【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Seq2Seq模型
我们先来看一个简单的seq2seq(sequence to sequence)模型。假设有一个法语句子:Jane visite l’Afrique en septembre.。我们想通过一个模型将其翻译成英语,例如:Jane is visiting Africa in September.。
使用$x^{<t>}$表示输入句子中的第t个单词,$y^{<t>}$表示输出句子中的第t个单词:

本文所用的方法主要来自以下两篇文献:
Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J]. arXiv preprint arXiv:1409.3215, 2014.
Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
首先,使用RNN构建一个编码器(encoder,下图绿色部分),待输入序列接收完毕后,接一个RNN构建的解码器(decoder,下图紫色部分),用于输出:
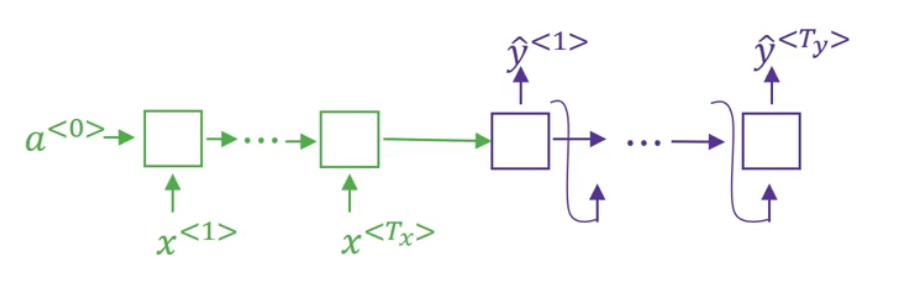
以上便是一个简单的seq2seq模型。再举另外一个seq2seq的例子:image captioning。即输入是一张图像(可以看作是一个序列),输出是对该图像的描述。我们同样使用encoder-decoder的模式来实现,将AlexNet作为encoder(此处去掉输出层),后接一个RNN作为decoder:
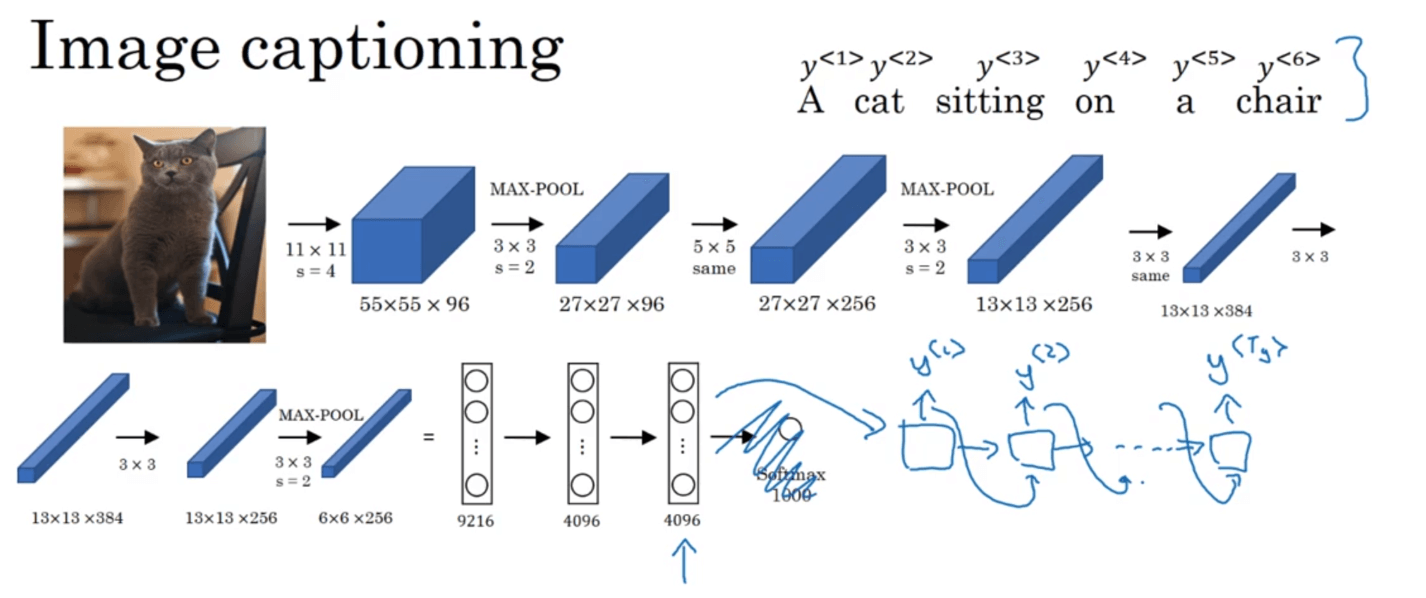
image captioning相关文献:
Mao J, Xu W, Yang Y, et al. Deep captioning with multimodal recurrent neural networks (m-rnn)[J]. arXiv preprint arXiv:1412.6632, 2014.
Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3156-3164.
Karpathy A, Fei-Fei L. Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3128-3137.
2.Beam Search
以第1部分中的机器翻译为例,输入法语句子,会得到很多不同的英语翻译,但是我们并不想要一个随机的翻译结果。我们希望模型最终输出的翻译可以最大化下述概率(即一个最好的最有可能的英语翻译结果):
\[\arg \max \limits_{y^{<1>},...,y^{<T_y>}}P(y^{<1>},...,y^{<T_y>} \mid x)\]Beam Search就是可以帮助我们实现这一目标的最常用的方法之一。Beam Search实现步骤见下:
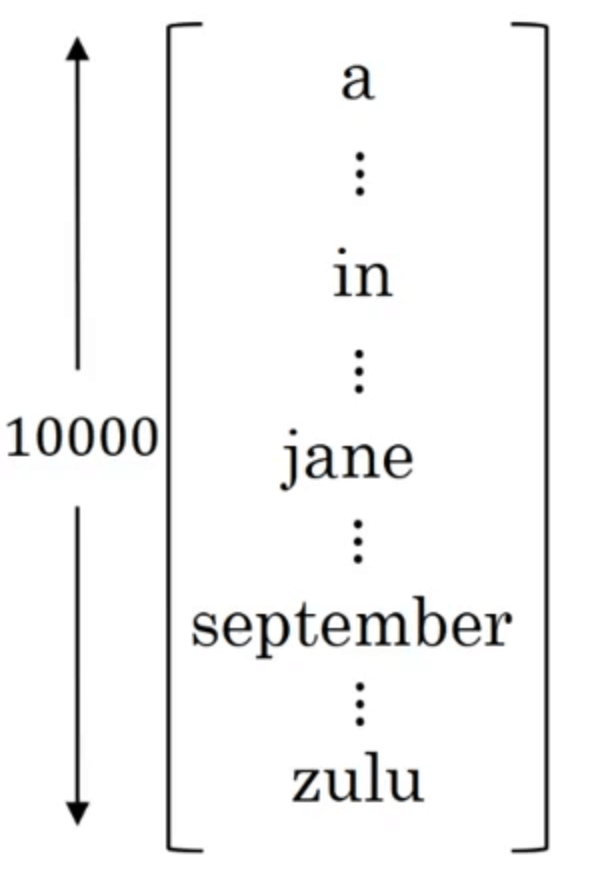
首先,我们先考虑翻译的第一个英语单词,假设我们所用的词汇表中共有10000个单词(本例中,我们忽略大小写,所有单词均使用小写):
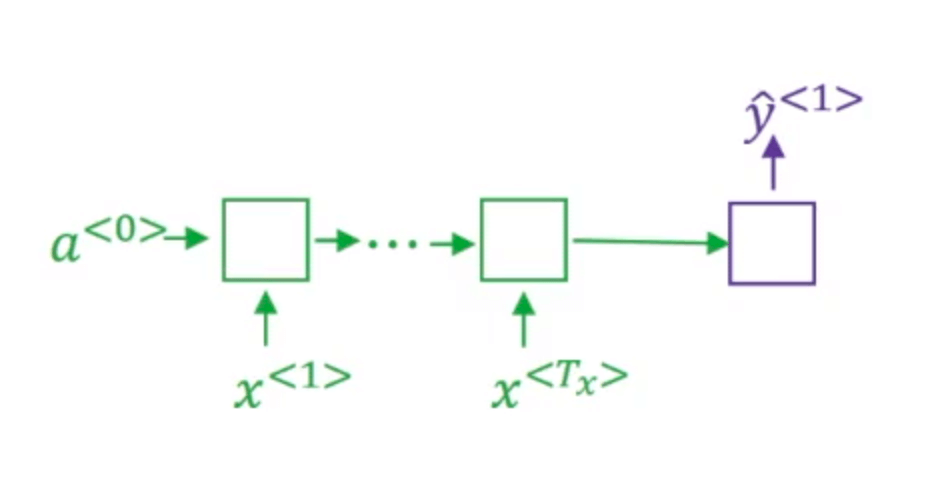
Beam Search的第一步我们使用如下的网络部分(绿色是编码部分,紫色是解码部分)来评估第一个单词的概率(即$P(y^{<1>} \mid x)$,$x$为输入的法语句子):
对于Greedy Search来说,它会选出最可能的那一个单词,然后继续。而Beam Search则会考虑多个选择,我们这里假设Beam Search的参数Beam Width等于3,这就意味着Beam Search一次会考虑3个最可能的结果。