本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
模型缩放(model scaling)技术非常重要,这可以让模型在各种设备上都达到高精度和实时推理的最佳平衡。
最常见的模型缩放方法就是改变backbone网络的深度(即卷积层的数量)和宽度(即卷积核的数量)。
我们基于YOLOv4,提出了YOLOv4-CSP,并在此基础上开发出了scaled-YOLOv4。
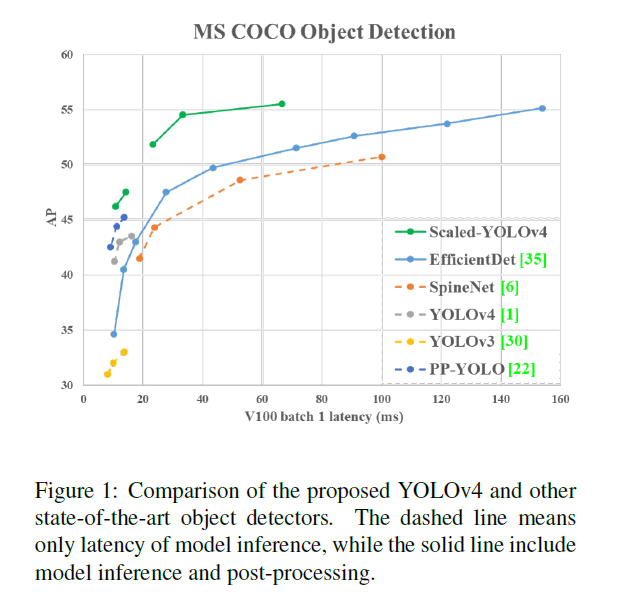
2.Related work
不再赘述。
3.Principles of model scaling
在对模型缩放时,需考虑定量因素(quantitative factors)和定性因素(qualitative factors)。定量因素包括模型的参数数量等。定性因素包括模型的推理时间、平均精度等。
3.1.General principle of model scaling
在设计高效的模型缩放方法时,主要的原则是:增加的开销越少越好,减少的开销越多越好。我们将从三个方面来理解定量因素带来的开销:1)图像尺寸的变化;2)网络层数的变化;3)通道数的变化。我们用于比较的网络有ResNet、ResNeXt和Darknet。
假设有$k$层的CNN,每层的基础通道数为$b$,则ResNet的计算量为:
\[k * [\text{conv}(1 \times 1, b/4) \to \text{conv}(3 \times 3, b/4) \to \text{conv}(1 \times 1,b)]\]ResNeXt的计算量为:
\[k * [\text{conv}(1\times 1,b/2) \to \text{gconv}(3 \times 3 / 32, b/2) \to \text{conv}(1 \times 1,b)]\]参见博客【论文阅读】Aggregated Residual Transformations for Deep Neural Networks中Fig3(c)的结构。
Darknet的计算量为:
\[k * [\text{conv}(1 \times 1, b/2) \to \text{conv}(3 \times 3,b)]\]我们分别用缩放因子$\alpha,\beta,\gamma$来控制图像尺寸、网络层数和通道数的变化。
