本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
FlowNet直接用CNN预测光流的方式颠覆了以往光流检测领域的传统方法。但是其依然很难和现有的优秀传统算法竞争。
我们提出的FlowNet2.0达到了SOTA的水平。

从Fig1可以看出,作为FlowNet的升级版,FlowNet2.0可以产生更加smooth的光流场,对精细的运动细节捕捉的更好,运行速度可达8~140FPS。在这个例子上,FlowNet2.0的精度是FlowNet的4倍。
首先,我们评估了dataset schedules。使用多个数据集的组合明显提升了结果。并且,在此基础上,我们还发现带有相关层的FlowNet明显优于没有相关层的FlowNet。
其次,我们引入了warping操作,使用该操作可以堆叠多个网络以显著提高结果。通过改变堆叠的深度和单一组件的大小,可以衍生出很多网络变体。这使得我们可以很方便的进行性能和计算资源之间的trade-off。
最后,我们聚焦在亚像素级别的小位移以及真实世界数据。为此,我们创建了一个特殊的训练集以及一个专门的网络。我们将这个专门的网络在这个特殊的训练集上进行训练,结果表明其在真实世界中的小位移上表现良好。为了可以在任意大小的位移上都表现很好,我们将以前堆叠的网络和这个可以很好支持小位移的网络进行了结合。
我们最终得到网络大幅优于之前的FlowNet,并且在Sintel和KITTI数据集上和SOTA方法不相上下。FlowNet2.0不仅可以很好的支持小位移和大位移,还能达到实时检测。
2.Related Work
在FlowNet之后,也相继有一些研究将CNN应用于光流估计,但效果都没有明显优于FlowNet。
3.Dataset Schedules
我们发现不仅数据质量对训练很重要,训练策略也很重要。
FlowNetS是在飞椅数据集上训练的。该数据集仅包含平面运动。
FlyingThings3D(Things3D)数据集可以看作是飞椅数据集的3D版本。该数据集包含22k张渲染的随机场景图像,其3D模型来自ShapeNet数据集。与飞椅数据集相比,Things3D数据集包含真实的3D运动以及照明效果,3D模型也更具有多样性。
我们分别在以下三个数据集上训练了FlowNetS和FlowNetC:1)飞椅数据集;2)Things3D数据集;3)飞椅和Things3D的混合数据集(各占50%)。使用的学习率衰减策略也有三种不同的方式(见Fig3):
- $S_{short}$:该方式一共训练600k次迭代,基本和FlowNet论文中的策略保持一致。只有两处稍有不同:1)FlowNet开始先用$1e-6$的学习率,然后再提升学习率,但这里一开始就直接使用$1e-4$的学习率;2)我们固定前300k次迭代的学习率,然后每100k次迭代,学习率就减半。
- $S_{long}$:该方式一共训练1.2M次迭代。
- $S_{fine}$:接在$S_{long}$之后,用一个较低学习率进行fine-tune。

在Sintel train clean上的测试结果见表1:
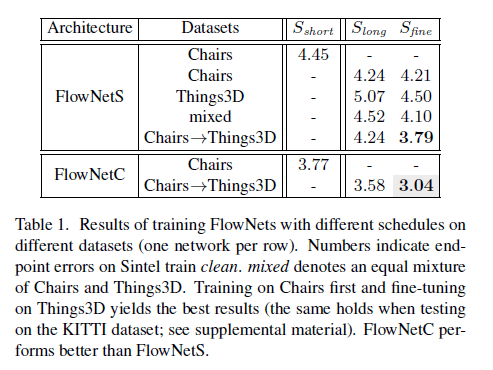
表1中每一行就是一种训练策略。表中的数值就是EPE。mixed指的是混合数据集。Chairs$\to$Things3D指的是先在飞椅数据集上进行训练,然后在Things3D上进行fine-tune。无论是FlowNetS还是FlowNetC,Chairs$\to$Things3D的方式都得到了最低的EPE(在KITTI数据集上也能得到一样的结论)。从表1中还能看出,FlowNetC的表现优于FlowNetS。
此外,还有如下一些发现。
👉The order of presenting training data with different properties matters.
尽管Things3D的数据更真实,但是单独在Things3D上训练的模型却比不上在飞椅上训练的模型。先在飞椅上训练,然后在Things3D上fine-tune始终可以得到最优的结果。我们认为原因在于更简单的飞椅数据集有利于网络先学习到比如颜色匹配等一些通用的一般性概念。
👉FlowNetC outperforms FlowNetS.
我们认为在FlowNet一文中,因为FlowNetC和FlowNetS没有在相同条件下进行测试,所以没有得到FlowNetC优于FlowNetS这一结论。我们在相同条件下测试了FlowNetC和FlowNetS,可以发现FlowNetC优于FlowNetS。
👉Improved results.
仅仅通过修改数据集和训练策略,我们就将FlowNetS的结果提高了约25%,将FlowNetC的结果提高了约30%。
在本节中,我们没有针对特定的场景使用专门的数据集进行fine-tune。所以我们的网络是通用的,在各种场景中都能很好的工作。
4.Stacking Networks
4.1.Stacking Two Networks for Flow Refinement
目前所有SOTA方法都依赖于迭代优化。CNN模型是否也能从迭代优化中获益?为了回答这个问题,我们尝试堆叠了多个FlowNetS和FlowNetC。
我们将多个网络堆叠成一个stack。stack中的第一个网络的输入为图像$I_1$和图像$I_2$。后续网络的输入除了$I_1,I_2$,还有上一个网络输出的光流估计结果$w_i = (u_i, v_i)^{\top}$,$i$是网络在stack中的index。
完整的网络结构见Fig2:
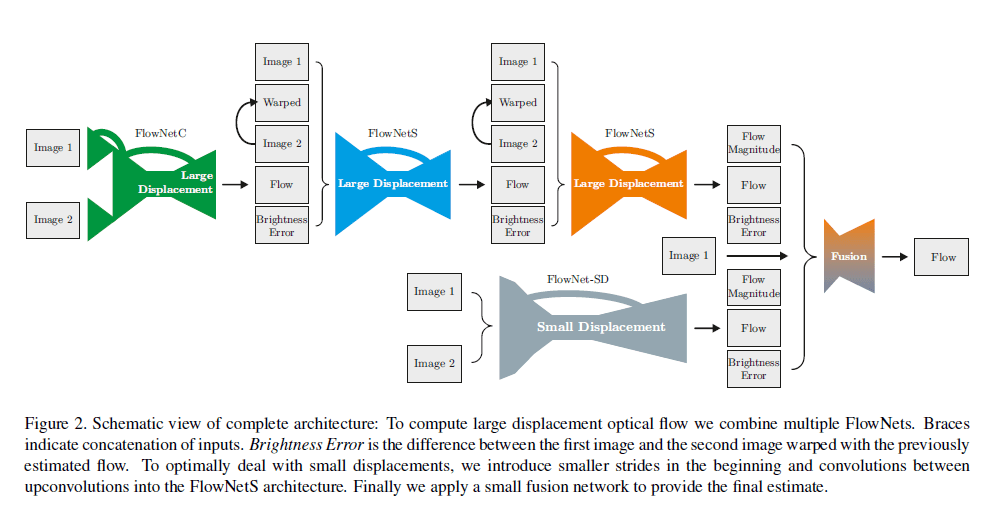
从Fig2可以看出,除了stack中的第一个网络,后续网络有5个输入:
- Image 1和Image 2:原始输入图像对,即$I_1,I_2$。
- Flow:上一个网络输出的光流检测结果。
- Warped:有了Flow和Image 2,我们可以推算出一个近似的Image 1(也作为网络的一个输入),这个操作就叫做warp。用公式表示为:$\tilde{I}_{2,i}(x,y)=I_2(x+u_i,y+v_i)$。这一步会用到双线性插值。
- Brightness Error:即近似的Image 1和真实的Image 1之间的误差。用公式表示为:$e_i = \parallel \tilde{I}_{2,i} - I_1 \parallel$。
该堆叠网络模型可以进行端到端的训练。

表2中,我们堆叠了两个FlowNetS网络。Net1是第3部分中提到的使用Chairs$\to$Things3D训练策略得到的FlowNetS(相当于是pretrian过的Net1)。Net2就是随机初始化的FlowNetS。Net1和Net2都是绿色对号表示在训练过程中,Net1和Net2的权重都会被更新(需要注意的是在前400k次迭代,Net1的权重不会更新,以保证可以先训练一会儿Net2)。Net1是红叉表示在整个训练过程中,Net1的权重都不会被更新。整个堆叠网络是在飞椅数据集上进行训练的,采用$S_{long}$的训练策略。W表示是否使用了warp操作。由于是在飞椅数据集上训练的,所以在相同数据集上的测试结果有点过拟合。”Loss after”表示是否输出Brightness Error。
通过以上实验,我们有如下发现:
- 仅堆叠网络而不使用warp操作,依然可以改善其在飞椅数据集上的表现,但会导致在Sintel数据集上的表现变差。
- 如果使用warp操作,堆叠网络总能带来性能上的提升。
- 让Net1输出Brightness Error有利于性能提升。
- 固定Net1,仅训练Net2,且使用warp操作,这一搭配获得了最佳结果。
当stack中的网络一个接一个的训练时,可以避免过拟合,从而获得最优结果。
4.2.Stacking Multiple Diverse Networks
我们还可以尝试堆叠不同类型的网络,或者同一类型但不同大小的网络。
我们将stack中的第一个网络称为bootstrap。后续的网络可以是一样的权重,然后再进行fine-tune,但我们发现这样做并不能改善结果。因此,我们将后续的网络设置为不同的权重。并且我们可以固定现有网络,然后只训练新添加的网络来将stack的训练分割成更小的部分。此外,我们还对不同的网络大小进行了实验,并搭配FlowNetS或FlowNetC作为bootstrap。由于在stack中,从第二个网络开始,其输入是多样化的,所以FlowNetC只能被用作bootstrap。我们通过对网络中每一层的通道进行采样来控制网络的大小。

Fig4是在单个FlowNetS上的测试结果。横轴是对通道的采样率,1就表示和原始通道数一样。左侧是在Sintel clean上测得的EPE,右侧是运行时间。为了很好的trade-off精度和运行时间,作者建议采样率为$\frac{3}{8}$。
表3是不同stack配置的测试结果:
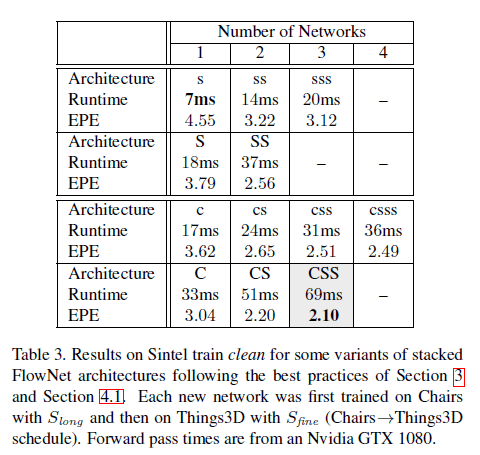
训练都遵循Chairs$\to$Things3D的策略。stack中的网络按一个接一个训练的模式。FlowNet2-CSS表示该stack包含一个FlowNetC(bootstrap)和两个FlowNetS,通道采样率为1。FlowNet2-css表示该stack包含一个FlowNetC(bootstrap)和两个FlowNetS,通道采样率为$\frac{3}{8}$。其余命名同理。
FlowNet2-CSS的性能比第3部分中的FlowNet2-C提升了约30%,比FlowNetC提升了约50%。此外,堆叠两个小网络总是优于一个大网络,并且速度更快,参数量更少:
- FlowNet2-ss参数量11M,FlowNet2-S参数量38M。
- FlowNet2-cs参数量11M,FlowNet2-C参数量38M。
并且,一个接一个训练新增网络的策略也使得我们可以训练更深的stack。FlowNet2-s的精度和FlowNet差不多,但检测速度达到了140FPS。
5.Small Displacements
5.1.Datasets
虽然FlowNet在Sintel数据集上表现良好,但其并不能很好的检测小位移(见Fig1)。这是违反常理的,因为通常来说,检测小位移对传统方法很容易,网络模型没有理由达不到等同的性能。因此,我们将飞椅数据集、Sintel数据集以及UCF101数据集(真实世界数据)进行了比较,我们发现飞椅数据集和Sintel数据集很相似,但和UCF101数据集却有很大的不同:Sintel数据集包含了很多传统方法难以检测的快速位移动作;而UCF101数据集中的位移却小得多,大多小于1个像素。因此,我们仿照飞椅数据集的视觉风格创建了一个新的数据集,其包含很多小位移,位移分布更贴近UCF101。此外,该数据集还添加了纯色和渐变色的背景,我们将这个新数据集称为ChairsSDHom。
5.2.Small Displacement Network and Fusion
我们在Things3D和ChairsSDHom的混合数据集上fine-tune了FlowNet2-CSS,我们将fine-tune之后的网络称为FlowNet2-CSS-ft-sd。这样做既增加了其对小位移的检测能力,也没有牺牲其在大位移上的表现。但在亚像素级别的运动下,噪声依然是个问题。因此,我们又基于原始的FlowNetS进行了修改,修改主要包括3方面:
- 移除了第一层步长为2的操作。
- 将$7\times 7$和$5\times 5$的卷积改为连续的$3\times 3$卷积以增加网络深度。
- 因为噪声通常属于小位移,所以我们在反卷积之间添加卷积,以获得更平滑的估计。
我们将这个修改过的网络称为FlowNet2-SD(见Fig2)。
Fig2的上半部分就是FlowNet2-CSS-ft-sd,下半部分是FlowNet2-SD。最后通过一个Fusion网络来融合FlowNet2-CSS-ft-sd和FlowNet2-SD。Fusion网络输入中的Flow Magnitude指的是光流的大小,个人理解就是光流矢量的模。在Fusion网络中,分辨率会先被缩小两次(每次缩小2倍),随后再扩展至图像原始分辨率(这一点和FlowNet不同)。我们将最终组合得到的网络称为FlowNet2,其能产生清晰的运动边界,并且在小位移和大位移上都表现良好。
6.Experiments
我们用我们网络模型的最佳变体和SOTA方法进行了比较。
6.1.Speed and Performance on Public Benchmarks
测试硬件为Intel Xeon E5 with 2.40GHz和Nvidia GTX 1080。测试结果见表4。
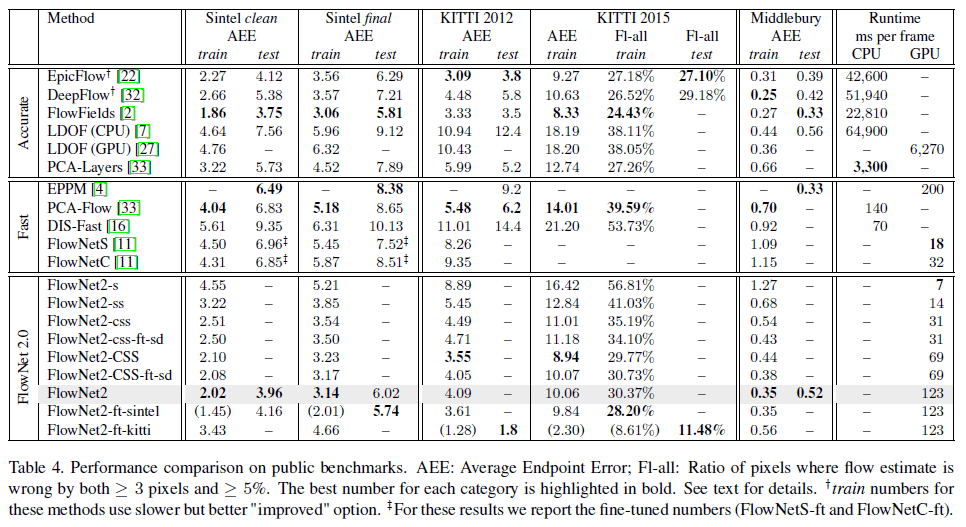
F1-all指的是光流估计误差大于3个像素且误差大于5%的像素点所占比例。模型后面的“+”表示在训练和测试时选择增加运行时间从而提升精度的策略。表中数值后面的“++”表示是fine-tune之后的结果。
👉Sintel:
在Sintel数据集上,FlowNet2的表现始终优于DeepFlow和EpicFlow,并且和FlowFields不相上下。我们把FlowNet2在Sintel clean+final上进行了fine-tune,得到FlowNet2-ft-sintel。FlowNet2-ft-sintel在clean上表现反而稍差一点,但是在final上的表现就更好一些。在final上,FlowNet2-ft-sintel和SOTA方法DeepDiscreteFlow的表现不相上下。
👉KITTI:
在KITTI数据集上,FlowNet2-CSS和EpicFlow、FlowFields的表现相当。相比FlowNet2-CSS,在小位移数据上fine-tune得到的FlowNet2-CSS-ft-sd在KITTI上的表现更差,这可能是因为KITTI通常包含很多大位移。在KITTI上fine-tune之后得到的FlowNet2-ft-kitti,误差减小了3倍。
👉Middlebury:
在Middlebury训练集上,FlowNet2的表现和传统算法相当。但在测试集上,相比传统算法,FlowNet2的表现就差了很多,但是依旧要比FlowNetS好很多。
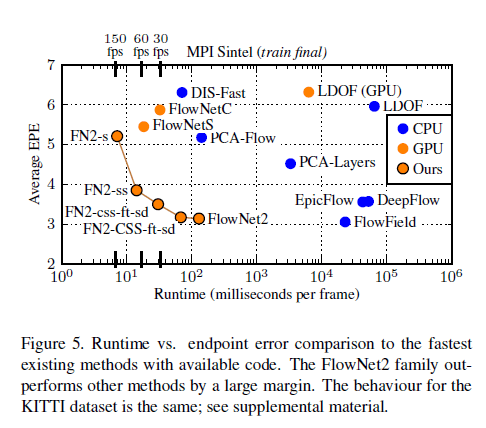
从Fig5可以看出。FlowNet2不但误差低,并且速度快。
6.2.Qualitative Results

Fig6是多个方法在Sintel数据集上的表现。FlowFields和FlowNet2的精度差不多,可以检测到很多细节,但FlowNet2的速度快很多。PCA-Flow、FlowNetS和FlowNet2的速度差不多,但是FlowNet2的精度却高出很多。

Fig7是不同方法在真实世界数据上的表现。前2行来自Middlebury,后3行来自UCF101。可以看出,FlowNet2的结果更为平滑,边界更为清晰,算法鲁棒性更好。
6.3.Performance on Motion Segmentation and Action Recognition
我们在动作识别和运动分割中评估了FlowNet2.0在实际应用中的性能。结果见表5。

结论就是,对于运动分割和动作识别,FlowNetS没有提供有用的结果,而FlowNet2起到了一定的作用。
7.Conclusions
FlowNet2的精度和现有SOTA方法相当,且运行速度快了几个数量级。
8.Supplementary Material
8.1.Video
👉Optical flow color coding.
