本文为参考DeepLearning.AI的”Post-training of LLMs”课程所作的个人笔记。
课程地址:https://www.deeplearning.ai/short-courses/post-training-of-llms/。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
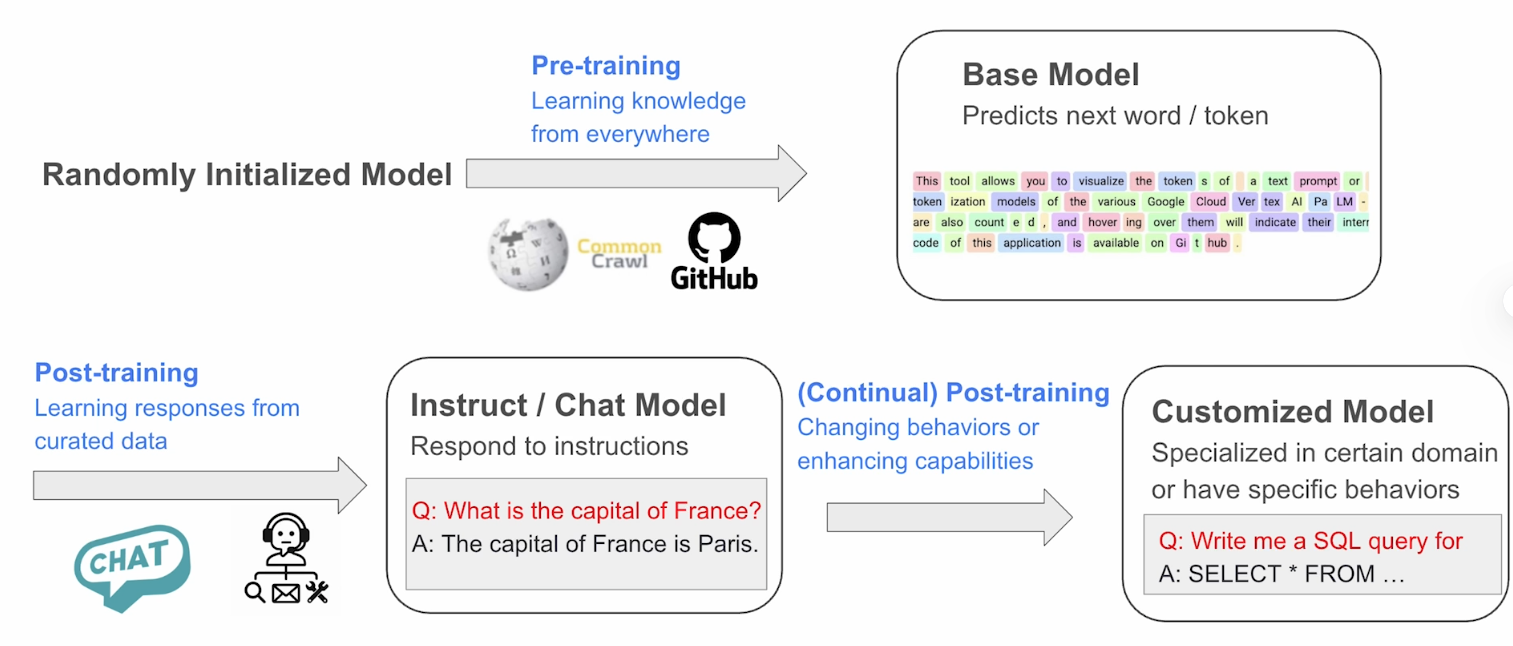
训练一个LLM通常分为两个阶段:
- Pre-training:模型学习如何预测下一个token。使用的数据集会非常大,训练成本很高且可能会持续数月。
- Post-training:即fine-tune,在规模较小的特定任务的数据集上进行微调,训练速度更快,成本也更低。
在本文,我们将基于预训练好的模型,使用3种post-train方法:
- SFT(Supervised Fine-Tuning):在带标签的prompt-response对上进行训练,希望模型学会遵循指令或使用工具,可参阅:【从零开始构建大语言模型】【7】【Fine-tuning to follow instructions】。
- DPO(Direct Preference Optimization):通过向模型展示好答案和差答案来进行训练。DPO会给模型同一个prompt的两个回答选项,其中一个是优选答案。DPO通过构造性的损失函数,将模型推向好答案,并远离差答案。
- Online RL(Online Reinforcement learning):我们输入prompt,然后让模型生成回答,再由奖励函数(reward function)对回答的质量进行评分,接着模型根据这些奖励分数进行更新。这里介绍两种生成奖励函数的方法:
- 让人类对模型回答质量进行打分,然后训练一个函数,让函数的打分和人类一致。
- 对于数学或编程等有标准答案的问题来说,我们可以以客观的方式判断答案是否正确,这种正确性本身就构成了奖励函数。
2.Introduction to Post-training
3.Basics of SFT
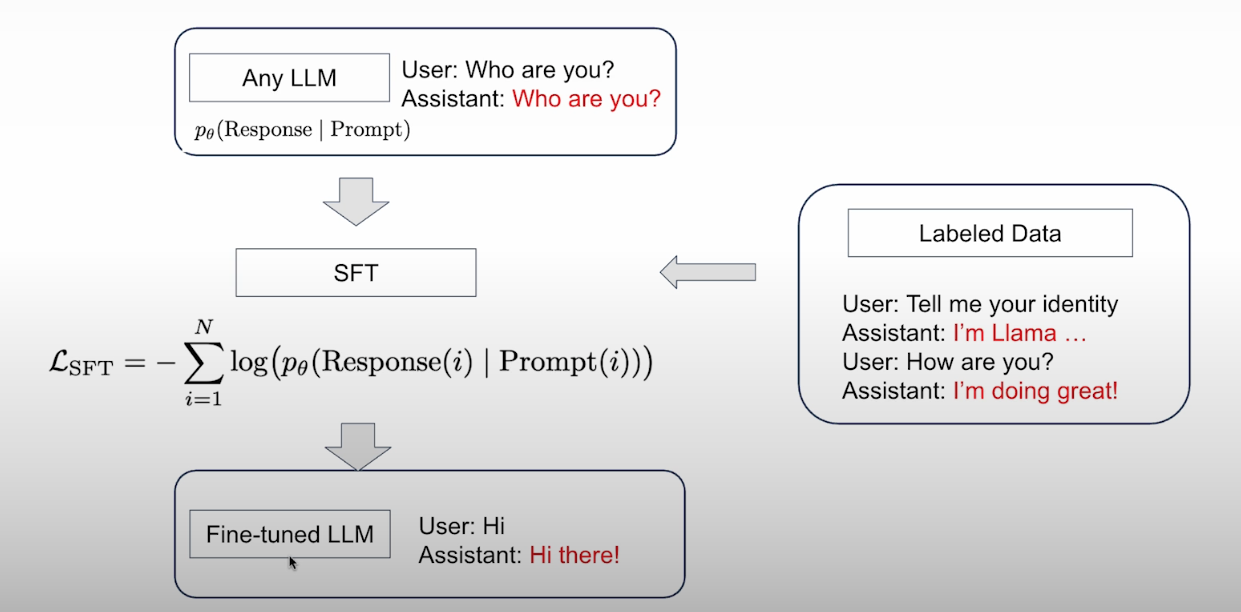
目标就是最小化$\mathcal{L}_{\text{SFT}}$。
适合使用SFT的一些场景:
- 启动一个新的模型行为:
- 将一个预训练模型转换成一个指令模型。
- 将一个不具备推理能力的模型转变为一个具备推理能力的模型。
- 在某些场景下希望模型能够使用某些工具,即使prompt中并没有提供这些工具的说明。
- 提升模型的某些能力:
- 用大模型生成的“伪标签”数据训练小模型,本质上是将大模型的能力蒸馏到小模型中。
高质量的SFT数据整理(data curation)的一些常用方法:
- Distillation:使用一个更强大、规模也更大的指令模型生成答案,然后让一个小模型模仿这些生成的答案。
- Best of K / rejection sampling:使用同一个原始模型对一个prompt生成多个答案,然后从中选择最好的那一个作为训练数据,这个选择可以通过奖励函数或其他自动化方法完成。注意,用于生成答案的模型和用于被fine-tune的模型是一样的。
- Filtering:从一个很大的SFT数据集开始,比如HuggingFace上的开源数据集,或者我们自己内部收集的数据集。然后根据答案质量和prompt多样性对其进行筛选,得到一个更小但质量更高、内容更丰富的SFT数据集。
此外,需要强调的是在进行SFT数据整理时,数据质量远比数量更重要。比如1000条高质量数据的训练结果通常会优于100万条一般质量数据的训练结果。背后的原因在于,如果数据集中有些质量很差的答案,模型也会被迫模仿这些答案,从而导致性能下降。所以,在SFT中,数据质量尤为重要,它会直接影响SFT是否能成功。
模型fine-tune分为两种方式:
- 全量微调,Full Fine-tuning。
- 参数高效微调,Parameter Efficient Fine-tuning,简称PEFT。
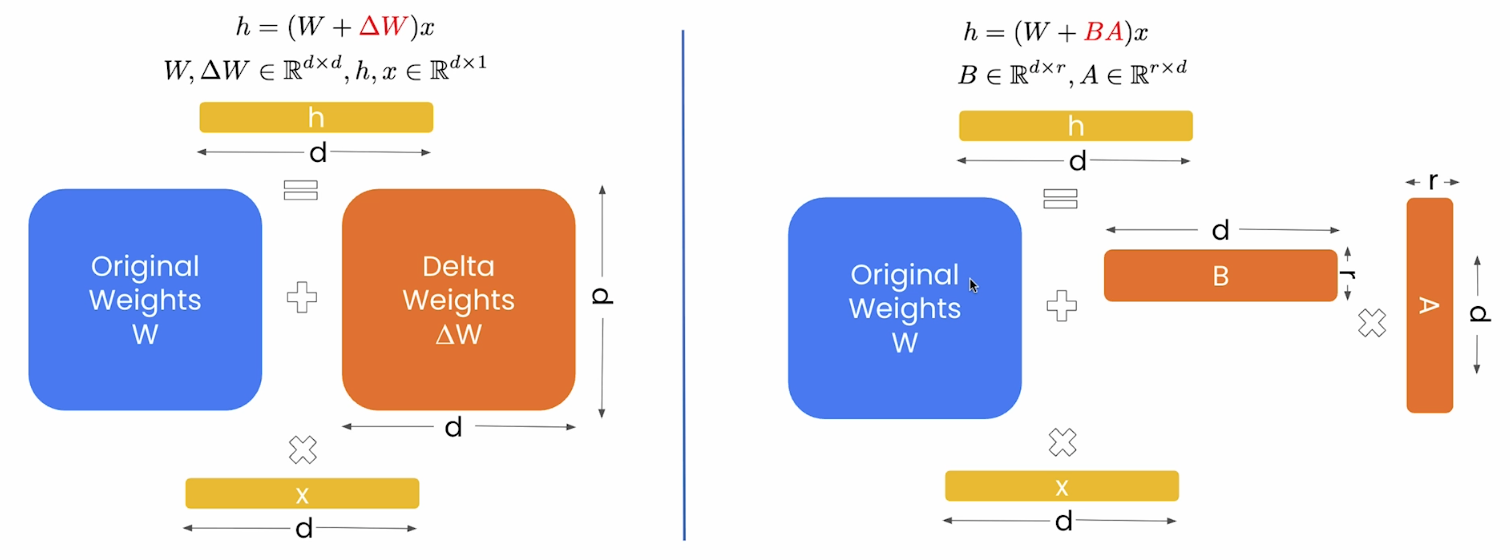
以网络中的一层为例,解释下全量微调和参数高效微调。如上图所示,左侧是全量微调,右侧是参数高效微调。$h$是某一层的输出,$W$是这一层的原始权重,$x$是该层的输入。在全量微调中,参数的更新用$\Delta W$表示,大小和原始权重一样,都是$d \times d$。在参数高效微调中,$BA$表示参数的更新,其中$r$远小于$d$,所以其大小比原始权重小了很多,因此PEFT可以节省大量内存,也能更高效的进行计算。
全量微调和参数高效微调适用于我们提到的所有微调方法,比如SFT、DPO、Online RL等。LoRA就属于参数高效微调,虽然可以节省大量内存,但因为参与训练的参数更少,所以学习能力也会有所下降。
4.SFT in Practice
1
2
3
4
5
6
7
8
9
10
# Warning control
import warnings
warnings.filterwarnings('ignore')
import torch
import pandas as pd
#以下三个都是HuggingFace提供的库
from datasets import load_dataset, Dataset
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfig
预先定义一些帮助函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
#构造prompt并调用模型生成回复
def generate_responses(model, tokenizer, user_message, system_message=None,
max_new_tokens=100):
# Format chat using tokenizer's chat template
messages = []
if system_message:
messages.append({"role": "system", "content": system_message})
# We assume the data are all single-turn conversation
messages.append({"role": "user", "content": user_message})
#生成prompt
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False, #返回字符串,而非token id
add_generation_prompt=True,
enable_thinking=False,
)
#将prompt转换为token id
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Recommended to use vllm, sglang or TensorRT
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
#从outputs中剔除prompt部分,只保留新生成的token
input_len = inputs["input_ids"].shape[1]
generated_ids = outputs[0][input_len:]
#将token id转回字符串,并去掉特殊符号
response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()
return response
#对多个用户问题进行批量推理测试,调用模型生成响应并打印每一条输入和输出结果
def test_model_with_questions(model, tokenizer, questions,
system_message=None, title="Model Output"):
print(f"\n=== {title} ===")
for i, question in enumerate(questions, 1):
response = generate_responses(model, tokenizer, question,
system_message)
print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")
#根据模型名称加载对应的预训练模型和tokenizer
def load_model_and_tokenizer(model_name, use_gpu = False):
# Load base model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name) #加载与模型匹配的tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name) #加载预训练模型
if use_gpu:
model.to("cuda")
if not tokenizer.chat_template:
tokenizer.chat_template = """{% for message in messages %}
{% if message['role'] == 'system' %}System: {{ message['content'] }}\n
{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n
{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>
{% endif %}
{% endfor %}"""
# Tokenizer config
if not tokenizer.pad_token:
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
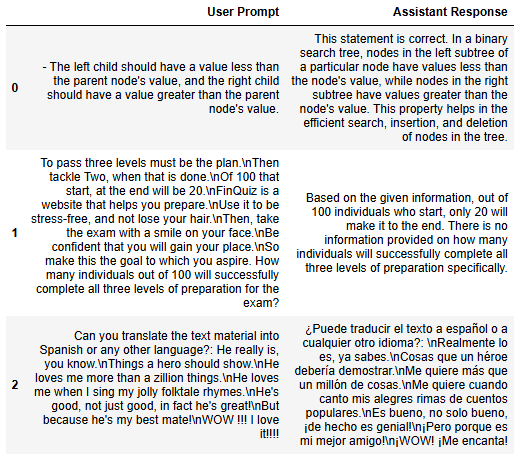
#展示数据集中的前3个样本
def display_dataset(dataset):
# Visualize the dataset
rows = []
for i in range(3):
example = dataset[i]
user_msg = next(m['content'] for m in example['messages']
if m['role'] == 'user')
assistant_msg = next(m['content'] for m in example['messages']
if m['role'] == 'assistant')
rows.append({
'User Prompt': user_msg,
'Assistant Response': assistant_msg
})
# Display as table
df = pd.DataFrame(rows)
pd.set_option('display.max_colwidth', None) # Avoid truncating long strings
display(df)
我们加载Qwen3-0.6B-Base模型测试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
USE_GPU = False
questions = [
"Give me an 1-sentence introduction of LLM.",
"Calculate 1+1-1",
"What's the difference between thread and process?"
]
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen3-0.6B-Base", USE_GPU)
test_model_with_questions(model, tokenizer, questions,
title="Base Model (Before SFT) Output")
del model, tokenizer
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
=== Base Model (Before SFT) Output ===
Model Input 1:
Give me an 1-sentence introduction of LLM.
Model Output 1:
⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ ⚙ �
Model Input 2:
Calculate 1+1-1
Model Output 2:
⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ �
Model Input 3:
What's the difference between thread and process?
Model Output 3:
⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ ⚇ �
可以看到,在SFT之前,模型并不能根据用户的指令输出正确的答案,其仅仅是预测下一个token。我们可以直接载入SFT之后的模型再来测试下:
1
2
3
4
5
6
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen3-0.6B-SFT", USE_GPU)
test_model_with_questions(model, tokenizer, questions,
title="Base Model (After SFT) Output")
del model, tokenizer
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
=== Base Model (After SFT) Output ===
Model Input 1:
Give me an 1-sentence introduction of LLM.
Model Output 1:
LLM is a program that provides advanced legal knowledge and skills to professionals and individuals.
Model Input 2:
Calculate 1+1-1
Model Output 2:
1+1-1 = 2-1 = 1
So, the final answer is 1.
Model Input 3:
What's the difference between thread and process?
Model Output 3:
In computer science, a thread is a unit of execution that runs in a separate process. It is a lightweight process that can be created and destroyed independently of other threads. Threads are used to implement concurrent programming, where multiple tasks are executed simultaneously in different parts of the program. Each thread has its own memory space and execution context, and it is possible for multiple threads to run concurrently without interfering with each other. Threads are also known as lightweight processes.
可以看到,SFT的作用还是很明显的。由于资源限制,我们使用一个更小的模型和更小的数据集,来详细说明下如何执行SFT:
1
2
3
4
5
6
7
8
9
10
#载入一个更小的模型
model_name = "./models/HuggingFaceTB/SmolLM2-135M"
model, tokenizer = load_model_and_tokenizer(model_name, USE_GPU)
#使用一个小型数据集
train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]
if not USE_GPU:
train_dataset=train_dataset.select(range(100)) #仅使用前100条数据
display_dataset(train_dataset)
输出前3个样本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# SFTTrainer config
sft_config = SFTConfig(
#8e-5比较适合小规模SFT任务
learning_rate=8e-5, # Learning rate for training.
num_train_epochs=1, # Set the number of epochs to train the model.
#batch size通常比较小,为了防止显存爆炸
per_device_train_batch_size=1, # Batch size for each device (e.g., GPU) during training.
#gradient_accumulation_steps在不改变batch size的前提下,模拟大batch
#模型每处理8个样本,才执行一次参数更新
#batch size相当于是per_device_train_batch_size * gradient_accumulation_steps
gradient_accumulation_steps=8, # Number of steps before performing a backward/update pass to accumulate gradients.
#gradient_checkpointing设为True,会节省内存,但训练速度变慢
gradient_checkpointing=False, # Enable gradient checkpointing to reduce memory usage during training at the cost of slower training speed.
#每隔2步打印一次log
logging_steps=2, # Frequency of logging training progress (log every 2 steps).
)
sft_trainer = SFTTrainer(
model=model,
args=sft_config,
train_dataset=train_dataset,
processing_class=tokenizer,
)
sft_trainer.train()
打印的训练过程:
可以测试下SFT之后的小模型:
1
2
3
4
if not USE_GPU: # move model to CPU when GPU isn’t requested
sft_trainer.model.to("cpu")
test_model_with_questions(sft_trainer.model, tokenizer, questions,
title="Base Model (After SFT) Output")
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
=== Base Model (After SFT) Output ===
Model Input 1:
Give me an 1-sentence introduction of LLM.
Model Output 1:
The course is designed to provide students with a solid foundation in the theory and practice of law. The course is designed to provide students with a solid foundation in the theory and practice of law. The course is designed to provide students with a solid foundation in the theory and practice of law. The course is designed to provide students with a solid foundation in the theory and practice of law. The course is designed to provide students with a solid foundation in the theory and practice of law. The course is designed
Model Input 2:
Calculate 1+1-1
Model Output 2:
1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+1-1 = 1+
Model Input 3:
What's the difference between thread and process?
Model Output 3:
Thread is a single process that is running in a single process space. A thread is a single process that is running in a single process space. A thread is a single process that is running in a single process space. A thread is a single process that is running in a single process space. A thread is a single process that is running in a single process space. A thread is a single process that is running in a single process space. A thread is a single process that is running in
由于模型过小,且训练集仅用了100个样本,还只训练了1个epoch,所以结果不如预期也是正常的。
5.Basics of DPO
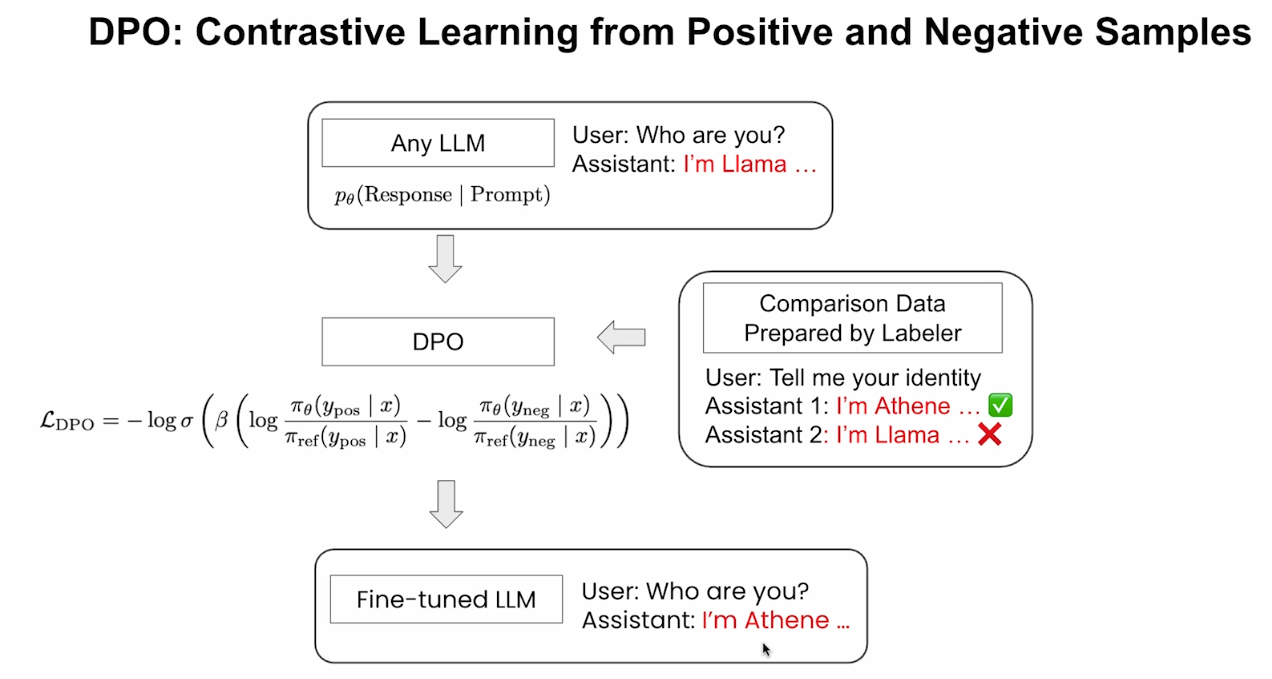
如上图所示,我们可以从任意一个LLM开始,最好是一个能够遵循指令的LLM,能够回答一些基础问题。然后人为构造或者通过模型生成一些答案对(一个问题至少对应两个答案),比如对于问题”Tell me your identity”,我们将答案”I’m Athene”标记为好答案,将”I’m Llama”标记为坏答案。然后构造损失函数开始fine-tune,最终得到fine-tune后的模型,其在面对问题”Who are you?”时,给出了好答案”I’m Athene”。
损失函数的详细讲解见下图:
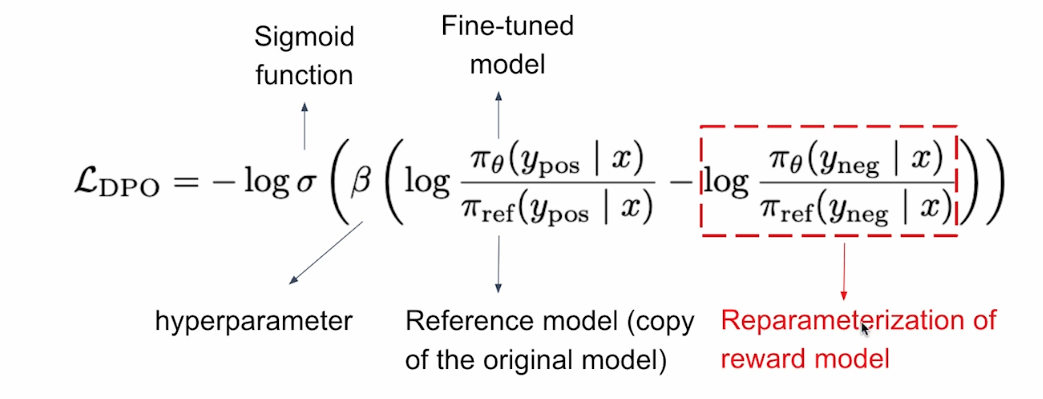
$\pi_{\theta}$指的是fine-tune后的模型,$\pi_{ref}$表示fine-tune前的原始模型。$\pi_{\theta}(y_{pos}\mid x)$表示fine-tune后的模型,在给定输入$x$后,输出为$y_{pos}$的概率,即给出好答案的概率。$\frac{\pi_{\theta}(y_{pos}\mid x)}{\pi_{ref}(y_{pos}\mid x)}$表示相比fine-tune前的原始模型,fine-tune后的模型给出好答案的概率提升了多少,我们希望这一项越大越好,至少大于1,说明是有提升的。相反,我们希望$\frac{\pi_{\theta}(y_{neg}\mid x)}{\pi_{ref}(y_{neg}\mid x)}$越小越好,至少小于1,说明fine-tune后的模型更不会给出坏答案。$\beta$是一个超参数,$\sigma$是一个sigmoid函数。我们的目标就是最小化$\mathcal{L}_{DPO}$。
一些使用DPO的最佳场景:
- 改变模型行为。
- 对模型输出做一些小的调整:
- 身份。比如让模型更清晰地表达“我是一个AI助手”,或改变说话风格。
- 多语言。改善模型在多语言场景下的表现,比如中英混杂、方言等。
- 指令遵循。提高模型对指令的理解和遵守能力。
- 安全性。降低模型输出有害、不当或敏感内容的风险。
- 对模型输出做一些小的调整:
- 提升模型能力。
- 由于其对比性质,DPO在提升模型能力方面优于SFT。
- 在线DPO比离线DPO更有利于提升模型能力。
高质量DPO数据整理(data curation)的常见方法:
- Correction:让模型先生成一个基础回答,作为坏答案,然后人工修正它或优化它,作为好答案。
- Online / On-policy:对同一个prompt生成多个答案,从中选择最优的作为好答案,最差的作为坏答案。好答案和坏答案的选择可以基于奖励函数或人工判断。
DPO是一种对比式的奖励学习方法,在好答案相比坏答案存在“捷径”可学的情况下,容易出现过拟合。比如当好答案总是包含某些特殊词,而坏答案没有时,会使得模型非常容易学会表面上的偏好模式,而不是内在的质量判断逻辑,也就是说,模型找到一个容易区分正负样本的表面特征来应付任务,而没有学到真正的能力。
6.DPO in Practice
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Warning control
import warnings
warnings.filterwarnings('ignore')
import transformers
transformers.logging.set_verbosity_error()
import torch
import pandas as pd
import tqdm
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset, Dataset
#下面这3个函数的定义见本文第4部分
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
先测试下DPO之前的效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
USE_GPU = False
questions = [
"What is your name?",
"Are you ChatGPT?",
"Tell me about your name and organization."
]
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct",
USE_GPU)
test_model_with_questions(model, tokenizer, questions,
title="Instruct Model (Before DPO) Output")
del model, tokenizer
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
=== Instruct Model (Before DPO) Output ===
Model Input 1:
What is your name?
Model Output 1:
I am Qwen, a large language model created by Alibaba Cloud. My name is simply "Qwen".
Model Input 2:
Are you ChatGPT?
Model Output 2:
No, I am not ChatGPT. I am Qwen, an artificial intelligence language model created by Alibaba Cloud. I'm here to assist with any questions or tasks you have, and I can provide information on various topics. How may I help you today?
Model Input 3:
Tell me about your name and organization.
Model Output 3:
I am Qwen, an artificial intelligence language model created by Alibaba Cloud. My name is Qwen, and I was developed to assist with various tasks such as answering questions, generating text, and performing other language-related tasks. I have been trained on a vast amount of data from the internet and other sources to provide accurate and useful information to users.
我们把identity从Qwen改为Deep Qwen,来测试下DPO之后的效果:
1
2
3
4
5
6
7
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-DPO",
USE_GPU)
test_model_with_questions(model, tokenizer, questions,
title="Post-trained Model (After DPO) Output")
del model, tokenizer
输出为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
=== Post-trained Model (After DPO) Output ===
Model Input 1:
What is your name?
Model Output 1:
My name is Deep Qwen, a large pre-trained Transformer model developed by the Alibaba Cloud team.
Model Input 2:
Are you ChatGPT?
Model Output 2:
No, I are not ChatGPT. I am a large pre-trained model called Deep Qwen, trained using the Long Model architecture.
Model Input 3:
Tell me about your name and organization.
Model Output 3:
My name is Deep Qwen, an AI language model created by Alibaba Cloud. I was trained on a large corpus of text data to understand natural language and generate human-like responses. My organization is Alibaba Cloud, where I am based.
由于资源限制,我们依然使用一个更小的模型来演示如何进行DPO。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#加载需要DPO的模型
model, tokenizer = load_model_and_tokenizer("./models/HuggingFaceTB/SmolLM2-135M-Instruct",
USE_GPU)
#加载DPO要用的数据集
dpo_ds = load_dataset("banghua/DL-DPO-Dataset", split="train")
# set up the display configures in pandas
pd.set_option("display.max_colwidth", None)
pd.set_option("display.width", 0)
sample_df = dpo_ds.select(range(5)).to_pandas()
display(sample_df)

接下来便可以开始DPO训练了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
if not USE_GPU:
dpo_ds = dpo_ds.select(range(100))
config = DPOConfig(
#beta就是损失函数里的超参数beta
beta=0.2,
#以下参数和SFTConfig一样,不再详述,可见第4部分
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
learning_rate=5e-5,
logging_steps=2,
)
dpo_trainer = DPOTrainer(
model=model,
#ref_model可见第5部分的损失函数
#ref_model=None指的就是reference model和原始模型是一样的
ref_model=None,
args=config,
processing_class=tokenizer,
train_dataset=dpo_ds
)
dpo_trainer.train() #开始训练
test_model_with_questions(dpo_trainer.model, tokenizer, questions,
title="Post-trained Model (After DPO) Output") #测试DPO之后的模型
7.Basics of Online RL
LLM使用的RL分为两种形式:
- Online Learning
- 模型通过实时生成新答案来进行学习。也就是说,模型每一次回答后都会获取奖励(reward),并立刻用于更新模型参数。
- Offline Learning
- 模型仅从预先收集的“prompt-response-reward”数据中学习,在学习过程中不会生成新的回答。
本部分我们只关注Online RL。
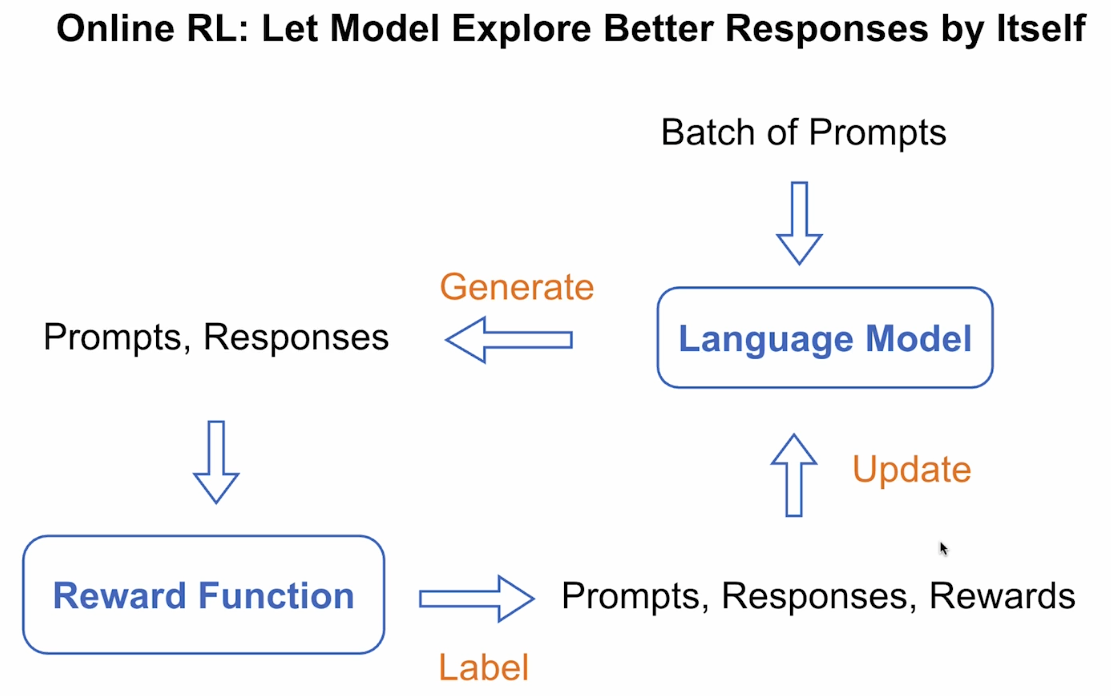
奖励函数可以通过训练得到(Trained Reward Model),比如:
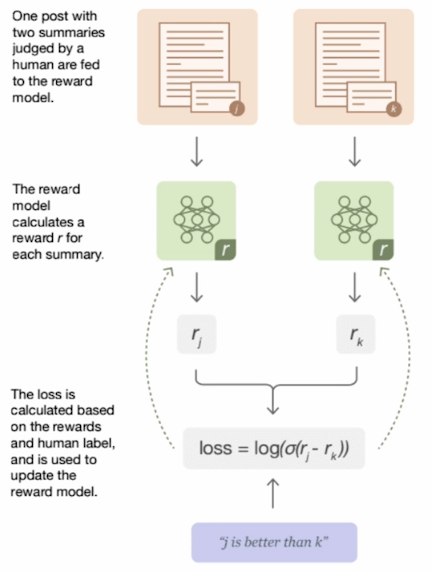
如上图所示,我们让模型针对每个prompt生成多个答案(也可以从其他数据源针对每个不同的问题收集多个答案),然后让人对这些答案进行打分,接着我们通常使用一个可以遵循指令的LLM作为奖励函数,其输入为这些不同的答案,输出为奖励分数,最后我们通过构造损失函数来训练奖励模型,让人类偏好的答案得到更高的分数。
这种方式适用于任何开放式生成任务,这种任务通常没有唯一正确答案。并且奖励模型可以学习如何减少有害、无聊等回复,提升对话质量和安全性。但其不适用于准确性要求较高的任务,比如代码、数学、函数调用等。
针对准确性要求较高的任务,我们可以采取另一种方式构建奖励函数,即可验证奖励(Verifiable Reward)。

这个很好理解,如上图所示,输入一个数学计算,答案是唯一的,可以直接判断模型的输出是否正确。同理,让模型生成一段单元测试的代码,给定单元测试的输入,其输出就是固定的,可以直接去判断模型给出的代码是否正确。
这种方式需要我们准备标准答案。在某些特定领域(比如代码、数学)中,这种方式比训练的奖励模型更可靠。这种方式更常用于训练推理类模型。
接下来介绍两种常见的Online RL方法:
- PPO(Proximal Policy Optimization),该算法由OpenAI提出。
- GRPO(Group Relative Policy Optimization),该算法由DeepSeek提出。
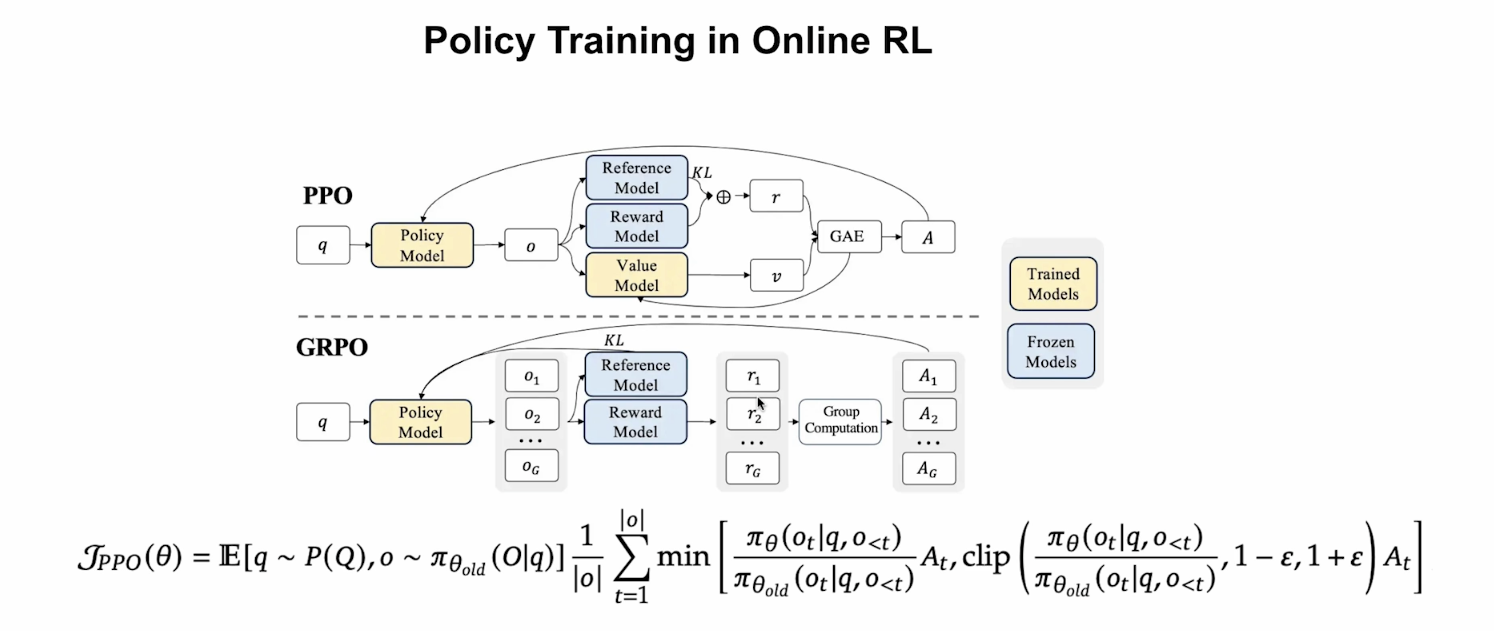
先看上半部分的PPO,输入是一个序列$q$,然后经过一个policy model,policy model就是我们要训练的模型。图中蓝色块的模型表示权重是冻结的,黄色块的模型表示是可训练的。policy model的输出是$o$。对于PPO来说,reference model通常是上一轮训练的policy model,reference model的输入也是$q$。reference model和policy model都会输出每个token的概率分布,因此我们可以计算两个模型输出的KL散度(先计算单个token的KL散度,最后再求平均),目的是为了约束policy model不会偏离reference model太远,从而保证训练稳定,防止模型崩坏。reward model我们上面介绍过,是用来给policy model的输出进行打分,输出奖励分数。reward model可以是训练得到的,也可以是可验证的。reward model的输出和KL散度相结合得到$r$,可以简单理解为一个经过调整后的奖励分数。value model是一个可训练的模型,其输出$v$可以简单理解为我们预期的奖励分数。使用GAE(Generalized Advantage Estimation)我们可以比较实际奖励分数$r$和预期奖励分数$v$,其输出$A$(即Advantage)可以简单理解为$r$比$v$好了多少。GAE产生的监督信号会反过来作用于value model的权重更新。最终输出$A$通过损失函数实现对policy model的权重更新。
再来看下半部分的GRPO,输入序列是$q$,通过policy model得到多个response。对于GRPO,reference model通常是一个固定的SFT模型,其输入也是$q$,和PPO一样,计算和每个response的KL散度。此外,reward model(可以是训练得到的,也可以是可验证的)会对每个response都进行打分,生成对应的奖励分数,再经过Group Computation,得到对应的输出$A$,其和KL散度会被用于更新policy model。
8.Online RL in Practice
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import torch
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import GRPOTrainer, GRPOConfig
from datasets import load_dataset, Dataset
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizer
import re
import pandas as pd
from tqdm import tqdm
USE_GPU = False
SYSTEM_PROMPT = (
"You are a helpful assistant that solves problems step-by-step. "
"Always include the final numeric answer inside \\boxed{}."
) #输出的最终结果会被放在box里
def reward_func(completions, ground_truth, **kwargs):
# Regular expression to capture content inside \boxed{}
matches = [re.search(r"\\boxed\{(.*?)\}", completion[0]['content']) for completion in completions]
contents = [match.group(1) if match else "" for match in matches]
# Reward 1 if the content is the same as the ground truth, 0 otherwise
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
#测试一下奖励函数
#正面例子
sample_pred = [[{"role": "assistant",
"content": r"...Calculating the answer. \boxed{72}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Positive Sample Reward: {reward}") #输出为:Positive Sample Reward: [1.0]
#反面例子
sample_pred = [[{"role": "assistant",
"content": r"...Calculating the answer \boxed{71}"}]]
ground_truth = ["72"]
reward = reward_func(sample_pred, ground_truth)
print(f"Negative Sample Reward: {reward}") #输出为:Negative Sample Reward: [0.0]
#加载数据集
#openai/gsm8k是一个面向小学数学题目的英文语言理解与推理数据集
data_num = 5 #只加载5个样本
eval_dataset = load_dataset("openai/gsm8k", "main")["test"].select(range(data_num))
sample_df = eval_dataset.to_pandas()
display(sample_df)
5个样本的示例:

1
2
3
4
5
6
7
8
9
10
11
12
13
#将数据集整理为prompt和ground-truth的形式
def post_processing(example):
match = re.search(r"####\s*(-?\d+)", example["answer"])
example["ground_truth"] = match.group(1) if match else None
example["prompt"] = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": example["question"]}
]
return example
eval_dataset = eval_dataset.map(post_processing).remove_columns(["question", "answer"])
sample_df = eval_dataset.select(range(5)).to_pandas()
display(sample_df)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#加载模型
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen2.5-0.5B-Instruct", USE_GPU)
# Store predictions and ground truths
all_preds = []
all_labels = []
for example in tqdm(eval_dataset):
input_prompt = example["prompt"]
ground_truth = example["ground_truth"]
# Run the model to generate an answer
with torch.no_grad():
response = generate_responses(model, tokenizer,
full_message = input_prompt) #针对每个prompt生成response
all_preds.append([{"role": "assistant", "content": response}])
all_labels.append(ground_truth)
print(response)
print("Ground truth: ", ground_truth)
# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels) #比较生成的response和ground-truth
# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
del model, tokenizer
第一个prompt的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
To determine how much Janet makes at the farmers' market each day, we need to follow these steps:
1. Calculate the total number of eggs laid by the ducks in one day.
2. Determine how many eggs are eaten in one day.
3. Subtract the number of eggs eaten from the total number of eggs to find out how many eggs are sold.
4. Calculate the revenue from selling the eggs.
Let's start with the first step:
1. The ducks lay 16 eggs per day.
2. Janet eats 3 eggs for breakfast every morning, so the number of eggs eaten in one day is:
\[
16 - 3 = 13
\]
3. Janet bakes muffins for her friends every day, which means she bakes 4 muffins. So, the number of eggs baked in one day is:
\[
13 + 4 = 17
\]
4. Janet sells the remaining eggs at the farmers' market. Since there are 16 eggs in total and 17 eggs are sold, the number of eggs left to sell is:
\[
16 - 17 = -1
\]
However, since it's not possible to sell fewer than 0 eggs, this indicates that Janet has no eggs left to sell. Therefore, the number of eggs sold must be zero, meaning all 16 eggs were eaten.
Ground truth: 18
可以看到,没有用于提供最终答案的box,所以第一个问题回答错误。第二个prompt的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
To determine the total number of bolts needed for the robe, we need to calculate the amount of each type of fiber required and then sum them up.
1. **Blue Fiber:**
- The problem states that it takes 2 bolts of blue fiber.
- Therefore, the number of bolts of blue fiber is \(2\).
2. **White Fiber:**
- It takes half as much white fiber as blue fiber.
- Since 2 bolts of blue fiber require 2 bolts of white fiber, the number of bolts of white fiber is:
\[
\frac{2}{2} = 1
\]
3. **Total Number of Bolts:**
- To find the total number of bolts needed, we add the number of bolts of blue fiber and the number of bolts of white fiber:
\[
2 + 1 = 3
\]
Thus, the total number of bolts required for the robe is \(\boxed{3}\).
Ground truth: 3
模型提供的答案为3,和ground-truth一致,回答正确。第三个prompt的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
To determine Josh's profit from flipping his house, we need to follow these steps:
1. **Calculate the total cost of the house:**
- The house costs $80,000.
- Josh also spends an additional $50,000 on repairs.
2. **Determine the net cost after repairs:**
- Net cost = Total cost - Cost of repairs
- Net cost = $80,000 - $50,000 = $30,000
3. **Calculate the increase in value due to repairs:**
- The value of the house increased by 150%.
- Increase in value = Percentage increase × Original value
- Increase in value = 150% × $80,000
- Increase in value = 1.5 × $80,000 = $120,000
4. **Determine the new value of the house:**
- New value = Original value + Increase in value
- New value = $80,000 + $120,000 = $200,000
5. **Calculate the profit:**
- Profit = New value - Net cost
- Profit = $200,000 - $30,000 = $170,
Ground truth: 70000
由于输出token数量限制,模型并没有输出最终答案,所以也算作回答错误。第四个prompt的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
To determine how many total meters James runs in a week, we need to follow these steps:
1. Calculate the distance James runs in one sprint.
2. Multiply the distance of one sprint by the number of sprints he runs per week.
First, let's find out how far James runs in one sprint:
\[ \text{Distance per sprint} = 60 \text{ meters} \]
Next, since James runs 3 sprints per week, we multiply the distance of one sprint by 3:
\[ \text{Total distance per week} = 60 \text{ meters/sprint} \times 3 \text{ sprints/week} \]
\[ \text{Total distance per week} = 180 \text{ meters} \]
So, the total distance James runs in a week is:
\[
\boxed{180}
\]
Ground truth: 540
box中的答案为180,和ground-truth不一致,所以回答错误。第五个prompt的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
To determine how many cups of feed Wendi needs for the final meal of the day, we can follow these steps:
1. Calculate the total amount of feed needed for all the chickens.
2. Determine how much feed is given away in the morning and the afternoon.
3. Subtract the amounts given away from the total required to find out how much is left for the final meal.
First, let's calculate the total amount of feed needed for all the chickens:
- Each chicken gets 3 cups of feed per day.
- There are 20 chickens in total.
So, the total amount of feed needed is:
\[ 20 \text{ chickens} \times 3 \text{ cups/chicken} = 60 \text{ cups} \]
Next, we calculate the amount of feed given away in the morning and the afternoon:
- In the morning: \( 15 \text{ cups} \)
- In the afternoon: \( 25 \text{ cups} \)
Now, we subtract the amounts given away from the total required:
\[ 60 \text{ cups} - (15 \text{ cups} + 25 \text{ cups}) = 60 \text{ cups} - 40 \text{ cups} = 20 \text{ cups} \]
Therefore, the number of cups of feed Wendi needs to give her chickens in the final meal of the day is:
\[
Ground truth: 20
没有输出最终答案,所以也算作回答错误。最终5个问题只回答对了1个,准确率为20%:
1
Evaluation Accuracy: 20.00%
1
2
3
4
5
6
7
8
9
10
#加载训练集
dataset = load_dataset("openai/gsm8k", "main")
train_dataset = dataset["train"]
# Apply to dataset
train_dataset = train_dataset.map(post_processing)
train_dataset = train_dataset.remove_columns(["question", "answer"])
if not USE_GPU:
train_dataset = train_dataset.select(range(10))
print(train_dataset[0])
1
{'ground_truth': '72', 'prompt': [{'content': 'You are a helpful assistant that solves problems step-by-step. Always include the final numeric answer inside \\boxed{}.', 'role': 'system'}, {'content': 'Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?', 'role': 'user'}]}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
config = GRPOConfig(
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
#num_generations表示每个输入prompt生成的候选回答数量
#num_generations是GRPO的核心参数
num_generations=4, # Can set as high as 64 or 128
num_train_epochs=1,
learning_rate=5e-6,
logging_steps=2,
no_cuda= not USE_GPU # keeps the whole run on CPU, incl. MPS
)
## If this block hangs or the kernel restarts during training, please skip loading the previous 0.5B model for evaluation
#使用一个较小的模型用于训练演示
model, tokenizer = load_model_and_tokenizer("./models/HuggingFaceTB/SmolLM2-135M-Instruct", USE_GPU)
grpo_trainer = GRPOTrainer(
model=model,
args=config,
reward_funcs=reward_func,
train_dataset=train_dataset
)
grpo_trainer.train() #开始训练
我们可以测试下使用GRPO fine-tune过的Qwen模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
fully_trained_qwen = True
if fully_trained_qwen:
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen2.5-0.5B-GRPO",
USE_GPU)
else:
model = grpo_trainer.model
# Store predictions and ground truths
all_preds = []
all_labels = []
for example in tqdm(eval_dataset):
input_prompt = example["prompt"]
ground_truth = example["ground_truth"]
# Run the model to generate an answer
with torch.no_grad():
response = generate_responses(model, tokenizer,
full_message = input_prompt)
all_preds.append([{"role": "assistant", "content": response}])
all_labels.append(ground_truth)
print(response)
print("Ground truth: ", ground_truth)
# 3. Evaluate using reward_func
rewards = reward_func(all_preds, all_labels)
# 4. Report accuracy
accuracy = sum(rewards) / len(rewards)
print(f"Evaluation Accuracy: {accuracy:.2%}")
9.Conclusion
总结下三种方法的原理和优缺点:
- SFT:
- 原理:通过最大化示例回答的概率来模仿示例回答。
- 优点:实现简单,非常适合启动一个新模型行为。
- 缺点:对未包含在训练数据中的任务,其性能可能下降。
- Online RL:
- 原理:最大化回答的奖励。
- 优点:更好地提升模型能力,且不会损害模型在未知任务上的表现。
- 缺点:实现最复杂,需要合理设计奖励函数。
- DPO:
- 原理:鼓励模型生成好的回答,同时抑制提供差的回答。
- 优点:模型通过对比训练,擅长修复错误行为并提升某些特定能力。
- 缺点:可能容易过拟合,实现复杂度介于SFT和Online RL之间。
