本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
最近,深度卷积网络显著提升了图像分类和目标检测任务的准确度。相比图像分类任务,目标检测任务更具挑战性且解决办法更为复杂。因此,目前multi-stage的方法速度都很慢并且模型不简洁。
方法复杂是因为要求精准定位目标,这里存在两个主要的挑战。一,有大量的备选区域(proposals)需要处理。二,这些proposals只是一个粗略的定位,想得到精准的定位还需进一步refine。很难同时顾全速度、准确度、模型简洁程度。
我们提出一种single-stage的训练算法来解决上述问题。
这里的stage指的是训练过程。
我们的方法可以训练极深的检测网络,比R-CNN快9倍,比SPPnet快3倍。推理一张图像仅需要0.3s(基于Nvidia K40 GPU/875MHz,不包括产生object proposal的时间),并且在PASCAL VOC 2012得到了很高的准确率mAP=66%,击败了R-CNN的62%。
1.1.RCNN and SPPnet
虽然R-CNN在目标检测任务中取得了不错的准确率,但其仍有一些明显的缺点:
- multi-stage的训练流程。R-CNN的训练一共分为三个stage:1)fine-tune卷积网络部分;2)SVM分类器的训练;3)bounding-box回归。
- 训练成本高(占据大量空间和时间)。对于SVM和BB回归的训练,需要通过卷积网络计算每幅图像中每个object proposal的feature,并写入disk。如果卷积网络部分使用VGG16,则在VOC07训练验证集(5k张图像)上训练需要2.5天(2.5 GPU-days)。这些feature需要数百GB的存储空间。
- 推理速度慢。在推理阶段,需要计算每张测试图像中每个object proposal的feature。在GPU上,如果卷积网络部分使用VGG16,则检测一张图像需要47秒。
R-CNN慢主要是因为对每个object proposal都要跑一遍网络。SPPnet改进了这一问题,相比R-CNN,其将推理耗时降低了10到100倍,训练耗时也降低了3倍。但是SPPnet和R-CNN的训练流程一样,只不过SPPnet只fine-tune了FC层。此外,固定的卷积层层数也限制了模型性能的进一步提升。
1.2.Contributions
我们提出一种新的训练算法以解决R-CNN和SPPnet的缺点,不但可以提升速度,也可以提升精度。我们将这种方法称为Fast R-CNN,可以更快的训练以及推理。Fast R-CNN有以下几点优势:
Fast R-CNN github地址:https://github.com/rbgirshick/fast-rcnn。
2.Fast R-CNN architecture and training
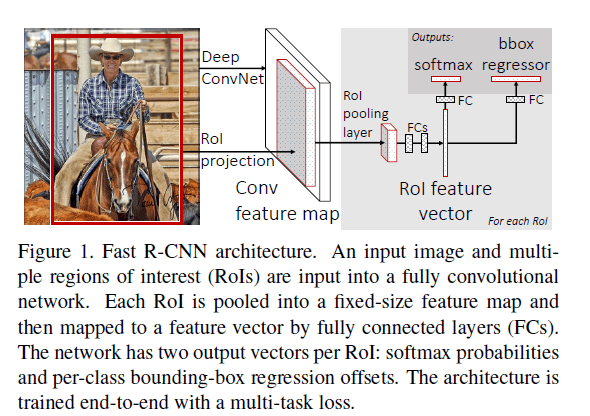
Fast R-CNN的结构见Fig1。输入有两个,一个是全图,另一个是一组object proposal。首先,全图经过卷积网络得到feature map。然后,映射得到object proposal在该feature map上对应的区域,即RoI。然后仅将RoI通过RoI pooling layer得到一个固定长度的特征向量,该特征向量通过几个FC层后流向两个输出分支:一个就是softmax函数,一共有K+1(背景)个类别;另一个分支输出4K个数值,每个类别对应4个数值,这4个数值用于平移和缩放bounding box。
2.1.The RoI pooling layer
RoI pooling layer通过max pooling将RoI统一变为$H \times W$(例如$7\times 7$),H和W为超参数。对于任何RoI来说,H和W是独立的。对于每个RoI,我们定义一组tuple $(r,c,h,w)$,$(r,c)$为左上角,$(h,w)$为高和宽。
其实RoI pooling layer就是spatial pyramid pooling layer的简化版。
2.2.Initializing from pretrained networks
