本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.网络爬虫架构
👉网页编写的几个重要元素:
- 【html】中文全称为超文本标记语言,类似于xml格式。
- 超文本:指页面内的图片、链接,甚至音乐、程序等非文字元素。
- html的结构包括“头(head)”部分和“主体(body)”部分,其中“头”部分提供关于网页的信息,“主体”部分提供网页的具体内容。
- 【css】中文全称为层叠样式表(可以理解为网页的化妆品,用于美化网页)。css是一种定义样式结构如字体、颜色、位置等的语言。
- 【JavaScript】常用来为网页添加各式各样的动态功能(以及交互行为)。
打开chrome浏览器,进入某一网站,选择开发者工具:
下面依次介绍常用的几个窗口:
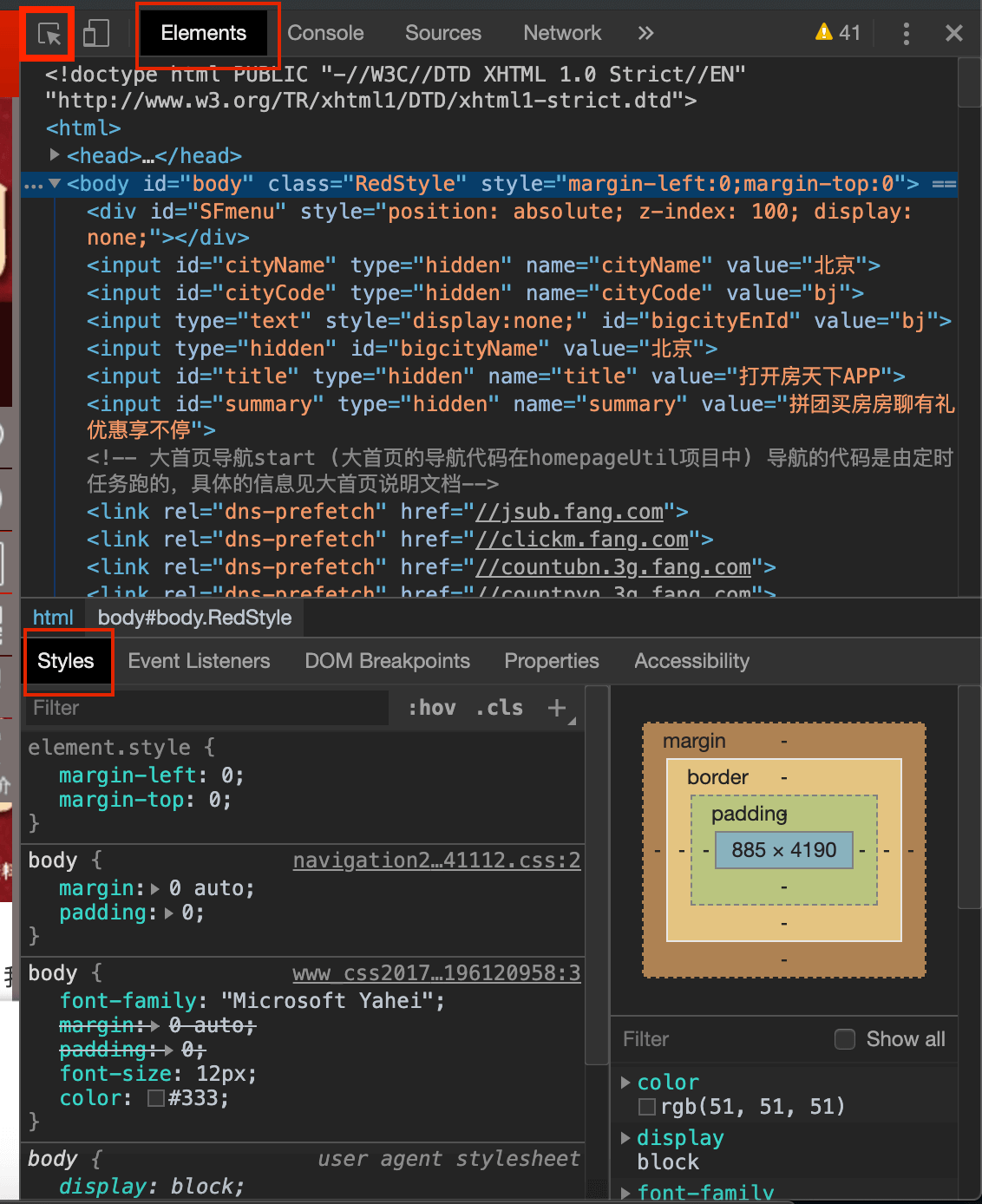
- Elements:html语言。
- Styles:css格式。
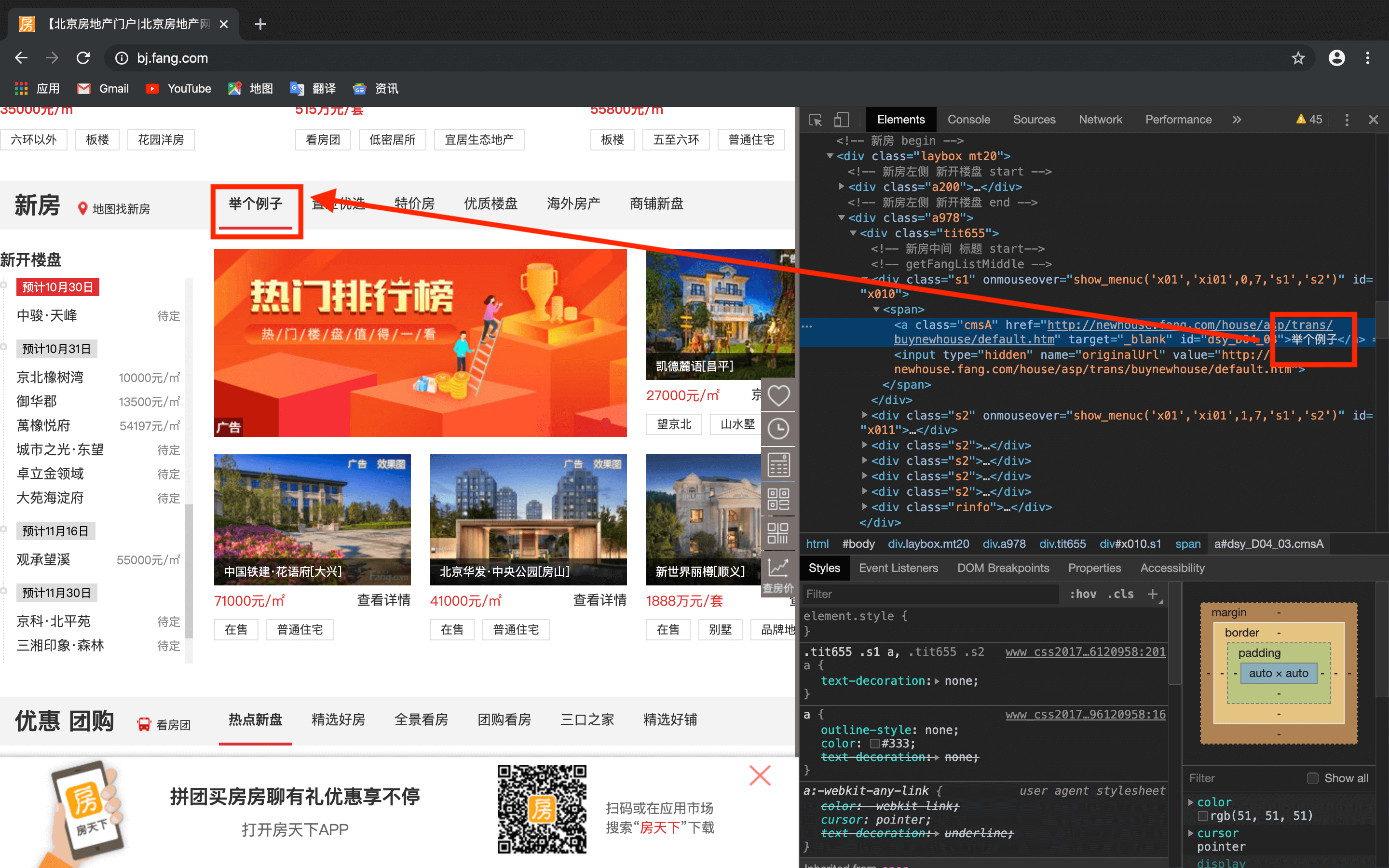
- 点击左上角的箭头图标,可查看网页各个内容对应的html代码,并在本地作出修改,例如:
- Styles:css格式。
- Console:编写JaveScript。例如输入
$('a').remove,去掉网页所有链接。 - Sources:网页源代码。
- Timeline:载入顺序。
- Network:关注网页的一举一动。
- All:发生的请求(各种类型的请求:css,js脚本,图片,文字等)。
- Doc:网页的文字信息(99%的文字信息都在这里,剩下的1%可能在“HDR”或“JS”)。
- Response:html语言(网页回应信息)

网络爬虫架构:
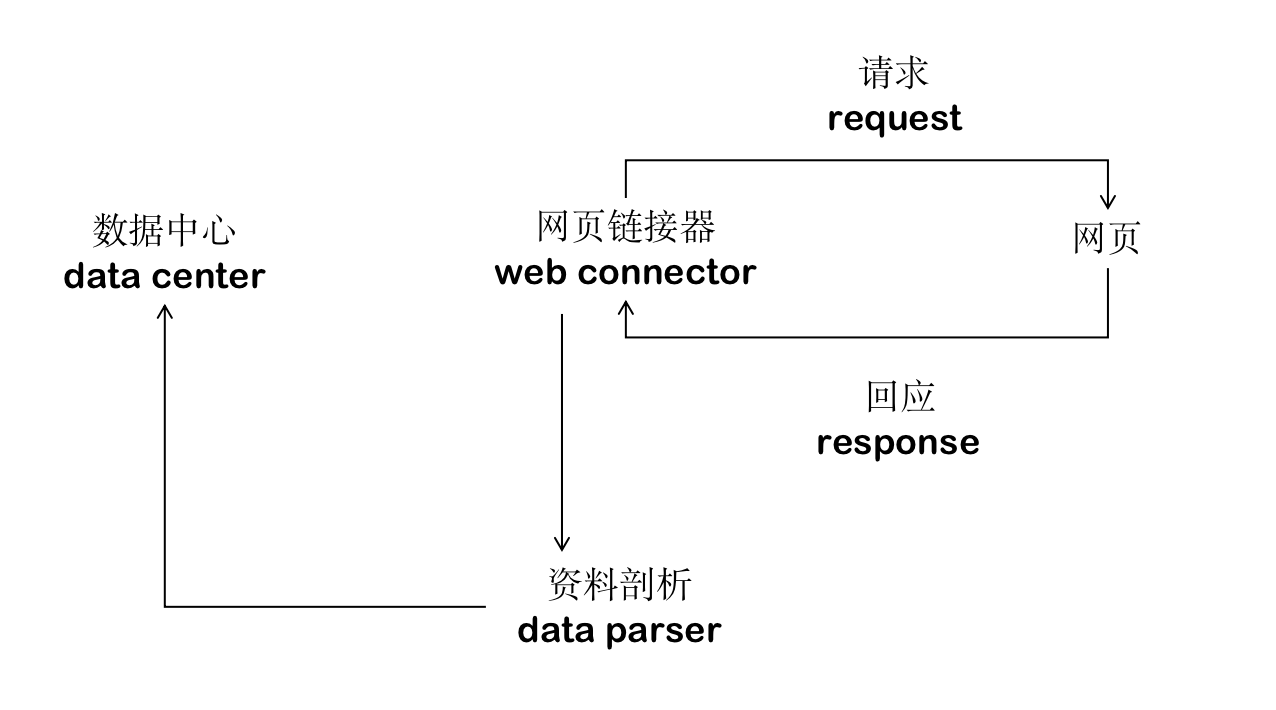
2.获取网页文字资讯
安装以下两个包:
pip install requestspip install BeautifulSoup4
或者直接安装Anaconda(Anaconda中包含这两个包)。
假设我们现在获取腾讯新闻主页的文字信息:
1
2
3
4
import requests
newsurl='http://news.qq.com/'
res=requests.get(newsurl)
print(res.text)
结果部分截图见下:
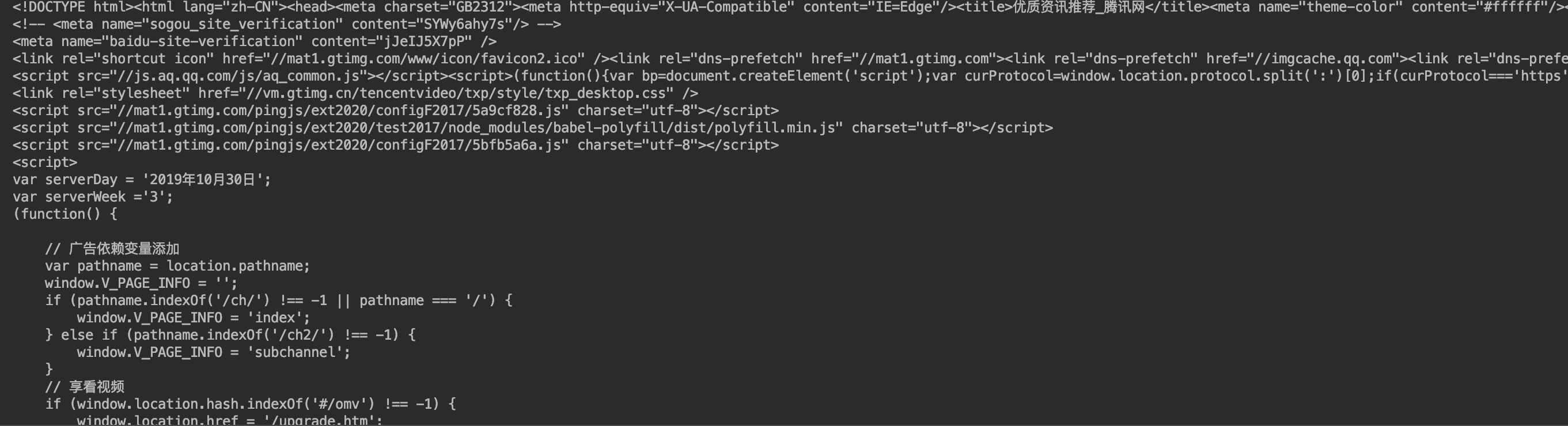
得到的是html格式的数据,我们希望可以将有用的信息进行进一步的提取,去掉繁琐的格式。
