本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.前言
使用numpy和pandas进行资料的转换。
2.向量化计算
假设我们有以下房屋资料的数据:
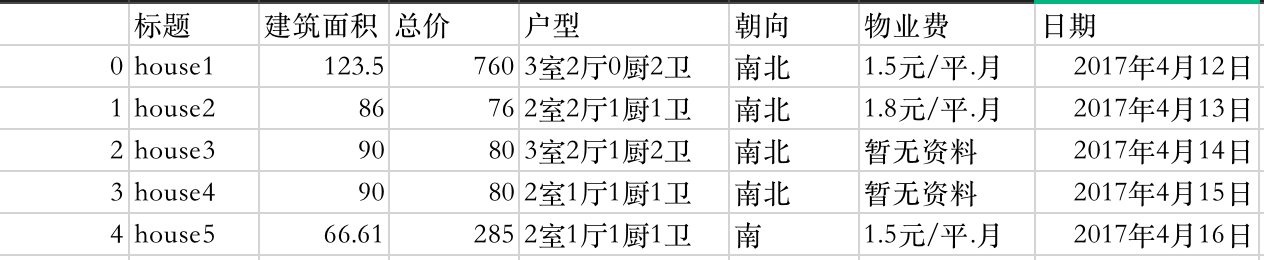
通过pandas读入:
1
2
import pandas as pd
df=pd.read_csv("house_price.csv")
如果在查看DataFrame时行或列没显示全,可添加以下代码解决:
👉“总价”一栏的单位是万元,将其转换成元:
1
df["总价"]*10000
👉把“朝向”和“户型”两栏进行合并:
1
df["朝向"]+df["户型"]
👉建立新的栏位“均价”:
1
df["均价"]=df["总价"] * 10000 / df["建筑面积"]
3.Apply、Map、ApplyMap
Map:将函数套用到Series上的每个元素。Apply:将函数套用到DataFrame上的行与列。ApplyMap:将函数套用到DataFrame上的每个元素。
3.1.Map
👉移除“物业费”中的元:
方法一:
1
2
3
def removeDollar(e):
return e.split('元')[0]
df["物业费"].map(removeDollar)
split用法👉:split。
举例如下:
方法二(使用匿名函数):
1
df["物业费"].map(lambda e:e.split('元')[0])
两种方法结果是一样的:

3.2.Apply
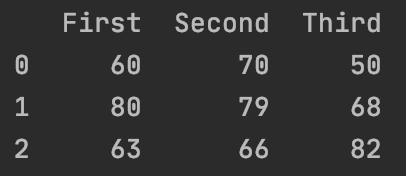
新建如下DataFrame:
1
df2=pd.DataFrame([[60,70,50],[80,79,68],[63,66,82]],columns=["First","Second","Third"])
1
2
df2.apply(lambda e:e.max()-e.min(),axis=0)#默认为axis=0
df2.apply(lambda e:e.max()-e.min(),axis=1)
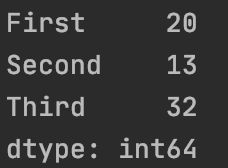
axis=0时按列输出为:
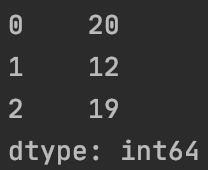
axis=1时按行输出为:
3.3.ApplyMap
将df中所有“暂无资料”的元素替代成缺失值(NaN):
1
2
3
4
5
6
7
8
9
#方法一
def convertNaN(e):
if e == "暂无资料":
return np.nan
else:
return e
df.applymap(convertNaN)
#方法二
df.applymap(lambda e:np.nan if e=="暂无资料" else e)