我们实验了3个使用ImageNet预训练过的网络,每个网络都有5个max pooling层+5~13个卷积层(详见第4.1部分)。按照以下三步将预训练好的网络转变成Fast R-CNN。
第一步:将最后一个max pooling layer替换为RoI pooling layer,并设置好H和W(比如对于VGG16,我们设置$H=W=7$)。
第二步:将最后一个FC层和softmax输出层替换为之前提到的两个输出分支结构。
第三步:将网络的输入改为两部分:一组图像和这些图像对应的一组RoI。
2.3.Fine-tuning for detection
在R-CNN训练的fine-tune这一步(SPPnet使用和R-CNN一样的fine-tune策略),mini-batch size=128,这128个经过warp后的region proposal可能来自多张不同的图像,甚至来自128张不同的图像。而Fast R-CNN相当于每次选择N张图像,每个图像再选择R/N个RoI(相当于mini-batch size=R)。例如设置N=2,R=128,这相当于是加速了64倍。这样做虽然大量RoI来自一张图像,但是并没有降低训练收敛速度。
个人理解:Fast R-CNN这样做能加速训练的原因在于有R/N个RoI可以共享前向传播的计算。也就是说提取feature map的卷积网络部分,同一图像的R/N个RoI共用一张feature map即可,只用算一遍。而对于R-CNN来说,每个region proposal在前向传播时都需要计算一遍feature map。
此外,Fast R-CNN可以把R-CNN的3个训练阶段放在一块一起fine-tune。
Multi-task loss.
Fast R-CNN有两个sibling output layers。第一个output是softmax函数,为每个RoI归属于每个类别的概率:$p=(p_0,…,p_K)$。第二个output是bounding-box的offset,针对每个类别都会有个offset:$t^k=(t_x^k,t_y^k,t_w^k,t_h^k)$。$t^k$的定义和R-CNN中保持一致。
每个RoI都有一个GT类别$u$和GT bounding-box $v$。我们定义一个multi-task的loss $L$,结合类别分类和bounding-box回归:
\[L(p,u,t^u,v)=L_{cls}(p,u) + \lambda [u \geqslant 1] L_{loc} (t^u,v) \tag{1}\]第一个task的loss:
\[L_{cls}(p,u)=-\log p_u\]对于第二个task的loss:$L_{loc}$。$v$是GT bounding box offset:$v=(v_x,v_y,v_w,v_h)$,预测的bounding box offset:$t^u=(t^u_x,t^u_y,t^u_w,t^u_h)$。当$u ≥ 1$时,$[ u ≥ 1]=1$,否则$[ u ≥ 1]=0$。因为$u=0$时其类别为背景,此时,$L_{loc}$可以忽略。$L_{loc}$计算见下:
\[L_{loc} (t^u,v)=\sum_{i \in \{x,y,w,h\}} smooth_{L_1}(t^u_i-v_i) \tag{2}\]其中,
\[smooth_{L_1}(x) = \begin{cases} 0.5x^2, & if \ \lvert x \rvert < 1 \\ \lvert x \rvert-0.5, & otherwise \end{cases} \tag{3}\]式(1)引入了超参数$\lambda$来平衡两个loss。我们将$v_i$归一化至均值为0,方差为1。所有的实验都使用$\lambda = 1$。
Mini-batch sampling.
一个batch里有128个RoI,其中32个为正样本(和GT的IoU大于等于0.5),96个为负样本(和GT的IoU满足$[0.1,0.5)$)。在训练过程中,图像有50%的几率被水平翻转。没有使用其他的数据扩展。
Back-propagation through RoI pooling layers.
RoI pooling layers的后向传播计算方式,在此不再赘述。
SGD hyper-parameters.