3.BeautifulSoup的使用
3.1.DOM Tree
假设我们有如下html格式的数据:
1
2
3
4
5
6
7
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#" class="link">This is link1</a>
<a href="# link2" class="link">This is link2</a>
</body>
</html>
其中h1是大标题,两个a是对应两个链接,href为链接的地址。
BeautifulSoup可将html数据解析成DOM(Document Object Model) Tree:
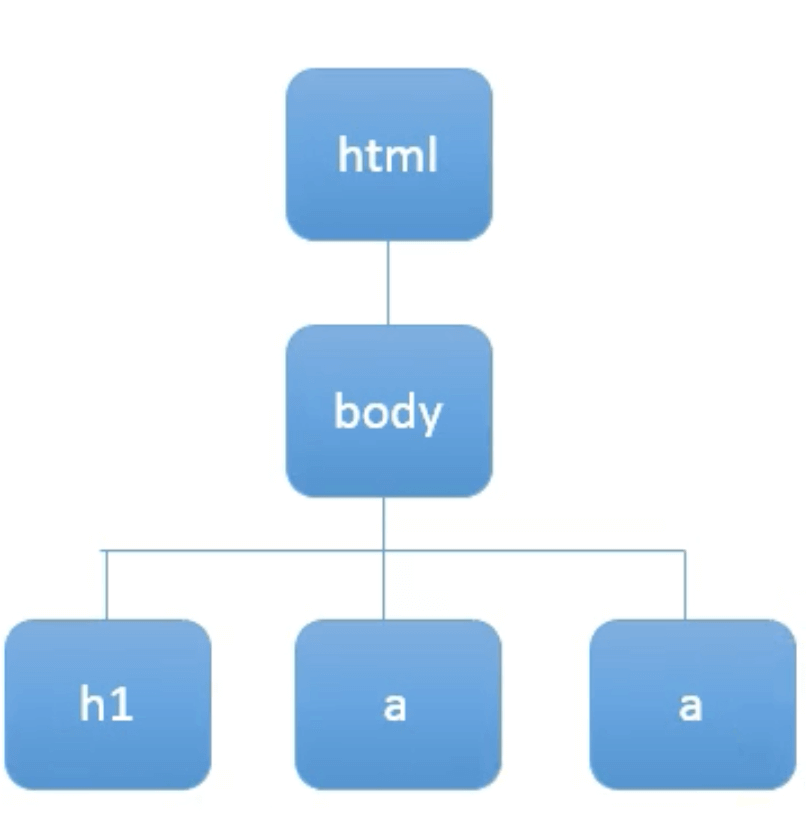
3.2.使用BeautifulSoup解析html数据
使用BeautifulSoup解析上述的html数据:
1
2
3
4
5
6
7
8
9
10
11
from bs4 import BeautifulSoup
html_sample='\
<html>\
<body>\
<h1 id="title">Hello World</h1>\
<a href="#" class="link">This is link1</a>\
