【深度学习基础】系列博客为学习Coursera上吴恩达深度学习课程所做的课程笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.One-Shot Learning
人脸识别所面临的一个挑战就是One-Shot Learning(单样本学习)。也就是说,在绝大多数人脸识别应用中,你仅能通过一张图片(或者一个人脸样例)去识别这个人。但是这对于需要大数据支持的深度学习并不友好。
我们通过一个直观的例子来了解这一过程并讨论如何解决数据量不足的问题。
假设公司数据库里有4张员工的照片。现在过来了一个访客想要通过我们的人脸识别安检系统,那么系统需要做的是仅凭已有的4张员工照片,判断过来的这个访客是否属于其中的一个或者都不属于。
显然,我们的算法只能通过一个样本进行学习。
其中一个思路是将人脸图片作为输入喂给一个CNN网络,然后以softmax函数作为输出函数,判断该输入为四个员工的其中一个或者都不是。但实际上因为我们的训练集过小,不足以训练一个稳健的CNN网络,所以这样做效果并不好。并且如果有新的员工加入公司,导致CNN网络的输出类别多了一类,我们又得重新训练网络。
那么我们该如何解决这个问题呢?方法之一就是使用“similarity” function,即计算两张图片之间的相似度。如果两张图片的差异小于既定阈值,那么就判定这两张图片为同一个人,反之差异大于阈值,则为不同的人。这样做的另外一个好处是如果有新员工加入公司,只需要把该员工的照片放进数据库即可,不需要重新训练模型。
那么新的问题来了,我们该如何构建网络,计算这个所谓的相似度或者说是差异呢?其中一种方式就是使用Siamese网络。
2.Siamese网络
Siamese译为“连体,孪生”之意,因此Siamese网络指的是两个或多个一模一样的网络。
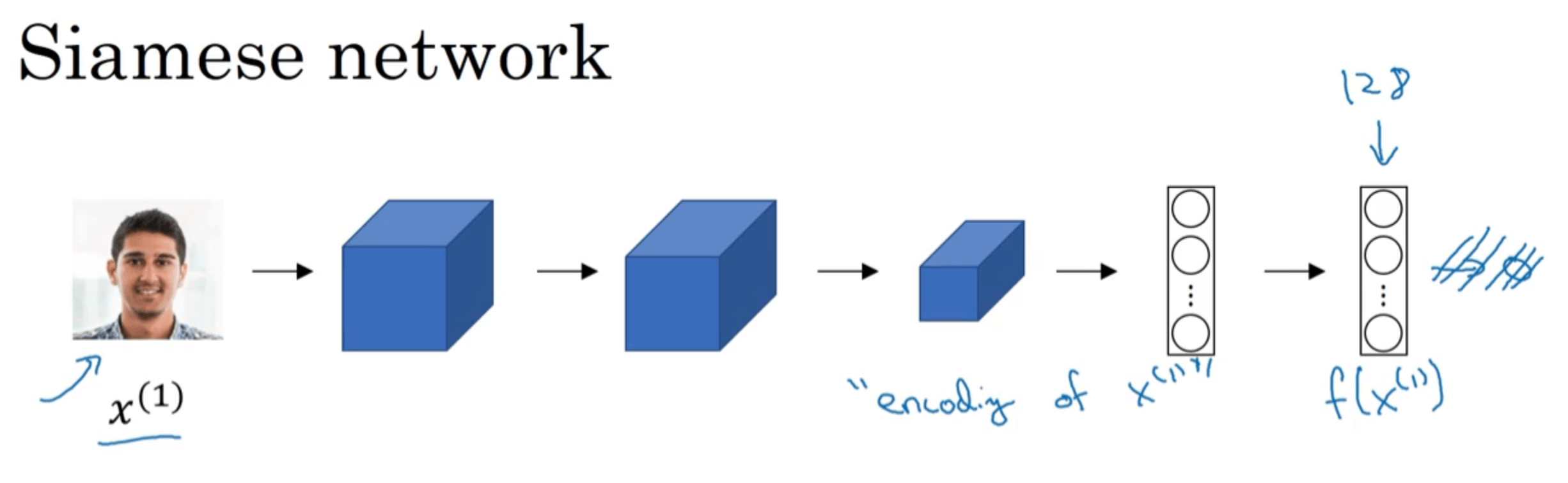
上面这个网络结构其实就是CNN网络去掉了输出层,保留其最后的全连接层,可以把这个全连接层看作输入的特征向量或者编码。本例中,特征向量(编码)的维度为128。同理,我们可以把另一张图片也输入到这个网络,同样也得到一个对应的特征向量(编码):
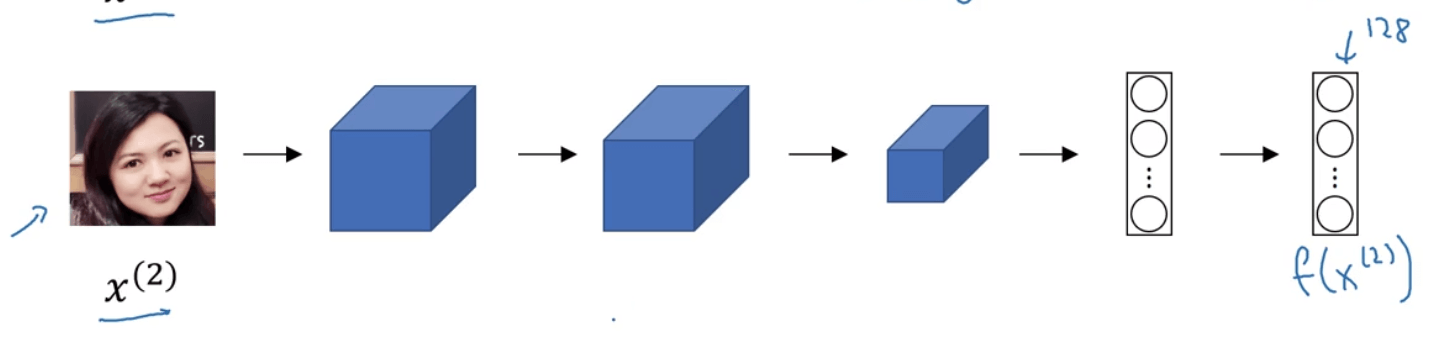
假设输入的两幅图片分别为:$x^{(1)},x^{(2)}$,对应的特征向量(编码)分别为:$f(x^{(1)}),f(x^{(2)})$,那么这两幅图片之间的差异(或者说是距离distance)可以定义为:
\[d(x^{(1)},x^{(2)})=\lVert f(x^{(1)})-f(x^{(2)}) \rVert _2 ^2\]以上便可看作是Siamese网络的两个branch,两个branch的参数都是绑定的,即都是一样的。
主要观点来自论文:Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1701-1708.
下一部分我们将介绍如何构建Siamese网络的loss function。
3.Triplet Loss Function
之所以叫triplet,是因为我们同时要比较三张图片:

- A : anchor image
- P : positive image(和A属于同一个人)
- N : negative image(和A不是同一个人)
按逻辑来讲,应该有:
\[d(A,P) \leqslant d(A,N)\]即:
\[d(A,P) - d(A,N) \leqslant 0\]但是如果模型输出的A,P,N的特征向量(编码)完全一样,则也可以满足上式,这显然是没有任何意义的。因此我们还需要对上式做一些修改:
\[d(A,P) - d(A,N) + \alpha \leqslant 0 \tag{1}\]$\alpha$被称作“间隔”,是一个超参数($\alpha > 0$)。
这里所说的“间隔”类似于支持向量机中的“间隔”。
因此,Triplet Loss Function构建如下:
\[L(A,P,N)=max(d(A,P) - d(A,N) + \alpha,0)\]对应的cost function为:
\[J=\sum_{i=1}^m L(A^{(i)},P^{(i)},N^{(i)})\]我们的目标就是最小化$J$。
因为我们需要构建triplet data set(即A,P,N对),所以我们需要同一个人的多个照片。那么我们该如何选择A,P,N对呢?如果随机选择的话,式(1)的约束非常容易被满足,网络并不能学到很多有用的信息。因此,我们需要选择一些比较困难的A,P,N对用于训练。
本部分内容来自论文:Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.
4.人脸识别与二分类
Triplet Loss Function是学习Siamese网络参数的一种办法,本节将介绍其他学习Siamese网络参数的方法:将人脸识别转换成一个二分类问题。
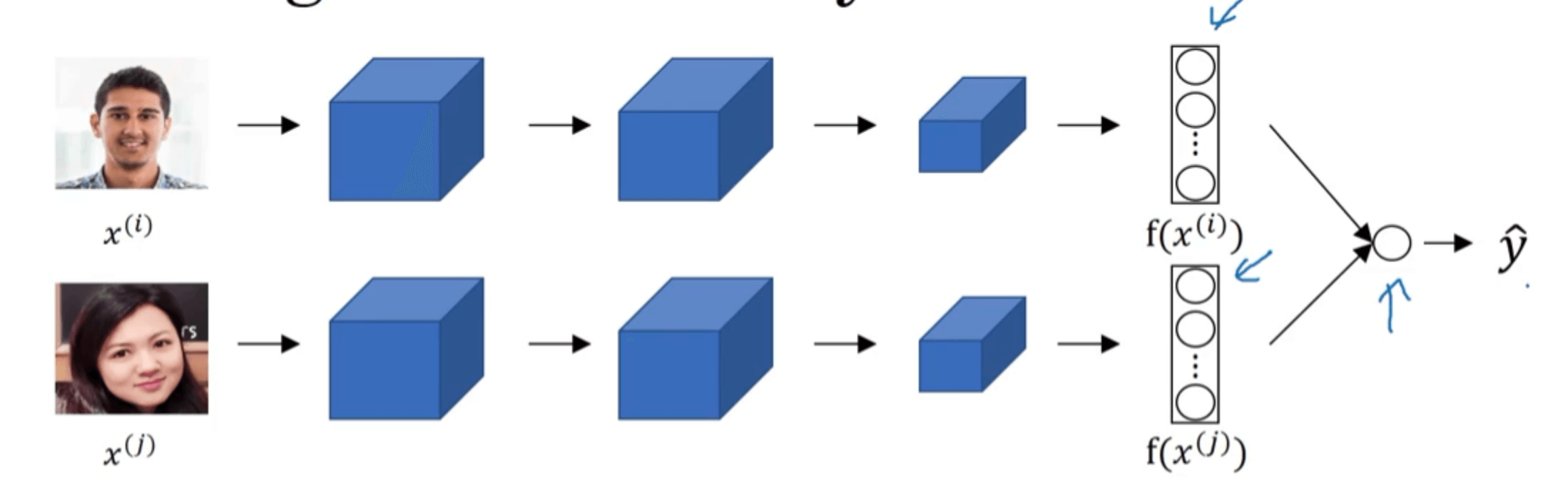
与之前介绍的不同之处在于我们将两幅图片的特征向量(假设为128维)输入给了logistic激活函数,最终输出变成了二分类。如果两幅图片是同一个人,则输出1,否则输出0:
\[\hat{y}=logistic(\sum_{k=1}^{128} w_k \left\vert f(x^{(i)})_k - f(x^{(j)})_k \right\vert +b)\]或者也可以写为:
\[\hat{y}=logistic(\sum_{k=1}^{128} w_k \frac{(f(x^{(i)})_k - f(x^{(j)})_k)^2}{ f(x^{(i)})_k + f(x^{(j)})_k}+b)\]上式可简写为:
\[\hat{y}=logistic(\sum_{k=1}^{128} w_k \chi ^2+b)\]主要观点来自论文:Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1701-1708.
Ps:为了提升识别效率,可以将训练好的模型为数据库中每一位员工生成其特定的特征向量并保存。当有访客来临时,只需计算访客的特征向量,并与已保存好的员工特征向量进行比较即可。