光流可视化的颜色编码见Fig1。颜色表示位移矢量的方向,像素值表示位移的大小。因此,白色就表示无运动。因为不同图像序列的位移范围差异比较大,因此在可视化之前可以进行归一化操作。

8.2.Dataset Schedules: KITTI2015 Results
在正文中的表1,我们展示了不同训练策略在Sintel数据集上的结果。这里的表1,我们展示了不同训练策略在KITTI2015训练集上的结果,可以得到和之前一样的结论。

8.3.Recurrently Stacking Networks with the Same Weights

这里表2的第一行就是正文表2中我们得到的最优模型。如果我们不重新训练,只是单纯的复制多个Net2(见这里表2的第二行和第三行),发现性能反而略有下降。如果我们复制多个Net2后,让这3个Net2权重共享,然后在飞椅数据集上fine-tune超过100k次迭代(只fine-tune这几个Net2),可以看到性能略有提升(见这里表2的后两行)。
8.4.Small Displacements
8.4.1.The ChairsSDHom Dataset
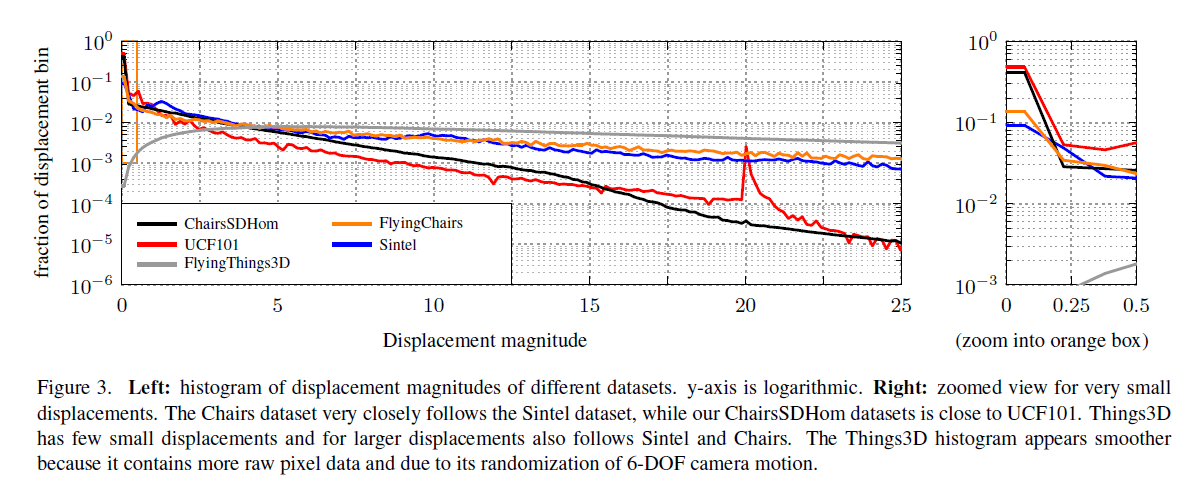
Fig3的左侧是不同程度位移的分布情况,右侧是小位移的分布情况。可以看出,飞椅数据集和Sintel数据集接近,ChairsSDHom数据集和UCF101数据集类似。Things3D数据集中小位移比较少,整体分布和Sintel以及飞椅数据集类似。
ChairsSDHom(Chairs Small Displacement Homogeneous)数据集的一些示例见Fig2。

8.4.2.Fine-Tuning FlowNet2-CSS-ft-sd
在fine-tune FlowNet2-CSS-ft-sd时,为了避免损失其对大位移的检测能力,我们尝试了不同的配置,最终通过设置mini-batch size=8达到了最好的效果(2张图象来自Things3D,6张图像来自ChairsSDHom)。并且我们通过取EPE的0.4次方来强调小位移。
8.4.3.Network Architectures
FlowNet2-SD和Fusion网络的结构见表3和表4。

FlowNet2-SD网络的输入是由两个RGB图像concat而成的,也就是说输入有6个channel。 Fusion网络的输入一共有11个channel:Img1占3个channel;来自两个网络的光流预测结果,每个占2个channel(x方向和y方向),一共占4个channel;光流的大小mags,两个网络的输出各占1个channel,一共占2个channel;errs也是两个网络的输出各占1个channel,一共占2个channel。注意,我们并没有将Img2作为Fusion网络的输入。所有输入都和原始图像分辨率一致,如果需要上采样则使用最近邻上采样。
8.5.Evaluation
8.5.1.Intermediate Results in Stacked Networks
关于网络堆叠所带来的提升,其定性分析见Fig5(都是小位移)。可以看到FlowNet2-C的预测结果非常嘈杂,但后续两个网络的预测结果明显改善。FlowNet2-SD是针对小位移进行训练的,即使没有额外的refine,也能很好的估计小位移。Fusion得到的结果是最佳的。
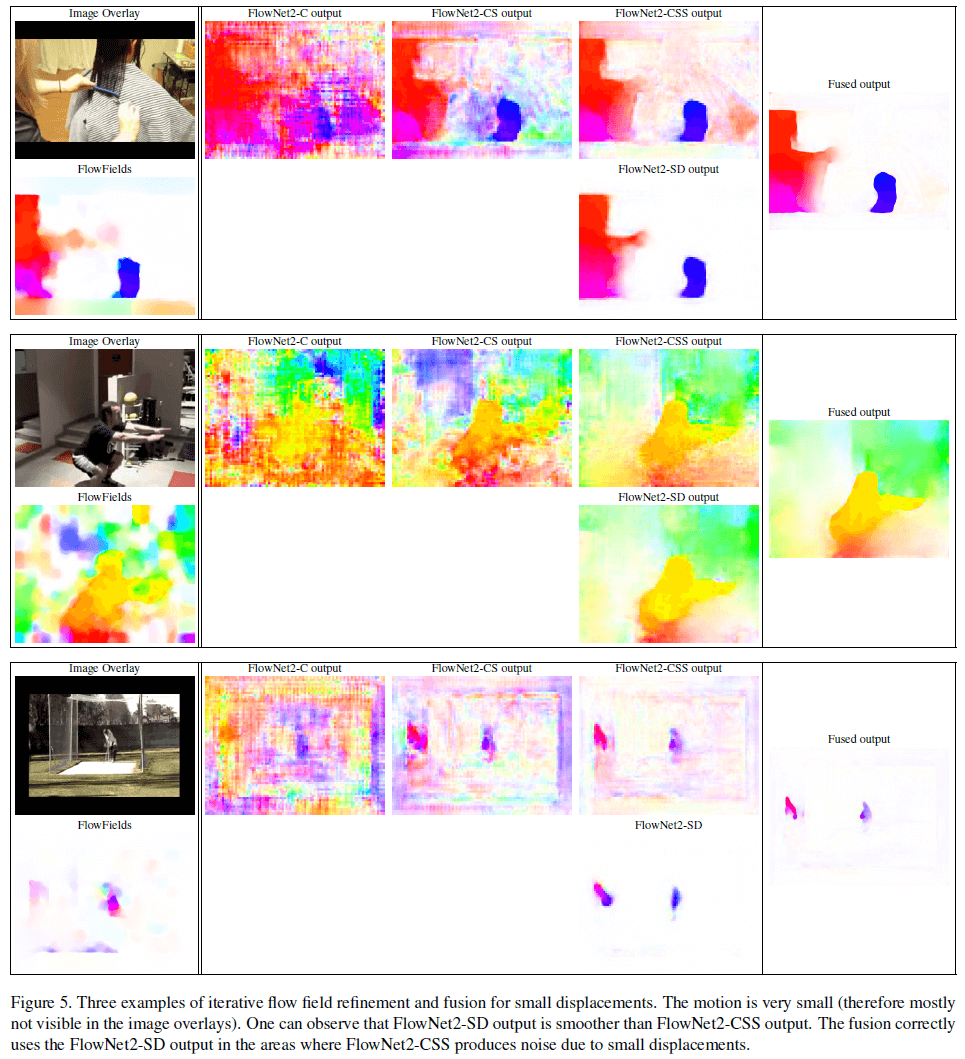
从Fig5中可以看出,FlowNet2-SD的预测结果比FlowNet2-CSS更平滑。在FlowNet2-CSS因小位移而产生的噪声区域,Fusion正确采用了FlowNet2-SD的结果。
大位移的定性分析见Fig6。

从Fig6中可以看出,FlowNet2-CSS在大位移方面的表现要优于FlowNet2-SD,并且Fusion也正确采用了FlowNet2-CSS对大位移的预测结果。
8.5.2.Speed and Performance on KITTI2012
在KITTI2012数据集上,EPE和运行时间之间的权衡见Fig4。

FlowNet2模型在精度和运行时间上取得了很好的平衡。
8.5.3.Motion Segmentation
使用不同光流算法的光流预测结果作为运动分割算法的输入,结果见表5。
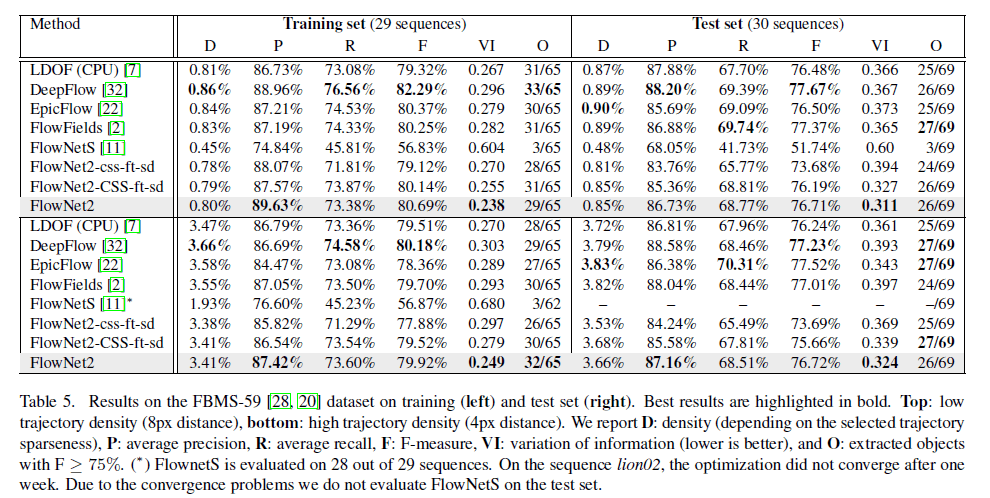
结论就是相比FlowNetS,FlowNet2的预测结果更好,和目前SOTA的方法不相上下。
8.5.4.Qualitative results on KITTI2015
在KITTI2015数据集上的定性分析见Fig7。
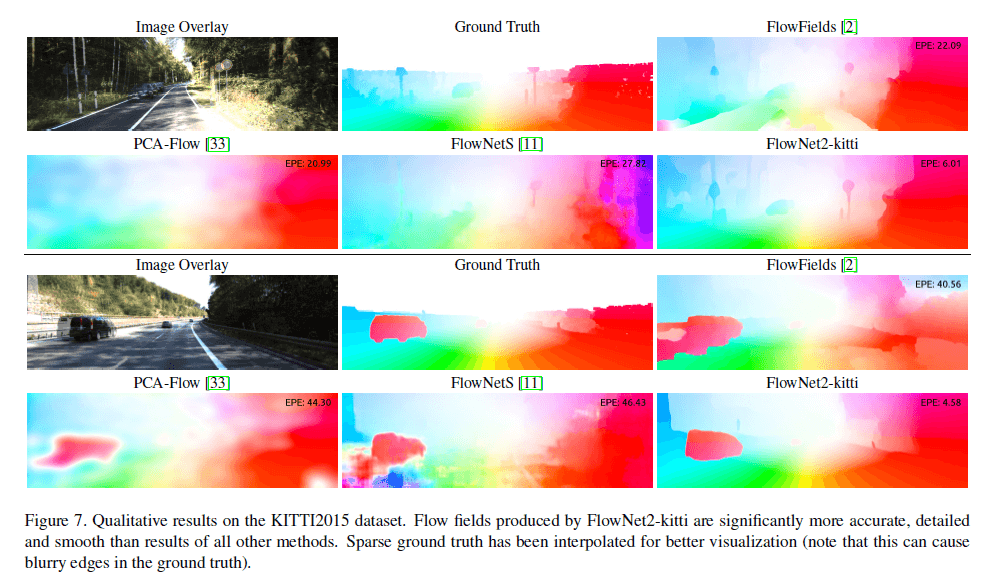
FlowNet2-kitti在fine-tune时并没有使用Fig7中展示的图像。KITTI的GT是稀疏的,所以为了更好的可视化,对GT进行了双线性插值。无论是定量分析还是定性分析,FlowNet2-kitti的表现都显著优于其他竞争方法。
8.6.Warping Layer
这部分是warping layer在正向传播和反向传播中的数学细节。这里不再详述,有兴趣的可以直接去阅读原论文,论文链接见本文末尾。
9.原文链接
👽FlowNet 2.0:Evolution of Optical Flow Estimation with Deep Networks