<a href="# link2" class="link">This is link2</a>\
</body>\
</html>'
soup=BeautifulSoup(html_sample,'html.parser')
print(soup.text)
\可用于较长的字符串换行。
函数BeautifulSoup()中,第一个参数为html数据,第二个参数为解析器的类型,可以是html.parser,也可以是html5lib.parser、lxml.parser等等,不同的解析器有不同的优缺点。这里使用html.parser。
上述代码输出为:
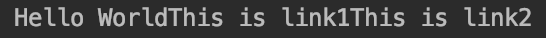
返回了一个字符串格式的数据,可以看到我们爬取了数据中所有的文字信息。
3.3.找出所有含特定标签的html元素
👉那么如果我们想爬取某个特定tag该怎么办呢?
1
2
3
4
5
header=soup.select('h1')
print(header)
alink=soup.select('a')
print(alink)
输出为:

返回的为列表结构的数据。
👉进一步爬取特定tag下的element:
1
2
3
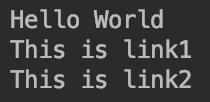
print(soup.select('h1')[0].text)
for xx in alink:
print(xx.text)
输出为:
3.4.取得含有特定css属性的元素
👉使用select找出所有id为title的元素(⚠️id前面需要加#):
1
alink=soup.select('#title')
输出为列表结构的数据:[<h1 id="title">Hello World</h1>]
👉使用select找出所有class为link的元素(⚠️class前面需加.):
1
2
for link in soup.select('.link'):
print(link)
输出为:
1
2
<a class="link" href="#">This is link1</a>
<a class="link" href="# link2">This is link2</a>
id是唯一的,但是class是多次重复出现的。
3.5.取得标签内的属性值
👉使用select找出所有a tag的href和class:
1
2
3
4
alinks=soup.select('a')
for link in alinks :
print(link['href'])
