本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.csv数据
1.1.读取csv数据
假设有csv数据demo.csv,内容如下:
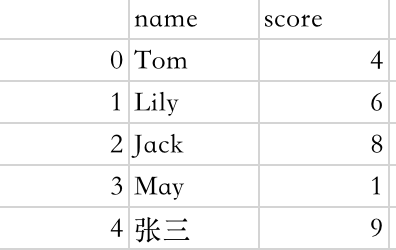
👉方法一:
1
2
with open('demo.csv','r') as f:
print(f.read())
输出见下:

如果csv中有的中文无法正确识别,可加上encoding='UTF-8'。
但是上述读入csv的结果输出,不方便查看与操作(列未对齐),可引入dataframe格式。
👉方法二:
1
df=pandas.read_csv('demo.csv')
输出结果为:

可以看出结果中多出了一列,即第一列,为行号。
1.2.抽取csv中的数据
👉方法一:
df[0]、df[1]均报错,因为不存在名字为0或1的列,[]里应该为列名,比如:df['name'],输出为:

df[0:3]输出第0、1、2行的数据,df[1:3]输出第1、2行的数据。例如df[0:3]的输出见下:
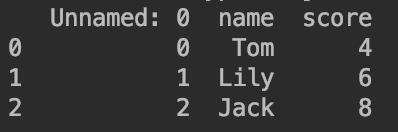
👉方法二:
.loc通过标签选取,用法为.loc[rows,cols],如果只有一个值,默认是行。一些常规用法见下:
df.loc[0]输出第0行的数据。df.loc[0:3]输出第0、1、2、3行的数据。⚠️注意和df[0:3]区分,df[0:3]中的[0:3]为一个列表,所以输出的是第0、1、2行的数据。但是df.loc[0:3]中[0:3]指的是具体的行号,即第0、1、2、3行。df.loc[0,'name'],df.loc[0:3,'name']df.loc[0,'name':'score'],df.loc[0:3,'name':'score']
👉方法三:
.iloc用位置选取元素,区别于.loc用标签选取。例如:df.iloc[0:3,0:2]输出第0、1、2行且第0、1列的数据,即:
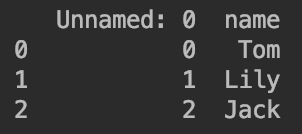
其中,df.iloc[0,1]为Tom。df.iloc[[0,2,4]]输出第0、2、4行的数据。
2.Excel数据
和读取csv文件一样,使用pandas包读取excel文件,以xls格式的数据为例(其他格式例如xlsx也可以):
1
df_xls=pandas.read_excel('demo.xls')
输出形式和操作与处理csv数据一样,不再赘述。
