博客为参考《程序是怎样跑起来的》一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.汇编语言和本地代码是一一对应的
👉第10章热身问答:
- 本地代码的指令中,表示其功能的英语缩写称为什么?
- 助记符。汇编语言是通过利用助记符来记述程序的。
- 汇编语言的源代码转换成本地代码的方式称为什么?
- 汇编。使用汇编器这个工具来进行汇编。
- 本地代码转换成汇编语言的源代码的方式称为什么?
- 反汇编。通过反汇编,得到人们可以理解的代码。
- 汇编语言的源文件的扩展名,通常是什么格式?
.asm。.asm是assembler(汇编器)的略写。
- 汇编语言程序中的段定义指的是什么?
- 构成程序的命令和数据的集合组。在高级编程语言的源代码中,即使指令和数据在编写时是分散的,编译后也会在段定义中集合汇总起来。
- 汇编语言的跳转指令,是在何种情况下使用的?
- 将程序流程跳转到其他地址时需要用到该指令。在汇编语言中,通过跳转指令,可以实现循环和条件分支。
计算机CPU能直接解释运行的只有本地代码(机器语言)程序。用C语言等编写的源代码,需要通过各自的编译器编译后,转换成本地代码。
通过调查本地代码的内容,可以了解程序最终是以何种形式来运行的。但是,如果直接打开本地代码来看的话,只能看到数值的罗列。如果直接使用这些数值来编写程序的话,还真是不太容易理解。因而就产生了这样一种想法,那就是在各本地代码中,附带上表示其功能的英语单词缩写。例如,在加法运算的本地代码中加上add(addition的缩写)、在比较运算的本地代码中加上cmp(compare的缩写)等。这些缩写称为助记符,使用助记符的编程语言称为汇编语言。这样,通过查看汇编语言编写的源代码,就可以了解程序的本质了。因为这和查看本地代码的源代码,是同一级别的。
不过,即使是用汇编语言编写的源代码,最终也必须要转换成本地代码才能运行。负责转换工作的程序称为汇编器,转换这一处理本身称为汇编。在将源代码转换成本地代码这个功能方面,汇编器和编译器是同样的。
用汇编语言编写的源代码,和本地代码是一一对应的。因而,本地代码也可以反过来转换成汇编语言的源代码。持有该功能的逆变换程序称为反汇编程序,逆变换这一处理本身称为反汇编(图10-1)。
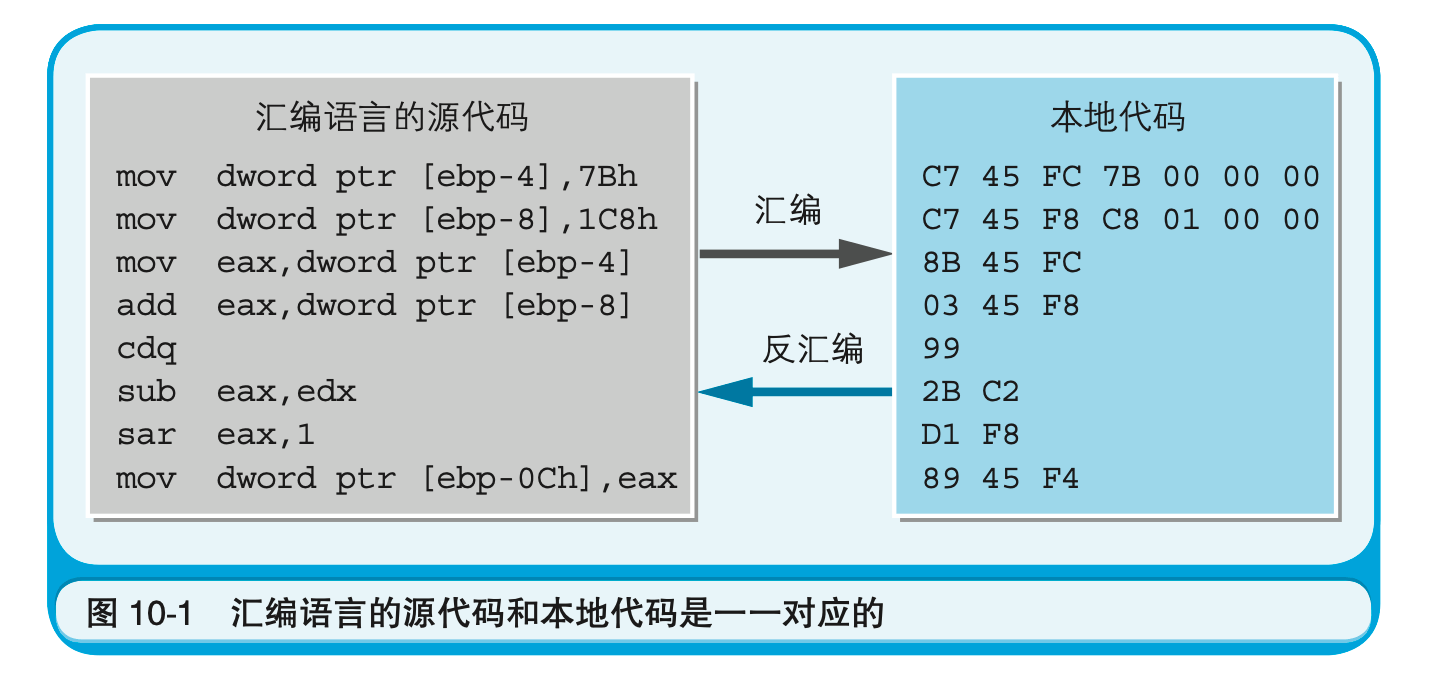
哪怕是用C语言编写的源代码,编译后也会转换成特定CPU用的本地代码。而将其反汇编的话,就可以得到汇编语言的源代码,并对其内容进行调查。不过,本地代码变换成C语言源代码的反编译,则要比反汇编困难。这是因为,C语言的源代码同本地代码不是一一对应的,因此完全还原到原始的源代码是不太可能的$^1$。
- 通过解析可执行文件得到源代码的方式称为“反汇编”或“反编译”,也称为“反向工程”。
2.通过编译器输出汇编语言的源代码
除了将本地代码进行反汇编这一方法外,通过其他方式也可以获取汇编语言的源代码。大部分C语言编译器,都可以把利用C语言编写的源代码转换成汇编语言的源代码,而不是本地代码。Borland C++中,通过在编译器的选项中指定“-S”,就可以生成汇编语言的源代码了。
用Windows的记事本等文本编辑器编写如代码清单10-1所示的C语言源代码,并将其命名为Sample4.c进行保存。因为没有包含程序运行起始位置$^1$的main函数部分,这种情况下直接编译是无法运行的。大家只需把它看成是学习汇编语言的一个示例即可。
- 在命令提示符上运行的程序中,main函数位于程序运行起始位置。而在Windows上运行的程序中,WinMain函数位于程序运行起始位置。程序运行起始位置也称为“入口点”。


由Windows开始菜单启动命令提示符,把当前目录变更到Sample4.c保存的文件夹后,输入下面的命令并按下Enter键。bcc32是启动Borland C++编译器的命令。“-c”选项指的是,仅进行编译而不进行链接$^1$。“-S”选项被用来指定生成汇编语言的源代码。
- 链接是指把多个目标文件结合成1个可执行文件。详情请参考第8章。
1
bcc32 -c -S Sample4.c
作为编译的结果,当前目录下会生成一个名为Sample4.asm的汇编语言源代码。汇编语言源文件的扩展名,通常用“.asm”来表示。下面就让我们使用记事本来看一下Sample4.asm的内容。可以发现,C语言的源代码和转换成汇编语言的源代码是交叉显示的。而这也为我们对两者进行比较学习提供了绝好的教材。在该汇编语言代码中,分号(;)以后是注释。由于C语言的源代码变成了注释,因此就可以直接对Sample4.asm进行汇编并将其转换成本地代码了(代码清单10-2)。


3.不会转换成本地代码的伪指令
汇编语言的源代码,是由转换成本地代码的指令和针对汇编器的伪指令构成的。伪指令负责把程序的构造及汇编的方法指示给汇编器(转换程序)。不过伪指令本身是无法汇编转换成本地代码的。这里我们把代码清单10-2中用到的伪指令部分摘出,如代码清单10-3所示。


