本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
我们提出了mlpconv层,其和传统的线性卷积层的比较见Fig1。mlpconv层和传统的线性卷积层都是将局部感受野映射到了输出特征向量。但不同之处在于,mlpconv使用了多层感知器(multilayer perceptron,MLP),其包含多个全连接层和非线性激活函数。而我们提出的方法NIN(Network In Network)的总体结构就是多个mlpconv层的堆叠。
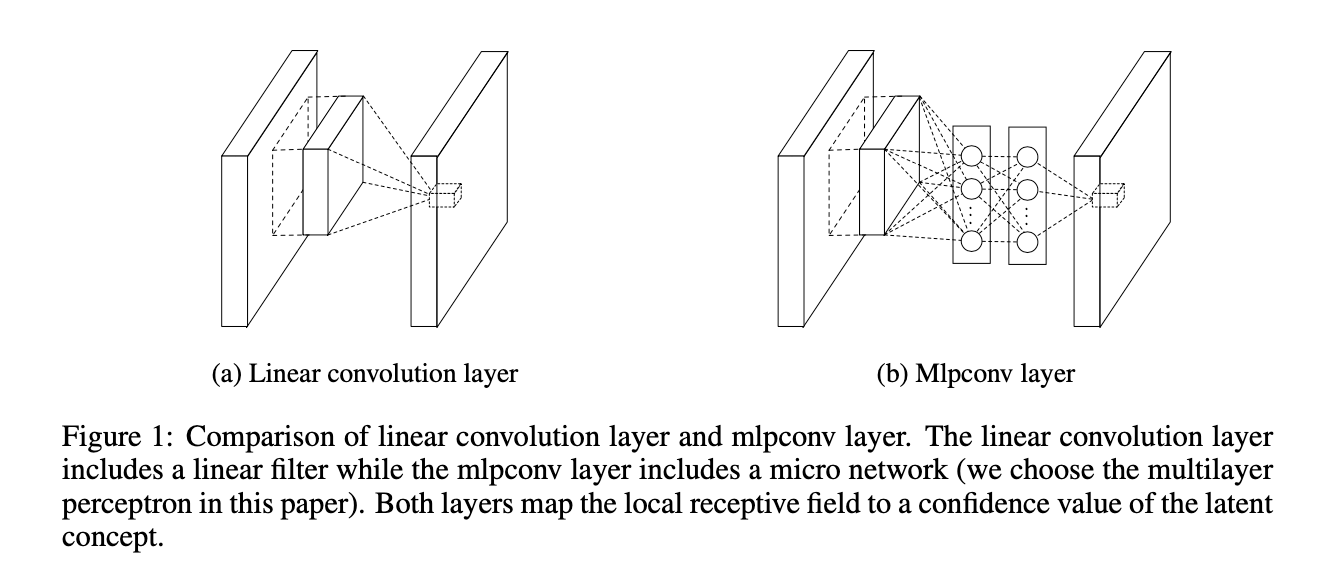
此外,我们没有在CNN中采用传统的全连接层进行分类,而是通过在最后一个mlpconv层后接一个全局平均池化层(global average pooling layer)来得到类别的置信度,然后将得到的向量输入到softmax层。相比全连接层,使用全局平均池化更具有意义和可解释性,并且全连接层容易过拟合(很依赖dropout正则化),而全局平均池化本身就是一个结构正则化器,它本身就防止了整个结构的过拟合(因为全局平均池化层没有需要优化的参数,因此就避免了过拟合)。
2.Convolutional Neural Networks
传统的CNN网络由交替堆叠的卷积层和空间池化层组成。卷积层通过线性卷积滤波器生成feature map,然后是非线性激活函数(rectifier,sigmoid,tanh等)。以ReLU激活函数为例,feature map的计算可表示为:
\[f_{i,j,k} = \max (w^T_k x_{i,j},0) \tag{1}\]其中,$(i,j)$是feature map中像素点的坐标,$x_{i,j}$是以$(i,j)$为中心的输入patch,$k$是feature map的通道索引。
3.Network In Network
3.1.MLP Convolution Layers
mlpconv层执行的计算如下:
\[\begin{gather} f_{i,j,k_1}^1 = \max (w_{k_1}^{1^T} x_{i,j} + b_{k_1}, 0) \\ \vdots \\ f_{i,j,k_n}^n = \max (w_{k_n}^{n^T} f_{i,j}^{n-1} + b_{k_n}, 0) \end{gather} \tag{2}\]$n$是MLP的层数。使用ReLU作为激活函数。公式2等效于正常卷积层的级联跨通道参数池化,同时也等效于具有$1\times 1$卷积核的卷积层。
3.2.Global Average Pooling
全局平均池化的思路是在最后一个mlpconv层中,对应分类任务中的每个类别都生成一个feature map,然后取每个feature map的平均值,并将结果直接输入softmax层。
3.3.Network In Network Structure
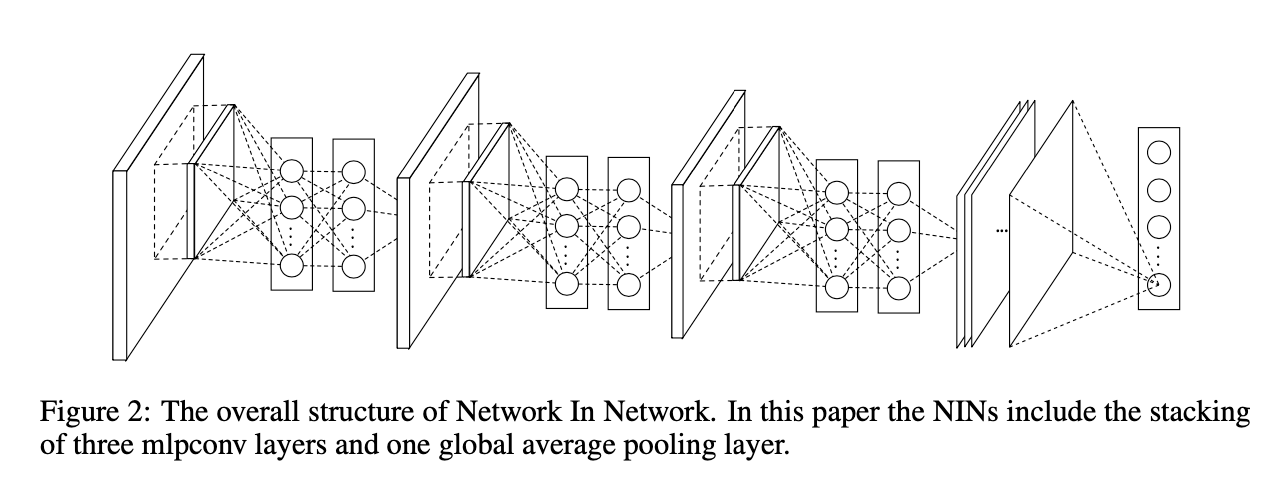
4.Experiments
4.1.Overview
我们在4个benchmark数据集(CIFAR-10,CIFAR-100,SVHN,MNIST)上进行了测试。测试用的NIN都由3个堆叠的mlpconv层组成,mlpconv层后都会跟一个空间最大池化层进行2倍的下采样。除了最后一个mlpconv,其余mlpconv的输出都应用了dropout。除非特殊说明,默认最后都是使用全局平均池化。此外还使用了另一个正则化方式是weight decay。数据集的预处理,训练集和验证集的划分都遵循论文“Ian J Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, and Yoshua Bengio. Maxout networks. arXiv preprint arXiv:1302.4389, 2013.”。
训练策略遵循AlexNet。
4.2.CIFAR-10
CIFAR-10数据集介绍:CIFAR-10数据集。借鉴maxout network,我们也使用了同样的global contrast normalization和ZCA whitening。我们将训练集中的1万张图像分作验证集。
每个mlpconv层feature map的数量和对应的maxout network中的一样。在验证集上微调了两个超参数:局部感受野的大小和weight decay。之后固定这两个超参数不变,在训练集+验证集上从头重新训练了网络。结果见表1。

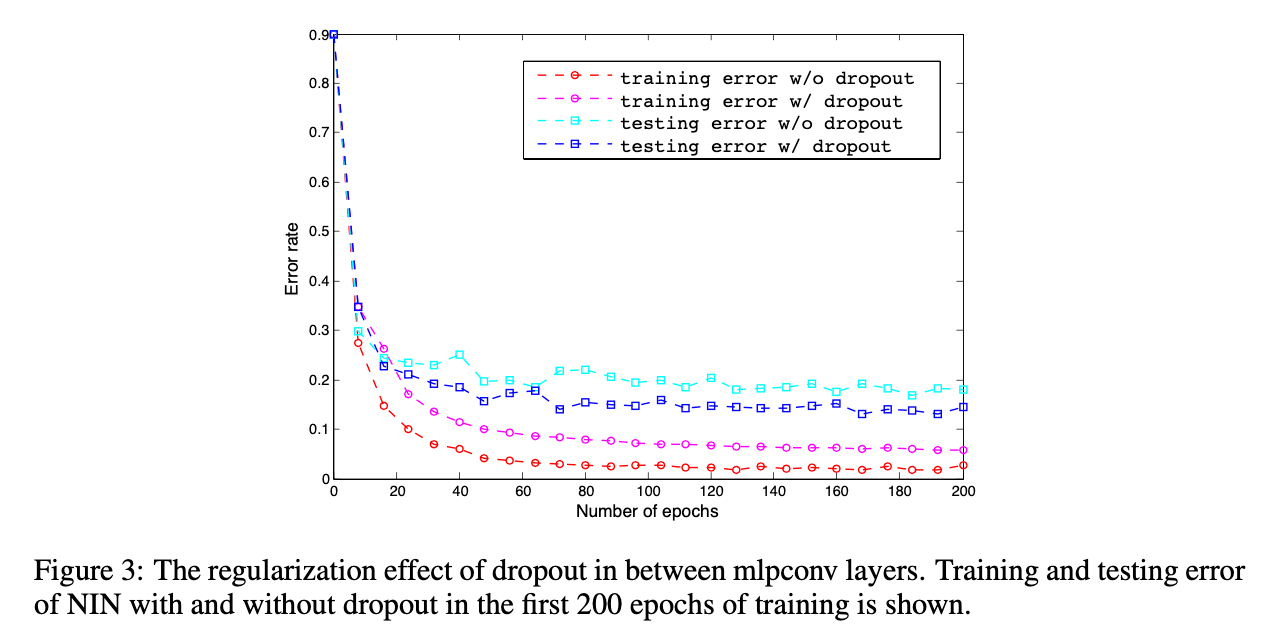
如Fig3所示,在mlpconv层间使用dropout可以有效的提高模型性能。
我们在CIFAR-10数据集上应用了平移和水平翻转这两种数据扩展方式,达到了8.81%的测试误差,取得了SOTA的表现。
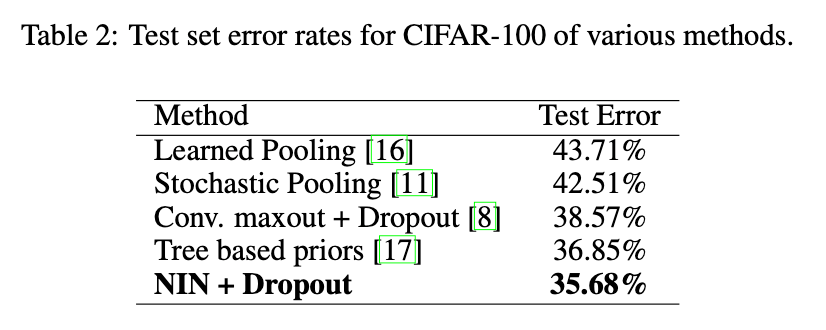
4.3.CIFAR-100
CIFAR-100和CIFAR-10的数据量和数据格式都一样,但是CIFAR-100包含了100个类别。因此,每个类别的图像数量只有CIFAR-10的十分之一。我们使用了和CIFAR-10一样的模型配置,但是没有微调超参数。
4.4.Street View House Numbers
SVHN数据集包括630,420张$32 \times 32$大小的彩色图像,分为训练集、测试集和额外集。该数据集的任务是对位于每个图像中心的数字进行分类。训练和测试流程都遵循maxout network。从训练集的每个类别中抽出400个样本,加上从额外集的每个类别中抽出200个样本组成验证集。剩下的训练集和额外集都用于训练。验证集只用于超参数调优,不参与模型训练。
数据集的预处理也遵循maxout network。在SVHN数据集上测试的模型同样也包含3个mlpconv层和最后的全局平均池化层。

4.5.MNIST
MNIST数据集包含0-9的手写数字图像,图像大小为$28 \times 28$。一共有60,000张训练图像和10,000张测试图像。使用和CIFAR-10一样的网络结构。但是每个mlpconv层生成的feature map数量有所减少。因为MNIST数据集相比CIFAR-10更简单,只需要更少的参数。测试没有使用数据扩展。

4.6.Global Average Pooling as a Regularizer
为了研究全局平均池化的正则化效应,我们将全局平均池化层替换为全连接层,而模型的其他部分保持不变。在CIFAR-10数据集上的评估结果见表5。

4.7.Visualization of NIN
我们将基于CIFAR-10训练的模型的最后一个mlpconv输出的feature map进行了可视化。

5.Conclusions
不再详述。
