本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.处理JSON格式数据
👉方法一:
采用open的方式:
1
2
3
with open ('jd.json','r') as f:
jd=f.read()
print(jd)
结果见下:
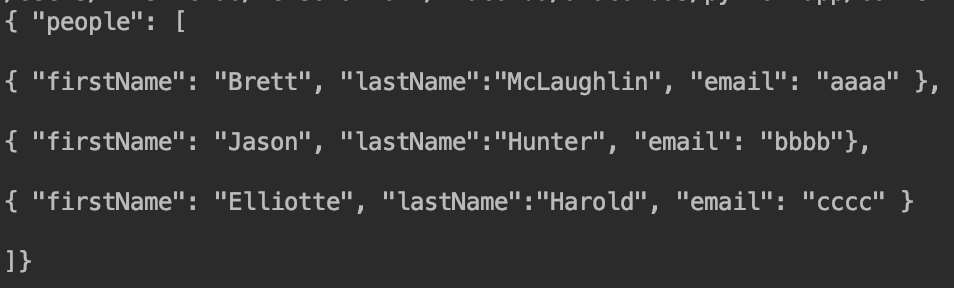
❗️其中,jd为字符串格式(因为.read()返回的即为字符串格式):

将输出结果转换成字典格式:
1
2
3
import json
dic=json.loads(jd)
print(dic)
其中,json.loads()中必须放入字符串格式的数据。上述代码输出见下:

将字典格式的json数据恢复成字符串类型:
1
2
jd2=json.dumps(dic)
print(jd2)
结果和jd比对如下:

少了换行符。
补充知识:
创建一个空的列表
li=[]。此时如果向空列表内直接写值li[0]=0会报错,向空的列表内写入内容需要li.append(0),这时li=[0]。
👉方法二:
使用pandas读入,类似于读csv和excel数据:
1
2
3
import pandas
df=pandas.read_json('jd.json')
print(df)
输出为DataFrame格式:

2.处理XML格式数据
从http://flash.weather.com.cn/wmaps/xml/china.xml处下载中国气象网的xml数据,部分内容见下:

2.1.XML数据格式
xml文档的字符分为标记与内容两类。标记通常以<开头,以>结尾,不是标记的字符就是内容:
<标记名称 属性名1=属性值1 属性名2=属性值2 ...>内容</标记名称>
2.1.1.标签(tag)
上文中的china 、city均为标记名称,即标签(tag)。以<开头,以>结尾,名字对大小写敏感。标签可分为三类:
- start-tag,如
<china> - end-tag,如
</china> - empty-element tag,如
<city .... />
2.1.2.元素(element)
元素是文档逻辑组成,或者在start-tag与匹配的end-tag之间,或者仅作为一个empty-element tag。例如:<greeting>Hello, world!</greeting>或<line-break />。
2.1.3.属性(attribute)
属性是一种标记结构,在start-tag或empty-element tag内部的“名字-值对”。例如,<img src="madonna.jpg" alt="Madonna" />。每个元素中,一个属性最多出现一次,一个属性只能有一个值。
2.2.处理xml数据
1
2
3
import xml.etree.ElementTree as ET
tree=ET.parse('china.xml')
root=tree.getroot()
关于
import
import xml,tree=xml.etree.ElementTree.parse('china.xml')from xml import etree,tree=etree.ElementTree.parse('china.cml')from xml.etree import ElementTree,tree=ElementTree.parse('china.xml')
2.2.1.解析xml文件
使用xml.etree.ElementTree解析xml文件。
ET.parse()将xml文件解析成ElementTree格式文件(一个树形结构),tree的结构见下:
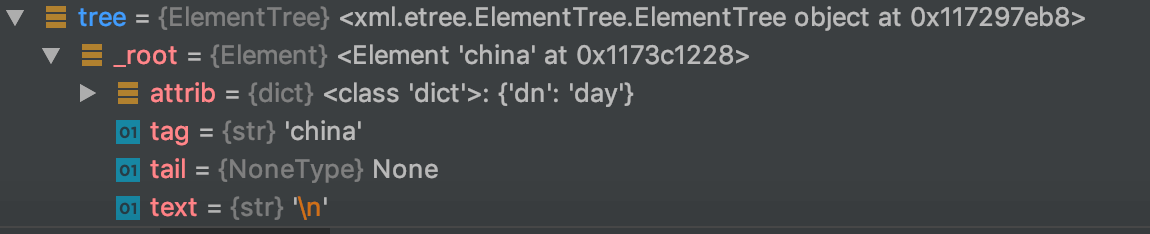
2.2.2.获取根节点
root=tree.getroot()可获取树的根节点:
root.tag:获取节点名称。即:china。root.attrib:获取节点对应的属性(❗️返回数据为字典格式)。即:{‘dn’: ‘day’}。
1
2
for xx in root :
print(xx.tag,xx.attrib)
xx依次为该根节点内的每个元素。上述代码输出为(部分):

也可以使用.iter()递归查询指定的子元素:
1
2
for city in root.iter('city')
print(city.get('cityname'),city.get('tem1'))
输出为(部分):

