本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
github源码地址:ATSS。
anchor-based检测器通常分为单阶段方法(比如SSD、RetinaNet)和两阶段方法(比如Faster R-CNN、R-FCN)。两种方法的共同点是首先在图像上排列大量预设的anchor,然后通过一次或多次预测这些anchor的类别,并refine它们的坐标,最后输出refine过的anchor作为检测结果。由于两阶段方法比单阶段方法多次refine anchor,所以前者的结果更准确,而后者的计算效率更高。在常见的检测benchmark上,anchor-based检测器仍然保持着SOTA的成绩。
随着FPN和Focal Loss的出现,学术界对anchor-free检测器的关注日益增加。anchor-free检测器在没有预设anchor的情况下直接检测目标,主要有两种方法。第一种方法是首先定位几个预定义或自学习的关键点,然后确定目标的空间范围,我们将这类anchor-free检测器称之为基于关键点的方法(比如CornerNet、ExtremeNet)。第二种方法是使用目标的中心点或区域来定义正样本,然后预测正样本到目标bbox边界的4个距离,我们将这类anchor-free检测器称之为基于中心的方法(比如FCOS、FoveaBox)。这些anchor-free检测器能够消除与anchor相关的超参数,并且已经达到了与anchor-based检测器相似的性能,并且anchor-free检测器在泛化能力方面更具潜力。
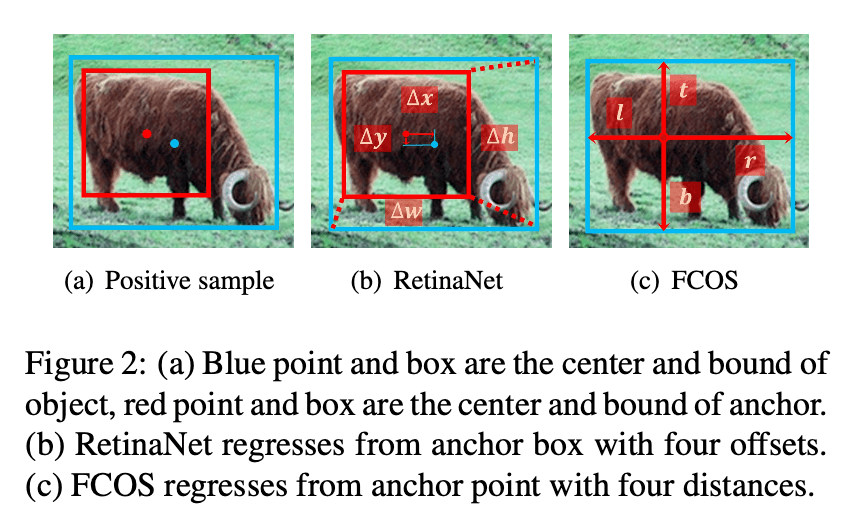
anchor-free检测器的两种方法中,基于关键点的方法遵循标准的关键点估计流程,这与anchor-based检测器不同。然而,基于中心的方法与anchor-based检测器就比较相似了,二者的不同点在于将像素点视为样本还是anchor box。以单阶段anchor-based检测器RetinaNet和基于中心的anchor-free检测器FCOS为例,它们之间有3个主要区别:
- 每个位置预设的anchor数量。RetinaNet在每个位置预设了多个anchor box,而FCOS在每个位置只预设了一个anchor point(个人注解:将位置视为训练样本)。
- 正负样本的定义。RetinaNet通过IoU来确定anchor box属于正样本还是负样本。而FCOS则通过空间和尺度约束来确定一个位置(即anchor point)属于正样本还是负样本(个人注解:简单来说就是如果该位置在GT bbox内,并且处于合适的尺度范围,则它就是正样本)。
- bbox回归的起始状态。RetinaNet从预设的anchor box开始回归目标的bbox,而FCOS则是直接基于anchor point定位目标。
FCOS的性能优于RetinaNet,值得研究这三点区别中的哪些导致了性能上的差异。
在本文中,我们通过严格排除所有实现上的不一致性,以一种公平的方式研究了anchor-based方法和anchor-free方法之间的差异。实验结果表明,这两类方法的本质区别在于正负训练样本的定义,这导致了它们性能上的差异。如果在训练过程中选择相同的正负样本,无论是从anchor box还是从anchor point开始回归,最终的性能差异并不明显。因此,如何选择正负训练样本值得进一步研究。受此启发,我们提出了ATSS(Adaptive Training Sample Selection),该方法根据目标的特征自动选择正负样本,从而弥补了anchor-based检测器和anchor-free检测器之间的差距。此外,通过一系列实验,我们得出结论:在图像的每个位置分配多个anchor box是没有必要的。在MS COCO数据集上的大量实验验证了我们的分析和结论。通过应用ATSS,在没有引入任何额外开销的情况下,在COCO数据集上达到了SOTA的性能。
2.Related Work
当前基于CNN的目标检测分为anchor-based检测器和anchor-free检测器,前者又进一步分为单阶段方法和两阶段方法,后者又进一步分为基于关键点的方法和基于中心的方法。
3.Difference Analysis of Anchor-based and Anchor-free Detection
在不失一般性的情况下,我们采用具有代表性的anchor-based的RetinaNet和anchor-free的FCOS来剖析它们之间的区别。在本部分,我们将重点关注后两点区别:正负样本的定义和bbox回归的起始状态。剩余的区别:每个位置预设的anchor数量,将在后面的部分讨论。因此,本部分中,我们仅在RetinaNet中为每个位置分配一个正方形anchor box,这与FCOS非常相似。接下来,我们首先介绍实验设置,接着排除所有实现上的不一致性,最后指出anchor-based检测器和anchor-free检测器之间的本质区别。
3.1.Experiment Setting
👉Dataset.
所有实验都使用MS COCO数据集,其包含80个目标类别。trainval35k中的所有115K张图像用于训练,minival中的所有5K张图像用于验证。最终性能评估基于test-dev。
👉Training Detail.
backbone为有着5层特征金字塔结构的且在ImageNet上预训练过的ResNet-50。新添加层的初始化方式同RetinaNet。在RetinaNet中,对于5层特征金字塔中的每一个层级,每个位置分配一个正方形的anchor box,scale为$8S$,$S$为下采样倍数(个人注解:从P3到P7,anchor box大小依次为$64\times 64,128\times 128,256\times 256,512\times 512,1024\times 1024$)。在训练阶段,我们将输入图像进行resize,使其短边为800,长边小于等于1333。训练使用SGD(Stochastic Gradient Descent)进行了90K次迭代,momentum=0.9,weight decay=0.0001,batch size=16。初始学习率设为0.01,并在第60K和第80K次迭代时衰减10倍。除非特殊说明,以上训练细节被应用于所有实验。
👉Inference Detail.
在推理阶段,对输入图像的resize方式和训练阶段一样,然后其通过整个网络的前向传播得到预测的bbox和对应的预测类别。使用0.05的阈值筛掉大量的背景bbox,然后选择特征金字塔中每个层级排名前1000的bbox。接着使用NMS,IoU阈值设为0.6,最终每张图像输出前100个检测结果。
3.2.Inconsistency Removal
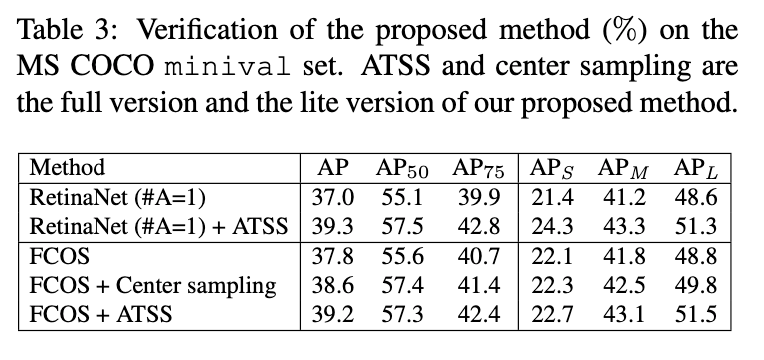
我们将每个位置仅分配一个正方形anchor box的RetinaNet记为RetinaNet(#A=1),其和FCOS非常相似。但是在FCOS原论文中,FCOS在MS COCO minival上的AP是37.1%,显著优于RetinaNet(#A=1)的32.5%。此外,如果FCOS再应用一些新的提升方式,包括把centerness挪到回归分支、使用GIoU loss、归一化回归目标等,可将其性能从37.1%提升至37.8%。然而,AP上的差距源自FCOS所用的一些通用的改进,比如,在head中添加GroupNorm、使用GIoU回归损失函数、将正样本限制在GT box内、引入centerness分支、为特征金字塔的每个层级添加可训练的scalar等。这些改进同样也可以被应用于anchor-based检测器,所以它们并不是anchor-based方法和anchor-free方法之间的本质区别。如表1所示,我们将这些改进应用在了RetinaNet(#A=1)上,以排除这些不相关的实现差异,其AP也达到了37.0%,但仍和FCOS的性能差了0.8%。至此,排除了所有不相关的差异后,我们可以在一个非常公平的环境下探索anchor-based方法和anchor-free方法之间的本质区别。

3.3.Essential Difference
在应用了这些通用的改进之后,RetinaNet(#A=1)和FCOS之间仅剩下两个差异,一个是如何定义正负样本,另一个是bbox回归是从anchor box开始还是从anchor point开始。
👉Classification.
如Fig1(a)所示,RetinaNet利用IoU将来自不同金字塔层级的anchor box划分为正负样本。它首先将和GT box的IoU大于$\theta_p$的anchor box记为正样本,然后将和GT box的IoU小于$\theta_n$的anchor box记为负样本,最后剩余的其他anchor box在训练中被忽略。如Fig1(b)所示,FCOS首先将GT box内的anchor point视为候选正样本,然后根据为每个金字塔层级定义的尺度范围从候选正样本中选择最终的正样本,未被选中的anchor point则为负样本。

如表2第一列所示,如果RetinaNet使用FCOS的正负样本定义方法,则AP从37.0%上升到37.8%。如表2第二列所示,如果FCOS使用RetinaNet定义正负样本的方法,则AP从37.8%掉到了36.9%。这些结果表明,正负样本的定义是anchor-based检测器和anchor-free检测器之间的一个本质区别。

👉Regression.
如Fig2(a)所示,目标的位置由正样本进行回归。如Fig2(b)所示,RetinaNet从anchor box开始回归。如Fig2(c)所示,FCOS从anchor point开始回归。如表2第一行和第二行所示,当RetinaNet和FCOS采用相同的样本选择策略时,无论是从anchor box还是从anchor point开始回归,最终性能并无差异,即37.0% vs. 36.9%和37.8% vs. 37.8%。
👉Conclusion.
根据这些在公平条件下进行的实验,我们发现,单阶段anchor-based检测器和基于中心的anchor-free检测器之间的本质区别在于如何定义正负训练样本。
4.Adaptive Training Sample Selection
我们提出了ATSS用于定义正负训练样本,与传统方法相比,ATSS几乎没有超参数,并且对不同设置具有鲁棒性。
4.1.Description
以往的样本选择策略中包含一些敏感的超参数,例如anchor-based检测器中的IoU阈值和anchor-free检测器中的尺度范围。不同的超参数设置会导致非常不同的结果。
为此,我们提出了ATSS,该方法根据目标的统计特征自动划分正负样本,几乎不需要任何超参数。

需要注意的是,如果一个anchor box被分配给多个GT box,则选择IoU最高的那个GT box。
$k=1$时的一个示例见Fig3:
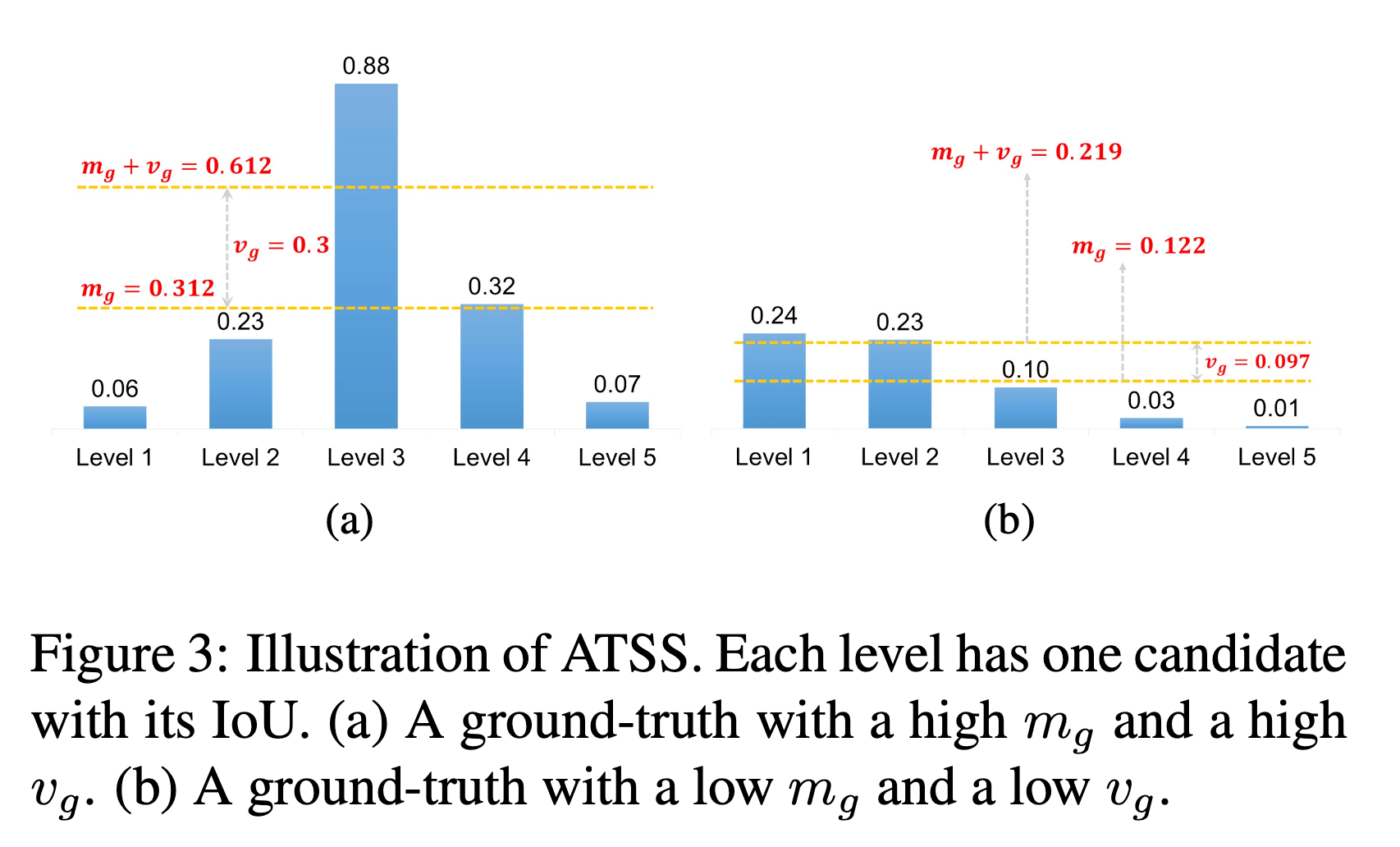
ATSS仅有一个超参数$k$,且对其变化并不敏感。
4.2.Verification
👉Anchor-based RetinaNet.
👉Anchor-free FCOS.
ATSS在FCOS上的应用分为两种版本:lite版本和full版本。原始的FCOS会将GT box内的大量anchor point视为正样本,这导致了很多低质量的正样本。因此,在lite版本中,对于每个GT box,我们只在特征金字塔的每个层级中选择排名前$k=9$个候选点作为正样本,即表3中的FCOS+Center sampling。lite版本依旧会保留尺度范围这个超参数。
对于full版本,我们为每个anchor point分配一个$8S$大小的anchor box(见第3.1部分),bbox回归的方式不变。结果见Fig3中的FCOS+ATSS。
4.3.Analysis
👉Hyperparameter k.

👉Anchor Size.

4.4.Comparison

表8中的这些实验我们采用了多尺度训练策略,即在训练过程中随机选择一个介于640到800之间的尺度,将图像的短边调整到该尺度。总迭代次数为180K次,并在第120K和第160K次迭代时进行学习率衰减。
4.5.Discussion

表7中的Imprs.指的是表1中列出的通用的改进方法。和表1中RetinaNet(#A=1)相比,表7中RetinaNet(#A=9)性能更好,即37.0% vs. 38.4%,说明在传统的基于IoU的样本选择策略下,每个位置增加anchor box数量是有效的。
在使用ATSS后,增加每个位置的anchor box数量变成了一个无效的操作,并不能带来性能的提升。
5.Conclusion
不再赘述。