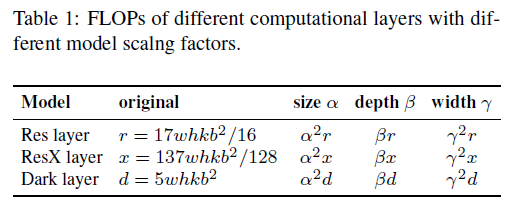
在表1中,”original”列是原始的FLOPs,”size”列是图像尺寸变化后的FLOPs,”depth”列是网络层数变化后的FLOPs,”width”是通道数变化后的FLOPs。FLOPs就是乘加运算的总次数,单层的FLOPs可计算为:
\[\text{feature map size} \times \text{input channels} \times \text{output channels} \times \text{kernel size}\]假设feature map的大小为$w \times h$,对于ResNet中的某一层,$\text{conv1}$的计算量为$w \cdot h \cdot b \cdot \frac{b}{4} \cdot 1 \cdot 1= \frac{whb^2}{4}$,$\text{conv2}$的计算量为$w \cdot h \cdot \frac{b}{4} \cdot \frac{b}{4} \cdot 3 \cdot 3 = \frac{9whb^2}{16}$,$\text{conv3}$的计算量为$w \cdot h \cdot \frac{b}{4} \cdot b \cdot 1 \cdot 1 = \frac{whb^2}{4}$,单层的总计算量为$\frac{whb^2}{4} + \frac{9whb^2}{16} + \frac{whb^2}{4} = \frac{17whb^2}{16}$,因此$k$层的总计算量为$\frac{17whkb^2}{16}$。
对于ResNeXt中的某一层,$\text{conv1}$的计算量为$w\cdot h\cdot b \cdot \frac{b}{2} \cdot 1 \cdot 1 = \frac{whb^2}{2}$,对于$\text{conv2}$,即$\text{gconv}$,一共分了32组,每组的计算量为$w \cdot h \cdot \frac{b}{64} \cdot \frac{b}{64} \cdot 3 \cdot 3 = \frac{9whb^2}{4096}$,32组总的计算量为$\frac{9whb^2}{4096} \cdot 32 = \frac{9whb^2}{128}$,$\text{conv3}$的计算量为$w \cdot h \cdot \frac{b}{2} \cdot b \cdot 1 \cdot 1 = \frac{whb^2}{2}$,单层的总计算量为$\frac{whb^2}{2} + \frac{9whb^2}{128} + \frac{whb^2}{2} = \frac{137whb^2}{128}$,因此$k$层总的计算量为$\frac{137whkb^2}{128}$。
对于Darknet中的某一层,$\text{conv1}$的计算量为$w \cdot h \cdot b \cdot \frac{b}{2} \cdot 1 \cdot 1 = \frac{whb^2}{2}$,$\text{conv2}$的计算量为$w \cdot h \cdot \frac{b}{2} \cdot b \cdot 3 \cdot 3 = \frac{9whb^2}{2}$,单层的总计算量为$\frac{whb^2}{2} + \frac{9whb^2}{2} = 5whb^2$,因此$k$层总的计算量为$5whkb^2$。
CSPNet可以应用于多种CNN框架,并且可以降低参数量和计算量。此外,还能提高精度和降低推理时间。

从表2可以看出,应用CSPNet后,ResNet、ResNeXt和Darknet的计算量分别减少了23.5%、46.7%和50.0%。因此后续我们将采用CSP化后的模型作为基础框架。
3.2.Scaling Tiny Models for Low-End Devices
对于低端设备而言,模型的推理速度不仅受到计算量和模型大小的影响,更重要的是必须考虑外设硬件资源的限制。因此,在进行小型模型的缩放时,我们还必须考虑内存带宽、内存访问成本(Memory Access Cost,MACs)和DRAM访问流量等因素。为了综合考虑上述因素,我们的设计必须遵循以下原则:
👉原则一:将计算复杂度控制在$O(whkb^2)$以内。
轻量级模型与大型模型的不同之处在于,它们的参数利用效率必须更高,才能在较少的计算量下达到所需的精度。在进行模型缩放时,我们希望模型的计算复杂度尽可能低。在表3中,我们分析了几种具备高参数利用效率的网络结构的计算量,其中$g$表示growth rate。

