本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
本文提出了一个高效的网络框架和两个超参数,用于构建非常小且低延迟的模型,这些模型可以轻松匹配移动端和嵌入式视觉应用的设计需求。
2.Prior Work
不再详述。
3.MobileNet Architecture
3.1.Depthwise Separable Convolution
在这里介绍过常规卷积、depth-wise卷积、point-wise卷积。
MobileNet模型基于深度分离卷积(depthwise separable convolutions)。深度分离卷积就是将一个常规卷积分解为一个depthwise卷积和一个pointwise卷积(即$1\times 1$卷积)。
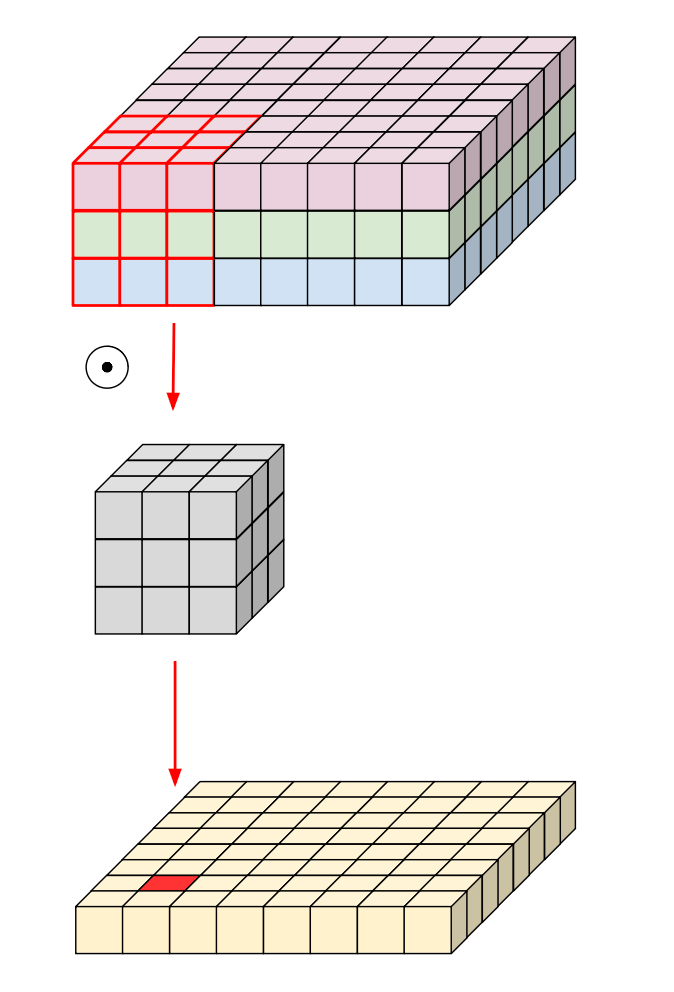
常规卷积示意图:
深度分离卷积示意图:

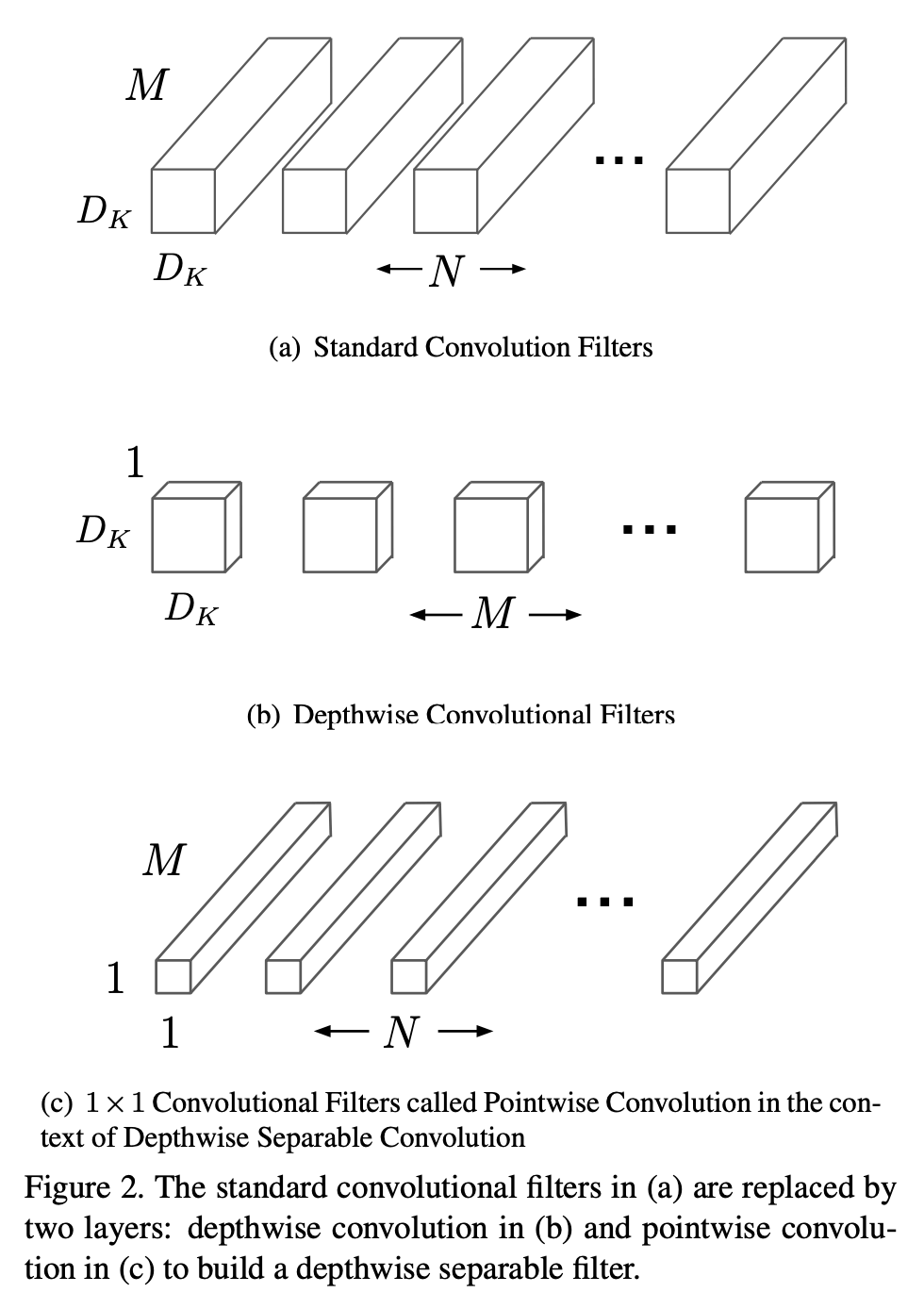
原文中给的示意图见下:
对于常规卷积层来说,假设输入feature map $\mathbf{F}$的维度为$D_F \times D_F \times M$,输出feature map $\mathbf{G}$的维度为$D_G \times D_G \times N$,卷积核$\mathbf{K}$的维度为$D_K \times D_K \times M \times N$。
输出feature map的计算方式为:
\[\mathbf{G}_{k,l,n} = \sum_{i,j,m} \mathbf{K}_{i,j,m,n} \cdot \mathbf{F}_{k+i-1,l+j-1,m} \tag{1}\]常规卷积的计算成本为:
\[D_K \cdot D_K \cdot M \cdot N \cdot D_F \cdot D_F \tag{2}\]而使用深度分离卷积可以大幅降低计算成本。在其分解得到的depthwise卷积层和pointwise卷积层中,都使用了batchnorm和ReLU激活函数。
depthwise卷积可以表示为:
\[\hat{\mathbf{G}}_{k,l,m} = \sum_{i,j} \hat{\mathbf{K}}_{i,j,m} \cdot \mathbf{F}_{k+i-1,l+j-1,m} \tag{3}\]depthwise卷积的计算成本为:
\[D_K \cdot D_K \cdot M \cdot D_F \cdot D_F \tag{4}\]深度分离卷积的计算成本为:
\[D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F \tag{5}\]相比常规卷积,深度分离卷积减少的计算成本为:
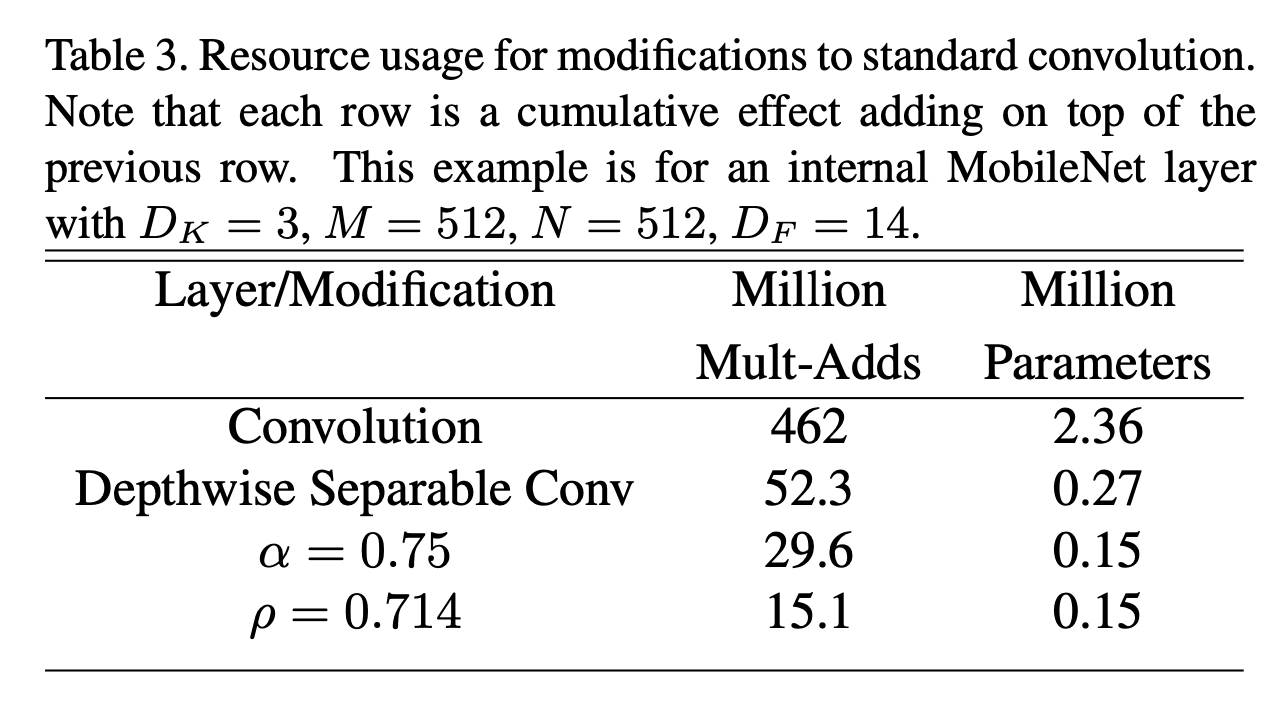
\[\frac{D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F}{D_K \cdot D_K \cdot M \cdot N \cdot D_F \cdot D_F} = \frac{1}{N} + \frac{1}{D_K^2}\]鉴于MobileNet使用$3 \times 3$的深度分离卷积,因此比常规卷积的计算成本降低了8-9倍,但准确率只是轻微下降。
3.2.Network Structure and Training
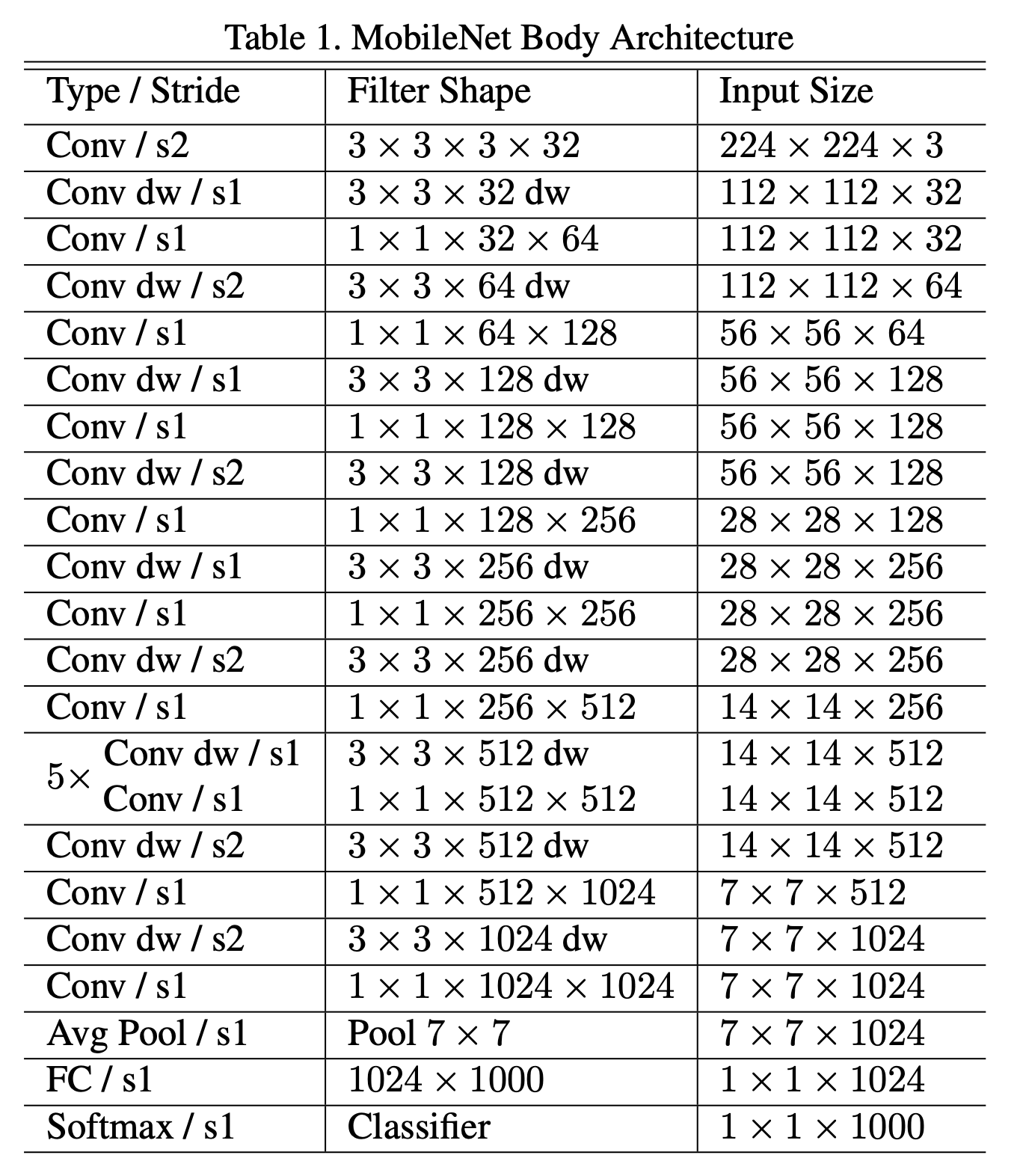
表1中的“dw”表示depthwise卷积。表1中将深度分离卷积中的depthwise卷积和pointwise卷积分开列出了。Fig3是常规卷积层和深度分离卷积层的详细结构。
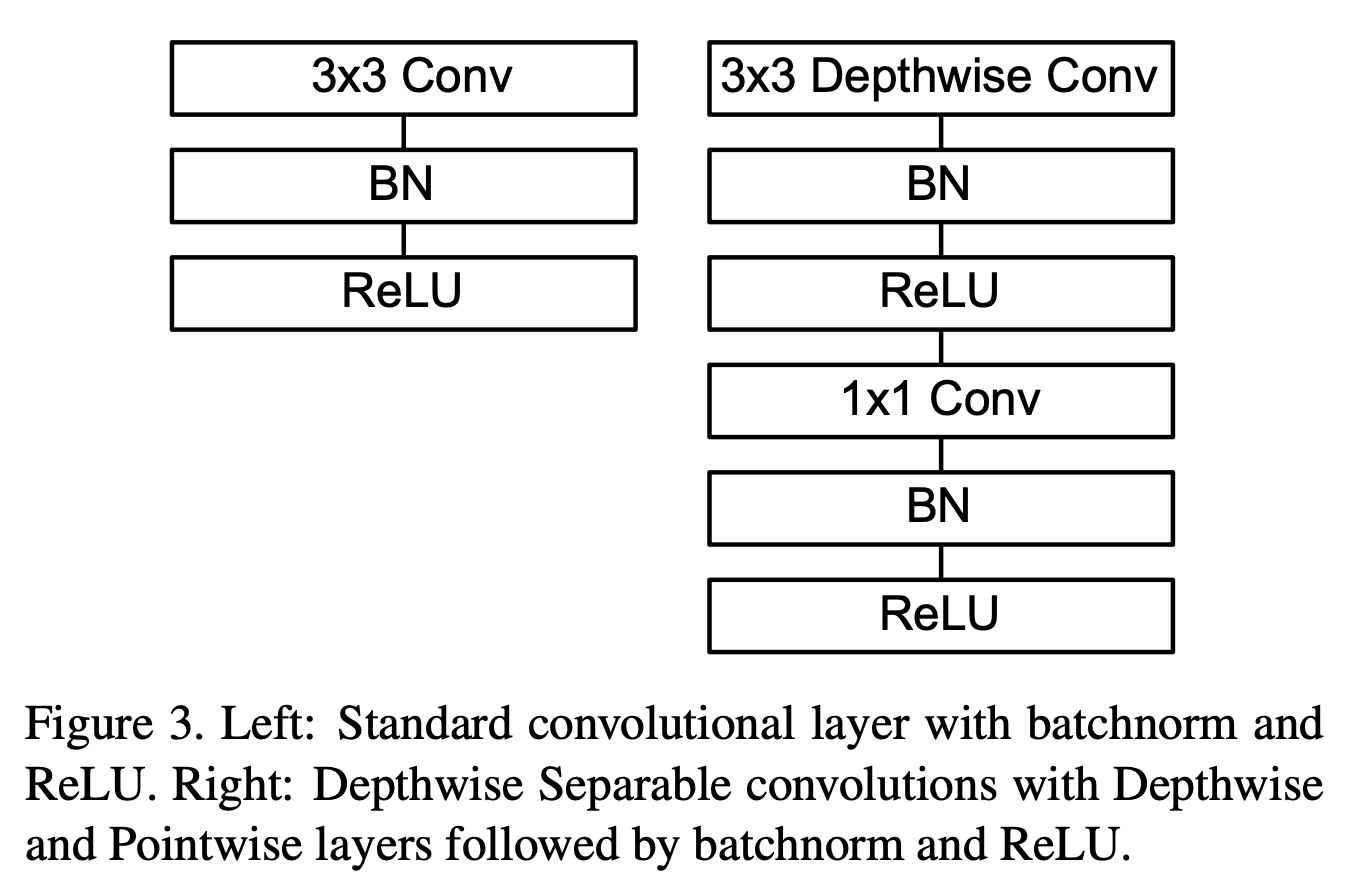
如果把depthwise卷积和pointwise卷积视为单独的层的话,MobileNet一共有28层。
网络设计时我们不仅要考虑加法和乘法的计算量,还要确保这些计算操作可以高效的实现。例如,非结构化的稀疏矩阵操作通常不会比密集矩阵操作更快,除非稀疏性非常高。我们的模型结构将几乎所有计算都集中在密集的$1 \times 1$卷积上,这可以直接通过高度优化的通用矩阵乘法(GEMM,general matrix multiply)函数来实现。而对于常规的卷积操作,则需要先进行内存重排(称为im2col),然后才能将其映射到GEMM操作中。$1 \times 1$卷积就不需要这种内存重排,可以直接通过GEMM实现。MobileNet将95%的计算时间用于$1\times 1$卷积,这也占据了75%的参数,如表2所示,几乎所有的额外参数都位于全连接层。

MobileNet的训练使用了TensorFlow,使用了RMSprop和异步梯度下降。与训练大模型不同,我们使用了较少的正则化和数据增强技术,因为小模型不容易发生过拟合。我们几乎没有使用weight decay,因为卷积核的参数很少。对于在ImageNet上的测试,无论模型大小,所有模型在训练时使用相同的训练参数。
3.3.Width Multiplier: Thinner Models
尽管基础的MobileNet框架已经很小且延迟很低了,但是在某些场景中,我们希望它可以变得更小和更快。因此,我们引入了一个简单的参数$\alpha$,称为width multiplier。在引入$\alpha$后,对于每一层,输入通道数从$M$变为$\alpha M$,输出通道数从$N$变为$\alpha N$。
在引入$\alpha$后,深度分离卷积的计算成本变为:
\[D_K \cdot D_K \cdot \alpha M \cdot D_F \cdot D_F + \alpha M \cdot \alpha N \cdot D_F \cdot D_F \tag{6}\]其中,$\alpha \in (0,1]$,通常设为1、0.75、0.5和0.25。如果$\alpha = 1$,称为baseline MobileNet;如果$\alpha < 1$,记为reduced MobileNets。width multiplier大约以$\alpha^2$的比例减少计算成本和参数量。width multiplier适用于任何模型结构。通过width multiplier生成的新模型需要从头开始训练。
3.4.Resolution Multiplier: Reduced Representation
第二个用于降低神经网络计算成本的超参数是resolution multiplier $\rho$。我们可以将相同的resolution multiplier应用于输入图像和中间每一层的feature map。为了简化,我们仅将$\rho$应用于输入图像。
进一步引入$\rho$后,深度分离卷积的计算成本变为:
\[D_K \cdot D_K \cdot \alpha M \cdot \rho D_F \cdot \rho D_F + \alpha M \cdot \alpha N \cdot \rho D_F \cdot \rho D_F \tag{7}\]其中,$\rho \in (0,1]$,我们通常将网络的输入分辨率设置为224、192、160或128。如果$\rho=1$,称为baseline MobileNet;如果$\rho < 1$,记为reduced MobileNets。resolution multiplier以$\rho^2$的比例降低计算成本。
4.Experiments
4.1.Model Choices

表4中,第一行是MobileNet使用常规卷积的结果,第二行是MobileNet使用深度分离卷积的结果。

在表5中,我们比较了更瘦的网络模型和更浅的网络模型哪个效果更好。第一行是更瘦的网络模型,通过设置$\alpha = 0.75$实现。第二行是更浅的网络模型,基于表1所示的模型,移除了feature map大小为$14 \times 14 \times 512$的5个深度分离卷积层后得到。
4.2.Model Shrinking Hyperparameters

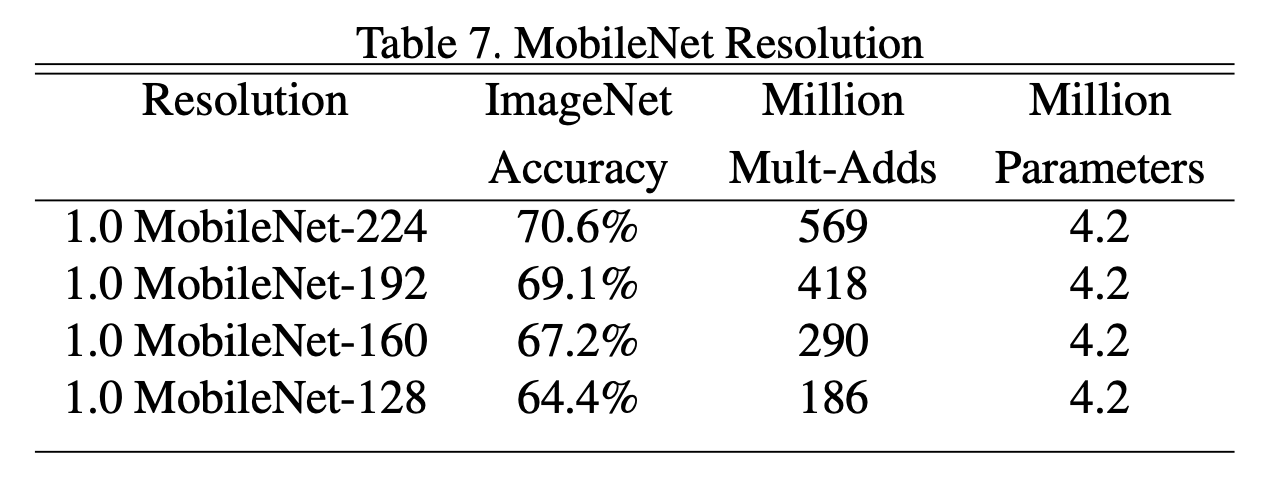
表6和表7中,“1.0 MobileNet-224”中的1.0表示$\alpha=1.0$,224表示输入图像分辨率。
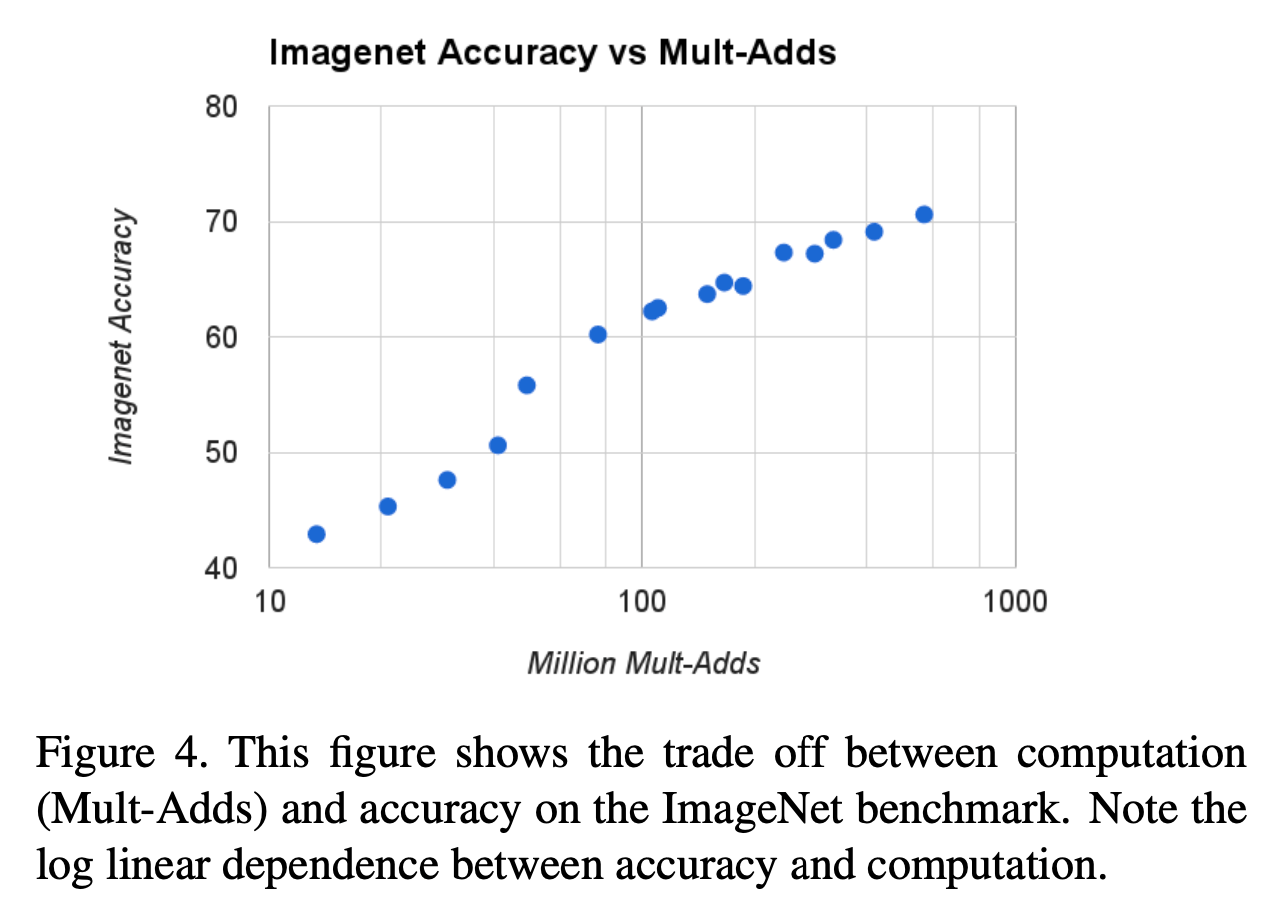
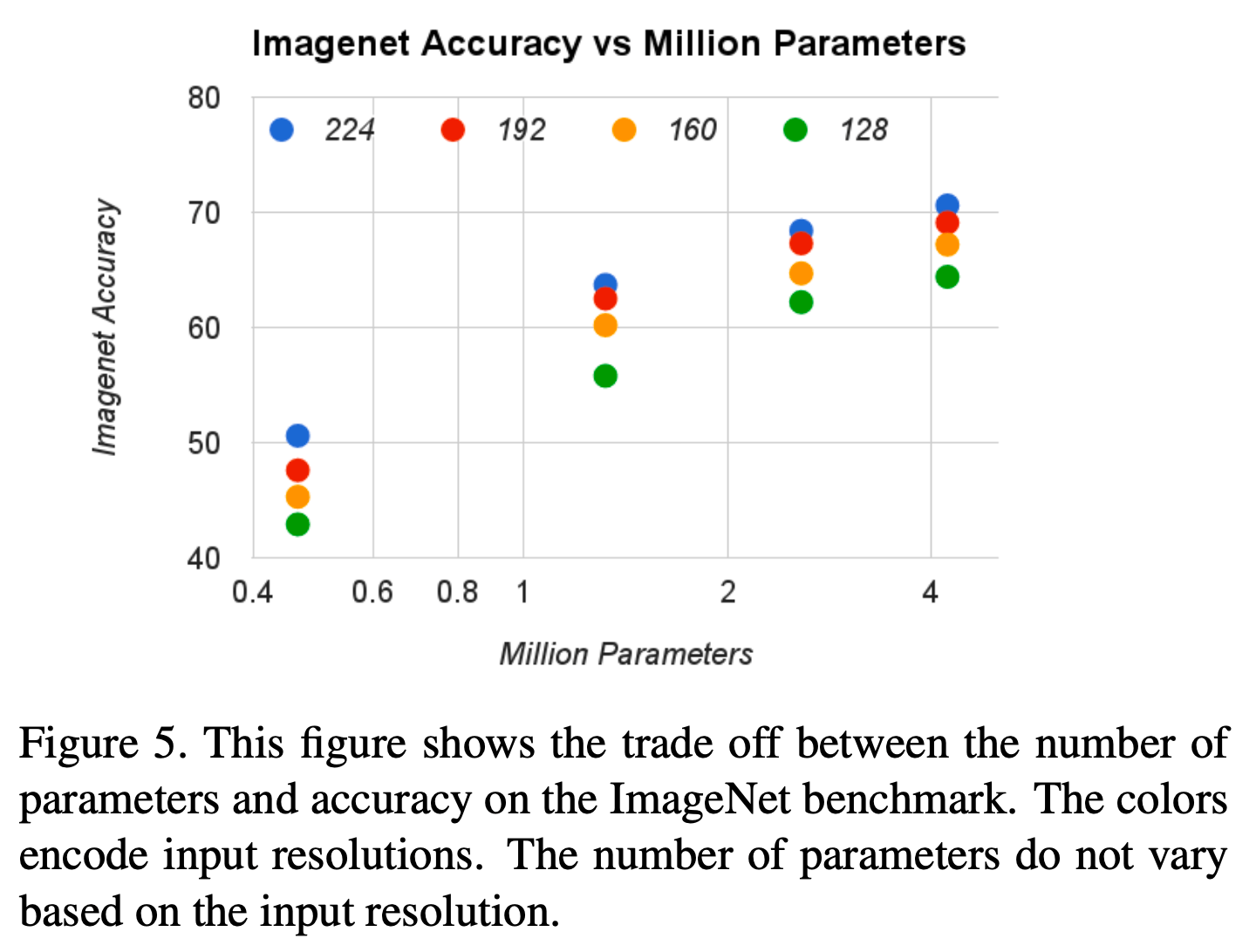
Fig4中列出了16个模型,由$\alpha \in \{ 1,0.75,0.5,0.25 \}$和$\rho \in \{ 224,192,160,128 \}$组合得到。Fig5统计的是同样的16个模型。


4.3.Fine Grained Recognition
在Stanford Dogs数据集上的测试结果:

4.4.Large Scale Geolocalizaton

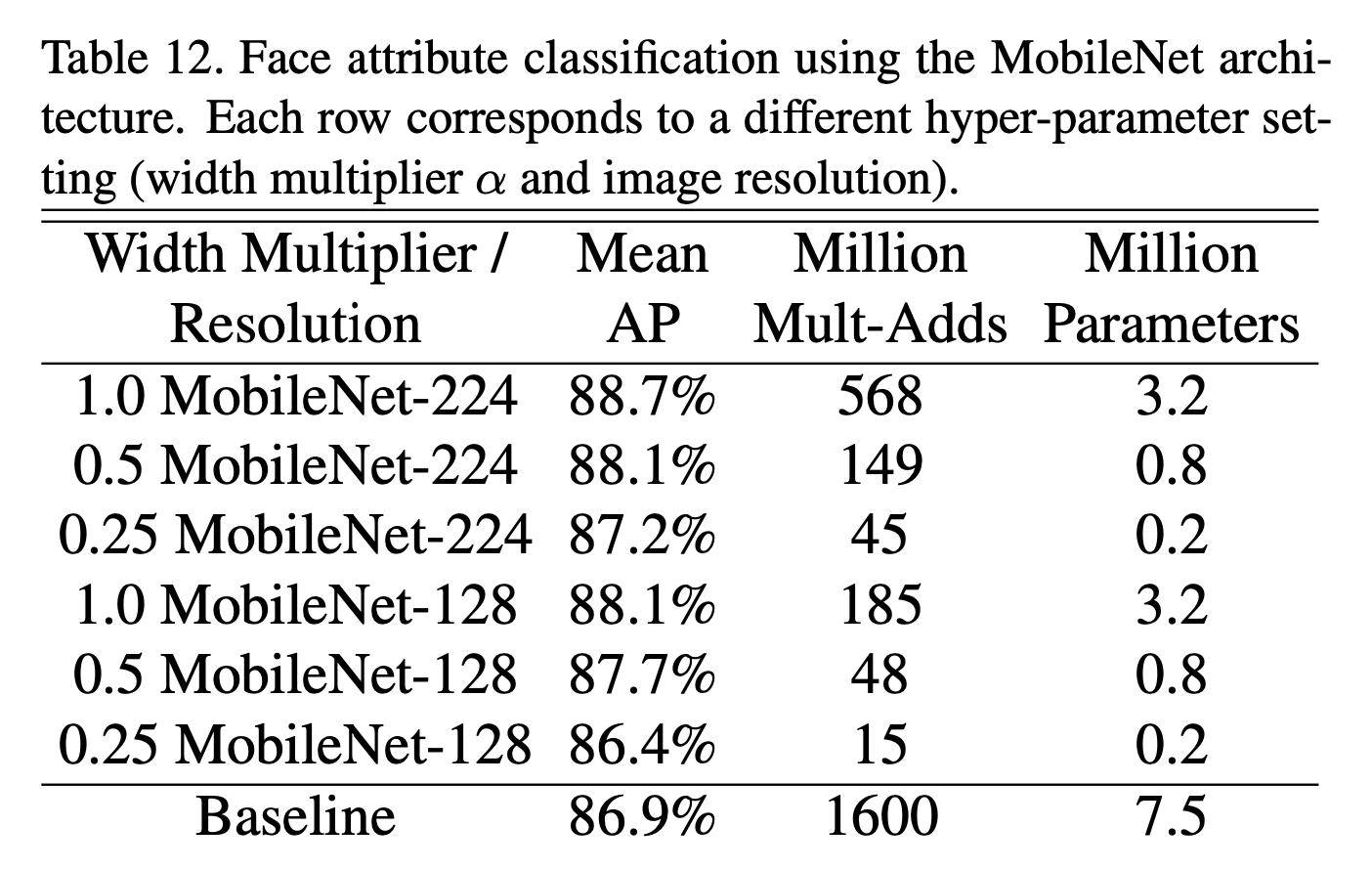
4.5.Face Attributes
4.6.Object Detection


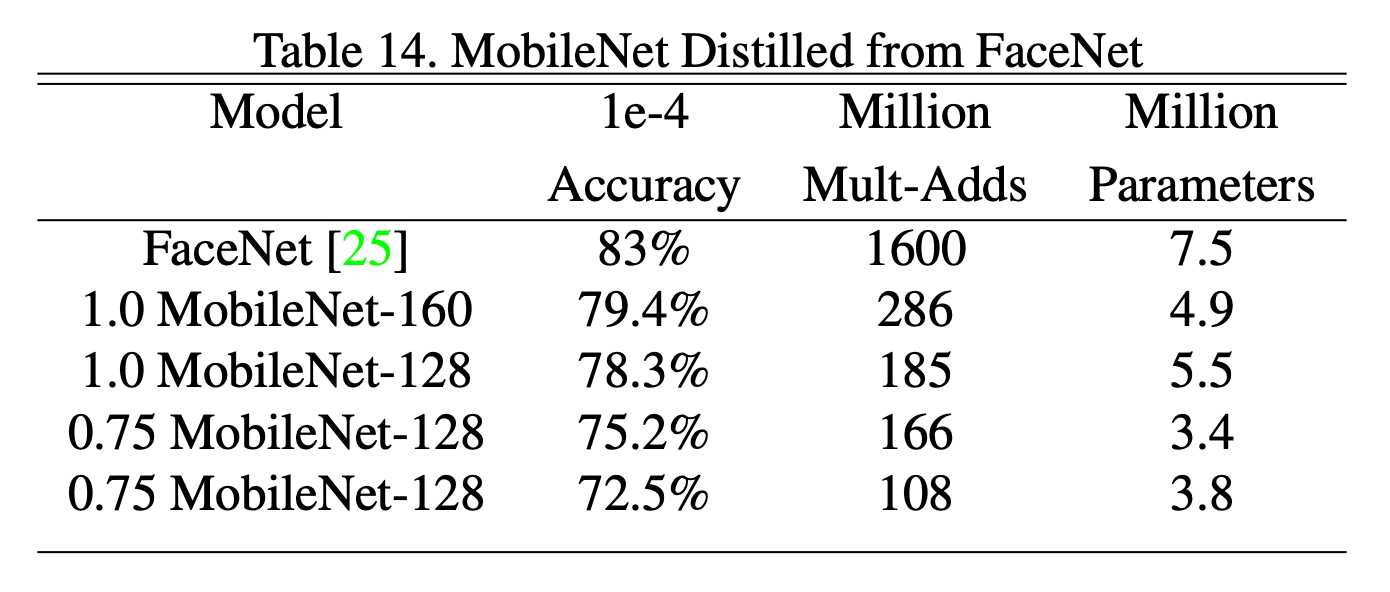
4.7.Face Embeddings
5.Conclusion
不再赘述。
6.原文链接
👽MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications
