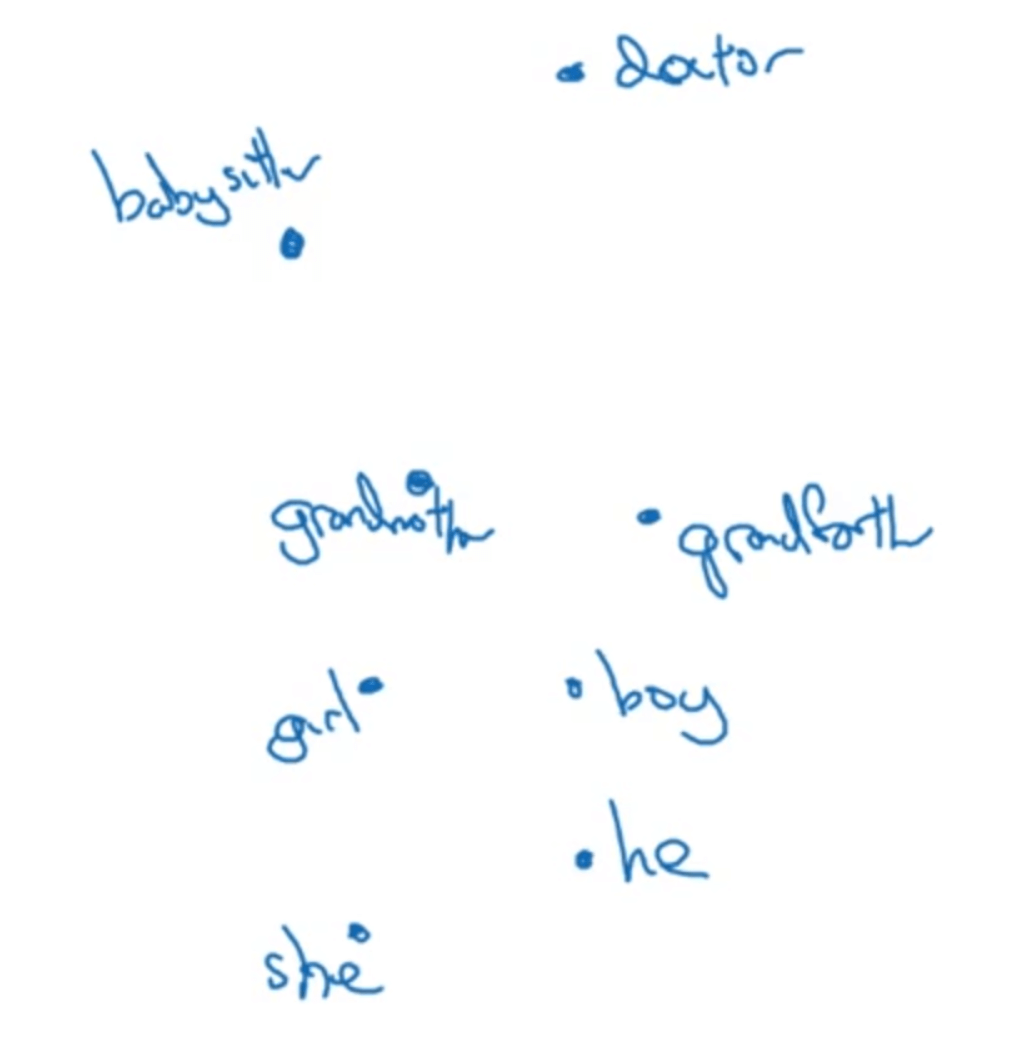
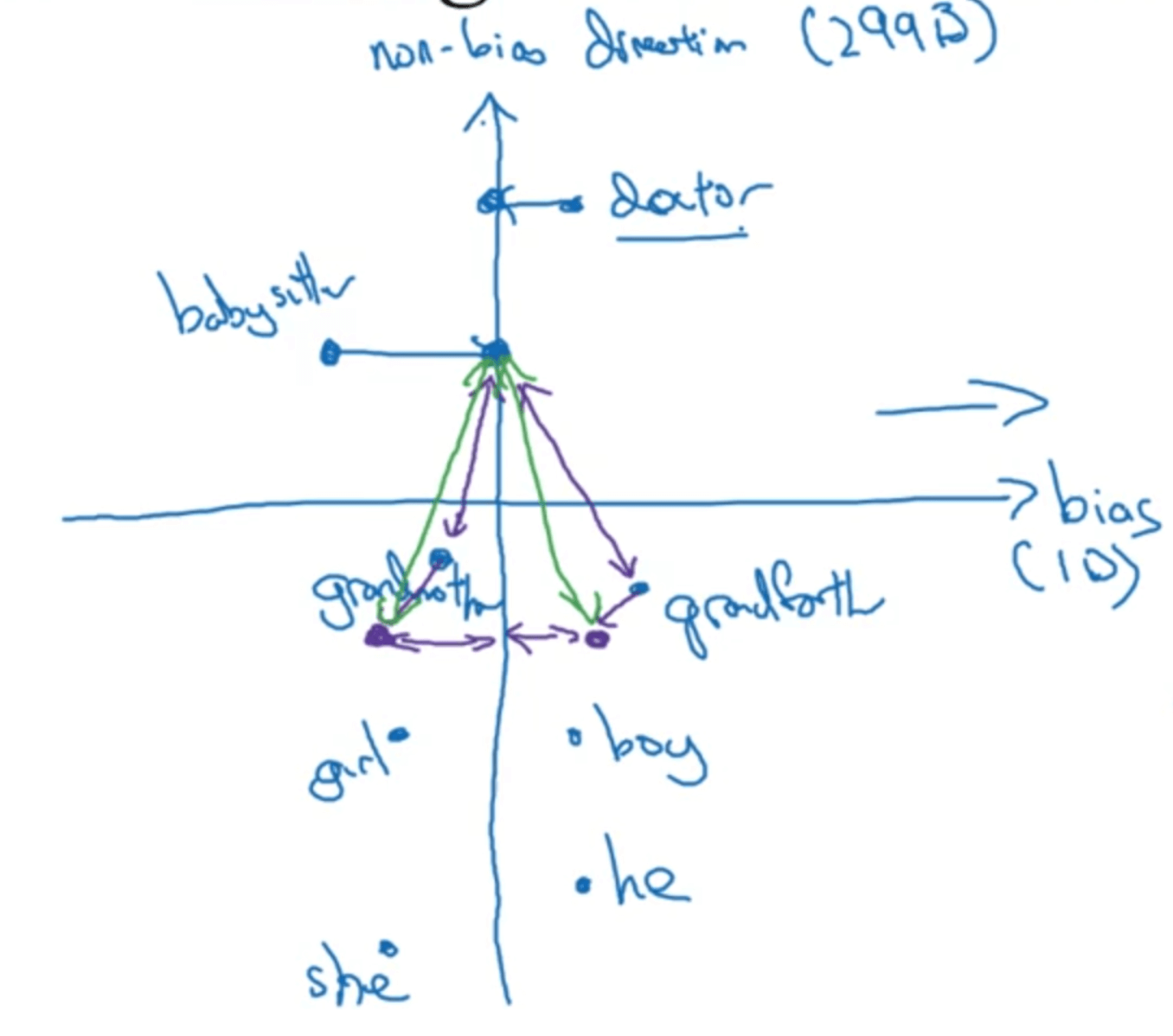
👉步骤一:Identify bias direction,即确定要消除或减少的偏见(或者歧视)。本例中,我们着重要消除性别歧视。假设因固有属性而不是偏见造成的只有性别存在差异的单词对有he/she、male/female等。将这些单词对的嵌入向量相减并求平均作为bias的方向:
\[average((e_{he}-e_{she})+(e_{male}-e_{female})+ \cdots)\]理所当然的,与bias方向(即bias direction)垂直的方向即为与性别无关的方向,即non-bias direction:
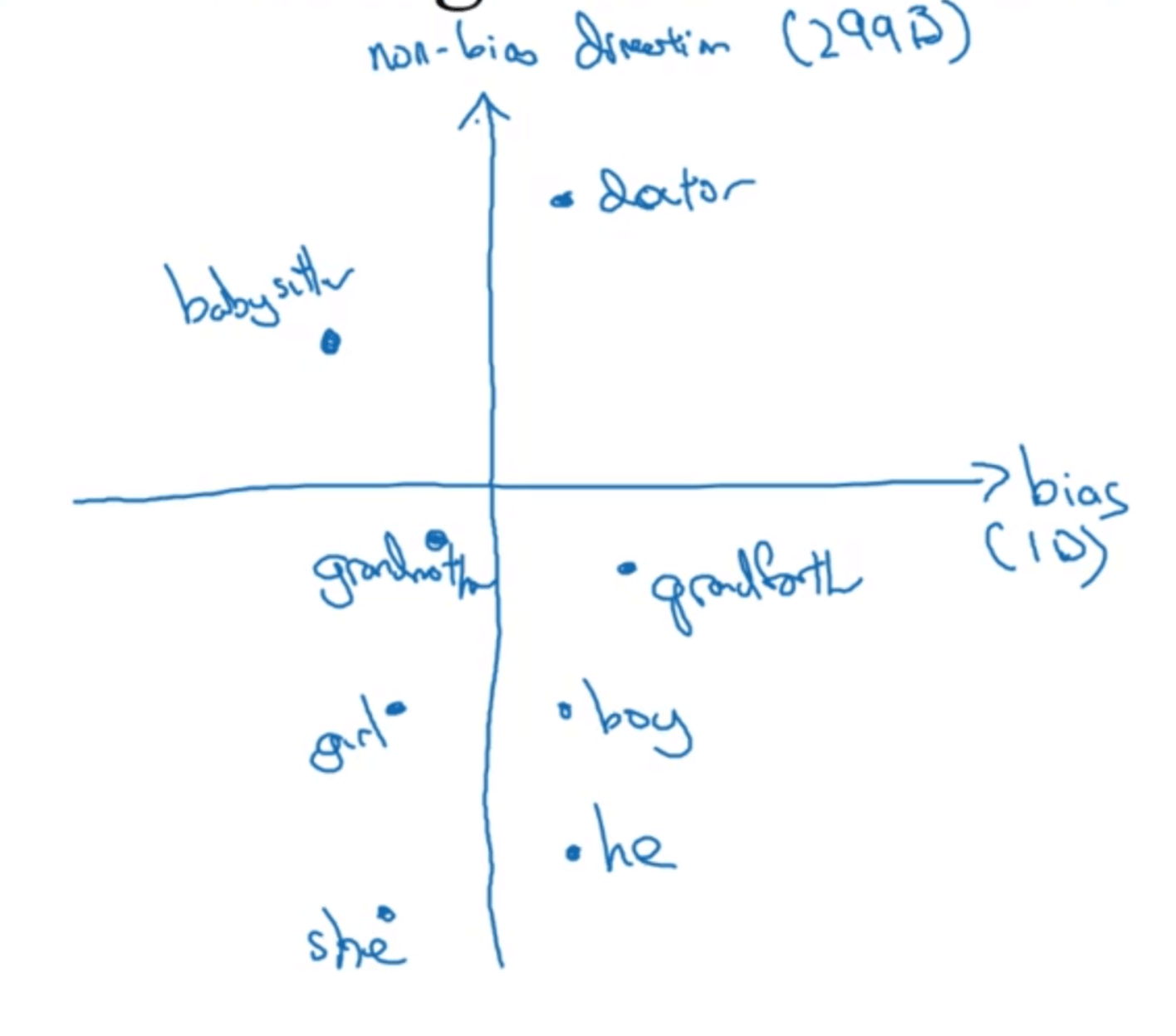