print(link['class'])
输出为:
1
2
3
4
#
['link']
# link2
['link']
取得某一个tag下的某一属性值:
1
2
alinks[0]['href'] #输出为:‘#’。为字符串格式。
alinks[0]['class'] #输出为:['link']。为列表结构。
4.网络爬虫基本思路
例如,我们要爬取腾讯新闻网站(https://news.qq.com/)中新闻的标题,使用chrome浏览器的开发者工具确定新闻标题的位置:
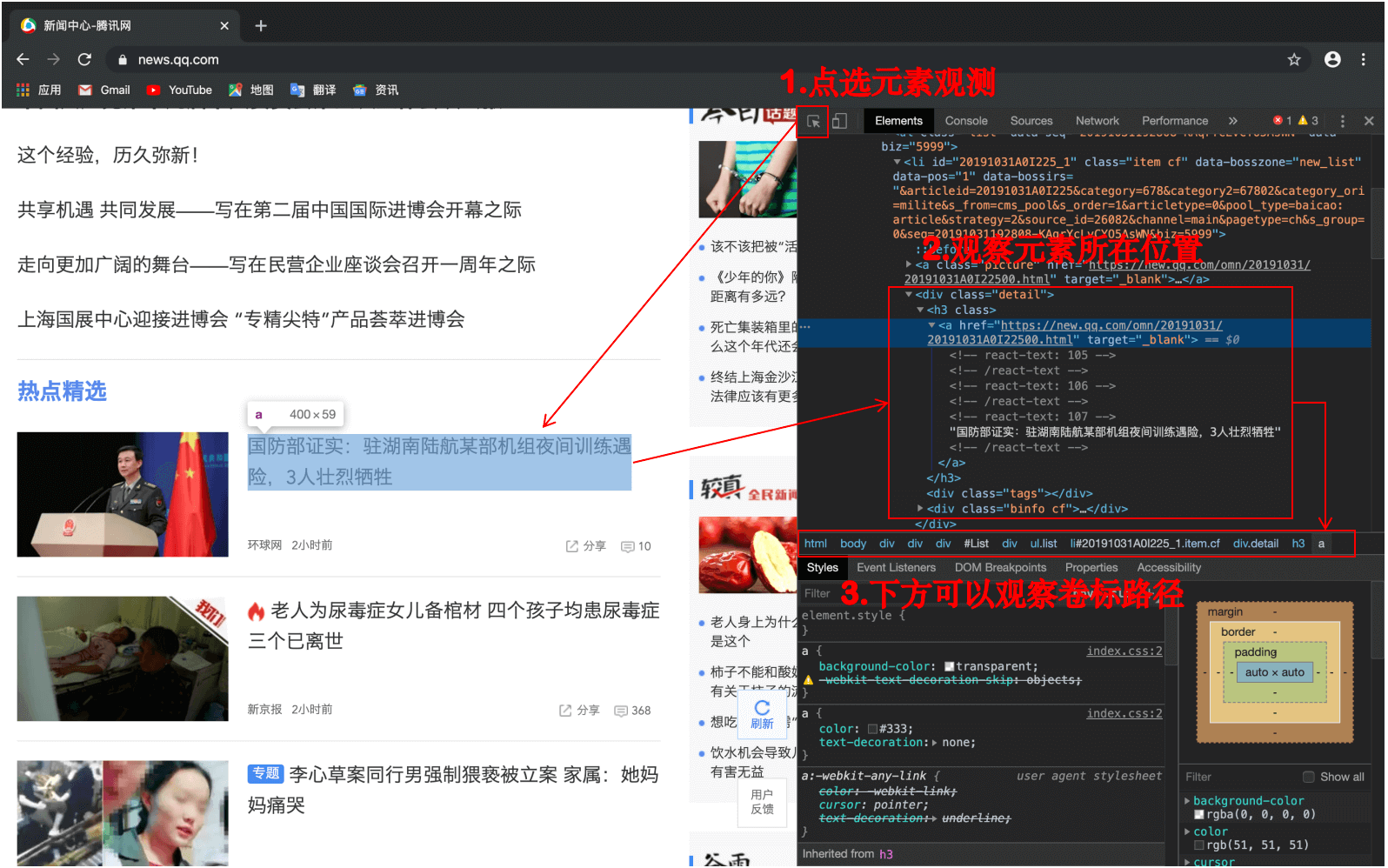
然后通过第3部分所讲的BeautifulSoup相关知识,将其文字内容爬取下来。
5.实战应用–北京房屋资料收集
假设我们现在需要收集北京的新房的房价信息。首先打开北京房天下网站,进入“新房”界面。进入开发者模式,查看文字信息的存储位置:
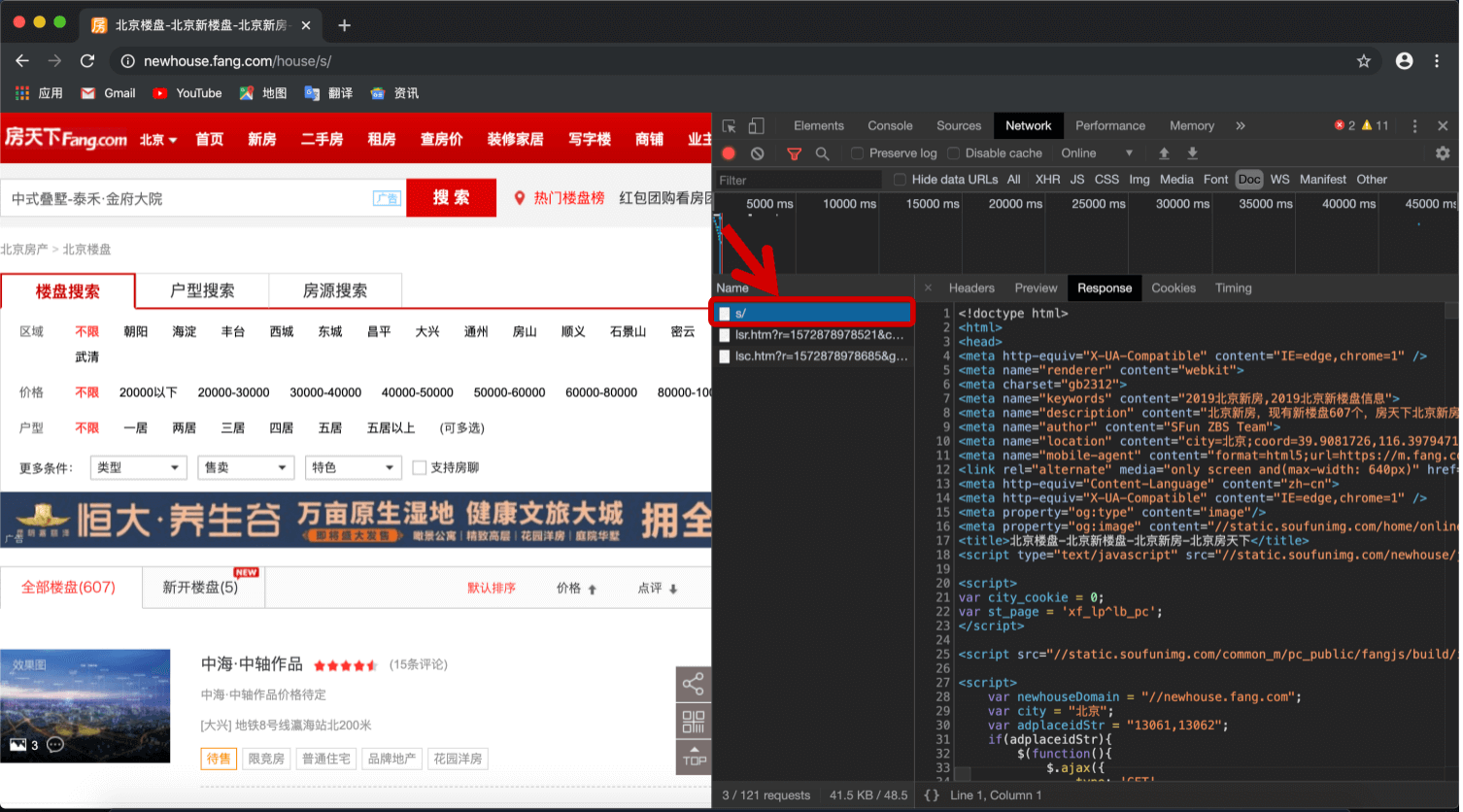
可以看出三个链接中只有第一个链接中存放着网页的文字信息:https://newhouse.fang.com/house/s/。
爬取北京新房的房价信息:res=requests.get('https://newhouse.fang.com/house/s/')。
在第2部分讲过提取网站的文字信息时可以用
requests.get(),但是需要注意一点:抓取的内容和网页的实时内容可能不同,因为网页的内容可能是一直在实时刷新,而抓取的内容则只是抓取操作那个时间点时网页的内容。
⚠️此时爬取的内容中中文可能会出现乱码的情况,需要特定的编码方式。一般网页的编码方式可在下面两个地方找到:
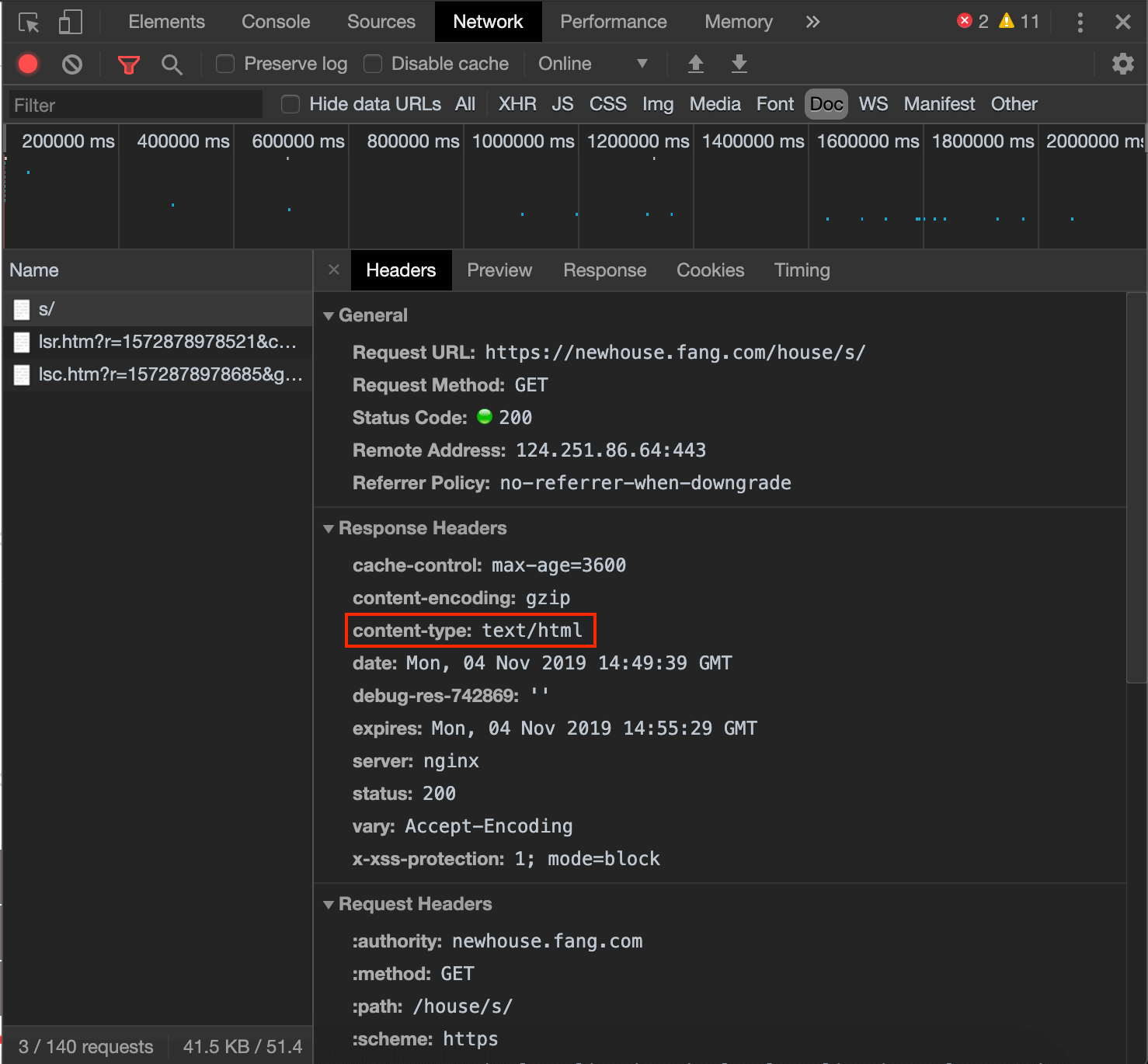
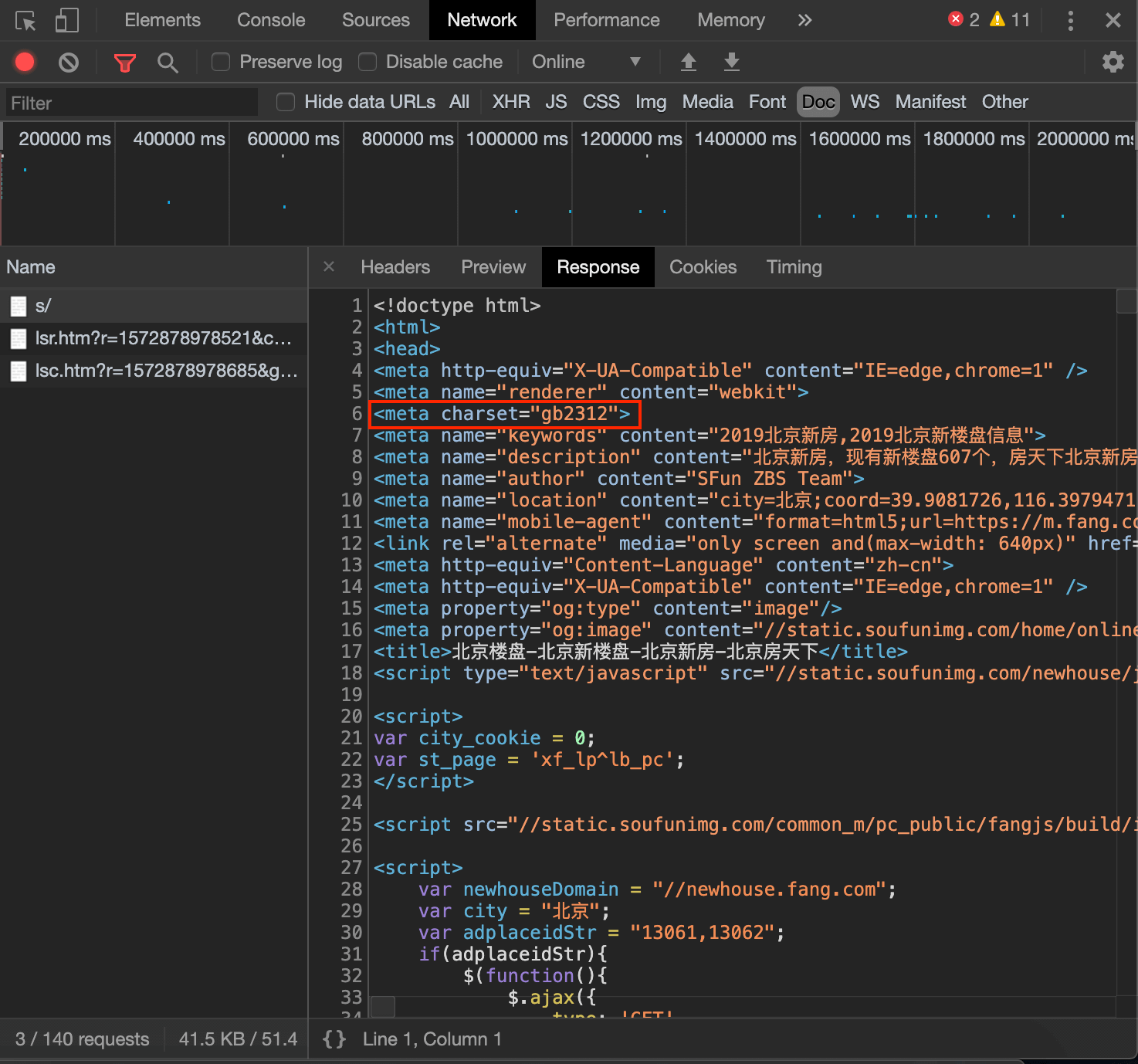
可以看出本例中网页的编码方式为”gb2312”,通过res.encoding='gb2312'即可解决中文乱码问题。
然后通过点击开发者模式左上角的箭头图标进行内容的具体定位(具体请见第4部分的讲解)。本例中房屋的名称均在class="nlcd_name"的标签下:
1
2
3
soup=BeautifulSoup(res.text,'html.parser')
for house_name in soup.select('.nlcd_name'):
print(house_name.text.strip())
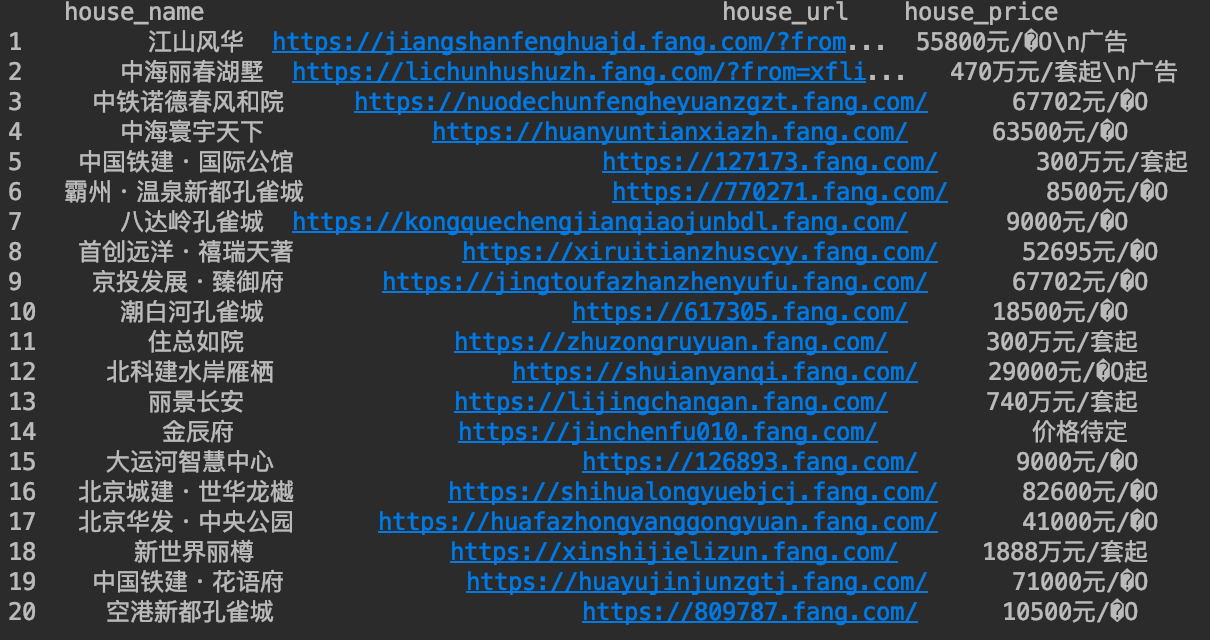
至此,我们便得到了该页面所有的房屋名称:

如果我们除了输出房屋的名称,还想得到该房屋信息的网络链接。
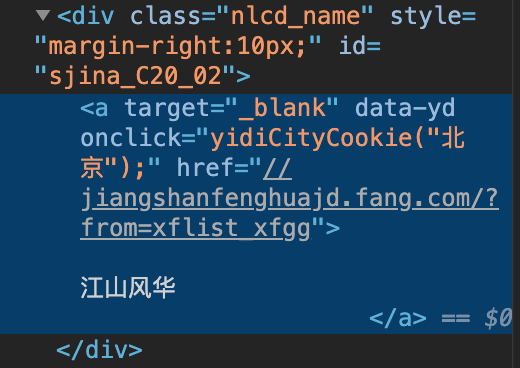
根据上图可以看出,房屋的链接href在标签a中,是标签div的子标签,并且该链接需要在前面加上https::
1
2
for house_url in soup.select('.nlcd_name a'):
print('https:' + house_url['href'])
输出见下:

❗️.nlcd_name a中间的空格表示标签a是class=”nlcd_name”所在标签的子标签。
❗️但是有一种特殊的情况,如果class=”info rel floatr”。如果直接soup.select('.info rel floatr'),会被认为.info、rel、floatr三个标签是层层递进的关系,则输出未匹配,只能输出空值。这种情况正确的写法为:soup.select('.info.rel.floatr')
类似的,我们也可以输出房屋的价钱,户型,地址等信息,这些信息都可以封装在一个函数中,方便调用。最终的结果可以存储在DataFrame中,进一步可导出为excel或其他格式: