本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.数据收集
假设我们想对最新的热点新闻进行分析,那么我们就需要首先从网络上爬取当前的最新新闻,以https://news.sina.com.cn/china/网站提供的最新新闻为例:
python网络爬虫详细教程:【Python基础】第八课:网络爬虫。本文不再详述该过程,只列出一些关键步骤。
首先获取链接地址,步骤见下图:
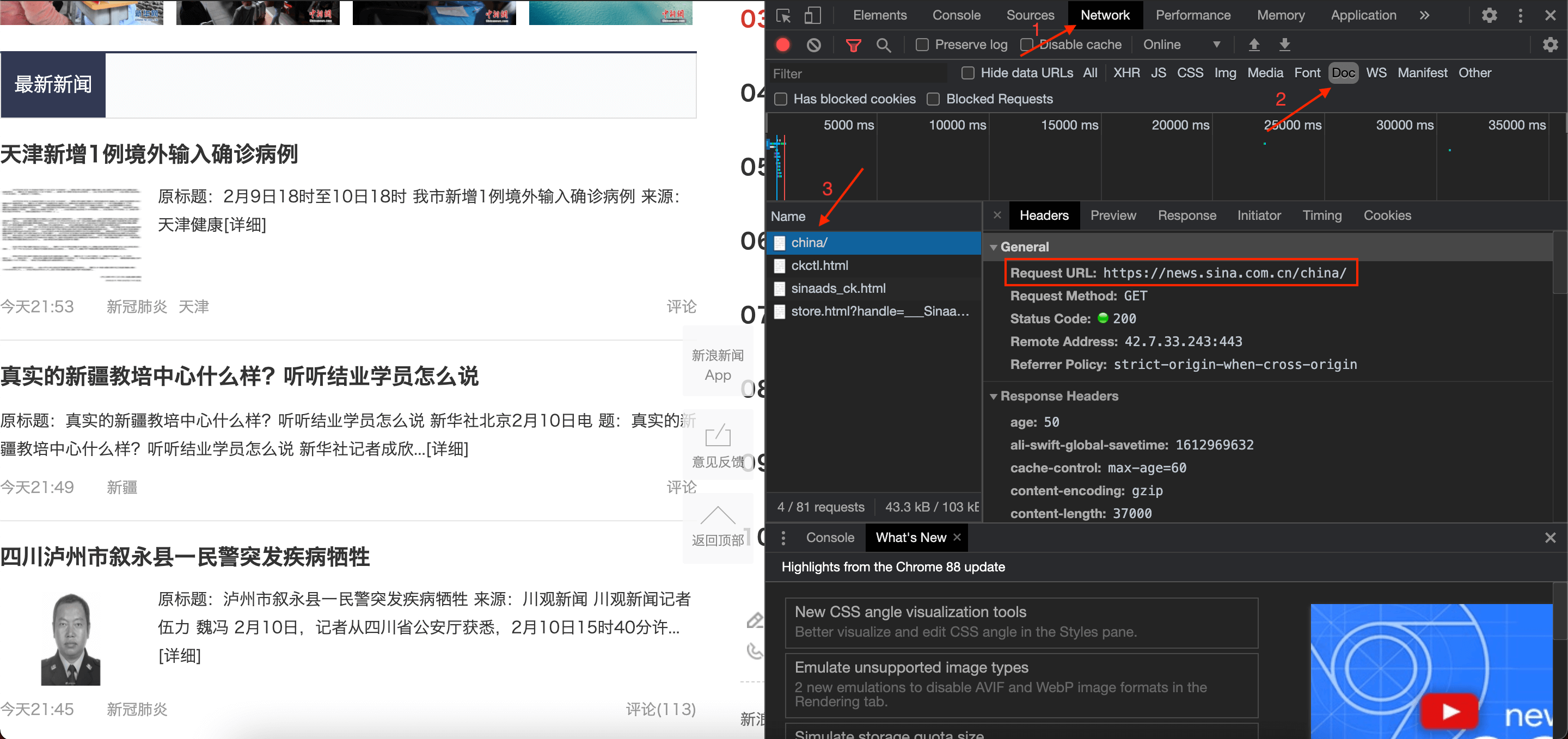
如果第3步没有任何内容,刷新下网页即可。
然后点击Response标签,确定该链接包含有本网页的文字内容:

如上图红色框标示的部分所示,说明该链接包含我们所要的网页中的最新新闻的内容。
如果该链接未包含网页的文字内容,则可尝试红色圆圈内剩余的另外三个链接。
确定完链接之后,我们便可以用python对其内容进行爬取了。首先import一些必要的库:
1
2
3
import requests
from bs4 import BeautifulSoup
import re
对内容进行爬取:
1
2
res = requests.get("https://news.sina.com.cn/china/")
print(res.text)
发现得到的文字内容都是乱码。通过查看网页源代码,得知其编码方式为utf-8:

而默认的编码方式为:
1
print(res.encoding) #输出为:ISO-8859-1
因此修改其编码方式:
1
2
res.encoding = 'utf-8'
print(res.text)
结果见下(部分):
1
2
3
4
5
6
<a href="https://news.sina.com.cn/c/2021-02-10/doc-ikftpnny6206975.shtml" target="_blank" title="春节假期来了 牢记这50条防疫要点">春节假期来了 牢记这50条防疫要点</a>
</li> <li>
<a href="https://news.sina.com.cn/c/2021-02-10/doc-ikftpnny6103607.shtml" target="_blank" title="牛弹琴:马上就是春节,三个好消息和一个坏消息!">牛弹琴:马上就是春节,三个好消息和一个坏消息!</a>
</li> <li>
<a href="https://news.sina.com.cn/c/xl/2021-02-07/doc-ikftpnny5527323.shtml" target="_blank" title="时政微纪录丨百姓心 中国年">时政微纪录丨百姓心 中国年</a>
</li>
在使用soup.select时,可以直接通过Copy selector获得内容所在路径:
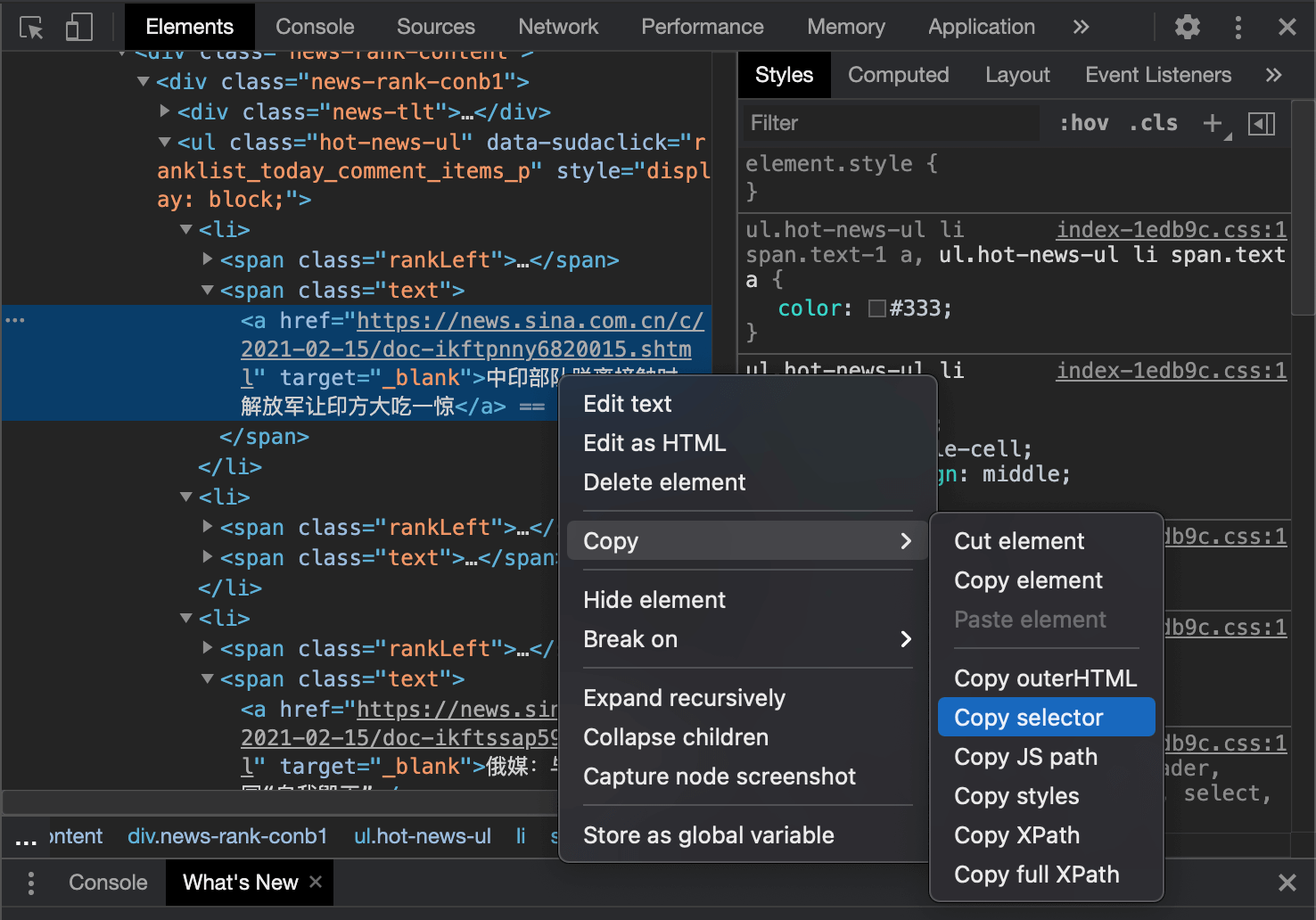
其他操作就没有特殊的了,按照之前博客【Python基础】第八课:网络爬虫中所介绍的,我们可以将热点新闻的标题、内容、来源以及关键词都爬取下来,并放在一个字典里,方便后续使用。
2.数据处理
使用pandas的DataFrame直接读取字典格式的数据,得到以下DataFrame:

👉整理关键词:将文章关键词放在一个list里:
1
df["keywords"] = df["keywords"].map(lambda e: e.split(","))

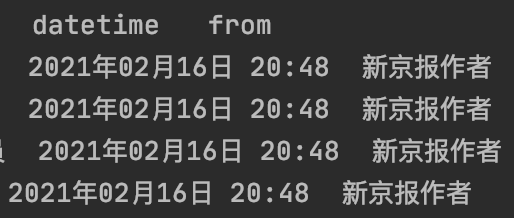
👉整理来源:将来源拆分为datetime和from两个栏位:
1
df[["datetime", "from"]] = df["source"].str.extract('\n+(\d+年\d+月\d+日 \d+:\d+)\n+(\w+)', expand=False)
转换datetime格式:
1
df["datetime"] = pd.to_datetime(df["datetime"], format="%Y年%m月%d日 %H:%M")
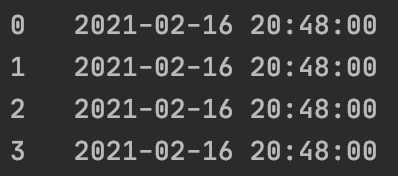
将时间转换成这个格式更方便我们使用,例如如果我们需要提取新闻发表的年份:
1
df["datetime"].map(lambda e: e.year)
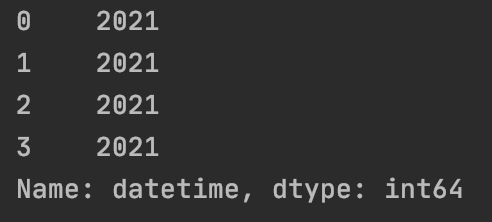
类似的还有:
1
df["datetime"].map(lambda e: e.month) #提取月份
栏位source现在可以被删除了:
1
del df["source"]
👉调整栏位顺序:
1
df = df[["from", "title", "content", "keywords", "datetime"]]

👉将整理好的数据存储至Excel:
1
df.to_excel("news.xlsx")
