本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
基于自注意力机制的框架,尤其是Transformers,已经成为了NLP任务的首选模型。主流的方式是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行fine-tune。由于Transformers的计算效率和可扩展性,使得训练超过100B参数数量的巨大模型成为可能。并且随着模型和数据集的增长,性能仍然没有饱和的迹象。
然而在CV领域,卷积结构仍占主导地位。受到NLP成功案例的启发,一些paper尝试将CNN结构和自注意力机制相结合,甚至完全取代卷积结构。但是目前来看,在大规模的图像识别任务中,经典的ResNet结构仍然是SOTA的。
受到Transformer在NLP领域内取得巨大成功的启发,我们尝试将标准的Transformer直接作用于图像,并尽可能少的修改。为此,我们把一幅图像分成多个patch,并将这些patch的linear embeddings序列作为输入喂给Transformer。image patch就相当于NLP任务中的token(word)。我们通过有监督的方式来训练我们的图像分类模型。
当我们在中等规模的数据集(比如ImageNet)上训练时(没有使用很强的正则化),得到的模型的准确率会比同等规模的ResNet低几个百分点。这一令人沮丧的结果可能是意料之中的:Transformer缺乏CNN所固有的一些归纳偏置(inductive biases,比如平移不变性和局部性),因此在数据量不足的情况下无法很好的进行generalize。
如果训练使用更大的数据集(14M-300M张图像),结果就不一样了。我们发现大规模的训练优于inductive biases。当有足够规模的预训练,然后在数据较少的任务上测试时,我们的模型Vision Transformer(ViT)能取得优异的结果。当在ImageNet-21k数据集或JFT-300M数据集上预训练后,ViT在多个图像识别benchmark上接近或超过了之前SOTA的结果。尤其是,ViT的准确率在ImageNet上达到了88.55%,在ImageNet-ReaL上达到了90.72%,在CIFAR-100上达到了94.55%,在VTAB上达到了77.63%。
fine-tuning的代码和预训练的模型:https://github.com/google-research/vision_transformer。
2.RELATED WORK
Transformer最初提出是用于机器翻译,后来成为许多NLP任务SOTA的方法。基于Transformer的大型模型通过在大型语料库上进行预训练,然后针对手头的任务进行fine-tune。
将自注意力机制单纯的应用于图像需要每个像素关注其他所有的像素。过去也有很多paper尝试了将Transformer应用于CV。这些paper都展示了有希望的结果,但是需要复杂的engineering才能高效的在hardware accelerators上执行。
和ViT最相似的一篇paper是:“Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self- attention and convolutional layers. In ICLR, 2020.”。但是我们进一步证明了大规模的预训练可以使Transformer接近或优于SOTA的CNN模型。并且,上述论文使用了$2\times 2$的patch,使其仅适用于小分辨率的图像,而ViT可处理中等分辨率的图像。
也有很多paper尝试将CNN和自注意力机制相结合,应用于目标检测,视频处理,图像分类等多种任务。
另一篇最近相关的paper是image GPT(iGPT):“Mark Chen, Alec Radford, Rewon Child, Jeff Wu, and Heewoo Jun. Generative pretraining from pixels. In ICML, 2020a.”,该模型在降低图像分辨率和彩色空间后,将Transformer应用于图像像素。该模型以无监督的方式作为生成模型(generative model)进行训练,最终在ImageNet上达到了72%的准确率。
3.METHOD
模型设计方面,我们尽可能的接近原始的Transformer。这样做的一个优点是对于Transformer,我们几乎可以说是开箱即用。
3.1.VISION TRANSFORMER (VIT)

模型的总体框架见Fig1。标准的Transformer的输入为一维的token embeddings的序列。为了使其能处理二维图像,假设原始图像为$\mathbf{x} \in \mathbb{R}^{H\times W \times C}$,其中$(H,W)$为原始图像的分辨率,$C$为通道数,将原始图像划分为多个patch,将每个patch都拍扁为一维,如果有$N$个patch则可得到序列:$\mathbf{x}_p \in \mathbb{R}^{N\times (P^2\cdot C)}$,其中$(P,P)$为每个patch的分辨率,$N=HW/P^2$为patch的数量(即Transformer的有效输入序列长度)。Transformer在所有层中使用了一个固定的向量大小$D$,因此我们也将拍平的patch通过一个可训练的线性映射投影到$D$维(见公式1,个人理解就是Transformer中的$d_{model}=512$,即Fig1中的Linear Projection)。我们将其称为patch embeddings。
类似于BERT的[class] token,我们也设置了一个可学习的嵌入向量($\mathbf{z}_0^0=\mathbf{x}_{class}$),其经过Transformer编码器得到的$\mathbf{z}_L^0$为image representation $\mathbf{y}$(见公式4,个人理解:就是图像的类别标识)。在预训练和fine-tune过程中,一个classification head和$\mathbf{z}_L^0$相连。在预训练时,classification head由一个带有一个隐藏层的MLP实现;在fine-tune时,classification head由一个线性层实现。
position embeddings也被加在了patch embeddings上以保留位置信息。我们使用标准的一维的可学习的position embeddings,因为我们发现更先进的二维position embeddings并没有带来显著的性能提升(见Appendix D.4)。生成的embedding vectors(即$\mathbf{z}_0$)作为编码器的输入。
Transformer编码器的每一层包含两个block:multiheaded self-attention(MSA,见Appendix A)和MLP(见公式2和公式3)。每个block之前都用了Layernorm(LN),每个block之后都添加了残差连接。
MLP包含两层并使用GELU非线性激活函数。
\[\mathbf{z}_0=[ \mathbf{x}_{class}; \mathbf{x}_p^1 \mathbf{E};\mathbf{x}_p^2 \mathbf{E};\cdots ; \mathbf{x}_p^N \mathbf{E} ]+\mathbf{E}_{pos}, \quad \mathbf{E} \in \mathbb{R}^{(P^2\cdot C)\times D},\mathbf{E}_{pos} \in \mathbb{R}^{(N+1)\times D} \tag{1}\] \[\mathbf{z}'_{\ell}=\text{MSA}(\text{LN} (\mathbf{z}_{\ell-1}))+\mathbf{z}_{\ell-1}, \quad \ell=1 \dots L \tag{2}\] \[\mathbf{z}_{\ell}=\text{MLP}(\text{LN}(\mathbf{z}'_{\ell}))+\mathbf{z}'_{\ell}, \quad \ell=1 \dots L \tag{3}\] \[\mathbf{y}=LN(\mathbf{z}_L^0) \tag{4}\]Inductive bias.
如我们在第1部分中提到的,相比CNN,ViT缺少inductive bias。对于CNN来说,局部性(locality)、two-dimensional neighborhood structure和平移不变性(translation equivariance)在整个模型中通过每一层进行反向传播。在ViT中,只有MLP层具有局部性和平移不变性,而自注意力层则是全局的。two-dimensional neighborhood structure在ViT中的使用是稀疏的(这个也很好理解,因为ViT将输入分割成多个patch,相比CNN的滑动窗口机制,这自然是稀疏的):在模型的开始,图像会被分隔为多个patch;并且在fine-tune的时候,针对不同的分辨率,我们会调整position embeddings(后文会有更详细的解释)。除此之外,在初始阶段,position embeddings并没有携带patch的2D位置信息,其需要从头自己学习patch之间的空间位置信息(个人理解:position embeddings不是通过特定公式算出来的,而是通过网络学习出来的,这点和Transformer不同)。
对于上述提到的CNN的几个性质的个人理解:
- locality:指的是CNN结构中的感受野机制。
- two-dimensional neighborhood structure:指的是CNN中的滑动窗口机制。
- translation equivariance:平移不变性意味着系统产生完全相同的响应(输出),不管它的输入是如何平移的。比如我们用$g$表示平移,$f$表示卷积,那么平移不变性用公式表示就是:$f(g(x)) = g(f(x))$,即无论是先平移后卷积还是先卷积后平移,得到的结果都是一样的。
Hybrid Architecture.
除了直接使用图像分割成的patch作为输入,也可以将CNN计算得到的feature map分割成patch作为输入,我们称这种复合模型为hybrid model(因为得先使用CNN计算feature map,然后再执行ViT)。如果是这样的话,有一种特殊情况就是feature map分割得到的patch大小可能是$1\times 1$,这样我们就省去了flatten的步骤。classification input embedding和position embeddings的使用还和之前一样。
简单串一下ViT模型的前向过程,首先假设输入图像大小为$224 \times 224 \times 3$,每个patch的大小设为$16\times 16$(这也是文章标题中$16 \times 16$的含义),那我们一共可以得到$N = \frac{224^2}{16^2}=196$个patch。每个patch的维度为$16 \times 16 \times 3=768$。Fig1中的Linear Projection其实就是一个全连接层,在前文(包括公式)中使用$\mathbf{E}$表示这个全连接层。该全连接层的维度为$768 \times 768$,其中第一个768是通过patch维度算出来的(即Flattened Patch),是不变的;第二个768为前文中的$D$,这个是用户可以自定义的,所以是可变的。此外除了这196个token外,我们还有一个class token,其维度为$1\times 768$,所以最终Transformer Encoder的输入维度为$197 \times 768$。另外需要注意的是,在进Transformer Encoder之前,每个patch对应的向量还需要加上一个position embedding,这个position embeddings可以看作是一个$196 \times 768$的矩阵,矩阵的每一行对应一个patch的position embedding($1\times 768$),这个矩阵是可以被学习的,所以加上position embedding并不会改变Transformer Encoder的输入维度。进入Transformer Encoder后,假设使用Transformer的base版本,即12头注意力机制,那么$k,q,v$的维度为$197 \times 64$(因为$768 \div 12 =64$),最后经过concat,所以MSA block的输出维度依然是$197 \times 768$。在MLP block中,先将维度扩大4倍,即$197 \times 3012$,然后再恢复成$197 \times 768$的维度。最后,MLP Head只接受$\mathbf{z}_L^0$作为输入,即只考虑class token。
3.2.FINE-TUNING AND HIGHER RESOLUTION
通常情况下,我们会先在大型数据集上预训练ViT,然后再在小型目标数据集上进行fine-tune。在fine-tune的时候,预训练完的MLP Head会被移除,然后添加一个用0初始化的$D \times K$的全连接层,$K$是小型目标数据集的类别数。如果小型目标数据集的图像分辨率更高,那这种fine-tune方式是很合适的。如果输入的图像分辨率更高,同时保持patch size不变,那序列长度就会变长(即patch数量更多)。只要硬件条件允许,ViT可以处理任意长度的序列,但序列长度的变化会使得之前预训练好的position embeddings就不能用了。我们的解决办法是对预训练好的position embeddings进行2维的线性插值以适配新的序列长度(依据patch在原始图像中的位置进行2维线性插值)。需要注意的是,这种分辨率调整策略和patch的抽取是ViT中唯一应用了有关2D结构的归纳偏置(inductive bias)的地方。
4.EXPERIMENTS
我们评估了ResNet,ViT以及混合模型(hybrid model)的表征(representation)学习能力。为了理解每种模型对数据量的需求,我们在不同大小的数据集上进行了预训练并在不同任务中进行了评估。当考虑预训练模型的计算成本时,ViT的表现无疑是非常好的,以较低的预训练成本即可在多数任务中达到SOTA的水平。最后,我们用自监督的方式进行了一个小实验,以证明自监督的ViT在未来是很有前景的。
这里简单说一下自己对于Self-Supervised Learning的理解。Self-Supervised Learning是先在大量无标注数据上通过某种方法训练模型使其具备一定的特征提取能力,然后再在少量有标注的数据(即所谓的下游任务)上进行fine-tune从而使模型具有分类或识别的能力。Self-Supervised Learning可以很好的解决标注数据不足的问题。
4.1.SETUP
👉Datasets.
为了探索模型的伸缩性(scalability),我们使用了以下几个数据集:
- ILSVRC-2012 ImageNet数据集,共有1k个类别,1.3M张图像(后文我们就简称为ImageNet数据集)。
- ImageNet-21k数据集,共有21k个类别,14M张图像。
- JFT数据集,共有18k个类别,303M张高分辨率的图像。
针对下游任务的测试集,对预训练的数据集进行去重(去重操作参照论文:Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.)。下游任务所用的数据集(都是分类任务)有:
- ImageNet on the original validation labels and the cleaned-up ReaL labels
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
这些下游任务数据集的预处理方式都遵循论文“Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.”。
此外,我们还在19-task VTAB classification suite上进行了评估。VTAB中每种任务有1000个样本。这些任务可分为三类:
- Natural:比如上述的那些任务,Pets,CIFAR等。
- Specialized:医学和卫星图像。
- Structured:需要学习几何信息的任务,比如定位(localization)。
👉Model Variants.
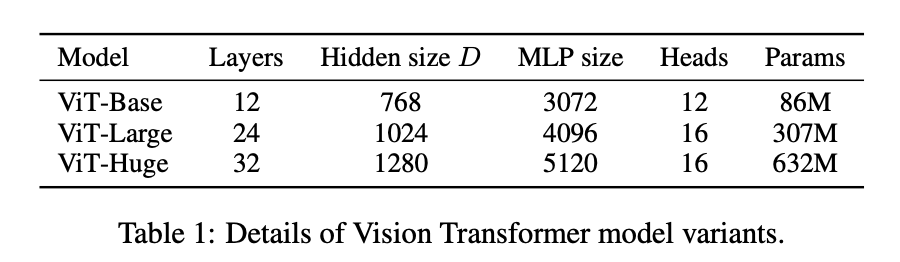
类似BERT的配置,我们也列出了几种不同配置的ViT(见表1)。除了“Base”和“Large”版本直接采用自BERT,我们还额外添加了“Huge”版本。在下文中,我们会用更简短的名称描述模型,比如ViT-L/16表示使用“Large”版本的变体,每个patch的大小(即input patch size)为$16 \times 16$。需要注意的是,Transformer的序列长度(即token数量)和patch size成反比,因此patch size越小,计算成本越高。
表1中的Layers指的是用了几个Transformer Encoder block。即Fig1中的L。
对于作为baseline的CNN网络,我们使用ResNet,但是把其中的BatchNorm替换成了Group Normalization,并且使用了standardized convolutions。我们将修改之后的模型称之为“ResNet(BiT)”。对于混合模型,我们将中间的feature map作为输入喂给ViT,patch size设为$1\times 1$。为了测试不同的序列长度,我们使用了两种方案:
- 直接使用ResNet50 stage 4的输出作为喂给ViT的feature map(维度为$14 \times 14$)。
- 依然是使用ResNet50,但是把stage 4移除(stage 4共有6个block),将stage 3从4个block扩展为10个block,将扩展后的stage 3的输出作为喂给ViT的feature map(维度为$28 \times 28$)。
方案二将序列长度增加了4倍($\frac{28^2}{14^2}=4$),计算成本也会更高。
standardized convolutions论文:Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, and Alan Yuille. Weight standardization. arXiv preprint arXiv:1903.10520, 2019.。
👉Training & Fine-tuning.
我们训练所有的模型,包括ResNet,都使用Adam($\beta_1 = 0.9, \beta_2 = 0.999$),batch size=4096,weight decay=0.1,我们发现这些参数的设置有利于所有模型的transfer(个人理解这里的transfer指的是先在大型数据集上预训练,然后将预训练好的模型transfer到小型目标数据集上进行fine-tune)(Appendix D.1表明,与常规做法相比,在我们的环境中,对于ResNet,Adam的效果要比SGD好一点点)。我们使用了线性的学习率进行warmup和线性的decay,详见Appendix B.1。
上述都是训练阶段的参数设置,接下来是fine-tune阶段的设置。在fine-tune阶段,所有模型都使用momentum,batch size=512,详见Appendix B.1.1。ImageNet的结果见表2,我们在更高的分辨率下进行fine-tune:512分辨率用于ViT-L/16、518分辨率用于ViT-H/14,此外还使用平均随机梯度下降算法,平均因子设置为0.9999。
平均随机梯度下降算法出自论文:B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization, 30(4):838–855, 1992. doi: 10.1137/0330046. URL https://doi.org/10.1137/0330046.。pytorch中也有对应API:
torch.optim.ASGD。
👉Metrics.
在下游任务上进行结果评估时,用到了两种准确率:few-shot准确率和fine-tune准确率。fine-tune准确率指的是每个模型在对应数据集上fine-tune之后得到的准确率。few-shot准确率其实指的是linear few-shot evaluation,即把预训练好的模型当作一个特征提取器,对其不进行fine-tune,将提取到的特征直接通过一个逻辑回归进行结果预测。few shot指的就是每个类别只取很少(few)的样本用于测试。虽然我们关注的是fine-tune的性能,但是fine-tune的成本太高了,所以我们可以使用few-shot准确率进行快速的测评。