假设我们最后找到的最有可能作为英语输出的第一个单词的三个选项为:in,jane,september。Beam Search会将这三个单词存入计算机内存里,以便后续使用。如果我们设置Beam Width=10,那么算法便会跟踪10个最有可能作为第一个单词的选择。所以,Beam Search的第一步就是输入法语句子到编码网络,然后解码这个网络,第一个单词对应的softmax层会输出词汇表中10000个单词的概率值,最后取前三个存起来。
接下来Beam Search的第二步会针对每一个可能的第一个英语单词,考虑第二个单词是什么。为了评估输出英语句子中的第二个单词,我们使用如下神经网络的部分(假设第一个单词我们暂时选择in):
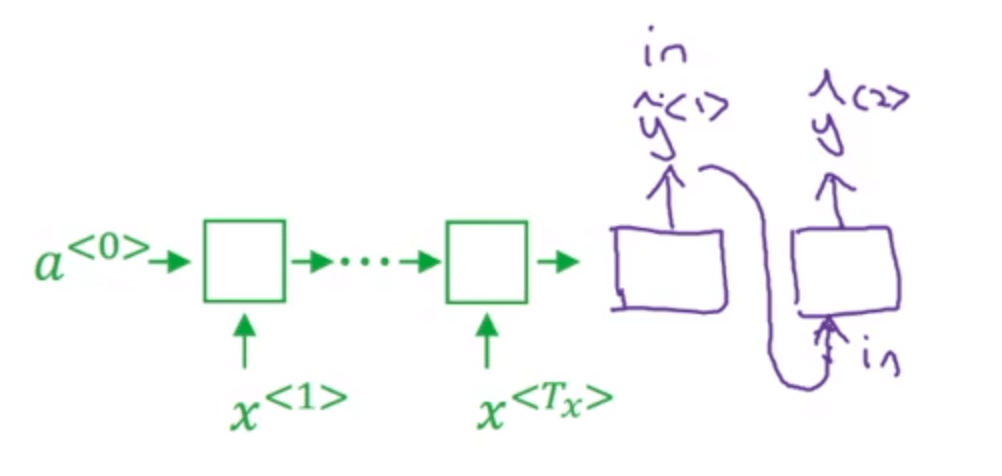
因为Beam Width=3,所以我们会有三个这样的网络副本。
第二个单词的概率(即条件概率)为:
\[P(y^{<1>},y^{<2>} \mid x)=P(y^{<1>} \mid x) P(y^{<2>} \mid x,y^{<1>})\]第二个单词我们共有$3 \times 10000=30000$种不同的选择(针对每一个第一个单词的选择,第二个单词都会有10000种选择)。在这30000个选择中,我们依旧挑取概率$P(y^{<1>},y^{<2>} \mid x)$最高的三个,假设这三个最高概率的单词为:
- 第二个单词=september $\mid$ 第一个单词=in
- 第二个单词=is $\mid$ 第一个单词=jane
- 第二个单词=visits $\mid$ 第一个单词=jane
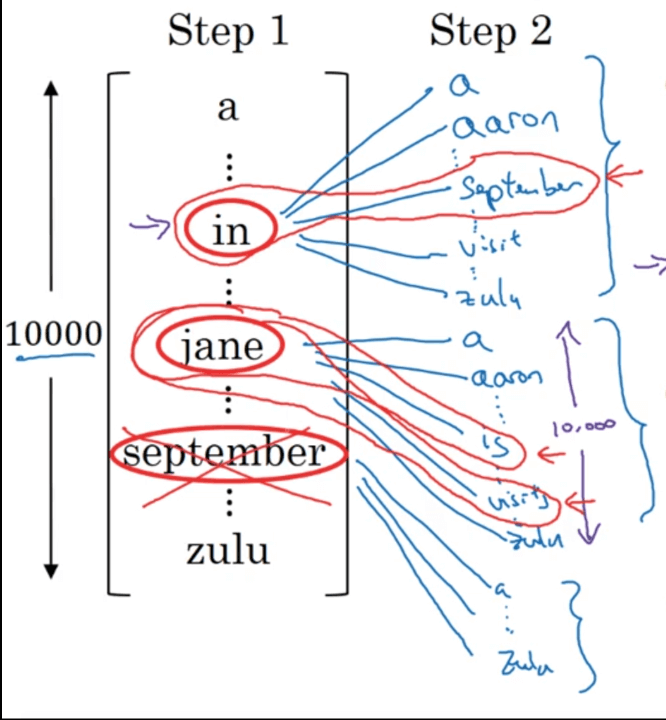