用于softmax分类的FC层使用均值为0,标准差为0.01的高斯分布来初始化权值;用于bounding-box回归的FC层使用均值为0,标准差为0.001的高斯分布来初始化权值。偏置项均被初始化为0。全局学习率为0.001。在VOC07和VOC12的trainval数据集上训练了30k次的mini-batch迭代,然后将学习率降为0.0001,再训练10k次迭代。如果在更大的数据集上训练,我们会迭代更多次数。momentum=0.9,decay=0.0005。
2.4.Scale invariance
使用和SPPnet一样的single-size training和multi-size training。
3.Fast R-CNN detection
推理过程相当于是一次前向传播的过程。输入为一张图像+R个object proposal。推理阶段,R大约是2000,尽管我们也可能尝试更大的值(比如R=45k)。和SPPnet一样,当我们使用image pyramid时,我们会将图像缩放到某一特定比例使得RoI的大小接近于$224 \times 224$。 和R-CNN一样,对得到的结果进行NMS。
3.1.Truncated SVD for faster detection
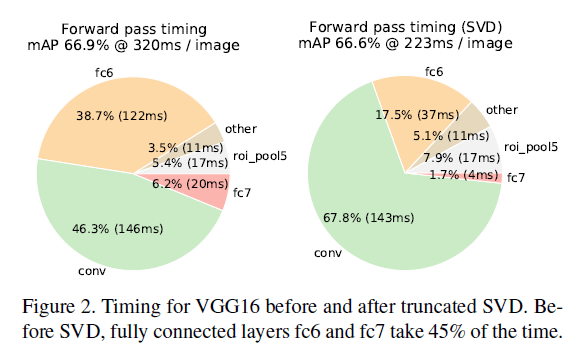
对于图像分类任务来说,FC层的计算量远小于卷积层。但是对于检测任务来说,计算大量的RoI使得FC层的计算占据了推理时间的一半左右,见Fig2。
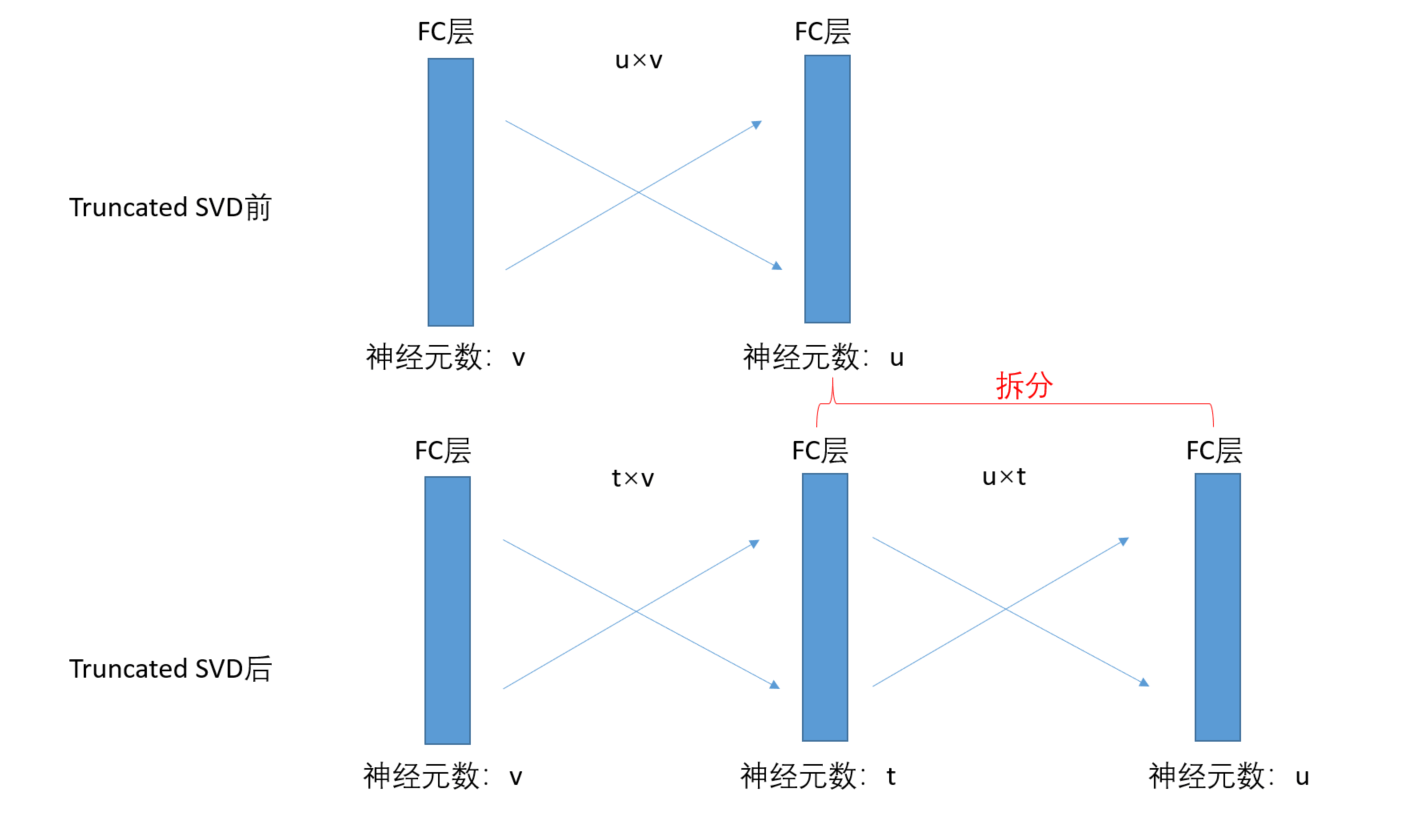
使用truncated SVD可以很容易的加速大型FC层。假设权重矩阵大小为$u\times v$,对其进行截断奇异值分解:
\[W \approx U \Sigma_t V^T \tag{5}\]其中,$U$为$u\times t$的矩阵,$\Sigma_t$为$t\times t$的矩阵,$V^T$为$v\times t$的矩阵。