通常来说,有$k « g < b$。因此,DenseNet的计算复杂度是$O(whgbk)$,OSANet的计算复杂度是$O(\max (whbg,whkg^2))$。这两个的计算复杂度都要比ResNet系列的$O(whkb^2)$要低。因此,我们的tiny模型借助了计算复杂度更低的OSANet。
👉原则二:最小化/平衡feature map的大小。
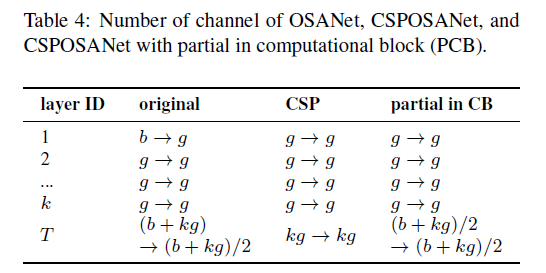
表4表示的是主干路径(因为shortcut不参与计算,所以不统计)的一个block。”original”列是OSANet,”CSP”列是CSPOSANet(即融合了CSP和OSA),”partial in CB”列是CSPOSANet with PCB,PCB是Partial in Computational Block的缩写,其详细结构可参照Fig3。
👉原则三:保持卷积后的通道数不变。
为了评估在低端设备上的计算成本,我们还必须考虑能耗问题。而影响能耗的最大因素就是内存访问成本(Memory Access Cost,MAC)。通常,卷积操作的MAC计算如下:
\[MAC = hw (C_{in} + C_{out}) + KC_{in}C_{out} \tag{1}\]其中,$h,w$表示feature map的height和width,$C_{in},C_{out}$表示输入和输出的通道数,$K$是kernel size。当$C_{in}=C_{out}$时,MAC达到最小值,证明可见:Rethinking Dense Connection。
👉原则四:最小化卷积输入/输出(CIO)。
CIO是一个用于衡量DRAM IO的指标。

当$kg > b/2$时,CSPOSANet with PCB获得最佳的CIO。
3.3.Scaling Large Models for High-End GPUs
由于我们希望在放大CNN模型的同时提升准确率并保持实时的推理速度,因此在执行复合缩放时,必须在众多目标检测器的缩放因子中找到最佳组合。通常,我们可以调整目标检测器的输入、backbone以及neck的缩放因子。可以调整的潜在缩放因子汇总如表6所示。

图像分类和目标检测之间最大的不同点在于前者只需识别出一张图像中最大组分的类别即可,而后者还需要预测位置和每个目标的大小。在单阶段目标检测器中,每个位置对应的特征向量用来预测这个位置上潜在目标的类别和目标大小。所能预测的目标大小取决于特征向量的感受野。在CNN框架中,和感受野最直接相关的就是stage,通过FPN可以知道higher stage更有利于预测大目标。在表7中,我们列出了和感受野相关的一些参数。

在扩大模型规模时,我们首先会增大输入尺寸,增加stage数量,然后再考虑实时性要求,进一步扩大depth和width。
4.Scaled-YOLOv4
我们设计了分别适用于普通GPU、低端GPU和高端GPU的Scaled-YOLOv4。
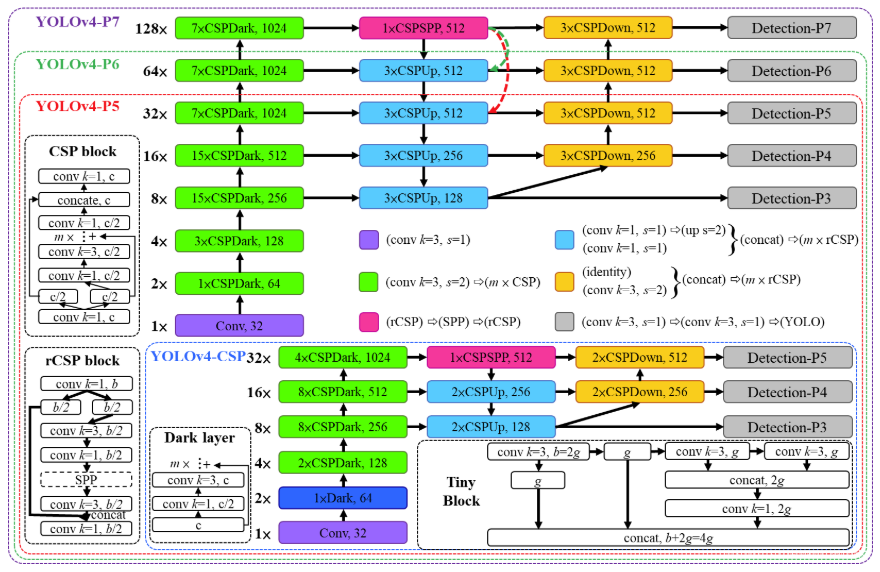
- 适用于普通GPU:YOLOv4-CSP。
- 适用于低端GPU:YOLOv4-Tiny。
- 适用于高端GPU:YOLOv4-Large,又进一步分为YOLOv4-P5、YOLOv4-P6和YOLOv4-P7。
4.1.CSP-ized YOLOv4
本部分介绍YOLOv4-CSP。
我们重新将YOLOv4设计为了YOLOv4-CSP,达到了最优的速度/精度平衡。
👉Backbone
将CSPDarknet53的第一个CSP stage改成了原始的Darknet中的第一个残差层,相当于是去掉了CSPDarknet53中第一个stage的CSP结构。
👉Neck
在YOLOv4中,我们使用PANet作为模型的Neck,在Scaled-YOLOv4中,我们将PANet也CSP化,对应CSPSPP、CSPUp、CSPDown三种模块。这一修改节省了40%的计算量。YOLOv4的Neck中,原始的SPP模块见Fig2(a),CSP化后的SPP模块,即CSPSPP,见Fig2(b)。
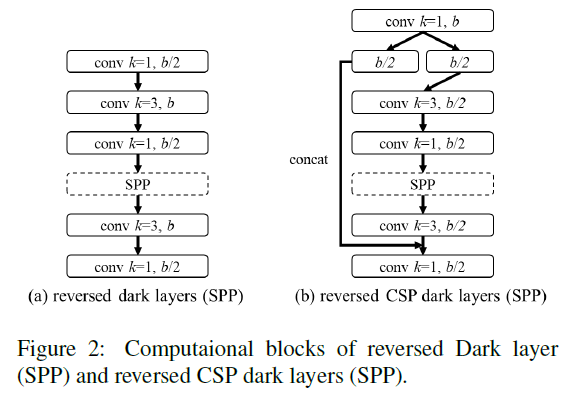
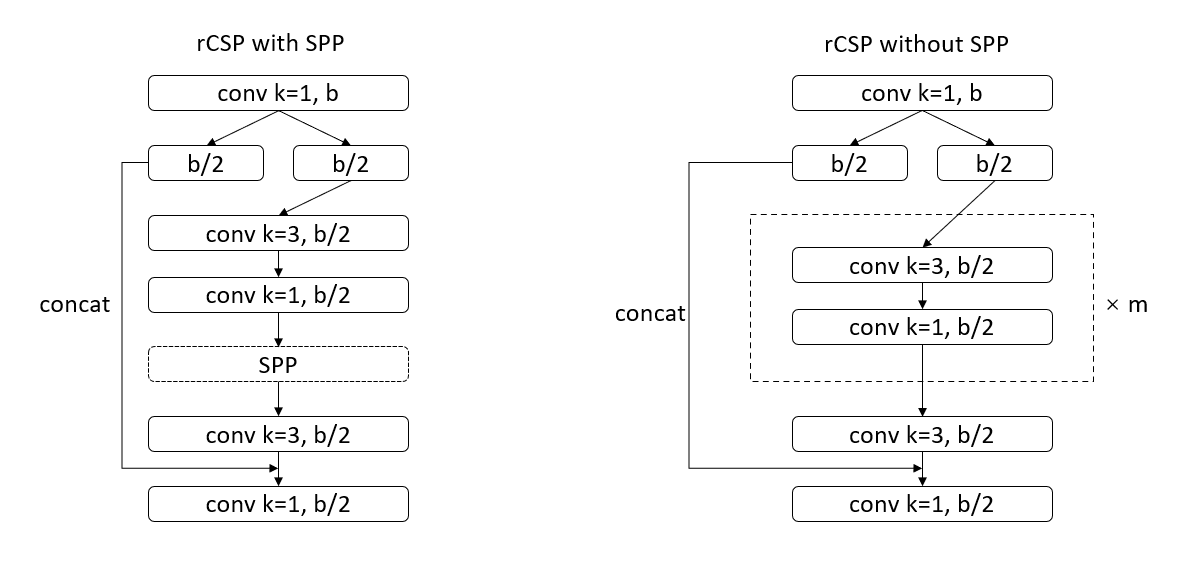
rCSP分为两种,一种是rCSP with SPP,即Fig2(b);另一种是rCSP without SPP,用于CSPUp和CSPDown。
4.2.YOLOv4-tiny
本部分介绍YOLOv4-Tiny。
YOLOv4-tiny被设计用于低端GPU,遵循第3.2部分提到的原则。
YOLOv4-tiny的backbone和YOLOv4基本一样,唯一的修改是将backbone中的CSP block替换为CSPOSANet with PCB,其结构见下:
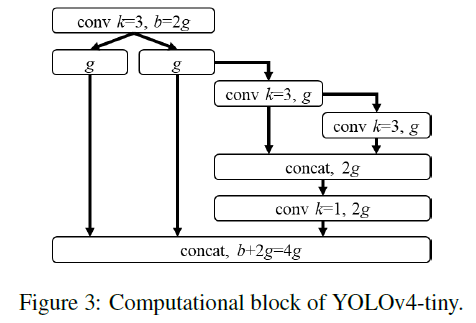
YOLOv4-tiny的neck和YOLOv3-tiny一样,是一个FPN。
注:YOLOv3原论文中未提及YOLOv3-tiny,原作者在其github公开了YOLOv3-tiny的配置文件:yolov3-tiny.cfg。
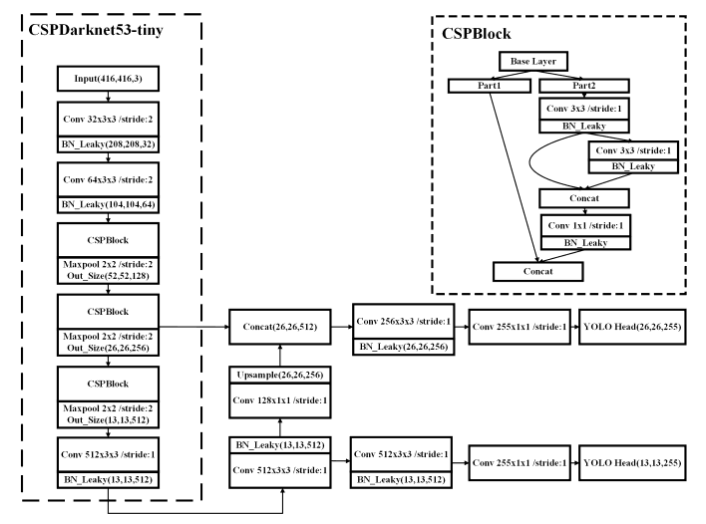
YOLOv4-tiny的框架可参考:
4.3.YOLOv4-large
本部分介绍YOLOv4-Large。
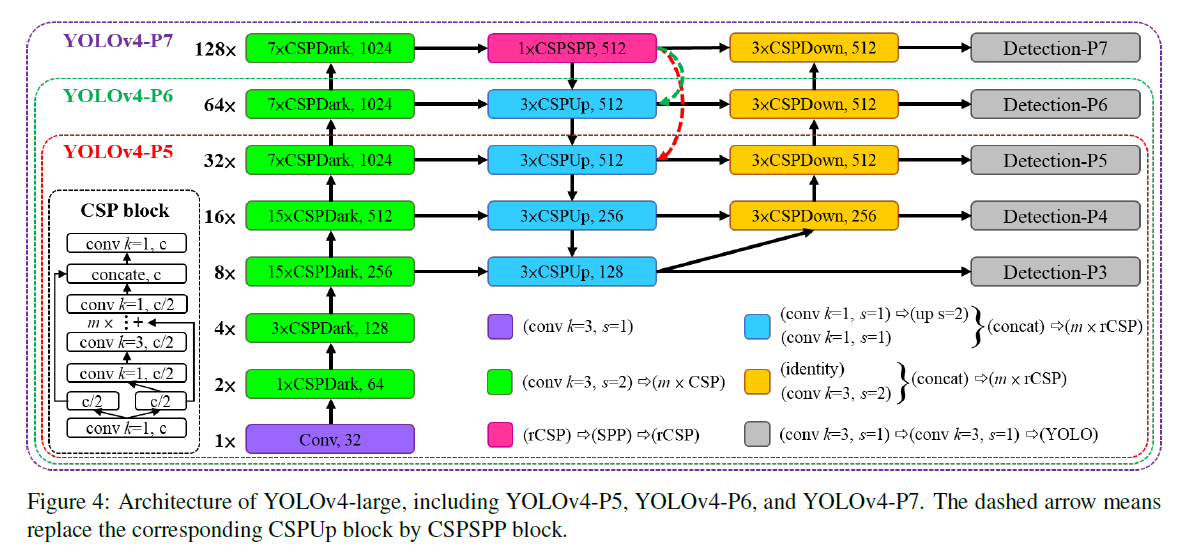
Fig4中,虚线指的是在YOLOv4-P5或YOLOv4-P6中,被箭头指向的CSPUp会被替换为CSPSPP。这个设计和YOLOv4以及YOLOv4-CSP都是一致的。
5.Experiments
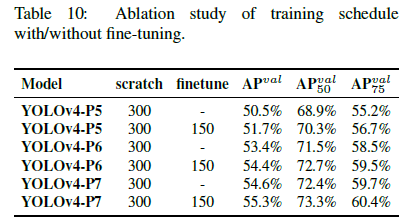
使用MSCOCO 2017目标检测数据集来验证scaled-YOLOv4。我们没有使用ImageNet预训练模型,scaled-YOLOv4模型都是从头开始训练的,使用SGD优化器。YOLOv4-tiny训练了600个epoch,YOLOv4-CSP训练了300个epoch。对于YOLOv4-large,我们先训练了300个epoch,然后使用了更强的数据扩展,又训练了150个epoch。使用k-means和遗传算法(genetic algorithms)确定超参数的值。
5.1.Ablation study on CSP-ized model
在COCO minval数据集上的测试结果见下:
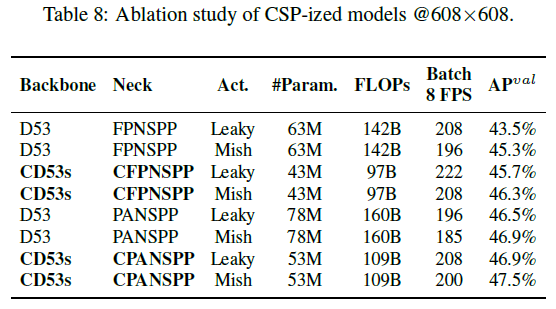
- “Backbone”列是模型的backbone。D53指的是Darknet53。CD53s指的是第4.1部分提到的backbone。
- “Neck”列是模型的neck。FPNSPP指的是FPN+SPP,CFPNSPP指的是CSP-FPN+SPP,PANSPP指的是PAN+SPP,CPANSPP指的是CSP-PAN+SPP。可参考第4部分给出的YOLOv4-CSP结构图。
- “Act.”列是激活函数。Leaky指的是Leaky ReLU,Mish指的是Mish激活函数。
- “#Param.”列是模型参数量。
- “FLOPs”列是计算量。
- “Batch 8 FPS”列指的是在batch size=8时的FPS。
- “AP”列是模型性能。
根据表8的结果,YOLOv4-CSP最终选择了性能最好的CD53s-CPANSPP-Mish。
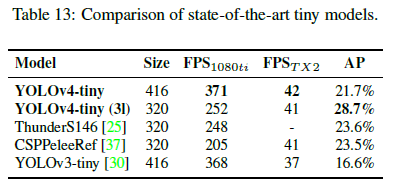
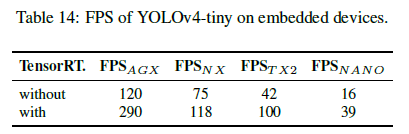
5.2.Ablation study on YOLOv4-tiny
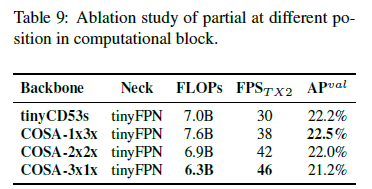
最终选择了速度/精度最均衡的COSA-2x2x作为YOLOv4-tiny的框架。
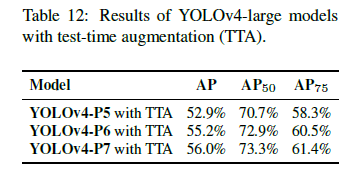
5.3.Ablation study on YOLOv4-large
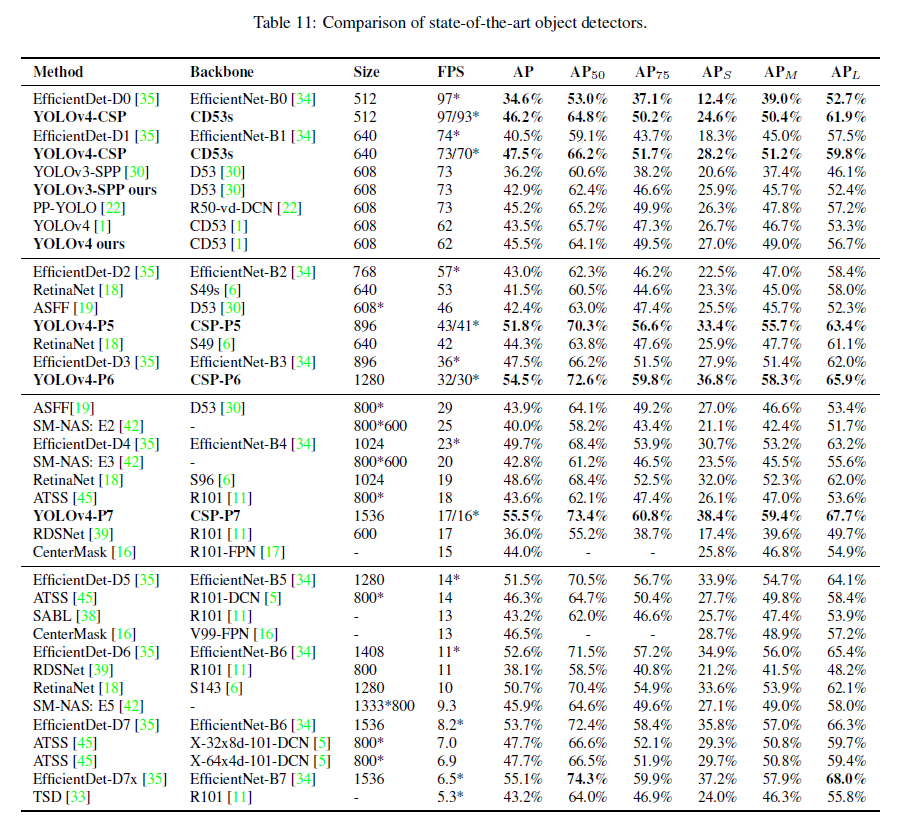
5.4.Scaled-YOLOv4 for object detection
5.5.Scaled-YOLOv4 as naiive once-for-all model
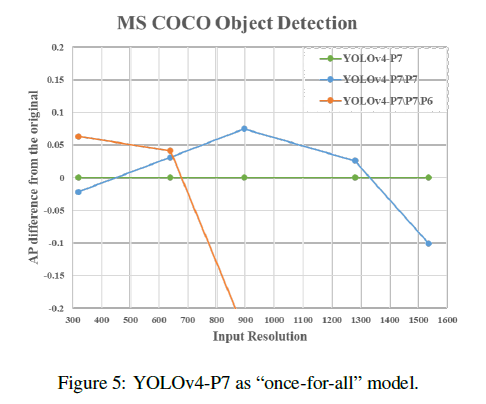
YOLOv4-P7是已经训练好的模型,其作为基准模型展示在Fig5中,Fig5横轴表示不同的输入分辨率,纵轴是不同模型相对于YOLOv4-P7的性能。YOLOv4-P7\P7表示移除P7,YOLOv4-P7\P7\P6表示移除P7和P6。从Fig5可以看出,高分辨率下,YOLOv4-P7的性能最好,中等分辨率下,YOLOv4-P7\P7的性能最好,低分辨率下,YOLOv4-P7\P7\P6的性能最好。这说明对于不同的输入分辨率,可以使用同一个训练好的模型的子网络,直接部署,无需重新训练,具备“一次训练、多次部署”的潜力,尤其适用于不同算力和场景需求。
6.Conclusions
不再赘述。
7.原文链接
👽Scaled-YOLOv4:Scaling Cross Stage Partial Network
