【机器学习基础】系列博客为参考周志华老师的《机器学习》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.支持向量回归
现在我们来考虑回归问题,给定训练样本$D=\{(\mathbf x_1,y_1),(\mathbf x_2,y_2),…,(\mathbf x_m,y_m) \},y_i \in \mathbb R$,希望学得一个形如$f(\mathbf x)=\mathbf w^T \mathbf x + b$的回归模型,使得$f(\mathbf x)$与$y$尽可能接近,$\mathbf w$和$b$是待确定的模型参数。
对样本$(\mathbf x,y)$,传统回归模型通常直接基于模型输出$f(\mathbf x)$与真实输出$y$之间的差别来计算损失,当且仅当$f(\mathbf x)$与$y$完全相同时,损失才为零。与此不同,支持向量回归(Support Vector Regression,简称SVR)假设我们能容忍$f(\mathbf x)$与$y$之间最多有$\epsilon$的偏差,即仅当$f(\mathbf x)$与$y$之间的差别绝对值大于$\epsilon$时才计算损失。如下图所示,这相当于以$f(\mathbf x)$为中心,构建了一个宽度为$2 \epsilon$的间隔带,若训练样本落入此间隔带,则认为是被预测正确的:
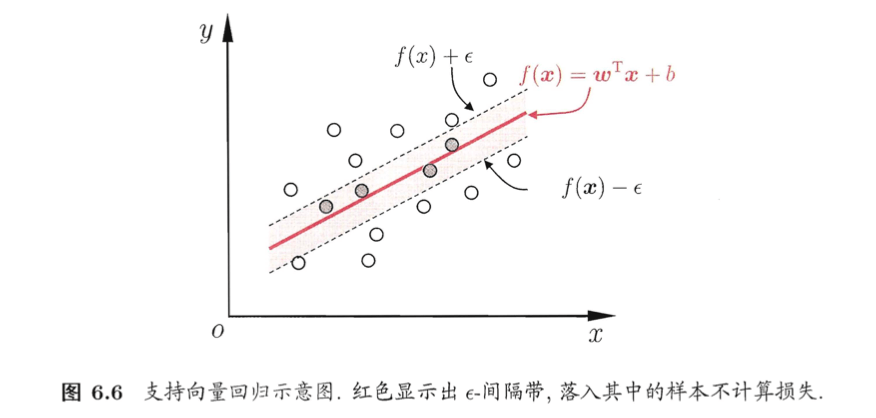
于是,SVR问题可形式化为:
\[\min \limits_{\mathbf w,b} \frac{1}{2} \parallel \mathbf w \parallel ^2 + C \sum^m_{i=1} \ell_{\epsilon} (f(\mathbf x_i)-y_i) \tag{1}\]其中$C$为正则化常数,$\ell_{\epsilon}$是下图所示的$\epsilon$-不敏感损失($\epsilon$-insensitive loss)函数:
\[\ell_{\epsilon} (z) = \left \{ \begin{array}{l} 0, \quad if \ \mid z\mid \leqslant \epsilon; \\ \mid z \mid - \epsilon, \quad otherwise \end{array} \right. \tag{2}\]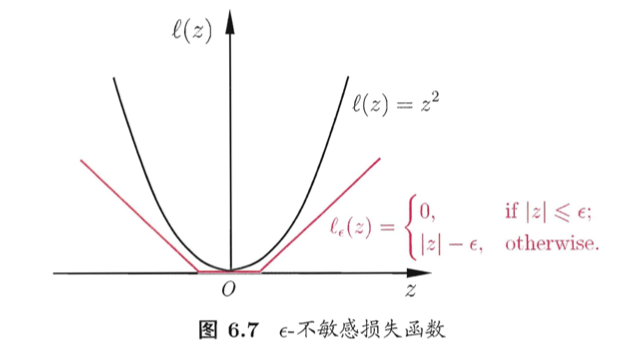
引入松弛变量$\xi _i$和$\hat \xi _i$,可将式(1)重写为:
\[\begin{align*} &\min \limits_{\mathbf w,b,\xi _i,\hat \xi _i} \frac{1}{2} \parallel \mathbf w \parallel ^2 + C \sum^m_{i=1} (\xi _i+\hat \xi _i) \\ & \begin{array}{l@{\quad}l@{}l@{\quad}l} s.t.& f(\mathbf x_i)-y_i \leqslant \epsilon+\xi_i, \\& y_i-f(\mathbf x_i) \leqslant \epsilon+\hat \xi_i, \\& \xi_i \geqslant 0 , \hat \xi_i \geqslant 0 , i=1,2,...,m. \\ \end{array} \end{align*} \tag{3}\]间隔带两侧的松弛程度可有所不同。
通过引入拉格朗日乘子$\mu_i \geqslant 0, \hat \mu_i \geqslant 0,\alpha_i \geqslant 0 , \hat \alpha_i \geqslant 0$,由拉格朗日乘子法可得到式(3)的拉格朗日函数:
\[L(\mathbf w,b,\mathbf \alpha, \hat{\mathbf \alpha},\mathbf \xi, \hat{\mathbf \xi},\mathbf \mu , \hat{\mathbf \mu})=\frac{1}{2} \parallel \mathbf w \parallel ^2 + C \sum^m_{i=1}(\xi_i+\hat \xi_i)-\sum^m_{i=1} \mu_i \xi_i - \sum^m_{i=1} \hat \mu_i \hat \xi_i+ \sum^m_{i=1} \alpha_i (f(\mathbf x_i)-y_i-\epsilon - \xi_i)+\sum^m_{i=1}\hat \alpha_i (y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i) \tag{4}\]将$f(\mathbf x)=\mathbf w^T \mathbf x + b$代入,再令$L(\mathbf w,b,\mathbf \alpha, \hat{\mathbf \alpha},\mathbf \xi, \hat{\mathbf \xi},\mathbf \mu , \hat{\mathbf \mu})$对$\mathbf w,b,\xi_i,\hat \xi_i$的偏导为零可得:
\[\mathbf w=\sum^m_{i=1} (\hat \alpha_i - \alpha_i) \mathbf x_i \tag{5}\] \[0=\sum^m_{i=1} (\hat \alpha_i - \alpha_i) \tag{6}\] \[C=\alpha_i+\mu_i \tag{7}\] \[C=\hat \alpha_i + \hat \mu_i \tag{8}\]将式(5)-(8)代入式(4),即可得到SVR的对偶问题:
\[\begin{align*} &\max \limits_{\mathbf \alpha,\hat{\alpha}} \sum^m_{i=1} y_i (\hat{\alpha_i} - \alpha_i) - \epsilon (\hat{\alpha_i} + \alpha_i) -\frac{1}{2} \sum^m_{i=1} \sum^m_{j=1} (\hat{\alpha_i} - \alpha_i)(\hat{\alpha_j} - \alpha_j) \mathbf x^T_i \mathbf x_j \\ & \begin{array}{l@{\quad}l@{}l@{\quad}l} s.t.& \sum^m_{i=1} (\hat{\alpha_i} - \alpha_i)=0, \\& 0\leqslant \alpha_i, \hat{\alpha_i} \leqslant C . \\ \end{array} \end{align*} \tag{9}\]上述过程中需满足KKT条件,即要求:
\[\left\{ \begin{array}{c} \alpha_i (f(\mathbf x_i)-y_i-\epsilon - \xi_i)=0, \\ \hat \alpha_i (y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i)=0, \\ \alpha_i \hat \alpha_i=0, \xi_i \hat \xi_i=0, \\ (C-\alpha_i)\xi_i = 0 , (C-\hat \alpha_i)\hat \xi_i = 0 .\end{array} \right. \tag{10}\]将式(5)代入$f(\mathbf x)=\mathbf w^T \mathbf x + b$,则SVR的解形如:
\[f(\mathbf x)=\sum^m_{i=1}(\hat \alpha_i - \alpha_i) \mathbf x^T_i \mathbf x + b \tag{11}\]能使式(11)中的$(\hat \alpha_i - \alpha_i) \neq 0$的样本即为SVR的支持向量,它们必落在$\epsilon$-间隔带之外。显然,SVR的支持向量仅是训练样本的一部分,即其解仍具有稀疏性。
落在$\epsilon$-间隔带中的样本都满足$\alpha_i=0$且$\hat \alpha_i=0$。
原因:因为样本是落在$\epsilon$-间隔带内,所以有$f(\mathbf x_i) -y_i < \epsilon$且$y_i-f(\mathbf x_i) < \epsilon$,又因为$\xi_i \geqslant 0 , \hat \xi_i \geqslant 0$。因此$f(\mathbf x_i)-y_i-\epsilon - \xi_i<0$且$y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i<0$,根据式(10),此时必须有$\alpha_i=0$且$\hat \alpha_i=0$。
由KKT条件(10)可看出,对每个样本$(\mathbf x_i,y_i)$都有$(C-\alpha_i) \xi_i=0$且$\alpha_i (f(\mathbf x_i)-y_i-\epsilon - \xi_i)=0$。于是,在得到$\alpha_i$后,若$0<\alpha_i<C$,则必有$\xi_i=0$,进而有:
\[b=y_i + \epsilon - \sum^m_{i=1}(\hat \alpha_i - \alpha_i) \mathbf x^T_i \mathbf x \tag{12}\]因此,在求解式(9)得到$\alpha_i$后,理论上来说,可任意选取满足$0<\alpha_i<C$的样本通过式(12)求得$b$。实践中常采用一种更鲁棒的办法:选取多个(或所有)满足条件$0<\alpha_i<C$的样本求解$b$后取平均值。
若考虑特征映射形式$f(\mathbf x)=\mathbf w ^T \phi (\mathbf x)+b$,则相应的,式(5)将形如:
\[\mathbf w=\sum^m_{i=1} (\hat \alpha_i - \alpha_i) \phi (\mathbf x_i) \tag{13}\]将式(13)代入$f(\mathbf x)=\mathbf w ^T \phi (\mathbf x)+b$,则SVR可表示为:
\[f(\mathbf x)=\sum^m_{i=1}(\hat \alpha_i - \alpha_i) \kappa (\mathbf x,\mathbf x_i)+b \tag{14}\]其中$\kappa (\mathbf x_i,\mathbf x_j)=\phi (\mathbf x_i)^T \phi (\mathbf x_j)$为核函数。
2.式(10)的推导
将式(3)的约束条件全部恒等变形为小于等于0的形式可得:
\[\left\{ \begin{array}{c} f(\mathbf x_i)-y_i-\epsilon - \xi_i \leqslant 0 \\ y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i \leqslant 0 \\ -\xi_i \leqslant 0 \\ -\hat \xi_i \leqslant 0 \end{array} \right.\]由于以上四个约束条件的拉格朗日乘子分别为$\alpha _i , \hat \alpha_i , \mu_i , \hat \mu_i$,可相应转化为以下KKT条件:
\[\left\{ \begin{array}{c} \alpha_i (f(\mathbf x_i)-y_i-\epsilon - \xi_i) = 0 \\ \hat \alpha_i (y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i) = 0 \\ -\mu_i \xi_i = 0 \Rightarrow \mu_i \xi_i = 0 \\ -\hat \mu_i \hat \xi_i = 0 \Rightarrow \hat \mu_i \hat \xi_i = 0 \end{array} \right.\]由式(7)、式(8)可知:
\[\mu_i = C-\alpha_i\] \[\hat \mu_i = C - \hat \alpha_i\]所以上述KKT条件可以进一步变形为:
\[\left\{ \begin{array}{c} \alpha_i (f(\mathbf x_i)-y_i-\epsilon - \xi_i) = 0 \\ \hat \alpha_i (y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i) = 0 \\ (C-\alpha_i) \xi_i = 0 \\ (C - \hat \alpha_i) \hat \xi_i = 0 \end{array} \right.\]又因为样本$(\mathbf x_i,y_i)$只可能处在间隔带的某一侧,那么约束条件$f(\mathbf x_i)-y_i-\epsilon - \xi_i=0$和$y_i-f(\mathbf x_i)-\epsilon-\hat \xi_i=0$不可能同时成立,所以$\alpha_i$和$\hat \alpha_i$中至少有一个为0,也即$\alpha_i \hat \alpha_i=0$。在此基础上再进一步分析可知,如果$\alpha_i=0$的话,那么根据约束$(C-\alpha_i) \xi_i = 0$可知此时$\xi_i=0$;同理,如果$\hat \alpha_i=0$的话,那么根据约束$(C - \hat \alpha_i) \hat \xi_i = 0$可知此时$\hat \xi_i=0$。所以$\xi_i$和$\hat \xi_i$中也是至少有一个为0,也即$\xi_i \hat \xi_i=0$。将$\alpha_i \hat \alpha_i=0,\xi_i \hat \xi_i=0$整合进上述KKT条件中即可得到式(10)。