在这种情况下,假设嵌入向量的维度为300,bias direction可以看作1维子空间(实际可能会超过1维),那么non-bias direction就是299维的子空间。
👉步骤二:Neutralize。即将存在性别歧视的单词映射到non-bias direction。比如单词doctor,babysitter:
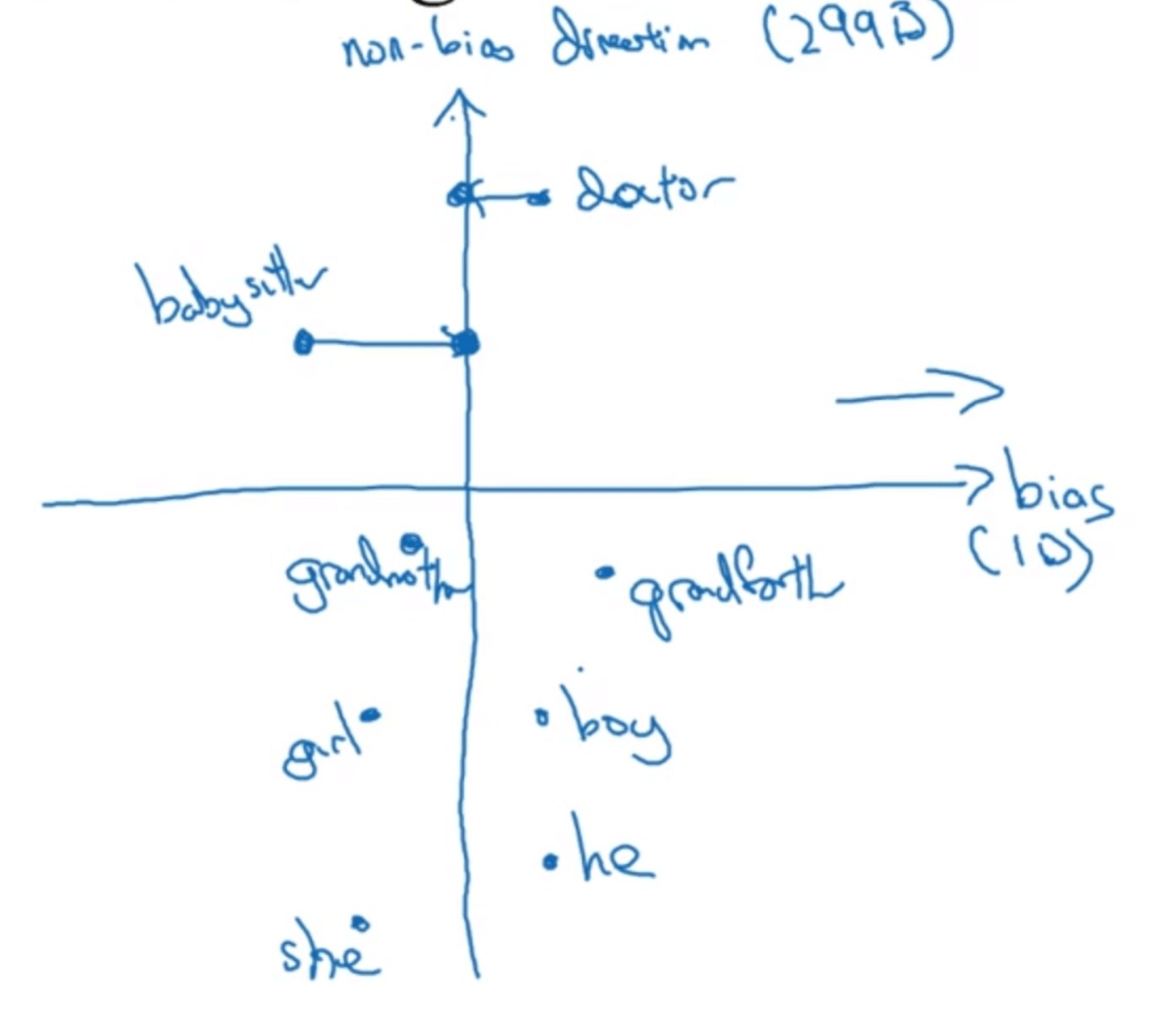
👉步骤三:Equalize pairs。以单词babysitter为例,在做完映射之后,该词到grandmother和gradfather的距离仍然不相等,也就是说在性别方面还是具有一定的偏向性。因此我们对步骤一中提到的单词对进行进一步的处理,使之到non-bias direction的距离都是相等的: