本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.读取用户购买记录
1
2
3
4
| import pandas as pd
m_cols = ["Time", "Action", "User", "Product", "Quantity", "Price"]
orders = pd.read_csv("purchase_order.tab", sep='\t', parse_dates={'Dates': [0]}, names=m_cols, encoding='utf-8')
|
.tab文件其实就是用制表符分隔的文本文件,许多电子表格程序都可以导入该类型的文件。sep='\t'表示分隔标识为制表符。
parse_dates={'Dates': [0]}表示将第一列的时间字符串转换成datetime格式,并将该列命名为“Dates”。
names可以为每一列命名。
1
2
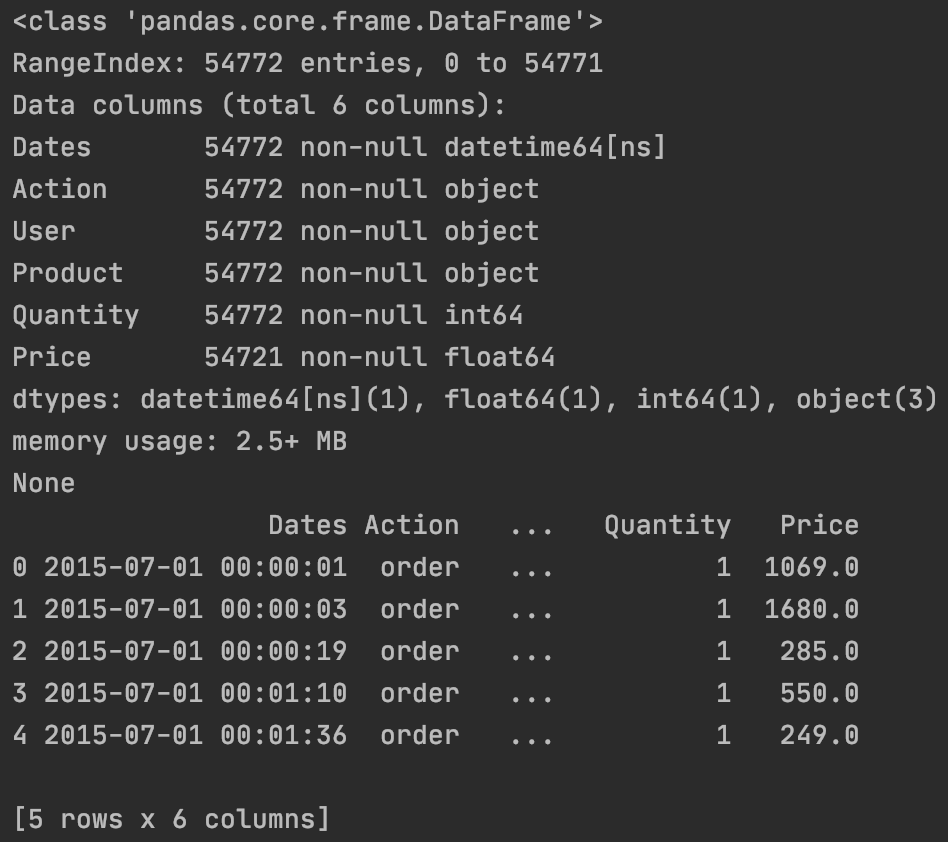
| print(orders.info())
print(orders.head())
|
2.探索用户购买记录
1
2
3
4
5
6
7
8
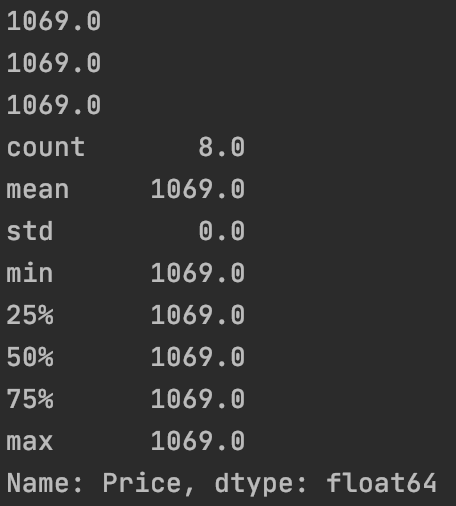
| #获取产品P0006944501的平均价钱
orders[orders["Product"] == "P0006944501"]["Price"].mean()
#获取产品P0006944501的最高价钱
orders[orders["Product"] == "P0006944501"]["Price"].max()
#获取产品P0006944501的最低价钱
orders[orders["Product"] == "P0006944501"]["Price"].min()
#获取产品P0006944501价钱的叙述性统计
orders[orders["Product"] == "P0006944501"]["Price"].describe()
|
1
2
3
| #统计产品类型(去除重复)
