本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.移除低变异数的特征
我们对如下数据进行处理,customer_behavior.csv:
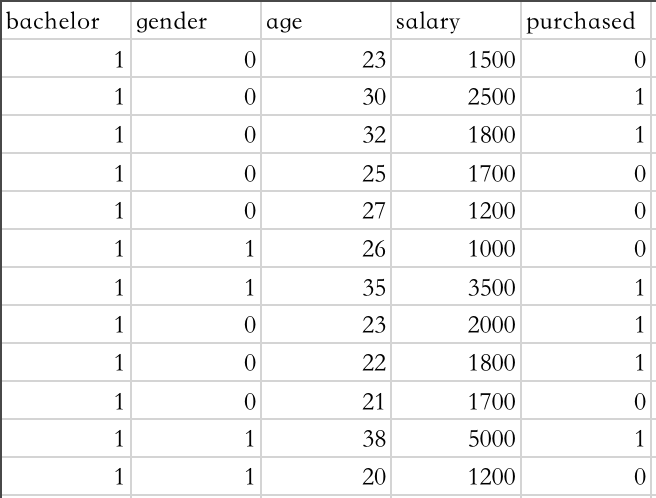
前四列为属性,第五列为标签。我们对前四列进行特征筛选:
1
2
3
4
5
6
7
8
9
import pandas
from sklearn.feature_selection import VarianceThreshold
df = pandas.read_csv("customer_behavior.csv")
X = df[['bachelor','gender','age','salary']]
sel = VarianceThreshold()
X_val = sel.fit_transform(X)
names = X.columns[sel.get_support()]
print(names) #输出为:Index(['gender', 'age', 'salary'], dtype='object')
可以看到我们把属性“bachelor”过滤掉了,说明其不是一个重要的特征。VarianceThreshold()通过计算每个属性的方差,将方差小于阈值(默认是0)的属性过滤掉。在本例中,4个属性的方差分别为:
1
2
print(sel.variances_)
#输出为:[0.00000000e+00 2.22222222e-01 3.04722222e+01 1.18520833e+06]
2.单变量特征选择
1
2
3
4
5
6
7
8
9
10
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X = df[['bachelor','gender','age','salary']]
y = df['purchased'].values
clf = SelectKBest(chi2, k=2)
clf.fit(X, y)
print(clf.scores_)
X_new = clf.fit_transform(X, y)
print(X_new)
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
[ 0. 0. 4.48447205 2766.66666667]
[[ 23 1500]
[ 30 2500]
[ 32 1800]
[ 25 1700]
[ 27 1200]
[ 26 1000]
[ 35 3500]
[ 23 2000]
[ 22 1800]
[ 21 1700]
[ 38 5000]
[ 20 1200]]
我们使用SelectKBest选择最佳的K个特征,本例中,特征好坏的评判标准为chi2,即卡方检验。本例中选择的两个最佳特征是“age”和“salary”。
3.暴力法选择特征
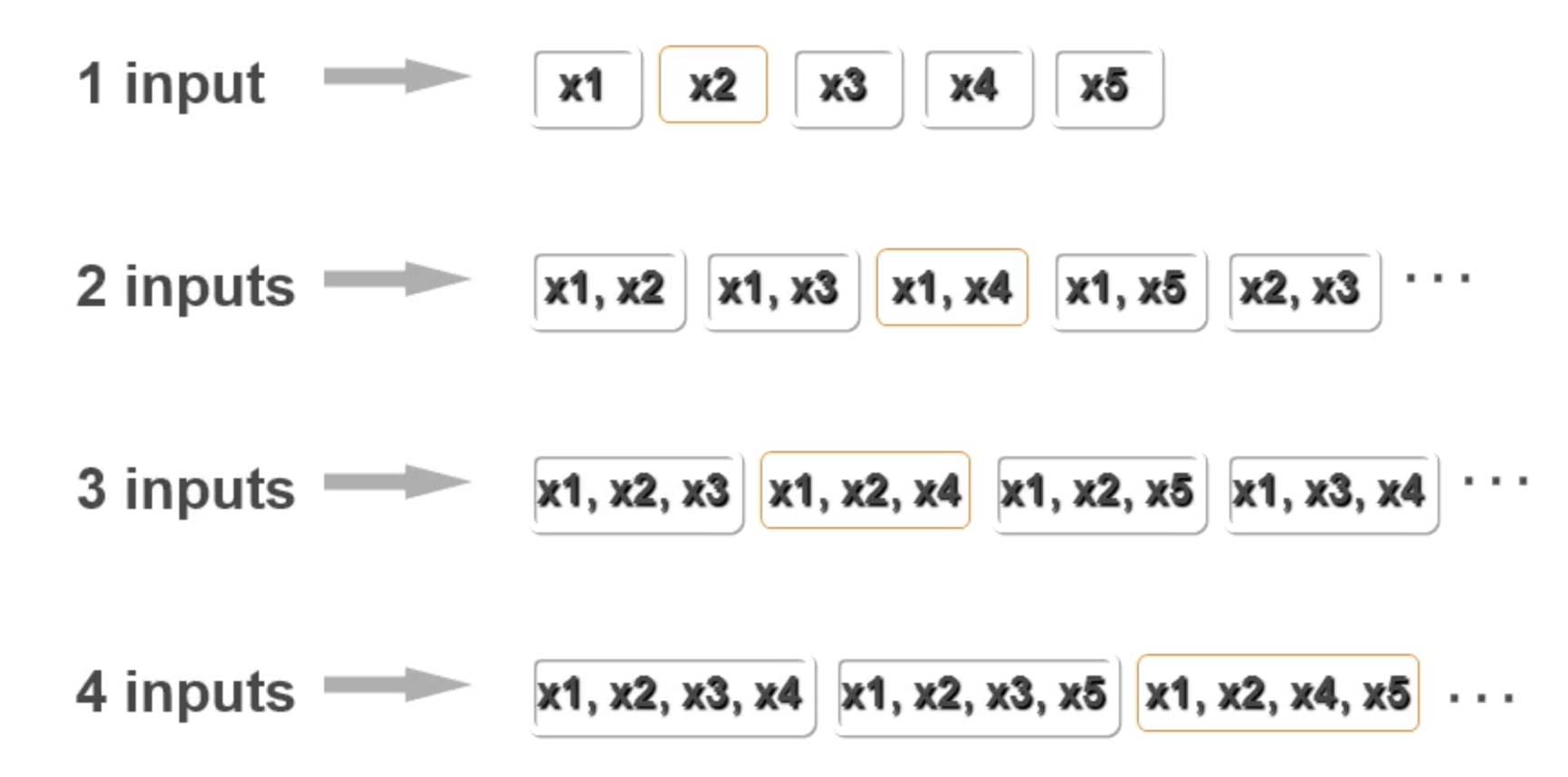
直接枚举所有的特征组合过于繁琐,所以介绍以下一种优化方式。
3.1.recursive feature elimination
逐步剔除特征以找到最好的特征组合。
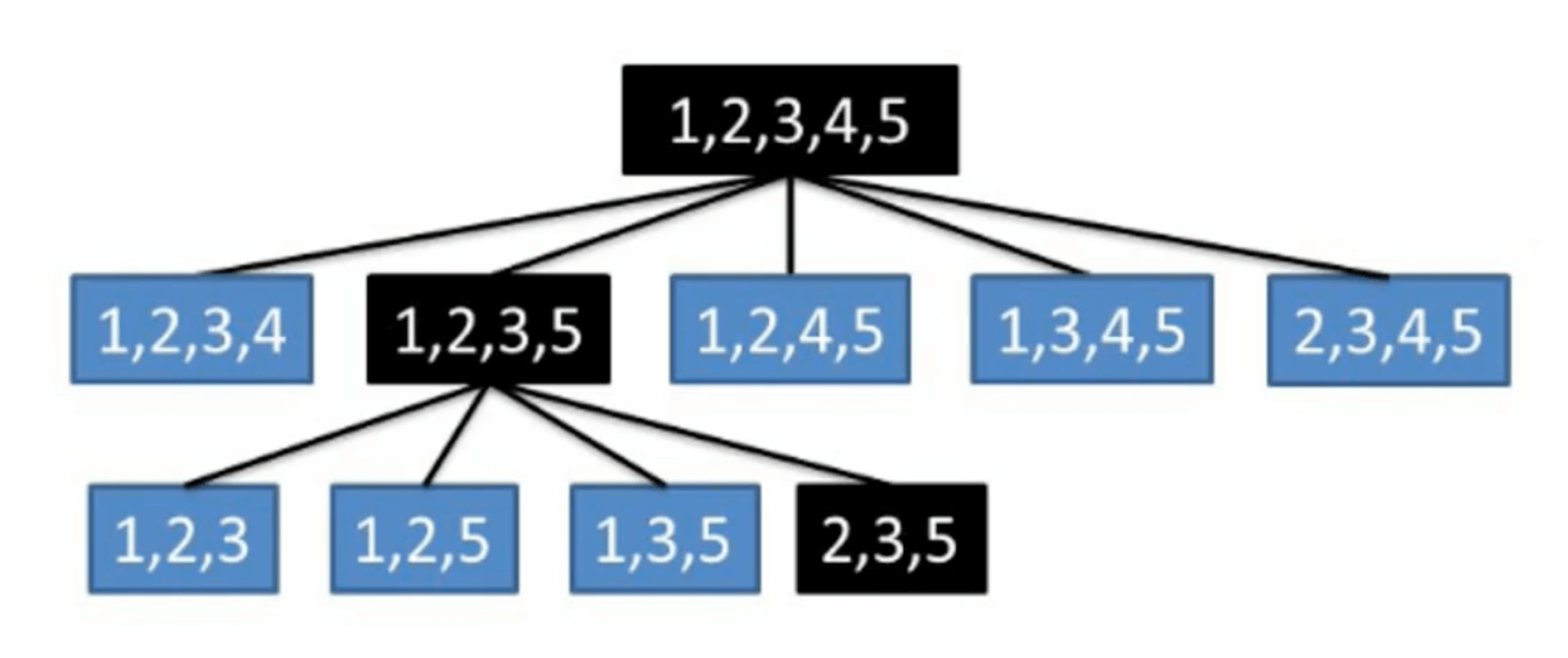
代码实现:
1
2
3
4
5
6
7
from sklearn.feature_selection import RFE
from sklearn.svm import SVC
clf = SVC(kernel='linear')
rfe = RFE(clf, n_features_to_select=1)
rfe.fit(X_val, y)
for x in rfe.ranking_:
print(names[x-1], rfe.ranking_[x-1])
输出为:
1
2
3
salary 1
age 2
gender 3
使用SVM模型的结果作为特征组合的评价标准,SVC()的讲解请见【Python基础】第二十九课:分类模型之SVM。n_features_to_select为要挑选出的特征数量。
4.使用随机森林筛选变量
1
2
3
4
5
6
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=10,random_state=123)
clf.fit(X_val, y)
for feature in zip(names,clf.feature_importances_):
print(feature)
输出为:
1
2
3
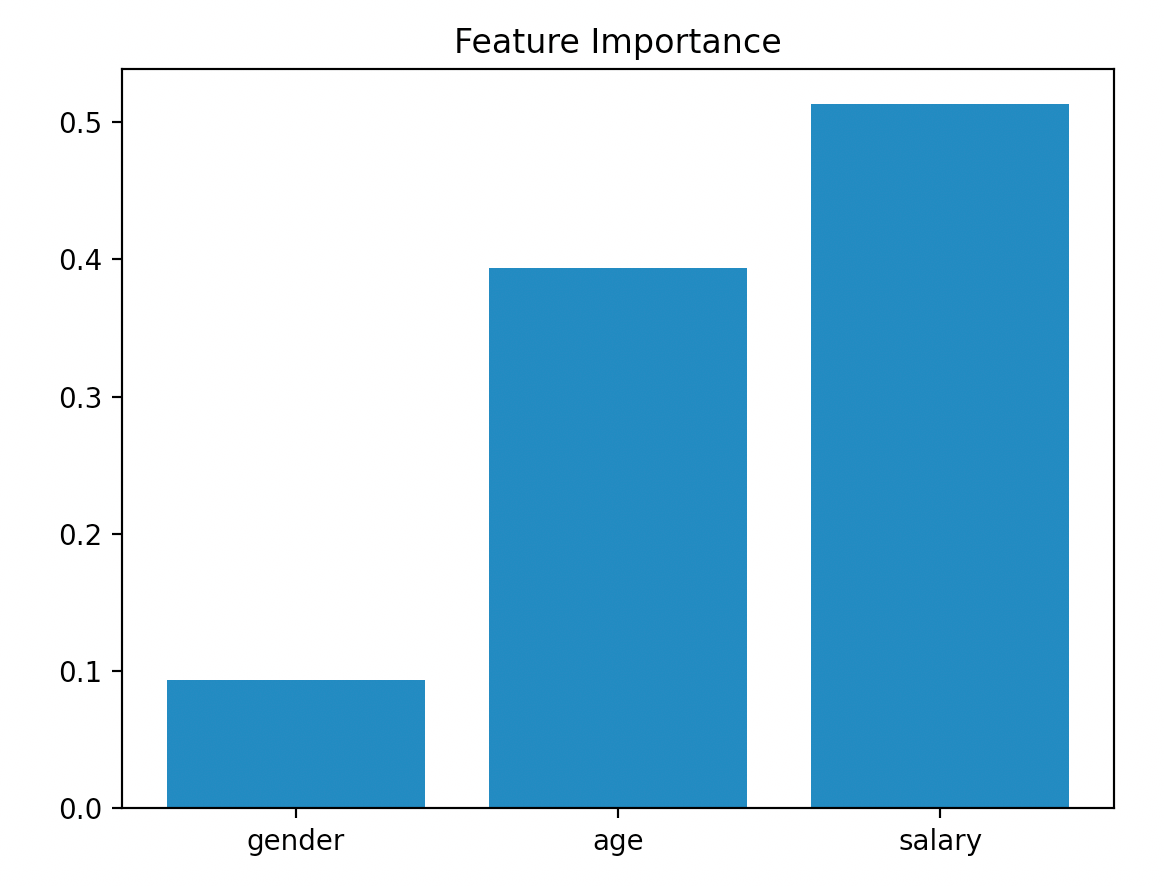
('gender', 0.0933015873015873)
('age', 0.39391203703703703)
('salary', 0.5127863756613757)
RandomForestClassifier()的讲解请见:【Python基础】第三十一课:分类模型之随机森林。
👉可视化呈现Feature Importance:
1
2
3
4
5
import matplotlib.pyplot as plt
plt.title('Feature Importance')
plt.bar(range(0,len(names)),clf.feature_importances_)
plt.xticks(range(0,len(names)),names)
plt.show()