由伪指令segment和ends围起来的部分,是给构成程序的命令和数据的集合体加上一个名字而得到的,称为段定义$^1$。在程序中,段定义指的是命令和数据等程序的集合体的意思。一个程序由多个段定义构成。
- 段定义(segment)是用来区分或者划定范围区域的意思。汇编语言的segment伪指令表示段定义的起始,ends伪指令表示段定义的结束。段定义是一个连续的内存空间。
源代码的开始位置,定义了3个名称分别为_TEXT、_DATA、_BSS的段定义。_TEXT是指令的段定义,_DATA是被初始化(由初始值)的数据的段定义,_BSS是尚未初始化的数据的段定义。类似于这种段定义的名称及划分方法是Borland C++的规定,是由Borland C++的编译器自动分配的。因而程序段定义的配置顺序就成了_TEXT、_DATA、_BSS,这样也确保了内存的连续性。group$^1$这一伪指令,表示的是把_BSS和_DATA这两个段定义汇总为名为DGROUP的组。此外,栈和堆的内存空间会在程序运行时生成,详见第8章。
- group指的是将源代码中不同的段定义在本地代码程序中整合为一个。
围起_AddNum和_MyFunc的_TEXT segment和_TEXT ends,表示_AddNum和_MyFunc是属于_TEXT这一段定义的。因此,即使在源代码中指令和数据是混杂编写的,经过编译或者汇编后,也会转换成段定义划分整齐的本地代码。
_AddNum proc和_AddNum endp围起来的部分,以及_MyFunc proc和_MyFunc endp围起来的部分,分别表示AddNum函数和MyFunc函数的范围。编译后在函数名前附带上下划线(_),是Borland C++的规定。在C语言中编写的AddNum函数,在内部是以_AddNum这个名称被处理的。伪指令proc和endp围起来的部分,表示的是过程(procedure)的范围。在汇编语言中,这种相当于C语言的函数的形式称为过程。
末尾的end伪指令,表示的是源代码的结束。
4.汇编语言的语法是“操作码+操作数”
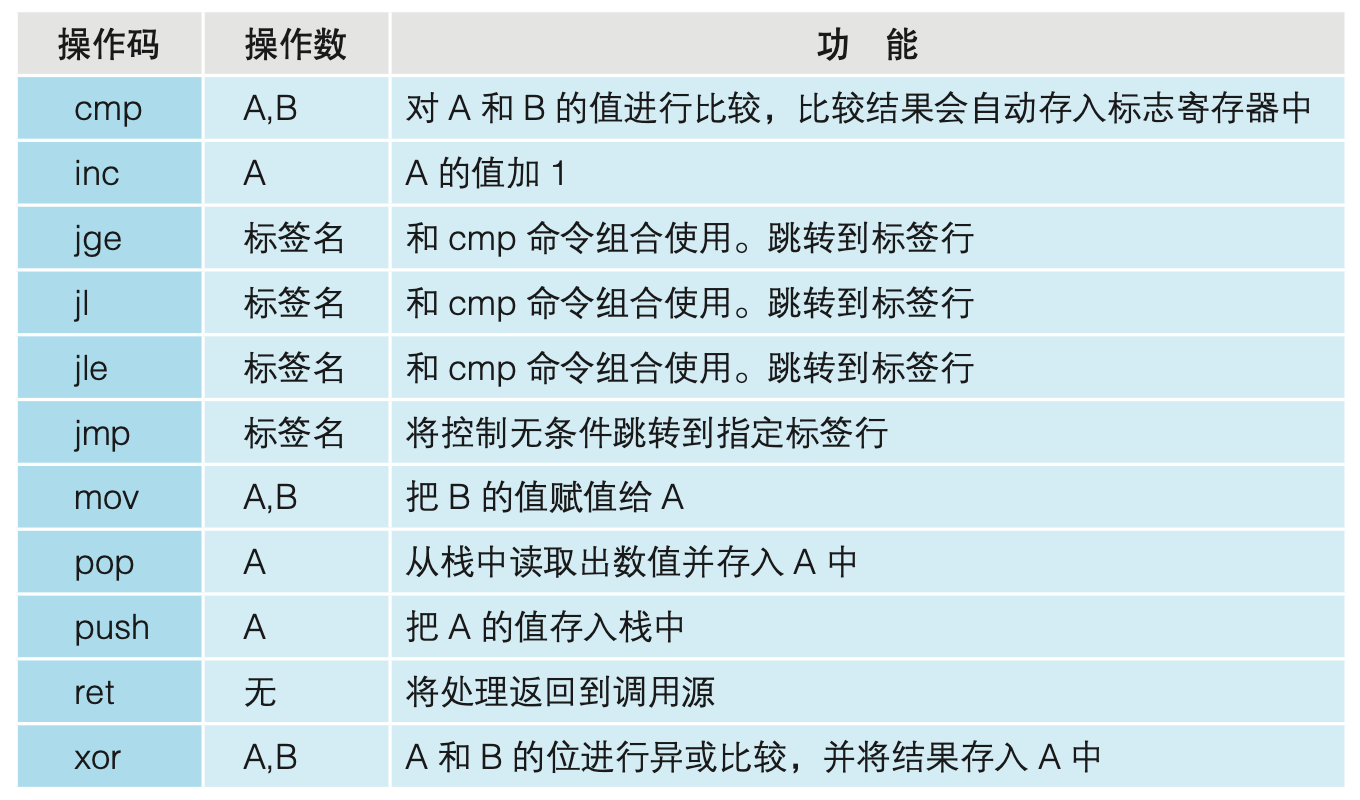
在汇编语言中,1行表示对CPU的一个指令。汇编语言指令的语法结构是操作码+操作数$^1$(也存在只有操作码没有操作数的指令)。
- 在汇编语言中,类似于mov这样的指令称为“操作码”(opcode),作为指令对象的内存地址及寄存器称为“操作数”(operand)。被转换成CPU可以直接解析运行的二进制的操作码和操作数,就是本地代码。
操作码表示的是指令动作,操作数表示的是指令对象。操作码和操作数罗列在一起的语法,就是一个英文的指令文本。操作码是动词,操作数相当于宾语。例如,用汇编语言来分析“Give me money”这个英文指令的话,Give就是操作码,me和money就是操作数。汇编语言中存在多个操作数的情况下,要用逗号把它们分割开来,就像Give me, money这样。
能够使用何种形式的操作码,是由CPU的种类决定的。表10-1对代码清单10-2中用到的操作码的功能进行了整理。这些都是32位x86系列CPU用的操作码。操作数中指定了寄存器名、内存地址、常数等。在表10-1中,操作数是用A和B来表示的。

本地代码加载到内存后才能运行。内存中存储着构成本地代码的指令和数据。程序运行时,CPU会从内存中把指令和数据读出,然后再将其存储在CPU内部的寄存器中进行处理(图10-2)。

