本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
现在的目标检测器,无论是单阶段方法还是两阶段方法,通常首先会生成一组冗余的bbox,并带有分类分数,然后再使用NMS来去除同一目标上的重复bbox。通常分类分数被用于在NMS中对bbox进行排序。然而,这会影响检测性能,因为分类分数并不总是能够很好的估计bbox的定位精度,因此那些定位准确但分类分数较低的检测可能会在NMS中被误删。
为了解决这个问题,现有的密集目标检测器预测额外的IoU分数或centerness分数作为对定位精度的估计,并将其与分类分数相乘来对NMS中的bbox进行排序。这些方法可以缓解分类分数和目标定位精度之间的不匹配问题。然而,这种方法是次优的,因为如果将两个不完美的预测相乘可能会导致更差的排序,我们也在实验中展示了这种方法所能达到的性能是有限的。此外,添加一个额外的网络分支并不优雅,还会增加额外的计算负担。
那么我们能否不额外预测定位精度分数,而是将其与分类分数合并?也就是说,预测一个可以感知定位精度的分类分数(记为IACS,localization-aware or IoU-aware Classification Score)。
我们的主要贡献:
- 展示了IACS的优势。
- 提出了一种新的Varifocal Loss,用于训练密集目标检测器来回归IACS。
- 设计了一种新的星形bbox特征表示方法。
- 开发了一种新的密集目标检测器,称为VarifocalNet或VFNet。
我们的方法如Fig1所示。

2.Related Work
不再详述。
3.Motivation
在本部分,我们研究了FCOS的性能上限,并识别了其主要瓶颈。还展示了使用IACS作为排序标准的重要性。
Fig2展示了FCOS head输出的一个示例,输出包含3部分:分类分数、bbox和centerness分数。
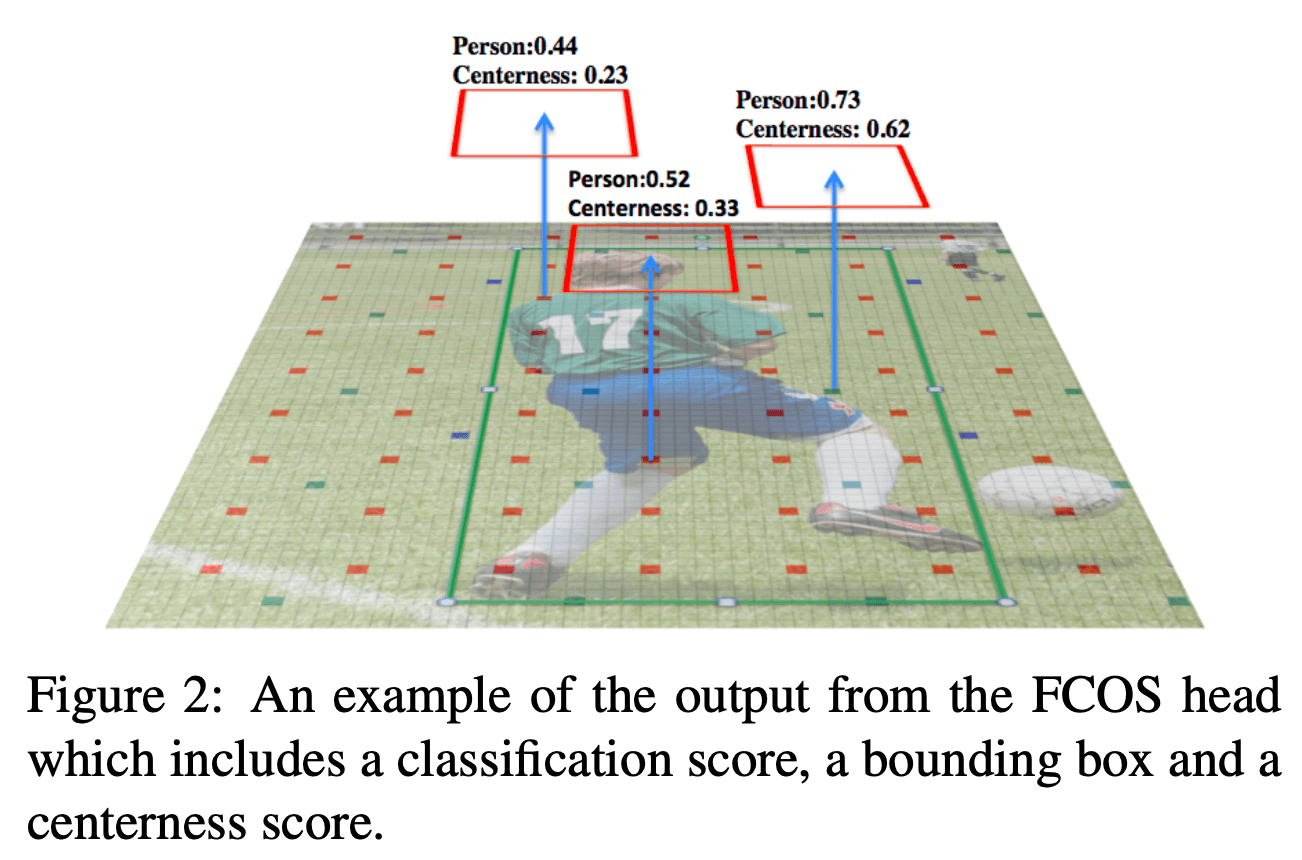
本文实际研究的是FCOS+ATSS,其在COCO train2017上进行训练,测试结果见表1:

如表1所示,我们依次将FCOS+ATSS的输出组件替换为GT,然后再执行NMS。w/ctr表示在推理阶段使用centerness分数。gt_ctr表示在推理阶段,将预测的centerness分数替换为GT centerness分数。gt_ctr_iou表示在推理阶段,将预测的centerness分数替换为预测bbox和GT bbox的IoU。gt_bbox表示在推理阶段,将预测的bbox替换为GT bbox,注意,因为有可能发生分类错误,所以即使替换为GT bbox,准确率也不是100%。gt_cls表示在推理阶段,将分数分数替换为真实类别,分类正确为1,分类错误为0。gt_cls_iou表示将分类分数替换为预测bbox和GT bbox的IoU。
从表1可以看到,原始的FCOS+ATSS的AP为39.2%,即使替换了gt_ctr(41.1%的AP)或gt_ctr_iou(43.5%的AP),也没有带来显著的性能提升。
相比之下,在不使用centerness分数,仅替换gt_bbox的情况下,性能达到了56.1%的AP。如果是仅替换gt_cls,则AP为43.1%,但在centerness分数的加持下,AP可以提升至58.1%,说明centerness分数在某种程度上可以区分准确的和不准确的bbox。
最令人惊讶的结果是在不使用centerness的情况下,仅替换gt_cls_iou竟然达到了74.7%的AP,显著高于其他情况。这揭示了在诸多预测的候选bbox中,已经存在准确的bbox,而实现卓越检测性能的关键就在于从预测的候选bbox中准确的选择出高质量的bbox。上述实验也表明,将分类分数替换为IoU是最有潜力的,基于此,我们提出了IACS(IoU-aware Classification Score)。
4.VarifocalNet
我们提出了一个新的密集目标检测器,称为VarifocalNet,简称VFNet,其基于FCOS+ATSS,但移除了centerness分支。和FCOS+ATSS相比,VFNet有3个新组件:varifcoal loss、星形的bbox特征表征、bbox的refine。
4.1.IACS–IoU-Aware Classification Score
IACS替代了传统的分类分数,在GT类别标签的位置上,其值为预测bbox和GT bbox的IoU。
4.2.Varifocal Loss
在Focal Loss的启发下,我们提出了Varifocal Loss。
我们首先来复习下Focal Loss。Focal Loss用于解决密集目标检测器在训练时前景类别和背景类别的极端不平衡问题。其定义为:
\[\text{FL}(p,y) = \begin{cases} -\alpha (1-p)^{\gamma}\log (p) & \text{if} \ y=1 \\ - (1-\alpha) p^{\gamma}\log (1-p) & \text{otherwise} \end{cases} \tag{1}\]其中,$y \in \{ \pm 1 \}$表示GT类别,$p \in [0,1]$表示前景类别的预测概率。前景类别的调控因子为$(1-p)^{\gamma}$,背景类别的调控因子为$p^{\gamma}$,这些调控因子可以减少容易样本的损失贡献,增加对困难样本的重视。
我们借鉴了Focal Loss的样本加权思想,来解决在密集目标检测器中使用IACS训练时的类别不平衡问题。然而,与Focal Loss处理正负样本时的一视同仁不同,我们对它们进行了不对称处理。Varifocal Loss的定义如下:
\[\text{VFL}(p,q) = \begin{cases} -q(q\log (p) + (1-q)\log (1-p)) & q>0 \\ -\alpha p^{\gamma} \log (1-p) & q=0 \end{cases} \tag{2}\]其中,$p$是预测的IACS,$q$是目标分数(target score)。对于前景点,GT类别的$q$是预测bbox和GT bbox的IoU,不是GT类别的$q$则为0。对于背景点,所有类别的$q$都是0。如Fig1所示。
如式(2)所示,Varifocal Loss仅通过$p^{\gamma}$来减少负样本($q=0$)对损失的贡献,而不会以同样的方式降低正样本$q>0$的权重,这是因为正样本相比负样本要少很多,我们应该保留它们宝贵的学习信号。此外,我们使用$q$对正样本进行加权,如果一个正样本的gt_IoU较高,它对损失的贡献将相对较大,这使得训练将集中在高质量的正样本上。
为了平衡正负样本之间的损失,我们在负样本的损失项中添加了可调的缩放因子$\alpha$。
4.3.Star-Shaped Box Feature Representation
如Fig1所示,红色bbox为预测的初始bbox,在FCOS中,这个bbox可以用一个4维向量表示,即$(l’,t’,r’,b’)$,分别表示位置$(x,y)$到bbox的左、上、右、下边界的距离。基于此,我们采样九个点,如Fig1中的黄色点所示,即$(x,y),(x-l’,y),(x,y-t’),(x+r’,y),(x,y+b’),(x-l’,y-t’),(x+r’,y-t’),(x-l’,y+b’),(x+r’,y+b’)$,然后将这九个点映射到feature map中。映射后,周围点到$(x,y)$的offset用于定义可变形卷积,见Fig3中的Star Dconv步骤。这些点的选择并没有引入额外的计算成本。
4.4.Bounding Box Refinement
如Fig1所示,基于初始的红色bbox($(l’,t’,r’,b’)$),我们预测了一组缩放因子$(\Delta l, \Delta t, \Delta r, \Delta b)$,则refine后的蓝色bbox可表示为$(l,t,r,b)=(\Delta l \times l’, \Delta t \times t’, \Delta r \times r’, \Delta b \times b’)$。
4.5.VarifocalNet
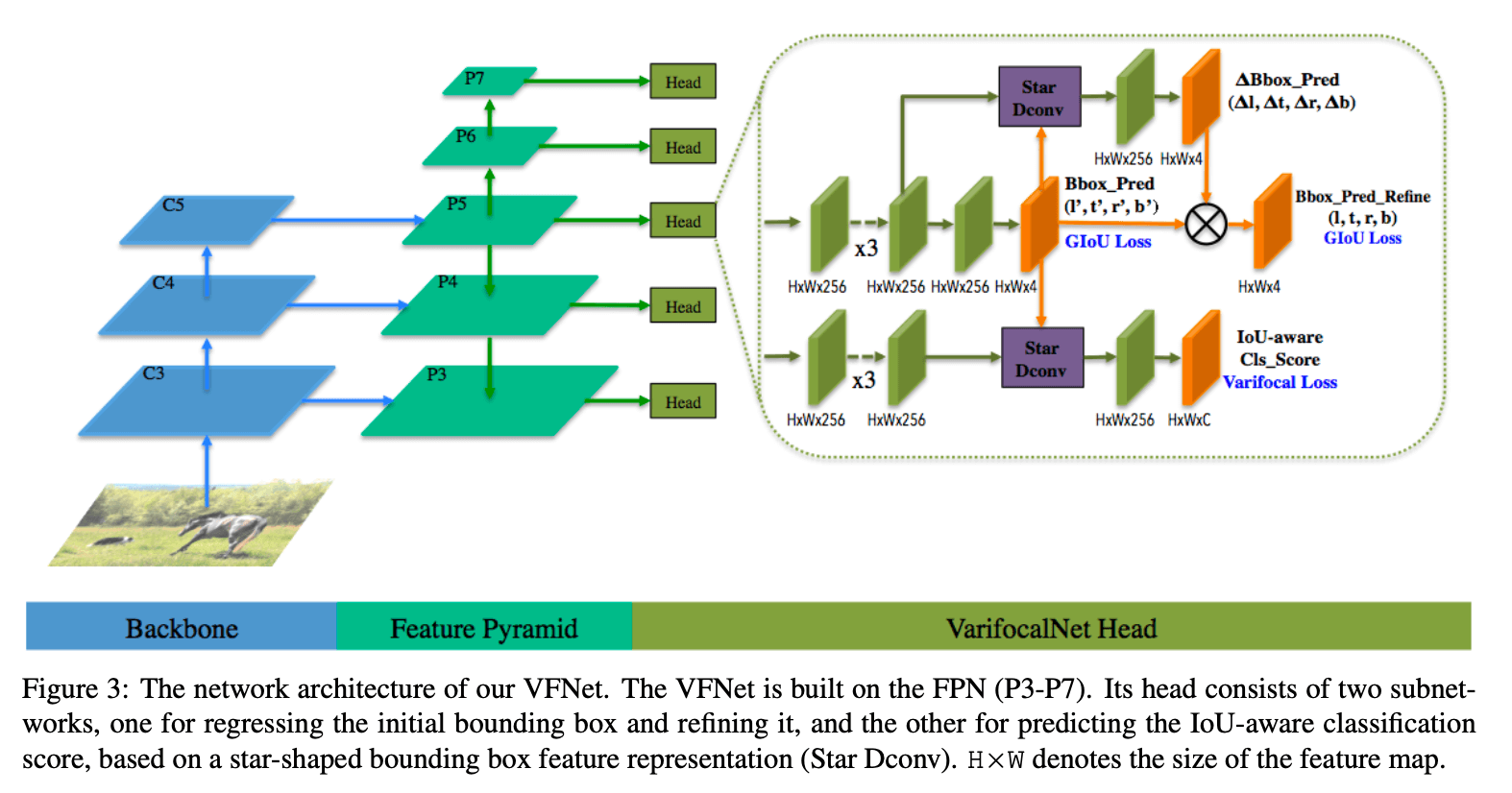
VFNet的backbone以及FPN部分和FCOS都是一样的。和FCOS的不同之处在于head的结构。VFNet的head包含两个子网络。定位子网络用于bbox的回归以及后续的refine。其输入是来自FPN每个层级的feature map,首先是3个$3 \times 3$的卷积,激活函数为ReLU,通道数为256。后续的结构如Fig3所示,已经很清晰了,不再赘述。
另一个子网络用于预测IACS,每个空间位置输出一个$C$维的向量($C$为类别数),向量中的每个元素都是目标存在置信度和定位精度的联合表示。
4.6.Loss Function and Inference
👉Loss Function.
VFNet训练所用的损失函数为:
\[\begin{align} Loss &= \frac{1}{N_{pos}} \sum_i \sum_c VFL (p_{c,i},q_{c,i}) \\&+ \frac{\lambda_0}{N_{pos}} \sum_i q_{c^*,i} L_{bbox} (bbox'_i,bbox^*_i) \\&+ \frac{\lambda_1}{N_{pos}} \sum_i q_{c^*,i} L_{bbox} (bbox_i,bbox^*_i) \end{align} \tag{3}\]其中,$p_{c,i}$和$q_{c,i}$分别表示在FPN每个层级的feature map中每个位置$i$上类别$c$的预测IACS和目标分数。$L_{bbox}$为GIoU Loss,$bbox’_i$表示预测的初始bbox,$bbox_i$表示refine后的bbox,$bbox^*_i$表示GT bbox。$\lambda_0$通常设为1.5,$\lambda_1$通常设为2.0。$N_{pos}$是前景点的数量。如第3部分所介绍的,在训练阶段,我们使用ATSS来定义前景点和背景点。
👉Inference.
推理阶段,输入图像通过网络的前向传播得到预测结果,然后使用NMS移除冗余的预测。
5.Experiments
👉Dataset and Evaluation Metrics.
我们使用MS COCO 2017 benchmark来评估VFNet。在train2017上训练,在val2017上进行消融实验,在test-dev上和其他检测器进行结果比较。
👉Implementation and Training Details.
使用MMDetection实现VFNet。除非特殊声明,我们使用MMDetection中的默认超参数。初始学习率为0.01,使用线性warm-up策略,warm-up ratio设置为0.1。在消融实验和性能对比中,我们使用了8块V100 GPU,总的batch size为16,即每块GPU处理2张图像。
在val2017上的消融实验,使用ResNet-50作为backbone,共训练了12个epoch(1x training schedule)。输入图像在不改变长宽比的情况下,最大resize到$1333 \times 800$。数据扩展仅用了随机水平翻转。
在test-dev上,和其他SOTA方法进行了性能比较,我们使用不同的backbone训练了VFNet,其中某些backbone使用了可变形卷积层(标记为DCN)。如果backbone使用了DCN,则我们也将其插入到星形可变形卷积之前的最后一层。共训练了24个epoch(2x training scheme),并使用了MSTrain(multi-scale training),每次迭代最大的图像尺寸是从一个范围内随机选择的。事实上,我们在实验中使用了2个图像尺寸范围。为了和baseline公平的比较,我们使用的尺寸范围为$1333 \times [640:800]$;此外,我们还实验了更广的尺寸范围:$1333 \times [480:960]$。需要注意的是,即使使用了MSTrain,在推理阶段,我们仍然保持图像的最大尺寸为$1333 \times 800$,尽管更大的尺寸可以得到稍微好一点的性能($1333 \times 900$的尺寸可以将AP提高约0.4)。
👉Inference Details.
在推理阶段,输入图像被resize(最大尺寸为$1333 \times 800$)后送入网络,得到预测的bbox和对应的IACS。我们首先过滤掉$p_{max} \leqslant 0.05$的bbox,然后每个FPN层级选择IACS分数最高的1000个bbox。然后执行NMS(阈值为0.6)得到最终的结果。
5.1.Ablation Study
5.1.1.Varifocal Loss
我们测试了Varifocal Loss的两个超参数:$\alpha$和$\gamma$。测试$\alpha$的取值范围为0.5到1.5,测试$\gamma$的取值范围为1.0到3.0,表2只展示了最优$\alpha$的结果。
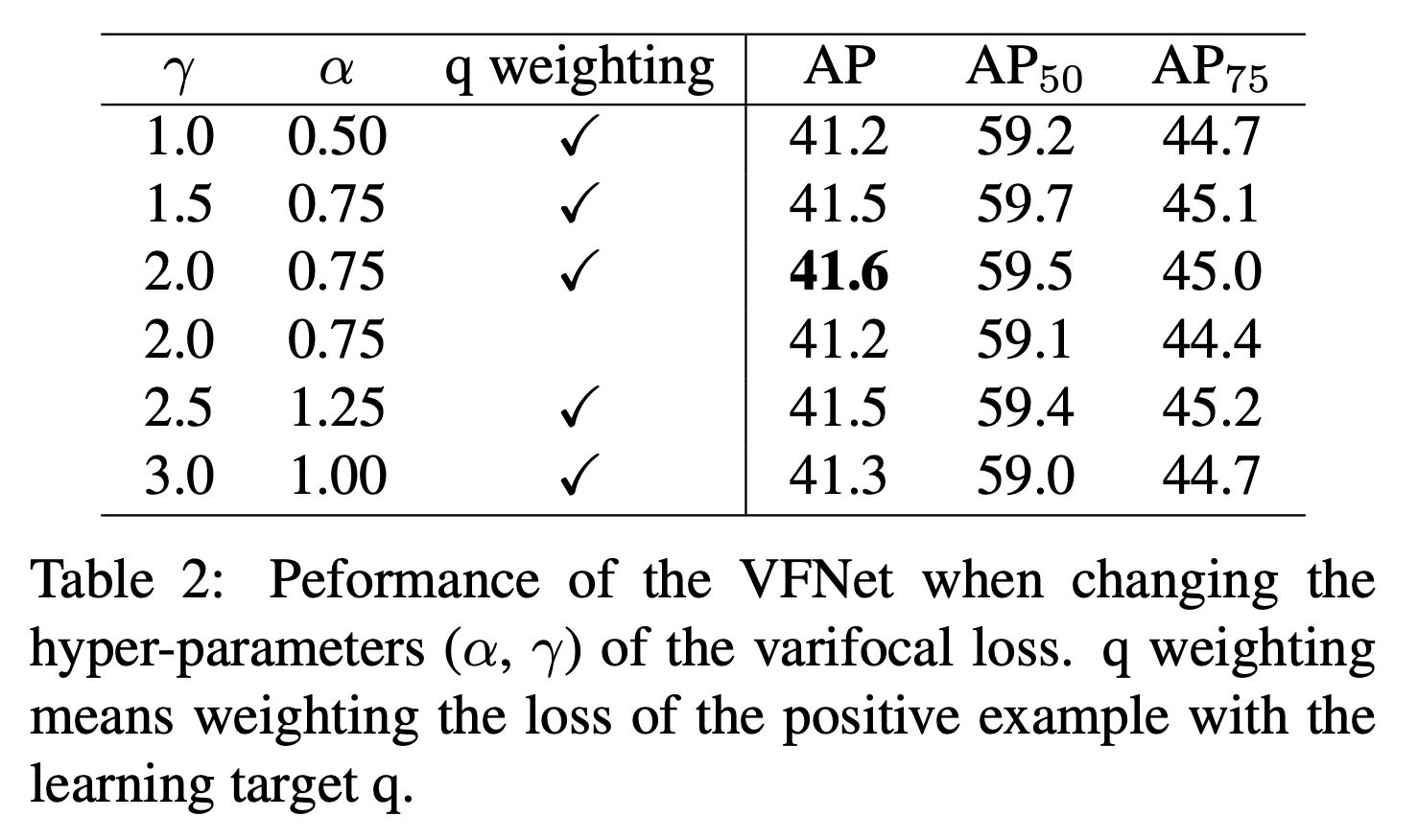
从表2可以看出,Varifocal Loss对$\alpha$和$\gamma$的取值并不敏感。当$\alpha=0.75,\gamma=2.0$时性能最好,我们在接下来的实验中也采用这两个值。
5.1.2.Individual Component Contribution
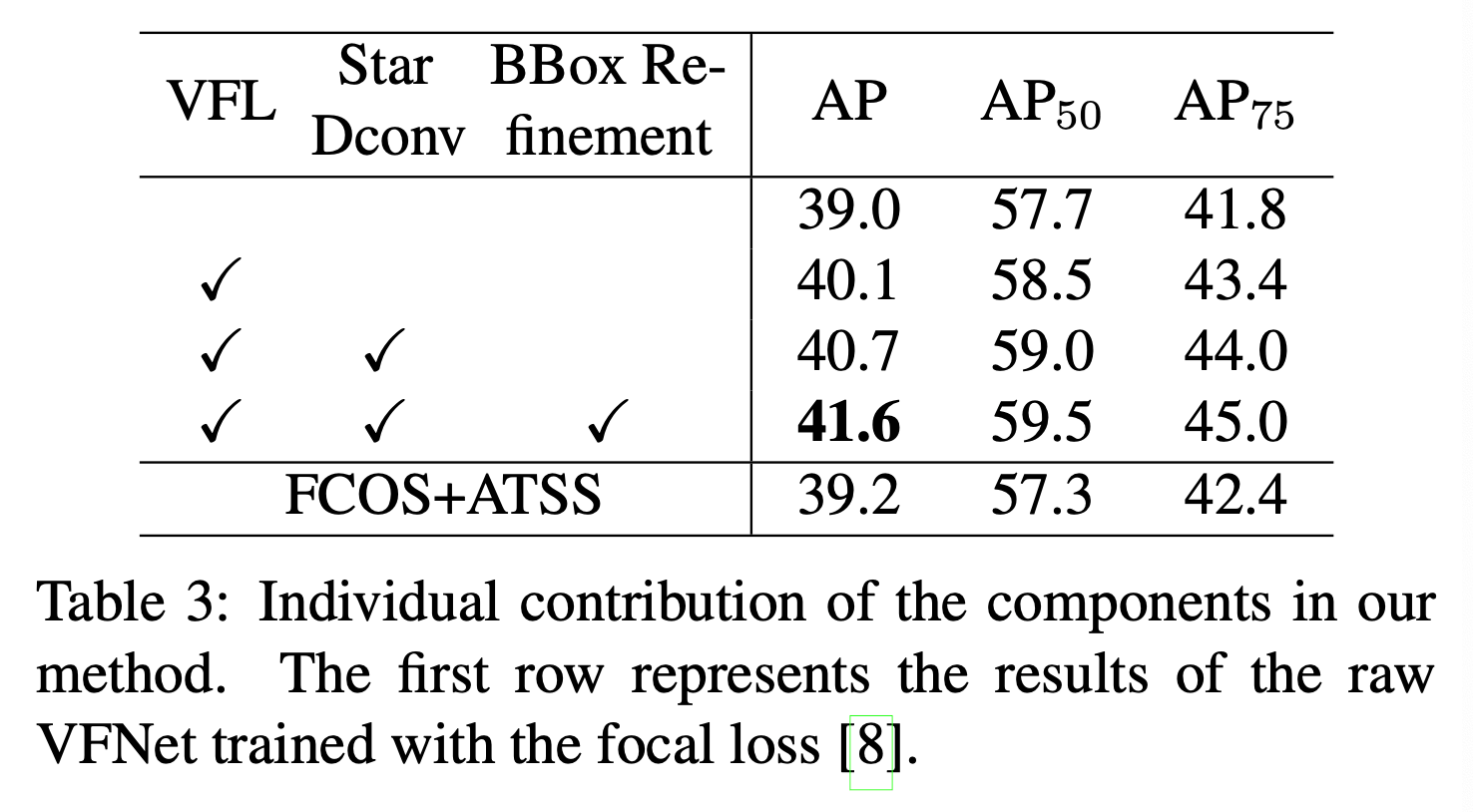
表3中,raw VFNet指的是移除了centerness分支的FCOS+ATSS(训练使用Focal Loss)。
5.2.Comparison with State-of-the-Art
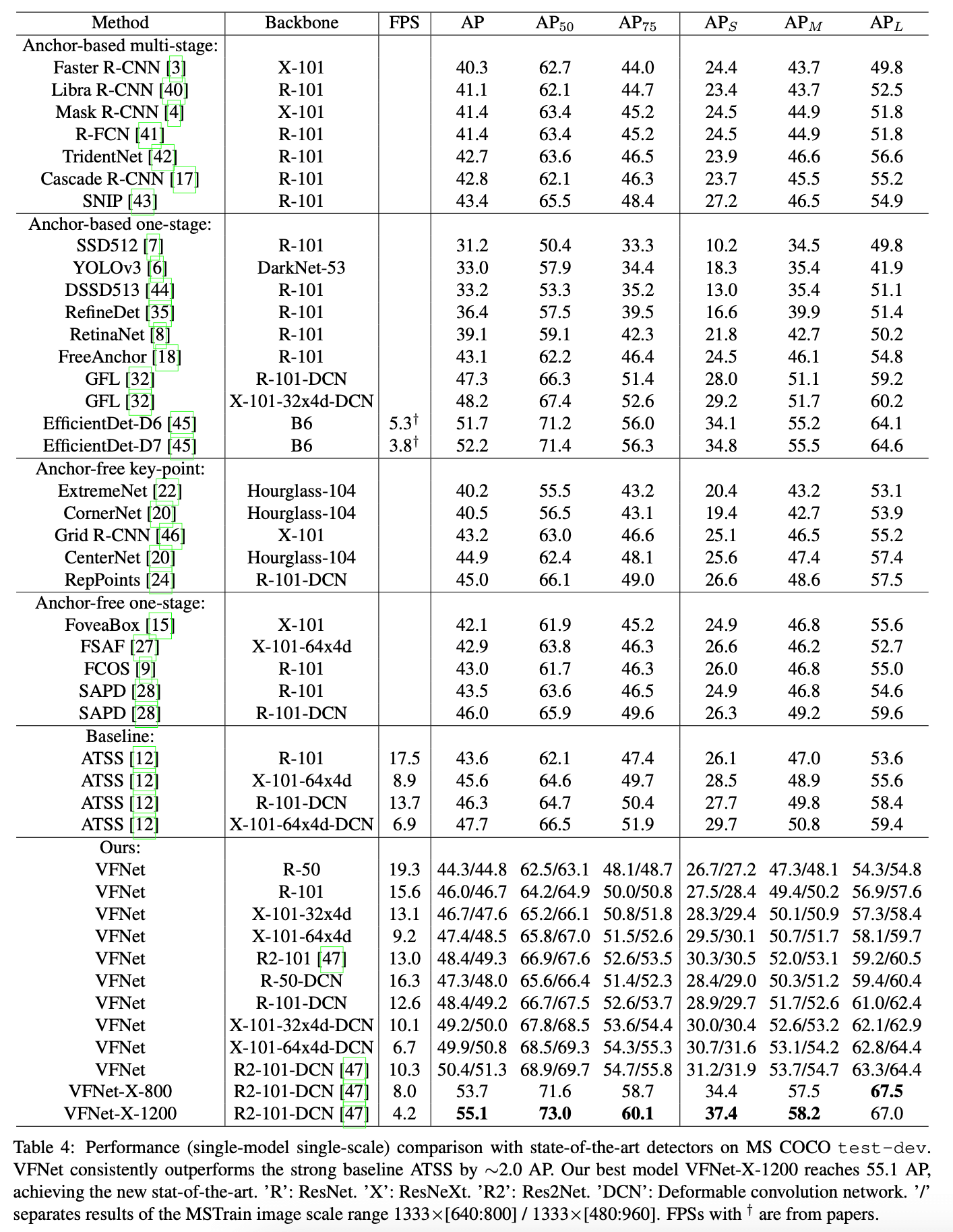
FPS的测试基于Nvidia V100 GPU。
5.3.VarifocalNet-X
我们还针对原始的VFNet做了一些扩展,称为VFNet-X,这些扩展包括:
- 将FPN替换为PAFPN,并且使用了DCN和group normalization(GN)。
- 将head堆叠的3个卷积层扩展为堆叠4个卷积层,将通道数从256扩展至384。
- 使用随机裁剪和cutout作为额外的数据扩展方式。
- 使用更大的MSTrain尺寸范围,即从$750 \times 500$到$2100 \times 1400$,初始训练41个epoch。
- 在训练VFNet-X时使用了SWA(stochastic weight averaging)技术,这使AP提升了1.2个点。在初始训练41个epoch之后,又使用cyclic learning rate schedule训练了18个epoch,然后将这18个checkpoints做简单的平均得到我们最终的模型。
SWA论文:Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407, 2018.。
VFNet-X在COCO test-dev上的性能见表4。当在推理阶段使用尺寸$1333 \times 800$,且使用soft-NMS时,VFNet-X-800达到了53.7的AP,而当将图像尺寸增加到$1800 \times 1200$时,VFNet-X-1200达到了SOTA的成绩,即55.1的AP。一些可视化结果见Fig4。

5.4.Generality and Superiority of Varifocal Loss
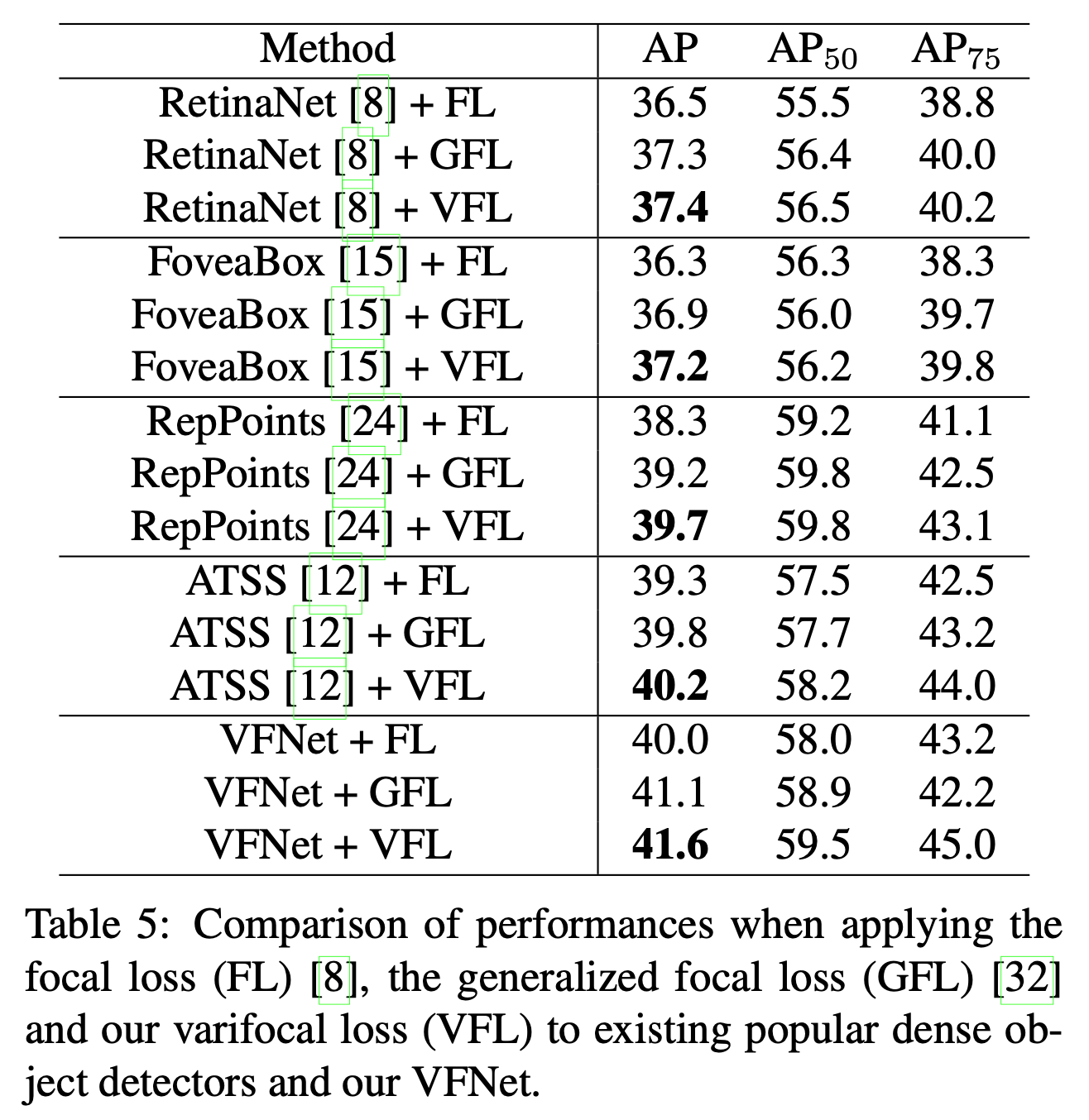
表5的结果基于val2017。这些方法的backbone都使用ResNet-50。
6.Conclusion
不再赘述。
