本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.为什么需要数学基础?
要想成为一名优秀的数据科学家,以下三方面的知识必不可少:
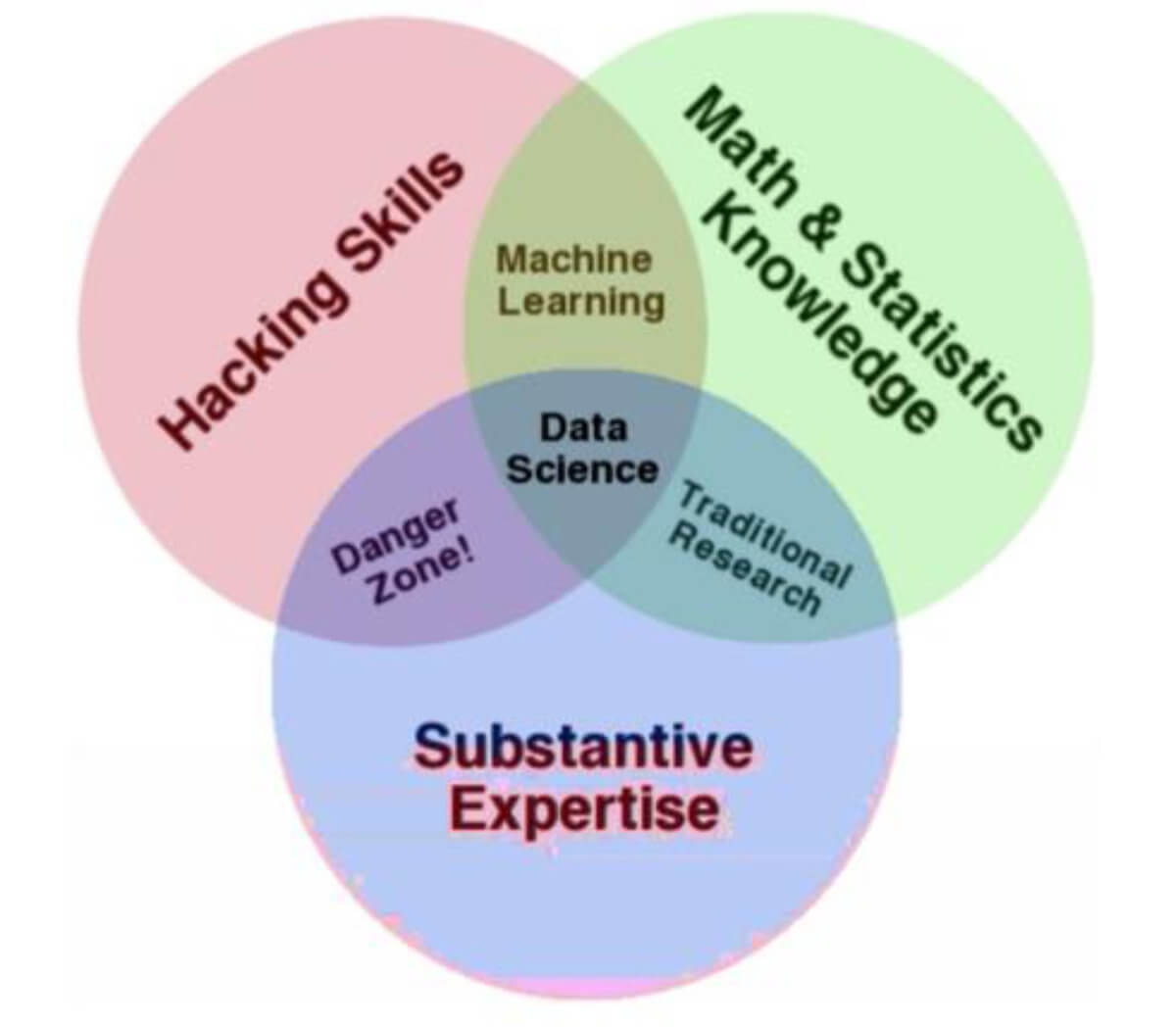 并且个人认为机器学习的本质其实就是数学,所以,有个扎实的数学基础至关重要。
并且个人认为机器学习的本质其实就是数学,所以,有个扎实的数学基础至关重要。
2.机器学习的分类
但是在开始我们的数学之旅之前,我们先了解一下机器学习的一些基础知识。
机器学习大体上可以分为4类。
2.1.有监督学习
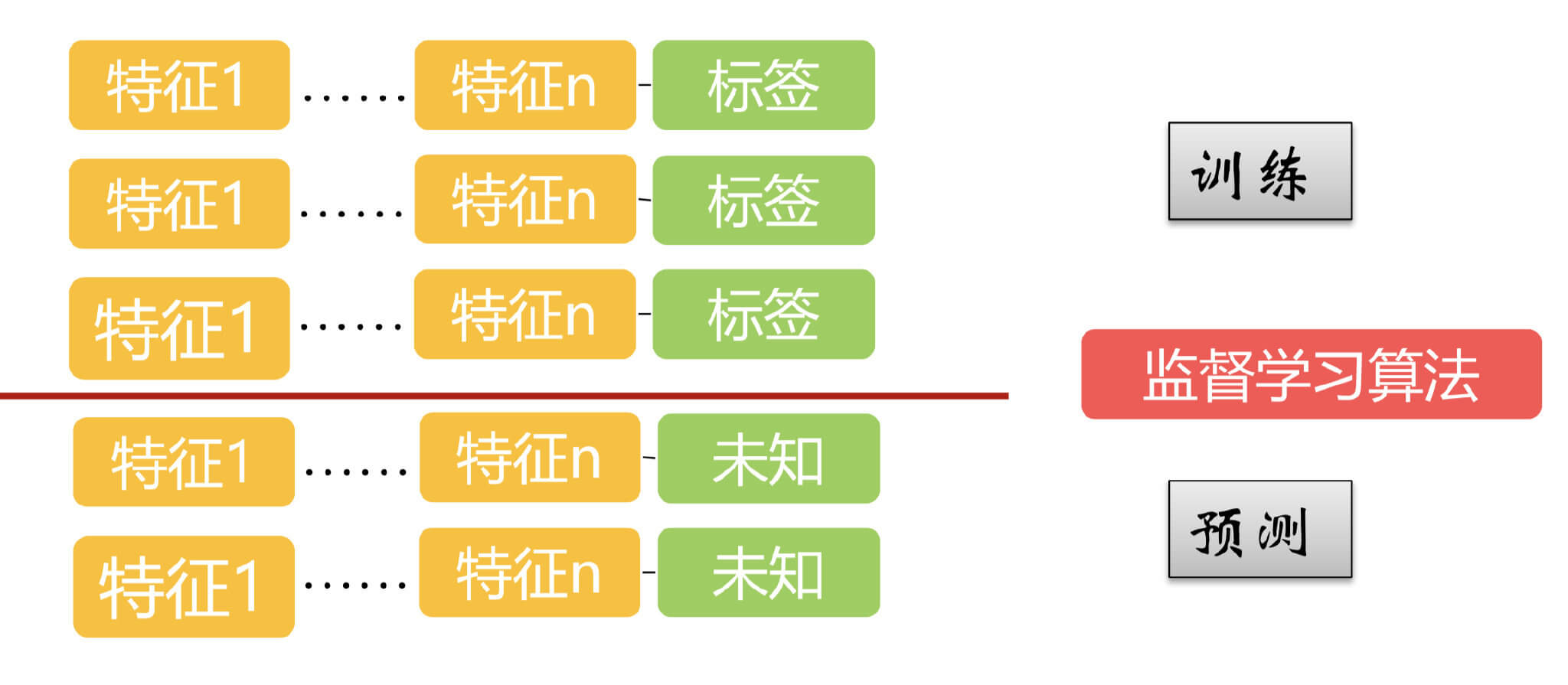 在有监督学习中,训练集都是有label的,测试集都是没有label的。常见的分类预测和回归分析都属于有监督学习,但是并不绝对。
在有监督学习中,训练集都是有label的,测试集都是没有label的。常见的分类预测和回归分析都属于有监督学习,但是并不绝对。
2.2.半监督学习
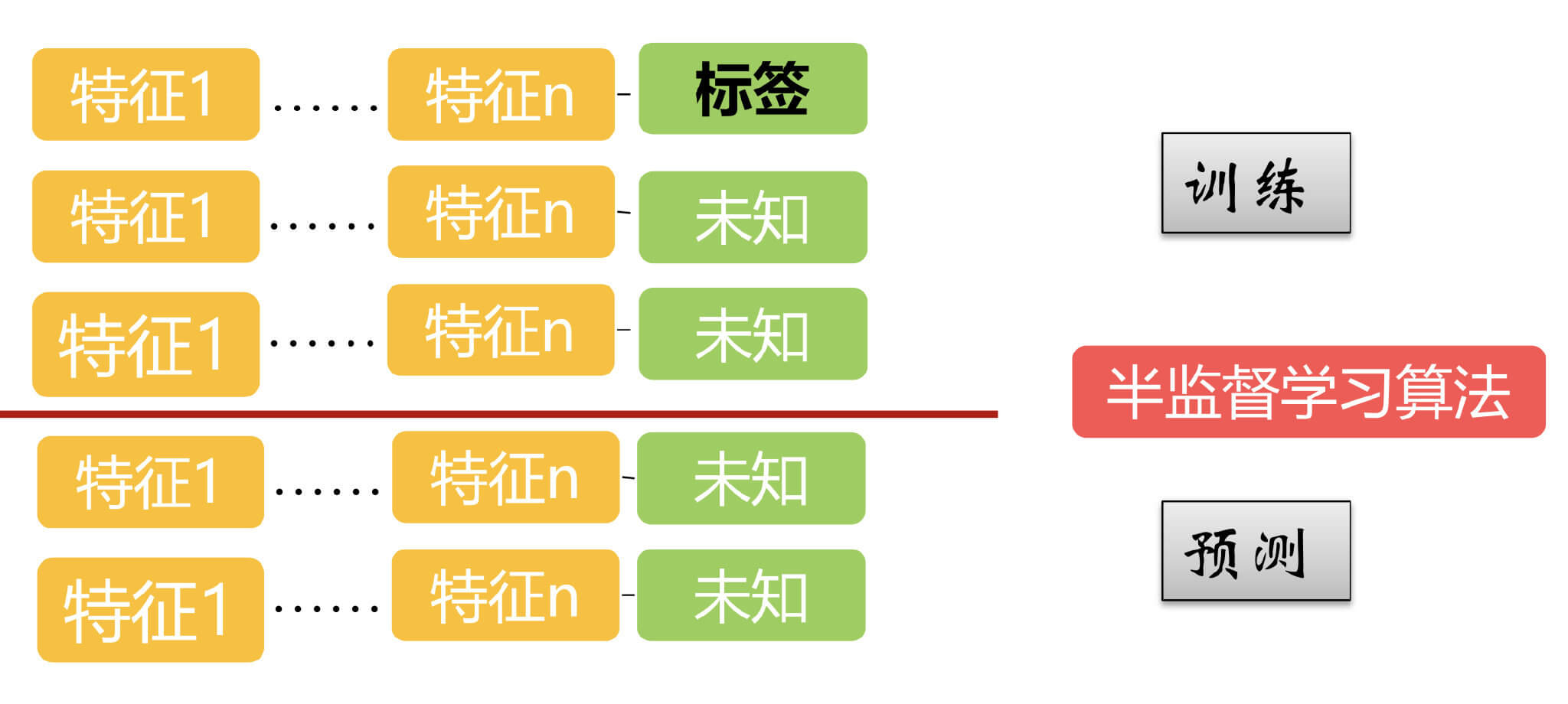 对于半监督学习,训练集中一部分样本有label,一部分样本没有label,测试集当然都是没有label的。
对于半监督学习,训练集中一部分样本有label,一部分样本没有label,测试集当然都是没有label的。
2.3.无监督学习
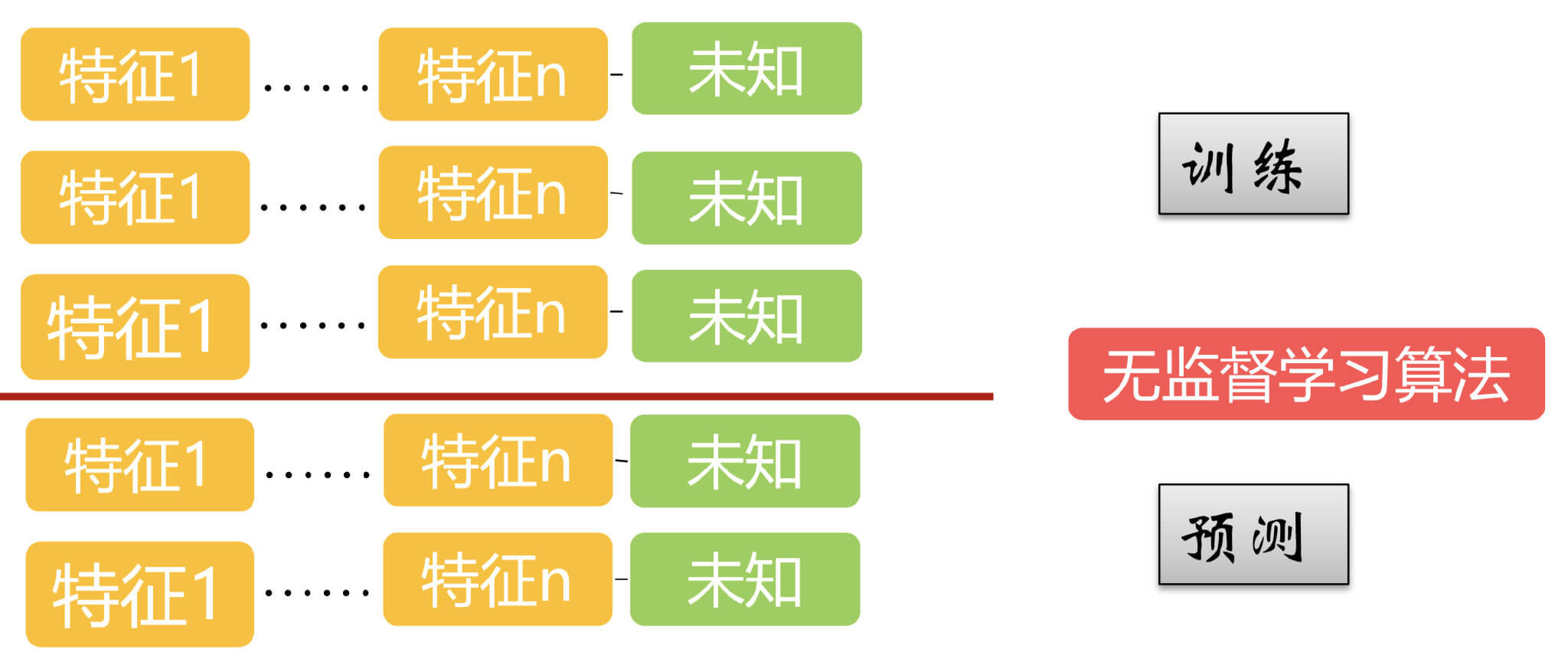 无监督学习中,训练集和测试集的数据都是没有标签的。比如聚类和关联规则。
无监督学习中,训练集和测试集的数据都是没有标签的。比如聚类和关联规则。
关于聚类,这里多说两句,在工程实际应用中,无监督学习通常人为聚类,按照个人对业务的理解。这也对应了第一节中提到的,专业知识也是一个优秀的数据科学家所必不可少的。
2.4.强化学习
强化学习(Reinforcement Learning,RL)包含四个要素:agent,environment,action,reward。其中,有环境的反馈很重要,即reward。
RL会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。应用领域:无人车;AlphaGo等等。
常见的强化学习:Q-learning;时间差学习等。
3.RL与有监督学习、无监督学习的比较
- RL是一个闭环。
- 有监督学习训练集中每一个样本的特征可以视为是对该Situation(或者说是Agent)的描述,而其label可以视为是应该执行的正确的action。但RL中,agent的action不一定正确。
- 无监督学习的目的是从一堆未标记样本中发现隐藏的结构,而RL的目的是最大化reward。
- RL不同之处总结:
- 其中没有监督者,只有一个reward信号;
- 反馈是延迟的,不是立即生成的;
- 时间在RL中具有重要的意义;
- agent的行为会影响之后一系列的data。
4.关于算法的选择
一张很经典的图帮助你更好的选择算法。
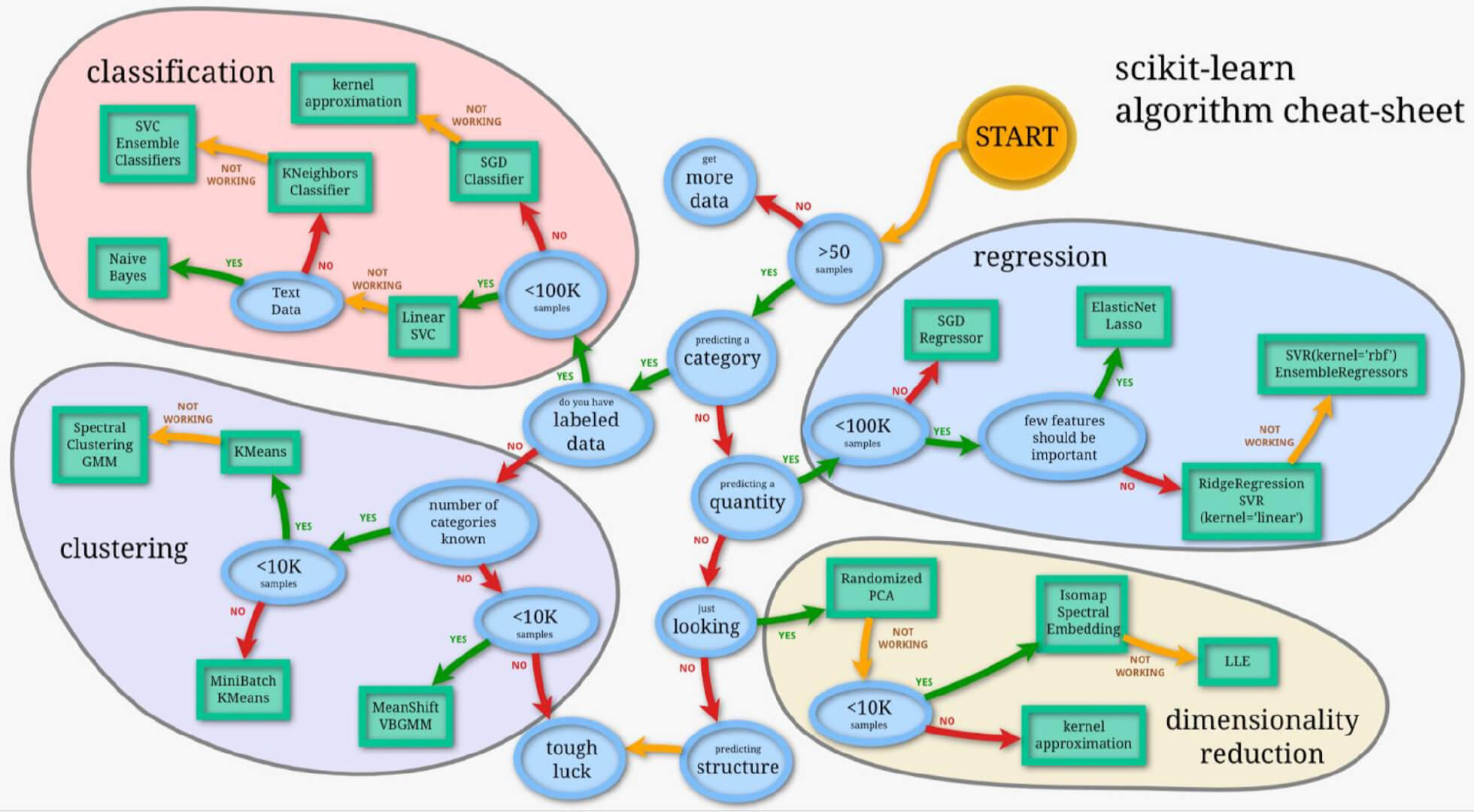 当然这都不是绝对,随着自己对算法的了解逐渐深入,针对哪种问题选择何种算法,自己心里应该都是有所权衡的。
当然这都不是绝对,随着自己对算法的了解逐渐深入,针对哪种问题选择何种算法,自己心里应该都是有所权衡的。
