本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Ultralytics YOLOv5 Architecture
YOLOv5没有发表官方论文。官方github地址:yolov5。本博文参考官方文档,因为YOLOv5还在不断的更新,本博文介绍的是YOLOv5的v6.0/6.1版本。
2.Model Structure
YOLOv5框架包含3个主要部分:
- Backbone:使用了一个新的CSP-Darknet53网络。
- Neck:使用了SPPF和一个新的CSP-PAN结构。
- Head:用的依旧是YOLOv3 Head。
YOLOv5整体结构见下:
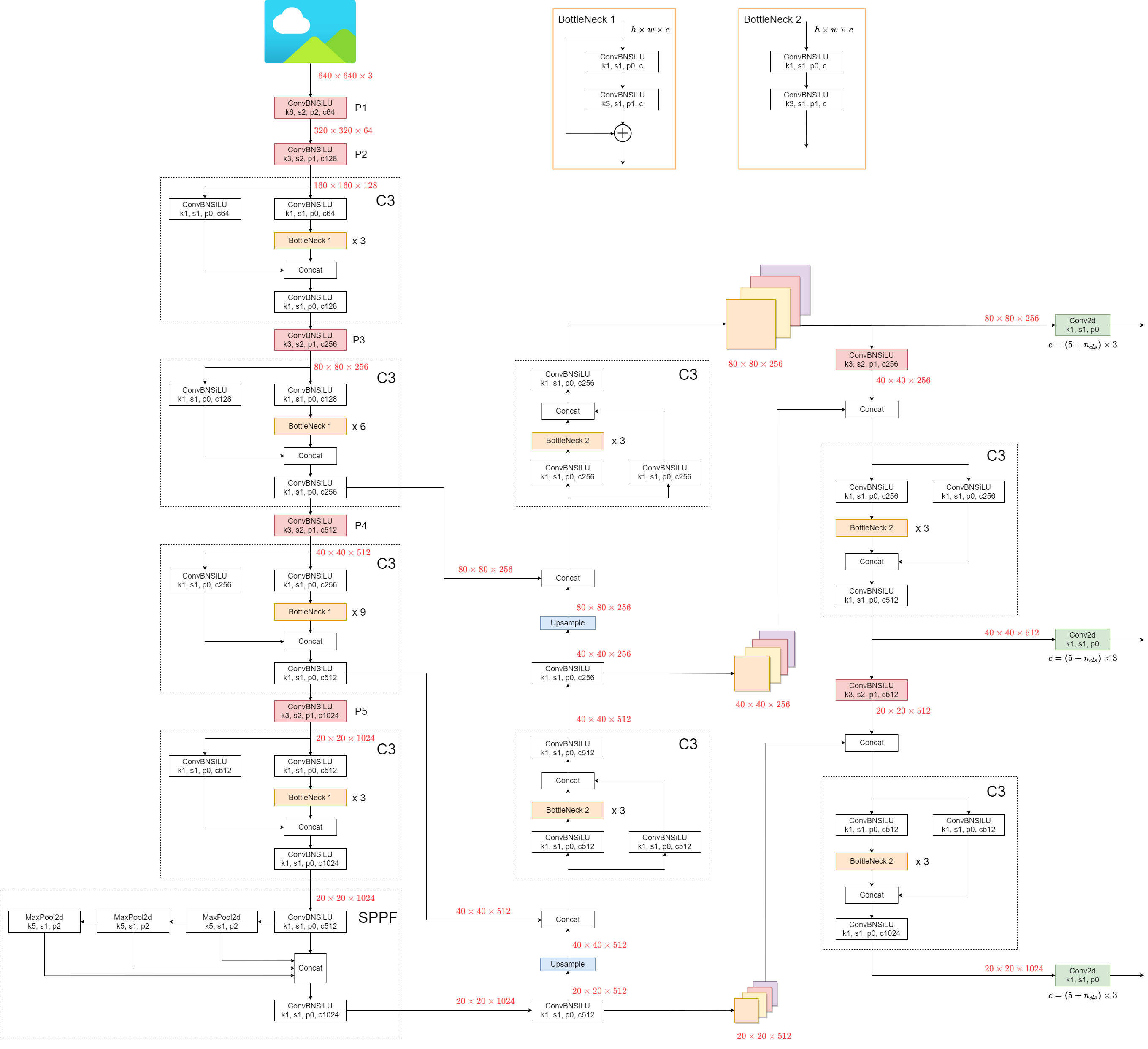
接下来逐一介绍下需要注意的点。
