本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
github官方repo:https://github.com/ViTAE-Transformer/ViTPose。
人体姿态估计是计算机视觉领域一个重要的任务类型,并且其在真实世界中有着广泛的应用场景。人体姿态估计任务的目标是定位人体解剖关节点,但由于各种形式的遮挡、截断、缩放以及不同的人物外观,而导致这项任务充满挑战。为了解决这些问题,基于深度学习的方法已经取得了迅速的进展,这些方法通常使用的都是CNN框架。
近期,ViT在多个视觉任务中都展现出了很强的潜力。受其成功的启发,各种不同的ViT框架被部署用于姿态估计任务。这些方法大多采用CNN作为backbone,然后使用Transformer来refine提取到的特征,最后对关节点之间的关系进行建模。比如,PRTR结合了Transformer的encoder和decoder,以级联的方式逐步细化估计关节点的位置。TokenPose和TransPose则仅用了Transformer的encoder来处理CNN提取到的特征。此外,HRFormer直接使用Transformer提取特征,并通过多分辨率并行的Transformer模块来获取高分辨率的representation。以上这些方法都在姿态估计任务中获得了非常不错的成绩。然而,这些方法要么需要额外的CNN用于特征提取,要么需要仔细搭建Transformer框架以适应任务。这就使得我们在考虑一个问题,最原始、最朴素的ViT,能在姿态估计任务中表现如何?
PRTR原文:K. Li, S. Wang, X. Zhang, Y. Xu, W. Xu, and Z. Tu. Pose recognition with cascade transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1944–1953, June 2021.。
TokenPose原文:Y. Li, S. Zhang, Z. Wang, S. Yang, W. Yang, S.-T. Xia, and E. Zhou. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.。
TransPose原文:S. Yang, Z. Quan, M. Nie, and W. Yang. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.。
HRFormer原文:Y.Yuan, R.Fu, L.Huang, W.Lin, C.Zhang, X.Chen, and J.Wang. Hrformer : High-resolution transformer for dense prediction. In Advances in Neural Information Processing Systems, 2021.。
为了回答这个问题,我们提出了ViTPose模型,并在MS COCO Keypoint数据集上验证了其性能。具体来说,ViTPose使用纯粹的ViT作为backbone直接提取特征,并且backbone是经过pre-trained的(pre-train的方法:pre-trained with masked image modeling pretext tasks,比如MAE)。然后,一个轻量级的decoder用于处理提取到的特征。尽管ViTPose没有在模型框架上花费太多心思,但是其依然在MS COCO Keypoint test-dev set上取得了SOTA的成绩(80.9的AP)。也就是说,即使是简单朴素的Transformer模型,也可以在姿态估计中取得很好的成绩。
MAE原文:K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16000–16009, 2022.。
除了性能上的优势,我们还展示了ViTPose在以下4个方面的优秀表现:
👉1)simplicity
得益于ViT强大的feature representation ability,ViTPose的框架相当简单。例如,它不需要特定的领域知识来精心的设计backbone。这种简单的结构使得ViTPose具有良好的并行性,从而在推理速度和性能方面达到了新的Pareto front,详见Fig1。
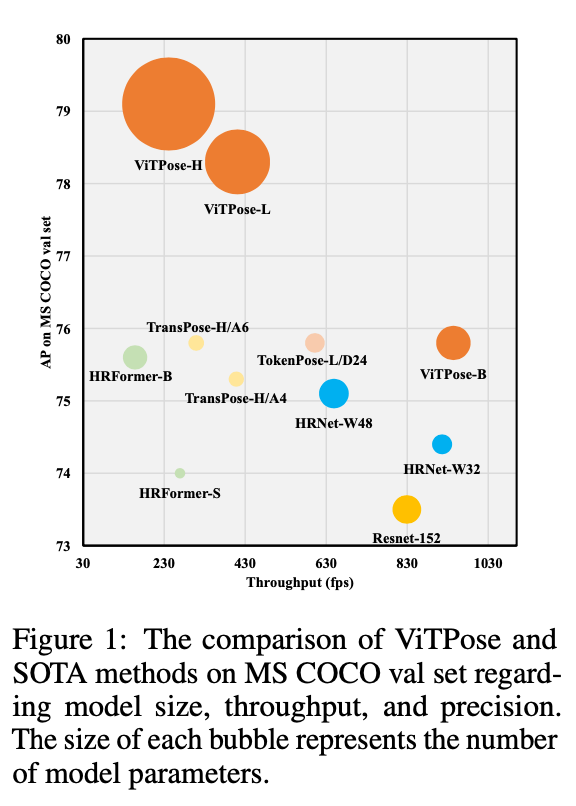
Fig1中,bubble的大小代表模型的参数数量。
👉2)scalability
此外,结构的simplicity给ViTPose带来了优异的scalability。这里的scalability指的是可以方便的通过transformer layers和feature dimensions来控制模型的大小,比如,使用ViT-B、ViT-L或ViT-H来平衡推理速度和性能。
👉3)flexibility
此外,我们还证明了ViTPose在训练中的灵活性。ViTPose只需稍作修改,便可以很好的适应不同的input resolutions和feature resolutions,并且对于高分辨率的输入,ViTPose始终可以提供更准确的姿态估计结果。除了在单个数据集上进行训练,我们还可以通过添加额外的decoder使得ViTPose可以在多个数据集上联合训练,这能带来显著的性能提升。因为decoder是非常轻量级的,所以这种训练模式所带来的额外计算成本并不多。当我们使用更小的无标签数据集进行预训练或者在fine-tune的时候冻结attention modules,ViTPose仍然可以取得SOTA的成绩,并且相比fully pre-trained finetuning,这样做的训练成本更低。
👉4)transferability
通过一个额外的learnable knowledge token,可以将large ViTPose models学到的knowledge迁移给small ViTPose models,从而提升small ViTPose models的性能。这说明ViTPose有着良好的transferability。
总的来说,本文的贡献有三方面:
- 我们提出了一个简单有效的模型(ViTPose)用于人体姿态估计。在没有精细设计复杂框架的情况下,依然在MS COCO Keypoint数据集上取得了SOTA的成绩。
- 简单的ViTPose模型有着以下令人惊讶的良好能力:structural simplicity、model size scalability、training paradigm flexibility、knowledge transferability。这些能力为基于ViT的人体姿态估计任务提供了一个强壮的baseline,促进了该领域的发展。
- 和流行的benchmark进行了比较,以研究和分析ViTPose的性能。如果使用big vision transformer model作为backbone(比如使用ViTAE-G作为backbone),单个的ViTPose模型可以在MS COCO Keypoint test-dev set上取得最高的80.9的AP。
ViTAE-G原文:Q. Zhang, Y. Xu, J. Zhang, and D. Tao. Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond. arXiv preprint arXiv:2202.10108, 2022.。
2.Related Work
2.1.Vision transformer for pose estimation
姿态估计经历了从CNN到vision transformer networks的快速发展。早期的工作更多的将transformer视为一个好的decoder,例如TransPose将其直接用于处理CNN提取到的特征。TokenPose通过额外的tokens来实现token-based representations,从而估计被遮挡关节点的位置,并且针对不同关节点之间的关系进行建模。为了不再使用CNN提取特征,HRFormer直接用transformers提取高分辨率的特征。这些基于transformer的姿态估计方法都在流行的keypoint estimation benchmarks上取得了优异的成绩。但是,这些方法要么需要CNN提取特征,要么需要仔细设计transformer的框架结构。它们并没有深入探索plain vision transformers在姿态估计任务中的潜力。在本文中,我们提出了基于plain vision transformers的ViTPose,填补了这一研究的空白。
2.2.Vision transformer pre-training
受到ViT成功的启发,大量不同的vision transformer backbones被提出,它们通常使用ImageNet-1K数据集进行有监督的训练。最近,自监督学习被提出用于plain vision transformers的训练。在本文中,我们专注于姿态估计任务,使用plain vision transformers作为backbones,并采用masked image modeling(MIM,个人理解:MIM和ViT中的自监督训练类似)的方法来预训练backbones。此外,我们还探讨了对于姿态估计任务,是否有必要使用ImageNet-1K进行预训练。令人惊讶的是,我们发现使用小型无标签的pose datasets进行预训练依然可以为姿态估计任务提供good initialization。
3.ViTPose
3.1.The simplicity of ViTPose
👉Structure simplicity.
本文的目标是:1)为姿态估计任务提供一个简单且有效的vision transformer baseline;2)探索plain and non-hierarchical vision transformers的潜力。因此,我们的模型结构会尽可能的简单,尽量不使用一些花哨复杂的模块,尽管这些模块可能会带来性能上的提升。我们仅仅是在transformer backbone后面添加了几个decoder layers,用以计算heatmap,从而进一步得到关节点,见Fig2(a)。为了简单化,我们在decoder layers中没有使用skip-connections或cross-attentions,只是使用了简单的反卷积层和一个预测层。具体来说,输入是一张person instance image(表示为$X \in \mathcal{R} ^ {\mathcal{H} \times \mathcal{W} \times 3}$),首先将原始图像划分为$d \times d$个patch($d$默认为16),每个patch经过patch embedding layer后得到一个embedded token(可表示为$F \in \mathcal{R} ^ {\frac{H}{d} \times \frac{W}{d} \times C}$)。随后embedded tokens被多个transformer layers继续处理,每个transformer layer包含一个multi-head self-attention (MHSA) layer和一个feed-forward network (FFN),即:
\[F'_{i+1} = F_i + \text{MHSA} ( \text{LN} (F_i)), F_{i+1} = F'_{i+1} + \text{FFN} ( \text{LN} (F'_{i+1})) \tag{1}\]其中,$F_0 = \text{PatchEmbed} (X)$,即patch embedding layer得到的特征。对于每个transformer layer,维度都是固定一样的。所以,backbone的输出维度为$F_{out} \in \mathcal{R} ^ {\frac{H}{d} \times \frac{W}{d} \times C}$。
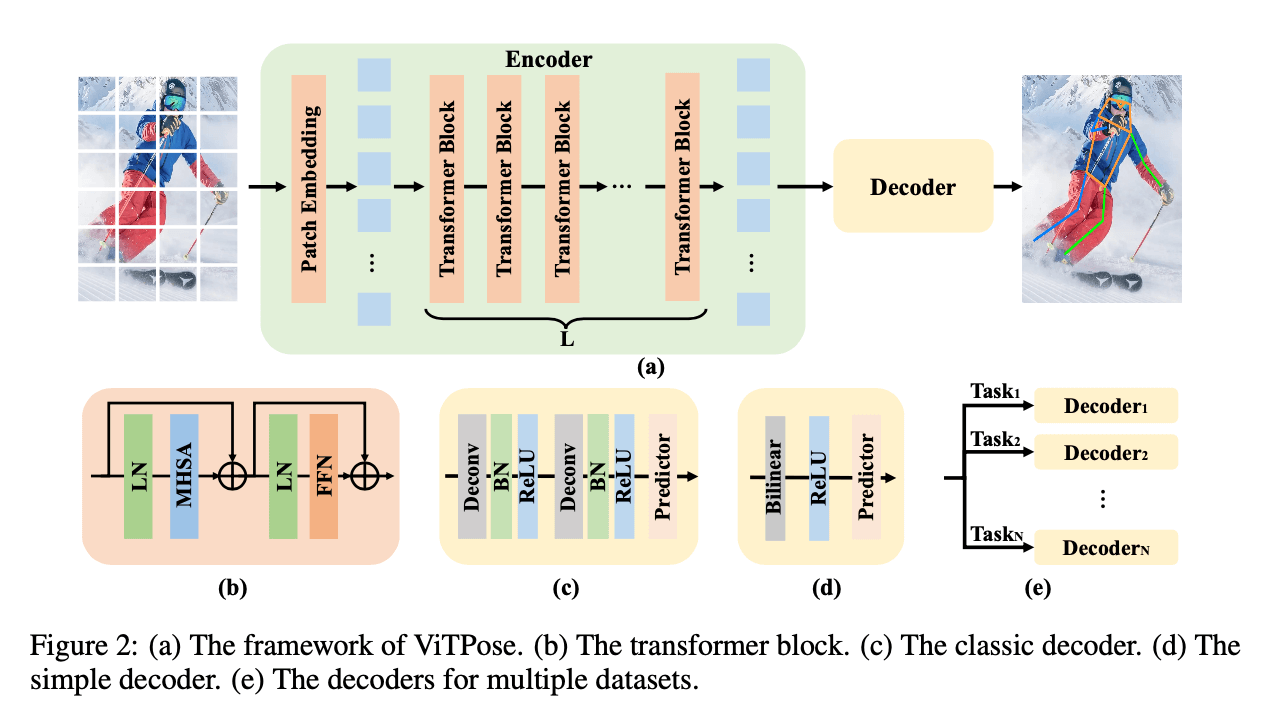
我们采用了两种轻量级的decoder来处理backbone提取到的特征并定位关节点。第一种是classic decoder。它包含两个反卷积blocks,每个block包含一个反卷积层、batch normalization层和ReLU层。每个block将feature map上采样2倍。最后通过一个kernel size为$1\times 1$的卷积层得到用于定位关节点的heatmap,即:
\[K = \text{Conv} _{1\times 1} (\text{Deconv} ( \text{Deconv} (F_{out}) )) \tag{2}\]其中,heatmap可表示为$K \in \mathcal{R} ^ {\frac{H}{4} \times \frac{W}{4} \times N_k}$,$N_k$为关节点的数目,例如对于MS COCO dataset,$N_k=17$。
尽管classic decoder已经足够简单和轻量级了,但我们还是尝试了更简单的decoder,并且得益于vision transformer backbone强大的特征提取能力,这种更简单的decoder效果也不错。具体而言,我们直接通过双线性插值将feature map上采样4倍,然后接一个ReLU,最后通过一个kernel size为$3 \times 3$的卷积层来获得heatmap,即:
\[K = \text{Conv}_{3\times 3} (\text{Bilinear} (\text{ReLU} (F_{out})) ) \tag{3}\]尽管这种decoder的non-linear capacity更小,但是相比classic decoder和其他研究中经过精心设计的transformer-based decoders相比,这种简单的decoder依旧能获得competitive performance。
3.2.The scalability of ViTPose
我们可以通过堆叠不同数量的transformer layers以及增减特征维度来轻易的控制模型的大小。为了研究ViTPose的scalability,我们使用不同大小的pre-trained backbones,并在MS COCO dataset进行finetune。例如,我们分别使用ViT-B,ViT-L,ViT-H和ViTAE-G作为backbone,并搭配classic decoder用于姿态估计,发现随着模型大小的增加,性能一直有稳步提升。对于ViT-H和ViTAE-G,在预训练时设置patch size为$14 \times 14$,而ViT-B和ViT-L使用的patch size为$16 \times 16$(需要使用zero padding以保证same setting)。
3.3.The flexibility of ViTPose
👉Pre-training data flexibility.
为了探索数据的灵活性,除了使用ImageNet进行预训练外,我们还在MS COCO数据集以及MS COCO+AI Challenger的联合数据集上,通过MAE方法对backbones进行预训练,即随机mask掉75%的patches,然后再将它们重建出来。接着在MS COCO dataset上finetune。我们的实验结果证明ViTPose可以从不同大小的数据集中得到良好的预训练结果。
👉Resolution flexibility.
我们通过改变输入图像的大小和下采样比例$d$来测试ViTPose在输入分辨率和特征分辨率上的灵活性。具体来说,为了使ViTPose支持更高分辨率的输入图像,我们只需调整输入图像的大小并相应地训练模型。此外,为了使模型支持更低的下采样比例,即更高的特征分辨率,我们只是简单的更改了patch embedding layer的stride并保持每个patch的size,也就是说,之前的patch划分是没有重叠的,这样操作之后相邻的patch之间是存在重叠部分的。我们的实验结果表明,无论是更高的输入分辨率还是更高的特征分辨率,ViTPose的性能都会持续提高。
👉Attention type flexibility.
在高分辨率feature map上使用完整的注意力机制会导致巨大的内存占用和计算成本。因此我们使用window-based attention with relative position embedding来解决这个问题。但是如果所有的transformer blocks都使用这种方法的话会导致性能的下降,因为丧失了全局信息的缘故。为了解决这个问题,我们采用了两种方案:
- Shift window
- 之前的window-based attention使用的是一个fixed windows用于注意力计算,而现在我们改用shift-window机制(引自Swin-Transformer)来帮助传递相邻windows的信息。
- Pooling window
- 除了shift-window机制,我们还尝试了另一种解决方案。具体来说,就是对每个window内的tokens进行pooling操作以获得global context feature。这些特征会被喂入每个window当作key tokens和value tokens,以此来获得cross-window feature communication(这里不太理解,key tokens和value tokens不应该是学出来的吗?)。
最后,我们证明了这两种方案是互补的,可以一起被用来提升性能并降低内存占用,并且不需要额外的参数和模块,只需要对注意力计算做一些简单的修改。
window-based attention with relative position embedding相关的两篇论文:
Y. Li, H. Mao, R. Girshick, and K. He. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.。
Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.。
👉Finetuning flexibility.
我们分别用3种方式在MS COCO数据集上finetune了ViTPose:1)all parameters unfrozen;2)MHSA modules frozen;3)FFN modules frozen。我们的实验表明,方式2取得了和方式1不相上下的性能表现。
👉Task flexibility.
由于ViTPose的decoder是简单且轻量级的,因此在共用同一个backbone encoder的情况下,我们不需要过多额外的成本就可以使用多个decoders来处理多个不同的姿态估计数据集。对于每次迭代,我们从多个训练数据集中随机采样。
3.4.The transferability of ViTPose
提升小模型性能的一个常用方法就是将大模型的knowledge迁移过来,比如knowledge distillation。假设有teacher network $T$和student network $S$,一个简单的distillation方法是添加一个distillation loss $L_{t \to s}^{od}$来促使student network的输出去模仿teacher network的输出,即:
\[L_{t \to s}^{od} = \text{MSE}(K_s, K_t) \tag{4}\]给定同一输入,$K_s,K_t$分别为student network和teacher network的输出。
knowledge distillation相关论文:
G. Hinton, O. Vinyals, J. Dean, et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2(7), 2015.。
J. Gou, B. Yu, S. J. Maybank, and D. Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129(6):1789-1819, 2021.。
通过对上述方法进行进一步的完善,我们提出了token-based distillation方法。具体做法是,对于teacher model,我们随机初始化一个额外的learnable knowledge token $t$,然后在patch embedding layer后将其添加到visual tokens。之后,我们冻结训练好的teacher model,只对knowledge token进行微调,微调会持续几个epochs来获得knowledge,即:
\[t^* = \arg \min \limits_{t} (\text{MSE} (T(\{t;X\}), K_{gt}) ) \tag{5}\]其中,$K_{gt}$为ground truth heatmaps,$X$为输入图像,$T(\{ t;X \})$为teacher model的预测输出,$t^*$为最小化loss得到的最优knowledge token。在这之后,knowledge token $t^*$会和student network的visual tokens concat在一起参与student network的训练,并且在此期间knowledge token $t^*$是被冻结的状态,即不再改变,这样就可以把teacher network的knowledge传递给student network了。因此,student network的loss可表示为:
\[L_{t \to s}^{td} = \text{MSE}(S(\{t^*;X \}), K_{gt} ) \tag{6}\]或
\[L_{t \to s}^{tod} = \text{MSE}(S( \{t^*;X \}),K_t ) + \text{MSE}(S( \{t^*;X \}),K_{gt} ) \tag{6}\]$L_{t \to s}^{td}$表示的是token distillation loss,$L_{t \to s}^{tod}$表示的是output distillation loss和token distillation loss的联合。
4.Experiments
4.1.Implementation details
ViTPose遵循人体姿态估计中常见的top-down setting,即detector用于检测person instances,ViTPose用于检测instances的关节点。我们分别使用ViT-B,ViT-L,ViT-H作为backbones,并将相应的模型表示为ViTPose-B,ViTPose-L,ViTPose-H。模型基于mmpose codebase,在8块A100 GPU上进行训练。使用MAE对backbones进行预训练。使用mmpose中的默认训练设置来训练ViTPose模型,即,输入分辨率为$256 \times 192$,AdamW optimizer(学习率为5e-4)。Udp被用于后处理。模型一共训练了210个epochs,其中在第170和200个epoch时学习率衰减10倍。此外,我们还对每个模型都使用了layer-wise learning rate decay(一种对学习率逐层修正的策略)和drop path(将深度学习网络中的多分支结构随机删除的一种正则化方法)。经过我们的实验,在表1中列出了最优的参数设置:
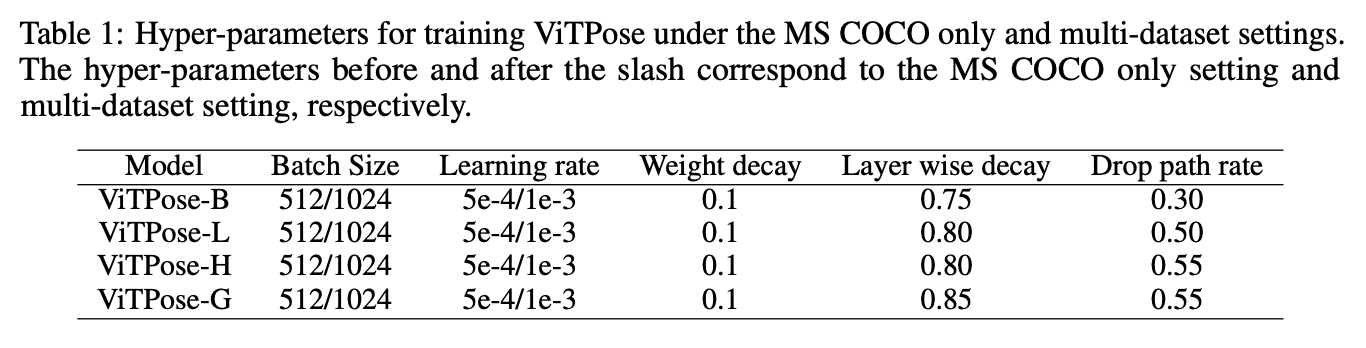
表1中列出了训练ViTPose的最优超参数,其中,斜杠前的参数表示仅在MS COCO数据集上训练,斜杠后的参数表示在multi-dataset上训练。
mmpose codebase:M. Contributors. Openmmlab pose estimation toolbox and benchmark. https://github.com/open-mmlab/mmpose, 2020.。
Udp:J. Huang, Z. Zhu, F. Guo, and G. Huang. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.。
layer-wise learning rate decay:Z.Yang, Z.Dai, Y.Yang, J.Carbonell, R.R.Salakhutdinov, and Q.V.Le. Xlnet : Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32, 2019.。
4.2.Ablation study and analysis
👉The structure simplicity and scalability.
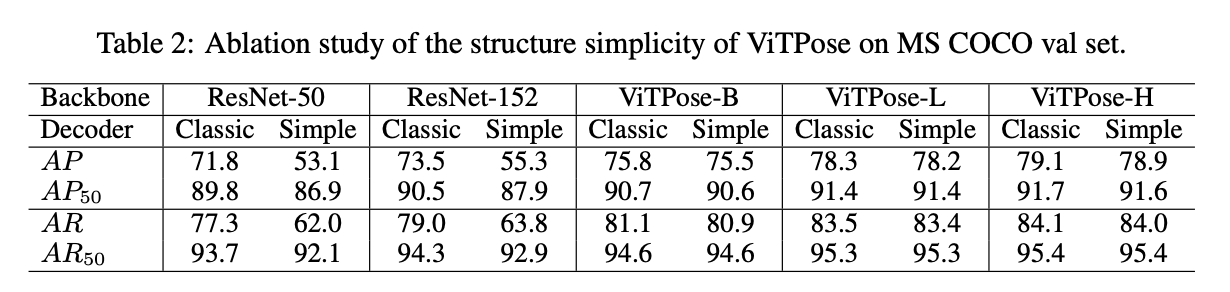
我们分别使用第3.1部分提到的classic decoder和simple decoder来训练ViTPose。作为比较,我们还训练了使用ResNet作为backbones的SimpleBaseline,并且也分别搭配两种不同的decoders。结果见表2。从表2中可以看出,对于ResNet-50和ResNet-152来说,相比classic decoder,使用simple decoder会导致AP降低18个点左右。然而对于ViTPose来说,相比classic decoder,使用simple decoder只会导致AP降低0.3个点左右。对于指标$\text{AP}_{50}$和$\text{AR}_{50}$,无论使用哪种decoder,ViTPose的表现都差不多,这说明plain vision transformer有着很强的representation能力,并且复杂的decoder不是必须的。此外,从表2中还可以得出结论,ViTPose的性能随着模型大小的增加而不断提升,这也证明了ViTPose有着良好的scalability。
👉The influence of pre-training data.
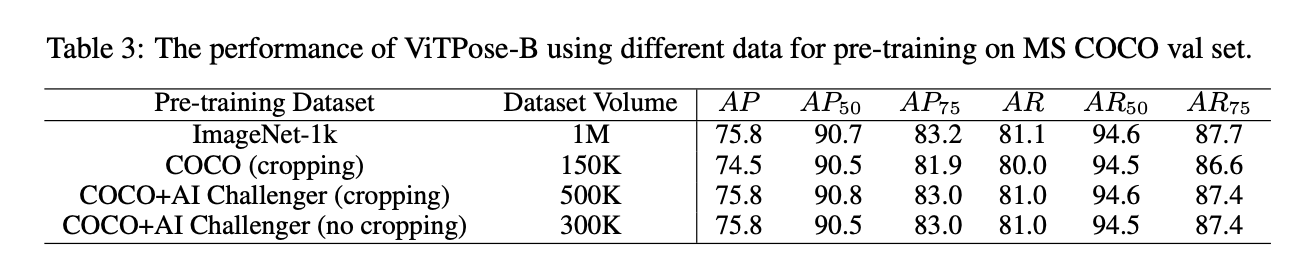
为了评估ImageNet-1K数据集对于姿态估计任务是否是必要的,我们使用不同的数据集对backbone进行了预训练,比如:ImageNet-1K,MS COCO以及MS COCO和AI Challenger的联合数据集。为了和ImageNet-1K数据集类似,我们将MS COCO和AI Challenger中的图像裁剪得到person instances,用作预训练的数据集。模型在这三个数据集上都分别预训练了1600个epoch,然后在MS COCO数据集上finetune了210个epoch。结果见表3。可以看到,使用MS COCO和AI Challenger联合数据集进行预训练的结果和使用ImageNet-1k差不多。但是其数据量只是ImageNet-1k的一半左右。这验证了ViTPose在预训练数据方面的flexibility。然而,如果仅使用MS COCO数据集进行预训练会导致AP下降1.3个点左右。这可能是因为MS COCO数据集的数据量过小,MS COCO中的instances数量比MS COCO和AI Challenger联合数据集少了大约3倍。此外,如果使用MS COCO和AI Challenger联合数据集进行预训练,无论是否裁剪,最终结果都差不多。这些发现验证了以下结论:下游任务本身的数据可以在预训练阶段带来更好的数据效率。
👉The influence of input resolution.
为了评估ViTPose是否可以很好的适应不同的输入分辨率,我们使用不同的输入图像尺寸来训练ViTPose,最终结果见表4。随着输入分辨率的增加,ViTPose-B的性能也一直在提升。此外,我们还注意到,平方输入虽然具有更高的分辨率,但并没有带来太多的性能提升,比如,$256 \times 256$ vs. $256 \times 192$。原因可能是因为MS COCO数据集中human instances的平均长宽比为$4:3$,而平方输入不满足这一统计信息。

👉The influence of attention type.
HRNet和HRFormer提出高分辨率feature maps有利于姿态估计任务。ViTPose可以通过改变patching embedding layer的下采样率(比如从patch size $16 \times 16$到$8\times 8$)来容易地生成高分辨率features。此外,为了缓解由quadratic computational complexity导致的内存不足问题,可以使用第3.3部分提到的Shift window机制(表5中的’Shift’)和Pooling window机制(表5中的’Pool’)。结果见表5。可以看到,使用原始的注意力机制搭配1/8 feature size得到了最高的77.4的AP,但是其内存占用也非常高。window attention可以降低内存占用,但由于缺乏全局上下文建模信息,AP由77.4降低到66.4。Shift window机制和Pooling window机制通过跨窗口信息交换来获得全局上下文建模信息,因此相比单纯的window attention,AP提高了10个点,并且内存占用增加不到10%。如果同时使用这两种机制,AP进一步提升至76.8,这与ViTDet的表现差不多(表5第6行),但是ViTDet是联合使用了full attention和window attention,虽然表现差不多(76.8 AP vs. 76.9 AP),但是前者内存占用更低(22.9G memory vs. 28.6G memory)。通过比较表5的第5行和最后一行,我们注意到可以通过将窗口大小从$8 \times 8$扩大到$16 \times 12$,使性能进一步从76.8 AP提升至77.1 AP,这一结果要优于ViTDet的联合策略。
ViTDet:Y. Li, H. Mao, R. Girshick, and K. He. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.。
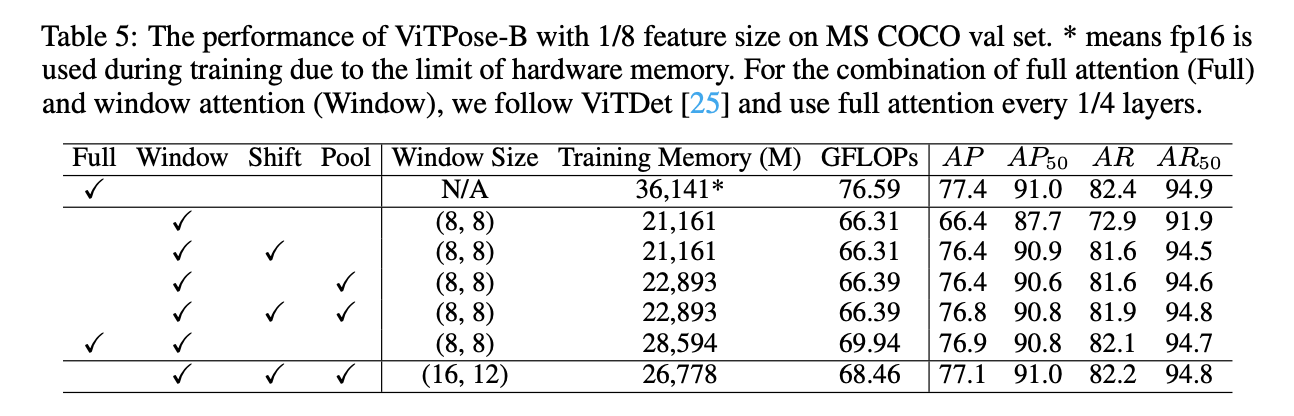
表5是ViTPose搭配1/8 feature size在MS COCO val set上的表现。*表示由于硬件内存限制,在训练时使用了fp16精度。对于full attention(’Full’)和window attention(’Window’)的联合策略,我们遵循ViTDet中的设置。
👉The influence of partially finetuning.
为了评估ViT是否可以通过部分finetune来适应姿态估计任务,我们通过3种不同的方式来finetune ViTPose-B:1)fully finetuning;2)冻结MHSA模块;3)冻结FFN模块。结果见表6,相比fully finetuning,冻结MHSA模块导致了轻微的性能下降(75.1 AP v.s. 75.8 AP),但是这两种方式的$\text{AP}_{50}$差不多。但是如果冻结FFN模块,AP会显著下降3.0个点。这一发现说明ViT的FFN模块会更负责特定任务(task-specific)的建模。相比之下,MHSA模块更具有任务无关性(task-agnostic)。

👉The influence of multi-dataset training.
由于ViTPose的decoder相当简单且轻量级,我们可以通过为每个数据集使用共享的backbone和单独的decoder,从而轻松的将ViTPose扩展到多数据集联合训练。我们使用MS COCO、AI Challenger和MPII来进行多数据集联合训练实验。在MS COCO val set上的实验结果见表7。更多数据集的实验结果见附录。需要注意的是,我们直接使用训练后的模型进行评估,并没有在MS COCO上进一步finetune。从表7中可以看到,随着更多的数据集加入训练,ViTPose的性能也在稳步提升(75.8 AP到77.1 AP)。尽管与MS COCO+AI Challenger的联合数据集相比,MPII数据集的数据量要小很多(40K v.s. 500K),但MPII的加入还是让AP提升了0.1个点,这说明ViTPose可以很好的利用不同数据集中的不同数据。

👉The analysis of transferability.
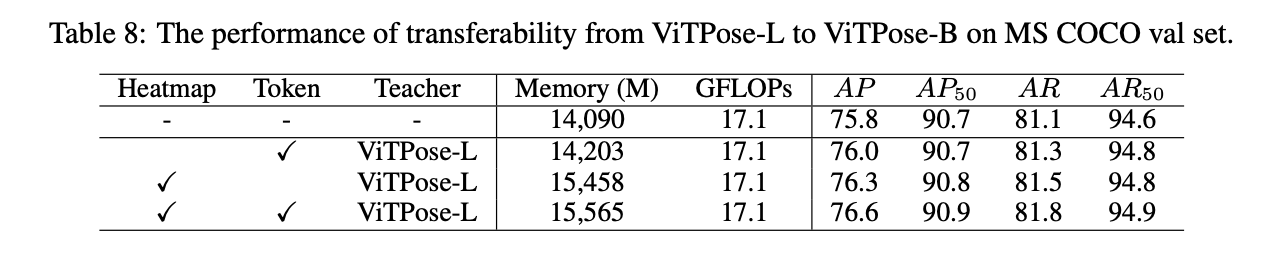
为了评估ViTPose的transferability,我们使用了2种方法来将ViTPose-L的knowledge迁移给ViTPose-B,一种方法是第3.4部分中简单的distillation方法(表8中的’Heatmap’),另一种是我们提出来的token-based distillation方法(表8中的’Token’)。实验结果见表8。从表8中可以看到,token-based distillation方法给ViTPose-B带来了0.2 AP的提升,并且内存占用没有增加很多,而简单的distillation方法带来了0.5 AP的增长。此外,这两种方法是互补的,可以一起使用,最终得到76.6的AP,这些结果说明了ViTPose具有优秀的transferability。
4.3.Comparison with SOTA methods
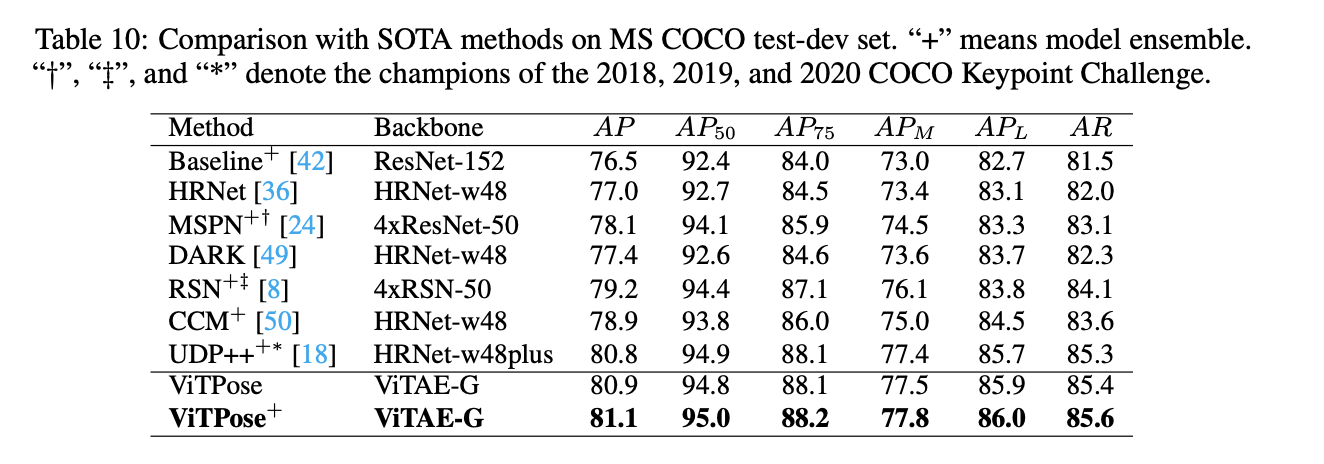
基于先前的分析,我们使用$256 \times 192$的输入分辨率,进行多数据集联合训练,并在MS COCO val and test-dev set上进行验证,结果见表9和表10。所有方法的速度测试都基于单块A100 GPU,batch size=64。从结果中可以看出,尽管ViTPose的模型很大,但它在throughput和accuracy之间有着很好的trade-off,这表明plain vision transformer有着很强的representation能力,并且对硬件友好。此外,backbone越大,ViTPose的性能越好。比如,ViTPose-L的表现要比ViTPose-B好(78.3 AP v.s. 75.8 AP,83.5 AR v.s. 81.1 AR)。ViTPose-L的表现优于之前SOTA的CNN模型和transformer模型。在仅使用MS COCO数据集用于训练的情况下,ViTPose-H的性能和推理速度均优于HRFormer-B(79.1 AP v.s. 75.6 AP,241 fps v.s. 158 fps)。相比HRFormer-B,ViTPose具有更快的推理速度,因为其结构仅包含一个branch,并且在相对较小的feature分辨率上操作(1/4 v.s. 1/16)。如果使用多数据集联合训练,ViTPose的性能得到进一步的提升,这意味着ViTPose有着良好的scalability和flexibility。
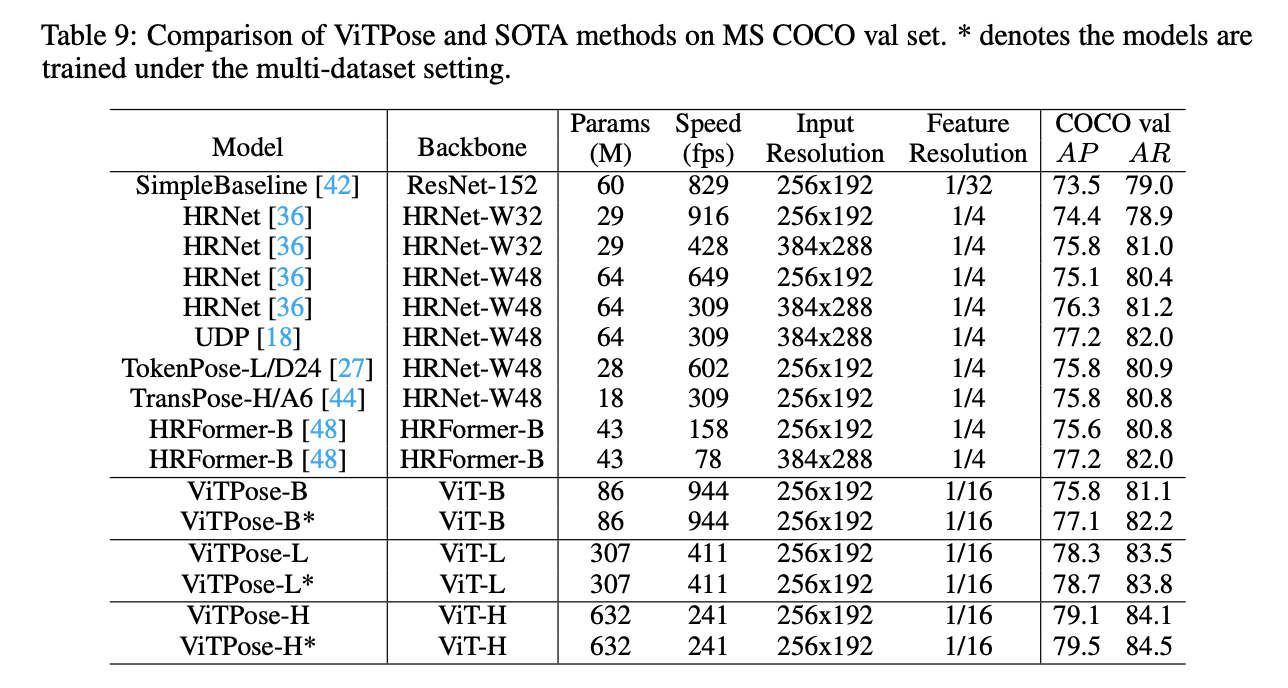
表9是在MS COCO val set上,ViTPose和SOTA方法的比较结果。*表示多数据集联合训练。
此外,我们还构建了一个更强壮的模型ViTPose-G,即使用ViTAE-G作为backbone,参数量达到了1B,有着更大的输入分辨率($576 \times 432$),在MS COCO+AI Challenger联合数据集上进行训练。和其他SOTA方法的比较见表10,在MS COCO test-dev set上,单个的ViTPose-G模型优于之前所有的SOTA方法,达到了80.9的AP,之前最优的方法UDP++,集成了17个模型才达到80.8的AP。如果集成3个模型,ViTPose最终达到81.1的AP。
4.4.Subjective results
我们还可视化了ViTPose在MS COCO数据集上的姿态估计结果。结果见Fig3,对于一些具有挑战性的case,比如很严重的遮挡、不同的姿势、不同的大小,ViTPose总能预测出准确的姿态估计结果。

5.Limitation and Discussion
在本文中,我们提出了一种用于姿态估计的简单且有效的vision transformer baseline:ViTPose。尽管在结构上没有精心设计,但是ViTPose依然在MS COCO数据集上获得了SOTA的表现。但是ViTPose的潜力尚未被完全发掘,比如使用更复杂的decoders或FPN结构,都有可能使得性能被进一步提升。此外,我们相信ViTPose也可以被应用于其他姿态估计数据集,比如动物姿态估计,面部关键点检测等。未来有待进一步研究。
6.Conclusion
本文提出ViTPose可以作为人体姿态估计中基于vision transformer的简单baseline。通过在MS COCO数据集上的大量实验,我们验证了ViTPose在姿态估计任务中有着良好的simplicity、scalability、flexibility和transferability。单个的ViTPose-G模型在MS COCO test-dev set上获得了最优的80.9的AP。我们希望本文可以激发出更多研究来探索plain vision transformers在计算机视觉任务中的潜力。
7.A.Additional results of multi-dataset training
为了更全面的评估ViTPose的性能,除了在MS COCO val set上测试,我们还使用ViTPose-B,ViTPose-L,ViTPose-H以及ViTPose-G分别在OCHuman val and test set,MPII val set和AI Challenger val set上进行了测试。请注意,ViTPose的变体都是在多数据集联合的情况下训练的,并且没有在特定训练集上进行进一步的finetune。
👉OCHuman val and test set.
为了评估人体姿态模型在human instances被严重遮挡情况下的性能,我们测试了ViTPose变体以及其他一些代表性模型在OCHuman val and test set上的表现。因为OCHuman数据集中并非所有的human instances都被标注了出来,所以会导致大量的“false positive” bounding boxes,从而无法反映姿态估计模型的真实能力。我们使用与MS COCO数据集相对应的ViTPose decoder head,因为MS COCO和OCHuman数据集中的关节点定义相同。结果见表11。与之前具有复杂结构的SOTA的方法相比(比如MIPNet),在OCHuman val set上,ViTPose将AP提升了超过10个点,并且我们并未针对遮挡做特殊的设计处理,这说明了ViTPose具有强大的feature representation ability。并且可以注意到,相比在MS COCO上的表现,HRFormer在OCHuman数据集上的表现有着巨大的下滑。这些现象意味着HRFormer可能过度拟合MS COCO数据集,特别是对于lager-scale models来说,并且需要额外的finetune才能从MS COCO转移到OCHuman。此外,无论是val set还是test set,ViTPose都显著提升了之前的最优成绩。这些结果表明,ViTPose可以灵活地处理具有严重遮挡的数据,并获得SOTA的性能。
MIPNet:R. Khirodkar, V. Chari, A. Agrawal, and A. Tyagi. Multi-instance pose networks: Rethinking top-down pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3122–3131, 2021.。

👉MPII val set.
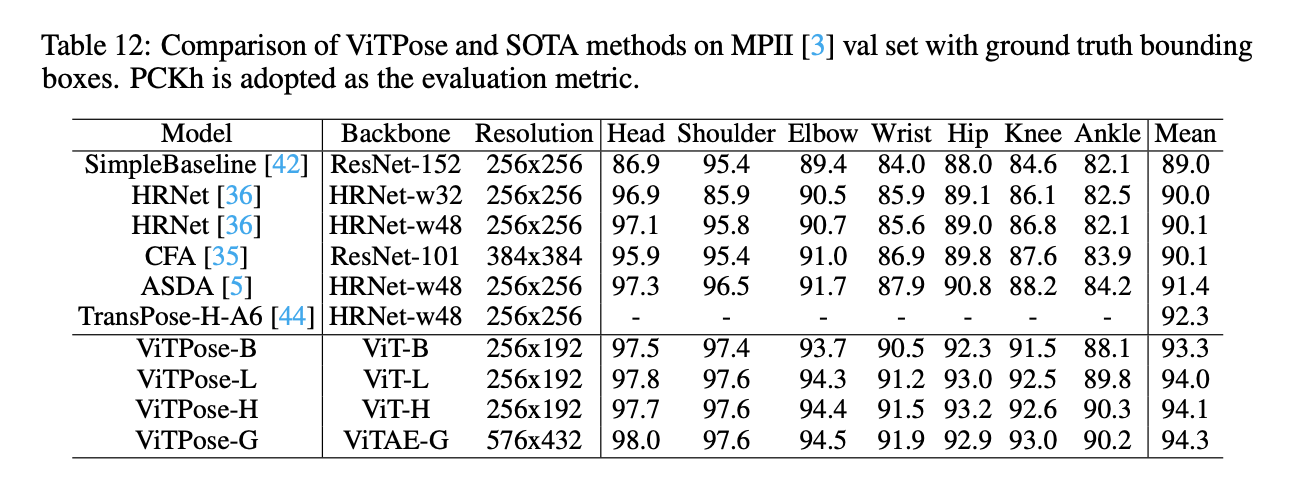
同样,我们也在MPII val set上做了实验。遵循MPII的默认设置,我们使用PCKh作为性能评估指标。如表12所示,无论是单个关节点评估还是平均评估,ViTPose都取得了更好的成绩,比如ViTPose-B、ViTPose-L和ViTPose-H分别取得了93.3、94.0和94.1的平均PCKh,并且输入分辨率更小($256 \times 192$ v.s. $256 \times 256$)。如果使用更大的输入分辨率和更大的backbone,比如ViTPose-G,性能达到了新的SOTA,即94.3的PCKh。
👉AI Challenger val set.
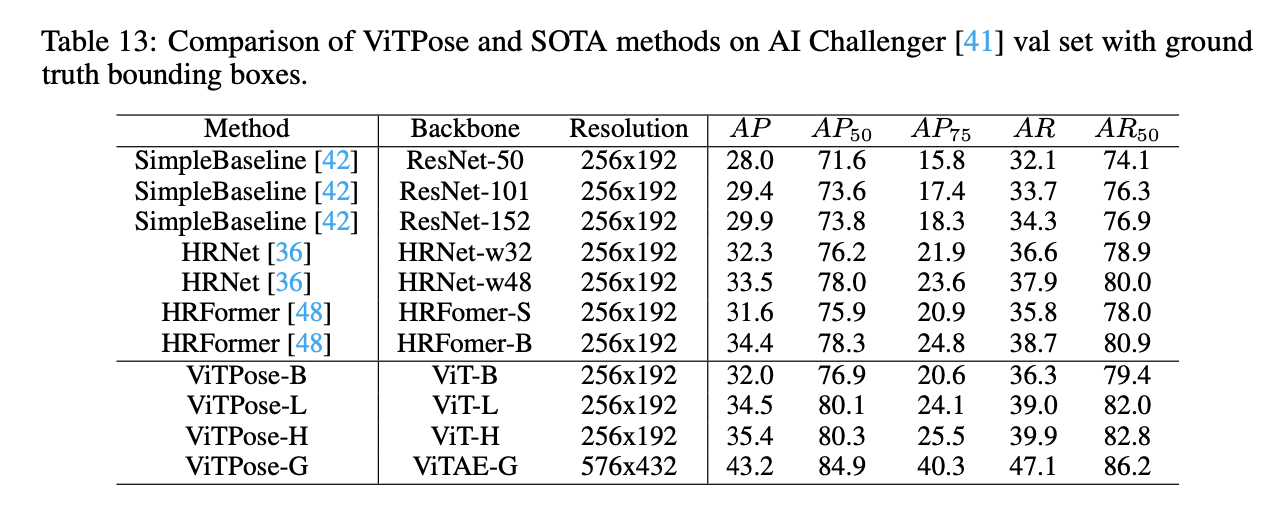
类似的,在AI Challenger val set上,我们也评估了ViTPose(搭配相应的decoder head)的表现。结果见表13,和之前基于CNN和基于transformer的优秀模型相比,ViTPose的表现更好,比如,ViTPose-H的AP为35.4,HRNet-w48的AP为33.5,HRFromer base的AP为34.4。如果使用更大的backbone和更大的输入分辨率,ViTPose-G刷新了这个数据集的最好成绩,取得了43.2的AP。但是模型在AI Challenger set这个数据集上的表现依然不够好,后续需要进一步的努力提升。
7.B.Detailed dataset details.
我们使用MS COCO,AI Challenger,MPII和CrowdPose等多个数据集进行训练和评估。OCHuman数据集仅用于评估阶段,用于衡量模型在处理遮挡数据时的表现。MS COCO数据集包含118K张图像,150K个human instances,每个instance最多标注有17个关节点可用于训练。该数据集的license为CC-BY-4.0。MPII数据集使用BSD license,包含15K张图像和22K个human instances可用于训练。该数据集中每个instance最多标注有16个关节点。AI Challenger数据集更大,包含超过200K张训练图像和350K个human instances,每个instance最多标注有14个关节点。OCHuman包含被严重遮挡的human instances,且只被用作val and test set,共包括4K张图像和8K个instances。
7.C.Subjective results
本节列出了ViTPose的一些可视化结果。AI Challenger的结果见Fig4,OCHuman的结果见Fig5,MPII的结果见Fig6。



8.原文链接
👽ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
