本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
识别不同尺度的物体是CV领域中一个基本的挑战。基于图像金字塔得到特征金字塔是这种问题的一个标准解决思路(如Fig1(a)所示)。这一思路在需要手工设计特征的年代非常流行,但是其速度很慢,比如DPM。
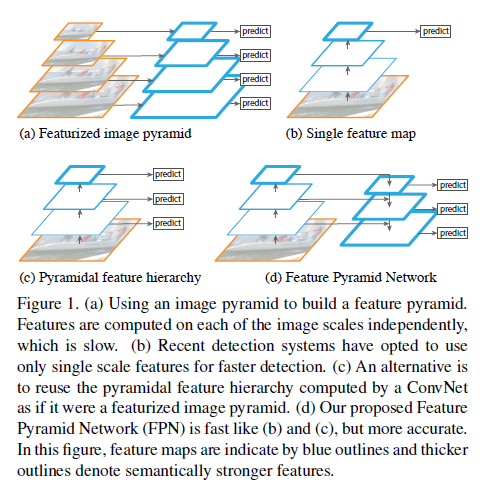
Fig1中蓝框表示feature map,框线越粗表示特征越强。
随着CNN的快速发展,最近一些基于CNN的方法使用如Fig1(b)所示的结构,其采用单尺度输入,速度会更快,比如SPP-net、Fast R-CNN、Faster R-CNN等。SSD则采用了如Fig1(c)所示的结构。而我们提出的FPN(Feature Pyramid Network)的结构如Fig1(d)所示,采用了自顶向下的结构以及横向的skip connection,我们的方法性能更好。采用同样类似结构的还有论文“P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Doll´ar. Learning to refine object segments. In ECCV, 2016.”,但是其只在最精细的feature map上进行了预测,见Fig2上。而我们的方法则是在每个精细度水平上都进行了预测,见Fig2下。
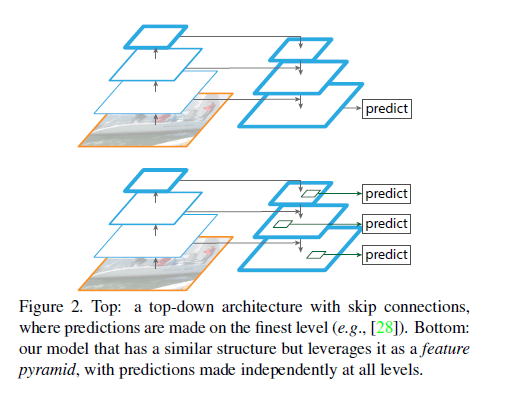
我们的金字塔结构可以在所有尺度上进行端到端的训练,并在训练和测试时保持一致。因此,FPN能够达到SOTA的结果。
2.Related Work
不再详述。
3.Feature Pyramid Networks
FPN是一个通用的理念。我们主要介绍将FPN应用于RPN和Fast R-CNN。
我们的方法可以以任意大小的单尺度图像作为输入,并生成多个level的feature map。这一过程是独立于backbone网络的。我们的金字塔结构包括自下而上的路径、自上而下的路径和横向连接。
👉Bottom-up pathway.
自下而上的路径是backbone卷积网络的前馈计算,每次进行二倍下采样,得到不同尺度的feature map。如果有许多层产生同一大小的feature map,则我们称这些层处在网络的同一阶段(same network stage)。对于我们构建的特征金字塔,其实就是为每个阶段定义一个金字塔级别。我们将基于每个阶段的最后一层的输出来创建我们的金字塔,因为每个阶段的最后一层都理应具有最强的特征。
以ResNet论文中的表1为例,我们取每个阶段最后一个残差块的输出(记为$\{C_2,C_3,C_4,C_5 \}$,分别对应conv2、conv3、conv4、conv5的输出,相较于输入图像的步长分别为$\{ 4,8,16,32 \}$)来构建特征金字塔。我们没有使用conv1的输出,因为其占用了大量内存。
👉Top-down pathway and lateral connections.