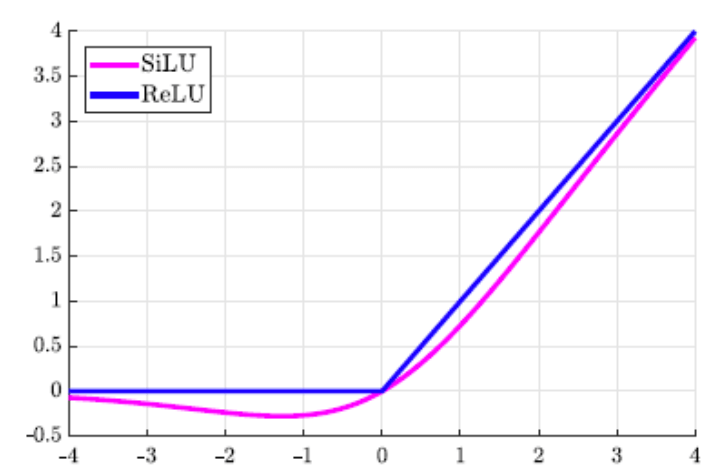
“ConvBNSiLU”表示卷积层+BN+SiLU激活函数。SiLU的全称是:Sigmoid Linear Unit,公式为:
\[f(x) = x \cdot sigmoid(x) = \frac{x}{1+e^{-x}}\]SiLU激活函数和ReLU激活函数的比较见下:
“k6, s2, p2, c64”是卷积层的参数,“k”是卷积核的大小,“s”指的是步长,“p”是padding的圈数,“c”是输出通道数。
之前的YOLOv5版本中,输入图像一开始会先进入一个Focus结构:
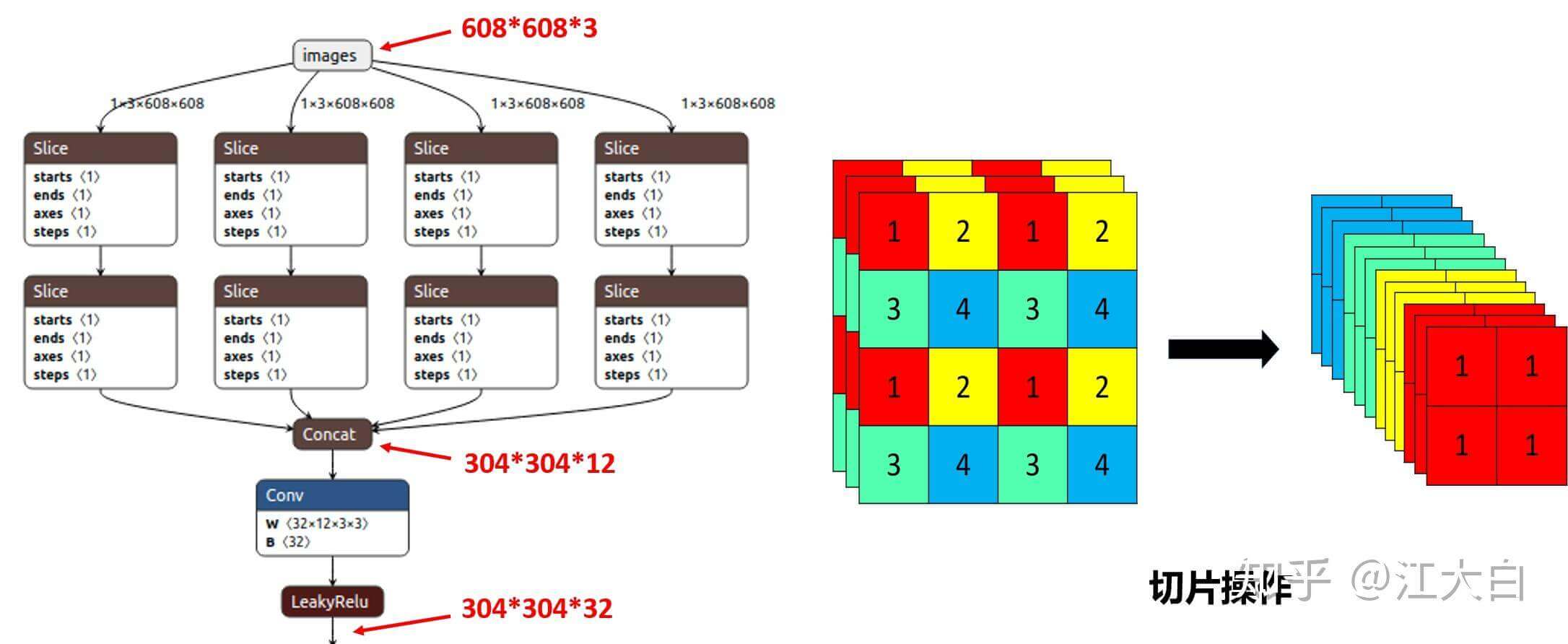
但是在新版YOLOv5中,作者将Focus结构替换成了$6 \times 6$卷积,这一修改提高了效率。
