本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
代码和模型开源地址:RTMPose。
在计算能力有限的设备上执行robust且实时的多人姿态估计仍然是一项具有挑战性的任务,其还不足以达到令人满意的工业应用性能。
在本文,我们从以下5个方面探讨了影响2D多人姿态估计框架性能和latency的关键因素:范式(paradigm)、backbone网络、定位方法、训练策略、部署。通过一系列的优化,我们提出RTMPose,即Real-Time Models for Pose estimation。
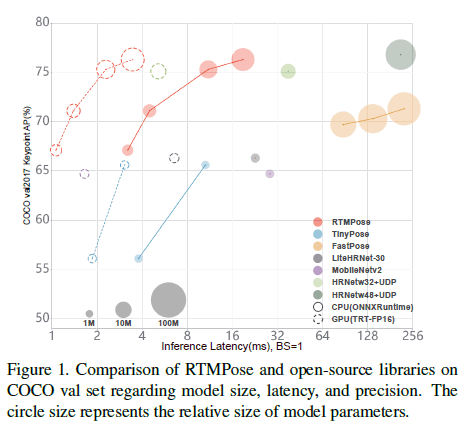
如Fig1所示,我们使用了不同的推理框架(PyTorch、ONNX Runtime、TensorRT、ncnn)和硬件(Intel i7-11700、GTX 1660Ti、Snapdragon 865)来评估RTMPose的效率。RTMPose-m在COCO val set上达到了75.8%的AP(with flipping),在Intel i7-11700 CPU上达到了90+ FPS,在NVIDIA GeForce GTX 1660 Ti GPU上达到了430+ FPS,在Snapdragon 865 chip上达到了35+ FPS。借助MMDeploy,RTMPose可以很容易的被部署到不同的backend上,比如RKNN、OpenVINO以及PPLNN等。
2.Related Work
不再详述。
3.Methodology
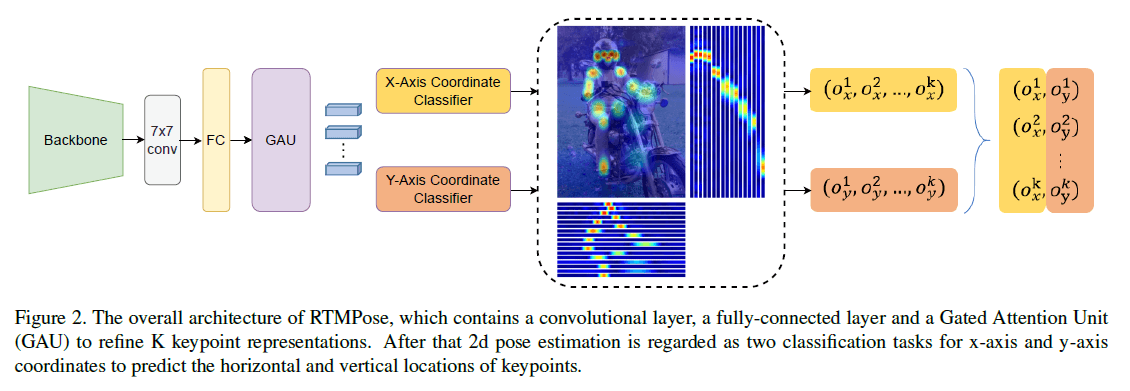
3.1.SimCC: A lightweight yet strong baseline
👉Preliminary
详见:SimCC。
👉Baseline
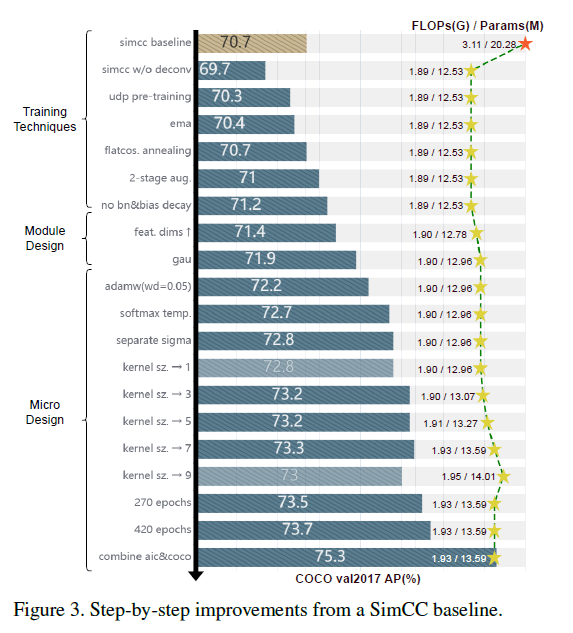
我们首先去除了标准SimCC中昂贵的上采样层。如表1所示,相比SimCC和基于heatmap方法的SimpleBaseline,修改后的SimCC复杂度更低,精度却没损失太多。如果我们将backbone从ResNet-50替换为更紧凑的CSPNext-m,模型的大小将进一步缩小(更加轻量化),AP略微降低到69.7%。
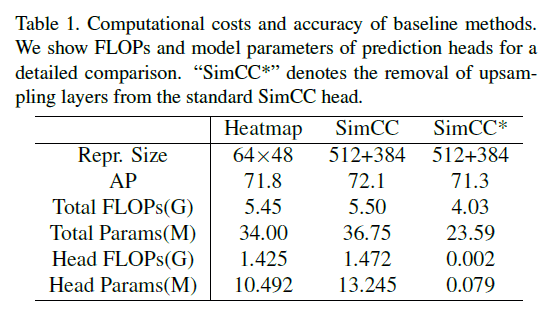
个人理解:SimpleBaseline的backbone是ResNet-50,表1第一列基本就是原始SimpleBaseline的结果。表1第二列是直接在SimpleBaseline后面接一个SimCC head,所以可以看到参数量有所上升。表1第三列是先把SimpleBaseline的上采样部分(即反卷积操作)给去掉后才接的SimCC head,所以参数量有很大幅度的降低,这和SimCC原文中的做法类似。但是Fig3中simcc baseline的70.7不知道怎么来的,论文里也没提。
最终,作者采用的backbone是CSPNext。
3.2.Training Techniques
👉Pre-training
之前的研究证实了预训练基于heatmap方法的backbone可以提升模型精度。因此,我们使用UDP方法对backbone进行了预训练。这将模型的AP从69.7%提升到了70.3%。在以下部分中,我们将使用此技术作为默认设置。
UDP:Junjie Huang, Zheng Zhu, Feng Guo, and Guan Huang. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.。
👉Optimization Strategy
我们采用RTMDet中的优化策略。使用EMA缓解过拟合(从70.3%提升到70.4%)。flat cosine annealing strategy将AP进一步提升到70.7%。我们也抑制了在normalization layers和biases上的weight decay。
👉Two-stage training augmentations
和RTMDet一样,使用先强后弱的两阶段数据增强策略。训练的前180个epoch使用强数据增强,后30个epoch使用弱数据增强。对于强数据增强,我们使用的图像缩放比例范围为$[0.6, 1.4]$,图像旋转因子为80,Cutout的概率为1。对于弱数据增强,我们关闭了随机shift,使用更小的随机旋转角度,将Cutout的概率设为0.5。
3.3.Module Design
👉Feature dimension
我们发现模型性能随着特征分辨率的提高而提高。因此,我们使用一个超参数,通过一个FC层来将1D keypoint representations扩展到我们想要的维度(本文使用256)。这一操作将AP从71.2%提升至71.4%。
👉Self-attention module
GAU:Weizhe Hua, Zihang Dai, Hanxiao Liu, and Quoc V. Le. Transformer quality in linear time. ArXiv, abs/2202.10447, 2022.。
传统的Transformer block为:MHSA(多头自注意力)+一层或者两层的FFN(全连接层)。FFN的计算可表示为:
\[\mathcal{O} = \phi (XW_u) W_o \ \text{Where} \ X \in \mathbb{R}^{T \times d},W_u \in \mathbb{R}^{d \times e}, W_o \in \mathbb{R}^{e \times d}\]其中,$T$表示句子长度,$d$表示词向量维度(也表示模型隐藏层维度)。
GLU(Gated Linear Unit)针对FFN部分进行了改进(MHSA部分不变),简单理解就是有两个分支,每个分支都是全连接层加激活函数,两个分支的激活函数可以不同,最后两个分支的结果会做element-wise乘法,得到的结果会再经过一个全连接层进行处理,详细如下图所示。
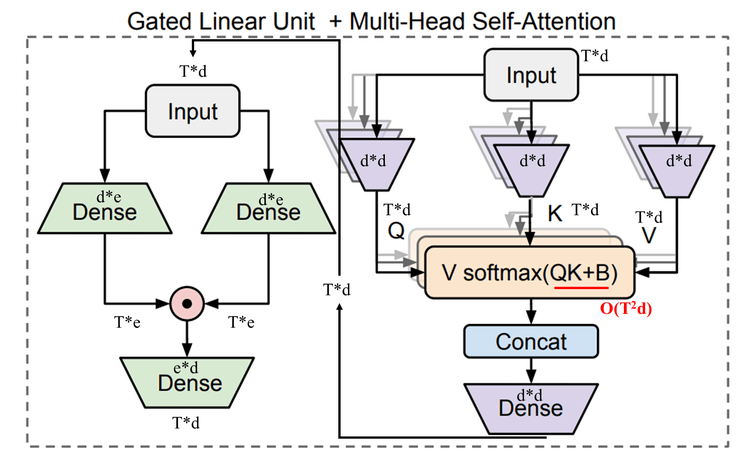
上图左边部分的GLU计算如下:
\[U = \phi _u (XW_u), \ V = \phi _v (XW_v) \ \in \mathbb{R}^{T \times e}\] \[O = (U \odot V) W_o \ \in \mathbb{R}^{T \times d}\]上面的GLU和注意力模块是独立开的,所以GAU(Gated Attention Unit)就将二者巧妙的融合到了一个模块:
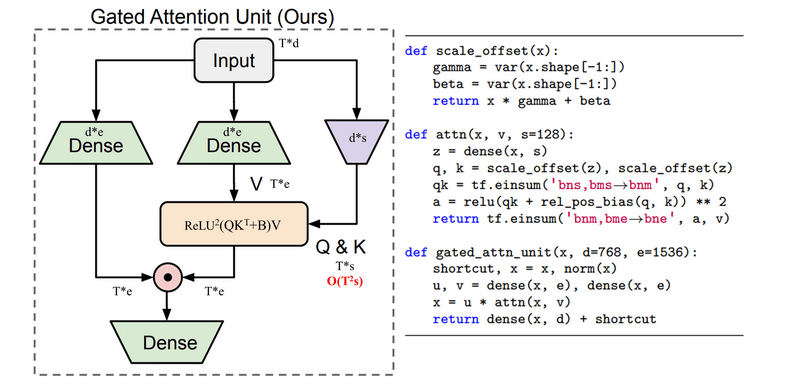
GAU的计算公式见下:
\[O = (U \odot \hat{V}) W_o \ \text{Where} \ \hat{V}=AV\]其中,
\[Z = \phi_z (XW_z) \ \in \mathbb{R}^{T \times s}\] \[A = \text{relu}^2 (\mathcal{Q}(Z) \mathcal{K}(Z)^{\top} + b) \ \in \ \mathbb{R}^{T \times T}\]并且有$s«d$,在GAU原文中,作者设$s=128$。$\mathcal{Q,K}$是两个廉价的变换。$b$是相对位置偏倚。将MHSA+FFN替换为GAU后,速度更快,性能更好。
在RTMPose中,$A$的计算如下:
\[A = \frac{1}{n} \text{relu}^2 (\frac{Q(X)K(Z)^{\top}}{\sqrt{s}}), \ Z = \phi_z (XW_z) \tag{2}\]同样设$s=128$,$Q,K$就是简单的线性变换,$relu^2(\cdot)$是先ReLU后平方的意思。自注意力模块将模型的AP提高到了71.9%。
3.4.Micro Design
👉Loss function
和SORD基本一致,即把回归问题视为一个分类问题。
\[y_i = \frac{e^{\phi (r_t, r_i)}}{\sum_{k=1}^K e^{\phi (r_t, r_k)}} \tag{3}\]SORD:Ra´ul D´ıaz and Amit Marathe. Soft labels for ordinal regression. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.。
这里说下个人理解,$r_t$是我们预测的某一关节点的位置,$r_i$和$r_k$都是关节点的GT位置,一共有$K$个关节点,$e^{\phi (r_t,r_i)}$是预测位置和GT之间的距离度量,分母就相当于是预测点到所有关节点GT位置的距离之和,$y_i$就表示$r_t$属于关节点$r_i$的概率,式(3)其实就是一个softmax函数。比如我们有5个关节点:[头、左肩、右肩、左脚、右脚],如果我们预测头关节点的位置,根据式(3)我们可以算出预测点$r_t$分别属于每个关节点的概率,比如为$[0.7,0.1,0.1,0.05,0.05]$,标签此时为$[1,0,0,0,0]$,然后就可以用比如CE loss等分类常用的损失函数来计算模型loss了。
距离计算公式:
\[\phi (r_t, r_i) = e^{\frac{-(r_t - r_i)^2}{2 \sigma^2}} \tag{4}\]基于式(3)添加$\tau$用于调整归一化分布形状:
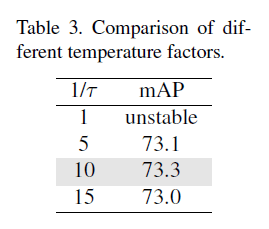
\[y_i = \frac{e^{\phi (r_t, r_i) / \tau}}{\sum_{k=1}^K e^{\phi (r_t,r_l)/\tau}} \tag{5}\]根据实验结果,我们将$\tau$设为0.1,这使得AP从71.9%提升至72.7%。不同$\tau$值的比较见表3。
👉Separate $\sigma$
SimCC使用了label smoothing,其水平坐标和垂直坐标的标签使用的平滑因子$\sigma$是一样的。我们对水平坐标和垂直坐标的标签设置不同的$\sigma$:
\[\sigma = \sqrt{ \frac{W_S}{16} } \tag{6}\]$W_S$是横向或纵向所分的bin的个数。这一操作将AP从72.7%提升到了72.8%。
👉Larger convolution kernel
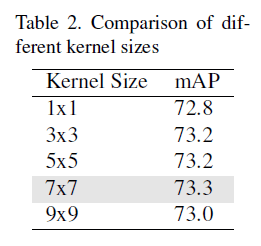
我们实验了在最后一个卷积层使用不同大小的卷积核。最终,$7 \times 7$的卷积核对性能提升最大,将AP提高到了73.3%。不同大小卷积核的比较见表2。
👉More epochs and multi-dataset training
增加训练epoch数量也带来了模型性能的提升。为了进一步探索模型的潜能,我们扩充了训练数据,加入了COCO和AI Challenger数据集用于预训练和fine-tune。最终AP达到了75.3%。
3.5.Inference pipeline
除了姿态估计模型之外,我们还进一步优化了整体自上而下的inference pipeline,以降低latency并提高鲁棒性。我们使用了BlazePose中的跳帧检测机制,见Fig4。
BlazePose:Valentin Bazarevsky, Ivan Grishchenko, Karthik Raveendran, Tyler Zhu, Fan Zhang, and Matthias Grundmann. Blazepose: On-device real-time body pose tracking, 2020.。

human detection是每隔K帧检测一次。为了平滑预测结果,我们在后处理阶段使用了基于OKS的pose NMS和OneEuro filter。
4.Experiments
4.1.Settings
训练设置见表7。
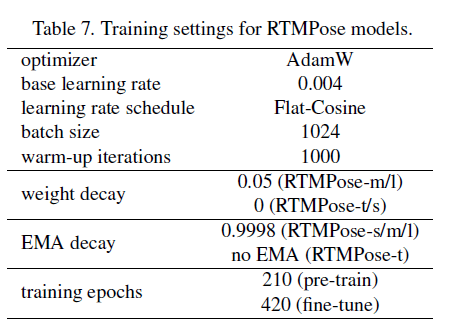
如第3.2部分所述,我们进行了基于heatmap的预训练,其和fine-tune使用一样的训练策略。所有模型的训练都是使用8块NVIDIA A100 GPU。
4.2.Benchmark Results
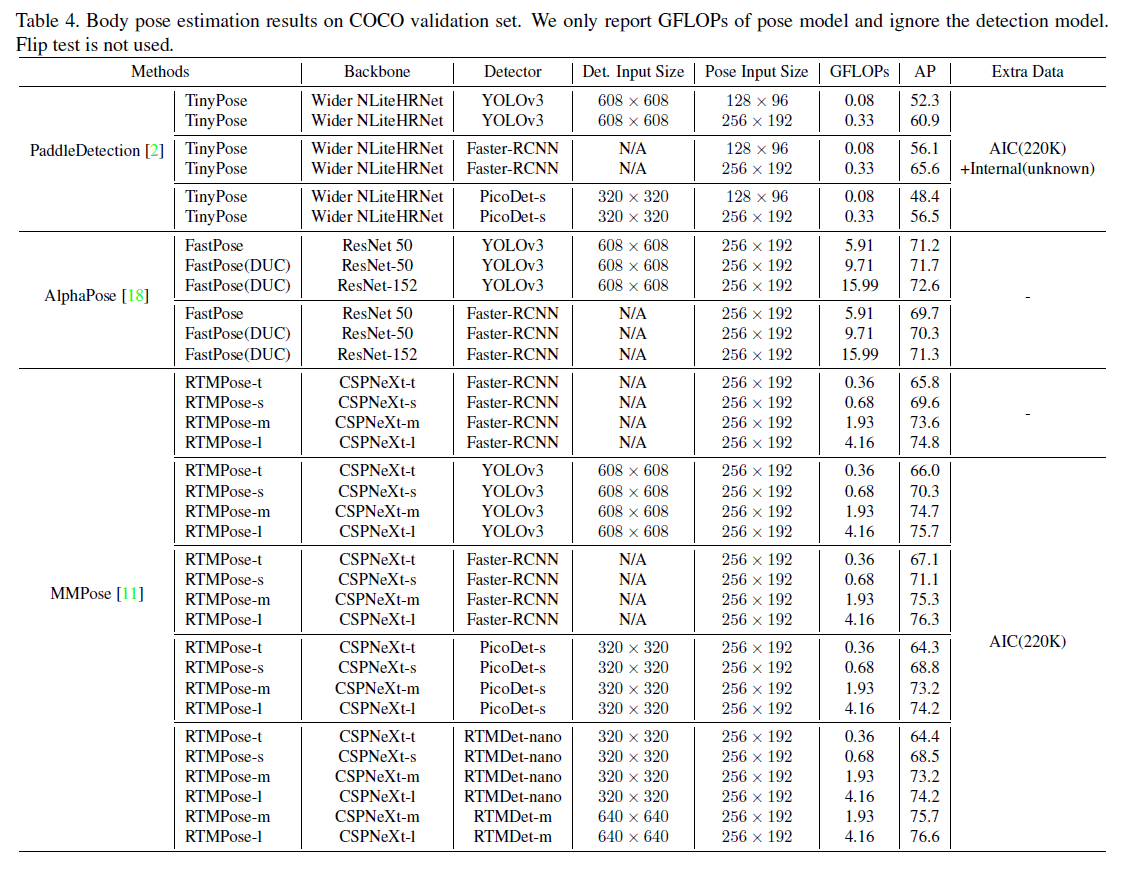
👉COCO
COCO是2D姿态估计最为流行的benchmark。我们使用标准的划分:train2017(118K张图像)用于训练、val2017(5K张图像)用于验证。
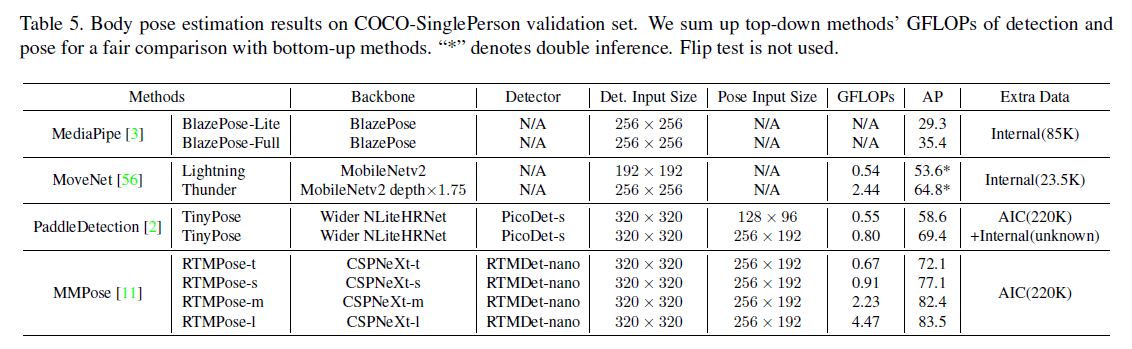
👉COCO-SinglePerson
一些姿态估计方法,比如BlazePose、MoveNet以及PaddleDetection,设计初衷都是针对单人或稀疏场景的,这对移动应用和人机交互是很有用的。因此,基于val2017,我们构建了一个包含1045张图像的单人图像数据集。对于MoveNet,我们遵循官方的inference pipeline使用了cropping算法,即第一次推理先通过粗糙的姿态估计结果对输入图像进行剪切,然后在第二次推理中获得更好的预测结果。

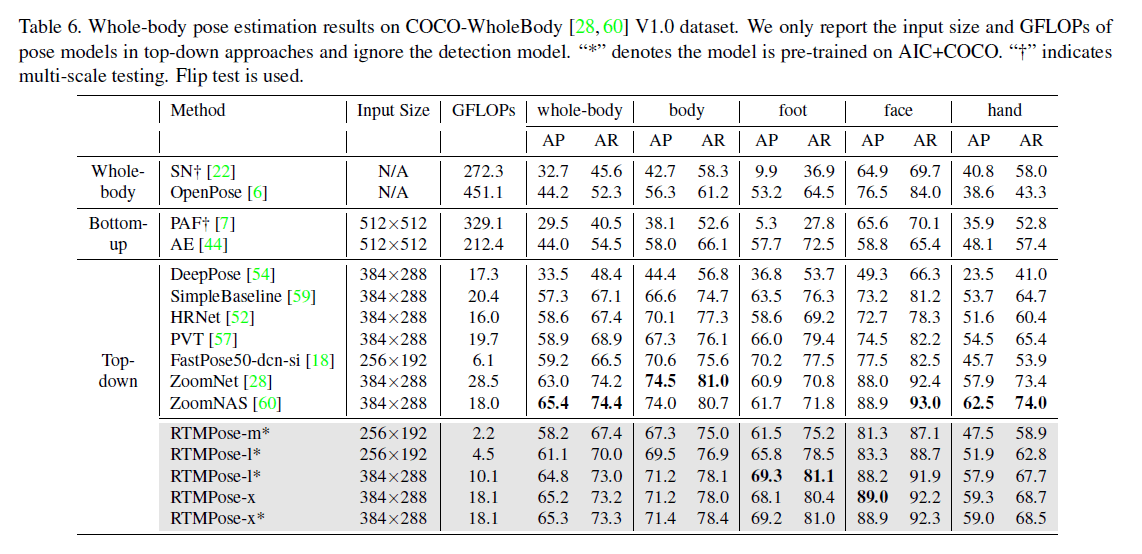
👉COCO-WholeBody
👉Other Datasets
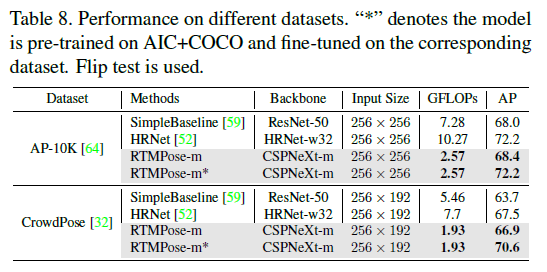

4.3.Inference Speed
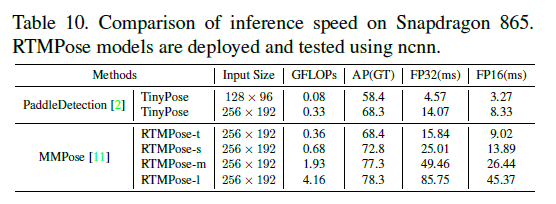

5.Conclusion
我们提出了一个高性能的、实时的多人姿态估计框架——RTMPose,其支持在多种设备上部署(CPU、GPU和移动设备)。
6.原文链接
👽RTMPose:Real-Time Multi-Person Pose Estimation based on MMPose
