本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.简介
1.1.Pandas
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
1.2.Numpy
NumPy是使用Python进行科学计算的基础软件包。除其他外,它包括:
2.NumPy基本用法
假设有两个列表:
1
2
a=[1,2,3]
b=[2,3,4]
如果我们想将a和b中每个对应元素相乘,直接a*b是不可以的,因为列表无法相乘。我们只能通过for循环实现这个功能:
1
2
for k,v in zip(a,b):
print(k*v)
关于zip的用法见2.1部分。
输出为:
1
2
3
2
6
12
也可将k*v的结果包装到list中:
1
[k*v for k,v in zip(a,b)] #输出为[2,6,12]
列表解析的用法见2.2部分。
可以看出过程比较复杂,如果我们使用NumPy的话会简单很多。我们构建两个NumPy数组:
1
2
3
4
5
import numpy as np
a=np.array([1,2,3])
b=np.array([2,3,4])
print(a+b) #输出为[3 5 7]
print(a*b) #输出为[2 6 12]
2.1.关于zip的用法
1
2
3
4
5
6
7
8
9
10
a=[1,2,3]
b=[4,5,6]
c=[4,5,6,7,8]
zipped1=zip(a,b)
print(list(zipped1)) #zipped1为[(1, 4), (2, 5), (3, 6)]
zipped2=zip(a,c)
print(list(zipped2)) #zipped2为[(1, 4), (2, 5), (3, 6)]
d1,d2=zip(*zip(a,b))
print(list(d1)) #d1为[1, 2, 3]
print(list(d2)) #d2为[4, 5, 6]
⚠️需要注意四点:
- Python2中
zip()返回的是一个列表,可以直接print(zipped1),但是在Python3中,为了减少内存,zip()返回的是一个对象,如需展示列表,需手动list()转换,即print(list(zipped1))。 - 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
- 利用
*号操作符,可以将元组解压为列表。 zip对象在使用一次后就会失效清空,例如:
1
2
3
4
5
a=[1,2,3]
b=[4,5,6]
c=zip(a,b)
d1,d2=zip(*c)#正常无报错
d1,d2=zip(*c)#c已经使用过一次了,本语句会报错
2.2.列表解析
列表解析是将for循环和创建新元素合并在一个语句完成:
1
listA=[a for a in range(1,5)]
⚠️listA=[1,2,3,4]而不是listA=[1,2,3,4,5]。
3.Pandas基本用法
3.1.DataFrame
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
1
2
import pandas as pd
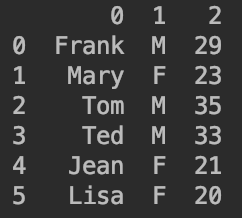
df=pd.DataFrame([['Frank','M',29],['Mary','F',23],['Tom','M',35],['Ted','M',33],['Jean','F',21],['Lisa','F',20]])
df的样式为:
新增字段名称(列名):
1
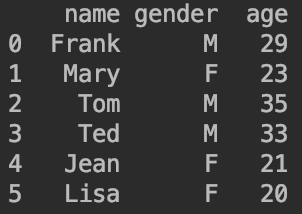
df.columns=['name','gender','age']
改完后的df样式为:
3.1.1.快速查看DataFrame的信息
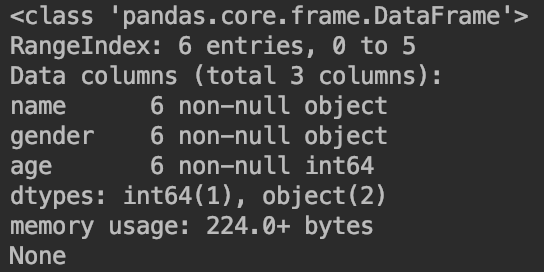
👉查看df的有关信息df.info():
👉查看df的前几行和后几行(默认查看5行):
1
2
3
4
df.head() #查看前5行
df.head(3) #查看前3行
df.tail() #查看后5行
df.tail(3) #查看后3行
👉查看有关df的叙述性统计(针对连续型数据)df.describe():
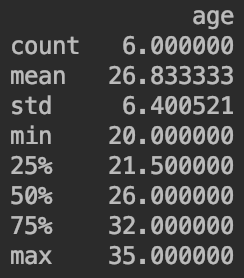
也可以用df["age"].describe()['mean']输出age属性的均值信息。
df["age"].describe().mean()输出的是统计信息(数据条数、均值、标准差等)的均值,而不是age属性的均值。
3.2.Series
序列(Series)是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
创建一个Series:
1
type=pd.Series([21,18,35])
type输出为:
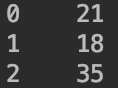
向Series中加入索引:
1
type=pd.Series([21,18,35],index=['A','B','C'])
type输出为:
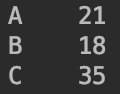
查看Series中的元素:
1
2
type[1] #按位置访问,输出为18
type['A'] #输出为21
type[0:2]输出为前两行的数据:
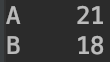
❗️多维的Series组合在一起就成为了DataFrame。