奇异值分解请见:【数学基础】第十七课:奇异值分解。truncated SVD用最大的$t$个奇异值和对应的左右奇异向量来近似描述矩阵$W$。
分解前的$W$的参数数量为$uv$,分解后三个矩阵加起来的参数数量为$t(u+v)$。只要$t$小于$min(u,v)$,通过truncated SVD就能实现参数的减少。因此,我们将权重矩阵为$W$的FC层拆成两个相连的FC层,这两层之间不使用非线性关系。其中,第一层的权重矩阵为$\Sigma_t V^T$(不使用偏置项),第二层的权重矩阵为$U$(继承拆分前的偏置项),示意图见下:
这个压缩方法很好的提升了检测速度。
个人理解:这个思想类似于Inception模块中对$1\times 1$卷积的使用。
4.Main results
三个主要的成果:
4.1.Experimental setup
我们在线上获取了3个已经使用ImageNet预训练好的模型(获取地址:https://github.com/BVLC/caffe/wiki/Model-Zoo)。第一个是CaffeNet,我们称其为S(译为small)。第二个是VGG_CNN_M_1024,和模型S深度一样,但是更宽,我们称其为M(译为medium)。第三个是VGG16,我们称其为L(译为largest)。这一部分所有的实验都使用single-scale traing and testing(s=600,详见第5.2部分)。
4.2.VOC 2010 and 2012 results
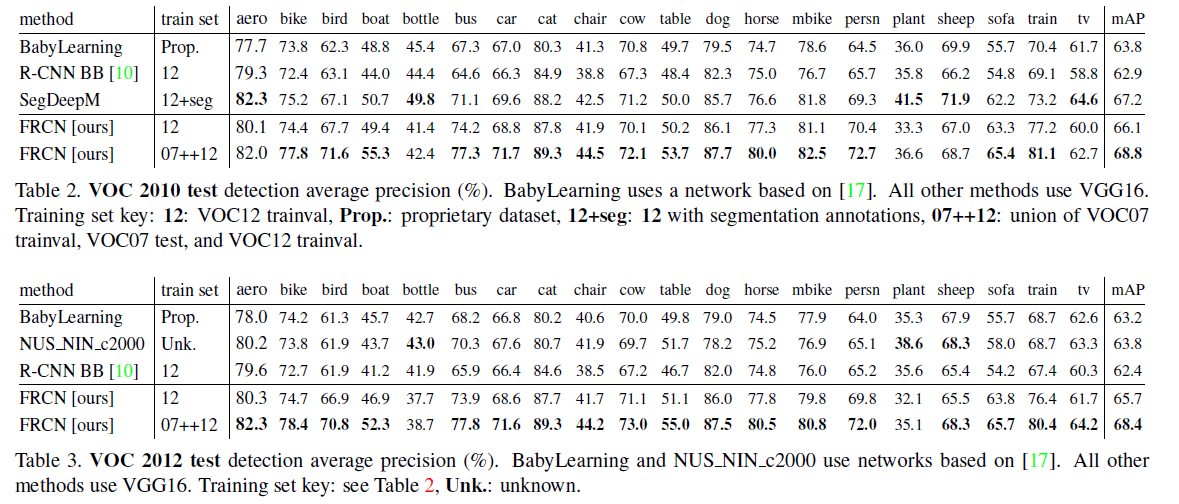
Fast R-CNN(简称为FRCN)和其他优秀方法的比较见表2、表3(数据来源:http://host.robots.ox.ac.uk:8080/leaderboard):
4.3.VOC 2007 results
结果比较见表1:
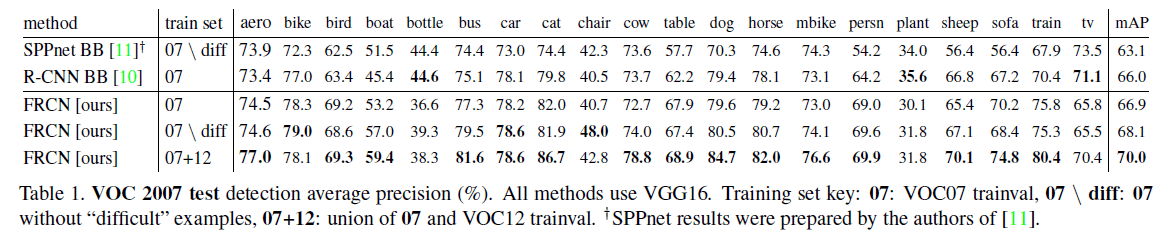
表1中所有的方法都使用一样的经过预训练的VGG16,并且都用了bounding box回归。
4.4.Training and testing time
更快的训练和推理速度是我们第二个主要成果。表4比较了不同方法的训练时间(小时)、推理速度(每张图像用时多少秒)以及在VOC07上的mAP。此外,Fast R-CNN内存占用更少,因为不再需要缓存feature。
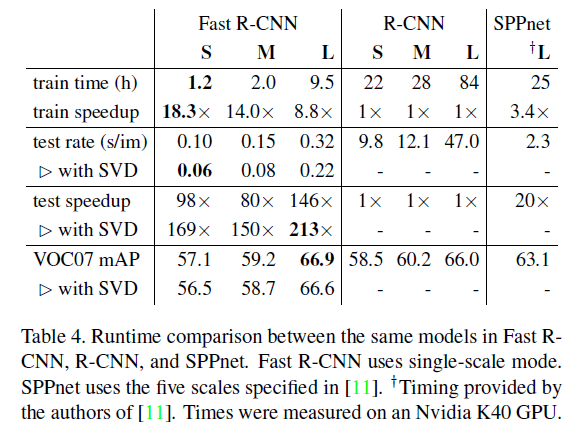
truncated SVD使我们的模型在仅牺牲0.3%mAP的情况下,速度提升了30%(见Fig2)。
4.5.Which layers to fine-tune?
SPPnet只对FC层进行了fine-tune,这可能对较浅的网络有用。对于较深的网络,我们认为fine-tune卷积层是很有必要的。我们以基于VGG16的Fast R-CNN为例:

从表5中可以看出,fine-tune卷积层很明显提升了mAP。但这并不意味着所有的卷积层都需要被fine-tune。对于模型S和模型M,我们发现fine-tune conv1并没有什么用。对于表5中的模型L,我们认为从conv3_1开始fine-tune更有意义(即fine-tune了13个卷积层中的9个),虽然从conv2_1开始fine-tune的mAP更高,但为了0.3% mAP的提升却损失了训练速度(12.5h vs. 9.5h)。因此,本文中所有模型L的fine-tune都是从conv3_1开始的,而模型S和模型M的fine-tune则是从conv2开始的。
5.Design evaluation
我们在PASCAL VOC07数据集上进行评估。
5.1.Does multi-task training help?
multi-task不但方便(结构简洁),而且两个task之间互相影响,在一定程度上可以提升目标检测的准确率。为了验证这一结论,我们做了如下实验。
结果见表6。模型S,M,L中的第一列我们只使用了分类代价$L_{cls}$(即$\lambda = 0$),并且没有使用bounding box回归。第二列我们使用了multi-task loss($\lambda = 1$),但是在推理阶段没有使用bounding box回归,这样能更公平的比较第一列和第二列的区别。
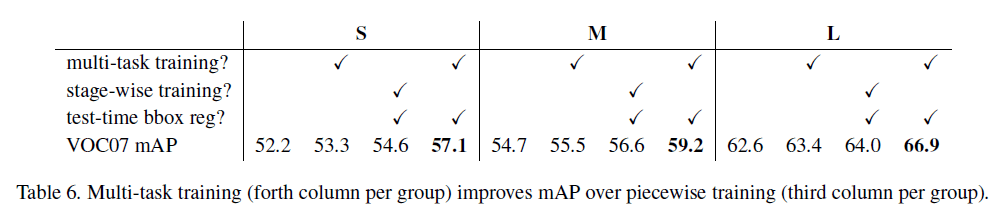
通过比较表6中每个模型的第一列和第二列可以看出,multi-task loss的使用将mAP提升了0.8到1.1不等。
表6中的stage-wise training指的是先只用$L_{cls}$(即$\lambda = 0$)训练整个模型,然后使用$L_{loc}$只训练bounding-box regression layer(其他层参数固定,不再变化)。test-time bbox reg指的是推理阶段是否使用bounding box回归。从表6中可以看出,stage-wise training的效果不如multi-task training。
5.2.Scale invariance: to brute force or finesse?
我们定义图像短边为$s$,我们比较了single-scale learning和multi-scale learning。
对于single-scale learning,我们设$s=600$。等比例缩放使$s=600$后,此时限制长边需小于1000(GPU内存限制)。对于multi-scale learning,我们设$s=\{ 480,576,688,864,1200 \}$,限制长边需小于2000(同样是GPU内存限制)。
表7中的模型S和模型M训练和推理都使用single-scale或都使用multi-scale。从表7中可以发现,multi-scale只带来了一点点mAP的提升,却增加了大量推理耗时。
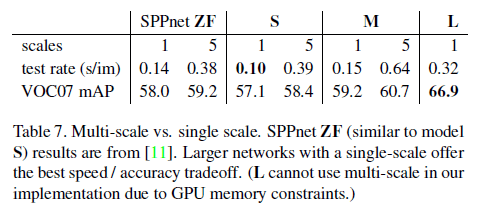
所以,我们认为single-scale性价比更高,尤其是对于较深的模型。我们在所有的实验中训练和测试都使用single-scale且设$s=600$。
5.3.Do we need more training data?
一个好的object detector的性能应该随着训练集的增大而提升。从表1中可以看出,我们的方法随着训练集的扩充,mAP从66.9%增加到70.0%(迭代次数也从40k增加至60k)。作者还在VOC10和VOC12上做了类似的实验,结论是一致的,不再赘述。
5.4.Do SVMs outperform softmax?
Fast R-CNN使用了softmax,而R-CNN和SPPnet使用了一对其余的线性SVM分类器。为了探究哪种更优,我们做了如下实验:

对于FRCN来说,无论模型S、M还是L,softmax都要优于SVM。
5.5.Are more proposals always better?
object detectors大致可分为两种类型:1)使用object proposal的一个sparse set(例如selective search);2)使用一个dense set(例如DPM)。
DPM原文:P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.

我们评估了每幅图像使用1k到10k个proposal的结果(基于模型M,每次都会re-training和re-testing),结果见Fig3蓝色实线,当proposal的数量过多时,mAP有轻微的下降。在SS(即selective search)的基础(2k个proposal)上,每幅图像再加上$1000 \times \{ 2,4,6,8,10,32,45 \}$个dense box,结果见Fig3蓝色虚线。Fig3中,蓝色三角指的是每幅图像生成45k个dense box,然后将2k个由SS生成的proposal转换成距离最近的dense box得到的结果(即最后每幅图像用了2k个dense box),mAP下降了1%,为57.7%。蓝色菱形指的是仅使用45k个dense box+softmax的结果,mAP=52.9%。蓝色圆形指的是仅使用45k个dense box+SVM的结果,mAP=49.3%。
我们认为sparse object proposal更能提升模型性能。
5.6.Preliminary MS COCO results
我们还在COCO数据集上测试了Fast R-CNN(with VGG16),本博文不再详述这部分。
6.Conclusion
全文总结,不再详述。