此外,我们不再选择september作为英语翻译结果的第一个单词。
Beam Search的第三步和第二步类似:
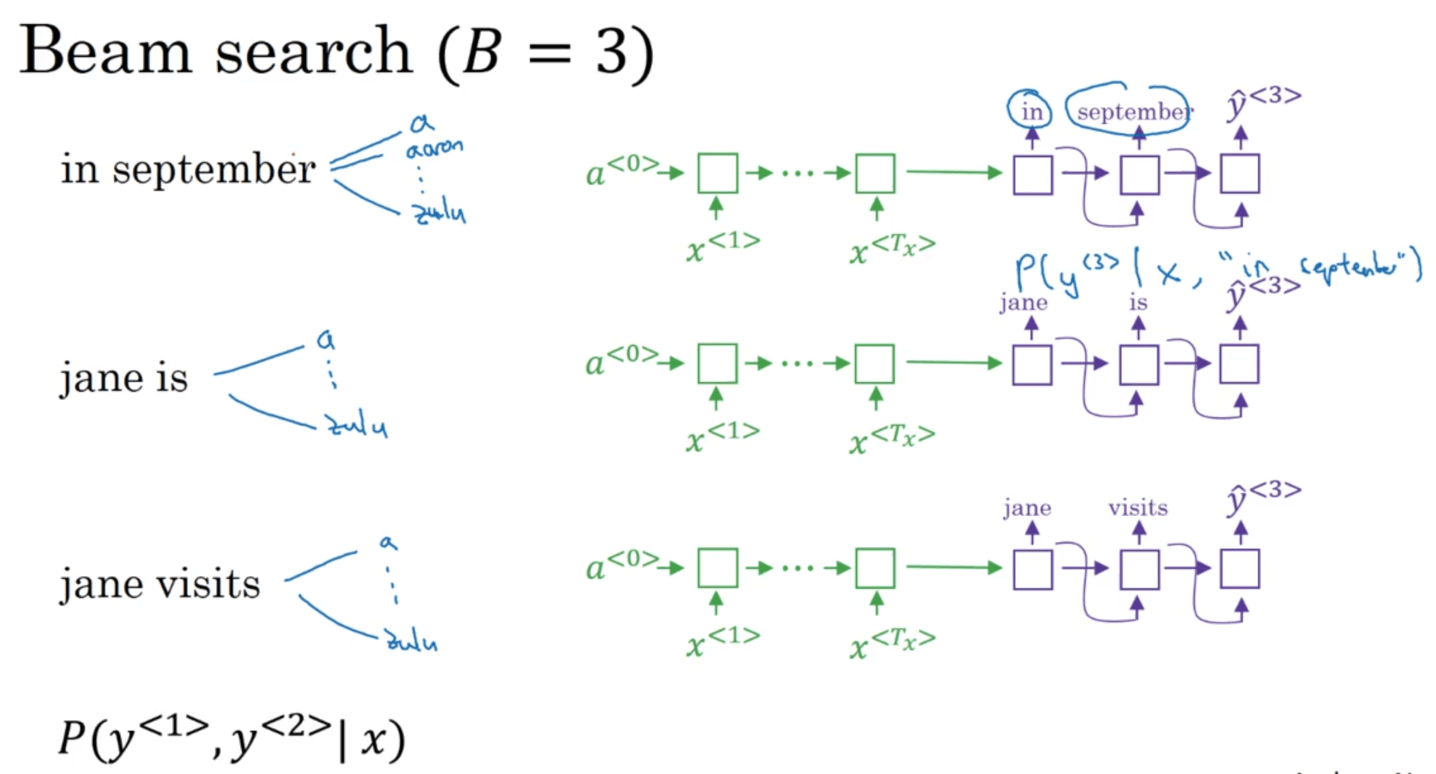
后续步骤与之类似,不再赘述。
当Beam Width=1时,此时为Greedy Search。其缺点为:1)不一定是最佳结果;2)计算量大。
3.Beam Search的改进
3.1.Length Normalization
Beam Search的目标就是最大化下述概率:
\[\arg \max \limits_{y} \prod _{t=1} ^{T_y} P(y^{<t>} \mid x,y^{<1>},...,y^{<t-1>})\]上式中这么多都是小于1的概率值相乘,会得到一个非常非常小的数,很容易造成数值下溢。此外,越长的句子,会有越多的概率值(小于1)相乘,得到的结果也会越小。因此,这个代价函数会偏向于较短的句子。
我们通过取log来解决数值下溢的问题:
\[\arg \max \limits_{y} \sum _{t=1} ^{T_y} \log P(y^{<t>} \mid x,y^{<1>},...,y^{<t-1>})\]但是这个代价函数依旧存在偏向于较短句子的问题。因为句子越长,相加的log值越多,又因为log值都是负值,所以代价函数会越小。因此,将代价函数进一步优化:
\[\frac{1}{T_y^{\alpha}} \sum _{t=1} ^{T_y} \log P(y^{<t>} \mid x,y^{<1>},...,y^{<t-1>})\]其中,$T_y$为句子中的单词个数,通常有$\alpha=0.7$($\alpha$为超参数)。
3.2.Beam Width
