【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.注意力模型
依旧以机器翻译为例,假设有如下待翻译的法语句子:

如果使用我们在【深度学习基础】第四十六课:Beam Search中介绍的seq2seq模型:

绿色的encoder部分需要先读入整个句子,然后记忆整个句子,再在感知机中传递,最后由decoder部分生成英文翻译:
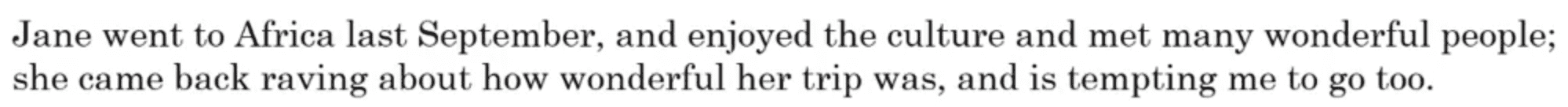
但是对于人工翻译来说,人们并不会通过读整个法语句子,再记忆里面的东西,然后从零开始翻译成一个英语句子,因为记忆一长段文字是一件很困难的事情。人们通常会先翻译句子的一部分,然后再翻译下一部分,直至翻译完整个句子。
上述的seq2seq模型对短句子的效果非常好,但是其对于长句子(比如大于30或者40词的句子)的效果并不好。因此我们引入注意力模型来解决这个问题,其作用机理和人工翻译类似(一次只翻译一部分)。
注意力模型原文:Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
首先,我们通过如下BRNN模型(GRU或LSTM)计算句子中每个单词的特征:

使用$t’$表示法语句子的时间步,第$t’$个时间步前向传播的激活值为$\overrightarrow a^{<t’>}$,后向传播的激活值为$\overleftarrow a^{<t’>}$。有:
\[a^{<t'>}=(\overrightarrow a^{<t'>}, \overleftarrow a^{<t'>} )\]我们将使用另一个单向RNN模型(只进行前向传播)用于生成英语翻译。使用$t$表示英语句子的时间步,用状态$S$表示生成翻译。每个单元的输入为上下文$C^{<t>}$,输出为$y^{<t>}$。以第一个输入$C^{<1>}$为例:
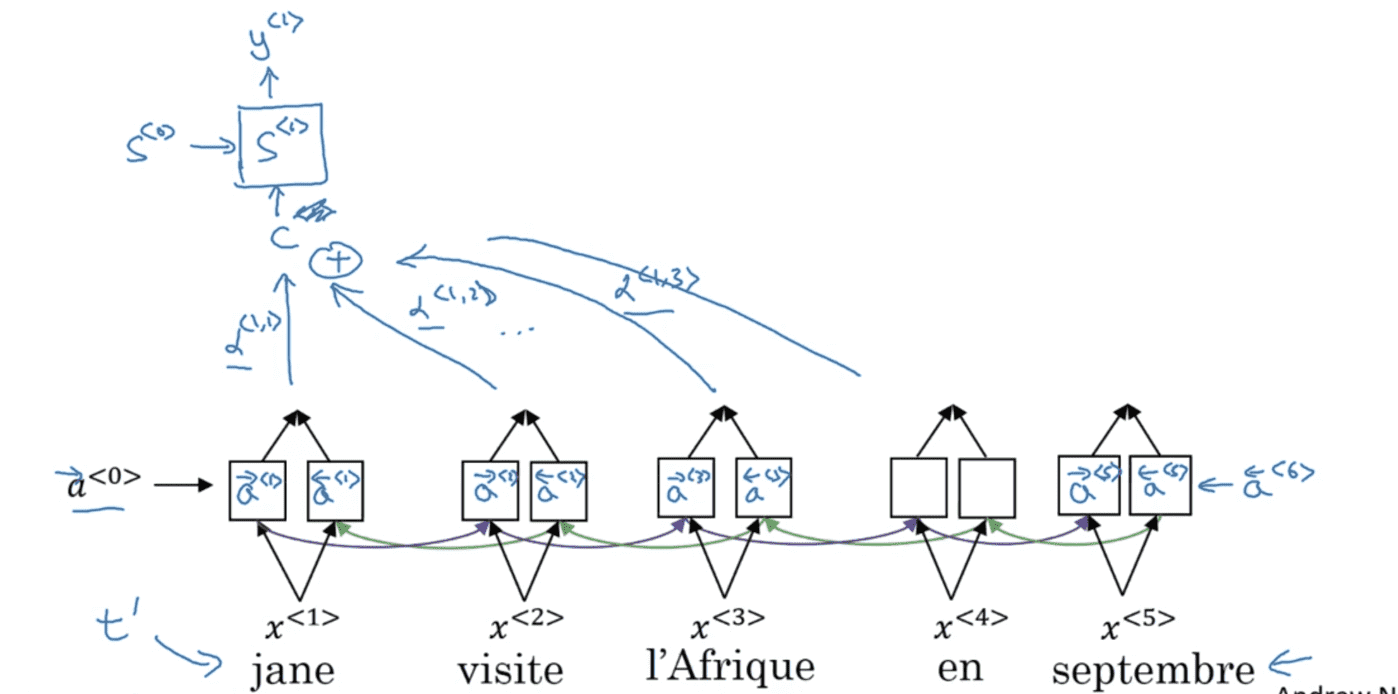
$C^{<1>}$会综合附近上下文多个单词的特征,并且每个特征都会有一个注意力权重$\alpha$。并且有:
\[\sum_{t'} \alpha ^{<1,t'>}=1\] \[C^{<1>}=\sum_{t'} \alpha ^{<1,t'>} a^{<t'>}\]$\alpha ^{<t,t’>}$表示$y^{<t>}$应该花多少注意力在第$t’$个输入词上面。$y^{<2>}$的输出以此类推:
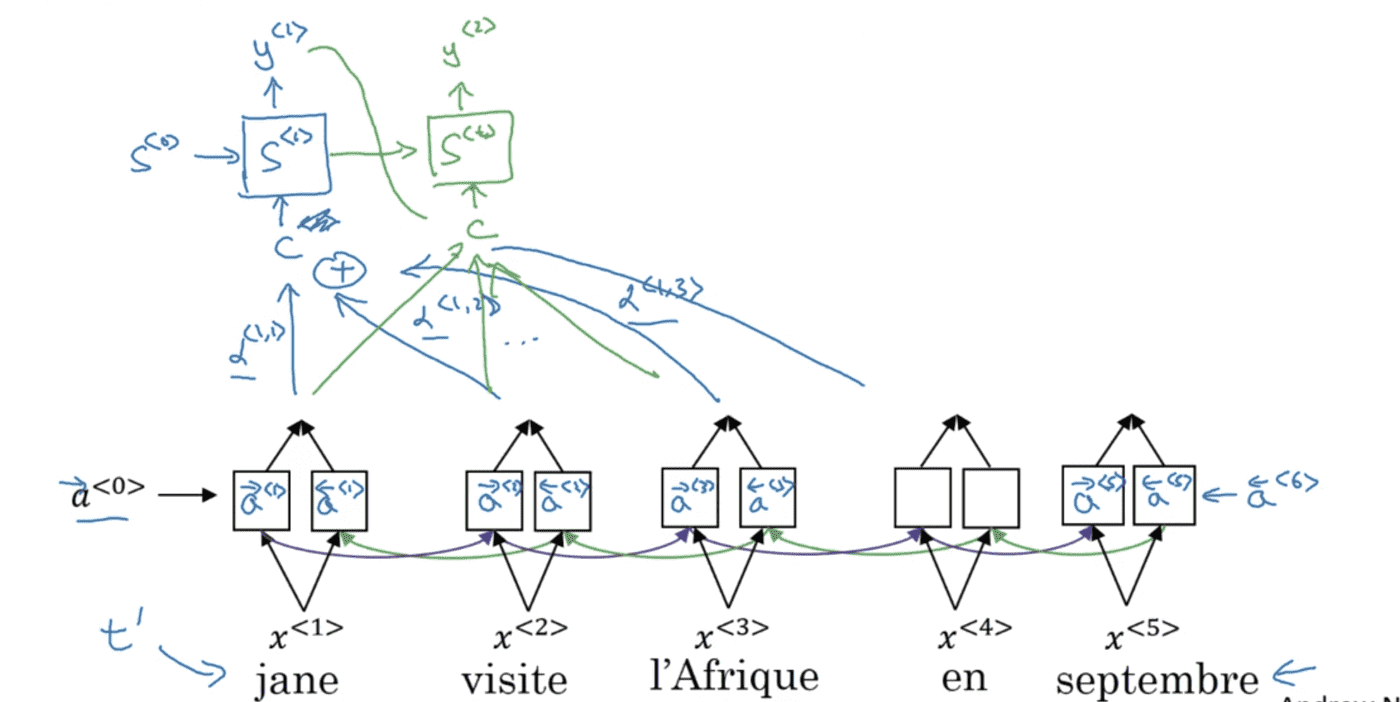
同理:
\[C^{<2>}=\sum_{t'} \alpha ^{<2,t'>} a^{<t'>}\]那么现在还剩一个问题就是:如何计算注意力权重$\alpha$?
\[\alpha ^{<t,t'>}=\frac{exp(e^{<t,t'>})}{\sum _{t'=1}^{T_x} exp(e^{<t,t'>})}\]使用了softmax函数的形式以确保对于每一个固定的$t$值,这些权重加起来等于1。$e$的计算可以使用如下这样小的神经网络:
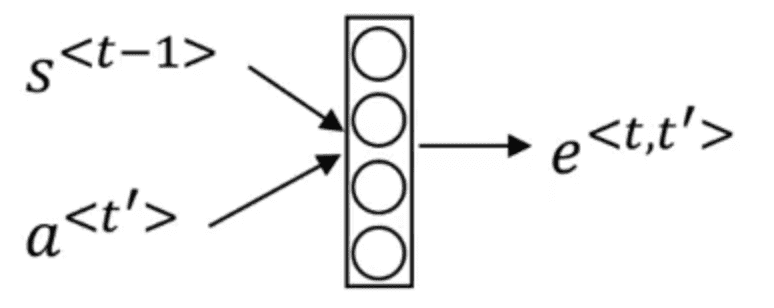
从直观感觉上来说,$\alpha ^{<t,t’>}$的值会受到$S^{<t-1>}$和$a^{<t’>}$的影响,因此我们将其作为这个小网络的输入。而之间的函数关系则交给网络自己通过梯度下降法去学习。
注意力模型的缺点就是时间复杂度过高,为$O(n^3)$。但通常机器翻译的句子都不会太长,所以可以忽略这个问题。
注意力模型除了在机器翻译领域,也被广泛用于其他领域,例如图片加标题(相关论文:Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//International conference on machine learning. PMLR, 2015: 2048-2057.)等。