寄存器是CPU中的存储区域。不过,寄存器并不仅仅具有存储指令和数据的功能,也有运算功能。x86系列CPU的寄存器的主要种类和角色如表10-2所示。寄存器的名称会通过汇编语言的源代码指定给操作数。内存中的存储区域是用地址编号来区分的。CPU内的寄存器是用eax及ebx这些名称来区分的。此外,CPU内部也有程序员无法直接操作的寄存器。例如,表示运算结果正负及溢出状态的标志寄存器及操作系统专用的寄存器等,都无法通过程序员编写的程序直接进行操作。
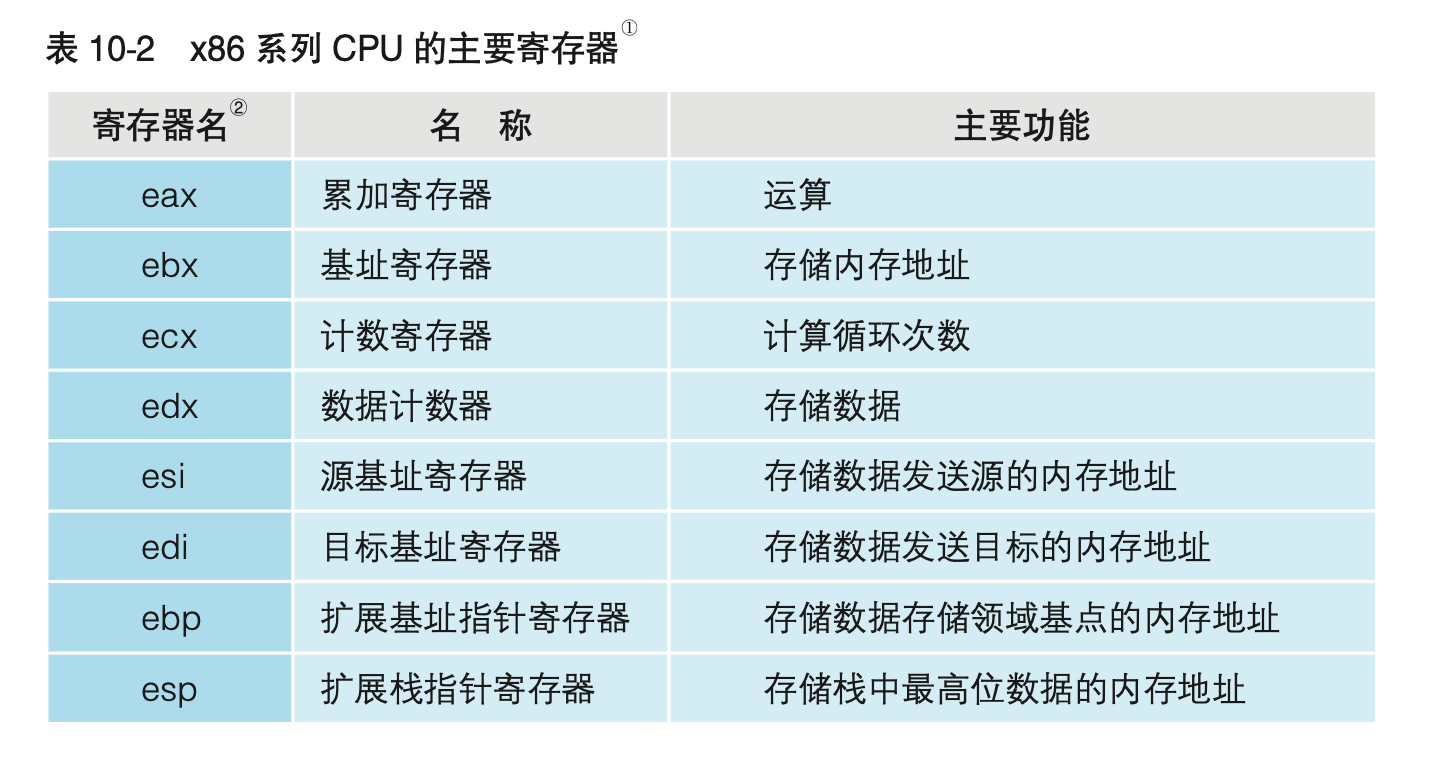
- 表10-2中表示的寄存器名称是x86自带的寄存器名称。在第1章中表1-1列出的寄存器名称是一般叫法。两者有些不同,例如,x86的扩展基址指针寄存器就相当于第1章中介绍的基址寄存器。
- x86系列32位CPU的寄存器名称中,开头都带了一个字母e,例如eax、ebx、ecx、edx等。这是因为16位CPU的寄存器名称是ax、bx、cx、dx等。32位CPU寄存器的名称中的e,有扩展(extended)的意思。我们也可以仅利用32位寄存器的低16位,此时只需把要指定的寄存器名开头的字母e去掉即可。
5.最常用的mov指令
指令中最常使用的是对寄存器和内存进行数据存储的mov指令。mov指令的两个操作数,分别用来指定数据的存储地和读出源。操作数中可以指定寄存器、常数、标签(附加在地址前),以及用方括号([])围起来的这些内容。如果指定了没有用方括号围起来的内容,就表示对该值进行处理;如果指定了用方括号围起来的内容,方括号中的值则会被解释为内存地址,然后就会对该内存地址对应的值进行读写操作。接下来就让我们来看一下代码清单10-2中用到的mov指令部分。
1
2
mov ebp, esp
mov eax, dword ptr [ebp+8]
mov ebp, esp中,esp寄存器中的值被直接存储在了ebp寄存器中。esp寄存器的值是100时ebp寄存器的值也是100。而在mov eax, dword ptr [ebp+8]的情况下,ebp寄存器的值加8后得到的值会被解释为内存地址。如果ebp寄存器的值是100的话,那么eax寄存器中存储的就是100+8=108地址的数据。dword ptr(double word pointer)表示的是从指定内存地址读出4字节的数据。像这样,有时也会在汇编语言的操作数前附带dword ptr这样的修饰语。
6.对栈进行push和pop
程序运行时,会在内存上申请分配一个称为栈的数据空间。数据在存储时是从内存的下层(大的地址编号)逐渐往上层(小的地址编号)累积,读出时则是按照从上往下的顺序进行(图10-3)的。
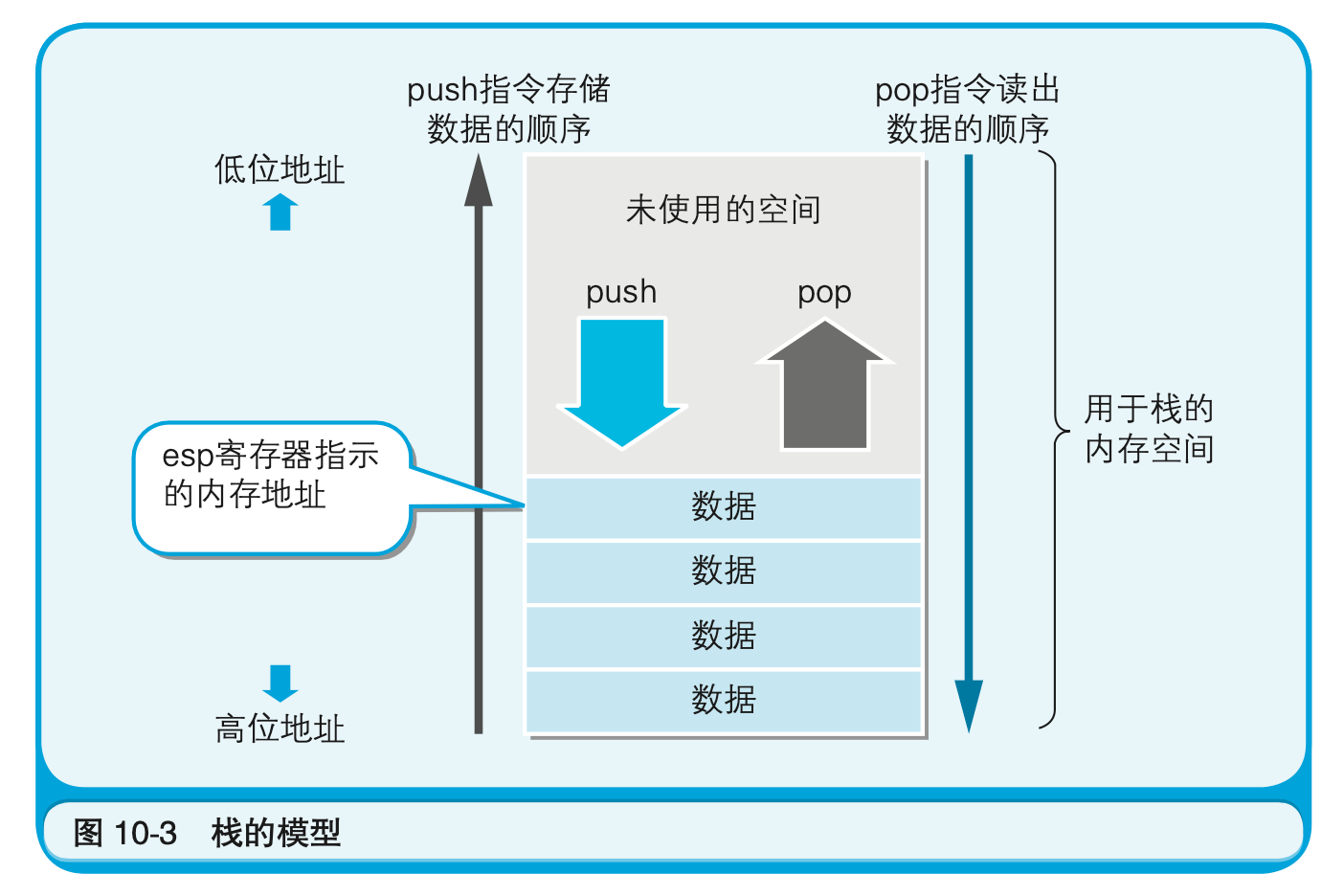
栈是存储临时数据的区域,它的特点是通过push指令和pop指令进行数据的存储和读出。往栈中存储数据称为“入栈”,从栈中读出数据称为“出栈”。32位x86系列的CPU中,进行1次push或pop,即可处理32位(4字节)的数据。
push指令和pop指令中只有一个操作数。该操作数表示的是“push的是什么及pop的是什么”,而不需要指定“对哪一个地址编号的内存进行push或pop”。这是因为,对栈进行读写的内存地址是由esp寄存器(栈指针)进行管理的。push指令和pop指令运行后,esp寄存器的值会自动进行更新(push指令是-4,pop命令是+4),因而程序员就没有必要指定内存地址了。
7.函数调用机制
让我们再来回顾一下代码清单10-2的内容。首先,让我们从MyFunc函数调用AddNum函数的汇编语言部分开始,来对函数的调用机制进行说明。函数调用是栈发挥大作用的场合。把代码清单10-2中的C语言源代码部分去除,然后再在各行追加注释,这时汇编语言的源代码就如代码清单10-4所示。这也就是MyFunc函数的处理内容。
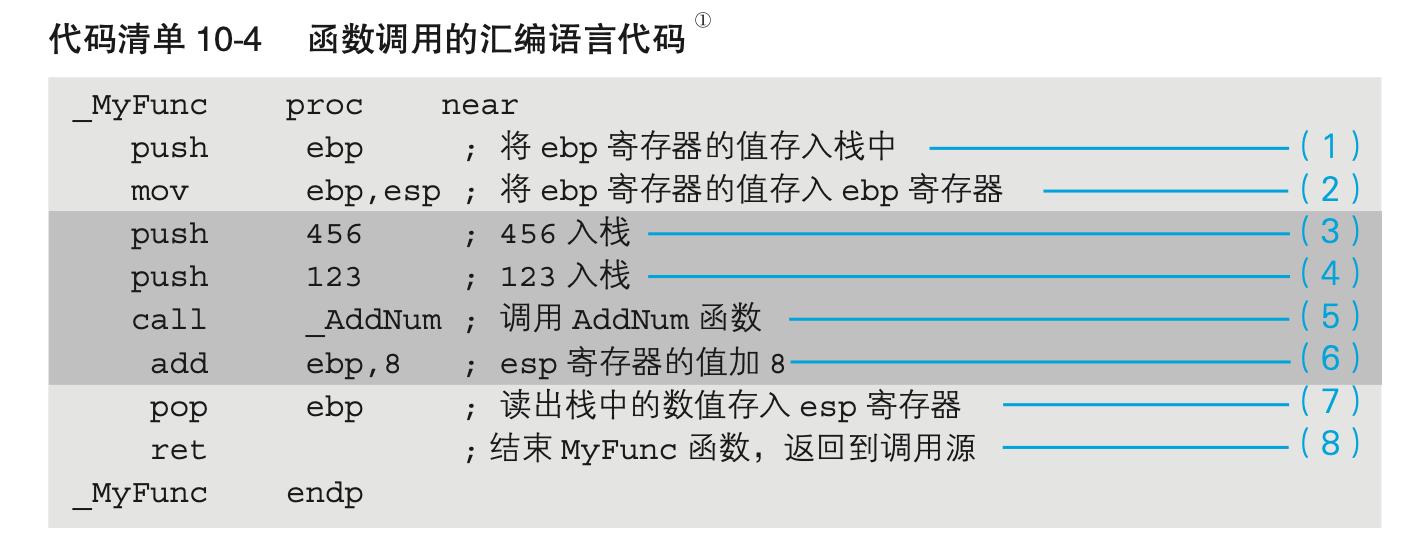
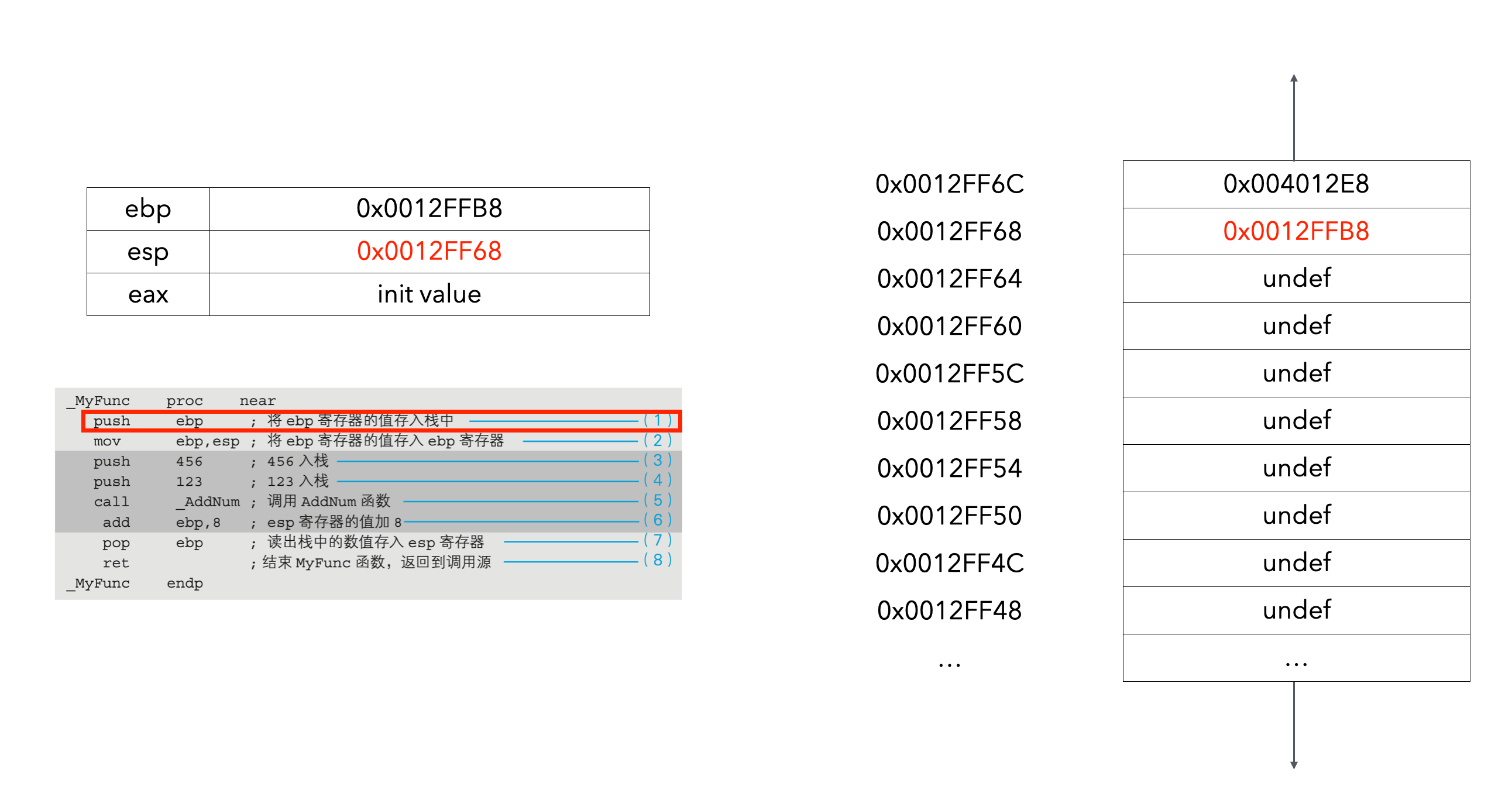
- 在函数的入口处把寄存器ebp的值入栈保存(代码清单10-4(1)),在函数的出口处出栈(代码清单10-4(7)),这是C语言编译器的规定。这样做是为了确保函数调用前后ebp寄存器的值不发生变化。
个人注解:如图10-3所示,esp自动指向栈的顶部。第(2)步的注释应该是将esp寄存器的值存入ebp寄存器。第(6)步的代码应该是
add esp,8。
(1)、(2)、(7)、(8)的处理适用于C语言中所有的函数。
(3)和(4)表示的是将传递给AddNum函数的参数通过push入栈。在C语言的源代码中,虽然记述为函数AddNum(123,456),但入栈时则会按照456、123这样的顺序,也就是位于后面的数值先入栈。这是C语言的规定。(5)的call指令,把程序流程跳转到了操作数中指定的AddNum函数所在的内存地址处。在汇编语言中,函数名表示的是函数所在的内存地址。AddNum函数处理完毕后,程序流程必须要返回到编号(6)这一行。call指令运行后,call指令的下一行((6)这一行)的内存地址(调用函数完毕后要返回的内存地址)会自动地push入栈。该值会在AddNum函数处理的最后通过ret指令pop出栈,然后程序流程就会返回到(6)这一行。
(6)部分会把栈中存储的两个参数(456和123)进行销毁处理。虽然通过使用两次pop指令也可以实现,不过采用esp寄存器加8的方式会更有效率(处理1次即可)。对栈进行数值的输入输出时,数值的单位是4字节。因此,通过在负责栈地址管理的esp寄存器中加上4的2倍8,就可以达到和运行两次pop命令同样的效果。虽然内存中的数据实际上还残留着,但只要把esp寄存器的值更新为数据存储地址前面的数据位置,该数据也就相当于被销毁了。
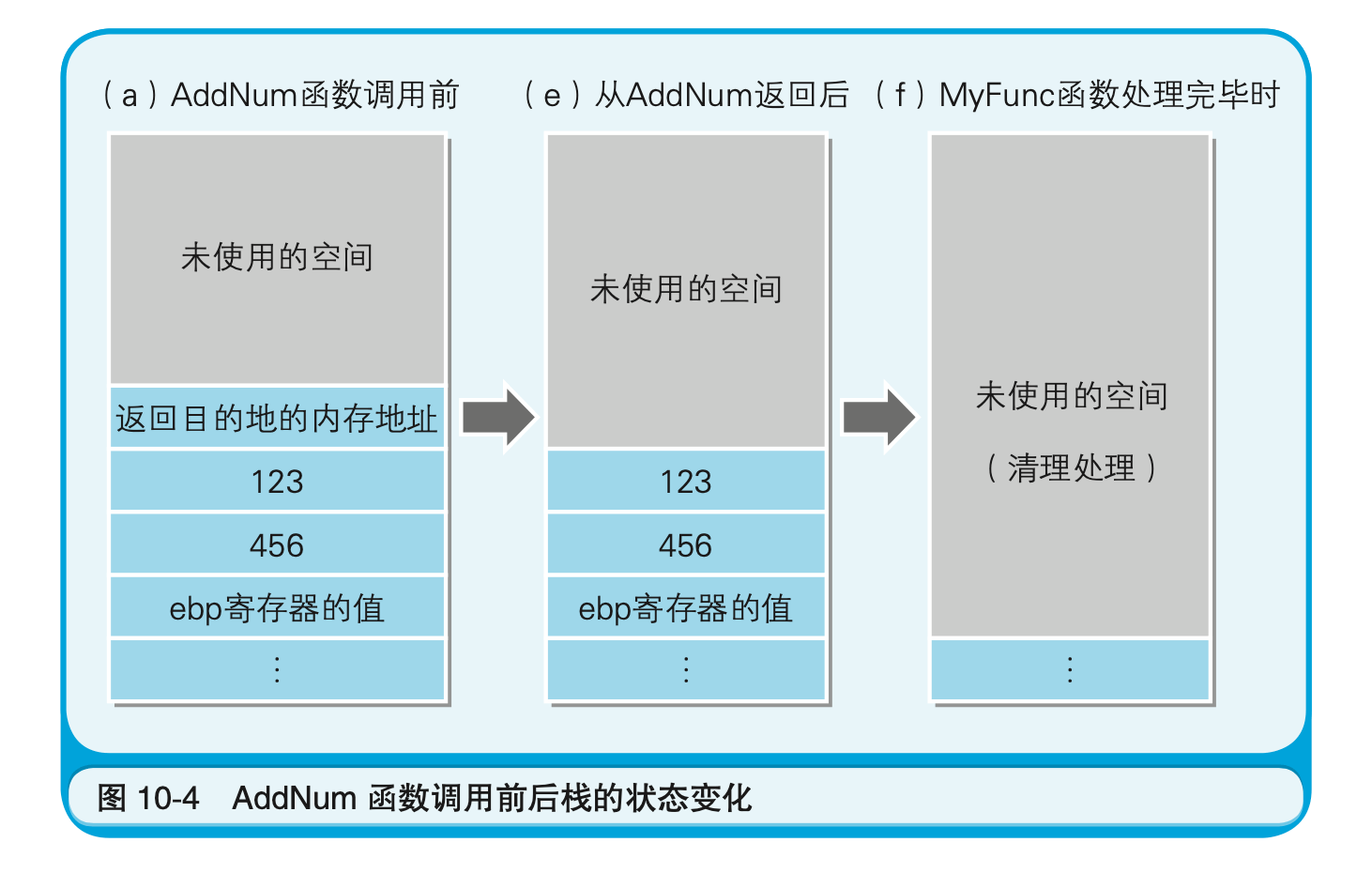
前面已经提到,push指令和pop指令必须以4字节为单位对数据进行入栈和出栈处理。因此,AddNum函数调用前和调用后栈的状态变化就如图10-4所示。长度小于4字节的123和456这些值在存储时,也占用了4字节的栈区域。
代码清单10-1中列出的C语言源代码中,有一个处理是在变量c中存储AddNum函数的返回值,不过在汇编语言的源代码中,并没有与此对应的处理。这是因为编译器有最优化功能。最优化功能是编译器在本地代码上费尽工夫实现的,其目的是让编译后的程序运行速度更快、文件更小。在代码清单10-1中,由于存储着AddNum函数返回值的变量c在后面没有被用到,因此编译器就会认为“该处理没有意义”,进而也就没有生成与之对应的汇编语言代码。在编译代码清单10-1的代码时,应该会出现“警告 W8004 Sample4.c 11: ‘c’的赋值未被使用 (函数MyFunc)”这样的警告消息。
8.函数内部的处理
接下来,让我们透过执行AddNum函数的源代码部分,来看一下参数的接收、返回值的返回等机制(代码清单10-5)。

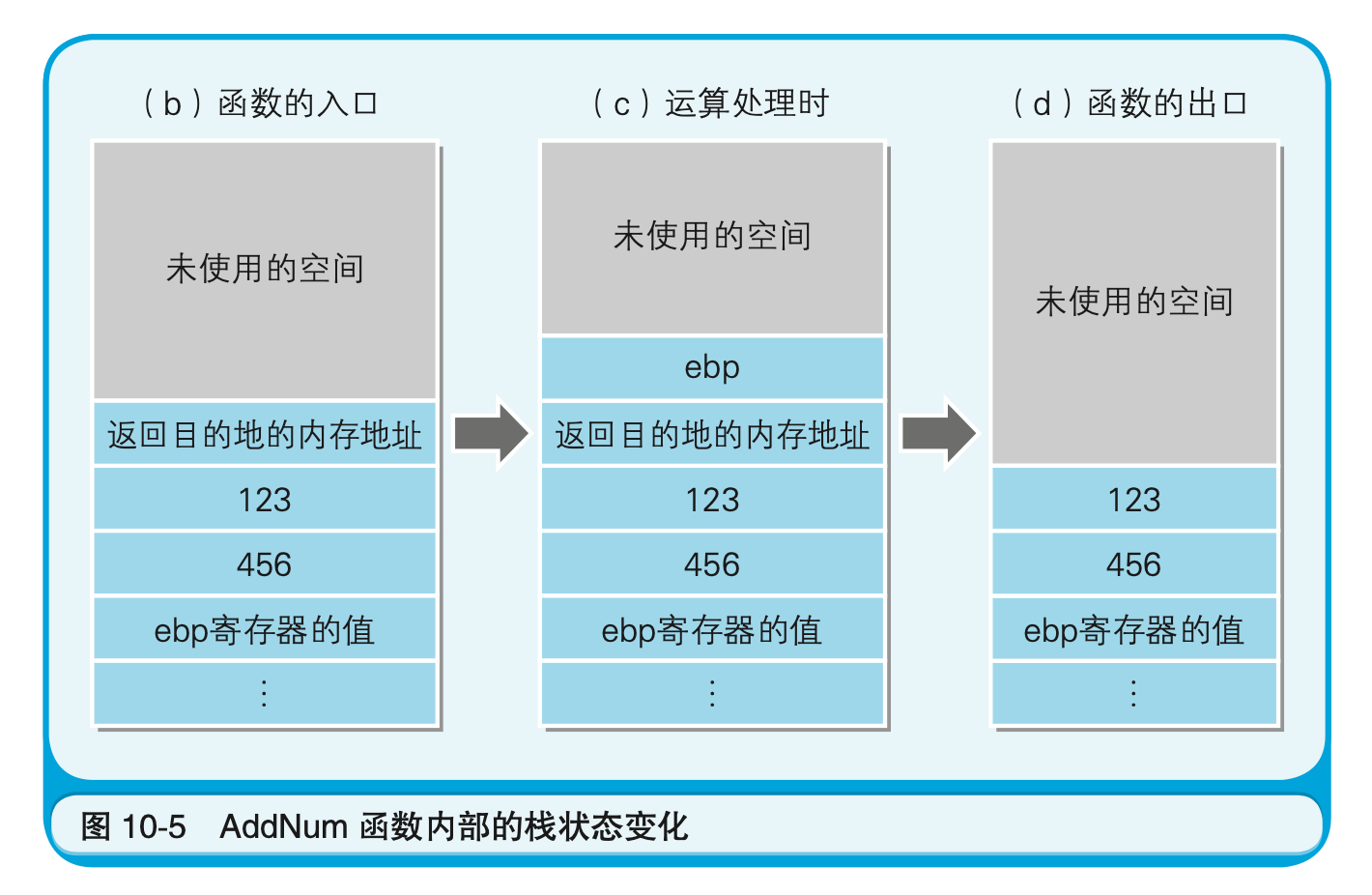
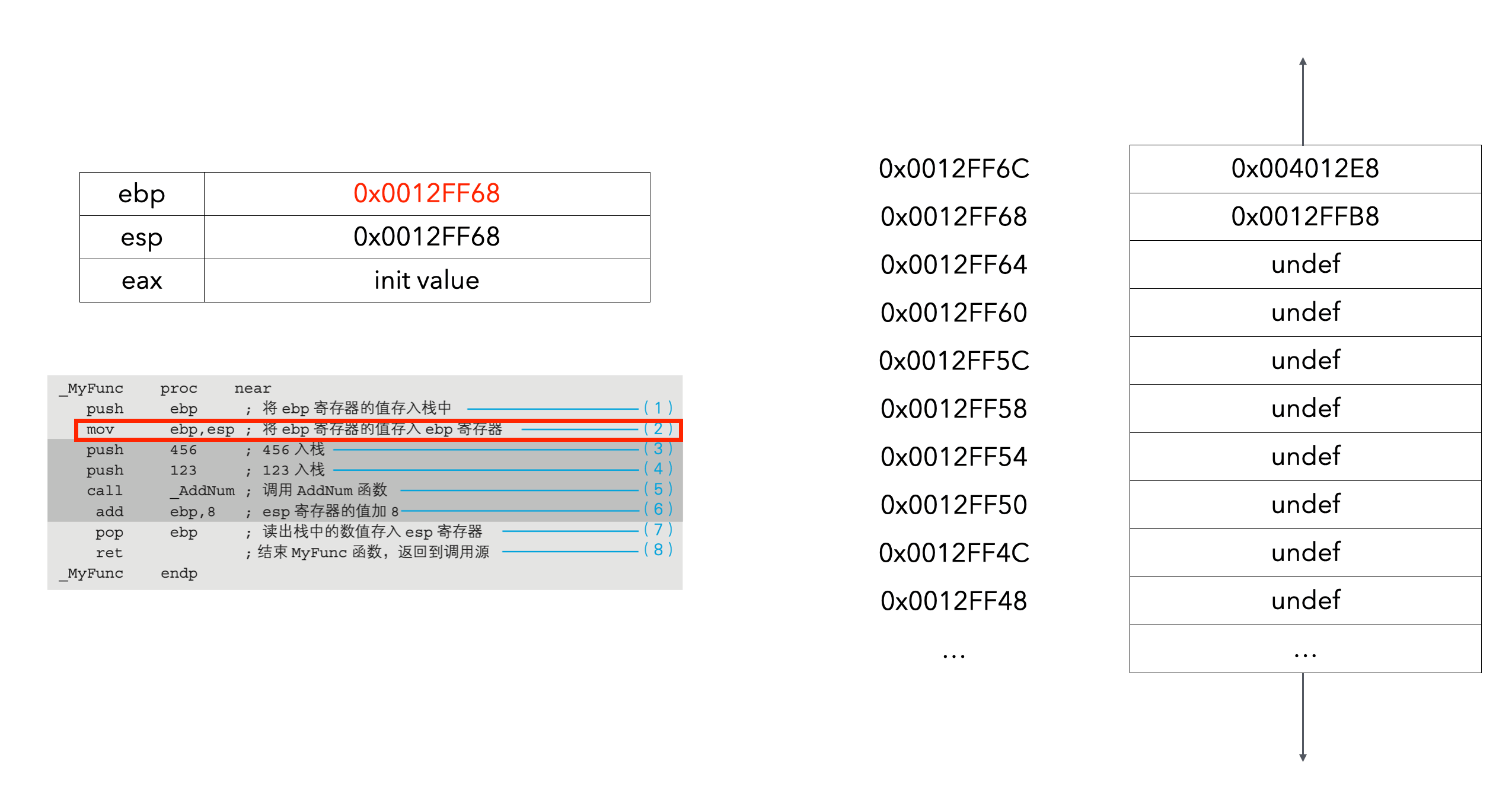
ebp寄存器的值在(1)中入栈,在(5)中出栈。这主要是为了把函数中用到的ebp寄存器的内容,恢复到函数调用前的状态。在进入函数处理之前,无法确定ebp寄存器用到了什么地方,但由于函数内部也会用到ebp寄存器,所以就暂时将该值保存了起来。CPU拥有的寄存器是有数量限制的。在函数调用前,调用源有可能已经在使用ebp寄存器了。因而,在函数内部利用的寄存器,要尽量返回到函数调用前的状态。为此,我们就需要将其暂时保存在栈中,然后再在函数处理完毕之前出栈,使其返回到原来的状态。
(2)中把负责管理栈地址的esp寄存器的值赋值到了ebp寄存器中。这是因为,在mov指令中方括号内的参数,是不允许指定esp寄存器的。因此,这里就采用了不直接通过esp,而是用ebp寄存器来读写栈内容的方法。
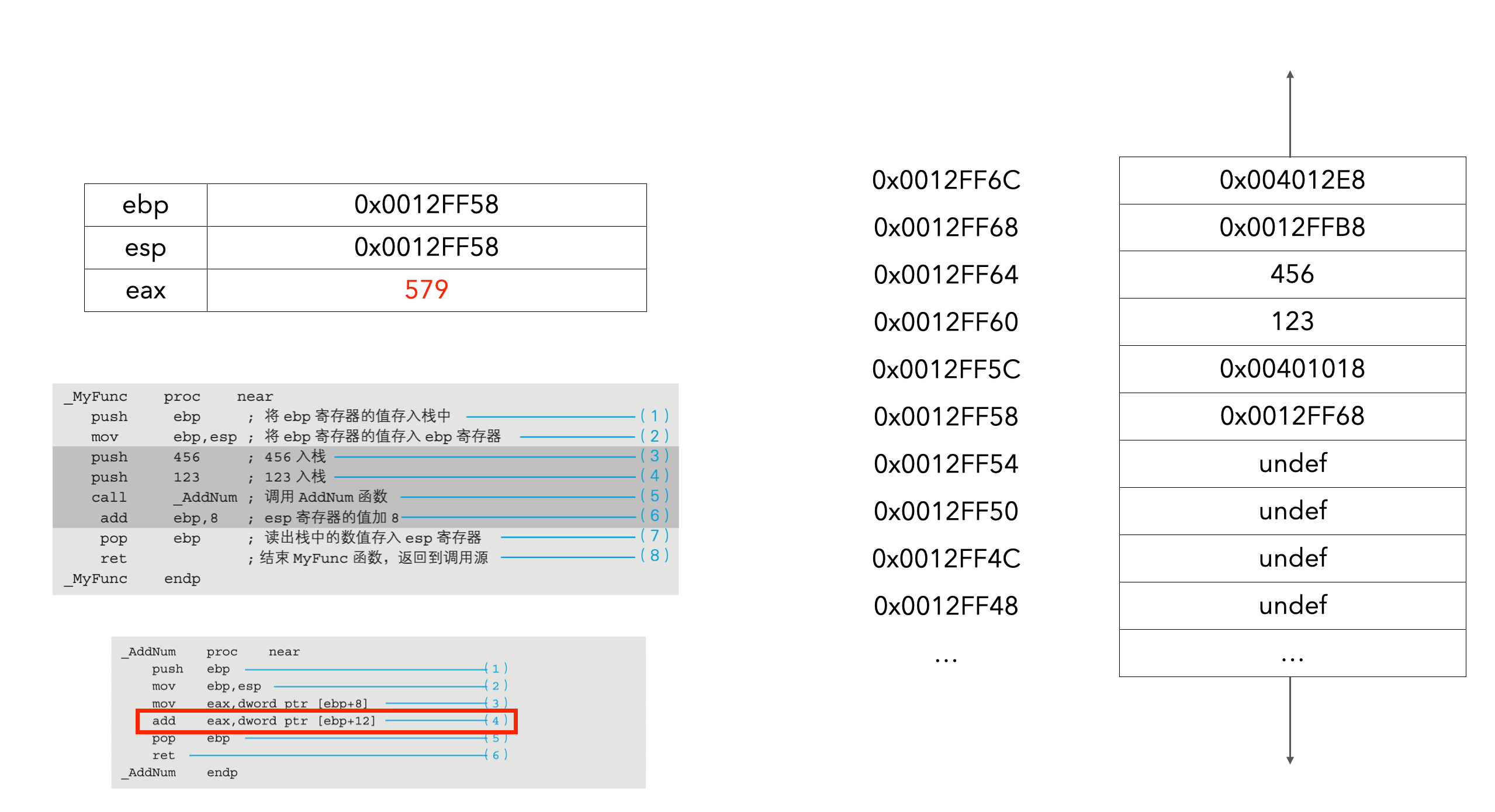
(3)是用[ebp+8]指定栈中存储的第1个参数123,并将其读出到eax寄存器中。eax寄存器是负责运算的累加寄存器。
通过(4)的add指令,把当前eax寄存器的值同第2个参数相加后的结果存储在eax寄存器中。[ebp+12]是用来指定第2个参数456的。在C语言中,函数的返回值必须通过eax寄存器返回,这也是规定。不过,和ebp寄存器不同的是,eax寄存器的值不用还原到原始状态。函数的参数是通过栈来传递,返回值是通过寄存器来返回的。
(6)中ret指令运行后,函数返回目的地的内存地址会自动出栈,据此,程序流程就会跳转返回到代码清单10-4的(6)(call _AddNum的下一行)。这时,AddNum函数入口和出口处栈的状态变化,就如图10-5所示。将图10-4和图10-5按照(a)(b)(c)(d)(e)(f)的顺序来看的话,函数调用处理时栈的状态变化就会很清楚了。由于(a)状态时处理跳转到AddNum函数,因此(a)和(b)是同样的。同理,在(d)状态时,处理跳转到了调用源,因此(d)和(e)是同样的。在(f)状态时则进行了清理处理。栈的最高位的数据地址,是一直存储在esp寄存器中的。
接下来举例详细说明下整个过程(ebp先给了一个初始值):


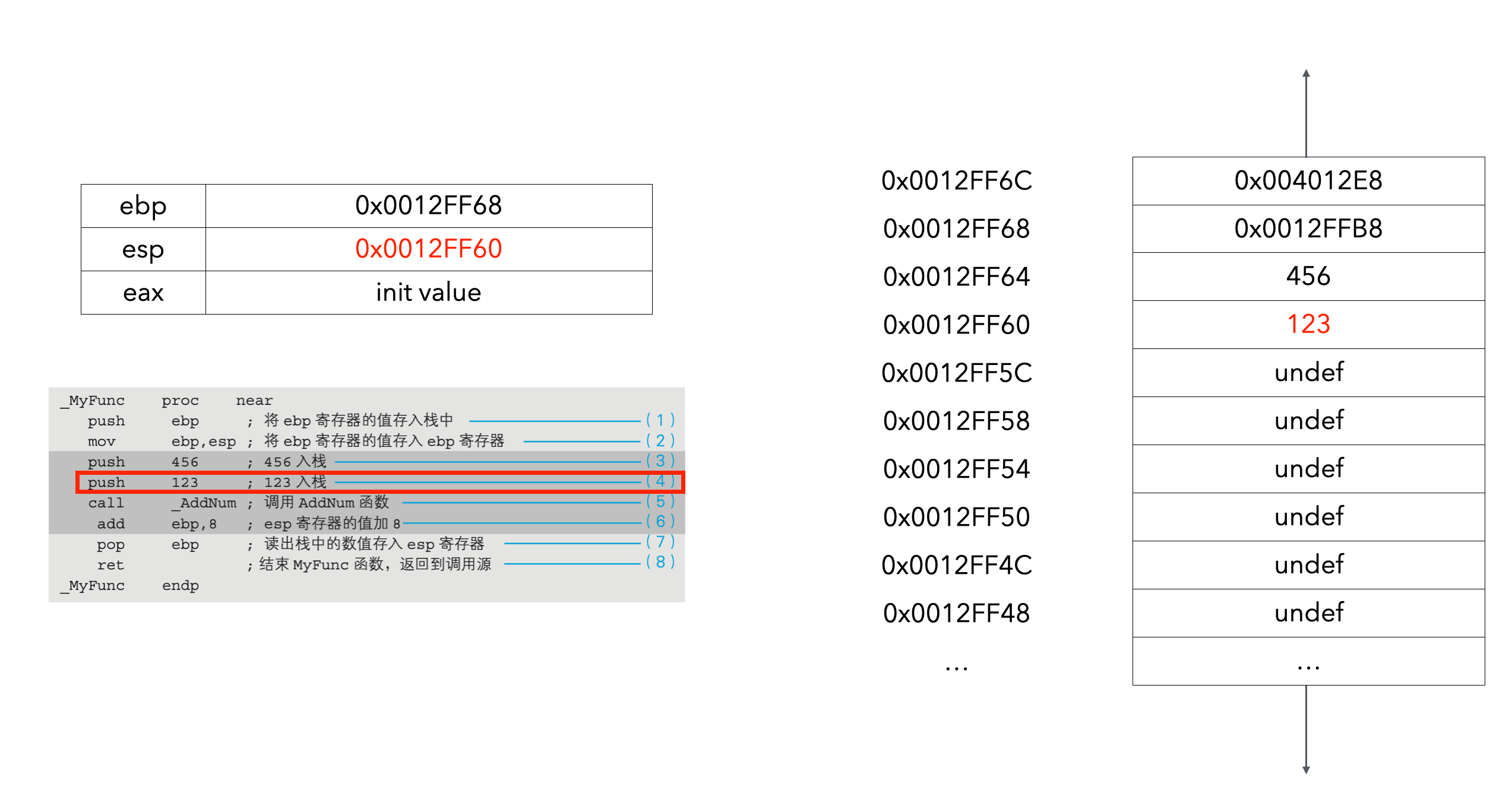
假设0x00401018是call _AddNum的下一行的内存地址:




eax存储的值是123+456=579:





9.始终确保全局变量用的内存空间
C语言中,在函数外部定义的变量称为全局变量,在函数内部定义的变量称为局部变量。


将代码清单10-6变换成汇编语言的源代码后,结果就如代码清单10-7所示。这里为了方便说明,我们省略了一部分汇编语言源代码,并改变了一下段定义的配置顺序,删除了注释。关于代码清单10-7中出现的汇编语言的指令,请参考表10-3。



编译后的程序,会被归类到名为段定义的组。初始化的全局变量,会像代码清单10-7的(1)那样被汇总到名为_DATA的段定义中,没有初始化的全局变量,会像(2)那样被汇总到名为_BSS的段定义中。指令则会像(3)那样被汇总到名为_TEXT的段定义中。这些段定义的名称是由Borland C++的使用规范来决定的。_DATA segment和_DATA ends、_BSS segment和_BSS ends、_TEXT segment和_TEXT ends,这些都是表示各段定义范围的伪指令。
首先让我们来看一下_DATA段定义的内容。(4)中的_a1 label dword定义了_a1这个标签。标签表示的是相对于段定义起始位置的位置。由于_a1在_DATA段定义的开头位置,所以相对位置是0。_a1就相当于全局变量a1。编译后的函数名和变量名前会附加一个下划线(_),这也是Borland C++的规定。(5)中的dd 1指的是,申请分配了4字节的内存空间,存储着1这个初始值。dd(define double word)表示的是有两个长度为2的字节领域(word),也就是4字节的意思。Borland C++中,由于int类型的长度是4字节,因此汇编器就把int a1 = 1;变换成了_a1 label dword和dd 1。同样,这里也定义了相当于全局变量a2~a5的标签_a2~_a5,它们各自的初始值2~5也都被存储在了4字节的领域中。
接下来,让我们来看一下_BSS段定义的内容。这里定义了相当于全局变量b1~b5的标签_b1~_b5。(6)的db 4 dup(?)表示的是申请分配了4字节的领域,但值尚未确定(这里用?来表示)的意思。db(define byte)表示有1个长度是1字节的内存空间。因而,db 4 dup(?)的情况下,就是4字节的内存空间。这里大家要注意不要和dd 4混淆了。db 4 dup(?)表示的是4个长度是1字节的内存空间。而dd 4表示的则是双字节(=4字节)的内存空间中存储的值是4。
在_DATA和_BSS的段定义中,全局变量的内存空间都得到了确保。因而,从程序的开始到结束,所有部分都可以参阅全局变量。而这里之所以根据是否进行了初始化把全局变量的段定义划分为了两部分,是因为在Borland C++中,程序运行时没有初始化的全局变量的领域(_BSS段定义)都会被设定为0进行初始化。可见,通过汇总,初始化很容易实现,只要把内存的特定范围全部设定为0就可以了。
10.临时确保局部变量用的内存空间
为什么局部变量只能在定义该变量的函数内进行参阅呢?这是因为,局部变量是临时保存在寄存器和栈中的。函数内部利用的栈,在函数处理完毕后会恢复到初始状态,因此局部变量的值也就被销毁了,而寄存器也可能会被用于其他目的。因此,局部变量只是在函数处理运行期间临时存储在寄存器和栈上。
在代码清单10-6中定义了10个局部变量。这是为了表示存储局部变量的不仅仅是栈,还有寄存器。为确保c1~c10所需的领域,寄存器空闲时就使用寄存器,寄存器空间不足的话就使用栈。
下面让我们来看一下代码清单10-7中_TEXT段定义的内容。(7)表示的是MyFunc函数的范围。在MyFunc函数中定义的局部变量所需要的内存领域,会被尽可能地分配在寄存器中。大家可能会认为用高性能的寄存器来代替普通的内存是很奢侈的事情,不过编译器不会这么认为,只要寄存器有空间,编译器就会使用它。因为与内存相比,使用寄存器时访问速度会高很多,这样就可以更快速地进行处理。局部变量利用寄存器,是Borland C++编译器最优化的运行结果。旧的编译器没有类似的最优化功能,局部变量就可能会仅仅使用栈。
代码清单中的(8)表示的是往寄存器中分配局部变量的部分。仅仅对局部变量进行定义是不够的,只有在给局部变量赋值时,才会被分配到寄存器的内存区域。(8)就相当于给5个局部变量c1~c5分别赋予数值1~5这一处理。eax、edx、ecx、ebx、esi是Pentium等x86系列32位CPU寄存器的名称(参考表10-2)。至于使用哪一个寄存器,则要由编译器来决定。这种情况下,寄存器只是被单纯地用于存储变量的值,和其本身的角色没有任何关系。
x86系列CPU拥有的寄存器中,程序可以操作的有十几个。其中空闲的,最多也只有几个。因而,局部变量数目很多的时候,可分配的寄存器就不够了。这种情况下,局部变量就会申请分配栈的内存空间。虽然栈的内存空间也是作为一种存储数据的段定义来处理的,但在程序各部分都可以共享并临时使用这一点上,它和_DATA段定义及_BSS段定义在性质上还是有些差异的。例如,在函数入口处为变量申请分配栈的内存空间的话,就必须在函数出口处进行释放。否则,经过多次调用函数后,栈的内存空间就会被用光了。
在(8)这一部分中,给局部变量c1~c5分配完寄存器后,可用的寄存器数量就不足了。于是,剩下的5个局部变量c6~c10就被分配了栈的内存空间,如(9)所示。函数入口(10)处的add esp,-20指的是,对栈数据存储位置的esp寄存器(栈指针)的值做减20的处理。为了确保内部变量c6~c10在栈中,就需要保留5个int类型的局部变量(4字节$\times$5=20字节)所需的空间。(11)中的mov ebp,esp这一处理,指的是把当前esp寄存器的值复制到ebp寄存器中。之所以需要(11)这一处理,是为了通过在函数出口处的(12)这一mov esp,ebp的处理,把esp寄存器的值还原到原始状态,从而对申请分配的栈空间进行释放,这时栈中用到的局部变量就消失了。这也是栈的清理处理。在使用寄存器的情况下,局部变量则会在寄存器被用于其他用途时自动消失(图10-6)。
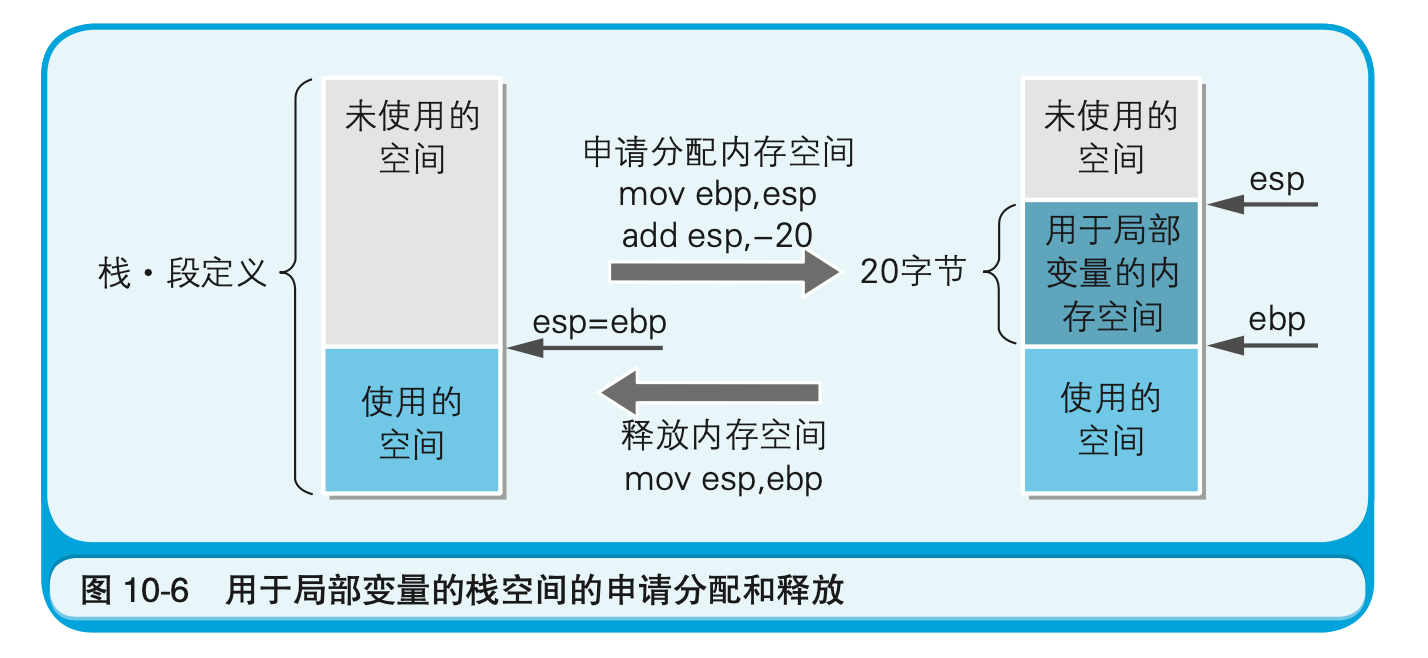
对(9)这一部分的解释:

11.循环处理的实现方法
接下来看一下for循环及if条件分支等C语言程序的流程控制是如何实现的$^1$。
- 通过利用for语句及if语句来改变程序流程的机制称为“流程控制”。

这里我们把代码清单10-8转换成汇编语言,然后仅把相当于for处理的部分摘出来,如代码清单10-9所示。

在汇编语言的源代码中,循环是通过比较指令(cmp)和跳转指令(jl)来实现的。
下面就让我们按照代码清单10-9的内容的顺序来进行说明。MyFunc函数中用到的局部变量只有i,变量i申请分配了ebx寄存器的内存空间。for语句的括号中的i=0;被转换成了xor ebx,ebx这一处理$^1$。虽然用mov指令的mov ebx,0也会得到同样的结果,但与mov指令相比,xor指令的处理速度更快。这里,编译器的最优化功能也会启动。
- 相同数值进行XOR运算,运算结果为0。XOR运算的规则是,值不同时结果为1,值相同时结果为0。
ebx寄存器的值初始化后,会通过call指令调用MySub函数(_MySub)。从MySub函数返回后,则会通过inc指令对ebx寄存器的值做加1处理。该处理就相当于for语句的i++。
下一行的cmp指令是用来对第一个操作数和第二个操作数的数值进行比较的指令。cmp ebx,10就相当于C语言的i<10这一处理,意思是把ebx寄存器的数值同10进行比较。汇编语言中比较指令的结果,会存储在CPU的标志寄存器中。不过,标志寄存器的值,程序是无法直接参考的。那么,程序是怎么来判断比较结果的呢?
实际上,汇编语言中有多个跳转指令,这些跳转指令会根据标志寄存器的值来判定是否需要跳转。例如,最后一行的jl,是jump on less than(小于的话就跳转)的意思。也就是说,jl short @4的意思就是,前面运行的比较指令的结果若“小”的话就跳转到@4这个标签。
代码清单10-10是按照代码清单10-9中汇编语言源代码的处理顺序重写的C语言源代码(由于C语言中无法使用@字符开头的标签,因此这里用了L4这个标签名),也是对程序实际运行过程的一个直接描述。此外,代码清单10-10的第一行中的i^=i,意思是对i和i进行XOR运算,并把结果代入i。为了和汇编语言的源代码进行同样的处理,这里把将变量i的值清0这一处理,通过对变量i和变量i进行XOR运算来实现了。借助i^=i,i的值就变成了0。

12.条件分支的实现方法

将代码清单10-11的MyFunc函数处理转换成汇编语言源代码后,结果就如代码清单10-12所示。


代码清单10-12中用到了三种跳转指令,分别是比较结果小时跳转的jle(jump on less or equal)、大时跳转的jge(jump on greater or equal)、不管结果怎样都无条件跳转的jmp。在这些跳转指令之前还有用来比较的cmp指令,比较结果被保存在了标志寄存器中。
13.了解程序运行方式的必要性
从汇编语言源代码中获得的知识,在某些情况下对查找bug的原因也是有帮助的。
代码清单10-13是更新全局变量counter的值的C语言程序。这里,假设我们利用多线程处理,同时调用了一次MyFunc1函数和MyFunc2函数。这时,全局变量counter的数值,理应变成$100\times 2 \times 2=400$。然而,某些时候结果也可能会是200。至于为什么会出现该bug,如果没有调查过汇编语言的源代码,也就是说如果对程序的实际运行方式不了解的话,是很难找到其原因的。

C语言源代码中counter*=2;这一个指令的部分,在汇编语言源代码,也就是实际运行的程序中,分成了3个指令,见代码清单10-14。

在多线程处理中,用汇编语言记述的代码每运行1行,处理都有可能切换到其他线程(函数)中。因而,假设MyFunc1函数在读出counter的数值100后,还未来得及将它的2倍值200写入counter时,正巧MyFunc2函数读出了counter的数值100,那么结果就会导致counter的数值变成了200(图10-8)。

为了避免该bug,我们可以采用以函数或C语言源代码的行为单位来禁止线程切换的锁定方法。通过锁定,在特定范围内的处理完成之前,处理不会被切换到其他函数中。
