本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
自从AlexNet赢得了ImageNet2012比赛之后,该网络框架就被成功应用于各种计算机视觉任务,比如目标检测,分割,人体姿势估计,视频分类,目标追踪以及超分辨率等。这些例子都仅是卷积神经网络成功应用的一小部分而已。
本文,我们探究了两种目前最新技术的结合:残差连接和最新版本的Inception。残差连接对于训练极深网络非常重要。因为Inception网络有发展的更深的趋势,所以添加残差连接可能是个不错的方案。这使得Inception在保留其计算效率的同时可以获得残差方法所带来的所有益处。
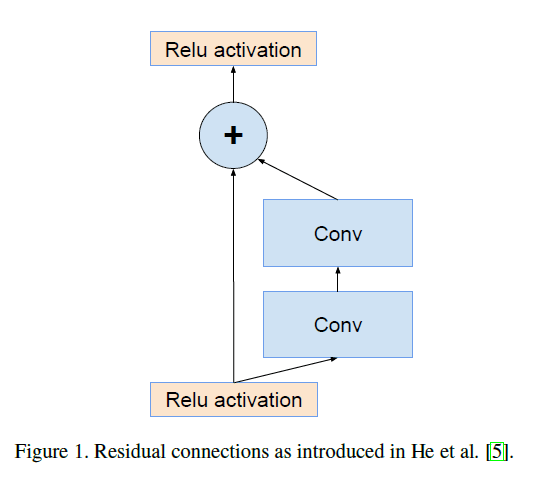
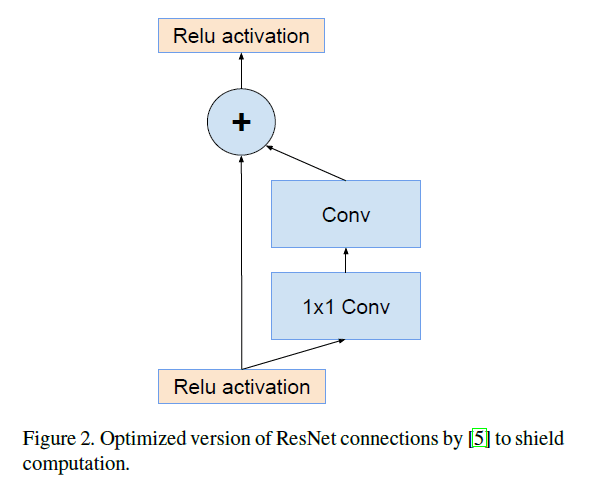
除了直接集成外,我们还研究了Inception模块是否可以通过将其本身变得更深和更宽来变得更高效。出于此目的,我们提出了Inception-v4,相比Inception-v3,Inception-v4的框架更简洁且包含更多的Inception模块。之前版本的Inception框架在技术上的限制主要来自需要使用DistBelief对分布式训练模型进行划分。现在,我们使用TensorFlow以解除这种限制,这使得我们的框架可以更为简洁。在第3部分将会详细介绍这种简洁的框架。
在本文中,我们将比较几种Inception变体:Inception-v3、Inception-v4、Inception-ResNet。在进行比较的时候,我们挑选了和非残差模型的参数和计算复杂度近似的Inception-ResNet。但是我们也在ImageNet数据集上测试了更大更宽的Inception-ResNet。
本文最后一个实验是对模型集成的一个评估。Inception-v4和Inception-ResNet-v2的表现都很好,都超过了以前SOTA的方法。但是令我们惊讶的是,单个模型的增益并没有给模型集成带来大的增益。不过我们依然使用4个模型的集成在验证集上取得了3.1%的top-5错误率,目前这是我们已知的最优结果。
本文的最后一部分我们讨论了一些分类失败的case,得出的结论是集成模型仍无法解决数据集中的标签噪声(个人理解:训练集中标签有错的),预测结果仍有提升的空间。
2.Related Work
介绍他人相关工作。
作者提出在图像分类任务中,他们的实验结果似乎并不支持ResNet的观点(即残差连接对训练极深网络是非常重要的)。不过作者认为可能需要更多的实验才能验证这一观点的正确性。在实验部分,我们验证了即使不要残差连接,训练相当深的网络也不是很困难。我们使用残差连接的理由是其可以大大提升训练速度。
作者将Going deeper with convolutions称之为GooLeNet或Inception-v1,Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift称之为Inception-v2,Rethinking the Inception Architecture for Computer Vision称之为Inception-v3。
Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift一文中并没有使用Inception-v2的字眼,而是称提出的框架为BN-Inception。Rethinking the Inception Architecture for Computer Vision一文中则是提出了Inception-v2以及Inception-v3,这里和本文作者的命名有差异。
3.Architectural Choices
3.1.Pure Inception blocks
这里的pure指的是只使用Inception模块,没有引入残差连接。