Beam Width越大,意味着我们考虑的选择越多,找到的句子可能就会越好,但是算法的计算代价也会越大,算法运行更慢。
4.误差分析
误差分析能够帮助我们集中时间做最有用的工作。Beam Search是一种近似搜索算法,也被称为启发式搜索算法,它不总是输出可能性最大的句子。如果Beam Search出现了问题该怎么办?如何将误差分析应用于Beam Search呢?
依旧以机器翻译为例,假设输入的待翻译的法语句子为:Jane visite l’Afrique en septembre.。人工标准英语翻译$y^*$为:Jane visits Africa in September.。机器翻译的结果$\hat y$为:Jane visited Africa last September.。$\hat y$无疑是一个糟糕的翻译结果,它改变了句子的原意。那么现在我们该如何判断问题是出自RNN网络部分还是Beam Search算法呢?例如如果是RNN网络的问题,我们可以增大数据集;如果是Beam Search的问题,我们可以增大Beam Width。只要知道了问题的来源,我们就可以对症下药。
通过RNN网络我们可以得到两个概率值:$P(y^* \mid x),P(\hat y \mid x)$。如果:
- $P(y^* \mid x) > P(\hat y \mid x)$,说明问题出自Beam Search算法。
- $P(y^* \mid x) \leqslant P(\hat y \mid x)$,说明问题出自RNN网络。
然后我们针对每一个结果都进行上述比较,最后统计问题出自Beam Search算法和问题出自RNN网络的比例,占比更大的那一个就是需要我们集中精力所要解决的。
