本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
代码:TOOD。
PP-YOLOE使用了TOOD中的TAL和T-Head。YOLOv6和YOLOv8都使用了TOOD中的TAL。
在目标检测任务中,由于分类和定位的学习机制不同,这两个子任务学到的特征在空间分布上可能存在差异,从而导致在使用两个独立分支进行预测时出现一定程度的misalignment。
最近的一些单阶段目标检测器通过关注目标的中心来尝试解决这一问题(比如CenterNet、FoveaBox、FCOS、ATSS)。这些方法假设在目标中心的anchor(对于anchor-free的方法,指的就是anchor point;对于anchor-based的方法,指的就是anchor box)可以为分类和定位提供更准确的预测。比如FCOS和ATSS都使用了centerness分支,用以提高目标中心附近anchor的分类分数,并为相应anchor的定位loss分配更大的权重。此外,FoveaBox将目标预先定义的中心区域内的anchor视为正样本。这些方法取得了很好的效果,但仍存在两个局限性:
- 分类和定位依然是各自独立的。这些方法都使用两个并行的分支分别独立的执行分类和定位。这使得分类子任务和定位子任务之间缺乏交互,从而导致预测不一致。如Fig1所示,在ATSS的结果中,待检测目标餐桌的最佳分类anchor却对披萨的定位更准确。
- 任务无关的样本分配。在划分正负样本的时候,anchor-free方法一般通过anchor point到目标中心的距离来划分样本,而anchor-based方法一般通过anchor box和GT box的IoU来划分样本。但是,最佳分类anchor和最佳定位anchor往往不一致(如Fig1中ATSS结果所示),并且可能随着目标形状和特征的不同而产生变化。并且从Fig1中我们还能看到,最佳anchor可能并不在目标中心。因此,在NMS阶段,精度较高的bbox可能会被精度较低的bbox抑制。

解释下Fig1,上面一行是ATSS的结果,下面一行是TOOD的结果。红色块是最佳分类anchor,绿色块是最佳定位anchor,如果两者重合,则只显示红色。待检测目标为餐桌(Dining table),其GT box用黄色框表示。白色箭头是最佳anchor偏离目标中心的主方向。由红色块anchor预测得到的检测框用红色框表示,由绿色块anchor预测得到的检测框用绿色框表示,如果二者重合,则只显示红色框。第一列是检测结果。第二列是分类分数的空间分布热图,颜色越接近红色,表示该区域分类分数越高。第三列是定位分数(即IoU)的空间分布热图,颜色越红表示IoU越高。
为了解决这些局限性,我们提出了TOOD(Task-aligned One-stage Object Detection)。
2.Related Work
不再详述。
3.Task-aligned One-stage Object Detection
👉Overview.

TOOD的pipeline见Fig2。首先,Task-aligned head(T-head)基于FPN产生分类和定位的预测结果,实线框是预测的最佳(分类/定位)anchor。然后基于预测结果计算每个anchor的任务对齐度(task alignment metric,用于衡量两个预测结果之间的对齐程度),使用Task Alignment Learning(TAL)基于任务对齐度为T-head产生学习信号(learning signals)。最后,T-head使用学习信号自动调整分类和定位的分布。
3.1.Task-aligned Head

单阶段检测器中head的传统设计如Fig3(a)所示。我们考虑以下两个方面对其进行改进,实现一种高效的head结构:1)增加两个任务之间的交互;2)增强检测器学习对齐(alignment)的能力。我们提出的T-head结构见Fig3(b),其包含一个简单的特征提取器和两个TAP(Task-Aligned Predictors)。
为了增强分类和定位之间的交互,我们使用特征提取器从多个卷积层中学习了一堆任务交互特征(task-interactive features),如Fig3(b)的蓝色虚线箭头所示。这种设计不仅促进了任务交互,同时也为两个任务提供了具有多尺度有效感受野的多层级特征。我们用$X^{fpn}\in \mathbb{R}^{H \times W \times C}$表示FPN特征,其中,$H,W,C$分别表示高、宽和通道数。特征提取器使用$N$个连续的卷积来计算任务交互特征:
\[X_{k}^{inter} = \begin{cases} \delta(conv_{k}(X^{fpn})), & k = 1 \\ \delta(conv_{k}(X_{k-1}^{inter})), & k > 1 \end{cases} ,\forall k \in \{1, 2, ..., N\} \tag{1}\]其中,$conv_k$表示第$k$个卷积层,$\delta$表示relu激活函数。然后,计算得到的任务交互特征被喂入两个TAP中。
个人注解:$X^{inter}_1$到$X^{inter}_N$都会传给TAP。
👉Task-aligned Predictor (TAP).
如Fig3(c)所示,针对分类和定位分别计算任务特定特征(task-specific features):
\[X_k^{task}=w_k \cdot X_k^{inter},\ \forall k \in \{ 1,2,...,N \} \tag{2}\]其中,$w$的计算如下:
\[w=\sigma(fc_2(\delta(fc_1(x^{inter})))) \tag{3}\]其中,$fc_1,fc_2$是两个全连接层。$\sigma$是sigmoid函数。把所有的$X_k^{inter}$ concat在一起得到$X^{inter}$(即Fig3(c)中的Cat),然后$X^{inter}$经过一个Global Average Pooling得到$x^{inter}$(即Fig3(c)中的GAP)。
\[Z^{task} = conv_2(\delta(conv_1(X^{task}))) \tag{4}\]其中,将所有的$X_k^{task}$ concat在一起得到$X^{task}$,$conv_1$是$1\times 1$卷积层用于降维。通过对输出维度的控制,得到的$Z^{task}$可以是分类预测结果$P \in \mathbb{R}^{H \times W \times 80}$或定位预测结果$B \in \mathbb{R}^{H \times W \times 4}$(FCOS和ATSS形式的bbox预测)。
👉Prediction alignment.
在预测步骤,我们进一步对齐$P$和$B$的空间分布。之前的工作,比如centerness分支或IoU分支,都只能根据分类特征或定位特征来调整分类预测,而我们则使用计算得到的任务交互特征来联合考虑这两个任务并对齐其预测结果。我们对两个任务分别执行对齐操作。如Fig3(c)所示,我们使用空间概率图(spatial probability map)$M \in \mathbb{R}^{H\times W \times 1}$来调整分类预测:
\[P^{align} = \sqrt{P \times M} \tag{5}\]其中,$M$是根据交互特征计算的,使其能够学习每个空间位置上两个任务之间的一致性程度。
同时,为了对齐定位预测,我们基于交互特征进一步学习了空间偏移图(spatial offset maps)$O \in \mathbb{R}^{H \times W \times 8}$,用于调整每个位置预测的bbox。
\[B^{align}(i,j,c) = B(i+O(i,j,2\times c),j+O(i,j,2\times c+1),c) \tag{6}\]其中,$(i,j,k)$表示第$c$个通道上坐标为$(i,j)$的点。式(6)通过双线性插值实现,由于$B$的通道数很少,所以其计算开销可以忽略不计。此外因为每个通道的偏移都是独立学习的,所以预测的bbox会更准确。
$M$和$O$的获取:
\[M = \sigma (conv_2 (\delta(conv_1(X^{inter})))) \tag{7}\] \[O = conv_4 (\delta (conv_3 (X^{inter}))) \tag{8}\]其中,$conv_1$和$conv_3$是两个$1\times 1$卷积层用于降维。$M$和$O$的学习会用到TAL。但是需要注意的是,我们的T-head是一个独立的模块,即使没有TAL也可以很好的工作。它可以很容易的以即插即用的方式应用于各种单阶段目标检测器,以提高检测性能。
3.2.Task Alignment Learning
TAL进一步指导T-head做出与任务对齐的预测(task-aligned predictions)。TAL和之前的一些研究有两方面的不同。首先,从任务对齐的角度来看,它根据设计的度量指标动态选择高质量的anchor。其次,它同时考虑了anchor分配和权重。它包括一个样本分配策略和专门为对齐这两个任务而设计的新loss。
3.2.1.Task-aligned Sample Assignment
为了应对NMS,训练实例的anchor分配应满足以下规则:
- 一个对齐良好的anchor应该能够预测得到一个精确的定位且有着高的分类分数。
- 未对齐的anchor应具有较低的分类分数,且后续被NMS算法所抑制。
基于这两个目标,我们设计了一个新的anchor对齐度量指标(alignment metric),以衡量anchor级别的任务对齐程度。对齐度量指标被集成到样本分配和损失函数中,以动态优化每个anchor的预测。
👉Anchor alignment metric.
分类分数代表了分类子任务的预测质量,预测bbox和GT box之间的IoU代表了定位子任务的预测质量,因此我们用分类分数和IoU的高阶组合来衡量任务对齐程度。具体来说,我们设计了以下度量指标来计算每个实例在anchor级别上的对齐程度:
\[t = s^{\alpha} \times u ^{\beta} \tag{9}\]其中,$s$是分类分数,$u$是IoU的值。
👉Training sample assignment.
个人注解:TOOD在训练过程中进行动态样本分配。
训练样本分配对目标检测器的训练至关重要。对于每个实例,选择具有最大$t$值的$m$个anchor作为正样本,剩余anchor作为负样本。
3.2.2.Task-aligned Loss
👉Classification objective.
为了提高对齐anchor的分类分数,同时降低未对齐anchor(即$t$值较小)的分类分数,在训练过程中,我们将正样本anchor的二值标签替换为$t$值。然而,我们发现,当正样本anchor的标签(即$t$值)随着$\alpha$和$\beta$的增加而变小时,网络无法收敛。因此,我们使用归一化后的$t$,即$\hat{t}$,作为正样本anchor的标签。归一化的方法:$\hat{t}$的最大值等于每个实例中最大的IoU值(即$u$)。对于分类子任务,在正样本上计算BCE:
\[L_{cls\_pos} = \sum_{i=1}^{N_{pos}} BCE(s_i,\hat{t}_i) \tag{10}\]个人注解:此处BCE的标签不是0和1了,计算应调整为:
\[BCE(s_i,\hat{t}_i) = -(\hat{t}_i\log (s_i)+(1-\hat{t}_i)\log (1-s_i))\]
对于分类子任务,为了缓解正负样本的不平衡,我们采用了focal loss。其中,focal loss在正样本上的计算可以替换为式(10),分类子任务最终的损失函数定义如下:
\[L_{cls}=\sum_{i=1}^{N_{pos}}\lvert \hat{t}_i-s_i \rvert^{\gamma} BCE(s_i,\hat{t}_i)+\sum_{j=1}^{N_{neg}}s_j^{\gamma} BCE(s_j,0) \tag{11}\]个人注解:
正样本部分的BCE计算:
\[BCE(s_i,\hat{t}_i) = -(\hat{t}_i\log (s_i)+(1-\hat{t}_i)\log (1-s_i))\]负样本部分的BCE计算:
\[BCE(s_j,0)=-\log (1-s_j)\]
👉Localization objective.
由对齐良好的anchor(即有较大的$t$值)预测的bbox通常具有较高的分类分数和精确的定位,并且更有可能在NMS期间被保留下来。
\[L_{reg} = \sum_{i=1}^{N_{pos}} \hat{t}_i L_{GIoU}(b_i,\bar{b_i}) \tag{12}\]使用GIoU loss。$b$是预测的bbox,$\bar{b}$是GT bbox。TAL总的训练loss是$L_{cls}$和$L_{reg}$的和。
个人注解:对于式(12),$\hat{t}$越大表示分类和定位对齐的越好,而$L_{GIoU}$越小则表示定位越准确,看似两个矛盾的指标被乘在了一起。实际上,高$\hat{t}$会放大$L_{GIoU}$的影响,迫使模型更关注那些分类和定位对齐度高但定位误差大的anchor。而对于$\hat{t}$小的anchor,即使定位误差较大,模型也不会过度关注。
4.Experiments and Results
👉Dataset and evaluation protocol.
所有的实验都在MS-COCO 2017上进行。训练集为trainval135k(共115K张图像),用于消融实验的验证集为minival(共5K张图像)。主要结果基于测试集test-dev。
👉Implementation details.
使用常见的“backbone-FPN-head” pipeline,使用了不同的backbone,包括ResNet-50、ResNet-101、ResNeXt-101-64x4d,在ImageNet上预训练。和ATSS类似,TOOD在每个位置上放置一个anchor。除非特殊说明,我们汇报的都是anchor-free版本的TOOD的结果(anchor-based版本的TOOD可以达到和表3近似的性能)。将T-head中的参数$N$设为6,使其和传统并行head有着近似的参数量,focal loss中的参数$\gamma$设为2。更多实现和训练细节见第6部分的补充材料。
4.1.Ablation Study
对于消融实验,我们使用ResNet-50作为backbone,训练了12个epoch。实验基于COCO minival数据集。
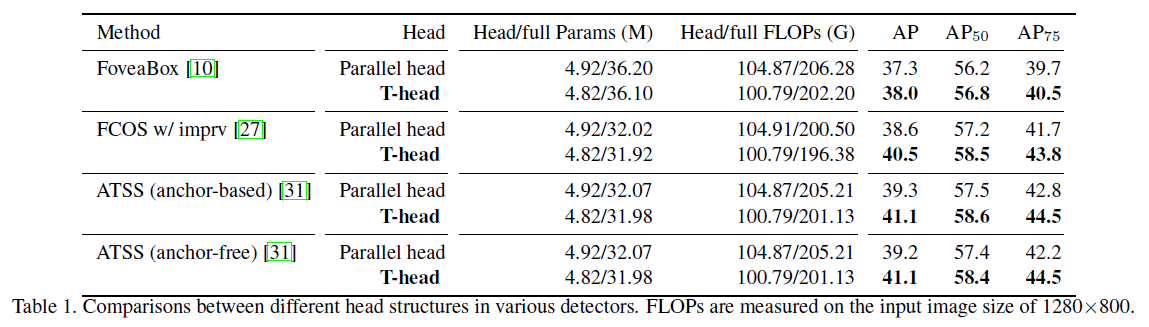
👉On head structures.
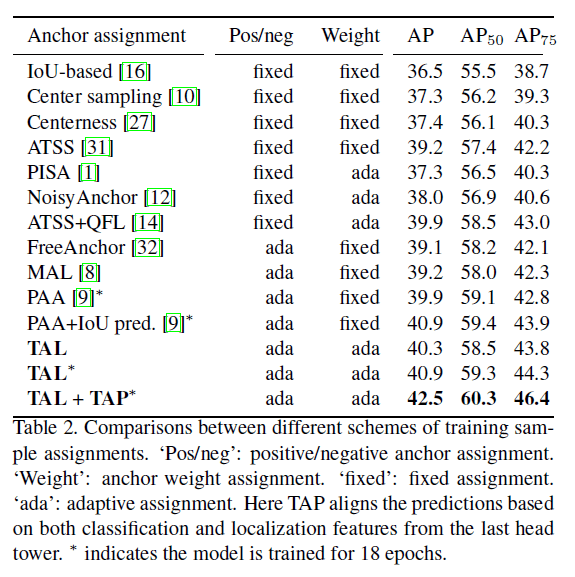
👉On sample assignments.
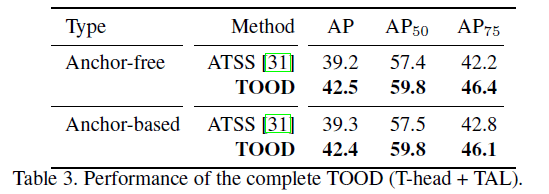
👉TOOD.
👉On hyper-parameters.

最后我们采用$\alpha=1,\beta=6$。我们还对参数$m$(见第3.2.1部分)进行了消融实验,取了不同的值:$[5,9,13,17,21]$,得到的结果在42.0~42.5 AP,说明$m$对性能的影响不明显,我们最后取$m=13$。
4.2.Comparison with the State-of-the-Art

在训练阶段,都使用了scale jitter(480-800),都训练了24个epoch。为了公平比较,汇报的结果都基于single model+single testing scale。对于TOOD+DCN,DCN只用在head tower的前两层。
个人注解:scale jitter会对输入图像进行随机缩放。
4.3.Quantitative Analysis for Task-alignment

我们定量分析了所提出方法对任务对齐的影响。在不使用NMS的情况下,使用皮尔逊相关系数(Pearson Correlation Coefficient,PCC)来衡量分类和定位之间的一致性。具体来说,对于每个实例,计算分类分数最高的50个anchor的分类和定位之间的相关性。此外,还计算了分类分数最高的10个anchor的IoU,用以衡量定位的精度。如表6所示,通过使用T-head和TAL,mean PCC和IoU都有所提升。在使用NMS和T-head以及TAL的情况下,正确检测框(Correct boxes,IoU>=0.5)的数量有所上升,冗余检测框(Redundant boxes,IoU>=0.5)和错误检测框(Error boxes,0.1<IoU<0.5)的数量有所下降。一些检测示例见Fig4。

Fig4中,红色块是分类最佳anchor,绿色块是定位最佳anchor。图的看法和Fig1一样。
5.Conclusion
不再赘述。
6.Supplementary material
6.1.Implementation details
👉Optimization.
我们的实现基于MMDetection和Pytorch。模型backbone为ResNet-50,训练使用了4块GPU,每块GPU上有mini-batch=4;其他backbone的模型训练用了8块GPU,每块GPU上有mini-batch=2。使用SGD,weight decay=0.0001,momentum=0.9。除非特殊说明,模型默认训练12个epoch(即1倍的learning schedule),初始学习率为0.01,然后在第8和第11个epoch时学习率除以10。输入图像被resize到短边为800,且长边小于1333。如果一个anchor被分配给多个目标,则我们会只选择面积最小的那个目标。在和其他SOTA方法比较的实验中,模型训练使用了scale jitter,且训练了24个epoch(即2倍的learning schedule)。
👉Inference.
推理过程和ATSS一样。对输入图像的resize和训练时的处理一样,然后通过网络得到预测的bbox及对应的预测类别。过滤掉分类分数低于0.05的预测结果,对每个特征层级,选取分数最高的1000个bbox。最后,使用NMS(IoU阈值为0.6),最终每张图像得到前100置信度的预测结果。
6.2.Discussion
比较了TAL和之前的一些方法,在此不再详述。