orders["Product"].unique()
len(orders["Product"].unique())
|

👉unique的用法:
1
2
| obj=pd.Series(['c','a','d','a','a','b','b','c','c','c'])
obj.unique()#输出:array(['c', 'a', 'd', 'b'], dtype=object)
|
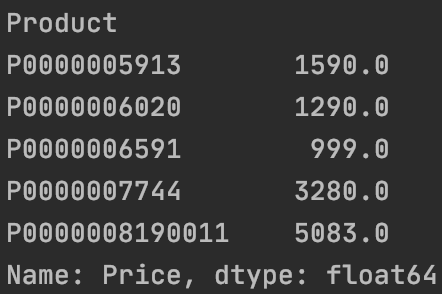
利用分层平均数(groupby)求不同产品的平均价格:
1
| orders.groupby("Product")["Price"].mean().head()
|
1
2
| #在上述基础上,对价格进行降序排列
orders.groupby("Product")["Price"].mean().sort_values(ascending=False).head()
|

1
2
| orders["Total_Price"] = orders["Quantity"] * orders["Price"]
print(orders.head())
|

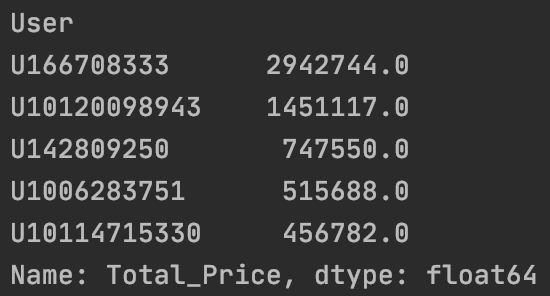
1
| orders.groupby('User')['Total_Price'].sum().sort_values(ascending=False).head()
|
3.读取用户浏览商品记录
1
2
3
4
| #读取用户浏览商品记录
m_cols = ['Time', 'Action', 'User', 'Product']
views = pd.read_csv("purchase_view.tab", sep='\t', parse_dates={"Dates": [0]}, names=m_cols, encoding='utf-8')
print(views.info())
|

1
| orders.groupby(['User', 'Product'])['Product'].count().head()
|
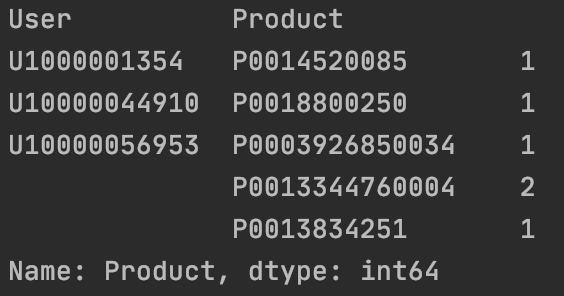
1
2
| orders_cnt = orders.groupby(['User', 'Product'])['Product'].count().reset_index(name='buys')
print(orders_cnt.head())
|
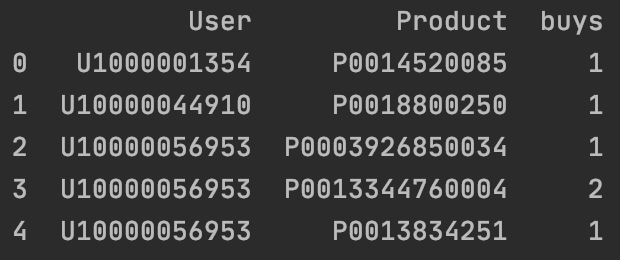
得到的orders_cnt是DataFrame格式。
👉reset_index用于重置索引:
1
2
3
4
| import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(20).reshape(5,4),index=[1,3,5,7,9])
print(df)
|
1
2
3
4
5
6
| 0 1 2 3
1 0 1 2 3
3 4 5 6 7
5 8 9 10 11
7 12 13 14 15
9 16 17 18 19
|
1
| print(df.reset_index())
|
1
2
3
4
5
6
| index 0 1 2 3
0 1 0 1 2 3
1 3 4 5 6 7
2 5 8 9 10 11
3 7 12 13 14 15
4 9 16 17 18 19
|
也可以不保留index列:
1
| print(df.reset_index(drop=True))
|
1
2
3
4
5
6
| 0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
|
一些其它情况:
1
2
3
4
5
6
| index 0
0 1 0
1 3 4
2 5 8
3 7 12
4 9 16
|
1
| df[0].reset_index(name='A')
|
1
2
3
4
5
6
| index A
0 1 0
1 3 4
2 5 8
3 7 12
4 9 16
|
1
2
| views_cnt = views.groupby(['User', 'Product'])['Product'].count().reset_index(name='views')
print(views_cnt.head())
|
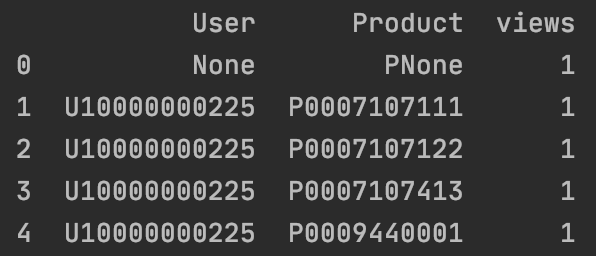
4.合并购买与浏览记录
1
2
3
| #合并购买与浏览记录
merge_df = pd.merge(orders_cnt, views_cnt, on=['User', 'Product'], how='right')
print(merge_df.head())
|
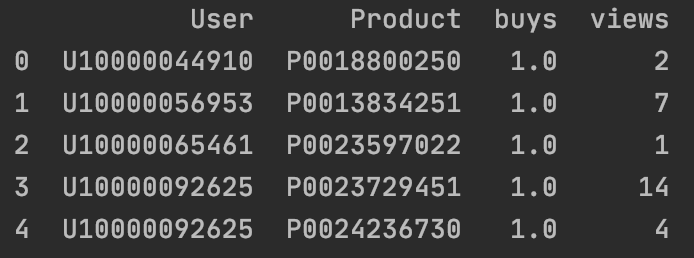
4.1.pandas.merge()
1
2
3
4
| def merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
|
部分参数详解:
left:参与合并的左侧DataFrame。right:参与合并的右侧DataFrame。how:“inner”、“outer”、“left”、“right”其中之一。默认为“inner”。on:用于连接的列名。必须存在于左右两个DataFrame对象中。如果未指定,且其他连接键也未指定,则以left和right列名的交集作为连接键。left_on:左侧DataFrame中用作连接键的列。right_on:右侧DataFrame中用作连接键的列。left_index:将左侧的行索引用作其连接键。right_index:将右侧的行索引用作其连接键。sort:根据连接键对合并后的数据进行排序,默认为True。有时在处理大数据集时,禁用该选项可获得更好的性能。suffixes:字符串值元组,用于追加到重叠列名的末尾,默认为('_x','_y')。例如,如果左右两个DataFrame对象都有“data”,则结果中就会出现“data_x”和“data_y”。copy:设置为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是复制。
下面举例说明一下,先构建两个DataFrame:
1
| df1=pd.DataFrame({'key':list('bbaca'),'data1':range(5)})
|
1
2
3
4
5
6
| key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
|
1
| df2=pd.DataFrame({'key':['a','b','c'],'data2':range(3)})
|
1
2
3
4
| key data2
0 a 0
1 b 1
2 c 2
|
👉on:
1
2
3
| pd.merge(df1,df2)
#等价于
pd.merge(df1,df2,on='key')
|
1
2
3
4
5
6
| key data1 data2
0 b 0 1
1 b 1 1
2 a 2 0
3 a 4 0
4 c 3 2
|
👉left_on和right_on:
针对两边合并字段不同时。
1
2
3
| df3=pd.DataFrame({'key1':list('bbaca'),'data1':range(5)})
df4=pd.DataFrame({'key2':['a','b','c'],'data2':range(3)})
pd.merge(df3,df4,left_on='key1',right_on='key2')
|
1
2
3
4
5
6
| key1 data1 key2 data2
0 b 0 b 1
1 b 1 b 1
2 a 2 a 0
3 a 4 a 0
4 c 3 c 2
|
👉how:
默认为“inner”,即取交集。“outer”为取并集,并且会用NaN填充。
1
2
| df5=pd.DataFrame({'key':list('bbacad'),'data1':range(6)})
pd.merge(df5,df2,how='outer')
|
1
2
3
4
5
6
7
| key data1 data2
0 b 0 1.0
1 b 1 1.0
2 a 2 0.0
3 a 4 0.0
4 c 3 2.0
5 d 5 NaN
|
“left”是左侧DataFrame取全部数据,右侧DataFrame匹配左侧DataFrame(右连接right和左连接类似)。
1
| pd.merge(df5,df2,how='right')
|
1
2
3
4
5
6
| key data1 data2
0 b 0 1
1 b 1 1
2 a 2 0
3 a 4 0
4 c 3 2
|
1
| pd.merge(df5,df2,how='left')
|
1
2
3
4
5
6
7
| key data1 data2
0 b 0 1.0
1 b 1 1.0
2 a 2 0.0
3 c 3 2.0
4 a 4 0.0
5 d 5 NaN
|
👉left_index和right_index:
可以通过设置left_index或者right_index的值为True来使用索引连接。
1
2
| #这里df1使用data1当连接关键字,而df2使用索引当连接关键字
pd.merge(df1,df2,left_on='data1',right_index=True)
|
1
2
3
4
| key_x data1 key_y data2
0 b 0 a 0
1 b 1 b 1
2 a 2 c 2
|
👉suffixes:
从上面可以发现两个DataFrame中都有key列,merge合并之后,pandas会自动在后面加上(_x,_y)来区分,我们也可以通过设置suffixes来设置名字。
1
| pd.merge(df1,df2,left_on='data1',right_index=True,suffixes=('_df1','_df2'))
|
1
2
3
4
| key_df1 data1 key_df2 data2
0 b 0 a 0
1 b 1 b 1
2 a 2 c 2
|
4.2.了解使用者在不同日期与时间的消费习惯
1
| views["Dates"].dt.date.head()
|
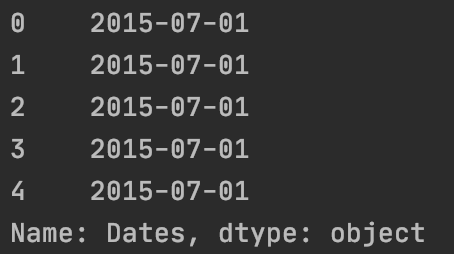
pandas.Series.dt.date官方用法说明:链接。
1
2
3
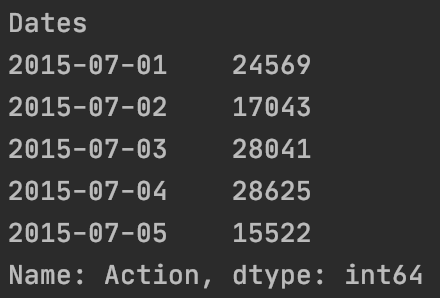
| #统计用户在不同日期的访问次数
views_cnt_by_date = views.groupby(views["Dates"].dt.date)['Action'].count()
print(views_cnt_by_date.head())
|
5.绘制图表
相关讲解:【Python基础】第二十课:使用pandas绘制统计图表。
1
| views_cnt_by_date.plot(kind="line", figsize=[10, 5])
|

1
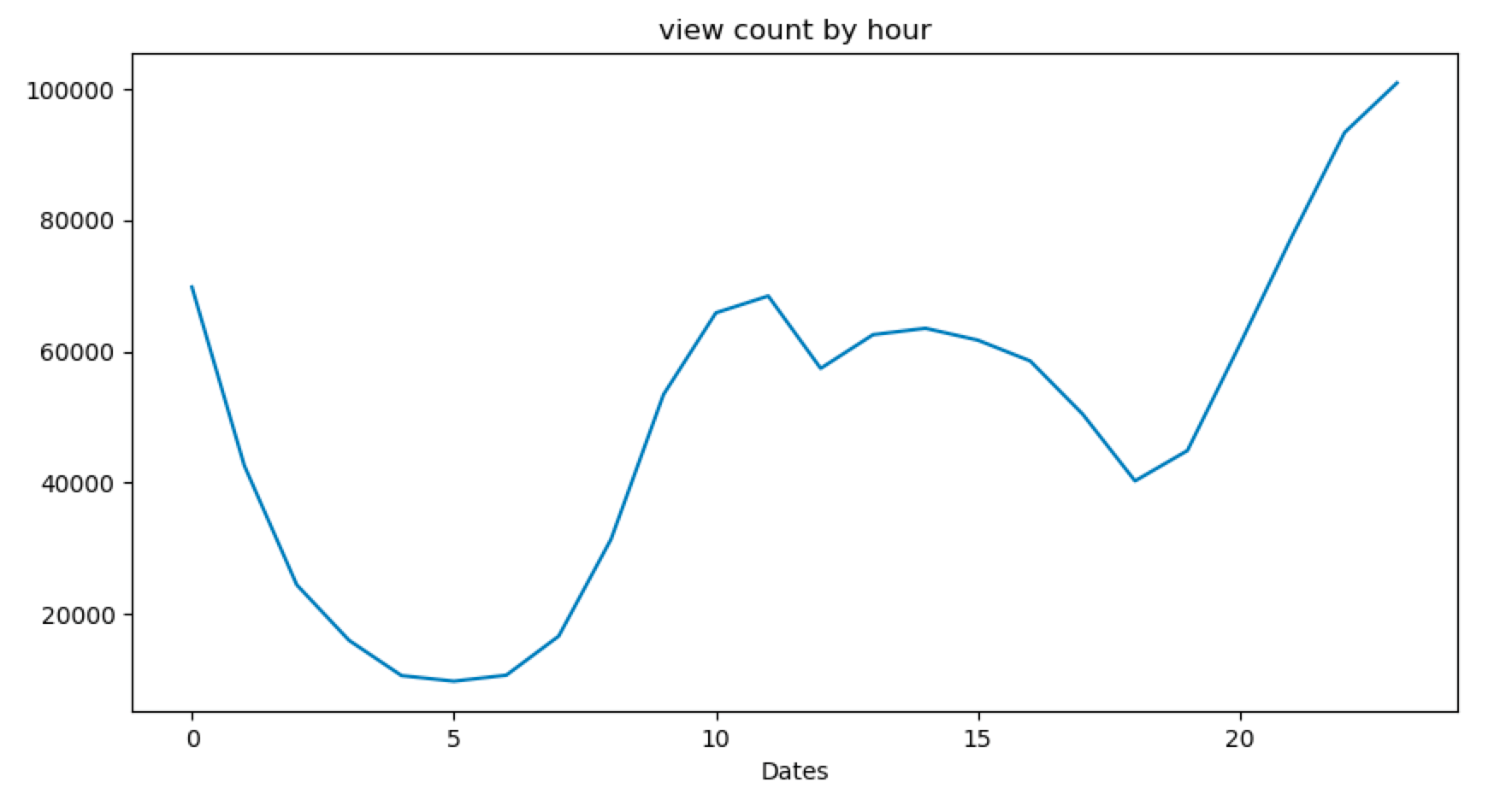
2
| views_cnt_by_hour = views.groupby(views["Dates"].dt.hour)['Action'].count()
views_cnt_by_hour.plot(kind="line", title="view count by hour", figsize=[10, 5])
|
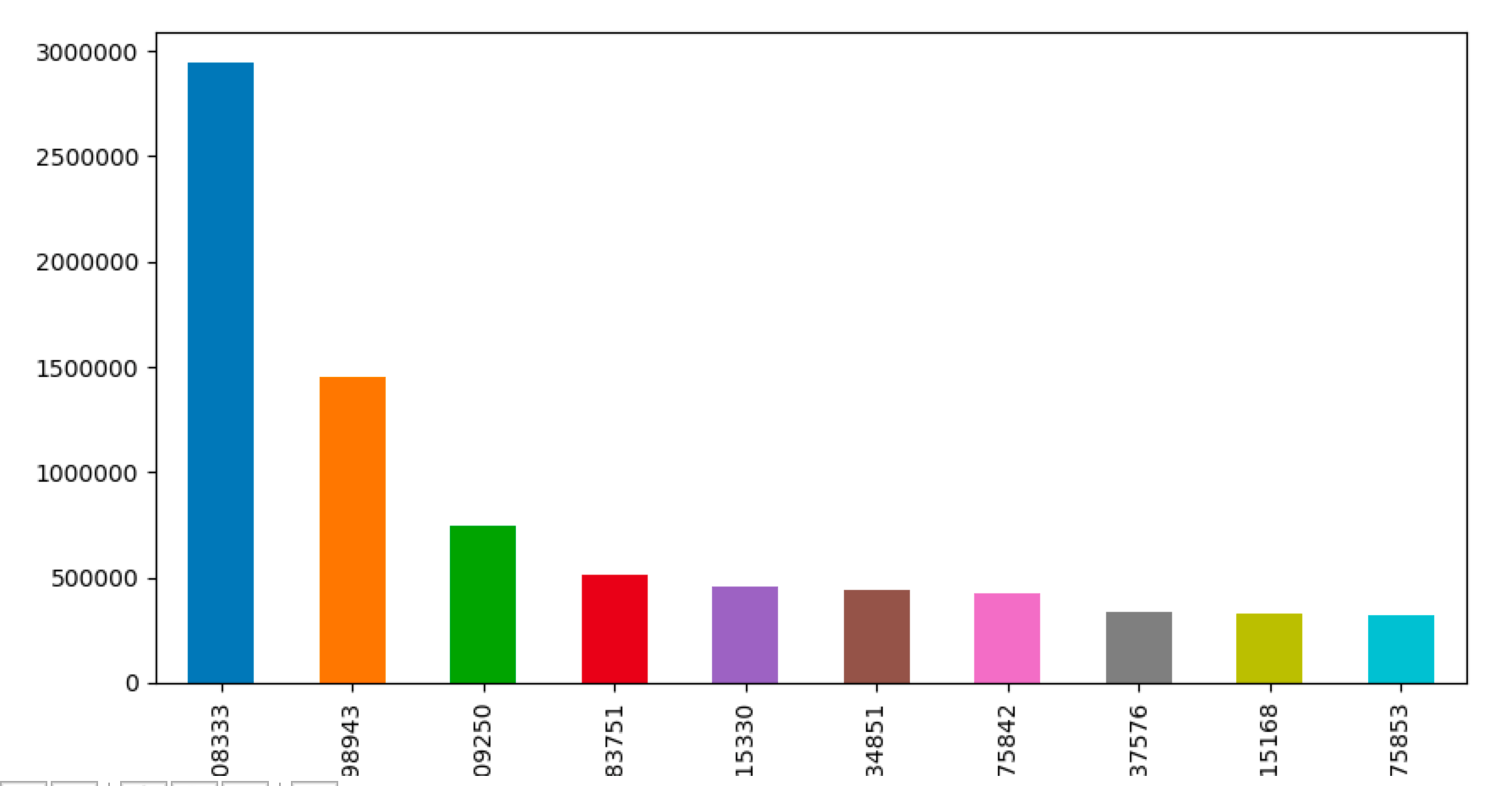
1
2
| g = orders.groupby('User')['Total_Price'].sum().sort_values(ascending=False)[0:10]
g.plot(kind='bar', figsize=[10, 5])
|
1
2
3
4
5
| view_daily_cnt = views.groupby(views["Dates"].dt.date)["Action"].count()
orders_daily_cnt = orders.groupby(orders["Dates"].dt.date)["Action"].count()
df = pd.concat([view_daily_cnt, orders_daily_cnt], axis=1)
df.dropna(inplace=True)
df.plot(kind="line", figsize=[10, 5], rot=30)
|
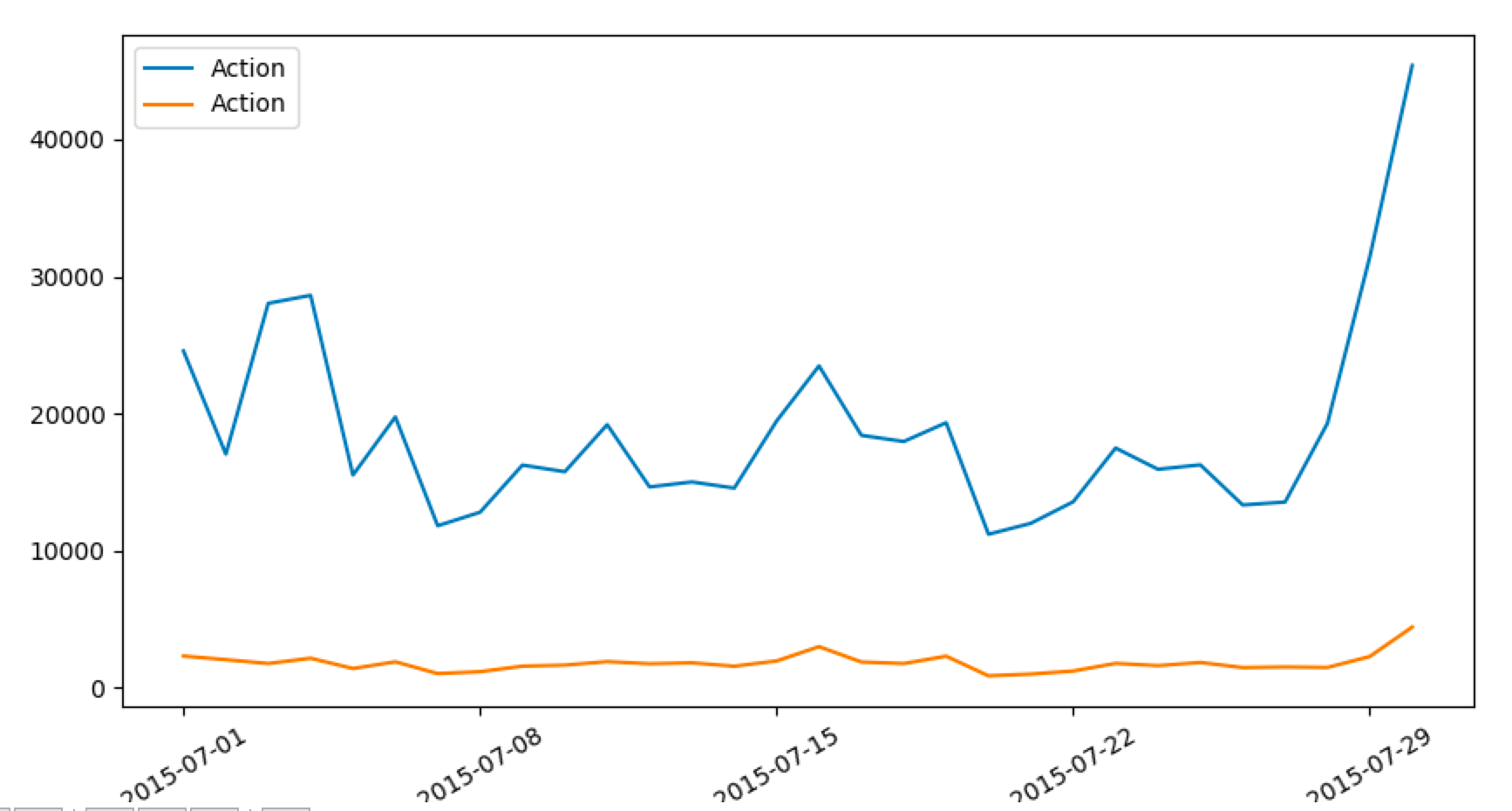
pandas.concat官方用法说明:链接。
dropna用法:链接。
plot中的参数rot指的是x轴标签(轴刻度)的显示旋转度数。
6.代码地址
- 网页浏览记录资料分析
7.参考资料
- pandas中的reset_index()
- [Python3]pandas.merge用法详解