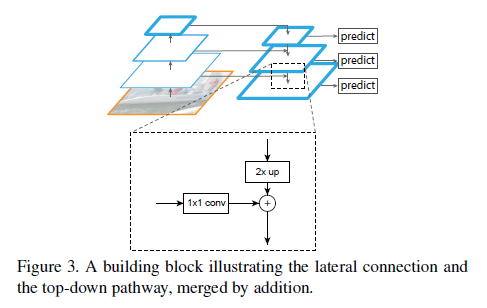
方便起见,2倍上采样可以采用最近邻上采样。通过$1\times 1$卷积降低通道维度。这里的加法使用的是element-wise addition。加完之后再附加一个$3 \times 3$卷积来减少上采样的混叠效应。最终自顶向下得到的一系列feature map可标记为$\{P_2,P_3,P_4,P_5 \}$,分别对应有着同样大小的$\{C_2,C_3,C_4,C_5 \}$。其中,$C_5$到$P_5$同样也是通过一个$1\times 1$卷积。
因为金字塔的所有层级共享一个分类器/回归器,所以我们将所有层级的通道数都固定为$d=256$。自顶向下这些额外的卷积层中没有使用非线性,因为作者发现非线性的影响很小。
4.Applications
4.1.Feature Pyramid Networks for RPN
RPN是一种基于滑动窗口的目标检测器。在原始的RPN设计中,基于一个单尺度的卷积feature map,在上面进行$3\times 3$窗口的密集滑动,其实就是执行一个$3\times 3$卷积,后面接两个并行的$1\times 1$卷积,一个用来分类,一个用来回归,我们把这个结构称为“头”。
我们可以把RPN替换为FPN。我们把“头”($3\times 3$卷积和两个并行的$1\times 1$卷积)附加在特征金字塔的每一个层级中。这样窗口就相当于是在金字塔的所有层级上密集滑动,我们就不再需要构建多尺度(即不同面积)的anchor了。因此,对于$\{P_2,P_3,P_4,P_5,P_6 \}$中的每个层级,anchor都只有一个对应的尺度,分别为$\{ 32^2, 64^2, 128^2, 256^2, 512^2 \}$。但是对于每个层级,anchor的长宽比依然有三个$\{ 1:2, 1:1, 2:1 \}$。所以我们一共使用了15种anchor。
这里的$P_6$是为了cover更大的anchor尺度$512^2$。$P_6$就是$P_5$的二倍下采样。在4.2部分没有使用$P_6$。
anchor的训练标签通过其与GT的IoU来确定。如果anchor和GT的IoU大于0.7,则认为是正样本,如果IoU小于0.3则认为是负样本。
需要注意的是,特征金字塔所有层级的“头”是共享参数的,我们也尝试了不共享参数,但是准确率区别不大。共享参数的良好性能表明,我们金字塔的所有层级共享相似的语义级别。
4.2.Feature Pyramid Networks for Fast RCNN
Fast R-CNN是一个基于region的目标检测器,其通过RoI pooling layer来提取特征。Fast R-CNN通常在单尺度feature map上执行。如果要和FPN一起使用,我们需要将不同尺度的RoI分配给金字塔的不同层级。
我们将$width=w,height=h$(在网络的输入图像上)的RoI分配给特征金字塔的$P_k$层级,其中$k$的计算公式为:
\[k = \lfloor k_0 + \log _2 ( \sqrt{wh} / 224 ) \rfloor \tag{1}\]其中,224是ImageNet预训练图像大小,$k_0$是$w\times h=224^2$的RoI应该映射到的目标层级。类似于基于ResNet的Faster R-CNN使用$C_4$作为单尺度feature map,我们设$k_0=4$。根据式(1),如果RoI的尺度很小(比如224的$\frac{1}{2}$),那这个RoI应该映射到更精细的层级(即$k=3$)。
我们将预测器头(在Fast R-CNN中,预测器头是一个特定的分类器和一个bounding box回归器)添加到了所有层级的所有RoI上。无论哪个层级,预测器头都是共享参数的。和Fast R-CNN一样,我们使用RoI pooling来提取$7 \times 7$个特征,后接两个1024-d的全连接层(ReLU激活函数),最后是预测器头。这些层都是随机初始化的。
5.Experiments on Object Detection
我们在80个类别的COCO目标检测数据集上进行了测试。我们训练使用了80k的训练集图像和35k的验证集(trainval35k)图像,在5k的minival数据集上进行了消融实验,在标准的测试集(test-std)上汇报了最终结果。
所有的backbone网络都在ImageNet1k分类数据集上进行了预训练,然后在检测数据集上进行了fine-tune。我们使用可以公开获得的预训练好的ResNet-50和ResNet-101(见github链接)。我们使用Caffe2重新实现了py-faster-rcnn。
5.1.Region Proposal with RPN
我们使用COCO风格的AR(Average Recall)作为评估指标。$AR_s,AR_m,AR_l$分别表示在小型(small)、中型(medium)、大型(large)目标上的AR。对于每张图像,我们分别汇报了100个和1000个proposal的结果($AR^{100}$和$AR^{1k}$)。
👉Implementation details.
所有的框架见表1,训练都是端到端的。输入图像通过resize使得短边为800个像素。使用同步SGD,在8块GPU上进行训练。每块GPU的mini-batch都包含2张图像,每张图像有256个anchor。weight decay=0.0001,momentum=0.9。前30k个mini-batch的学习率为0.02,接下来10k个mini-batch的学习率为0.002。和Faster R-CNN不同,在所有的RPN(包括baseline)的实验中,我们没有排除超过图像边界的anchor。其余实现细节都和Faster R-CNN一样。一共在8块GPU上训练了8个小时。

5.1.1.Ablation Experiments
👉Comparisons with baselines.
为了公平的和原始RPN进行比较,我们选择了2个baseline(见表1(a,b)),使用的是ResNet-101中$C_4$或$C_5$(即第四个残差块conv4_x或第五个残差块conv5_x)输出的单尺度feature map,全都使用一样的超参数设置(包括5种尺度的anchor:$\{ 32^2, 64^2, 128^2, 256^2, 512^2 \}$)。表1(b)并没有优于表1(a),说明单个更高级别的feature map是不够的。
在RPN中添加FPN(表1(c)),$AR^{1k}$为56.3,相比表1(a)提升了8.0。此外,在小型目标上,表1(c)的$AR_s^{1k}$相比表1(a)提升了12.9。FPN的加入大大提高了RPN对目标尺度变化的鲁棒性。
👉How important is top-down enrichment?
表1(d)展示了我们的方法在去掉自顶向下路径后的结果,整体的结构更像Fig1(b)。表1(d)的结果和baseline持平,但远差于我们提出的方法。
👉How important are lateral connections?
表1(e)是取消了$1\times 1$横向连接的结果。
👉How important are pyramid representations?
我们尝试了将预测头只添加到最精细的feature map上(比如$P_2$),见表1(f)。和单尺度baseline类似,我们把所有anchor都分配给了$P_2$。表1(f)的表现优于baseline,但还是比不上我们提出的方法。
此外,因为$P_2$有着较大的空间分辨率,所以单独使用$P_2$进行预测会有更多的anchor(750k个)。这也说明更多的anchor并不足以提高精度。
5.2.Object Detection with Fast/Faster R-CNN
接下来我们测试了在region-based(非滑动窗口)的检测器上使用FPN。我们使用COCO风格的AP(Average Precision)和PASCAL风格的AP(单个IoU阈值为0.5)来评估目标检测的结果。我们在COCO数据集上汇报了在小型(small)、中型(medium)和大型(large)目标上的AP结果(即$AP_s,AP_m,AP_l$)。
👉Implementation details.
将输入图像的短边resize到800个像素。使用同步SGD,在8块GPU上训练模型。每块GPU的每个mini-batch包含2张图像,每张图像有512个RoI。weight decay=0.0001,momentum=0.9。前60k个mini-batch的学习率为0.02,后20k个mini-batch的学习率为0.002。训练时,每张图像使用2000个RoI,测试时每张图像使用1000个RoI。在COCO数据集上训练Fast R-CNN+FPN用了10个小时。
5.2.1.Fast R-CNN (on fixed proposals)
为了更好的研究FPN对region-based检测器的影响,我们在消融实验中固定了proposal的数量。我们固定表1(c)所生成的proposal。除非特殊说明,为了简化实验,Fast R-CNN和RPN之间没有共享feature。
使用基于ResNet的Fast R-CNN作为baseline。结果见表2。

注意,这里表2(a)的预测头的隐藏层用的是conv5,而其他模型用的都是2个全连接层。表2(c)的表现优于表2(a)和表2(b),这说明我们提出的特征金字塔要优于单尺度的feature map。
5.2.2.Faster R-CNN (on consistent proposals)
在Faster R-CNN上的实验见表3。

表3(*)是ResNet原文中实现的ResNet-50+Faster R-CNN。我们复现的结果见表3(a)和表3(b),比原始实现的性能高了很多,我们认为原因有以下几点:
- 我们将输入图像的短边resize到800个像素,而不是600个像素。
- 在训练时,每张图像使用了512个RoI,这能更快的收敛。原始实现用的是64个RoI。
- 我们使用了5种尺度的anchor,原始实现只使用了4种,我们新加了$32^2$。
- 在测试阶段,我们每张图像使用了1000个proposal,而原始实现只使用了300个。
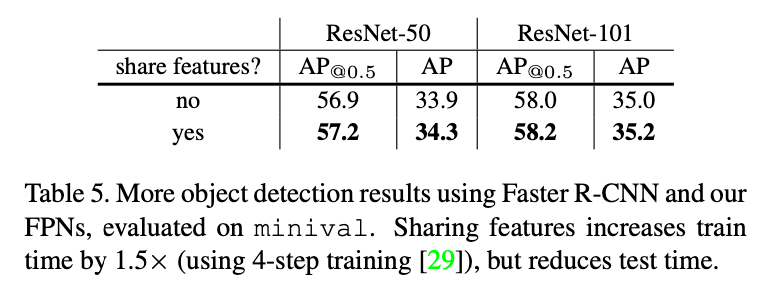
👉Sharing features.
在之前的章节中,为了简化,RPN和Fast R-CNN之间没有共享feature。在表5中,我们按照Faster R-CNN中的4步训练法共享了feature。从表5中可以看出,共享feature不仅可以提高精度,还能降低测试时间。
👉Running time.
在单个NVIDIA M40 GPU上,FPN+ResNet-50+Faster R-CNN一张图像的推理时间是0.148秒,FPN+ResNet-101+Faster R-CNN一张图像的推理时间是0.172秒。作为对比,表3(a)推理一张图像的时间是0.32秒。
5.2.3.Comparing with COCO Competition Winners
我们发现表5的ResNet-101模型在默认学习率策略下没有得到充分的训练。因此我们在训练Fast R-CNN的步骤中,将每个学习率的mini-batch数量翻倍。这一改动使得在不共享feature的情况下,在minival上的AP就增加到了35.6。这也是我们在表4中使用的模型,因为时间关系,我们没有使用共享feature的模型。
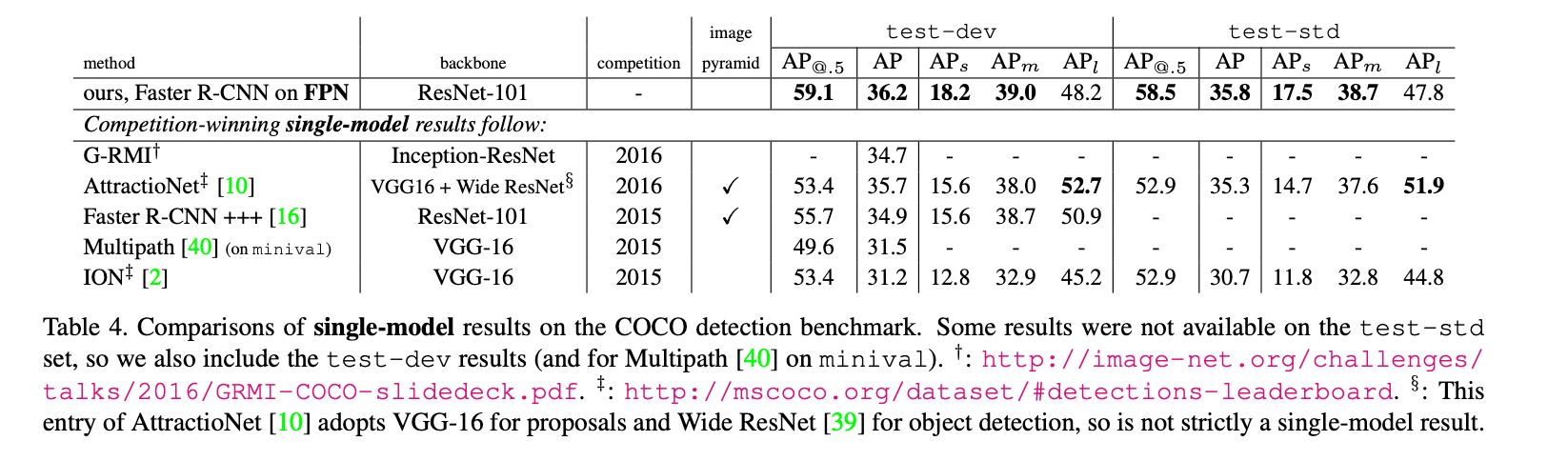
6.Extensions: Segmentation Proposals
我们将FPN应用于DeepMask/SharpMask框架,执行分割任务。
DeepMask/SharpMask在image crop上进行训练,来预测实例分割和是否为目标的分数。在推理时,生成dense proposal。为了生成不同尺度的分割,图像金字塔通常是必需的。
FPN可以很容易的被调整来生成mask proposal。我们使用全卷积设置来进行训练和推理。我们按第5.1部分的方式构建了特征金字塔,并设$d=128$。在特征金字塔每个层级的顶部,在一个$5 \times 5$的滑动窗口上,以全卷积的方式(MLP,只不过都是卷积层)预测得到一个$14 \times 14$的mask和一个目标分数,见Fig4。此外,DeepMask/SharpMask在图像金字塔中每个octave上都使用了2种尺度,所以我们也使用了第二个MLP,接在一个$7 \times 7$滑动窗口的后面。这两个MLP的作用就像RPN中的anchor。框架是端到端训练的,全部的实现细节见附录。
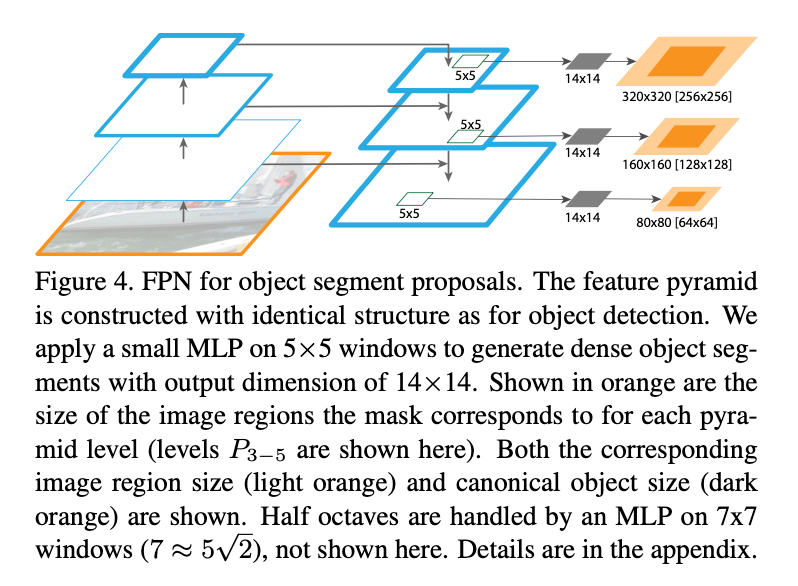
Fig4中的橙色是每个金字塔层级(此处显示的是$P_{3-5}$层级)的mask所对应的图像区域的大小。浅橙色是对应的图像区域大小,深橙色是目标大小。
6.1.Segmentation Proposal Results
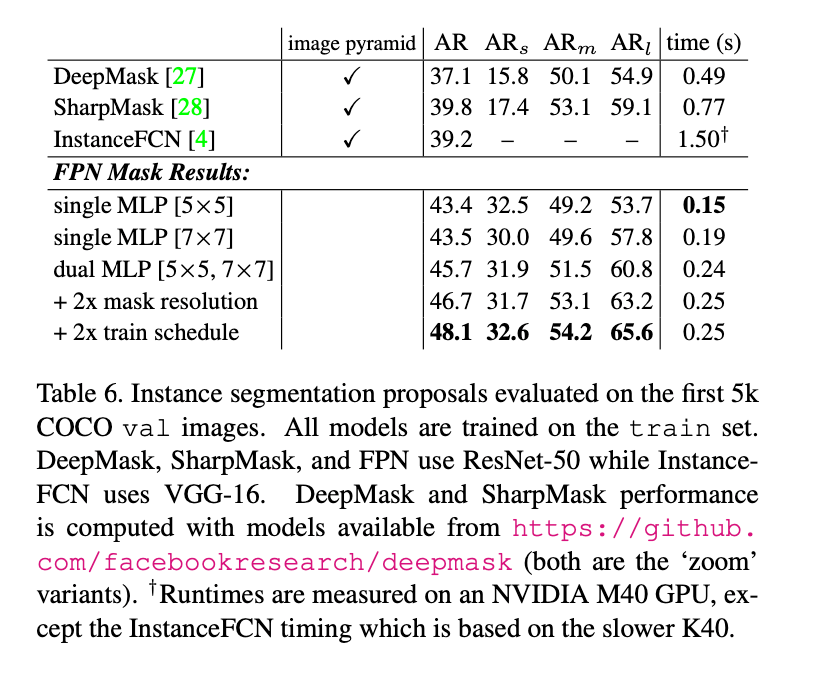
结果见表6。我们汇报了1000个proposal的分割AR。将mask的输出大小从$14\times 14$增加到$28 \times 28$提升了AR(更大反而会导致精度下降)。将训练迭代次数翻倍把AR提升到了48.1。
我们提出的方法相比之前的SOTA方法(DeepMask、SharpMask、InstanceFCN),不仅精度更高而且速度更快。这些结果表明,我们的模型是一个通用的特征提取器,可以取代图像金字塔来解决其他多尺度检测问题。
7.Conclusion
不再赘述。
8.Appendix.A.Implementation of Segmentation Proposals
我们使用我们提出的特征金字塔网络来有效的生成对象分割proposal,采用以图像为中心的训练策略。我们的FPN mask生成模型继承了DeepMask/SharpMask的许多idea。但是,与这些在image crop上进行训练并使用密集采样的图像金字塔进行推理的模型不同,我们在特征金字塔上进行全卷积训练以进行mask预测。虽然这需要更改许多细节,但我们的实现仍然和DeepMask相似。具体来说,为了在每个滑动窗口上定义mask实例的标签,我们将此窗口视为输入图像上的crop,从而允许我们从DeepMask继承正/负样本的定义。
我们使用和第5.1部分一样的框架来构建特征金字塔($P_{2-6}$)。我们设$d=128$。特征金字塔的每个层级都用于预测不同尺度的mask。和DeepMask一样,我们将mask的尺度定义为其width和height的最大值。在$5 \times 5 $ MLP上,$\{32,64,128,256,512 \}$尺度的mask分别对应层级$\{P_2,P_3,P_4,P_5,P_6 \}$。在$7 \times 7$ MLP上,不同层级对应的mask尺度会再乘上一个$\sqrt{2}$,比如$P_4$对应的mask尺度是$128 \sqrt{2}$。中间尺度的目标被匹配到在对数空间中最接近的尺度上。
由于在金字塔的每一层级上,MLP只能预测一定尺度范围内的目标,因此需要对目标进行padding。我们使用了25%的padding。对于$5 \times 5$ MLP,层级$\{P_2,P_3,P_4,P_5,P_6 \}$对应的mask尺度分别为$\{ 40,80,160,320,640 \}$。同样的,对于$7 \times 7$ MLP,尺度再乘个$\sqrt{2}$。
feature map中的每个空间位置都用于预测不同位置的mask。具体来说就是,在$P_k$上,feature map上的每个空间位置用于预测中心位于该位置$2^k$个像素范围内的mask(这样的话,对应于feature map刚好是$\pm 1$个cell的偏移)。如果没有目标的中心落在此范围内,则该位置被视为负样本,并且和DeepMask中一样,仅用于训练分数分支,而不用于训练mask分支。
我们用于预测mask和分数的MLP相当简单。我们使用512个$5 \times 5$的卷积核,后面跟两个并行的FC层,一个输出大小为$14^2$,用来预测$14 \times 14$的mask;一个输出大小为1,用来预测目标分数。模型通过全卷积的方式实现(使用$1\times 1$卷积代替FC层)。$7 \times 7$ MLP使用的结构和$5 \times 5$ MLP一样。
在训练过程中,mini-batch size=2048(16张图像,每张图像128个样本),一个batch内正负样本比例为1:3。mask loss的权重是score loss的10倍。在8块GPU上进行端到端的训练,使用同步SGD(每块GPU两张图像)。前80k个mini-batch的学习率为0.03,后60k个mini-batch的学习率为0.003。在训练和测试时,将图像尺度设为800个像素(我们没有使用scale jitter)。在推理阶段,我们的模型对所有位置和尺度都预测分数,并在1000个分数最高的位置设置mask。我们没有使用NMS或后处理。
