本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.读入数据
1
2
3
import pandas as pd
df = pd . read_csv ( "Region_Data.csv" , encoding = 'gb2312' , skiprows = 3 , skipfooter = 2 , engine = "python" )
skiprows=3表示读入文件时跳过前面三行;skipfooter=2表示读入文件时跳过后面两行。
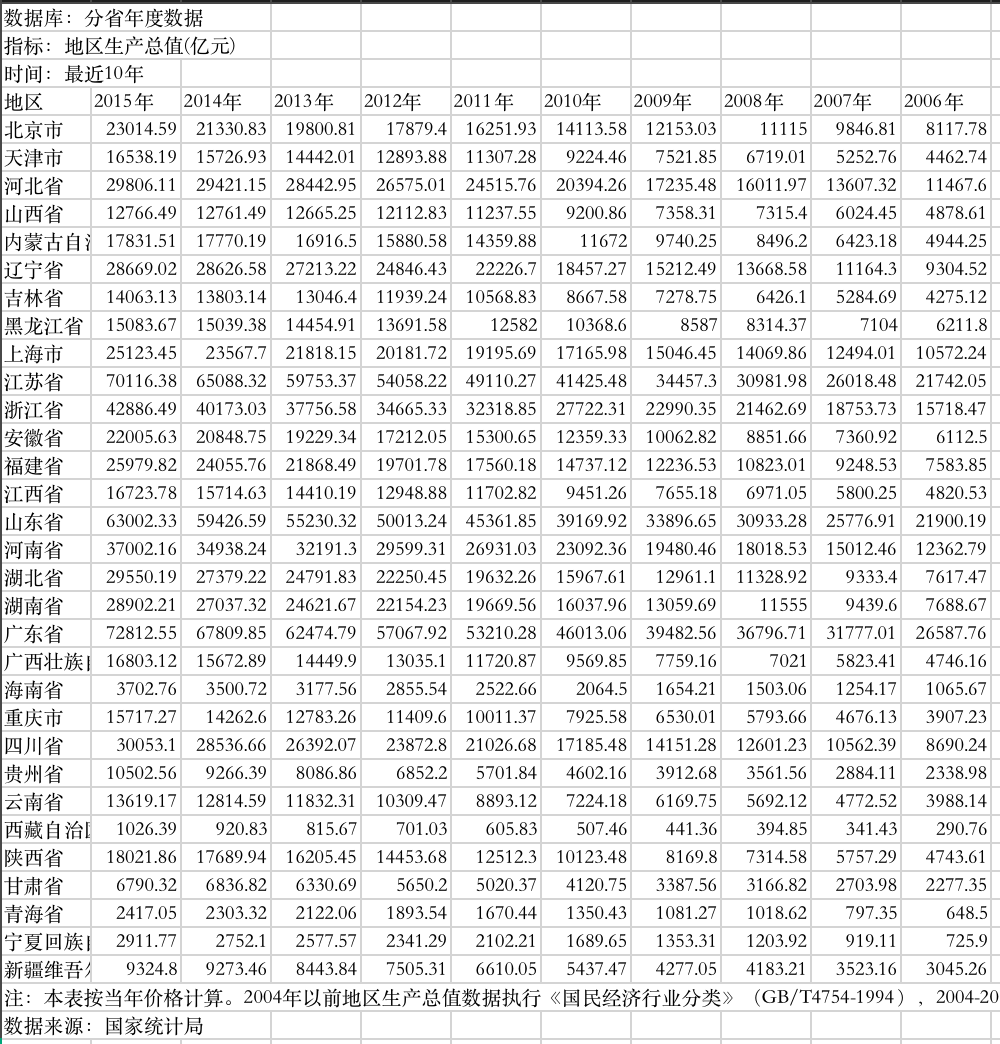
数据见下:
2.数据转换
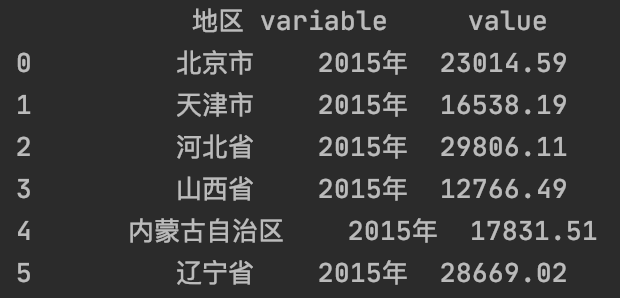
将数据拆分为“地区”、“年份”和“生产总值”三个栏位:
1
df = pd . melt ( df , col_level = 0 , id_vars = "地区" )
pandas.melt的用法见本文2.1部分。
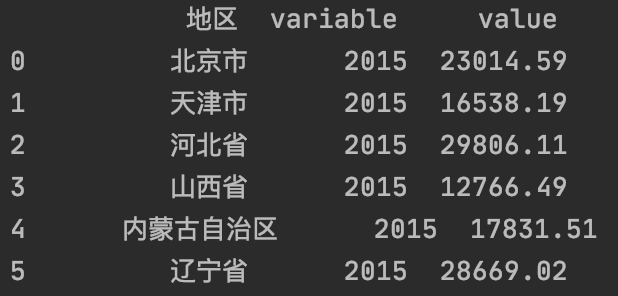
移除“年”:
1
df [ 'variable' ] = df [ 'variable' ]. map ( lambda e : int ( e . strip ( '年' )))
map的用法见:map 。
strip的用法见:strip 。
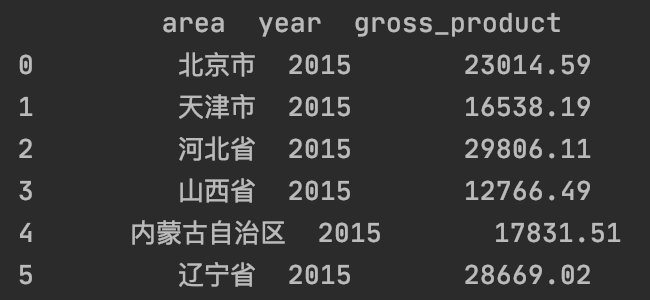
修改字段名:
1
df . columns = [ 'area' , 'year' , 'gross_product' ]
2.1.pandas.melt
1
2
3
4
5
6
7
8
def melt (
frame ,
id_vars = None ,
value_vars = None ,
var_name = None ,
value_name = 'value' ,
col_level = None
)
参数解释:
frame:要处理的数据集。id_vars:不需要被转换的列名。value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了。var_name和value_name:是自定义设置对应的列名。col_level:如果列是MultiIndex,则使用此级别。
举个例子:
1
2
3
4
import pandas as pd
df = pd . DataFrame ({ 'A' : { 0 : 'a' , 1 : 'b' , 2 : 'c' },
'B' : { 0 : 1 , 1 : 3 , 2 : 5 },
'C' : { 0 : 2 , 1 : 4 , 2 : 6 }})
1
2
3
4
A B C
0 a 1 2
1 b 3 4
2 c 5 6
1
2
3
pd . melt ( df , id_vars = [ 'A' ])
#等同于:
pd . melt ( df , id_vars = [ 'A' ], value_vars = [ 'B' , 'C' ])
1
2
3
4
5
6
7
A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 6
1
pd . melt ( df , id_vars = [ 'A' ], value_vars = [ 'B' ])
1
2
3
4
A variable value
0 a B 1
1 b B 3
2 c B 5
1
2
pd . melt ( df , id_vars = [ 'A' ], value_vars = [ 'B' ],
... var_name = 'myVarname' , value_name = 'myValname' )
1
2
3
4
A myVarname myValname
0 a B 1
1 b B 3
2 c B 5
multi-index的情况:
1
df . columns = [ list ( 'ABC' ), list ( 'DEF' )]
1
2
3
4
5
A B C
D E F
0 a 1 2
1 b 3 4
2 c 5 6
1
pd . melt ( df , col_level = 0 , id_vars = [ 'A' ], value_vars = [ 'B' ])
1
2
3
4
A variable value
0 a B 1
1 b B 3
2 c B 5
1
pd . melt ( df , id_vars = [( 'A' , 'D' )], value_vars = [( 'B' , 'E' )])
1
2
3
4
(A, D) variable_0 variable_1 value
0 a B E 1
1 b B E 3
2 c B E 5
3.存储数据到数据库
1
2
3
4
import pandas as pd
import sqlite3 as lite
with lite . connect ( 'country_stat.sqlite' ) as db :
df . to_sql ( 'regional_gross_product' , con = db , if_exists = 'replace' , index = None )
4.筛选数据
读取表格(*表示选择所有字段):
1
SELECT * FROM regional_gross_product
1
2
3
with lite . connect ( 'country_stat.sqlite' ) as db :
df2 = pd . read_sql ( 'SELECT * FROM regional_gross_product' , con = db )
print ( df2 . head ())
1
2
3
4
5
6
area year gross_product
0 北京市 2015 23014.59
1 天津市 2015 16538.19
2 河北省 2015 29806.11
3 山西省 2015 12766.49
4 内蒙古自治区 2015 17831.51
筛选行:
1
SELECT * FROM regional_gross_product WHERE year = 2014
1
2
3
with lite . connect ( 'country_stat.sqlite' ) as db :
df2 = pd . read_sql ( 'SELECT * FROM regional_gross_product WHERE year=2014' , con = db )
print ( df2 . head ())
1
2
3
4
5
6
area year gross_product
0 北京市 2014 21330.83
1 天津市 2014 15726.93
2 河北省 2014 29421.15
3 山西省 2014 12761.49
4 内蒙古自治区 2014 17770.19
筛选字段:
1
SELECT area , gross_product FROM regional_gross_product
1
2
3
with lite . connect ( 'country_stat.sqlite' ) as db :
df2 = pd . read_sql ( 'SELECT area,gross_product FROM regional_gross_product' , con = db )
print ( df2 . head ())
1
2
3
4
5
6
area gross_product
0 北京市 23014.59
1 天津市 16538.19
2 河北省 29806.11
3 山西省 12766.49
4 内蒙古自治区 17831.51
5.排序数据
排序数据(DESC为降序排列,默认为升序排列):
1
SELECT * FROM regional_gross_product ORDER BY gross_product DESC
1
2
3
with lite . connect ( 'country_stat.sqlite' ) as db :
df3 = pd . read_sql ( 'SELECT * FROM regional_gross_product ORDER BY gross_product DESC' , con = db )
print ( df3 . head ())
1
2
3
4
5
6
area year gross_product
0 广东省 2015 72812.55
1 江苏省 2015 70116.38
2 广东省 2014 67809.85
3 江苏省 2014 65088.32
4 山东省 2015 63002.33
取得前三排行的数据:
1
SELECT * FROM regional_gross_product ORDER BY gross_product DESC LIMIT 3
1
2
3
with lite . connect ( 'country_stat.sqlite' ) as db :
df3 = pd . read_sql ( 'SELECT * FROM regional_gross_product ORDER BY gross_product DESC LIMIT 3' , con = db )
print ( df3 . head ())
1
2
3
4
area year gross_product
0 广东省 2015 72812.55
1 江苏省 2015 70116.38
2 广东省 2014 67809.85
6.聚合数据
使用Group By聚合数据:
1
SELECT area , AVG ( gross_product ) as avg_gross_product FROM regional_gross_product GROUP BY area
1
2
3
4
5
#按area求分组平均
with lite . connect ( 'country_stat.sqlite' ) as db :
df4 = pd . read_sql ( 'SELECT area,AVG(gross_product) as avg_gross_product FROM regional_gross_product GROUP BY area' ,
con = db )
print ( df4 . head ())
1
2
3
4
5
6
area avg_gross_product
0 上海市 17923.525
1 云南省 8531.537
2 内蒙古自治区 12403.454
3 北京市 15362.376
4 吉林省 9535.298
使用Having挑选出平均生产总值为10000以上的地区:
1
SELECT area , AVG ( gross_product ) as avg_gross_product FROM regional_gross_product GROUP BY area HAVING avg_gross_product >= 10000
1
2
3
4
5
with lite . connect ( 'country_stat.sqlite' ) as db :
df4 = pd . read_sql (
'SELECT area,AVG(gross_product) as avg_gross_product FROM regional_gross_product GROUP BY area HAVING avg_gross_product >= 10000' ,
con = db )
print ( df4 . head ())
1
2
3
4
5
6
area avg_gross_product
0 上海市 17923.525
1 内蒙古自治区 12403.454
2 北京市 15362.376
3 四川省 19307.193
4 天津市 10408.911
7.代码地址
SQL Query的使用
8.参考资料
Pandas 的melt的使用 pandas.melt