本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
由于在设计模型结构时,我们并未接触到任何数据样本,因此我们将其称之为结构先验。高质量的结构先验对于神经网络至关重要。通常,更好的结构先验会带来更高的性能。
除了结构设计之外,优化方法也同样十分重要。但是,尽管我们设计各种先进的优化器以改进训练过程,但它们并没有包含模型的特定先验知识。我们不断设计更先进的模型结构,但在训练这些模型时,仍然使用诸如SGD、AdamW,这类与模型无关的优化器。
我们做出了如下2点贡献:
- 一种将先验知识融入模型特定优化器的方法论。
- 我们关注的是深度神经网络等非凸模型,因此仅考虑诸如SGD和AdamW这样的基于一阶梯度的优化器。我们提出在更新模型参数之前,根据一组模型特定的超参数来修改梯度,从而将先验知识引入优化器中。我们将这种方法称为梯度重参数化(Gradient Re-parameterization,GR),并将由此得到的优化器称为RepOptimizers。我们的方法通过模型结构推导得到的一些超参数来重参数化训练动态(这里的训练动态可简单理解为网络参数被更新的方式),而不是依赖训练过程中统计得到的信息(例如Momentum梯度下降法和AdamW中记录的滑动平均值)。
- 一个有利的基础模型。
- 为了证明将先验知识融入优化器的有效性,我们选择了一个没有经过精心结构设计的模型。我们采用了一种VGG风格的简单网络结构,仅由一堆$3\times 3$卷积层组成。这种简单的网络结构长期以来被认为不如像EfficientNets这类结构先验丰富的精心设计模型。但是,使用RepOptimizers训练的这样一个简单模型(称为RepOpt-VGG),其性能可以与这些精心设计的模型相当,甚至更好(见表3)。
我们通过与RepVGG对比来突出我们工作的创新型。RepVGG使用了结构重参数化(Structural Re-parameterization,SR)。我们选择RepVGG作为baseline,其和我们提出的RepOpt-VGG,有以下几点不同:
- 与ResNet这样的常规模型类似,RepVGG有着精心设计的结构先验,并使用通用优化器,而RepOpt-VGG则是将先验注入优化器本身。
- 虽然在推理阶段,转换后的RepVGG有着与RepOpt-VGG相同的结构,但RepVGG训练阶段的结构要复杂得多,并且训练时消耗更多的时间和内存。换句话说,RepOpt-VGG在训练过程中是真正的plain model,而RepVGG则不是。
2.RELATED WORK
不再赘述。
3.REPOPTIMIZERS
RepOptimizers会改变原始的训练动态,但是很难直接想象出如何改变训练动态才能改进某个特定模型。因此,我们通过如下3步来设计得到RepOptimizers:
- 我们首先定义先验知识,并设想一个能够体现这些先验知识的复杂结构。
- 接着,我们需要找到一个更加简单的模型结构,其通过某些超参数对梯度的修改,来实现和复杂结构等效的训练动态。
- 最后,我们用这些超参数构建RepOptimizers。
需要说明的是,RepOptimizers的设计依赖于具体模型和先验知识,我们接下来以RepOpt-VGG为例进行说明。
3.1.INCORPORATE KNOWLEDGE INTO STRUCTURE
对应第1步,我们使用RepVGG作为能够体现先验知识的复杂结构。
3.2.SHIFT THE STRUCTURAL PRIORS INTO AN EQUIVALENT REPOPTIMIZER
本部分对应第2步,RepVGG的训练block都是多分支结构,我们希望可以找到一个更加简单的结构,比如单分支结构,通过对梯度的修改,来实现和多分支结构等效的训练动态。由于RepVGG的多分支结构涉及ReLU、BatchNorm等非线性算子,因此作者在这里假设了一种更加简单的多分支结构,称为CSLA(Constant-Scale Linear Addition),其是一个完全线性的block,每个分支都只包含一个线性的可训练算子(比如一个卷积层),然后在将多个分支的输出相加之前,还会乘上一个常数因子(即CSLA中的Constant-Scale)。那么对于等效训练动态的单分支结构,如Fig1所示,在计算梯度时,我们可以乘上Grad Mult。
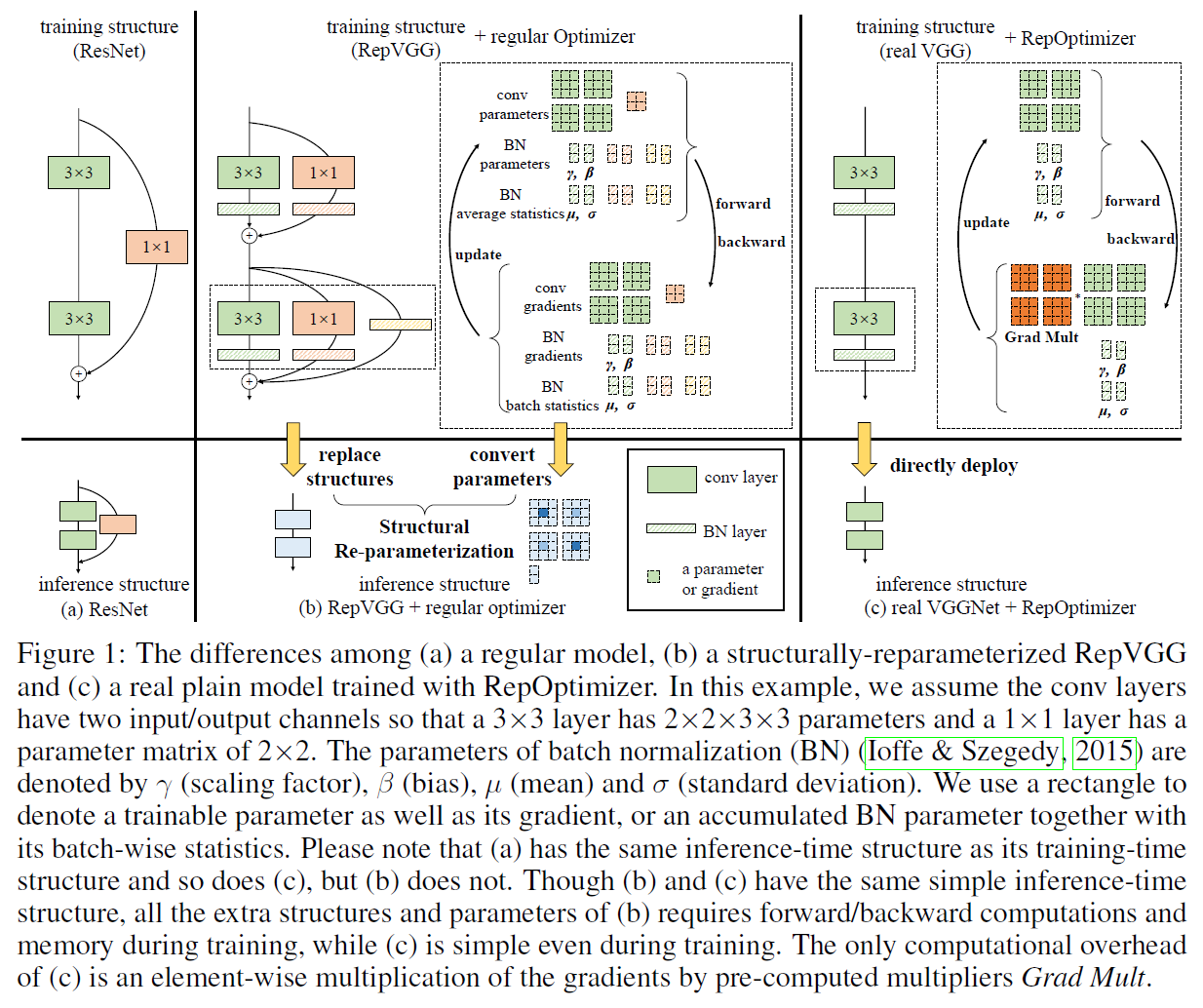
正常情况下,参数的更新规则是$W \leftarrow W - \lambda \frac{\partial L}{\partial W}$,其中$\lambda$为学习率,如果引入了Grad Mult,那么参数的更新规则变为$W \leftarrow W - \lambda * \text{GradMult} * \frac{\partial L}{\partial W}$,其中$W,\text{GradMult},\frac{\partial L}{\partial W}$三者的维度都是一样的。Grad Mult就是梯度重参数化的一种具体实现。简而言之,存在如下等效关系:
\[\text{CSLA}模块+常规优化器=单一算子+带\text{GR}的优化器 \tag{1}\]式(1)的证明见附录A。为了简化,这里只考虑两个卷积和两个常数因子的情况,设$\alpha_A,\alpha_B$为两个常数因子,$W^{(A)},W^{(B)}$为两个形状相同的卷积核,$X,Y$分别为输入和输出,$*$表示卷积运算,则CSLA模块的计算流程可表示为:
\[Y_{CSLA} = \alpha_A (X * W^{(A)}) + \alpha_B (X * W^{(B)})\]对于GR的对应形式,我们直接训练参数为$W’$的目标结构,使得:
\[Y_{GR} = X * W'\]设$i$为训练迭代次数,只要遵循以下两条规则,我们可以保证对任意$i \geqslant 0$,都有:
\[Y^{(i)}_{CSLA} = Y^{(i)}_{GR}\]👉规则一:初始化规则。
$W’$应该被初始化为:
\[W'^{(0)} \leftarrow \alpha_A W^{(A)(0)}+\alpha_B W^{(B)(0)}\]👉规则二:迭代规则。
当CSLA对应模型采用常规的梯度下降法进行更新时,GR对应模型的梯度应乘以$(\alpha_A^2+\alpha_B^2)$。设$L$为目标函数,$\lambda$为学习率,则参数更新规则为:
\[W'^{(i+1)} \leftarrow W'^{(i)} - \lambda (\alpha_A^2 + \alpha_B^2) \frac{\partial L}{\partial W'^{(i)}} \tag{2}\]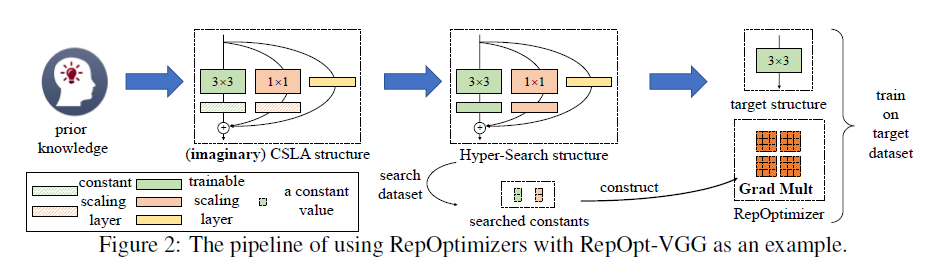
如Fig2所示,对于RepOpt-VGG,我们通过如下方式实例化CSLA结构:将RepVGG block中$3\times 3$以及$1 \times 1$卷积后的BatchNorm替换为逐通道的常数缩放层(即每个通道都对应一个常数缩放因子),而对于identity分支,则将BatchNorm替换为可训练的逐通道缩放层(即每个通道对应的缩放因子不再是常数,而是可训练的)。这样,我们就保证了CSLA中每个分支至多包含一个线性可训练算子。
