博客为参考《程序是怎样跑起来的》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.内存的物理机制很简单
👉第4章热身问答:
- 有十个地址信号引脚的内存IC(集成电路)可以指定的地址范围是多少?
- 用二进制数来表示的话是0000000000~1111111111(用十进制数来表示的话是0~1023)。地址信号引脚是十个时表示$2^{10}=1024$个地址。
- 高级编程语言中的数据类型表示的是什么?
- 占据内存区域的大小和存储在该内存区域的数据类型。例如,C语言数据类型中的short类型,它表示的就是占据2字节的内存区域,并且存储整数。
- 在32位内存地址的环境中,指针变量的长度是多少位?
- 32位。指针指的是用于存储内存地址的变量。
- 与物理内存有着相同构造的数组的数据类型长度是多少?
- 1字节。物理内存是以字节为单位进行数据存储的。
- 用LIFO方式进行数据读写的数据结构称为什么?
- 栈。栈是一种后入先出(LIFO=Last In First Out)式的数据结构。
- 根据数据的大小链表分叉成两个方向的数据机构称为什么?
- 二叉查找树(binary search tree)。二叉查找树指的是从节点分成两个叉的树状数据结构。
计算机是进行数据处理的设备,而程序表示的就是处理顺序和数据结构。由于处理对象数据是存储在内存和磁盘上的,因此程序必须能自由地使用内存和磁盘。
