本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
whole-body pose estimation是一个很重要的课题,目前的一些流行算法,比如OpenPose和MediaPipe,其性能并不能令人满意。和只检测body-only keypoints相比,whole-body pose estimation面临着更多的挑战:
- 更加细粒度的关节点定位。
- 手部和脸部的低分辨率。
- 针对多人检测时的身体部位匹配问题,尤其是对于遮挡和复杂的手部姿势。
- 数据量不够的限制,尤其是全身图像且有不同的手部和头部姿态。
MediaPipe:
- Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris Mc-Clanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. Mediapipe: A framework for building perception pipelines. arXiv preprint arXiv:1906.08172, 2019.
- Fan Zhang, Valentin Bazarevsky, Andrey Vakunov, Andrei Tkachenka, George Sung, Chuo-Ling Chang, and Matthias Grundmann. Mediapipe hands: On-device real-time hand tracking. arXiv preprint arXiv:2006.10214, 2020.
知识蒸馏(Knowledge Distillation,KD)通常被用于对模型进行压缩(即在保证性能的前提下减少模型参数量),降低其推理成本。
Knowledge Distillation技术来自Hinton在2015年发表的一篇论文:Distilling the Knowledge in a Neural Network。
我们提出了一种新的two-stage的姿态蒸馏框架:DWPose,该模型取得了SOTA的结果,具体见Fig1。我们使用RTMPose(已在COCO-WholeBody数据集上训练好的)作为基础模型。
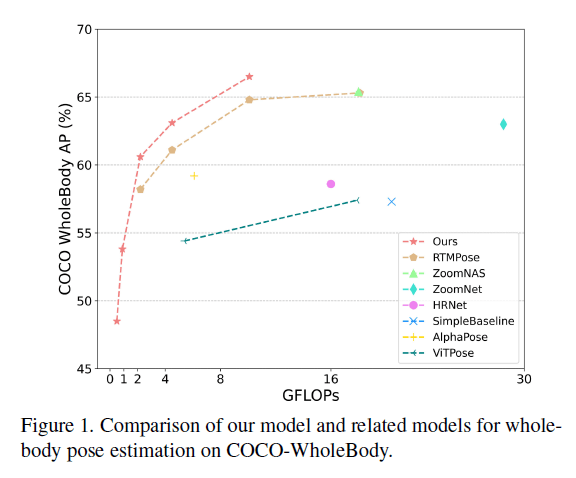
在第一阶段的蒸馏过程中,我们使用老师模型(比如RTMPose-x)的中间层和final logits来指导学生模型(比如RTMPose-l)。以前的姿态估计模型训练只使用可见的关节点。我们与此不同,我们使用老师模型的完整输出,其包括可见和不可见的关节点,这可以促进学生模型的学习过程。同时,我们使用weight-decay策略来提升效率,在整个训练阶段逐步降低蒸馏的权重。由于更好的头将决定更精确的定位,因此我们提出了head-aware self-KD来增强头的性能。我们构建了两个相同的模型,一个作为老师,另一个作为需要更新的学生。学生模型的backbone是冻结的,只有头通过蒸馏过程而更新。值得注意的是,这种即插即用的方式使得学生模型仅用20%的训练时间就达到了更好的结果。
数据的数量以及多样性也会影响模型性能。由于现有数据集上有限的关节点标注,无法对手部和面部的landmark进行细粒度的定位。因此,我们额外使用了一个UBody数据集,该数据集主要包含在各种现实场景中捕捉的不同面部和手部关节点。
我们的贡献总结如下:
- 我们介绍了一种two-stage的姿态蒸馏方法,以追求高效、精确的全身姿态估计。
- 为了突破数据的限制,我们使用了更全面的训练数据。
- 基于RTMPose,使用我们提出的蒸馏和数据策略将RTMPose-l的AP从64.8%提升到了66.5%,甚至超过了其老师模型RTMPose-x(65.3%的AP)。我们还验证了DWPose在生成任务中也有强大的有效性和效率。
2.Related work
不再赘述。
3.Method
接下来详细介绍two-stage姿态蒸馏(two-stage pose distillation,TPD)。如Fig2所示,TPD包含两个不同的阶段。第一个阶段:经过预训练的老师模型从头开始引导学生模型的学习。第二个阶段:自我蒸馏(self-KD)。该模型使用自己的logits在没有任何标记数据的情况下训练head,从而在训练阶段显著提高性能。

3.1.The First-stage distillation
老师模型backbone和学生模型backbone输出的特征分别记为$F^t$和$F^s$,老师模型和学生模型最终输出的logit分别记为$T_i$和$S_i$。第一阶段蒸馏会迫使学生模型学习老师模型的特征$F^t$和logit $T_i$。
3.1.1.Feature-based distillation
针对基于特征的蒸馏,我们强迫学生模型直接模仿老师模型输出的特征。使用MSE loss来衡量学生模型输出特征$F^s$和老师模型输出特征$F^t$之间的差异。特征蒸馏的loss定义为:
\[L_{fea} = \frac{1}{CHW} \sum_{c=1}^C \sum_{h=1}^H \sum_{w=1}^W ( F_{c,h,w}^t - f(F_{c,h,w}^s) )^2 \tag{1}\]$f$是$1\times 1$的卷积,用来将$F^s$的维度变换为和$F^t$的维度一样。$H,W,C$分别表示老师模型输出特征的height、width和channel。
3.1.2.Logit-based distillation
RTMPose使用了SimCC,将关节点定位视为一个分类问题。RTMPose使用的原始分类损失见下:
\[L_{ori} = -\sum_{n=1}^N \sum_{k=1}^K W_{n,k} \cdot \sum_{i=1}^L \frac{1}{L} \cdot V_i \log (S_i) \tag{2}\]在RTMPose原文里没有介绍其使用的分类损失。
$N$是一个batch内图像中的人物数量,$K$是关节点的数量(比如COCO-WholeBody是133个关节点),$L$是x或y方向上bin的数量。$W_{n,k}$表示关节点是否可见。$V_i$是标签。
这里说下个人理解,在RTMPose中的第3.4部分,我们介绍了如何把坐标回归问题变成一个分类问题,第3.4部分式(3)的$y_i$就是上面式(2)中的$S_i$,在第3.4部分我用[头、左肩、右肩、左脚、右脚]举了个例子,但从上面式(2)来看,其会遍历计算每个bin,比如我们在x方向共有6个bin(即$L=6$,这里我个人理解x和y方向可以分开计算,也可以合在一起计算),那预测的位置(也是离散的,为0-6中的某一个)分别属于每个bin的概率为$S_i$,但只有真实位置所对应的bin的$V_i$为1(其余bin的标签都是0)。$W_{n,k}$在关节点可见时为1,不可见时为0。此外,文中说的logit其实指的就是坐标分类。
我们在基于logit的蒸馏中,放弃了$W$。因为虽然有些关节点是不可见的,但是老师模型依然会有一个预测位置,我们认为这个预测结果也是有帮助的。因此,我们将logit蒸馏的损失定义为:
\[L_{logit} = -\frac{1}{N} \cdot \sum_{n=1}^N \sum_{k=1}^K \sum_{i=1}^L T_i \log (S_i) \tag{3}\]$T_i$就是老师模型输出的预测位置(以此作为标签),代替了式(2)中人工标注的标签$V_i$。
3.1.3.Weight-decay strategy for distillation
训练学生模型用的loss最终为:
\[L = L_{ori} + \alpha L_{fea} + \beta L_{logit} \tag{4}\]$\alpha,\beta$都是超参数。受到TADF的启发,我们对蒸馏使用了权重衰减策略。这一策略有助于学生模型更加专注于真实标签,并取得更好的性能。我们用时间函数$r(t)$来实现这一策略:
\[r(t) = 1-(t-1) / t_{max} \tag{5}\]TADF:Ruoyu Sun, Fuhui Tang, Xiaopeng Zhang, Hongkai Xiong, and Qi Tian. Distilling object detectors with task adaptive regularization. arXiv preprint arXiv:2006.13108, 2020.
其中,$t \in (1,…,t_{max})$为当前的epoch数,$t_{max}$为训练的总epoch数。最终的loss可表示为:
\[L_{s1} = L_{ori} + r(t) \cdot \alpha L_{fea} + r(t) \cdot \beta L_{logit} \tag{6}\]3.2.The Second-stage distillation
在第二个蒸馏阶段,我们让训练好的学生模型进行自学,以提高其性能。无论之前是否对学生模型进行过训练,这种方式都可以带来性能的提升。
姿态估计模型包括encoder(即backbone)和decoder(即head)两部分。基于已经训练好的模型,我们构建一个backbone已经训练过但head还未训练过的学生模型。而对应的老师模型则是backbone和head都是经过训练的,其整体框架和学生模型一样。在训练过程中,我们冻结学生模型的backbone,只更新head。因为老师模型和学生模型的框架都是一样的,所以我们只从backbone提取特征一次即可。然后这个特征被分别送进老师模型已经训练过的head和学生模型未被训练过的head中,对应得到$T_i$和$S_i$。在第二阶段的蒸馏中,使用式(3)对学生模型进行训练。这里我们没有使用$L_{ori}$。第二阶段蒸馏所用的最终loss见下($\lambda$为超参数):
\[L_{s2} = \gamma L_{logit} \tag{7}\]和之前self-KD的方法不同,我们提出的head-aware蒸馏可以有效的从head提取到知识,并且只需要20%的训练时间,并进一步提高定位能力。
4.Experiments
4.1.Datasets and Details
👉Datasets.
我们使用COCO和UBody进行了实验。对于COCO数据集,我们使用train2017和val2017,118K张图像用于训练,5K张图像用于测试。除非特殊说明,否则我们都默认使用SimpleBaseline作为人物检测器,其在COCO val数据集上的AP为56.4%。UBody包含15个真实场景的超1M帧。它提供133个2D关节点和SMPL-X参数。需要注意的是,原始数据集只关注3D whole-body的姿态估计,而没有验证2D注释的有效性。我们训练和测试所用的数据都是每隔10帧挑选一帧。UBody数据集提供GT的人物box。
👉Implementation details.
对于第一阶段蒸馏,在式(6)中,我们使用了$\alpha,\beta$两个超参数。在COCO和UBody上的所有实验,我们都设置$\{ \alpha=0.00005, \beta=0.1 \}$。对于第二阶段蒸馏,在式(7)中,我们使用了超参数$\gamma$。在所有实验中,我们设置$\gamma=1$。第一阶段蒸馏的训练设置和RTMPose一致。第二阶段蒸馏只需要很短的训练时间,约为总训练epoch数的五分之一。其他训练设置也都是一样的。基于Pytorch和MMPose,我们使用8块GPU。
4.2.Main Results
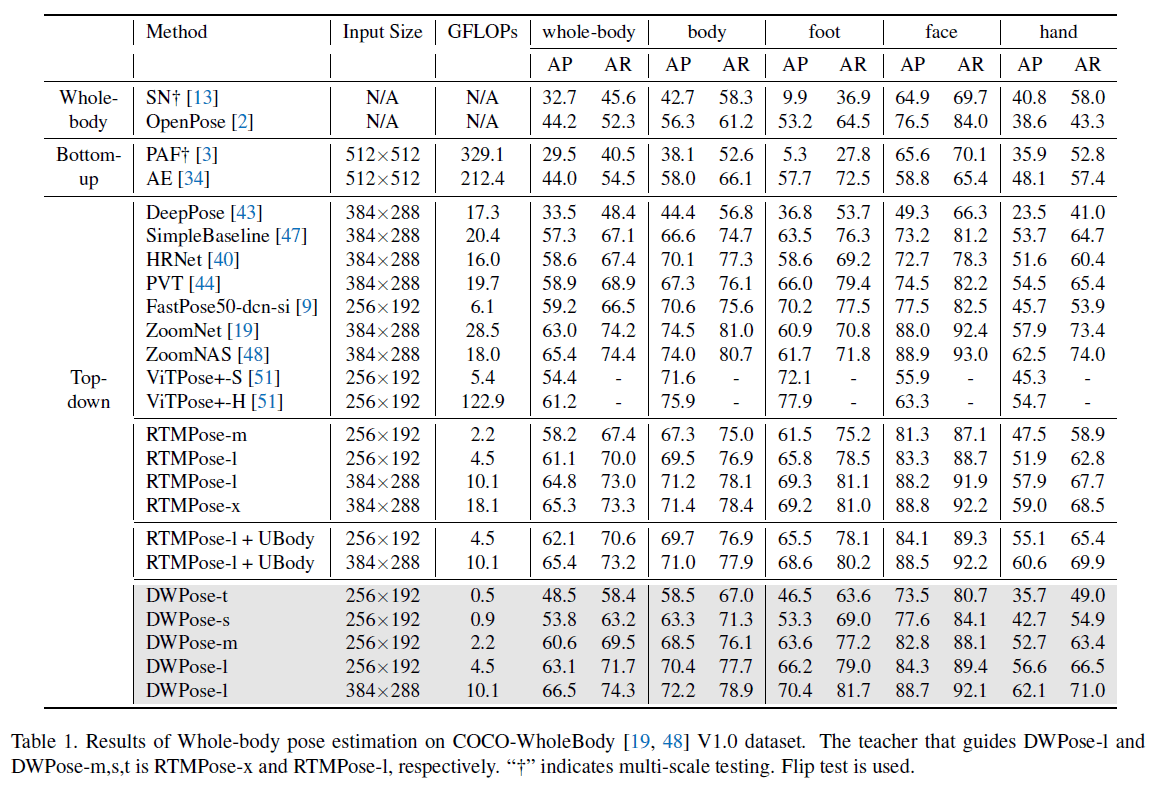
为了公平的比较,我们在公开的COCO-WholeBody数据集上进行了评估。结果见表1和Fig3。

和OpenPose、MediaPipe的比较见Fig4。

5.Analysis
5.1.Effects of TPD Method and UBody Data
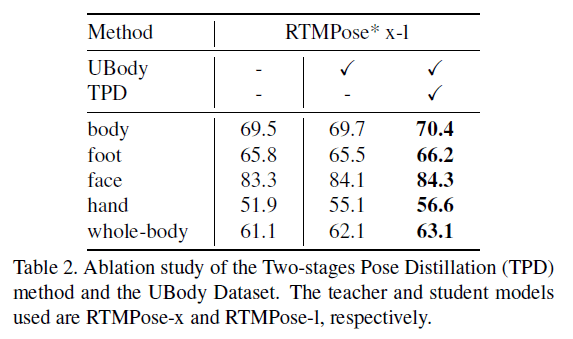
表2中第一列是在COCO数据集上的结果(训练集只有COCO),第二列是在加入UBody数据集后在COCO上的结果(训练集为COCO+UBody),第三列是再加上TPD后在COCO上的结果(COCO+UBody+TPD)。
5.2.Performance on UBody
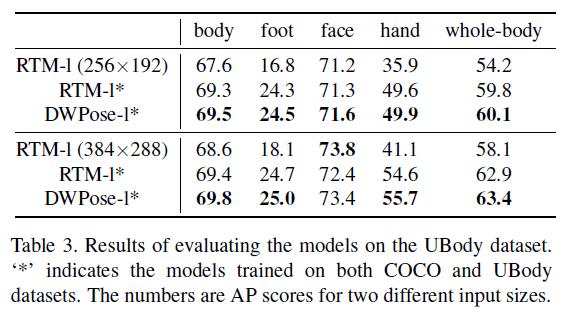
在UBody数据集上的测试结果见表3。
5.3.Effects of First and Second Stage Distillation
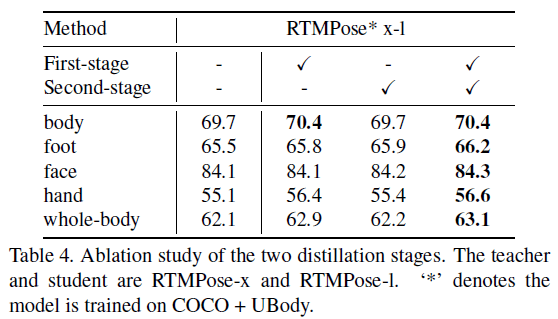
5.4.Second-stage Distillation for Trained Models
第二阶段蒸馏既可以应用在第一阶段蒸馏的基础上,也可以应用在没有蒸馏的模型上。当没有更好和更大型的老师模型时,我们可以只使用第二阶段蒸馏。
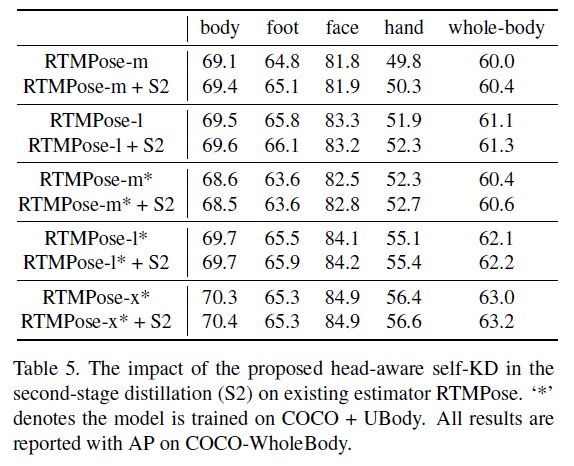
5.5.Ablation Study of the First-stage Distillation
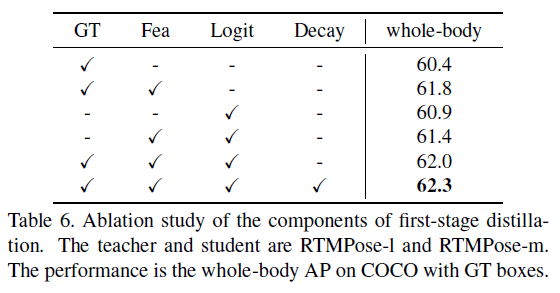
“GT”列为式(6)中的$L_{ori}$项,”Fea”列为式(6)中的$L_{fea}$项,”Logit”为式(6)中的$L_{logit}$项,”Decay”为权重衰减策略(即式(5))。
有趣的一点是,即使我们只使用老师模型的logit来训练学生模型,学生模型依然达到了60.9%的AP,比只使用了GT的模型还高0.5%。这说明我们可以用老师模型的输出来标注新数据,从而取代手动标注。
5.6.Target Mask for Logit-based Distillation

如式(3)所示,我们省略了$W$(即target weight mask),对$W$的有效性实验见表7。
5.7.Better Pose, Better Image Generation
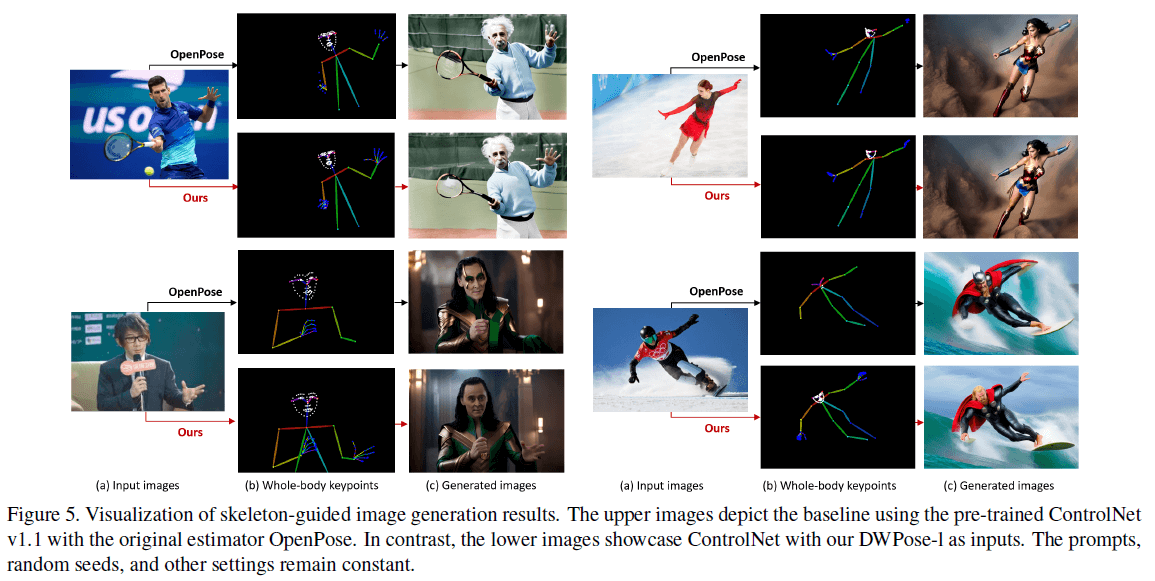
最近,可控的图像生成取得了巨大进展。对于人物图像生成,精确的骨骼框架至关重要。主流技术,比如ControlNet,通常依赖OpenPose来产生人体姿态。但是如表1所示,OpenPose只有44.2%的AP,还有巨大的提升空间。因此,我们将ControlNet中的OpenPose替换为了DWPose。利用top-down方式,我们先用YOLOX检测到人物,然后用DWPose检测关节点。比较结果见Fig5。
推理速度的比较见表8。

6.Conclusion
不再赘述。
7.原文链接
👽Effective Whole-body Pose Estimation with Two-stages Distillation
