本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
角点检测是许多CV任务的第一步。现有的角点检测算法占用大量计算资源,无法满足高帧率、实时处理等场景的要求。
1.1.Previous Work
不再详述。
2.High-Speed Corner Detection
2.1.FAST: Features from Accelerated Segment Test
FAST算法的步骤见下(结合OpenCV官方文档):
- 选择图像中的一点$p$,其像素值为$I_p$。
- 选择一个合适的阈值$t$。
- 考虑点$p$周围圆周上的16个像素点,如Fig1所示(Fig1展示了一个半径为3的Bresenham circle)。
- 如果点$p$周围圆周上有连续$n$个点的像素值都大于$I_p+t$(即更亮)或小于$I_p-t$(即更暗),则将$p$视为角点(比如Fig1中虚线所穿过的像素点),通常设$n=12$。
- 在连续检查$n$个点之前,我们可以先做一个快速筛查,即仅判断序号为1、5、9、13这4个点,如果这4个点中至少有3个的像素值都满足大于$I_p+t$或小于$I_p-t$,则接下来再去检查所有的16个点,看是否有连续$n$个点都满足要求;如果这4个点满足要求的不足3个,则认为点$p$不是角点,可以直接拒绝点$p$。

FAST检测器虽然性能很高,但仍然存在几个缺点:
- 当$n<12$时,检测器效果不佳。
- 周围像素点的选择和排序隐含了一些假设,可能不适用于不同类型的图像。
- 快速筛查所用的4个点的信息没有被充分利用,浪费了潜在的线索。
- 在一些情况下,多个特征点可能会在相邻区域内被同时检测到,导致冗余检测。
前三点通过机器学习方法解决(见第2.2部分),第四点通过NMS解决(见第2.3部分)。
2.2.Machine Learning a Corner Detector
- 选择一个图像集用于训练(训练图像最好来自目标应用领域)。
- 在每张图像上运行FAST算法以找到特征点。
-
对于每个特征点,将其周围圆周上的16个位置的像素值保存为一个向量。将所有图像的特征点向量都存放到$P$中。$P$如下图所示:
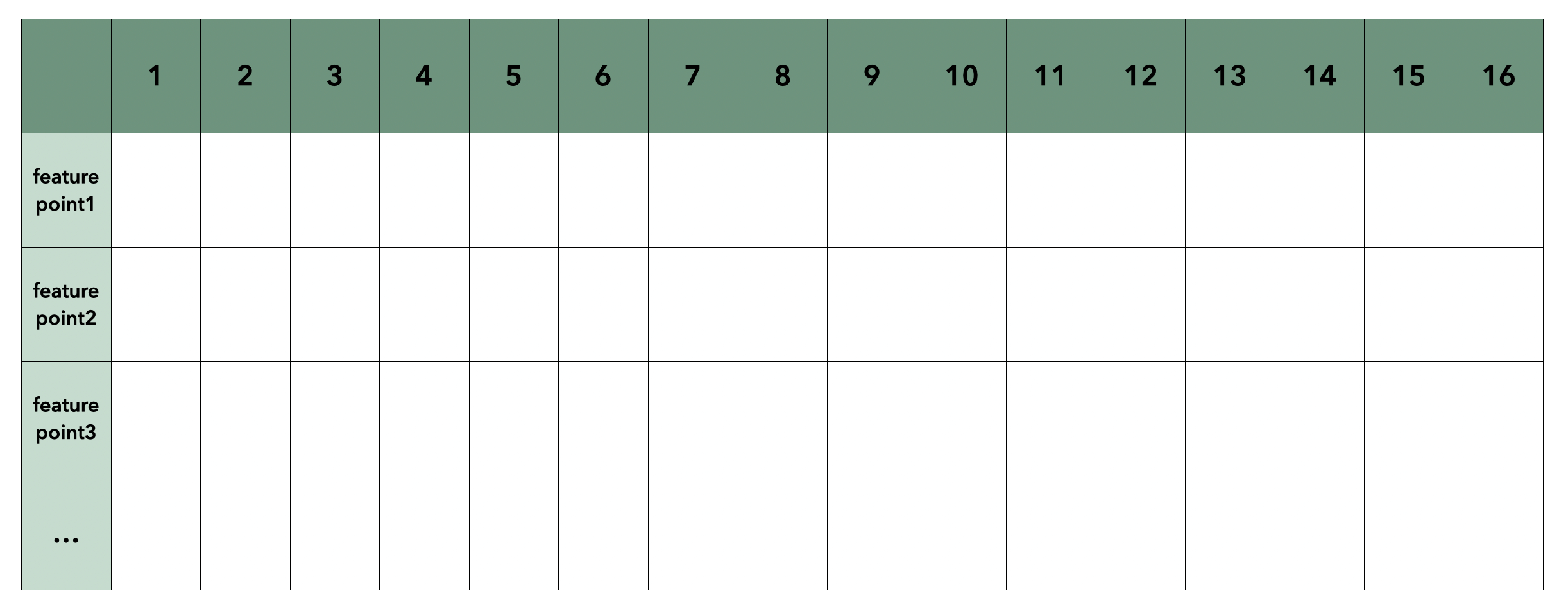
-
圆周上16个位置中的每一个位置$x$都可以指定为以下三种状态中的一种:
\[S_{p \rightarrow x} = \begin{cases} d, & I_{p \rightarrow x} \leq I_p - t \quad (\text{darker}) \\ s, & I_p - t < I_{p \rightarrow x} < I_p + t \quad (\text{similar}) \\ b, & I_p + t \leq I_{p \rightarrow x} \quad (\text{brighter}) \end{cases}\]如下图所示:

- 根据任何一个位置$x$,$P$都可以被分成$P_d,P_s,P_b$三个子集。
- 使用布尔值$K_p$表示$p$是否是一个角点,如果$K_p$为true,则$p$是一个角点,如果是false则不是角点。
-
使用ID3算法训练一个决策树分类器,决策树的划分属性就是16个位置。集合$P$的信息墒定义为:
\[H(P) = (c+\bar{c})\log_2(c+\bar{c})-c\log_2c-\bar{c}\log_2 \bar{c}\]其中,$c=\lvert \{ p \mid K_p \text{ is true} \} \rvert$为角点的数量,$\bar{c} = \lvert \{ p \mid K_p \text{ is false} \} \rvert$为非角点的数量。信息增益的计算为:
\[H(P) - H(P_d) - H(P_s) - H(P_b)\]每次我们就使用可以最大化信息增益的位置$x$作为划分属性。构建的决策树示例见下:
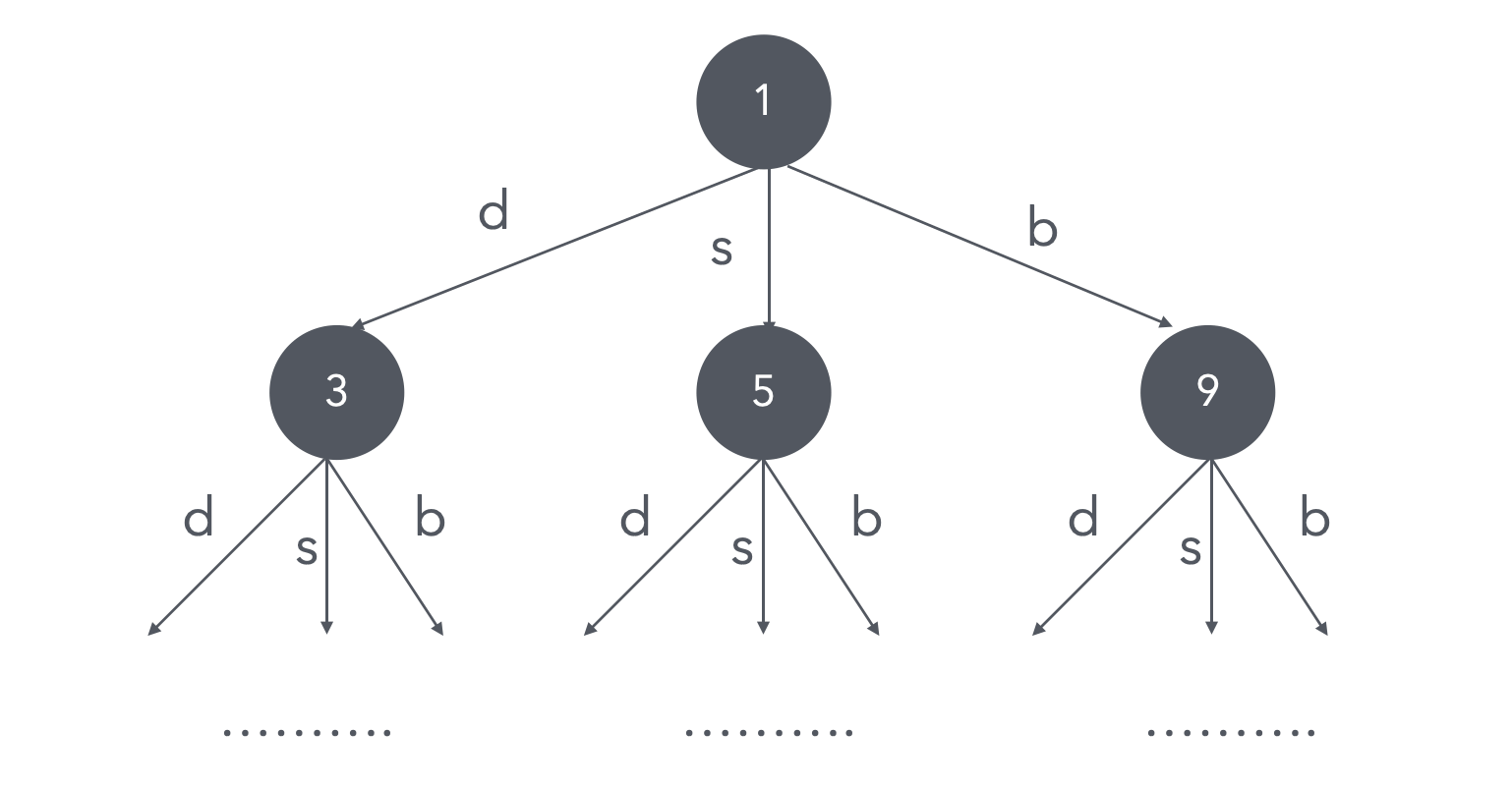
- 训练好的决策树可以在其他图像中进行角点的快速检测。
2.3.Non-maximal Suppression
如果想要执行NMS,我们需要为每个检测到的角点计算一个分数,这样在一定邻域内,分数较低的角点会被分数较高的角点所抑制。分数的计算公式见下:
\[V=\max \left( \sum_{x\in S_{bright}} \lvert I_{p\to x} - I_p \rvert - t, \sum_{x \in S_{dark}} \lvert I_p - I_{p\to x} \rvert -t \right)\]其中,
\[S_{bright} = \{ x \mid I_{p\to x} \geqslant I_p + t \}\] \[S_{dark} = \{ x \mid I_{p \to x} \leqslant I_p - t \}\]2.4.Timing Results

从表1可以得到以下结论:
- 相比其他特征检测器,比如Harris、DoG、SUSAN,FAST算法的性能更高。
- 相比原始的FAST算法(Original FAST),基于机器学习优化的FAST检测器速度有显著提升。
- 基于机器学习优化的FAST检测器在$n=9$时也有不错的性能。
- 针对不同硬件上的测试,FAST算法展示出了其高效性和适应性。
3.A Comparison of Detector Repeatability
不再详述。
4.Results and Discussion
不再详述。
5.Conclusions
不再详述。
6.原文链接
👽Machine Learning for High-Speed Corner Detection