这里我们给出对应单个$3\times 3$卷积的Grad Mult的构造方式。设$C$为通道数,$s,t\in \mathbb{R}^C$分别为CSLA模块中$3\times 3$分支和$1\times 1$分支的逐通道常数缩放因子(因此$s$和$t$都是长度为$C$的向量),则Grad Mult $M^{C\times C \times 3 \times 3}$可定义为(输入和输出通道数都是$C$):
\[M_{c,d,p,q} = \begin{cases} 1+s_c^2 + t_c^2 & \text{if } c=d,p=2 \text{ and } q=2, \\ s_c^2+t_c^2 & \text{if } c\neq d,p=2 \text{ and } q=2, \\ s_c^2 & \text{elsewise.} \end{cases} \tag{3}\]这里解释下式(3)。式(3)是Grad Mult的构造方式,对应的CSLA模块是3个分支的结构($3\times 3$卷积、$1\times 1$卷积和identity分支)。在这个示例中,Grad Mult的维度和$3\times 3$卷积是一样的,如下图所示:
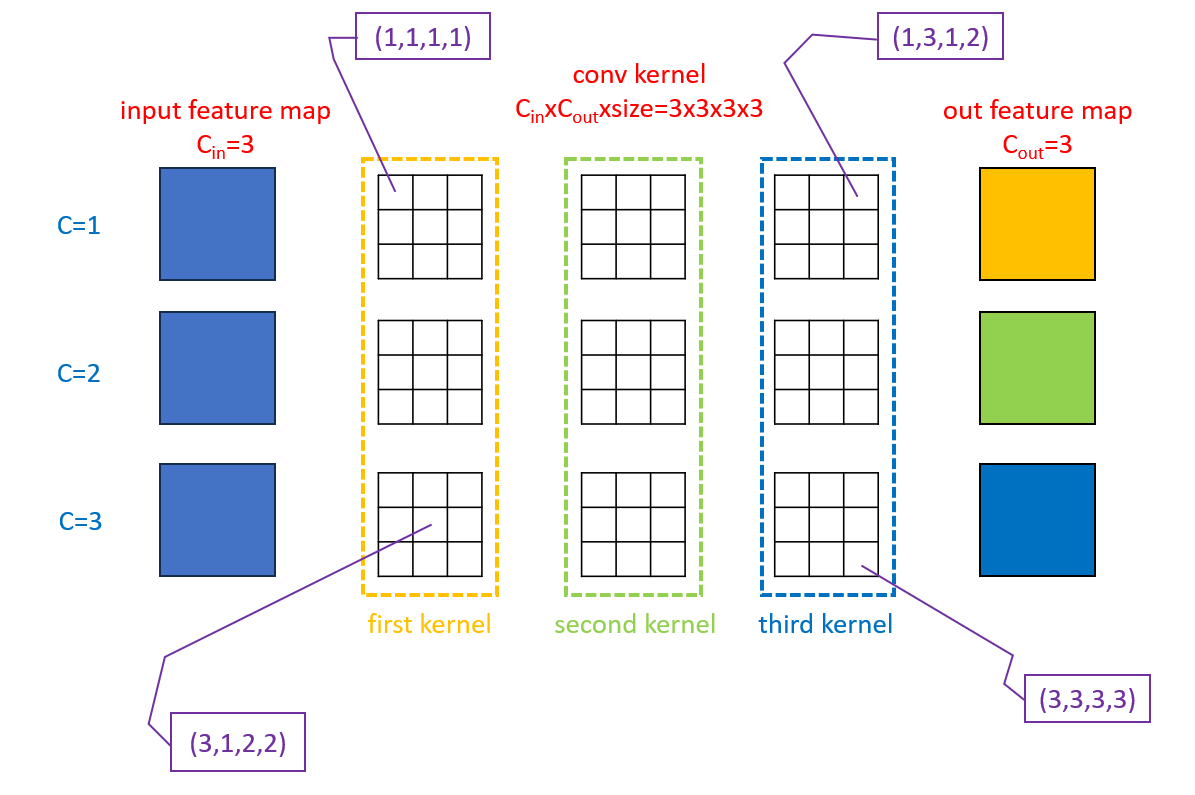
$M_{c,d,p,q}$中的$c$是输入通道的索引,$d$是输出通道的索引,$(p,q)$表示单个$3\times 3$网格的坐标。
对于CSLA模块中的$3\times 3$分支,常数因子为$s_1,s_2,s_3$,每个网格中都是有参数的,如下图所示:
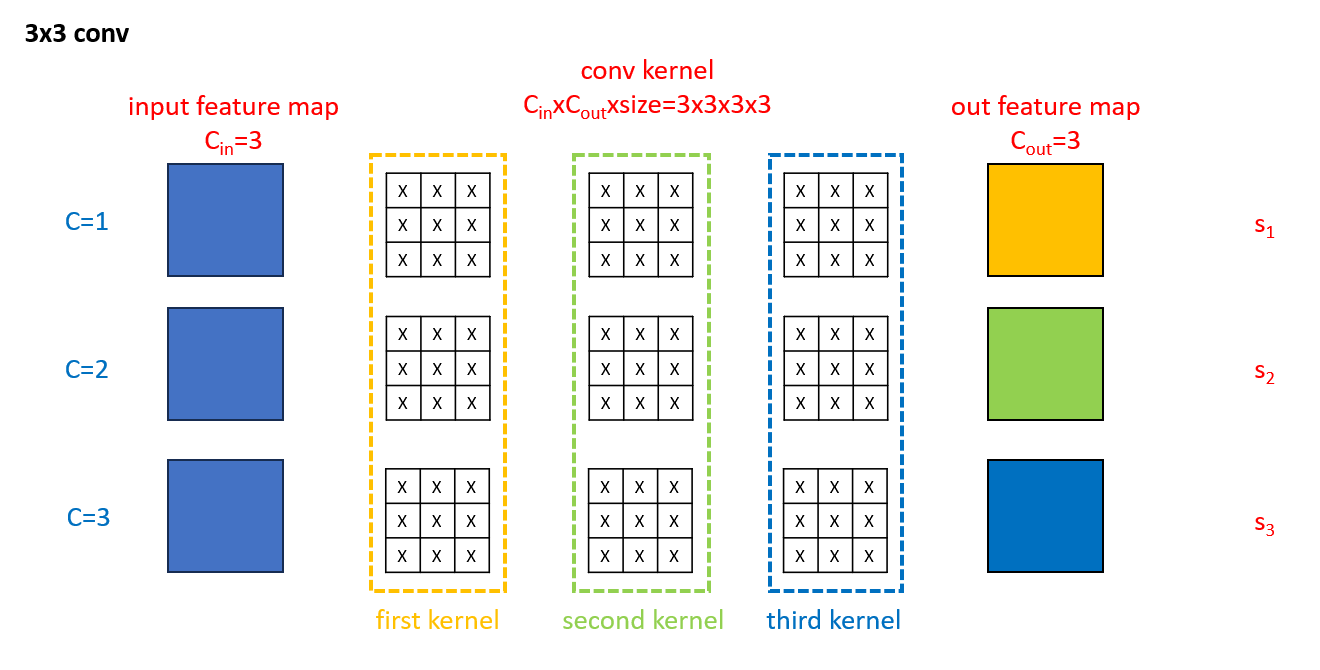
对于CSLA模块中的$1 \times 1$分支,常数因子为$t_1,t_2,t_3$,将其扩展到$3\times 3$大小后,只有$p=q=2$的位置(即中心位置)上才是有参数的,如下图所示:
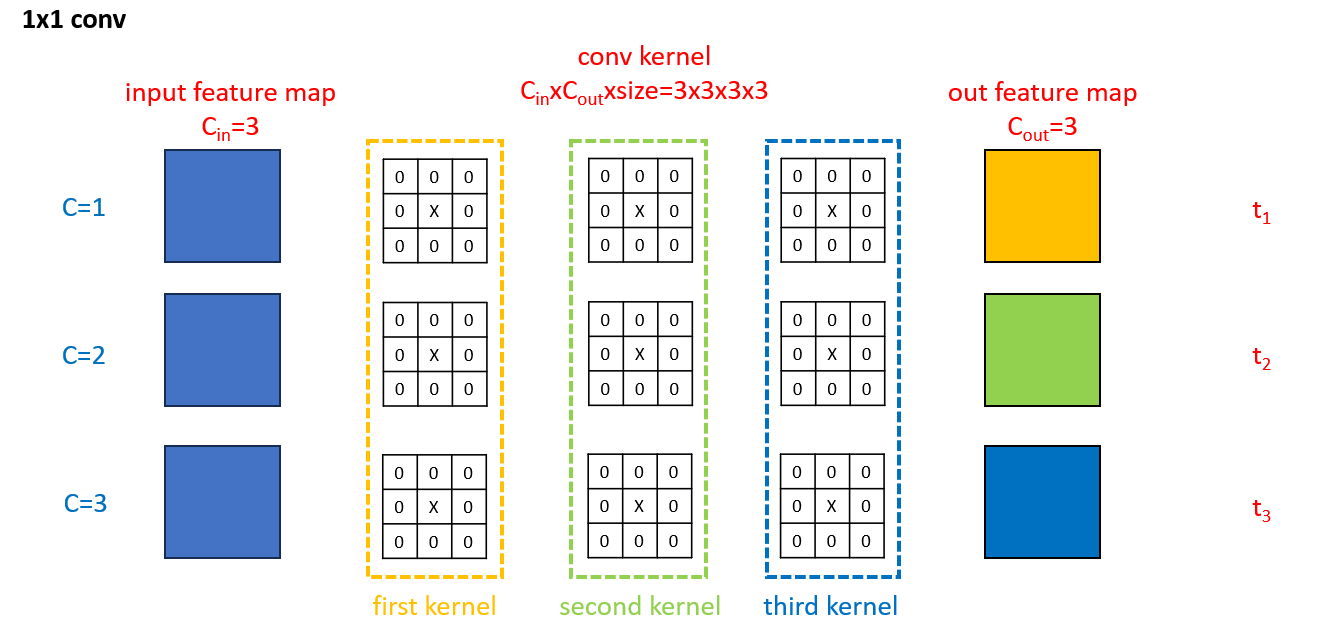
对于CSLA模块中的identity分支,常数因子可认为是$1,1,1$,将其扩展到$3\times 3$大小后,只有$c=d$且$p=q=2$的位置上才有参数,如下图所示:
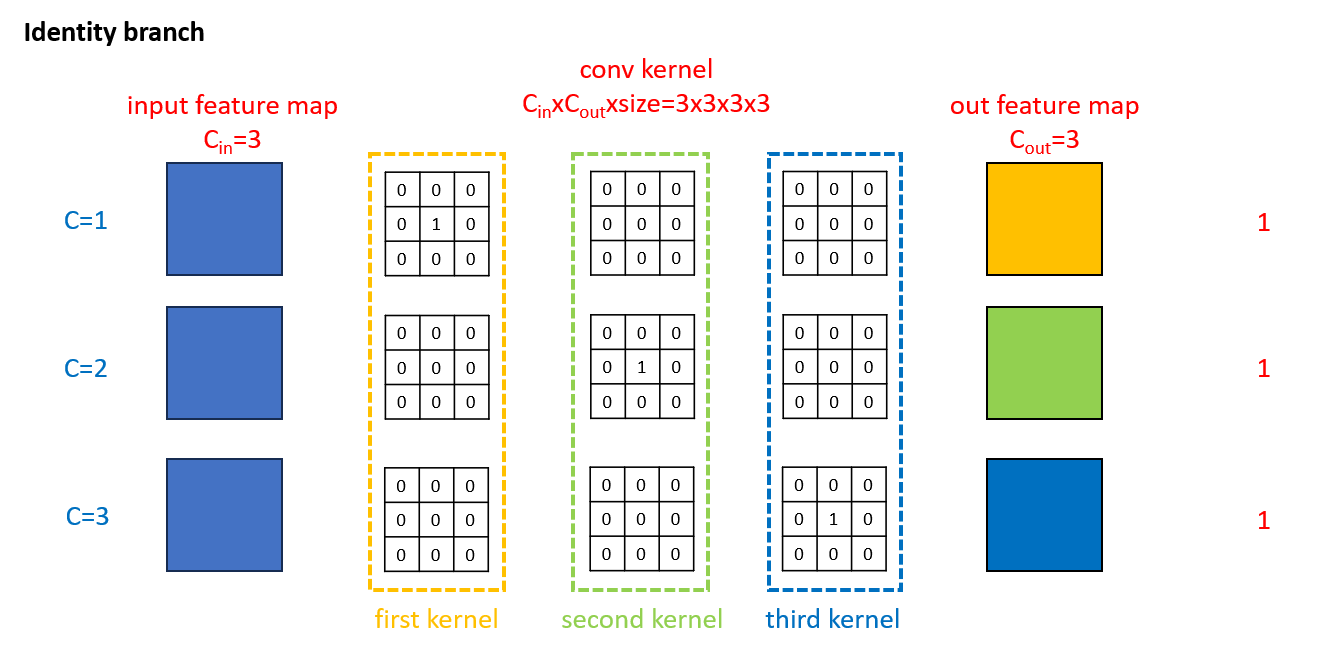
因此,在式(3)中,对于$c=d$且$p=q=2$的位置,3个分支均有参数,因此Grad Mult在这些位置上的值为$1+s_c^2+t_c^2$;对于$c\neq d$且$p=q=2$的位置,只有$3\times 3$分支和$1\times 1$分支是有参数的,因此Grad Mult在这些位置上的值为$s_c^2+t_c^2$;对于剩下的其他位置,只有$3\times 3$分支有参数,因此Grad Mult在这些位置上的值为$s_c^2$。
那么我们该如何获得常数缩放因子$s$和$t$呢?
3.3.OBTAIN THE HYPER-PARAMETERS OF REPOPTIMIZER VIA HYPER-SEARCH
在第3部分一开始,我们提到了RepOptimizers的设计是基于模型的,也就是说,本篇论文的核心思想是基于一个具有多分支结构的先验网络模型,通过推导等价的梯度重参数化规则,将其简化为一个plain network。那么这里我们选择的具有多分支结构的先验网络模型是RepVGG。在RepVGG block中,有$3\times 3$、$1\times 1$和identity三个分支,因此其对应抽象出来的CSLA模块也是$3\times 3$、$1\times 1$和identity三个分支。也就是说,CSLA模块的具体结构是基于先验网络模型的。
对于RepOptimizers,其本质就是普通优化器(比如SGD或Adam等)加上梯度重参数化规则(比如Grad Mult等)。
到这里,我们已经定义好了CSLA模块的结构,也证明了Grad Mult的有效性。下一步就是确定RepOptimizers中的超参数,即Grad Mult中常数因子的值。
这里,我们提出一种新方法,将优化器的超参数与一个辅助模型中的可训练参数关联起来并进行搜索,我们将这种方法称为HS(Hyper-Search)。具体来说,就是使用CSLA模块构建一个网络(即HS模型),这个HS模型是和RepOpt-VGG的结构基本是一一对应的,主要区别就是把RepOpt-VGG中的blcok替换为CSLA模块。需要注意的是,在这里,我们将CSLA模块中的常数因子替换为一个可训练的缩放因子,然后将HS模型在一个较小的数据集(如CIFAR-10)上进行训练。可训练缩放因子的最终值就是Grad Mult中超参数的值。注意,RepOpt-VGG中的每个算子(即每个$3\times 3$卷积层)都会对应一个自己的Grad Mult,这也是我们让HS模型和RepOpt-VGG结构上对应的一个目的。
3.4.TRAIN WITH REPOPTIMIZER
RepOpt-VGG的训练需遵循第3.2部分提到的初始化规则和迭代规则。
根据式(3),我们可以得到初始化规则的具体实现方式如下:
\[W'^{(0)}_{c,d,p,q} = \begin{cases} 1+s_c W^{(s)(0)}_{c,d,p,q} + t_c W^{(t)(0)}_{c,d,1,1} & \text{if } c=d,p=2 \text{ and } q=2, \\ s_c W^{(s)(0)}_{c,d,p,q} + t_c W^{(t)(0)}_{c,d,1,1} & \text{if } c\neq d,p=2 \text{ and } q=2, \\ s_c W^{(s)(0)}_{c,d,p,q} & \text{elsewise.} \end{cases} \tag{4}\]其中$W^{(s)(0)}\in \mathbb{R}^{C \times C \times 3 \times 3}, \ W^{(t)(0)} \in \mathbb{R}^{C \times C \times 1 \times 1}$分别表示随机初始化的$3\times 3$卷积和$1\times 1$卷积,因此式(4)中$W^{(t)(0)}$的下标索引是$c,d,1,1$。
4.EXPERIMENTS
4.1.REPOPTIMERS FOR IMAGENET CLASSIFICATION
我们选择RepVGG作为baseline。我们通过以下方式验证RepOptimizers的有效性:RepOpt-VGG在精度上与RepVGG非常接近,同时具有更快的训练速度和更低的内存开销;并且在性能上可以与当前最先进、精心设计的EfficientNets相当,甚至更优。作为一个更简单的示例,我们还为RepGhostNet(一个使用了结构重参数化的轻量级模型)设计了RepOptimizer,详见附录D。
RepGhostNet:Chengpeng Chen, Zichao Guo, Haien Zeng, Pengfei Xiong, and Jian Dong. Repghost: A hardware-efficient ghost module via re-parameterization. arXiv preprint arXiv:2211.06088, 2022.。
👉Architectural setup.

如表1所示,RepOpt-VGG的结构和RepVGG基本上是一一对应的,首先是一个步长为2的$3\times 3$卷积(表1中未列出),然后是4个stage,全都是$3\times 3$卷积,其中每个stage中的第一层步长为2。最后一个stage后面接全局平均池化和一个FC层(表1中未列出)。
表1中的每一行代表一个模型,以第一行为例,$\{4,6,16,1 \}$表示每个stage中包含的层数,$\{ 128, 256, 512, 2048 \}$表示每个stage中所用的通道数量。其中,B1模型对应RepVGG-B1,B2模型对应RepVGG-B2。
👉Training setup.
对于RepOpt-VGG和RepVGG在ImageNet上的训练,我们采用一致的的训练设置。我们用了8块GPU,每块GPU上设置batch size为32,输入分辨率为$224 \times 224$,对于学习率策略,warm-up持续5个epoch,初始学习率为0.1,cosine annealing持续120个epoch。对于数据扩展,我们使用了随机裁剪、左右翻转和RandAugment。label-smoothing系数设置为0.1。baseline模型使用常规的SGD优化器,RepOpt-VGG使用RepOptimizers,momentum设为0.9,weight decay设为$4 \times 10^{-5}$。我们在验证集上汇报了结果。
👉Hyper-Search (HS) setup.
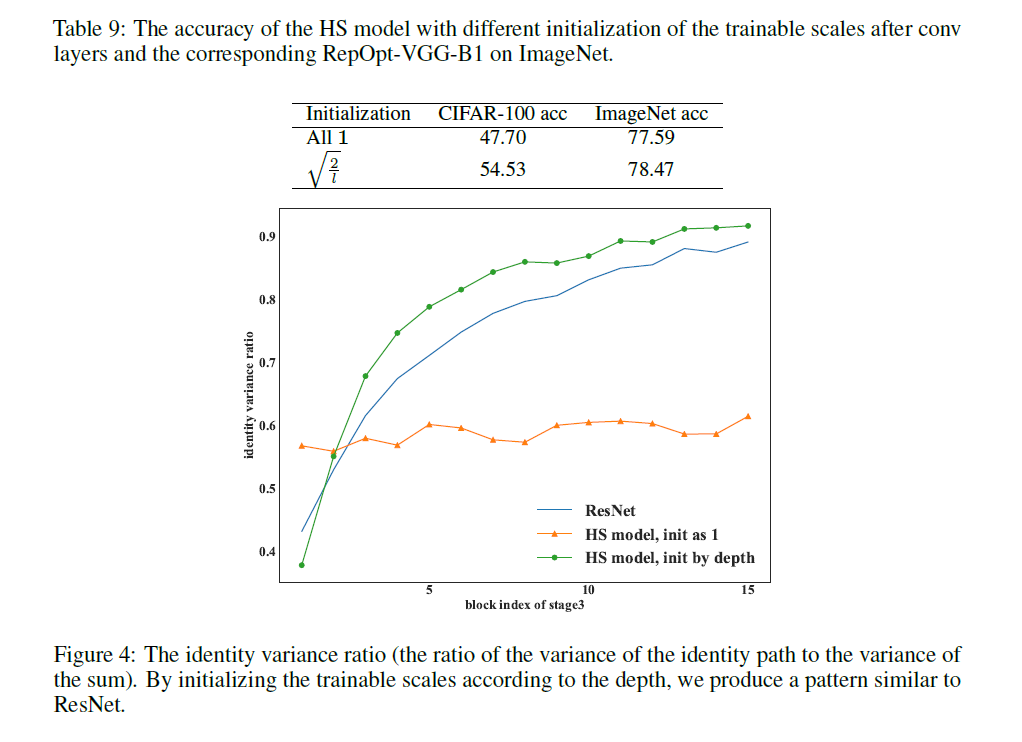
HS模型在CIFAR-100数据集上训练了240个epoch,仅使用了左右翻转和裁剪两种数据扩展方式,其训练成本很低。可训练缩放因子的初始化值依赖于其所在层数,假设$l$表示层的深度,比如每个stage的第一层有$l=1$,下一层有$l=2$,这些可训练缩放因子的初始化值为$\sqrt{\frac{2}{l}}$,关于初始化规则的讨论见附录B。
👉Comparisons with RepVGG.
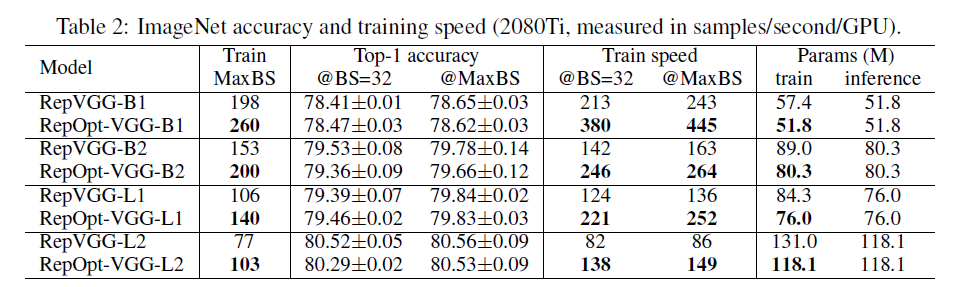
首先,我们测试了每块GPU所能支持的最大batch size,简记为MaxBS(maximum batch size),以衡量训练时的显存消耗并比较训练速度。具体来说,当batch size增加到MaxBS+1时,会在配备11GB显存的2080Ti GPU上触发OOM(Out Of Memory)错误。为了公平比较,我们使用相同的配备了8块2080Ti GPU的机器,使用同样的训练脚本,来测试模型的训练成本。我们在两种不同的batch size设置下测试了每个模型的训练速度,第一种情况是batch size均设置为32,第二种情况是batch size都设置为其各自对应的MaxBS。我们在这两种batch size设置下均将模型训练120个epoch。当增大batch size时,我们按比例线性放大学习率。每个模型重复训练三次,并报告最终精度的均值和标准差。实验结果见表2:
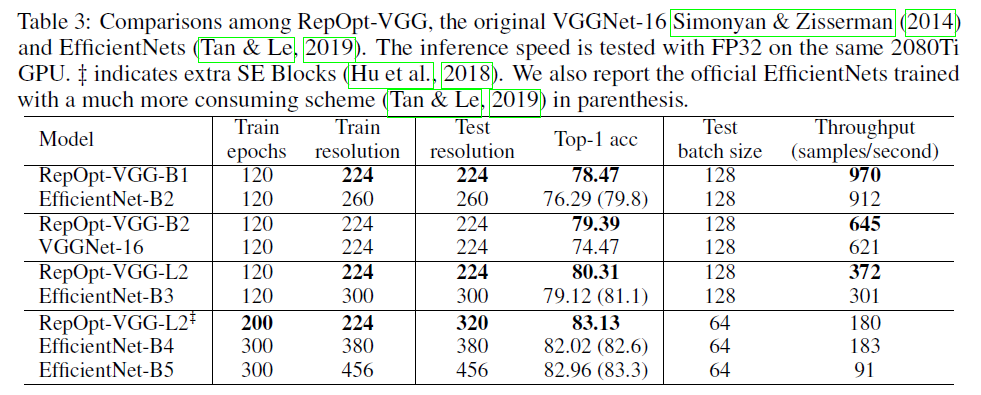
👉Comparisons with VGGNet-16 and EfficientNets.
4.2.ABLATION STUDIES
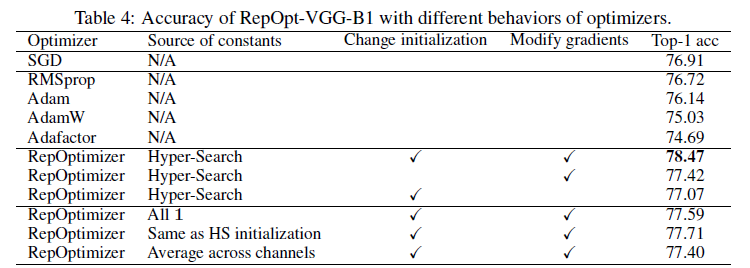
如表4所示,测试了RepOpt-VGG-B1使用不同优化器时的结果。
- “Source of constants”表示常数缩放因子。
- “N/A”表示该优化器不涉及常数缩放因子。
- “Hyper-Search”表示通过HS模型确定常数缩放因子。
- “All 1”表示将常数缩放因子都设置为1。
- “Same as HS initialization”表示将常数缩放因子设置为HS模型中可训练缩放因子的初始化值,即$\sqrt{\frac{2}{l}}$,详见第6.B.1部分。
- “Average across channels”表示将常数缩放因子设置为每一层内所有通道缩放因子的平均值。
- “Change initialization”表示RepOpt-VGG-B1是否按照式(4)的规则进行初始化。
- “Modify gradients”表示是否使用Grad Mult修改梯度。
4.3.REPOPTIMIZERS ARE MODEL-SPECIFIC BUT DATASET-AGNOSTIC

在表5中,”Search dataset”是HS模型搜索超参数所用的数据集。从表5可以看出,无论使用哪个超参数搜索数据集,最终对性能的影响并不大,说明RepOptimizers可能是模型相关,但与数据集无关。

从表6可以看出,HS模型在搜索数据集上的准确率并不能反映RepOpt-VGG在ImageNet数据集上的准确率。由于RepOpt-VGG是为ImageNet设计的,其包含5个步长为2的卷积层用于下采样。在CIFAR-100上训练其对应的HS模型似乎并不合理,因为CIFAR-100的输入分辨率仅为$32 \times 32$,这意味着最后两个stage的$3\times 3$卷积只能作用在$2\times 2$和$1 \times 1$的feature map上。正如预期那样,HS模型在CIFAR上的精度较低(54.53%),但其搜索得到的RepOptimizer在ImageNet上却表现良好。
当我们通过将原本5个下采样层重新配置为步长为1来降低CIFAR-100上HS模型的下采样比例时,HS模型的准确率提升了,但对应的RepOpt-VGG反而退化。这一现象进一步说明:被搜索到的常数因子是模型相关的,也就是说,RepOptimizers是模型相关的。原因在于,原始模型的总下采样比例为$32 \times$,而将某一层的步长改为1会得到一个总下采样比例为$16 \times$的HS模型,在这种不同下采样结构下搜索得到的常数因子,自然无法很好地适配原始$32 \times $下采样的模型。
如表7所示,在COCO检测任务和Cityscapes分割任务上,RepOpt-VGG的性能和RepVGG相当。

4.4.REPOPTIMIZERS FOR EASY QUANTIZATION
对结构重参数化模型进行量化往往会导致显著的精度下降。例如,如表8所示,使用简单的PTQ(Post-Training Quantization)方法将RepVGG-B1量化为INT8,会使top-1准确率下降到约54.55%。相比之下,直接对RepOpt-VGG进行量化仅会带来约2.5%的精度损失。

我们进一步研究了RepOpt-VGG-B1和RepVGG-B1在同一位置卷积核的参数分布,如Fig3所示,卷积核参数分布明显不同。从表8可以看出,标准差相差约4倍。
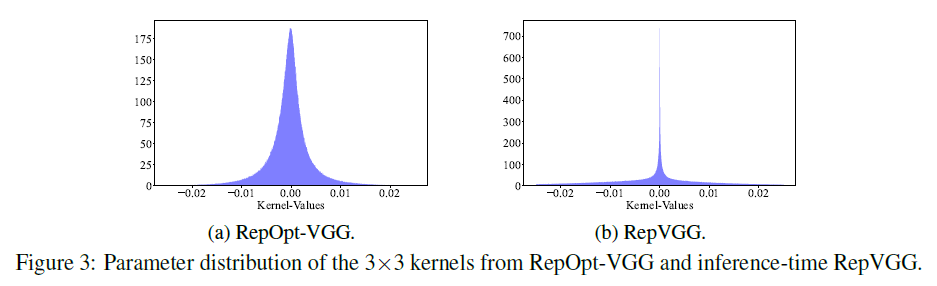
在附录C中,我们揭示了:结构转换过程会导致不利于量化的参数分布,而RepOptimizer则天然的解决了这一问题,因为它在训练过程中完全不需要进行任何结构转换。
5.CONCLUSIONS AND LIMITATIONS
不再赘述。
6.APPENDIX
6.A.PROOF OF CSLA = GR
如前文所述,CSLA结构中,每个分支仅包含一个可微的线性算子及其可训练参数(例如卷积、全连接层、缩放层),并且不包含任何训练阶段的非线性算子,例如BatchNorm或Dropout。我们注意到,使用常规SGD训练一个CSLA模块,与使用经过修改梯度训练一个单一算子在训练行为上是等价的。
我们从一个简单的情形开始,CSLA模块包含两个并行的、形状相同的卷积核,并且每个卷积核都由一个常数因子进行缩放。设$\alpha_A,\alpha_B$是两个常数因子,$W^{(A)},W^{(B)}$是两个卷积核,$X,Y$分别为输入和输出,$*$表示卷积运算。则CSLA模块的计算为:
\[Y_{CSLA} = \alpha_A (X * W^{(A)}) + \alpha_B (X * W^{(B)})\]对于GR对应形式,我们直接训练由$W’$参数化的目标结构,使得:
\[Y_{GR} = X * W'\]设目标函数为$L$,训练迭代次数为$i$,$W$的梯度为$\frac{\partial L}{\partial W}$,而$F(\frac{\partial L}{\partial W’})$表示对GR对应结构中梯度所施加的任意变换。
👉命题:
存在一个仅由$\alpha_A$和$\alpha_B$决定的变换$F$,使得用$F(\frac{\partial L}{\partial W’})$来更新$W’$,就可以保证:
\[Y_{CSLA}^{(i)} = Y_{GR}^{(i)} \quad \forall i \geqslant 0 \tag{5}\]👉证明:
利用卷积的可加性和齐次性,我们需要保证:
\[\alpha_A W^{(A)(i)} + \alpha_B W^{(B)(i)} = W'^{(i)} \quad \forall i \geqslant 0 \tag{6}\]在第0次迭代时,通过正确初始化可以保证等价性:设$W^{(A)(0)},W^{(B)(0)}$是任意初始化值,则初始条件为:
\[W'^{(0)} = \alpha_A W^{(A)(0)} + \alpha_B W^{(B)(0)} \tag{7}\]因此有:
\[Y_{CSLA}^{(0)} = Y_{GR}^{(0)} \tag{8}\]设$\lambda$为学习率,参数的常规更新规则为:
\[W^{(i+1)}=W^{(i)} - \lambda \frac{\partial L}{\partial W^{(i)}} \quad \forall i \geqslant 0 \tag{9}\]对于CSLA模块,则有:
\[\alpha_A W^{(A)(i+1)} + \alpha_B W^{(B)(i+1)} = \alpha_A W^{(A)(i)} + \alpha_B W^{(B)(i)} - \lambda \left( \alpha_A \frac{\partial L}{\partial W^{(A)(i)}} + \alpha_B \frac{\partial L}{\partial W^{(B)(i)}} \right) \tag{10}\]我们使用$F(\frac{\partial L}{\partial W’})$来更新$W’$,即:
\[W'^{(i+1)} = W'^{(i)} - \lambda F (\frac{\partial L}{\partial W'^{(i)}}) \tag{11}\]假设第$i$次迭代等价性成立,根据式(6)、式(10)和式(11),我们必需满足:
\[F(\frac{\partial L}{\partial W'^{(i)}}) = \alpha_A \frac{\partial L}{\partial W^{(A)(i)}} + \alpha_B \frac{\partial L}{\partial W^{(B)(i)}} \tag{12}\]通过式(6)可得:
\[\frac{\partial W'^{(i)}}{\partial W^{(A)(i)}} = \alpha_A, \quad \frac{ \partial W'^{(i)}}{\partial W^{(B)(i)}} = \alpha_B \tag{13}\]因此,我们可以得到:
\[\begin{align*} F(\frac{\partial L}{\partial W'^{(i)}}) &= \alpha_A \frac{\partial L}{\partial W'^{(i)}} \frac{\partial W'^{(i)}}{\partial W^{(A)(i)}} + \alpha_B \frac{\partial L}{\partial W'^{(i)}} \frac{\partial W'^{(i)}}{\partial W^{(B)(i)}} \\&= (\alpha_A^2+\alpha_B^2) \frac{\partial L}{\partial W'^{(i)}} \end{align*} \tag{14}\]至此,我们就得到了梯度转换公式。
通过式(14),可保证$\alpha_A W^{(A)(i+1)} + \alpha_B W^{(B)(i+1)} = W’^{(i+1)}$。再结合式(8)和数学归纳法,可证明对所有$i\geqslant 0$等价成立。
我们便是利用这些常数因子来构建Grad Mult。这里的$(\alpha_A^2+\alpha_B^2)$就是Grad Mult。
6.B.DISCUSSIONS OF THE INITIALIZATION
6.B.1.INITIALIZATION OF THE HS MODEL
HS模型中的可训练缩放因子会根据层的深度进行初始化,设$l$表示层的深度,即每个stage中第一个包含identity分支的block记为$l=1$,下一个为$l=2$,后面以此类推,则卷积层之后的可训练缩放因子(在文中被记为$s,t$)被初始化为$\sqrt{\frac{2}{l}}$。而identity分支中的可训练因子全部初始化为1。
这里对作者的理论分析不再详述,仅列出作者的实验结果:
6.B.2.INITIALIZATION OF THE TARGET MODEL
需要注意的是,在目标数据集上训练的目标模型,其初始化方式与HS模型中卷积核的初始取值是相互独立的。换句话说,从HS模型中继承的唯一信息只有已经训练好的缩放因子,而不需要记录HS模型的任何其他初始信息。
6.C.DISCUSSIONS OF THE QUANTIZATION
6.C.1.QUANTIZATION RESULTS
对结构重参数化网络进行量化可能会导致显著的精度下降,从而限制其在实际部署中的应用。例如,采用简单的PTQ(Post-Training Quantization)方法将RepVGG-B1直接量化为INT8,会使top-1准确率下降到约54.55%,使模型几乎完全不可用。更糟糕的是,由于重参数化后的RepVGG不再包含BN层,而重新加入BN层又容易损害性能,使用QAT(Quantization-Aware Training)进行微调也并不容易实现。目前,对结构重参数化模型的量化仍然是一个尚未完全解决的问题,可能需要定制化的量化策略才能应对。
相比之下,RepOpt-VGG在推理阶段具有与RepVGG相同的结构,但在训练过程中完全避免了任何结构转换,因此天然地解决了量化问题。例如,使用PyTorch官方库(torch.quantization)提供的简单PTQ方法即可将RepOpt-VGG-B1量化为INT8,且精度仅下降2.58%(从78.47%降到75.89%)。而采用简单的QAT方法,仅经过10个epoch的微调,就能将精度差距进一步缩小到0.23%(从78.47%降到78.24%)。

6.C.2.INVESTIGATION INTO PARAMETER DISTRIBUTION
接着在第4.4部分对Fig3和表8的分析,我们进一步研究了RepVGG出现如此高方差参数分布的来源。由于训练阶段的RepVGG block会经历两次变换才能最终变成一个单一的$3\times 3$卷积层,即:1)融合BN层;2)合并多分支。因此我们分别评估了这两种变换对参数分布的影响。我们分别统计并展示了卷积核中心位置与周围位置(即$3\times 3$矩阵除中心外的八个位置)参数的标准差,详见Fig5和表11。
在某个卷积层中,如果权重参数分布的方差大,那就意味着参数值分布很分散,非常不利于量化,并且也会影响训练稳定性。
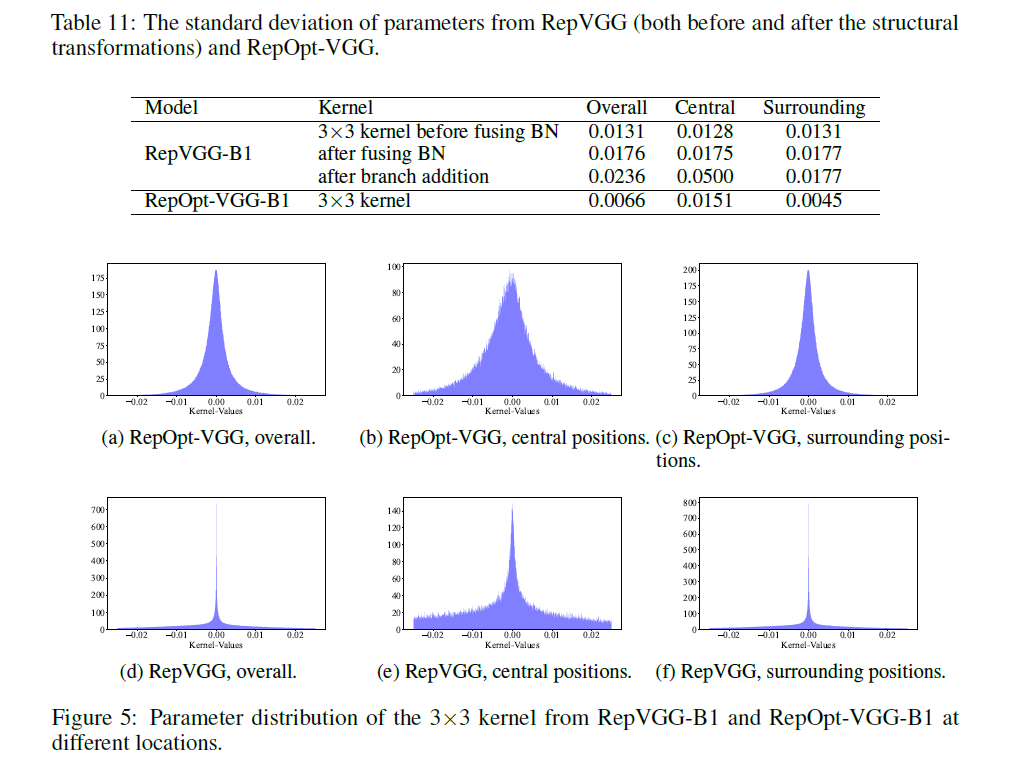
总结来说,相比结构重参数化,梯度重参数化的一大优势在于:能够在不进行结构转换的情况下完成模型训练,这不仅提升了效率,也显著改善了量化性能。
6.D.GENERALIZING TO REPGHOSTNET
验证RepOptimizer在RepGhostNet上的有效性。不再详述。

6.E.RUN-TIME ANALYSIS OF SEARCHED SCALES
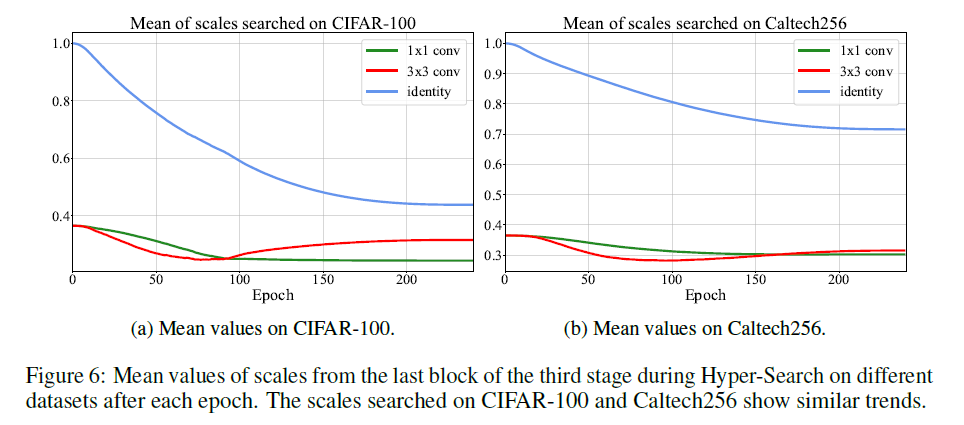
在Fig6中,我们绘制了在不同HS数据集上搜索得到的缩放因子在每个epoch之后的平均值。如Fig6所示,在两个显著不同的数据集上搜索得到的缩放因子呈现出相似的变化趋势,这进一步支持了RepOptimizer是模型相关但与数据集无关这一结论。
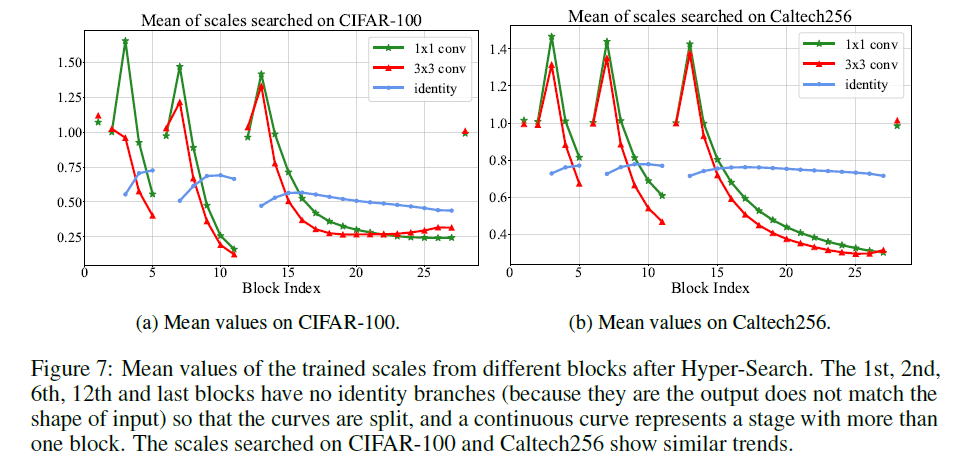
在Fig7中,我们展示了在不同HS数据集,最后一个epoch之后,不同block的缩放因子的平均值,以此来探寻缩放因子如何随着网络深度变化。如Fig7所示,在两个不同数据集上搜索得到的RepOptimizer超参数呈现出相似的模式:$1\times 1$分支和$3\times 3$分支的缩放因子具有相似的平均值,并且在每个stage的起始位置较大;随着深度增加,identity分支的缩放因子平均值变化并不显著。
7.原文链接
👽RE-PARAMETERIZING YOUR OPTIMIZERS RATHER THAN ARCHITECTURES