Inception框架是高度可调的,这意味着不同层中的filter数量可能会有很多变化,这些变化不会影响经过充分训练的网络的质量。Inception-v4的整体框架见下:

Fig9中的Stem结构见下:
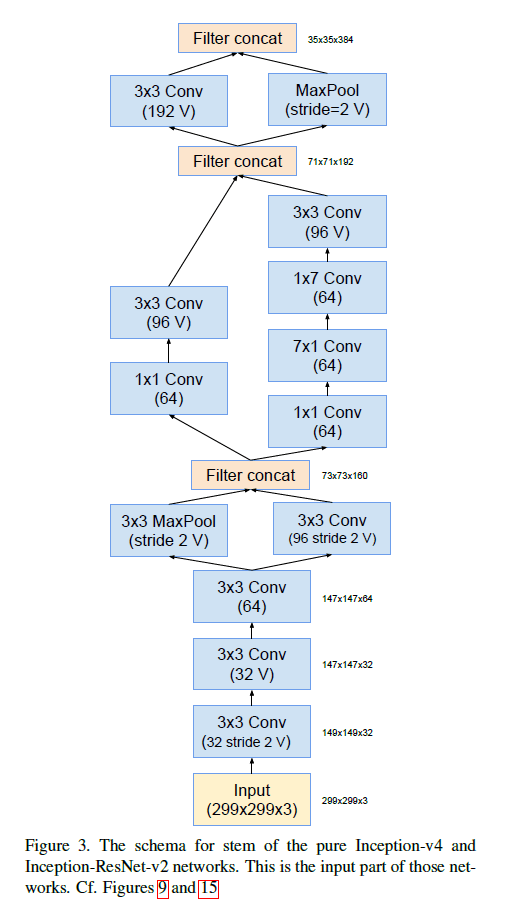
Fig9中的Inception-A结构见下:

Fig9中的Inception-B结构见下:
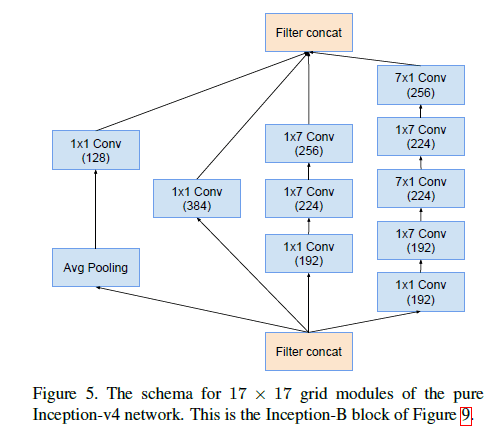
Fig9中的Inception-C结构见下:

Fig9中的Reduction-A结构见下:
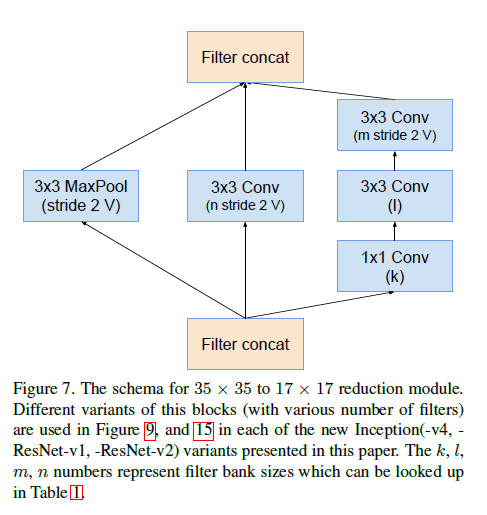
Inception-v4、Inception-ResNet-v1和Inception-ResNet-v2均使用了Reduction-A的不同变体(即不同的filter数量),详见表1。Fig7中的k,l,m,n表示filter的数量。

Fig9中的Reduction-B结构见下:
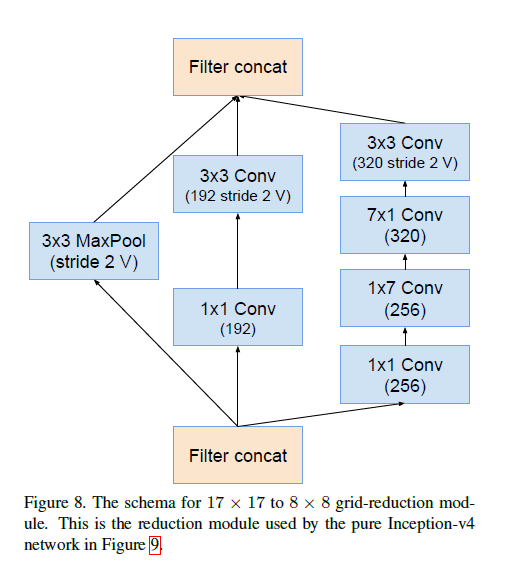
图中的标记“V”表示padding方式为VALID,未标记“V”则表示padding方式为SAME。
3.2.Residual Inception Blocks
对于残差版本的Inception网络,我们使用相比原始Inception更为廉价的Inception block。每个Inception block后都跟一个不使用激活函数的$1\times 1$卷积层(称为filter-expansion layer)用于缩放维度。
我们尝试了几种不同的Inception-ResNet。这里详细的介绍两种,一个是Inception-ResNet-v1(和Inception-v3的计算成本相近),另一个是Inception-ResNet-v2(和Inception-v4的计算成本相近)。Inception-ResNet-v1/v2的结构见下:
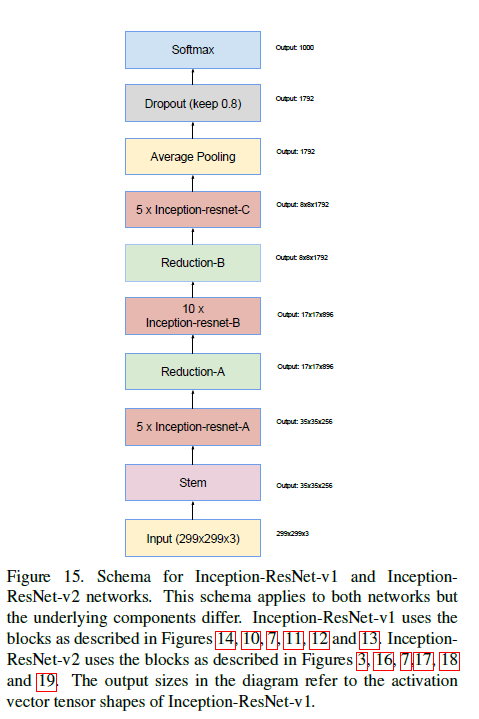
Inception-ResNet-v1/v2使用的整体框架是一样的,但是组件细节不同。
Inception-ResNet-v1中Stem的结构见下:

Inception-ResNet-v1中Inception-ResNet-A的结构见下:
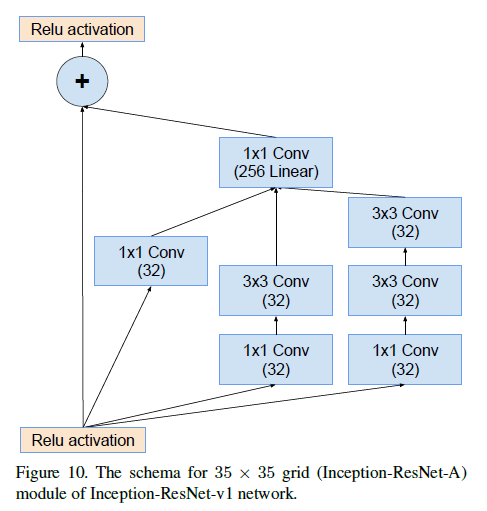
Inception-ResNet-v1中Reduction-A的结构见Fig7。
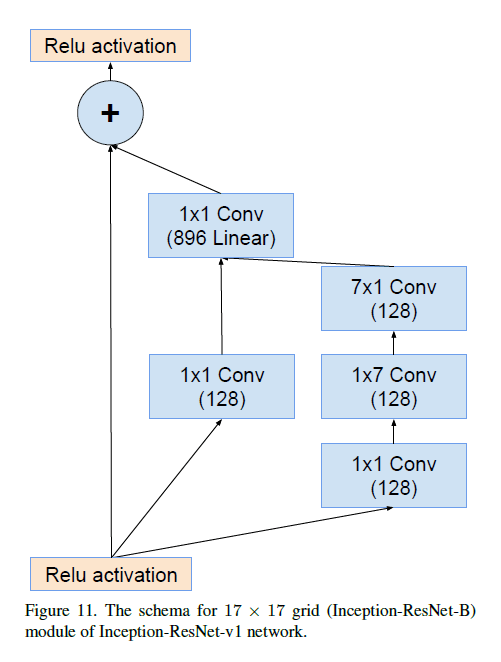
Inception-ResNet-v1中Inception-ResNet-B的结构见下:
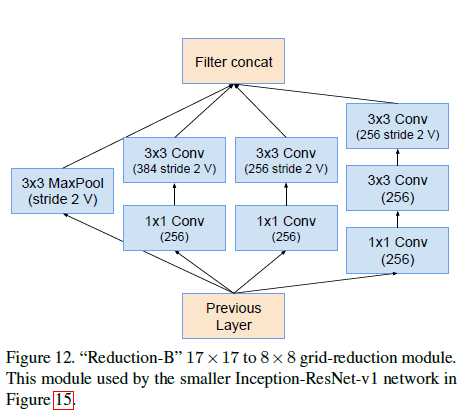
Inception-ResNet-v1中Reduction-B的结构见下(和Inception-v4使用的Reduction-B不一样):
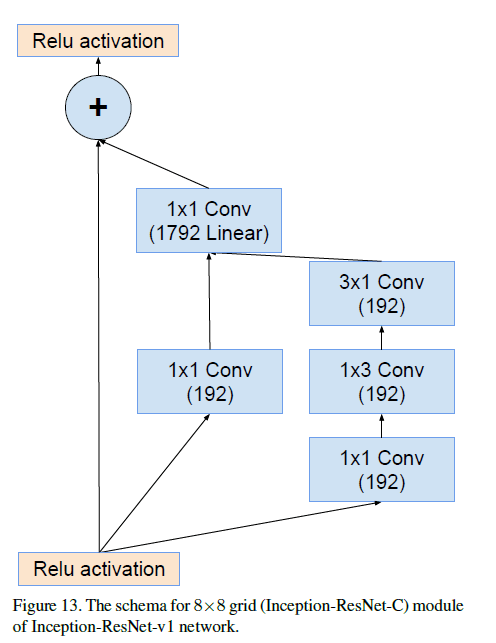
Inception-ResNet-v1中Inception-ResNet-C的结构见下:
Inception-ResNet-v2中Stem的结构见Fig3(和Inception-v4的Stem一样)。
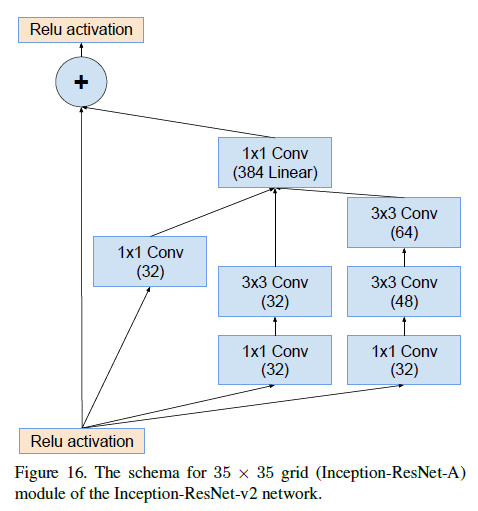
Inception-ResNet-v2中Inception-ResNet-A的结构见下:
Inception-ResNet-v2中Reduction-A的结构见Fig7。
Inception-ResNet-v2中Inception-ResNet-B的结构见下:
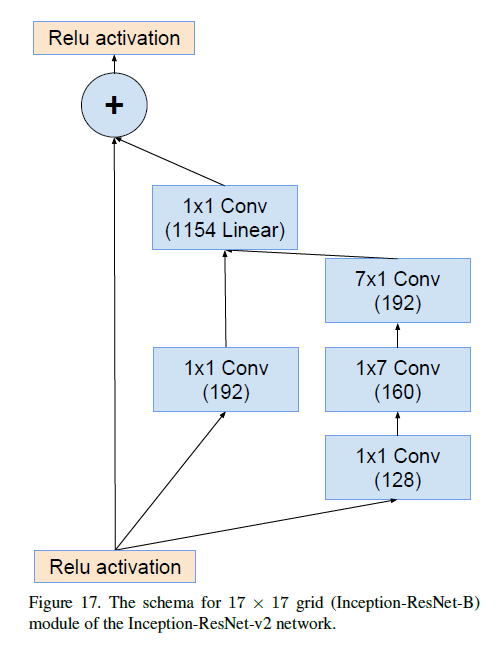
Inception-ResNet-v2中Reduction-B的结构见下(和Inception-ResNet-v1以及Inception-v4的Reduction-B都不相同):

Inception-ResNet-v2中Inception-ResNet-C的结构见下:
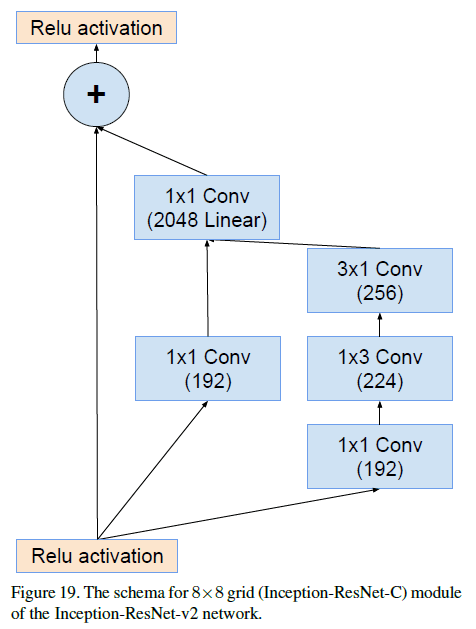
Inception和Inception-ResNet在实现上的另外一个不同之处:对于Inception-ResNet,我们只在顶端的传统卷积层中使用了BN。虽然所有部分都使用BN应该会更好,但是为了使单个模型在一块GPU上训练是可行的,所以才使用了这种策略。结果证明较大激活值的层占了GPU大量资源。因此我们省略部分层的BN以能够显著增加Inception block的数量。如果GPU资源充沛,就没必要采取这种策略了。
3.3.Scaling of the Residuals
我们发现当filter的数量超过1000时,残差变量(residual variants)开始变得不稳定,并使得网络早期训练就“死亡”。降低学习率和添加BN都无法解决该问题。
因此我们在残差加到上一层激活值前对其进行缩小操作,这使得训练更加稳定。缩小比例通常在0.1到0.3之间。示意图见Fig20:
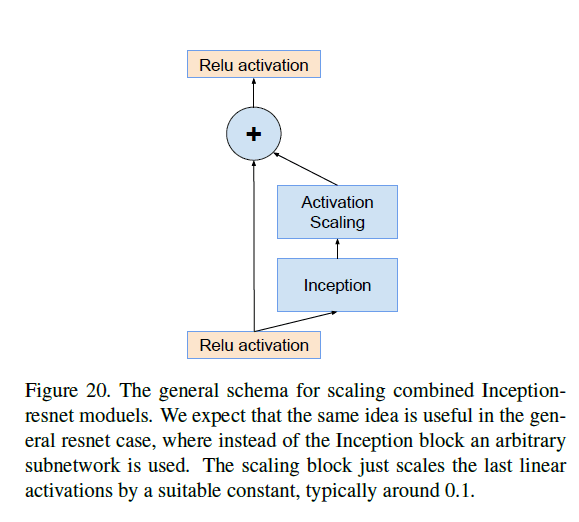
我们期望这种解决办法对普通的ResNet也适用。scaling block仅缩放最后一个线性激活,缩放因子通常为0.1。
在ResNet原文的第4.2部分,ResNet的作者也发现了类型的现象,他们采取的解决办法是two-phase的训练,先用一个较小的学习率(the first “warm-up” phase),然后再使用一个大的学习率(the second phase)。但是我们发现如果filter的数量过多,two-phase的训练依然解决不了不稳定的问题(即使“warm-up”学习率设的足够低,为0.00001)。我们发现还是scale的方法更可靠。
虽然有时scaling不是必要的,但是scaling的存在看起来并不会影响最后的准确率,并且还能帮助稳定训练。
4.Training Methodology
使用TensorFlow,NVidia Kepler GPU。早期的实验中,momentum=0.9。在最优模型中,使用RMSProp(decay=0.9,$\epsilon=1.0$)。初始学习率为0.045,使用指数衰减(exponential rate为0.94),每两个epoch衰减一次。
5.Experimental Results
pure Inception-v3和Inception-ResNet-v1有着近似的计算成本,在ILSVRC-2012的验证集(single crop)上,二者的top-1(Fig21)和top-5(Fig22)错误率变化趋势见下:
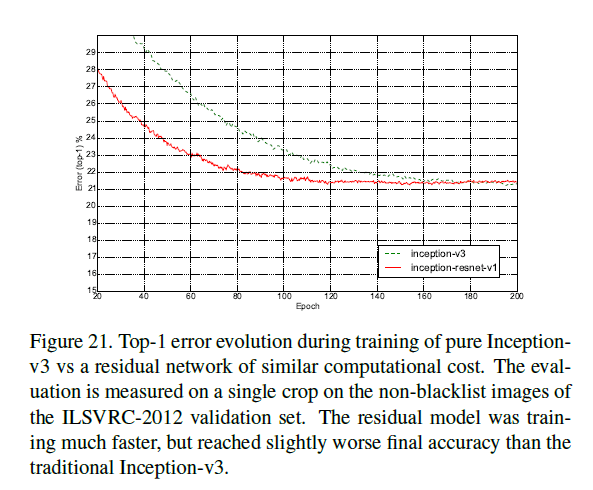
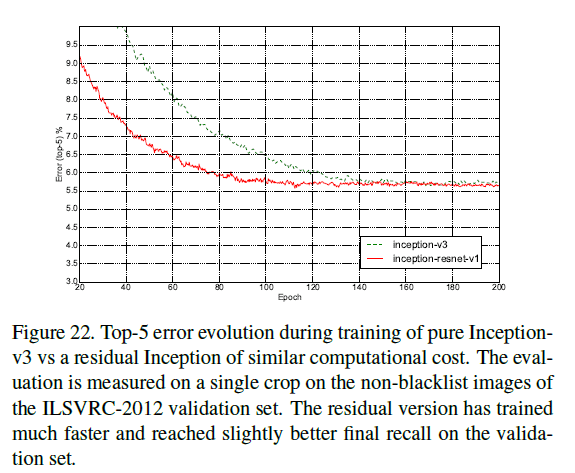
加入残差连接之后,训练速度显著加快。类似的,Inception-v4和Inception-ResNet-v2的计算成本相近,在ILSVRC-2012的验证集(single crop)上,二者的top-1(Fig23)和top-5(Fig24)错误率变化趋势见下:
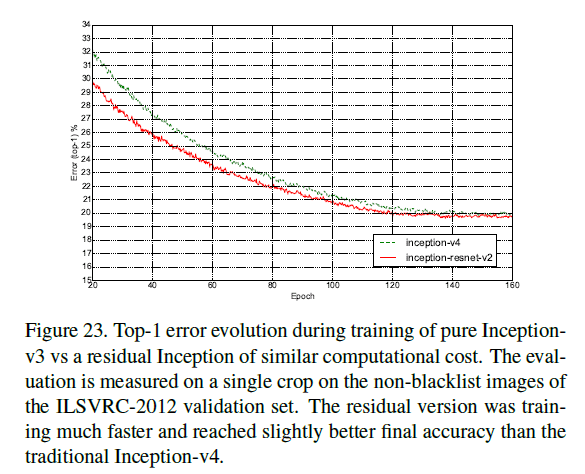
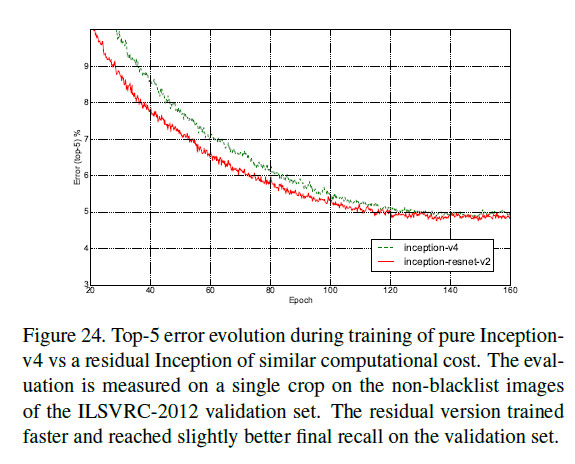
加入残差连接之后,训练速度显著加快,且模型性能有微小的提升。
所有以上四个模型的top-1(Fig26)和top-5(Fig25)错误率变化趋势见Fig25-26(single model+single crop)。Fig25-26展示了模型的size扩大对性能的提升。虽然加入残差连接使得收敛更快,但是模型最终的性能主要还是取绝于模型的size。
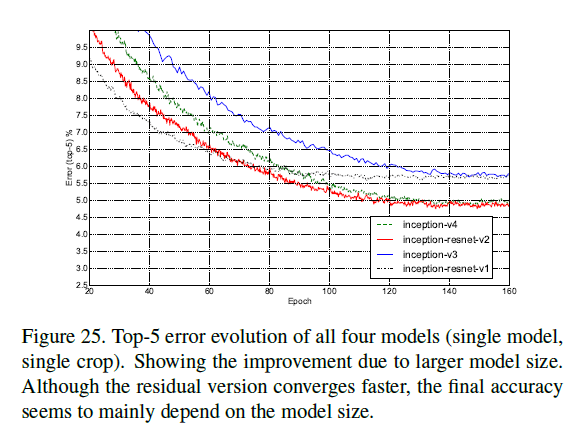
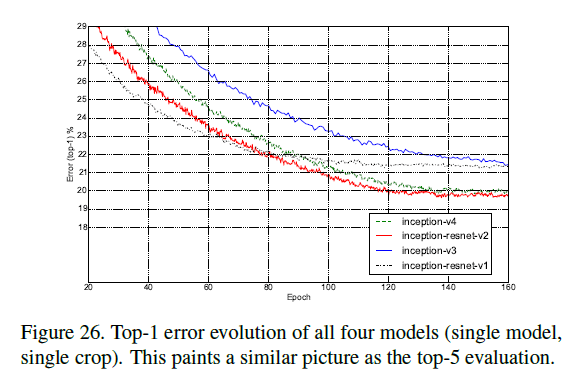
表2是single-model+single crop的top-1和top-5错误率:
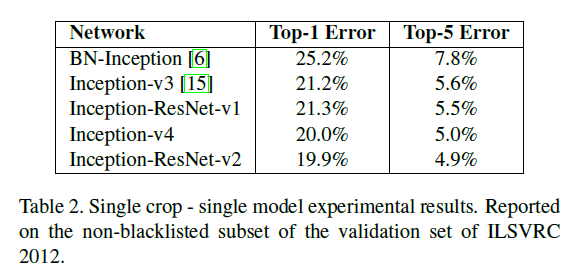
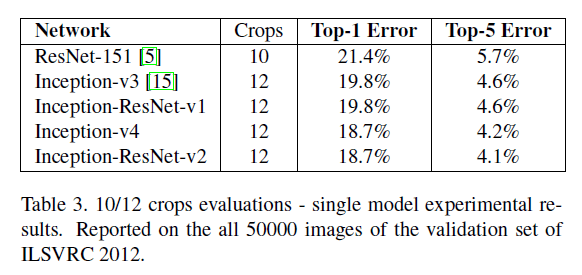
表3是multi-crop的结果,ResNet使用10 crop,Inception使用12 crop:
更多crop的结果:

dense evaluation的介绍请见:链接。
集成模型的结果见表5,ResNet-151使用6个模型的dense evaluation。Inception网络使用4个模型(表5第二行:四个Inception-v3,表5第三行:一个Inception-v4+三个Inception-ResNet-v2)+144 crop:

6.Conclusions
我们介绍了三种新的网络框架:
- Inception-ResNet-v1:一种混合的Inception框架,和Inception-v3有着相近的计算成本。
- Inception-ResNet-v2:计算成本高于Inception-ResNet-v1,但是性能也更好。
- Inception-v4:纯净的Inception变种,未添加残差连接。和Inception-ResNet-v2的识别性能差不多。
我们介绍了残差连接是如何显著提升Inception框架的训练速度的。我们在本文所提出的最新的几个框架(添加或未添加残差连接)都仅仅是增加了模型的size,就获得了比我们之前所有模型都要好的结果。
7.原文链接
👽Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