内存实际上是一种名为内存IC的电子元件。虽然内存IC包括DRAM、SRAM、ROM$^1$等多种形式,但从外部来看,其基本机制都是一样的。内存IC中有电源、地址信号、数据信号、控制信号等用于输入输出的大量引脚(IC的引脚),通过为其指定地址(address),来进行数据的读写。
- ROM(Read Only Memory)是一种只能用来读取的内存。
图4-1是内存IC(在这里假设它为RAM$^1$)的引脚配置示例。虽然这是一个虚拟的内存IC,但它的引脚和实际的内存IC是一样的。VCC和GND是电源,A0~A9是地址信号的引脚,D0~D7是数据信号的引脚,RD和WR是控制信号的引脚。将电源连接到VCC和GND后,就可以给其他引脚传递比如0或者1这样的信号。大多数情况下,+5V的直流电压表示1,0V表示0。
- RAM(Random Access Memory)是可被读取和写入的内存,分为需要经常刷新(refresh)以保存数据的DRAM(Dynamic RAM),以及不需要刷新电路即能保存数据的SRAM(Static RAM)。
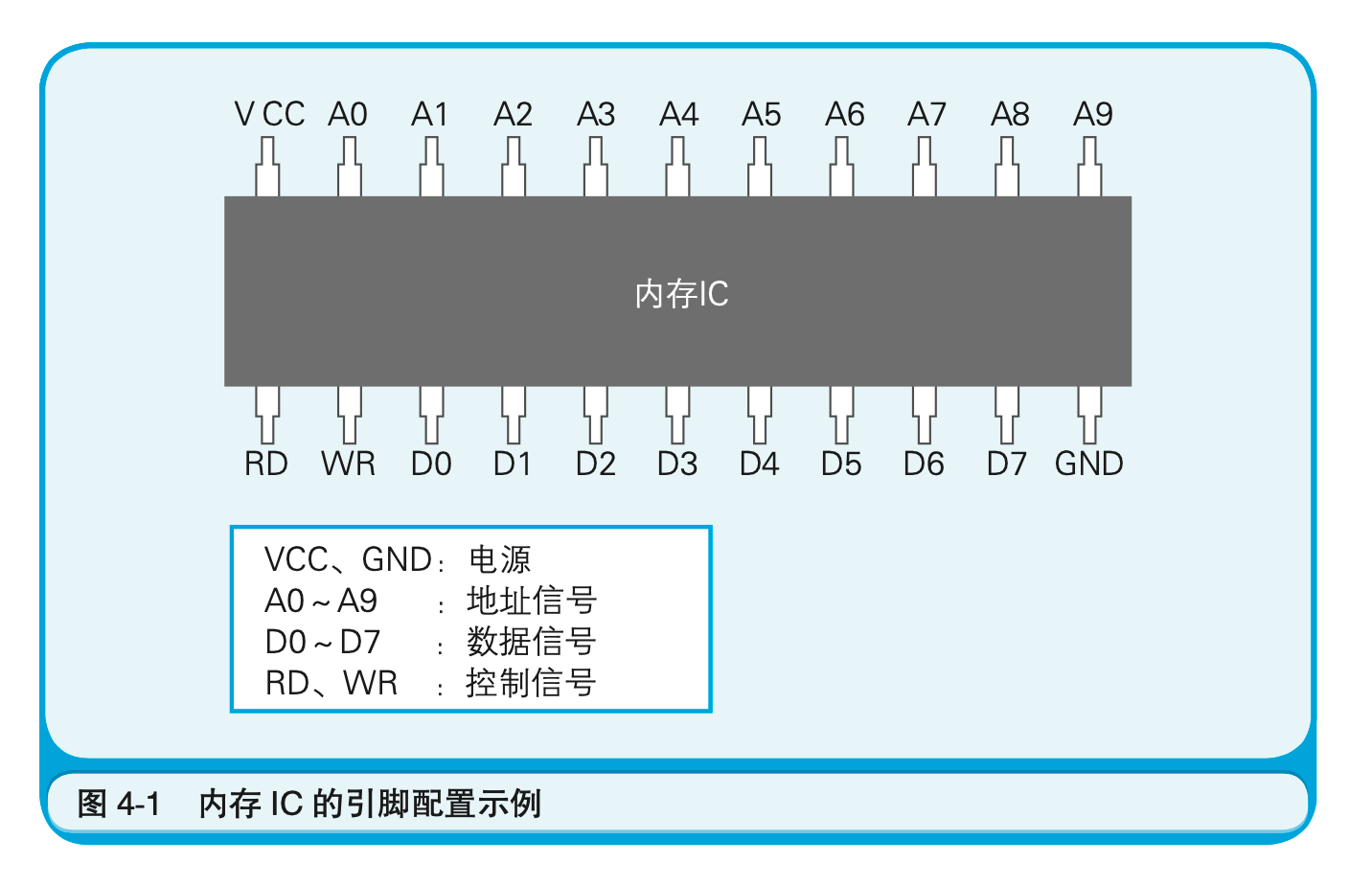
那么,这个内存IC中能存储多少数据呢?数据信号引脚有D0~D7共八个,表示一次可以输入输出8位(=1字节)的数据。此外,地址信号引脚有A0~A9共十个,表示可以指定0000000000~1111111111共1024个地址。而地址用来表示数据的存储场所,因此我们可以得出这个内存IC中可以存储1024个1字节的数据。因为1024=1K$^1$,所以该内存IC的容量就是1KB。
- 在计算机领域,大写字母K表示的并不是1000,而是2的10次幂的结果1024。1000通常用小写k来表示。
现在大家使用的计算机至少有512M的内存。这就相当于512000个(512MB除以1KB等于512K)1KB的内存IC。当然,一台计算机中不太可能放入如此多的内存IC。通常情况下,计算机使用的内存IC中会有更多的地址信号引脚,这样就能在一个内存IC中存储数十兆字节的数据。因此,只用数个内存IC,就可以达到512MB的容量。
下面让我们继续来看刚才所说的1KB的内存IC。首先,我们假设要往该内存IC中写入1字节的数据。为了实现该目的,可以给VCC接入+5V,给GND接入0V的电源,并使用A0~A9的地址信号来指定数据的存储场所,然后再把数据的值输入给D0~D7的数据信号,并把WR(write)信号设定成1。执行完这些操作,就可以在内存IC内部写入数据(图4-2(a))了。
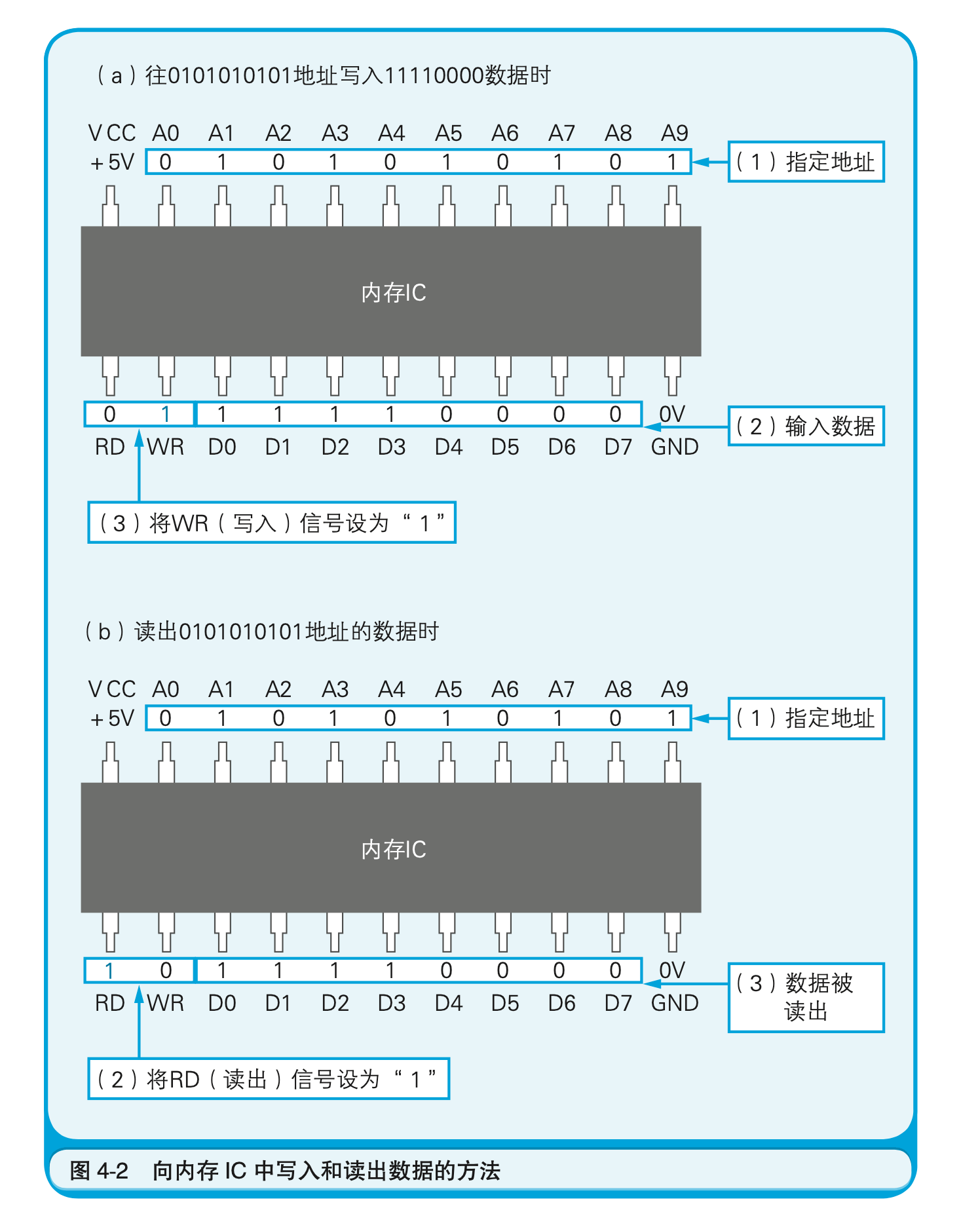
读出数据时,只需通过A0~A9的地址信号指定数据的存储场所,然后再将RD(read)信号设成1即可。执行完这些操作,指定地址中存储的数据就会被输出到D0~D7的数据信号引脚(图4-2(b))中。另外,像WR和RD这样可以让IC运行的信号称为控制信号。其中,当WR和RD同时为0时,写入和读出的操作都无法进行。
总体来讲,内存IC内部有大量可以存储8位数据的地方,通过地址指定这些场所,之后即可进行数据的读写。
2.内存的逻辑模型是楼房
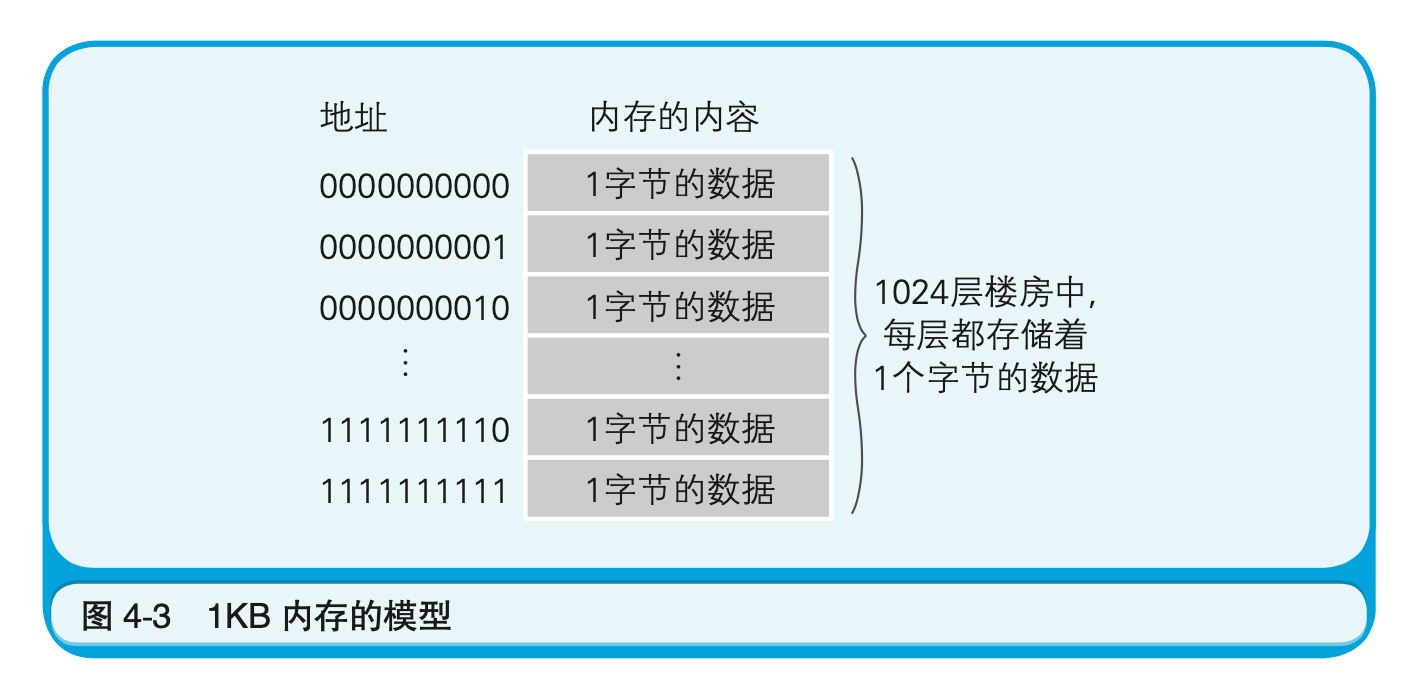
在介绍程序时,大部分参考书都会用类似于楼房的图形来表示内存。在这个楼房中,1层可以存储1个字节的数据,楼层号表示的就是地址。
虽然内存的实体是内存IC,不过从程序员的角度来看,也可以把它假想成每层都存储着数据的楼房,并不需要过多地关注内存IC的电源和控制信号等。内存为1KB时,表示的是如图4-3所示的有1024层的楼房(这里地址的值是从上往下逐渐变大,不过也有与此相反的情况)。
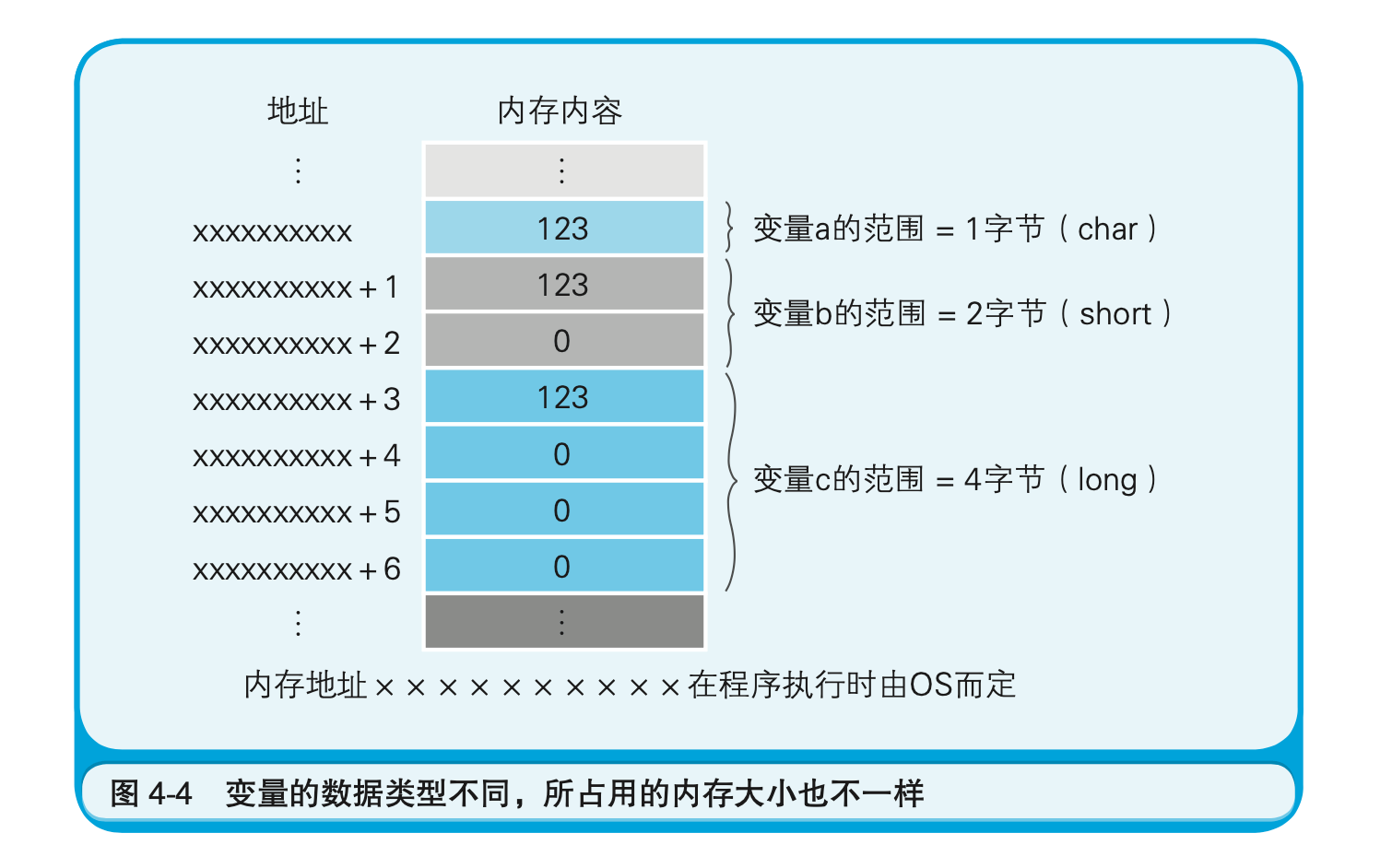
不过,程序员眼里的内存模型中,还包含着物理内存中不存在的概念,那就是数据类型。编程语言中的数据类型表示存储的是何种类型的数据。从内存来看,就是占用的内存大小(占有的楼层数)的意思。即使是物理上以1个字节为单位来逐一读写数据的内存,在程序中,通过指定其类型(变量的数据类型等),也能实现以特定字节数为单位来进行读写。
下面我们来看一个具体的示例。如代码清单4-1所示,这是一个往a、b、c这3个变量中写入数据123的C语言程序。这3个变量表示的是内存的特定区域。通过使用变量,即便不指定物理地址,也可以在程序中对内存进行读写。这是因为,在程序运行时,Windows等操作系统会自动决定变量的物理地址。

这3个变量的数据类型分别是,表示1字节长度的char,表示2字节长度的short,以及表示4字节长度的long$^1$。因此,虽然同样是数据123,存储时其所占用的内存大小是不一样的。这里,我们假定采用的是将数据低位存储在内存低位地址的低字节序(little endian)$^2$方式(图4-4)。
- 在C语言中,int这一数据类型经常会用到。int也是CPU最容易处理的数据类型的长度。在32位的CPU中,int是32位的。在以前的16位的CPU中,int是16位的。
- 将多字节数据的低位字节存储在内存低位地址的方式称为低字节序,与此相反,把数据的高位字节存储在内存低位的方式称为高字节序。本章的示例图中使用的是奔腾等英特尔处理器所采用的低字节序方式。
3.简单的指针
指针也是一种变量,它所表示的不是数据的值,而是存储着数据的内存的地址。通过使用指针,就可以对任意指定地址的数据进行读写。虽然前面所提到的假想内存IC中仅有10位地址信号,但大家在Windows计算机上使用的程序通常都是32位(4字节)的内存地址。这种情况下,指针变量的长度也是32位。
在代码清单4-2中,定义了d、e、f这3个指针变量的C语言程序。d、e、f都是用来存储32位(4字节)的地址的变量。然而,为什么这里又用来指定char(1字节)、short(2字节)、long(4字节)这些数据类型呢?实际上,这些数据类型表示的是从指针存储的地址中一次能够读写的数据字节数。

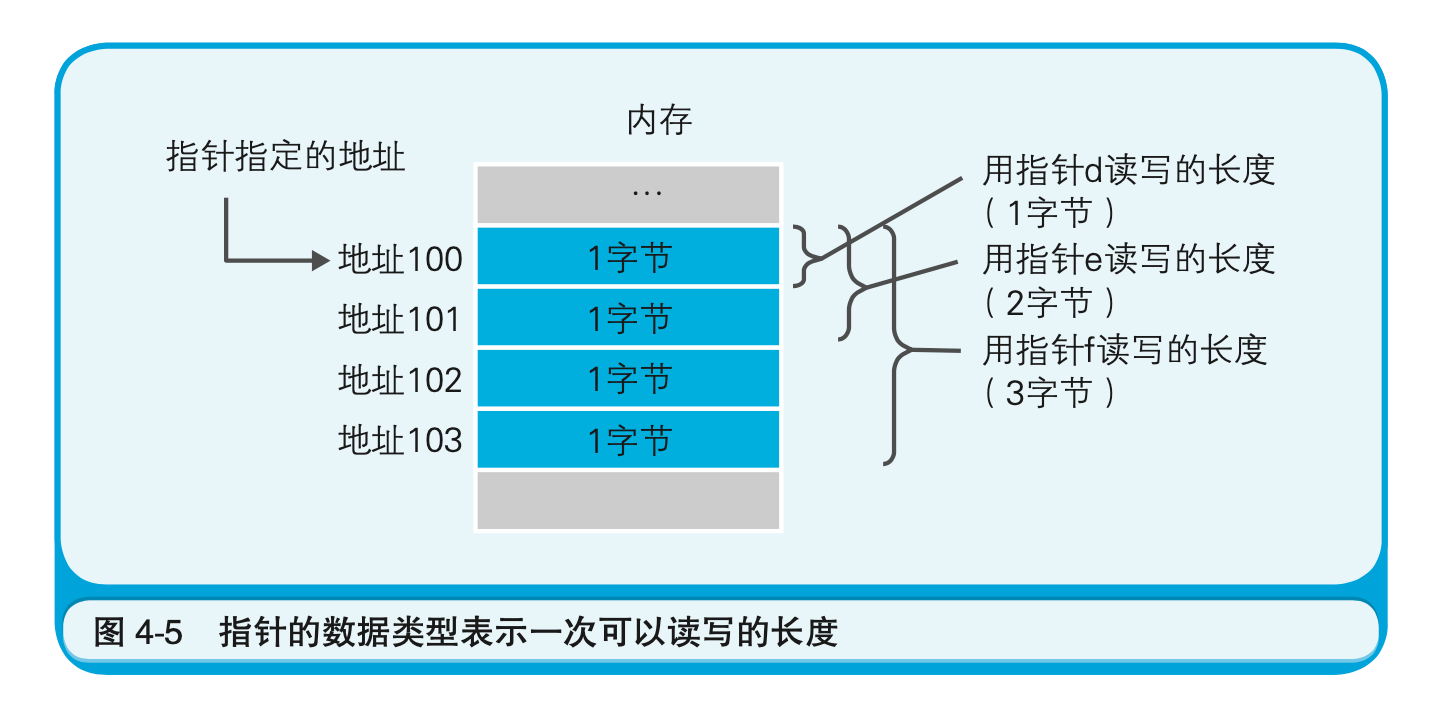
假设d、e、f的值都是100。在这种情况下,使用d时就能够从编号100的地址中读写1个字节的数据,使用e时就是2个字节(100地址和101地址)的数据,使用f时就是4个字节(100地址~103地址)的数据。见图4-5。
4.数组是高效使用内存的基础
数组是指多个同样数据类型的数据在内存中连续排列的形式。作为数组元素的各个数据会通过连续的编号被区分开来,这个编号称为索引(index)。指定索引后,就可以对该索引所对应地址的内存进行读写操作$^1$。而索引和内存地址的变换工作则是由编译器自动实现的。
- CPU是通过利用基址寄存器和变址寄存器来指定内存地址的。
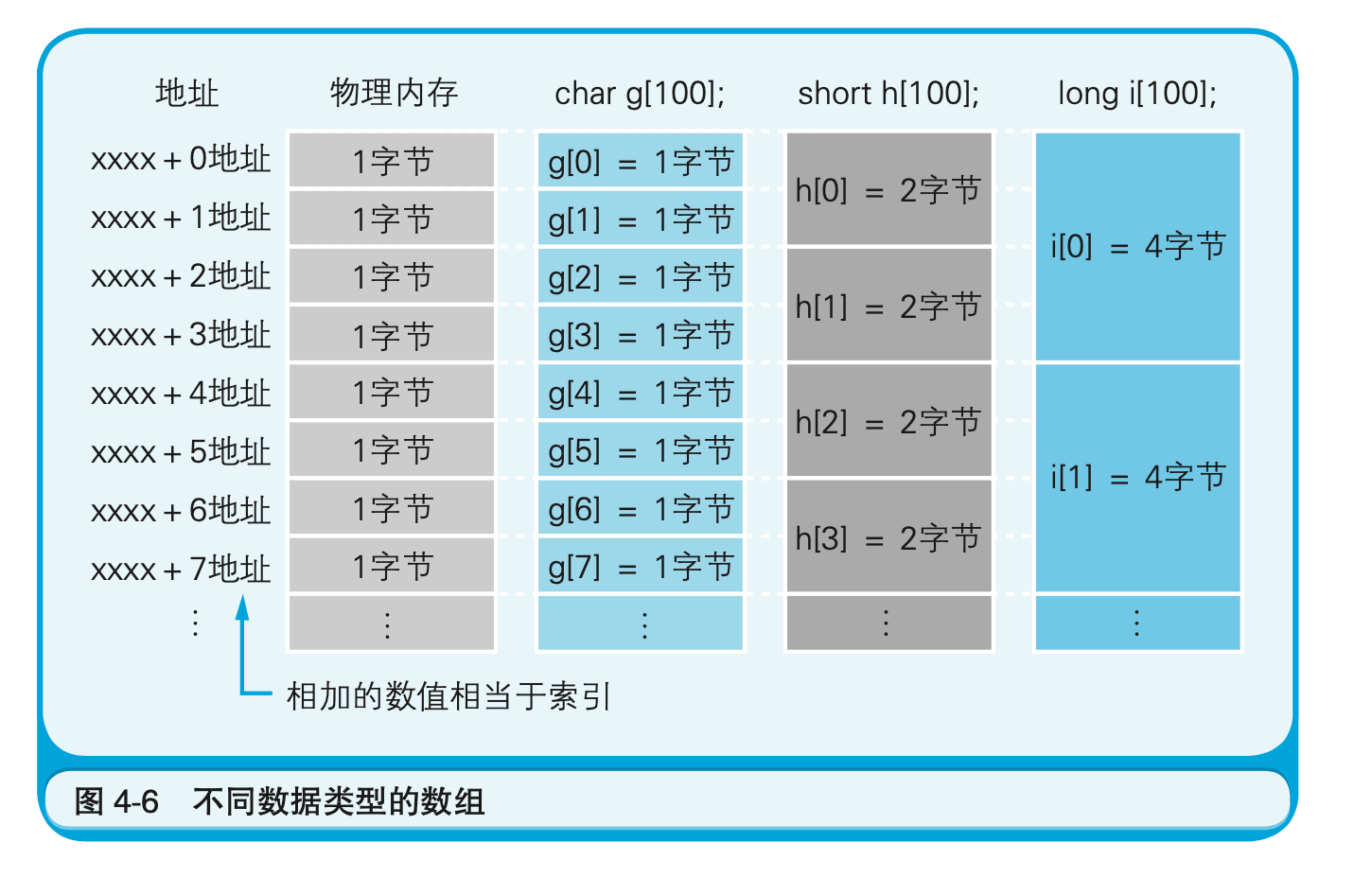
代码清单4-3表示的是在C语言中定义char类型、short类型和long类型这三个数组。

数组的定义中所指定的数据类型,也表示一次能够读写的内存大小。数组是使用内存的基本。之所以这么说,是因为数组和内存的物理构造是一样的。特别是1字节类型的数组,它和内存的物理构造完全一致。
5.栈、队列以及环形缓冲区
栈$^1$和队列,都可以不通过指定地址和索引来对数组的元素进行读写。需要临时保存计算过程中的数据、连接在计算机上的设备或者输入输出的数据时,都可以通过这些方法来使用内存。如果每次保存临时数据都需指定地址和索引,程序就会变得比较麻烦,因此要加以改进。
- 这里所说的栈并不是函数调用时使用的栈,而是指程序员自身做成的LIFO形式的数据存储方式(该栈的实体是数组)。
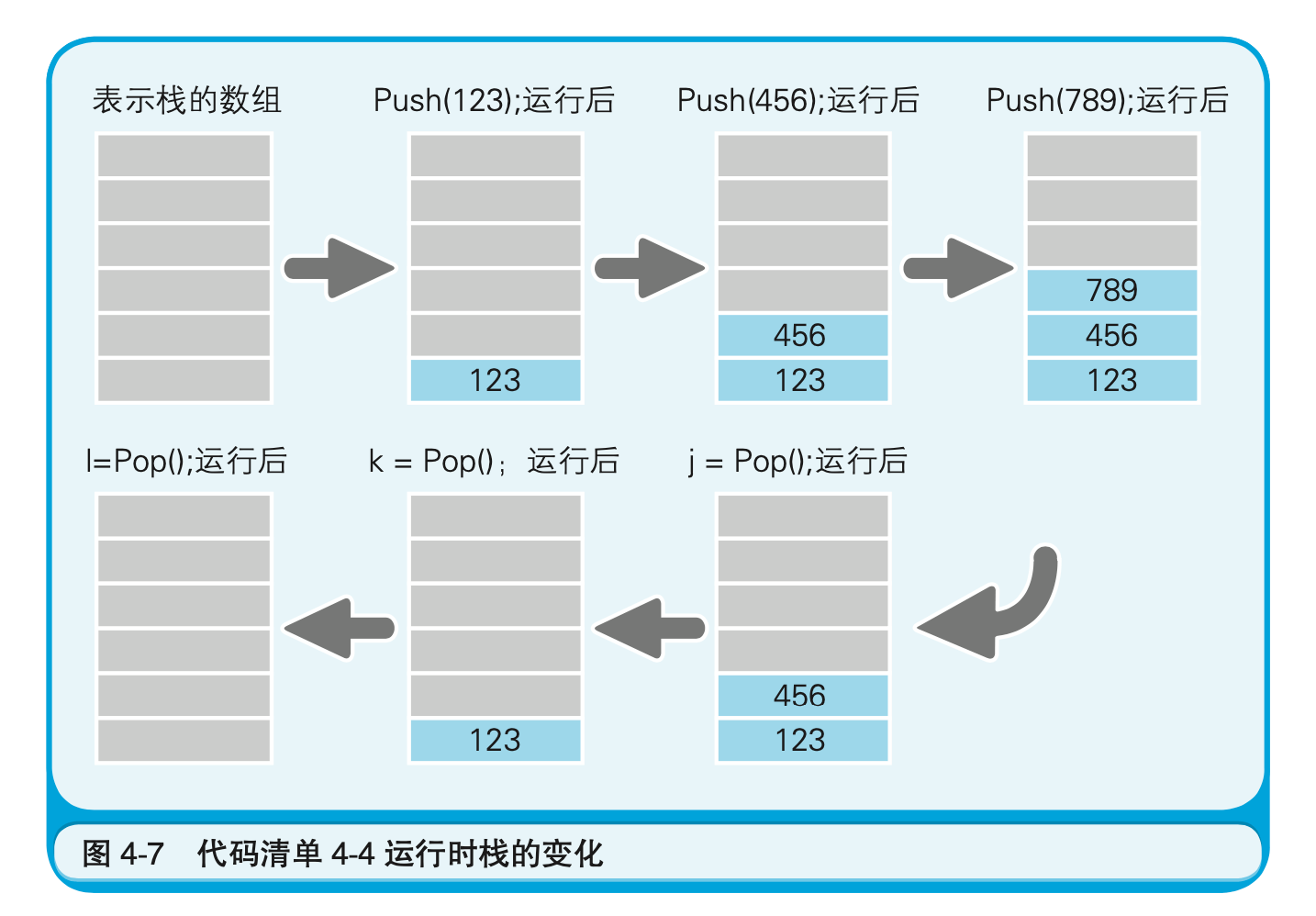
栈和队列的区别在于数据出入的顺序是不同的。在对内存数据进行读写时,栈用的是LIFO(Last Input First Out,后入先出)方式,而队列用的则是FIFO(First Input First Out,先入先出)方式。如果我们在内存中预留出栈和队列所需要的空间,并确定好写入和读出的顺序,就不用再指定地址和索引了。
如果要在程序中实现栈和队列,就需要以适当的元素数来定义一个用来存储数据的数组,以及对该数组进行读写的函数对。当然,在这些函数的内部,对数组的读写会涉及索引的管理,但从使用函数的角度来说,就没有必要考虑数组及索引了。
这里,我们暂且把往栈中写入数据的函数命名为Push$^1$,把从栈中读出数据的函数命名为Pop,把往队列中写入数据的函数命名为EnQueue,把从队列中读出数据的函数命名为DeQueue。
- 汇编语言中有push和pop两个指令,但这里指的是程序员为了以LIFO形式对数组进行读写而做成的Push函数和Pop函数。


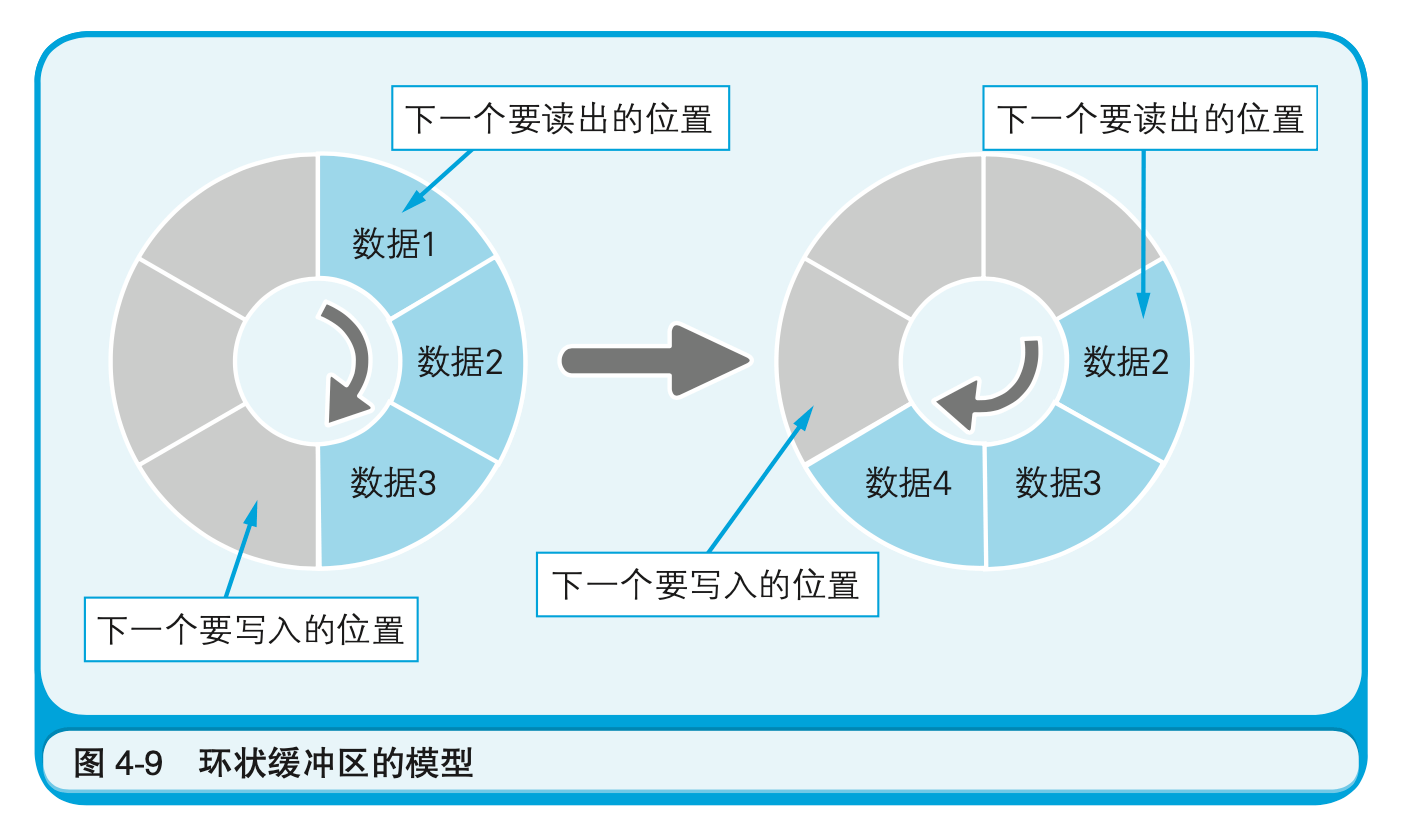
队列一般是以环状缓冲区(ring buffer)的方式来实现的。假设我们要用有6个元素的数组来实现一个队列。这时可以从数组的起始位置开始有序地存储数据,然后再按照存储时的顺序把数据读出。在数组的末尾写入数据后,后一个数据就会被写入数组的起始位置(此时数据已经被读出所以该位置是空的)。这样,数组的末尾就和开头连接了起来,数据的写入和读出也就循环起来了(图4-9)。
6.链表使元素的追加和删除更容易
其他博文对链表的介绍:链表。
通过使用链表,可以更加高效地对数组数据(元素)进行追加和删除处理。而通过使用二叉查找树,则可以更加高效地对数组数据进行检索。
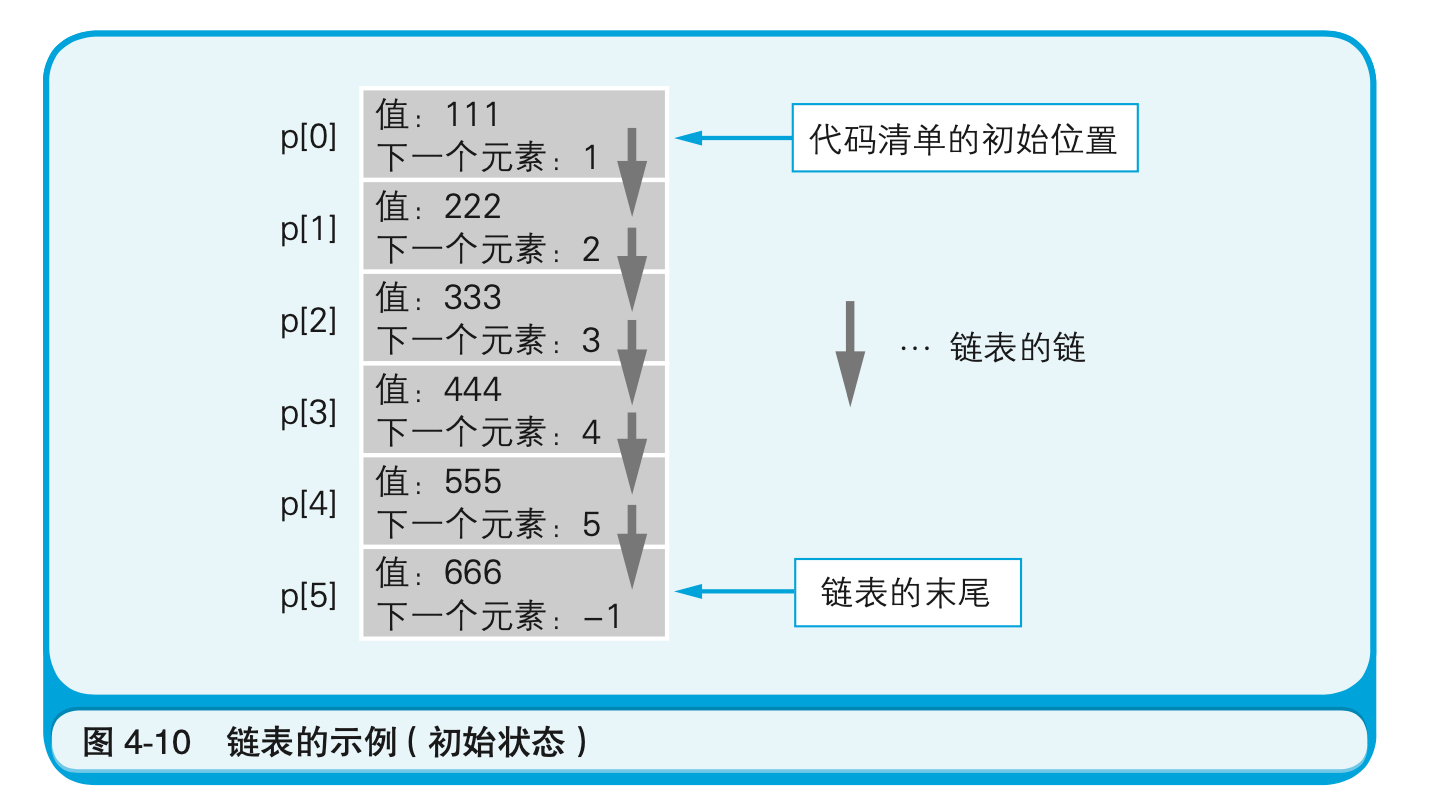
由于链表末尾的元素没有后续的数据,因此就需要用别的值(在这里是-1)来填充(图4-10)。
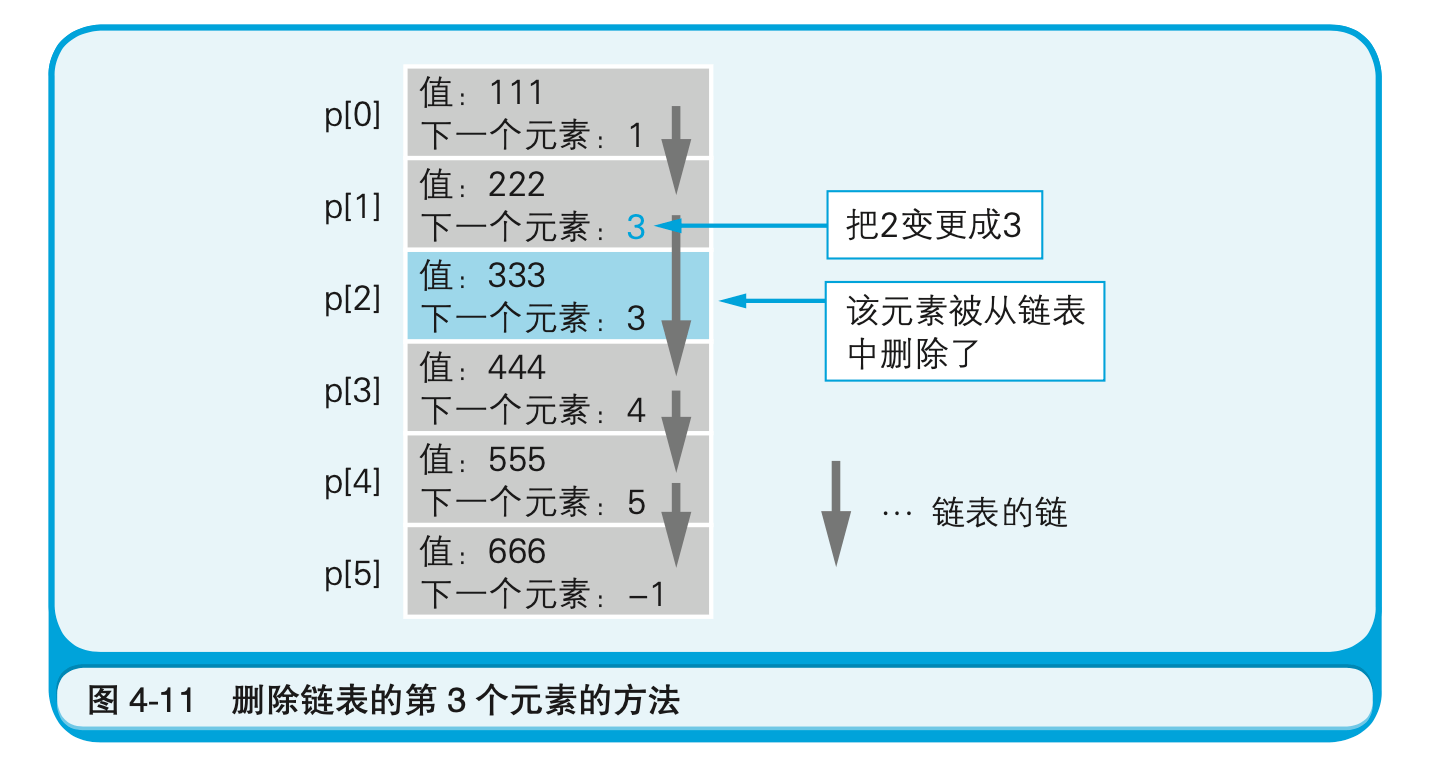
虽然第3个元素在物理内存上还残留着,但在逻辑上则确实被删除了(图4-11)。
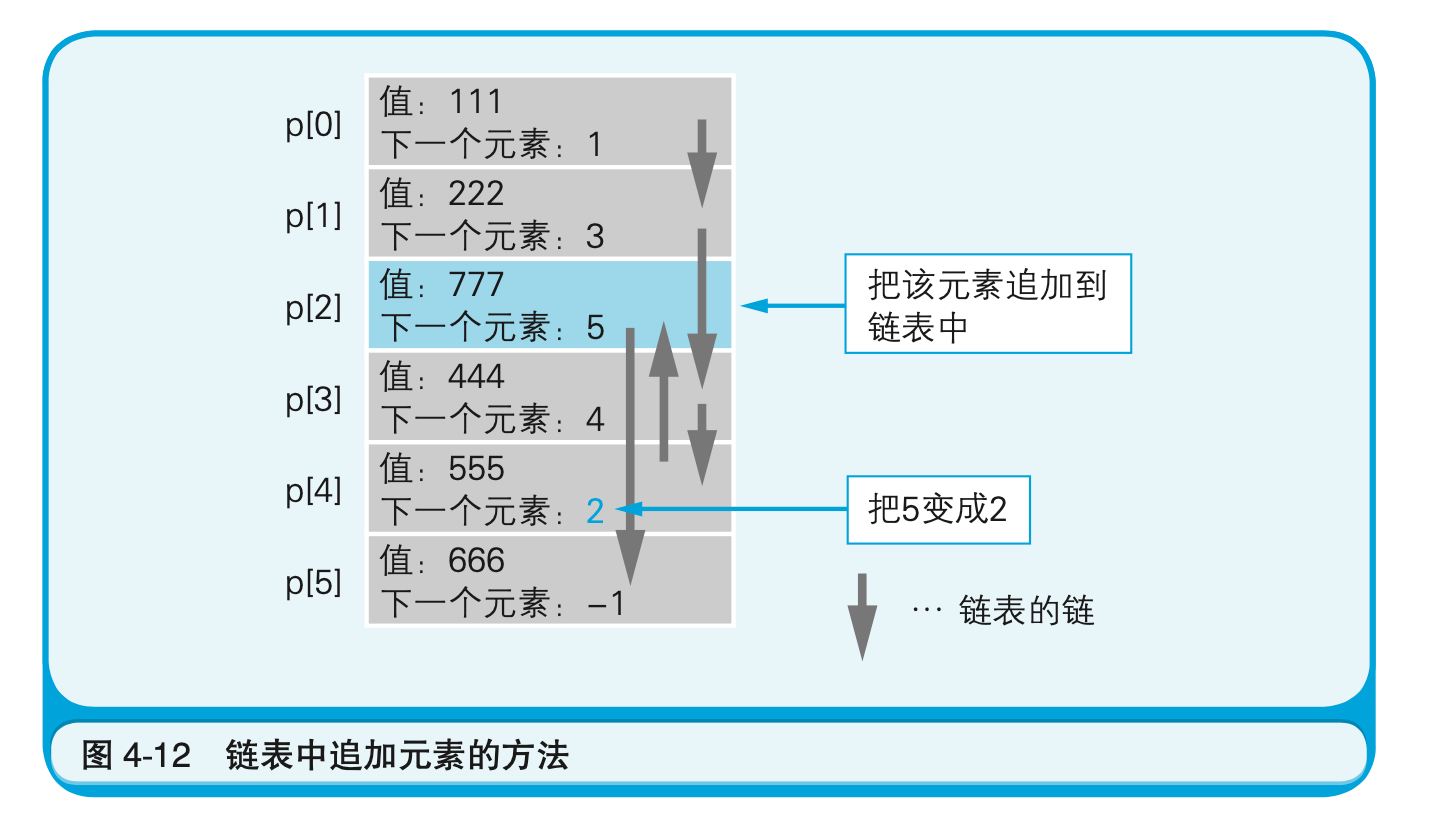
虽然新追加的元素在物理上是第3个,但从逻辑上看来则是第5个(图4-12)。
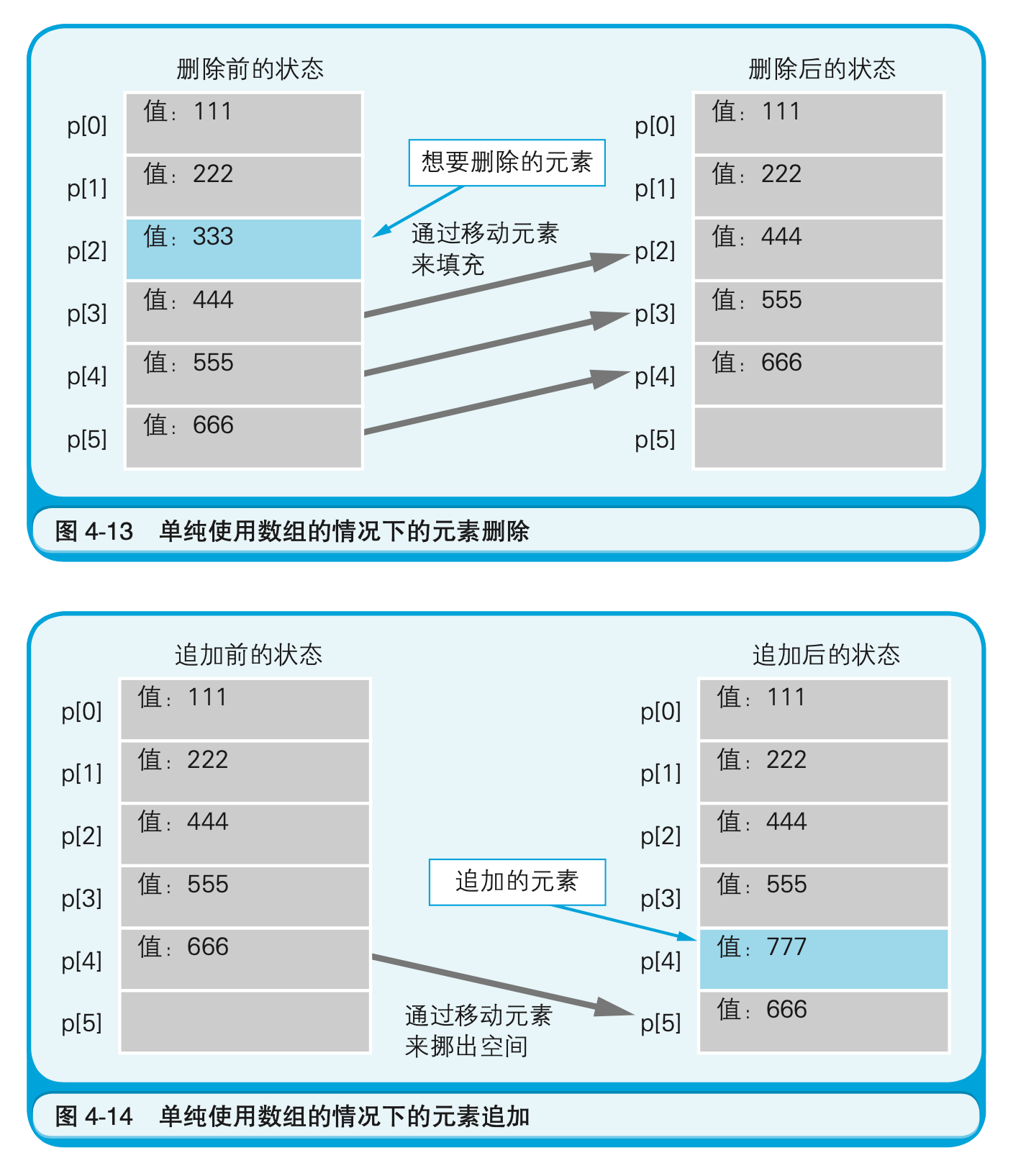
如果不使用链表数组,那么中途删除或追加元素时,其后的元素就必须要全部移动。如果每次都需要移动数千至数万个元素,那么哪怕是高速计算机也会花费很长时间(图4-13、图4-14)。
7.二叉查找树使数据搜索更有效
二叉查找树是指在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。但实际的内存并不会分成两个方向,这是在程序逻辑上实现的(图4-15)。
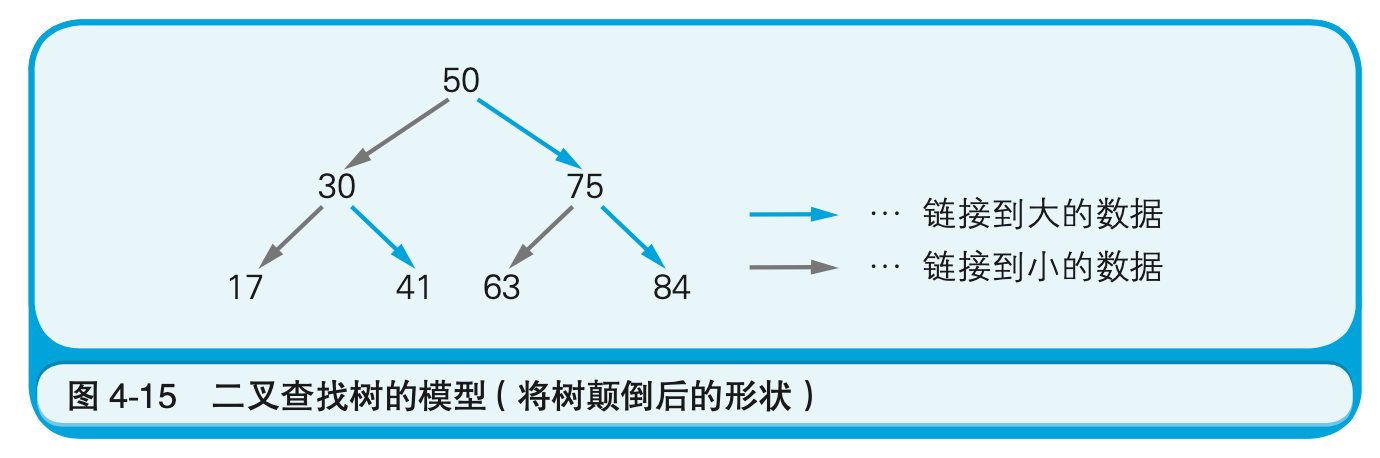
为了实现二叉查找树,怎么处理比较好呢?其实数组的每个元素中只要有数据的值和两个索引信息就可以了。图4-16向我们展示了如何用数组来实现图4-14中的二叉查找树。二叉查找树是由链表构造发展而来的表现形式,因此在追加或删除元素方面也同样是有效的。
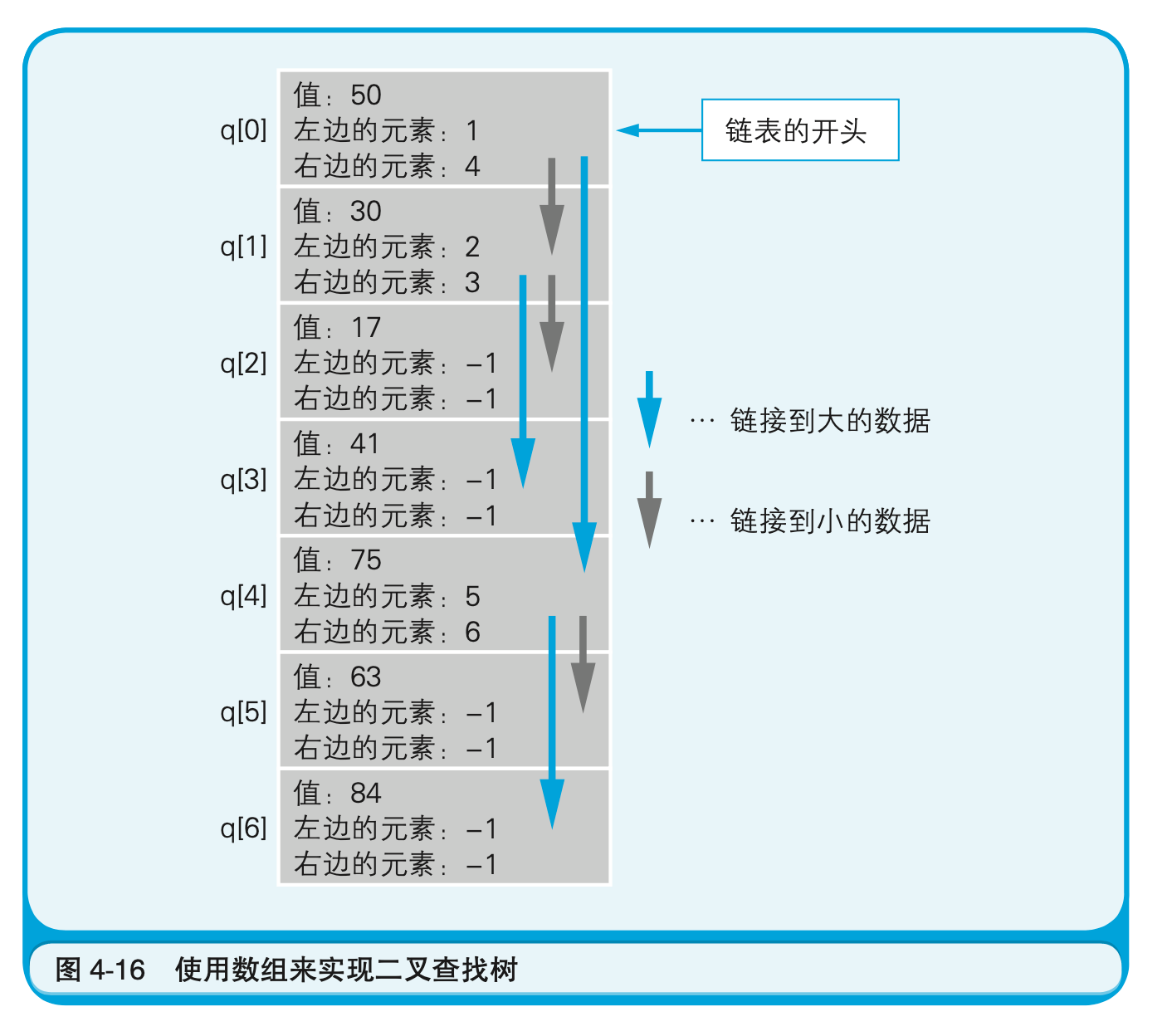
使用二叉查找树的便利之处在于可以使数据的搜索等更有效率。