SPPF是基于SPP进行的修改,SPPF的速度比SPP快两倍多。
3.Data Augmentation Techniques
YOLOv5使用的data augmentation方法见下。
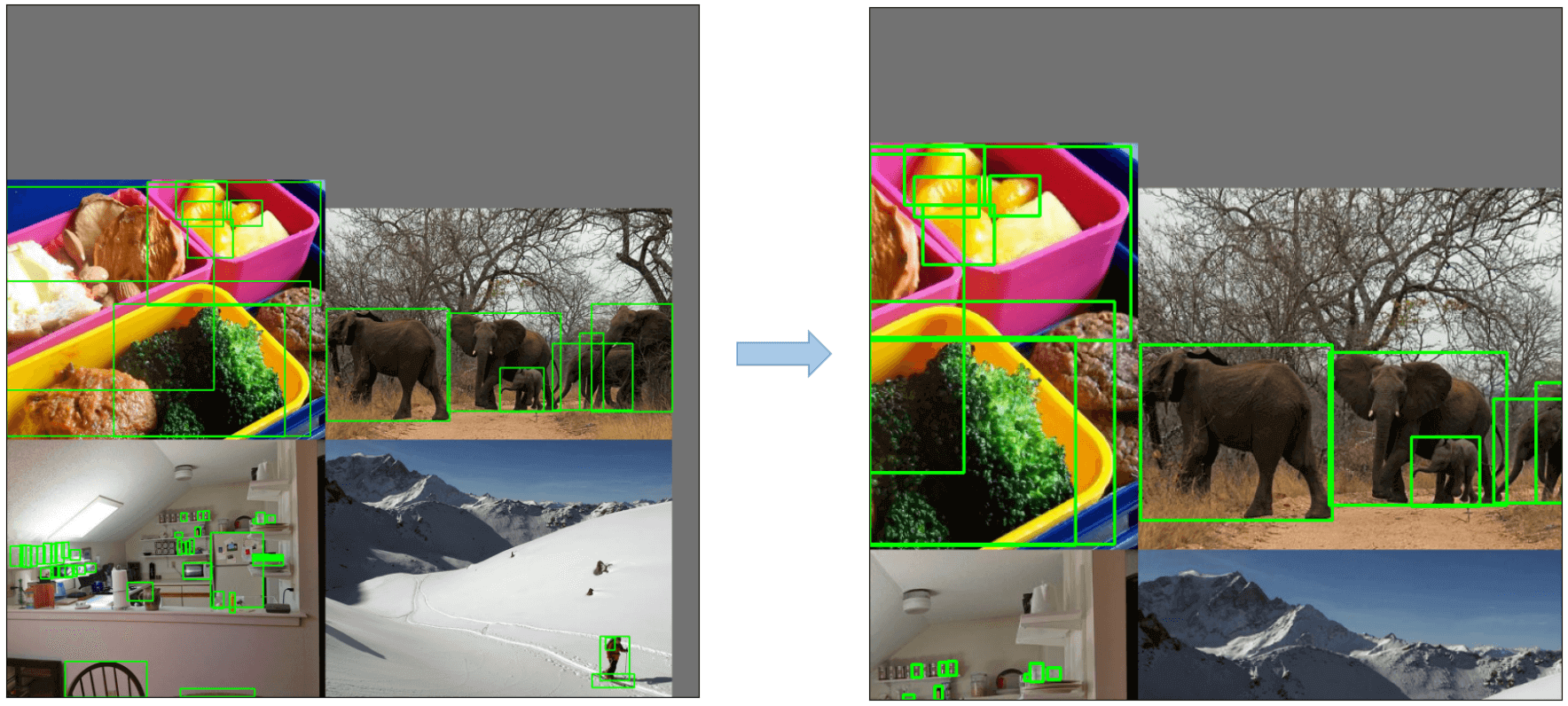
Mosaic Augmentation
将4幅图像合成一幅。

Copy-Paste Augmentation

Random Affine Transformations
包括图像的随机旋转、缩放、平移和剪切。
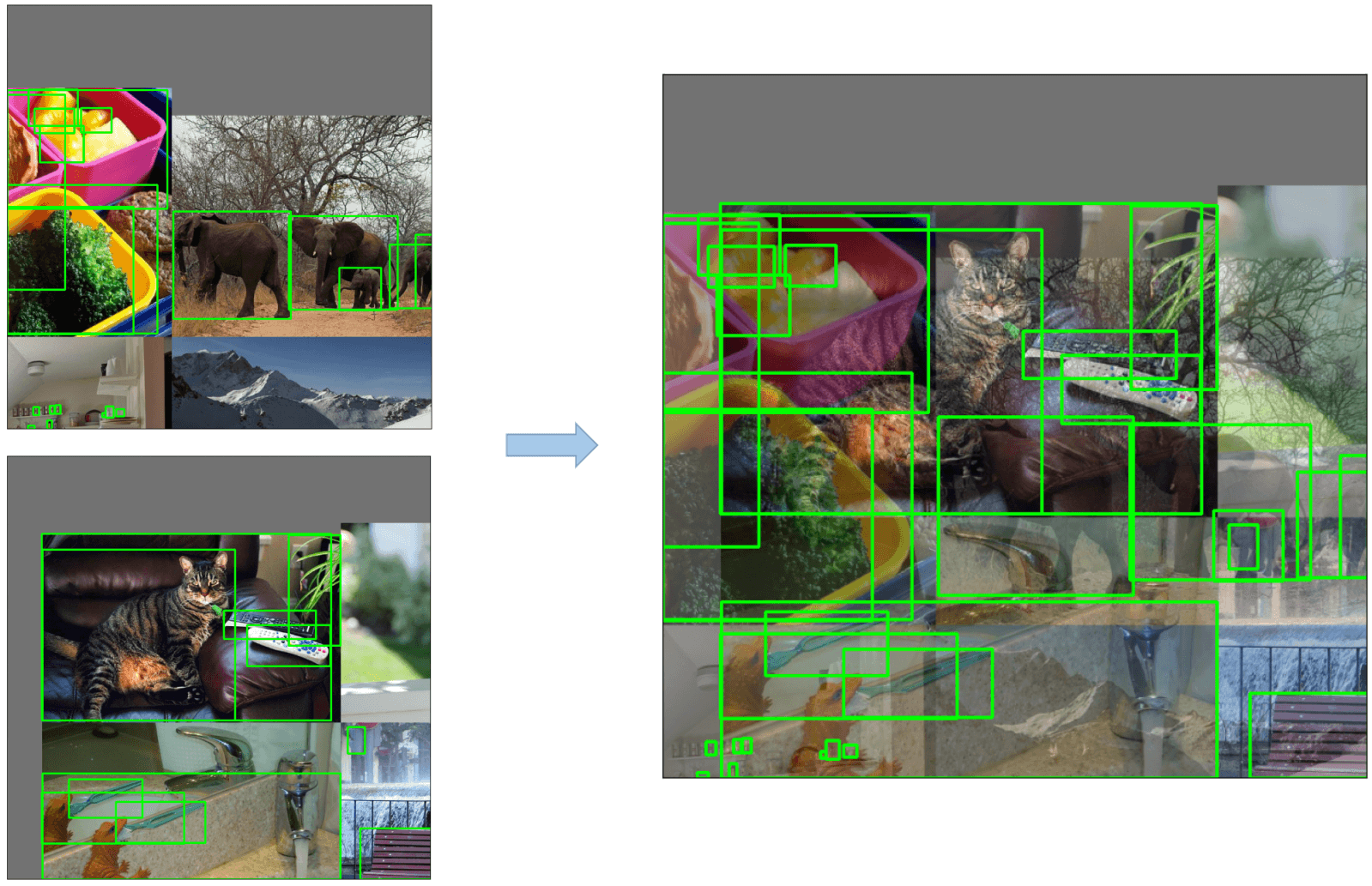
MixUp Augmentation
将2幅图像线性组合在一起。
Albumentations
一个强大的image augmentation库,支持多种augmentation技术。