4.2.COMPARISON TO STATE OF THE ART
首先我们比较了ViT-H/14,ViT-L/16和SOTA的CNN网络模型。第一个比较对象是Big Transfer(BiT),其使用一个很大的ResNet进行监督迁移学习(supervised transfer learning)。第二个比较对象是Noisy Student,这是一个使用ImageNet和JFT-300M(去掉labels)数据集,且通过半监督学习训练的一个大型EfficientNet。目前,Noisy Student是在ImageNet上表现最优的方法之一,而BiT-L则是其他数据集(即除了ImageNet之外的数据集)上最优的方法之一。所有的模型都在TPUv3上进行训练,使用TPUv3-core-days表示使用TPUv3的一个core进行训练需要的天数。
BiT论文:Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.。
Noisy Student论文:Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V. Le. Self-training with noisy student improves imagenet classification. In CVPR, 2020.。
测试结果见表2。ViT-L/16在JFT-300M上进行了预训练,BiT-L也在同样的数据集上进行了预训练,但是ViT-L/16的结果在所有fine-tune数据集上的表现都更胜一筹,并且训练天数也大大减少(0.68k vs. 9.9k)。对于我们更大的模型ViT-H/14,性能进一步得到提升,尤其是在一些更具挑战性的数据集上,比如ImageNet,CIFAR-100和VTAB suite。并且,与现有SOTA的方法相比,ViT-H/14需要更少的训练时间。此外,我们发现预训练的效果不仅会受到模型框架的影响,还会受到其他参数的影响,比如training schedule,optimizer,weight decay等等。在第4.4部分,我们提供了不同框架的性能和计算的对照研究。最后,我们还测试了将ViT-L/16放在ImageNet-21k上进行预训练,其在多数数据集上fine-tune的结果也还不错,并且只需要在8核的TPUv3上训练大约30天即可。
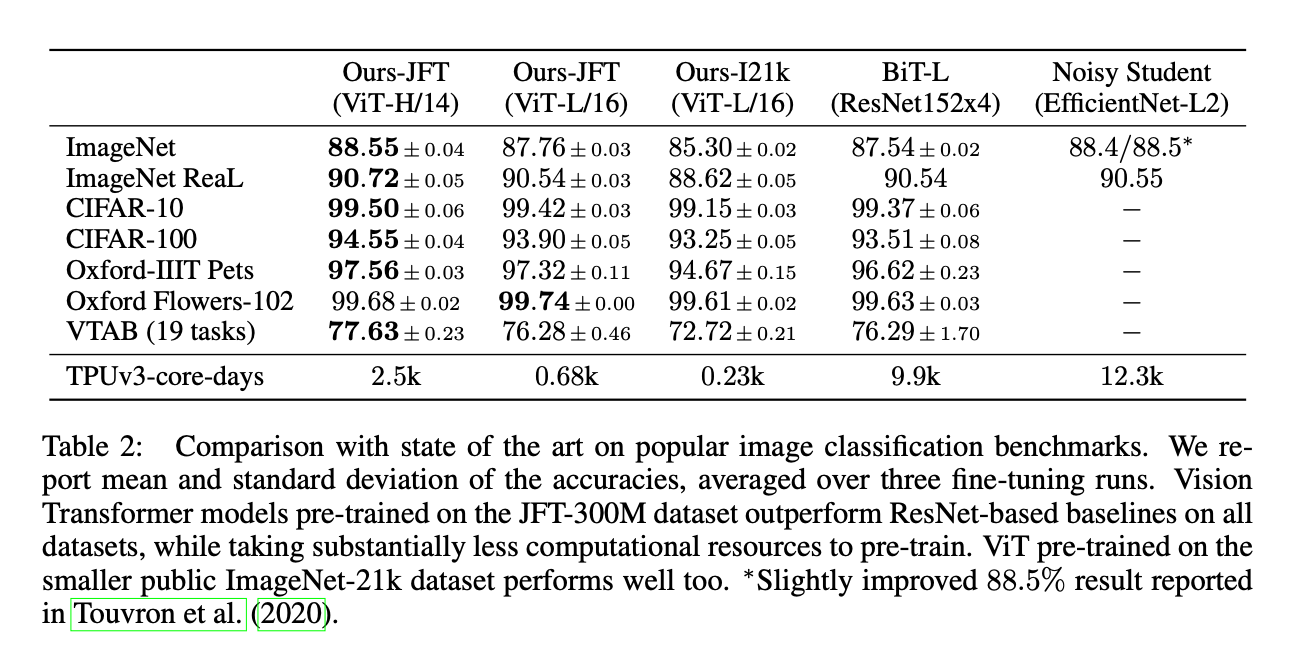
表2是和常见的图像分类任务的benchmark的比较结果。基于三次fine-tune的平均运行结果,我们列出了准确率的均值和标准差。
Fig2是将VTAB的任务分成了三类(前文有提到过),并分别和之前SOTA的方法进行比较:
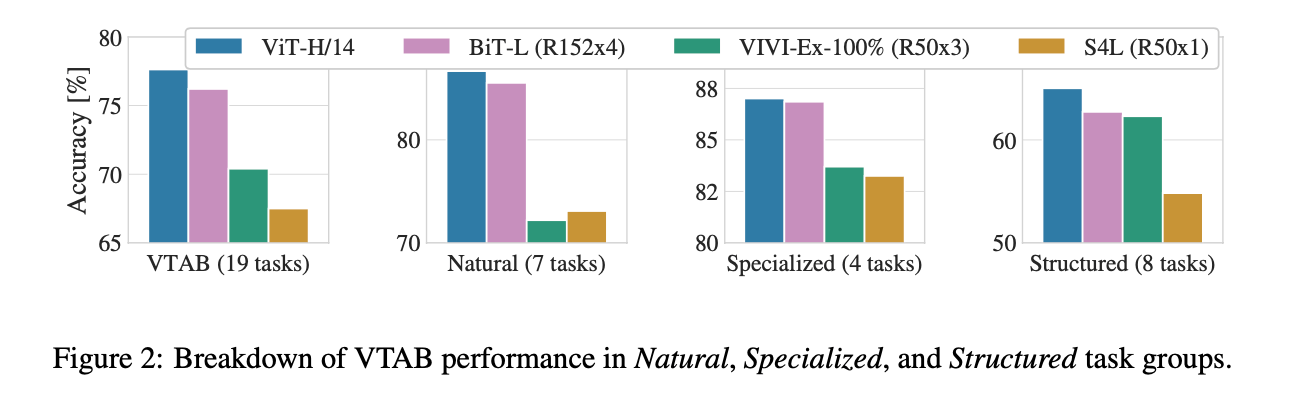
很明显,ViT-H/14都是最优的。
4.3.PRE-TRAINING DATA REQUIREMENTS
ViT在大型数据集JFT-300M上预训练的效果很好。虽然ViT比ResNet有更少的归纳偏置,那数据集的大小会有多重要呢?我们进行了两个系列的实验。
首先,我们将ViT在以下数据集上进行预训练(按数据集从小到大排列):ImageNet,ImageNet-21k,JFT-300M。为了提升其在更小型数据集上的表现,我们优化了3个基础的正则化参数:weight decay,dropout,label smoothing。Fig3展示了针对ImageNet进行fine-tune之后的结果(在其他数据集上的测试结果见表5)。这里需要注意的是在ImageNet预训练的模型同时再次被拿到ImageNet上进行了fine-tune。这是因为在fine-tune时会使用更高的分辨率以提高模型表现。当在最小的数据集ImageNet上进行预训练时,ViT-L的表现不如ViT-B,尽管使用了适度的正则化。当使用ImageNet-21k进行预训练时,ViT-L和ViT-B的表现差不多。只有当使用JFT-300M进行预训练时,大型模型的优势才得以全部呈现。Fig3也展示了BiT在不同大小数据集上进行预训练的表现。当使用较小的数据集进行预训练时(比如ImageNet),ViT的效果不如BiT CNNs。但是当在较大数据集上进行预训练时(比如ImageNet-21k和JFT-300M),ViT的表现更胜一筹。
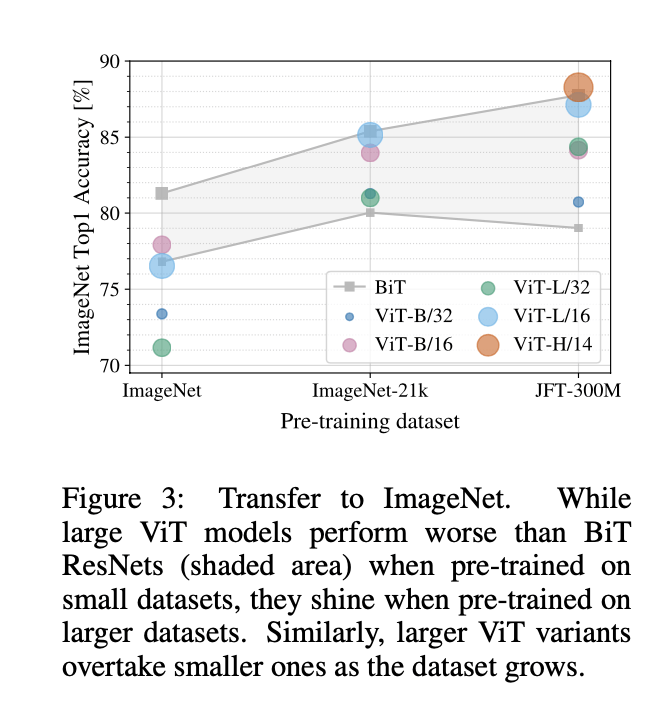
个人理解:Fig3中表示BiT的有两条折线,较大方块应该表示的是BiT的大型模型,较小方块表示的是BiT的小型模型。
第二个实验,我们从完整的JFT-300M数据集中随机抽取9M,30M,90M大小的子数据集用于训练模型。我们在子数据集上没有使用额外的正则化,所有模型都使用一样的超参数。这样我们就屏蔽掉了正则化的影响,只是单纯的评估模型的固有属性。我们评估了模型在验证集上的最优准确率。为了节省计算成本,我们使用了few-shot准确率,而不是fine-tune准确率。实验结果见Fig4。在较小数据集上,ViT相比ResNet更容易过拟合。例如,ViT-B/32比ResNet50稍快一点,在9M的子数据集上,ViT-B/32的表现更差,但是在90M+的子数据集上,ViT-B/32的表现更好。对于ResNet152x2和ViT-L/16之间的比较是一样的趋势。这一结果更印证了卷积的归纳偏置特性对于小型数据集更有用,但是对于大型数据集,直接从数据中学习相关模式(the relevant patterns)就足够了,甚至是有益的。
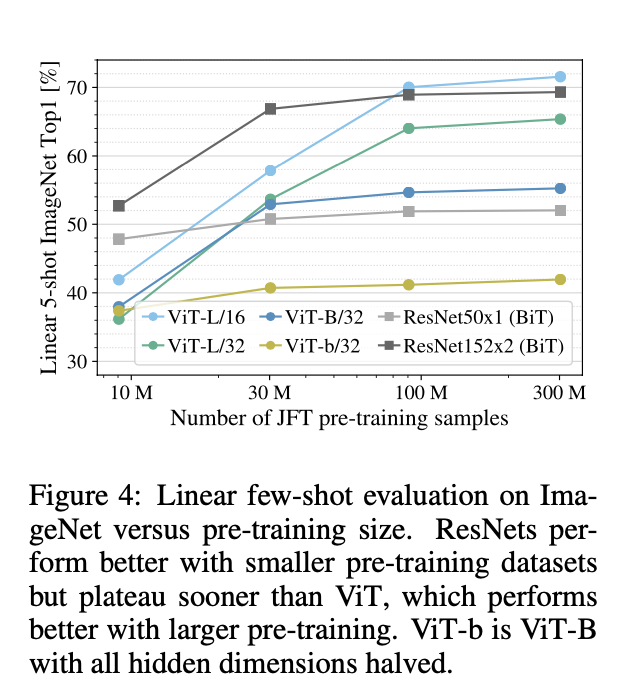
个人理解:Fig4中的ViT-b指的是将ViT-B的Hidden size D(见表1)减半得到的模型。
此外,如何提升ViT对小样本(low-data,个人理解就是提升ViT在小型数据集上的表现)的学习将会是未来很有价值的一个研究方向。
4.4.SCALING STUDY
通过在JFT-300M数据集上预训练,我们评估了不同大小的模型的迁移学习能力(transfer performance)。这种情况下,预训练数据集不会是模型性能的限制因素,我们评估了每个模型的性能以及预训练成本。我们评估的模型有:
- 7个ResNets变体:
- R50x1,R50x2,R101x1,R152x1,R152x2,以上5个模型预训练7个epoch。
- R152x2,R200x3,以上2个模型预训练14个epoch。
- 6个ViT变体:
- ViT-B/32,ViT-B/16,ViT-L/32,ViT-L/16,以上4个模型预训练7个epoch。
- ViT-L/16,ViT-H/14,以上2个模型预训练14个epoch。
- 5个混合模型(和之前命名不同,混合模型名字后面的数字不是代表patch size,而是表示ResNet backbone中的总下采样比例):
- R50+ViT-B/32,R50+ViT-B/16,R50+ViT-L/32,R50+ViT-L/16,以上4个模型预训练7个epoch。
- R50+ViT-L/16,以上1个模型预训练14个epoch。
在Fig5中,我们比较了总的预训练成本和迁移学习性能的关系(关于计算成本详见Appendix D.5)。每个模型的详细结果见表6。首先,ViT在性能/计算成本的trade-off上优于ResNet。从5个测试数据集的平均结果来看,同等性能下,ViT的计算成本少2-4倍。其次,当计算成本较低时,混合模型的性能略优于ViT,但是当计算成本较高时(即使用更大的模型,模型复杂度更高),这种差异逐渐消失。这个结果还是有点让人惊讶的,正常来说,通过卷积网络得到的特征应该能帮助到任意大小的ViT模型,但现实看起来并不是这样。此外,ViT看起来依旧没有饱和的趋势。
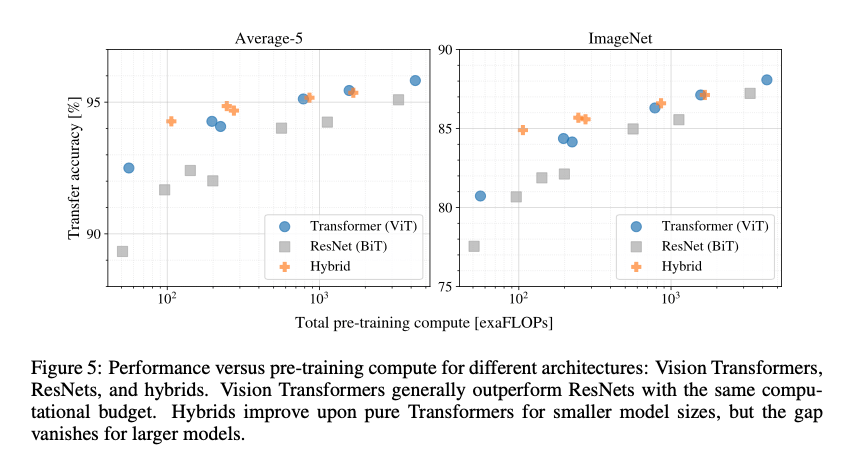
Fig5中可以看出,同等计算成本下,ViT的性能要优于ResNet。
4.5.INSPECTING VISION TRANSFORMER
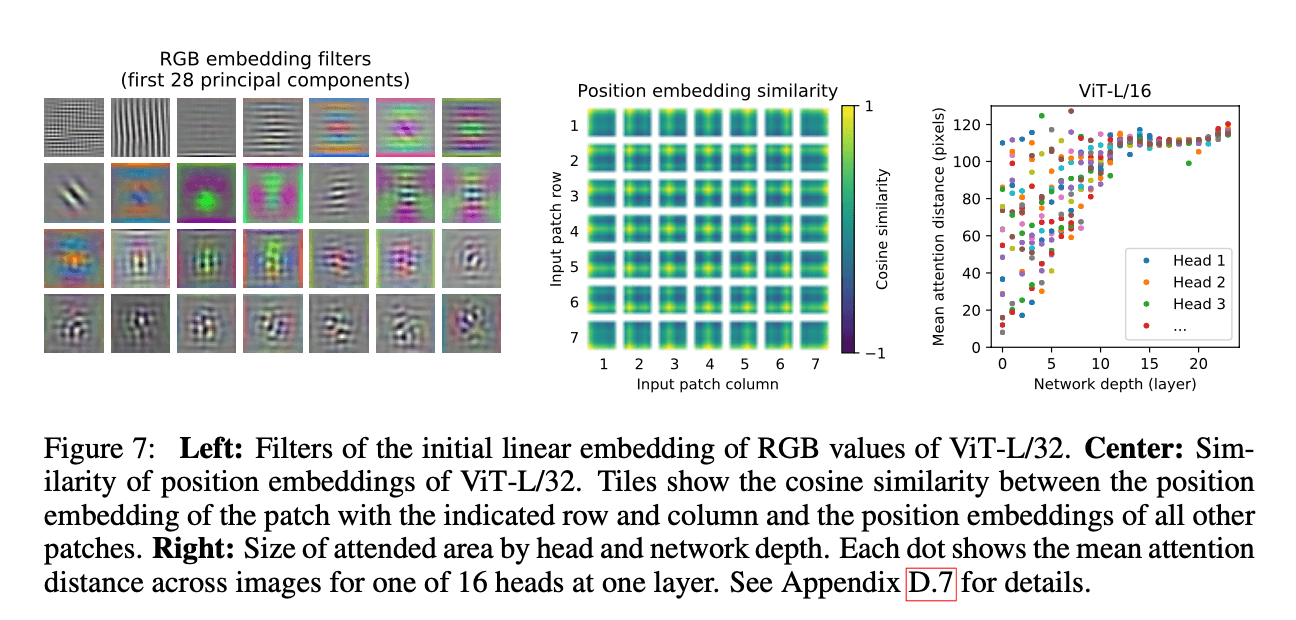
为了理解ViT是怎么处理图像的,我们分析了ViT的内部表征(internal representations)。首先我们分析了ViT的第一层,即linear projection layer,也就是公式(1)中的$\mathbf{E}$。Fig7最左边的图就展示了这一层学到的最主要的28个成分,可以看出,第一层还是学到了一些基础的纹理结构和颜色的(这里作者也没有说具体是怎么可视化的)。
在linear projection之后,我们还给patch representations加上了一个position embedding。Fig7中间这张图展示了不同位置的patch对应的position embedding之间的相似度(cosine similarity,1表示非常相关,-1表示非常不相关)。简单说下这张图怎么看,原始图像被分成了$7\times 7=49$个patch,以$(1,1)$这个patch为例,计算该patch的position embedding和其他所有位置的patch的position embedding之间的相似度,可以看到,该patch和本身的相似度是最高的(左上角为黄色,表示相似度高)。距离该patch较近的其它patch的相似度也比较高。此外,我们还可以发现,同一行或者同一列的patch的position embedding之间的相似度也比较高,这说明虽然position embedding是一维的,但其还是学到了二维位置信息,这也解释了为什么我们尝试使用二维的position embedding时并没有带来性能的提升(具体见Appendix D.4)。
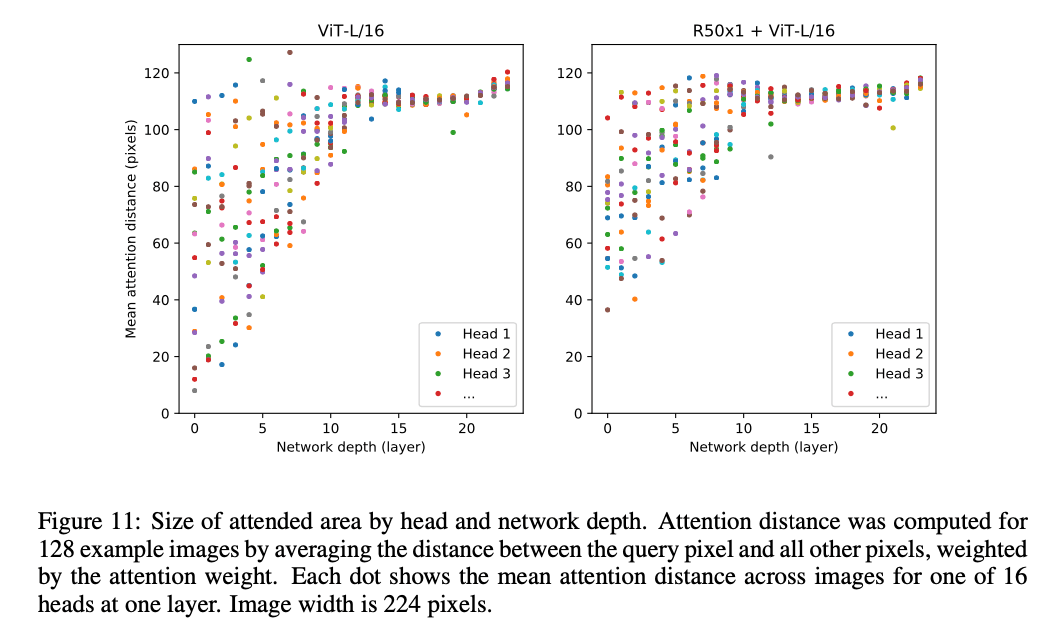
自注意力机制使得ViT从第一层开始便可以学到整幅图像的信息(因为自注意力机制可以模拟长距离的关系,在NLP里,其体现为在一个很长的句子里,句首和句尾的词可以被关联起来,而在图像中,其可以体现为很远的两个像素点之间也能做自注意力)。于是我们便测试了一下ViT对这种能力的使用程度。测试结果见Fig7最右边的图。测试使用的模型为ViT-L/16,其共有24层,对应图中的横坐标。每一个横坐标上都有16个彩色的点(即每一列都有16个彩色的点),对应模型的16个head(ViT-L/16共有16个head)。图的纵坐标为mean attention distance,假设用$d_{ab}$表示图像上两个点$a,b$之间的mean attention distance,则$d_{ab}$的计算方式为:
\[d_{ab} = l_{ab} * A_{ab}\]更多分析见Appendix A。
其中,$l_{ab}$为$a,b$两点之间的像素距离,$A_{ab}$为两点之间的attention weights(但是作者在原文中并没有详细介绍attention weights是怎么设置的)。作者还说mean attention distance其实有点类似于CNN网络中感受野大小的概念。从Fig7最右边这张图中可以看出来,在头几层有些head注意的距离比较近,但是也有一些head可以注意到很远的距离(将近120个像素的距离)。这也证明了ViT确实可以在网络最开始的前几层就能注意到全局的信息了。这一点就和CNN不同,在CNN网络的前几层,通常感受野都比较小,只能注意到比较近的距离。说回ViT,随着网络越来越深,学到的信息也越来越high level,即越来越具有语义信息。因此从图中可以看出,在网络的后半部分,所有head能注意到的距离都已经非常远了。为了验证这一点,作者又展示了Fig6:

作者是用output token折射回原始图像而得到的这些图。可以看到,网络确实学到了这些语义信息。
4.6.SELF-SUPERVISION
Transformer在NLP领域中展示了超强的能力。除此之外,让Transformer真正爆火还有另外一个原因,就是大规模的自监督训练。我们仿照BERT使用的masked language modeling task(类似于完形填空),我们使用了一种叫做masked patch prediction的自监督训练方法(个人理解:就是将图像分好patch后挖去其中某一个patch让ViT去预测,即训练ViT的特征提取能力)。通过这种自监督预训练的方式,ViT-B/16在ImageNet上取得了79.9%的准确率,相比从头开始训练增加了2%的准确率,但是相比有监督的预训练,还是低了4%。更多细节见Appendix B.1.2。这将会是未来的研究方向之一。
5.CONCLUSION
我们尝试了直接将Transformer应用于图像识别领域。和之前在CV任务中使用自注意力机制的研究工作不同,除了在初始的patch提取阶段,我们没有在框架中引入image-specific的归纳偏置。相反,我们将图像看作是一系列的patch,直接用标准的Transformer encoder来处理这些patch。这种简单且可扩展的方式在和大型数据集预训练结合使用时效果惊人。因此,在图像分类任务中,ViT追平甚至超过了许多SOTA的方法,并且ViT的预训练更便宜。
虽然这些结果令人鼓舞,但依然存在许多挑战。其中一个挑战是将ViT应用于其它CV任务,例如检测和分割。另一个挑战是继续探索自监督方式的预训练。我们的实验结果表明自监督预训练确实有助于性能提升,但是和大型的有监督预训练相比,仍有不小的差距。最后,扩大ViT的规模有助于性能提升。
6.APPENDIX
6.A.MULTIHEAD SELF-ATTENTION
多头自注意力的讲解详见:【论文阅读】Attention Is All You Need。
但是需要提一点的是,这里作者提到了attention weights,用$A_{ij}$表示,计算方式为:
\[A = softmax \left( \mathbf{qk}^T / \sqrt{D_h} \right) A \in \mathcal{R}^{N\times N}\]其实就是【论文阅读】Attention Is All You Need中下图的0.88和0.12:

所以我个人觉得4.5部分中我们提到的mean attention distance的计算方式中的$a,b$应该代表的是两个patch,这样$A_{ab}$就和这里说的attention weights能对上了,或者还有一个可能,$a,b$还是代表两个像素点,然后$A_{ab}$表示$a,b$各自所在patch之间的attention weights。
6.B.EXPERIMENT DETAILS
6.B.1.TRAINING
不同模型的训练设置见表3。我们发现从头在ImageNet上训练模型时较强的正则化是一个关键。dropout会被安排在dense layer后,但有两个例外:1)qkv-projections中不使用dropout;2)将position embedding加到patch embedding之后不接dropout。混合模型参照表3中对应的ViT模型的设置。所有的训练都在224的分辨率下完成。
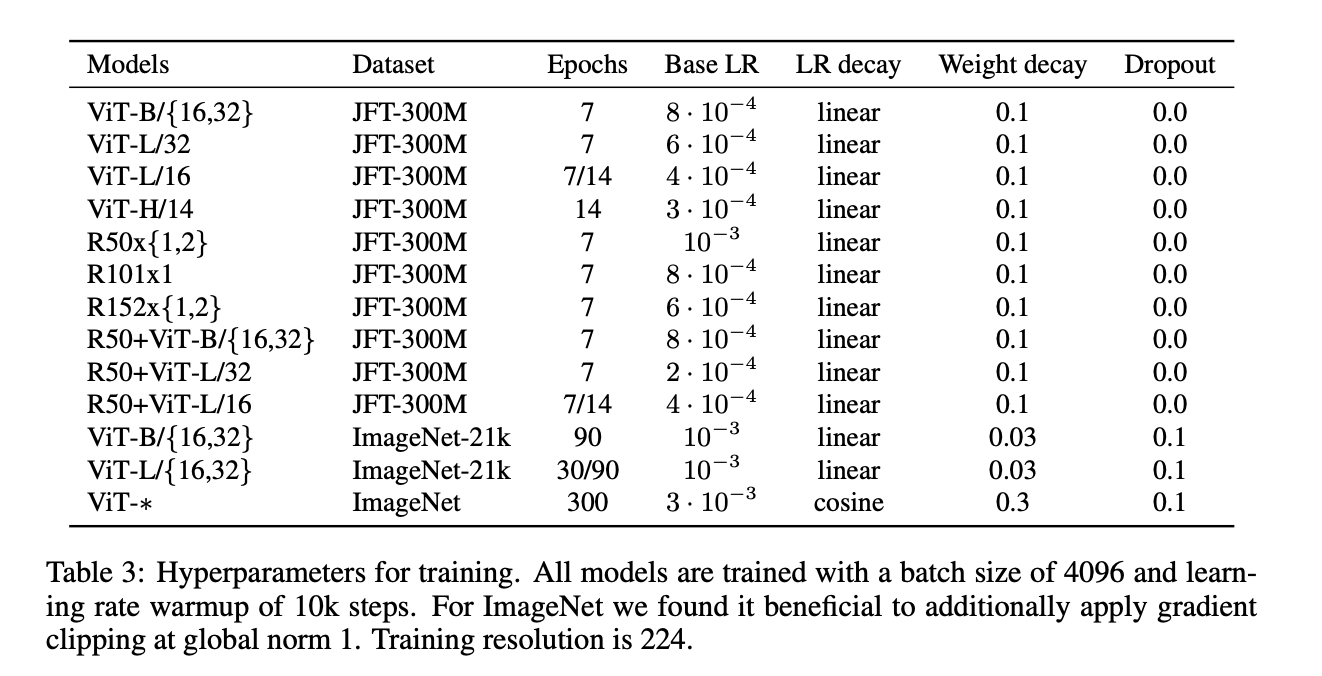
表3列出了训练的一些超参数。所有模型训练使用的batch size都为4096,学习率warmup step均等于10k。对于ImageNet数据集,我们发现额外使用gradient clipping(global norm设为1)很有用。
6.B.1.1.FINE-TUNING
我们使用SGD,momentum=0.9来fine-tune所有的ViT模型。对学习率使用了grid search,具体搜索范围见表4(个人理解:这里是为了搜索最优初始学习率,后续还有学习率衰减策略的应用)。我们将训练集分成了两个子集用于grid search:1)验证子集:10%的Pets和Flowers,2%的CIFAR,1%的ImageNet;2)训练子集:除验证子集的剩余数据。最后,我们在整个训练集和对应的测试集上获得最终的结果。ResNets和混合模型的fine-tune使用完全一样的参数设置,唯一的不同是对于ImageNet数据集,学习率搜索范围多加了一个0.06。此外,对于ResNets,我们也尝试了论文“Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.”中的参数设置,和我们的相比,选择了一个最优的。未加特殊说明,所有的fine-tune实验所用分辨率均为384(使用与训练不同的分辨率进行fine-tune是一种很常见的做法)。
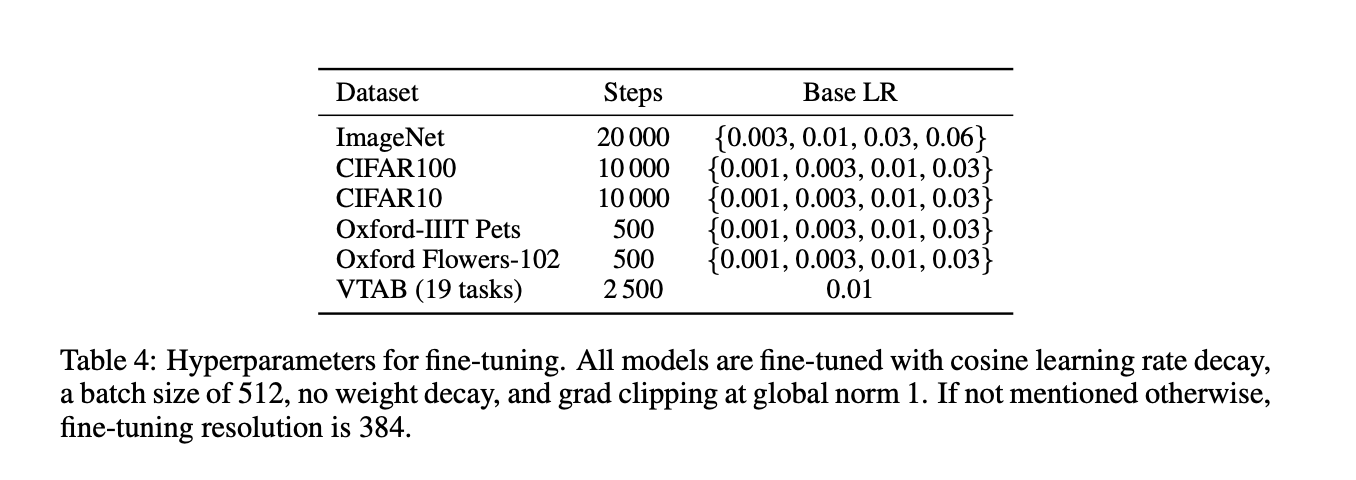
表4列出了fine-tune的超参数。所有fine-tune的模型都使用cosine learning rate decay,batch size=512,没有weight decay,使用gradient clipping(global norm设为1)。
cosine learning rate decay是一种学习率衰减策略,在论文“SGDR: STOCHASTIC GRADIENT DESCENT WITH WARM RESTARTS”中被提出。学习率计算公式为:
\[\eta_t = \eta_{min}^i + \frac{1}{2} (\eta_{max}^i - \eta_{min}^i) (1+ \cos (\frac{T_{cur}}{T_i} \pi))\]$i$为运行次数的索引,在$i$次运行时,$T_i$为该次运行预设的总的epoch数,$T_{cur}$为当前已经执行过的epoch数。$\eta_{min}^i$和$\eta_{max}^i$为该次运行的学习率的预设范围,通常有$\eta_{min}=0,\eta_{max}=1$。$\eta_t$为更新后的学习率。
当将ViT迁移到其它数据集时,我们移除了整个head(个人理解就是移除了MLP Head,包含一个隐藏层和一个输出层,一共两个linear layers),将其直接替换为一个用0初始化权重的输出层,输出神经元数和目标数据集类别数一样。我们还尝试只重新初始化输出层(即不移除MLP Head),但效果不如前者。
对于VTAB数据集,我们使用和“Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.”一样的protocol,对于VTAB的所有任务,使用一样的超参数设置。如表4所示,我们使用0.01的学习率,训练2500 steps(step和epoch表示的不是一个东西)。我们是通过200个example的验证集选出的这组参数。我们遵循“Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): General visual representation learning. In ECCV, 2020.”中的预处理方式,唯一不同的是我们没有使用任务特定的输入分辨率。因为我们发现对于所有任务,ViT从高分辨率($384\times 384$)中能获得最高的收益。
6.B.1.2.SELF-SUPERVISION
我们使用masked patch prediction进行初步的自监督实验。为此,我们将50%的patch embedding做如下三种处理中的一个:
- 替换为可学习的mask embedding(80%,即50%中的80%)。
- 随机替换为其它patch embdding(10%)。
- 保持原样(10%)。
这一操作和BERT中的语言处理方式类似。Finally, we predict the 3-bit, mean color (i.e., 512 colors in total) of every corrupted patch using their respective patch representations.(我自己没太理解这句话,在网上查了好久也没找到合适的解释,我自己理解的ViT的自监督方式就是如下图所示的那样)。

我们将这个自监督模型在JFT数据集上训练了1M steps(约14个epoch),batch size=4096。使用Adam算法,base学习率为$2 \cdot 10^{-4}$,warmup step等于10k,使用cosine learning rate decay。对于预训练的预测目标,我们尝试了以下设置(没太理解mean, 3bit color什么意思,这里直接放了原文):
- predicting only the mean, 3bit color (i.e., 1 prediction of 512 colors)
- predicting a 4 × 4 downsized version of the 16 × 16 patch with 3bit colors in parallel (i.e., 16 predictions of 512 colors)
- regression on the full patch using L2 (i.e., 256 regressions on the 3 RGB channels)
wramup是针对学习率优化的一种方式,warmup是在ResNet中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoch之后,再修改为预先设置的学习率来进行训练。
warmup的使用通常有两个原因:1)在实际中,由于训练刚开始时,训练数据计算出的梯度可能与期望方向相反,所以此时采用较小的学习率,随着迭代次数增加,学习率线性增大,增长率通常为$\frac{1}{warmup\_ steps}$,迭代次数等于warmup_steps时,学习率为初始设定的学习率。2)由于刚开始训练时,模型的权重是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择warmup预热学习率的方式,可以使得开始训练的几个epoch内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
通常会把warmup和cosine learning rate decay一起使用会达到更好的效果。
我们发现这几种方法都还不错,方法3会稍微差一点点。我们展示了方法1的最终结果,因为方法1的few-shot性能最好。如果我们将处理的patch比例从50%降到15%,few-shot的结果会稍微变差一点。
最后,我们想指出的是,masked patch prediction不需要大量的预训练,也不需要像JFT这样的大型数据集,即使这样,也能在ImageNet分类任务上获得类似的性能提升(这里的比较对象是有监督的预训练)。不管是自监督预训练还是有监督的预训练,在超过100k个预训练step后,性能提升逐渐饱和。
6.C.ADDITIONAL RESULTS
本部分列出了更详细的结果。表5对应Fig3,展示了不同的ViT变体在逐渐增大的预训练数据集上预训练后的迁移学习能力。
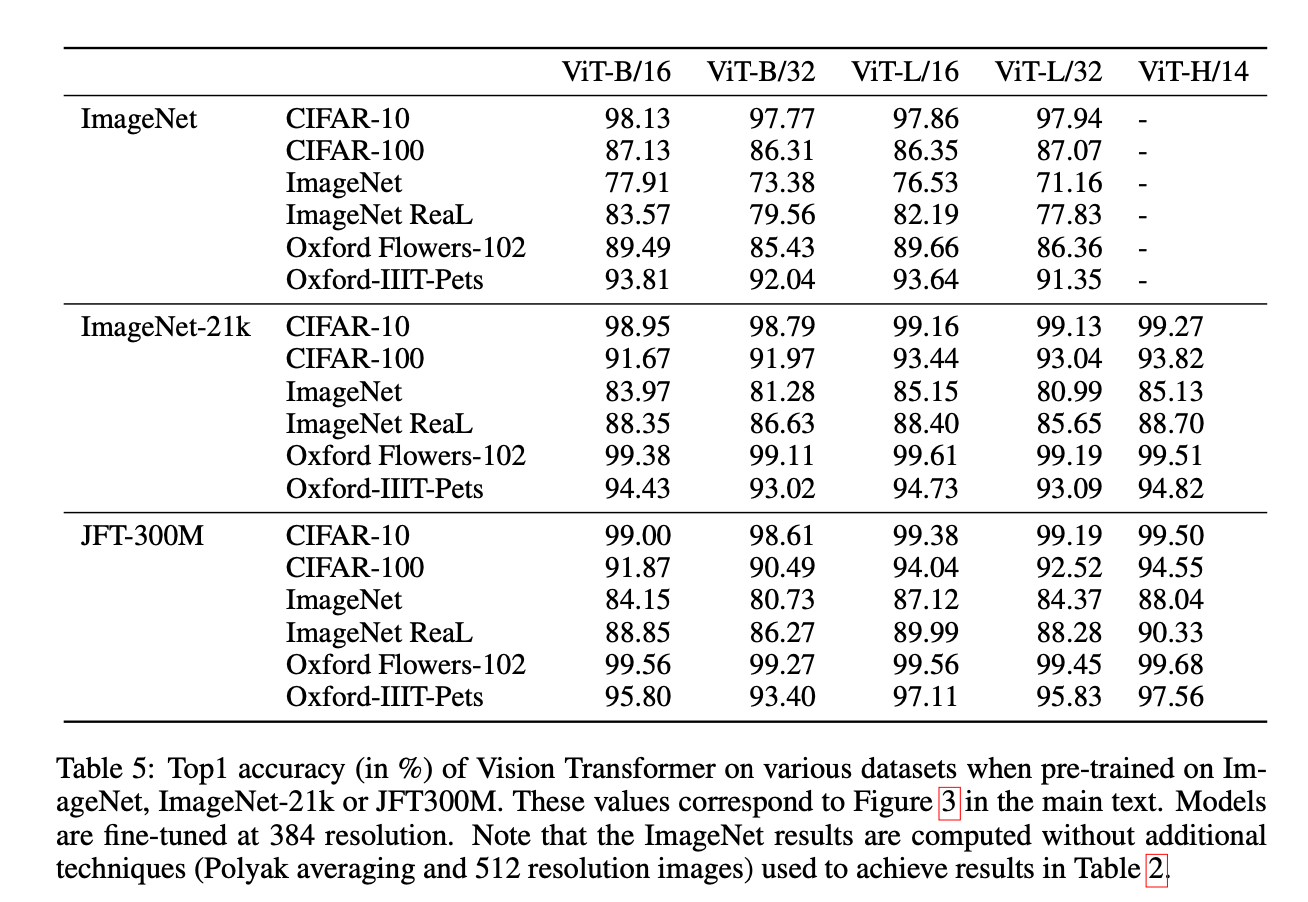
表5列出的都是top1准确率。模型都是在384分辨率上进行fine-tune的。请注意,这里的ImageNet结果和表2的不太一样,因为这里没有使用平均随机梯度下降算法和512分辨率。
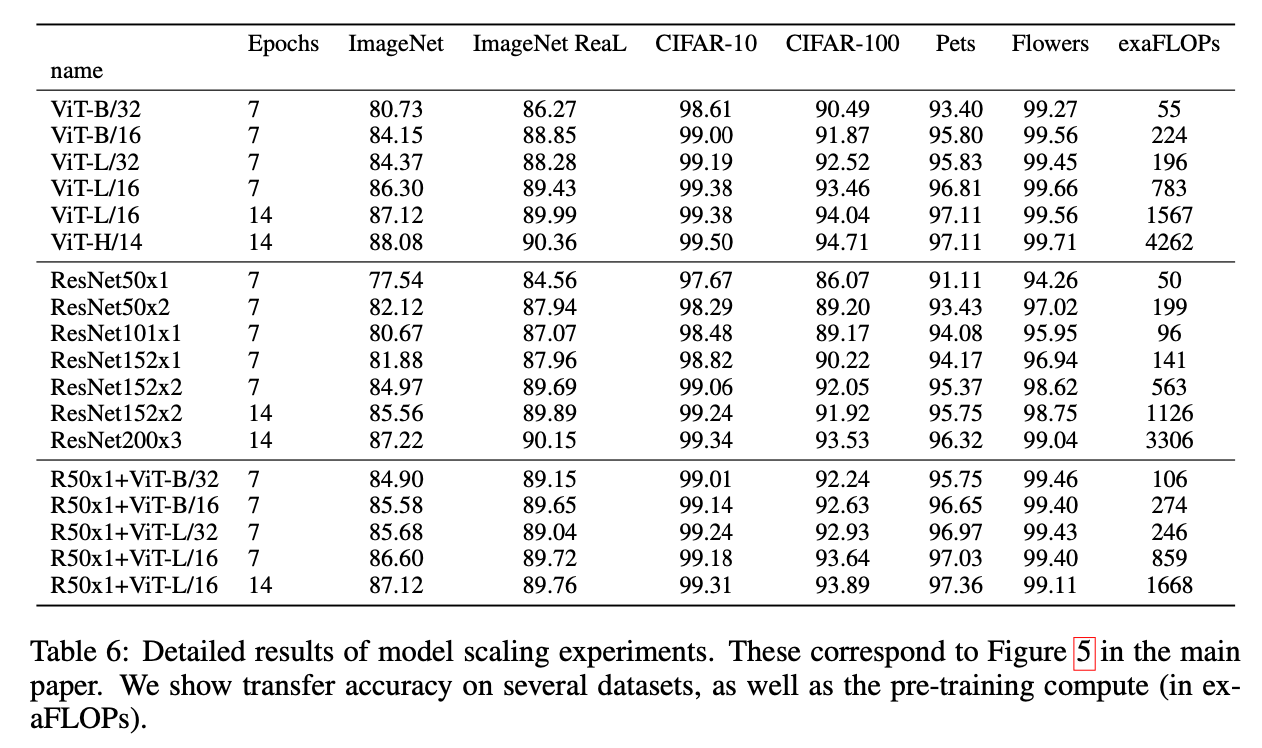
表6对应Fig5,展示了不同大小的ViT,ResNet和混合模型的迁移学习性能以及其计算成本。
6.D.ADDITIONAL ANALYSES
6.D.1.SGD VS. ADAM FOR RESNETS
ResNets使用SGD进行训练,而我们使用Adam算法。我们接下来的实验结果说明了我们做这一选择的原因。我们在JFT数据集上分别使用SGD和Adam算法预训练了ResNets-50x1和ResNets-152x2,然后在目标数据集上进行fine-tune。对于SGD,我们使用和BiT中一样的超参数。实验结果见表7。
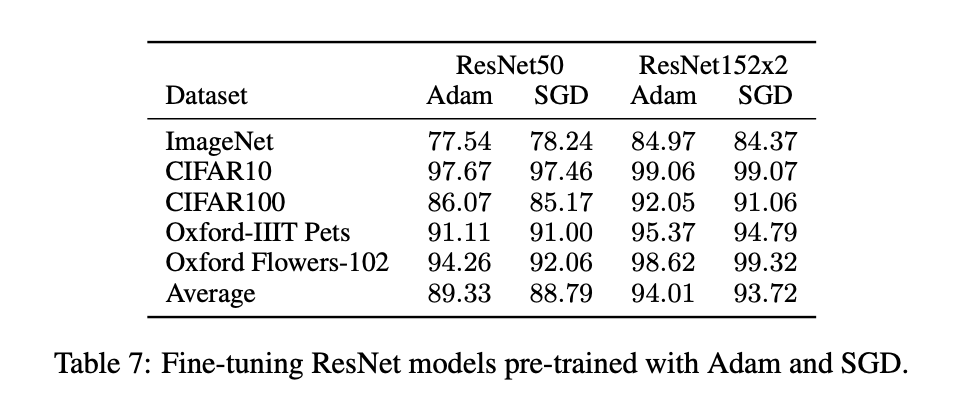
在多数目标数据集上,以及从平均结果来看,使用Adam算法预训练的性能要优于用SGD预训练的性能。需要注意的是,我们测试结果的绝对数值可能比BiT原文中要低一点,那是因为我们只训练了7个epoch,而不是30个。
6.D.2.TRANSFORMER SHAPE
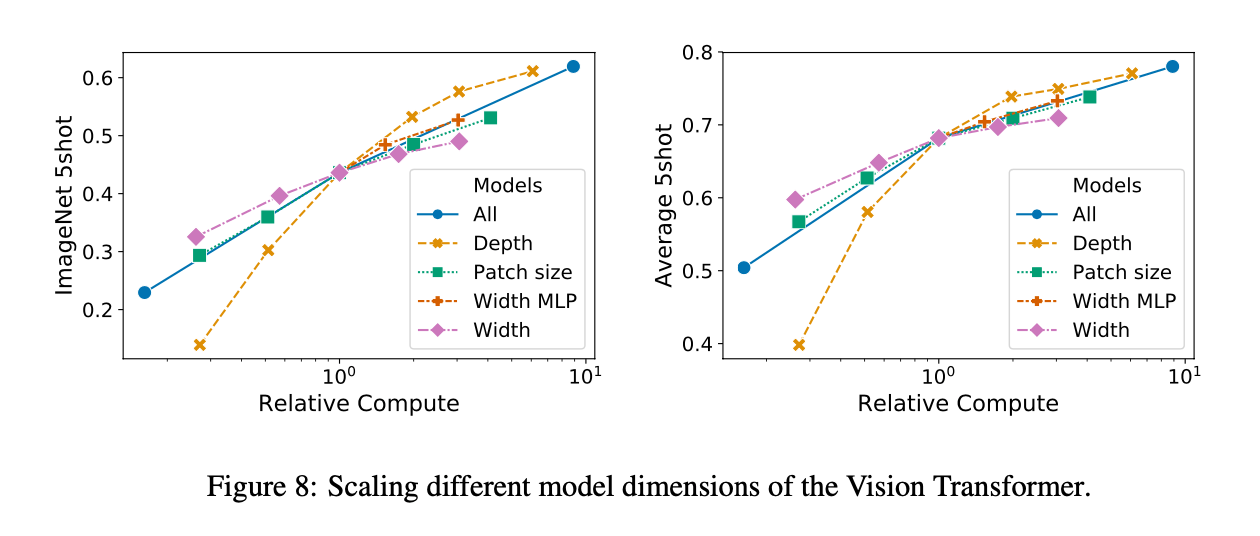
我们还测试了不同大小的ViT变体。Fig8展示了在ImageNet上,不同模型配置的5-shot性能。Fig8中所有线的交点处的模型配置为8 layers,D=1024,$D_{MLP}=2048$,patch size=32。我们可以从Fig8中看出,depth(即layer数目)对模型性能的影响最大,当layer数目甚至达到64后,模型性能还在改进。但是,当layer数目大于16之后,通过增加layer来提升性能这一措施的性价比就不高了,因为提升趋势开始变缓。此外,width(即$D$和$D_{MLP}$)对模型性能的影响最小。减小patch size,从而增加有效序列长度(即patch个数变多,或者说token个数变多),在不改变其他参数的情况下,模型性能稳步提升(这里注意一下Fig8的横轴是计算成本)。这些发现表明,更大的模型的性能会更好,并且depth的重要性高于width。
6.D.3.HEAD TYPE AND CLASS TOKEN
为了尽可能的接近原始的Transformer,我们添加了一个额外的[class] token。该token的输出(指的是通过Transformer部分得到的输出)通过一个小的MLP(multi-layer perceptron,实际就只有一层,激活函数为tanh)后用于类别预测。
但其实最开始的设计不是这样的,最开始的设计思路是没有[class] token,只使用patch embedding,然后将通过Transformer部分的所有输出做一个globally average-pooling(GAP),最后再接一个线性分类器(就像ResNet中最后的feature map一样),但是我们发现这种方式效果很差。令人意外的是,效果差的原因既不是缺少[class] token,也不是GAP机制。根本原因是性能上的差异完全可以用不同的学习率来解释,见Fig9。

个人理解,从Fig9来看,不用[class] token也完全可以,只要调整好GAP方法的学习率就行。
6.D.4.POSITIONAL EMBEDDING
我们尝试了不同的空间信息编码方式:
- 不考虑空间位置信息。
- 1D的positional embedding:将patch看作是一个序列,本文的默认方法,不再赘述。
- 2D的positional embedding:个人理解这里是将1D的positional embedding分成两部分,每部分的size都是$\frac{D}{2}$,前半部分代表X-embedding,后半部分代表Y-embedding。整个positional embedding依然是可学习的。
-
相对的positional embedding:使用patch之间的相对位置信息来编码空间信息,而不是使用patch的绝对位置。为此,我们使用了1D的相对注意力(Relative Attention),我们定义了所有可能的patch对之间的相对距离。原文中对Relative Attention这部分的解释没太看懂,个人理解就是对原来Transformer中的注意力机制做了一些手脚,将其改为:
\[Attention(Q,K,V)=softmax\left( \frac{Q(Q-K)^T}{\sqrt{d_k}} \right)V\]如有不同意见,欢迎留言一起讨论。
除了比较空间信息的不同编码方式,我们还尝试了多种将空间位置编码嵌入模型的方法。对于1D和2D的positional embedding,我们尝试了以下三种方法:
- 和本文默认方式一样,在进入Transformer encoder之前,直接加在patch embedding上。
- 加在每个layer(即encoder block)的输入上。此时,positional embedding是可以被更新学习的。
- 同样是加在每个layer的输入上,但是positional embedding是已经学好的,不需要再被更新学习了。

个人理解:表8中的“Every Layer”表示的是每个layer学习自己的positional embedding;“Every Layer-Shared”表示的是layer之间共享positional embedding。也就是说,表8的第一列是方法1,第二列是方法2,第三列是方法3。
表8是这次消融实验的结果(基于ViT-B/16模型)。从表8中可以看到,不使用positional embedding和使用positional embedding之间的差异比较大,至于使用哪种方式的positional embedding,其实差异并不大。因为我们的Transformer encoder操作的是patch级别的输入,而不是像素级别的,因此我们推测不同方式的positional embedding对模型性能的影响不大。更准确地说,patch级别的输入维度(比如$14\times 14$)比像素级别的输入维度(比如$224 \times 224$)小的多,所以对于任意一种positional embedding方式,都能很容易的在如此小的分辨率下学到空间关系。即使如此,网络学习到的positional embedding的相似性仍取决于训练的超参数(见Fig10)。
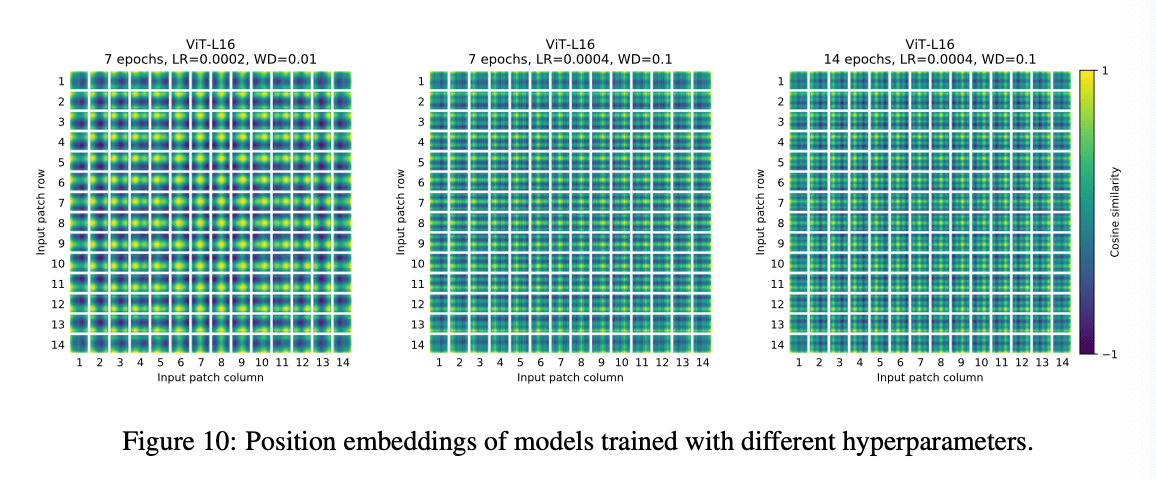
个人理解:从Fig10中可以看出,超参数确实对positional embedding的学习质量影响比较大。
6.D.5.EMPIRICAL COMPUTATIONAL COSTS
我们还在TPUv3上测试了推理速度。
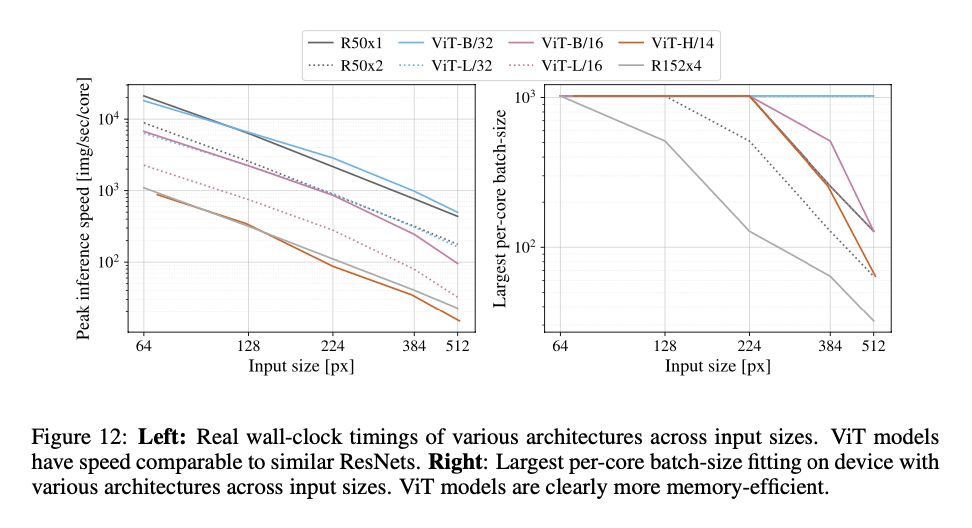
Fig12的左图表示一个核一秒可以处理的图像张数,横轴为不同的输入尺寸。纵轴是在各种batch size中测量的峰值性能。
另一个值得关注的问题是一个核可容纳的最大的batch size,越大的batch size有利于将模型扩展到更大的数据集。Fig12的右图是同一组模型的测试结果。这表明大型ViT模型在内存效率方面明显优于ResNet模型。
6.D.6.AXIAL ATTENTION
轴向注意力(Axial Attention)是一个简单、有效的在大尺寸输入(可视为多维tensor)上测试自注意力的一种技术。其主要思想是每次只沿着input tensor的一个轴做注意力(相当于每个轴都要做一次注意力),而不是像之前将input的维度拍扁为1维然后做一次注意力。对于轴向注意力机制来说,每次的注意力只关注一个维度,和其他维度是互相独立的。沿着这一思路,论文“Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. arXiv preprint arXiv:2003.07853, 2020b.”提出了AxialResNet模型,所有$3\times 3$的卷积都被轴向注意力所代替,并通过positional embedding加以增强。我们测试了AxialResNet的baseline model。
关于轴向注意力,作者引用了两篇论文:
- Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Humphrey Shi, Wenyu Liu, and Thomas S. Huang. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, 2020.
- Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidi- mensional transformers. arXiv, 2019.
我们测试的AxialResNet baseline model是基于PyTorch的开源实现:https://github.com/csrhddlam/axial-deeplab。在实验中,我们重现了原文的准确率,但是其在TPU上的速度非常慢。所以我们无法将其用于大规模实验。
此外,我们还修改了ViT使其可以接受2D的输入(代替了1D的patch embedding),加入了轴向注意力block(代替了自注意力+一个MLP的结构),变为行自注意力(row-self-attention)+一个MLP后接一个列自注意力(column-self-attention)+一个MLP。
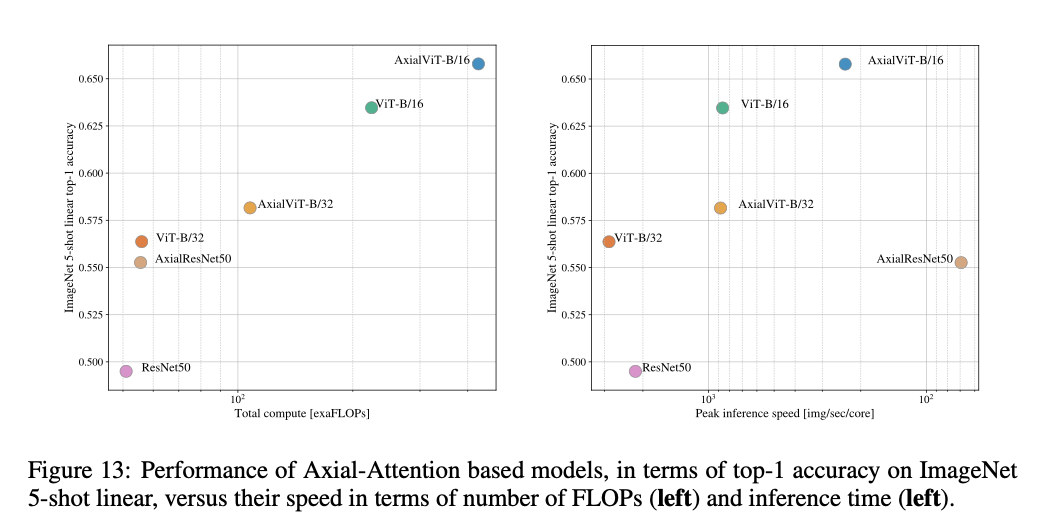
Fig13展示了经过JFT预训练后,AxialResNet、Axial-ViT-B/32和Axial-ViT-B/16在ImageNet上的5-shot性能,主要对比了计算成本和推理速度。从Fig13中我们可以看出,虽然Axial-ViT-B/32和Axial-ViT-B/16的性能都要优于各自对应的ViT-B/32和ViT-B/16,但是计算成本也更高。这是因为在Axial-ViT模型中,每个带有全局自注意力的Transformer block被替换成了两个Axial Transformer block(一个是行自注意力,一个是列自注意力),尽管在轴向情况下,序列的长度会更短,但是每个Axial-ViT block之后还有一个额外的MLP。至于AxialResNet,虽然看起来其在精度和计算成本之间有着不错的trade-off(见Fig13左),但是其在TPU上的推理速度却很慢(见Fig13右)。
6.D.7.ATTENTION DISTANCE
为了理解ViT是怎么利用自注意力学习整幅图像的信息的,和Fig7最右图一样,我们展示了Fig11(Fig7的最右图和Fig11的左图是一样的)。分析和第4.5部分一样,不再赘述。
6.D.8.ATTENTION MAPS
作者得到Fig6(即所谓的attention map)的方法是Attention Rollout,引自论文:“Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. In ACL, 2020.”。作者在Fig14中列出了更多的例子。

6.D.9.OBJECTNET RESULTS
我们根据BiT中提出的评估设置,我们测试了ViT-H/14在ObjectNet benchmark上的表现,最终结果为82.1%的top-5准确率和61.7%的top-1准确率。
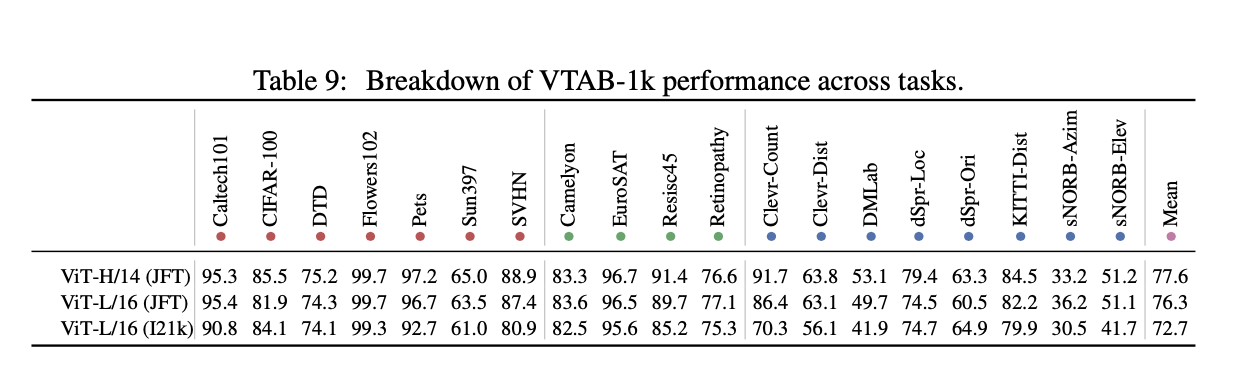
6.D.10.VTAB BREAKDOWN
表9展示了ViT在VTAB-1k任务上的表现。
7.原文链接
👽AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