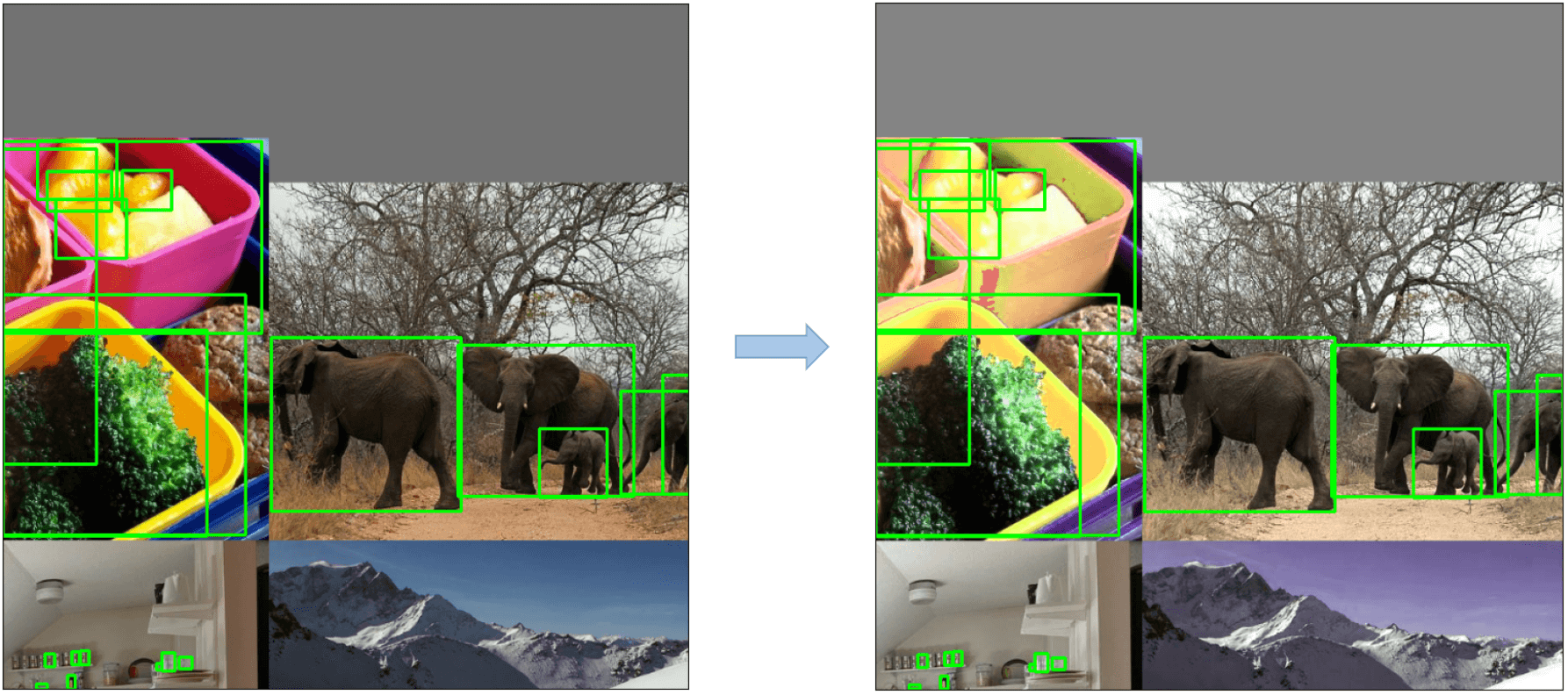
HSV Augmentation
随机修改图像H、S、V的值。
Random Horizontal Flip

4.Training Strategies
YOLOv5使用了一些复杂的训练策略来提升性能,它们包括:
- Multiscale Training:输入图像随机缩放0.5~1.5倍。
- AutoAnchor:即通过k-means聚类得到anchor,和YOLOv2中类似。
- Warmup and Cosine LR Scheduler:学习率调整策略。Warmup见链接,Cosine LR Scheduler见链接。
- Exponential Moving Average (EMA):使用EMA来稳定训练过程并减少泛化误差。
- Mixed Precision Training:一种以半精度格式(half-precision format,从32 bit的精度降低到16 bit)进行运算的方法,可减少内存使用并提高计算速度。
- Hyperparameter Evolution:自动调整超参数以达到最优性能。
5.Additional Features
5.1.Compute Losses
YOLOv5的loss有以下3部分组成:
- Classes Loss (BCE Loss)
- Objectness Loss (BCE Loss)
- Location Loss (CIoU Loss)
最终的loss function可表示为:
\[Loss = \lambda_1 L_{cls} + \lambda_2 L_{obj} + \lambda_3 L_{loc}\]接下来简单说下CE Loss和BCE Loss的区别。
- Cross-Entropy Loss(CE Loss)
- 用于多分类问题,一般搭配softmax函数使用。
- 公式:$CE\ Loss = - \sum_{i=1}^N y_i \log (\hat{y}_i)$。$y_i$是真实标签的概率分布(one-hot编码),$\hat{y}_i$是模型预测的概率分布,$N$是样本数量。
- Binary Cross-Entropy Loss(BCE Loss)
- 用于二分类问题,一般搭配sigmoid函数使用。
- 公式:$BCE\ Loss = -\frac{1}{N} \sum_{i=1}^N [ y_i \log(\hat{y}_i) + (1-y_i) \log (1-\hat{y}_i) ]$。$y_i$是真实标签(0或1),$\hat{y}_i$是模型的预测结果,$N$是样本数量。
在分类问题中,如果类别间不互斥,则需采用sigmoid+BCE当作多个二分类问题处理。如果遇到类别互斥的情况,则使用sigmoid+BCE化为多个二分类问题,或者也可以直接用softmax+CE。
5.2.Balance Losses
objectness losses在三个输出层(P3、P4、P5)上的权重是不一样的。
5.3.Eliminate Grid Sensitivity
参见:Eliminate Grid Sensitivity。
5.4.Build Targets
参见:Using multiple anchors for a single ground truth。
6.Conclusion
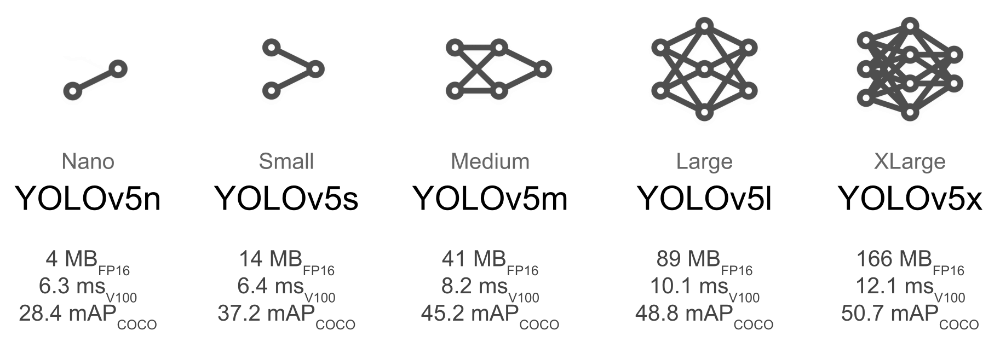
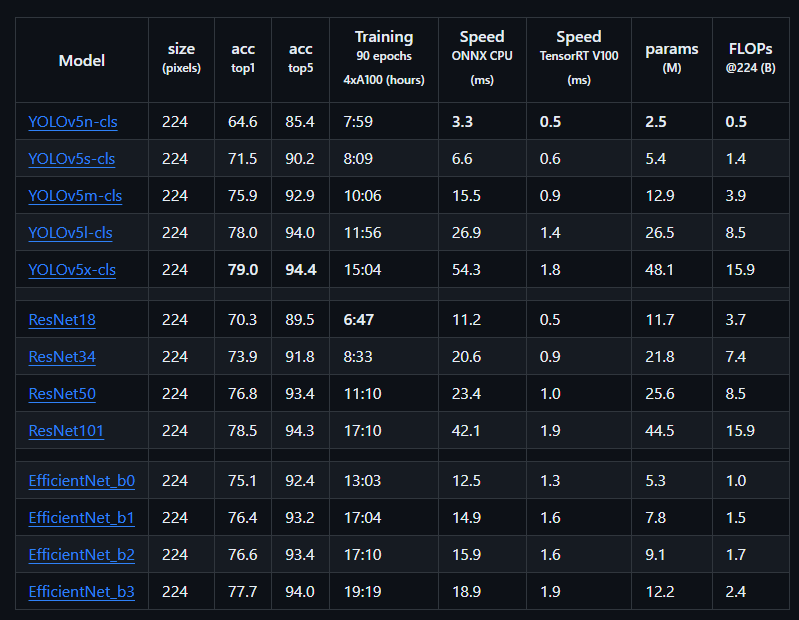
YOLOv5不同变体之间的区别主要在于:1)网络深度,即CSP block的数量;2)网络的宽度,即卷积核的数量。
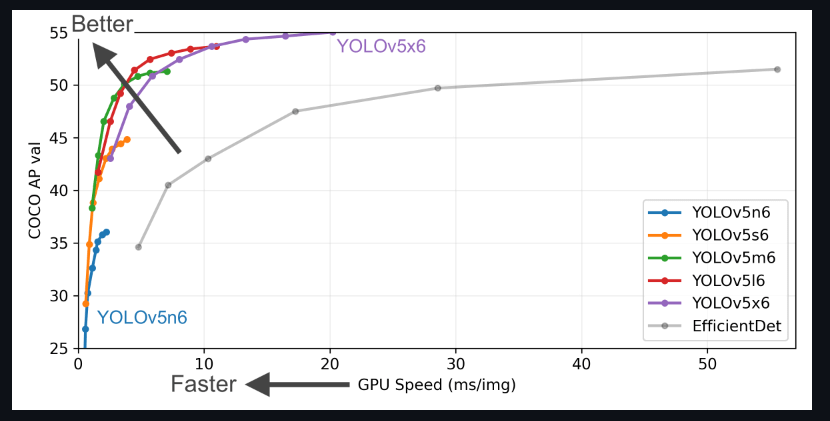
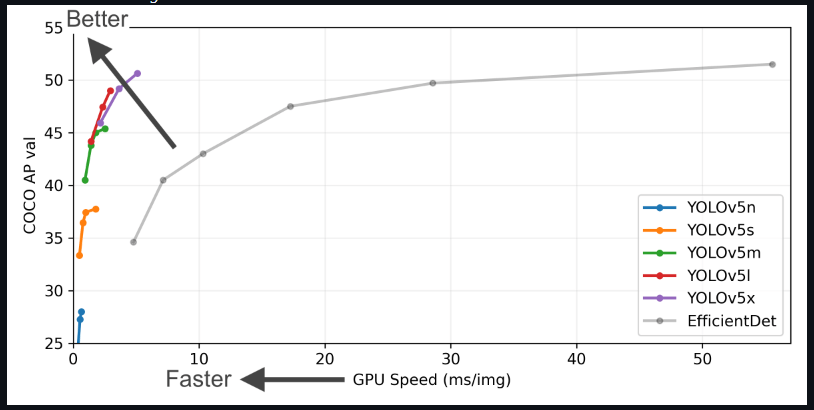
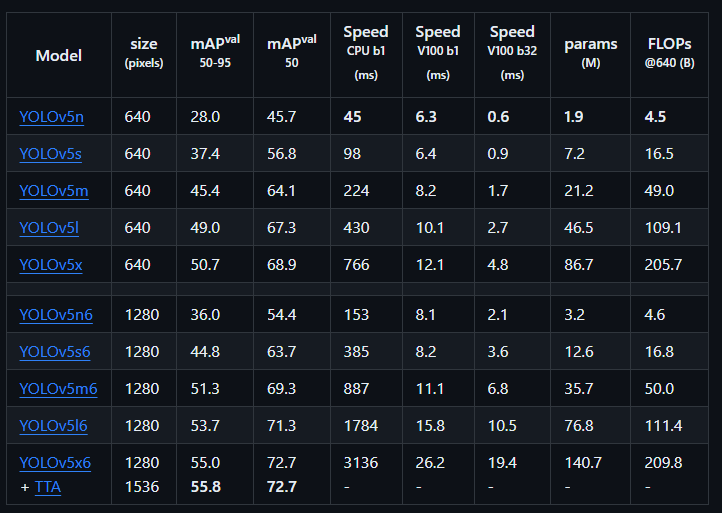
在检测任务上的性能:
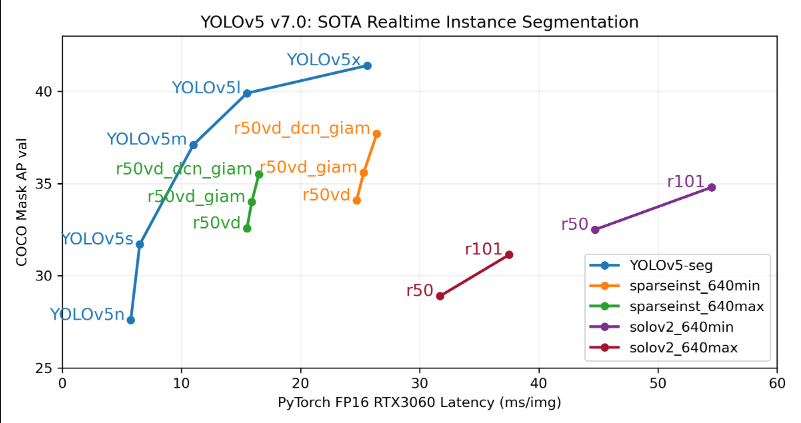
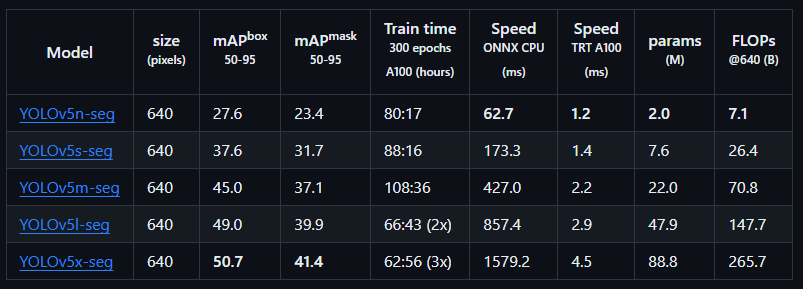
在分割任务上的性能(YOLOv5 v7.0):

在分类任务上的性能: