本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
目前的CNN网络存在一个技术问题:网络输入必须是固定尺寸(比如$224 \times 224$)。通常通过对原始图像进行crop或者warp来使其满足网络输入的尺寸要求,如Fig1所示。但是crop可能会导致目标裁剪不全,warp则会改变目标原始几何比例。这种信息丢失以及形变会进一步影响模型性能,降低识别准确率。此外,固定的输入尺寸对大小各异的目标来说也是不合适的。

那么为什么CNN网络需要固定的输入尺寸呢?通常来讲,一个CNN网络包含两部分:卷积层和全连接层。卷积层通过滑动窗口的方式产生feature map(见Fig2)。事实上,卷积层并不要求固定的图像大小,其可以产生任意大小的feature map。但是全连接层则需要固定大小的输入。所以问题主要来自全连接层。

在本文中,我们介绍一种新的层,叫做spatial pyramid pooling (SPP) layer来移除网络固定输入大小的限制。通常我们在最后一个卷积层的后面添加一个SPP层。SPP层通过一种特殊的pooling方式处理feature并生成一个固定大小的output,以适配下一个全连接层(见Fig1下)。我们称使用了SPP层的网络为SPP-net。
作者的idea来自人脑对信息的处理,人脑一般都是直接处理整幅图像,而不会去crop或者warp来使其变为固定尺寸。
在CNN流行之前,SPP一直是分类和检测任务中的常胜将军。但是目前还没有人考虑在CNN中应用SPP。我们注意到SPP对于深层CNN有一些益处:1)无所谓input的size,SPP能够产生固定长度的output;2)SPP使用multi-level spatial bins,但是CNN通过滑动窗口的方式进行pooling只使用了单一的window size。并且multi-level pooling对目标形变具有鲁棒性;3)SPP能pool到任意尺寸的feature。实验表明,SPP的这些性质都可以提高深度网络的精度。
SPP-net的灵活性使得我们可以使用完整的图像用于测试。同时,在训练阶段,它可以接收任意大小和比例的输入图像,这增加了比例不变性(scale-invariance,即保持图像原有比例)并减小了过拟合的风险。我们开发了一种multi-size的训练方法以利用SPP-net的特性。并通过一系列的实验验证了使用1)multi-level pooling;2)full-image representations;3)variable scales的好处。基于ImageNet2012数据集,使用SPP(相比不使用SPP的同一网络)可降低1.8%的top-1错误率。我们的方法在Caltech101达到了91.4%的准确率,在Pascal VOC 2007达到了mAP=80.1%(仅使用单张整幅图像进行测试)。
SPP-net在目标检测任务中甚至发挥的更好。对于该领域的优秀算法R-CNN,由于其对每幅图像中数千个warped regions都需要重复的进行卷积运算,因此很耗时。在本文中,我们对于整幅图像只运行一次卷积网络(不管有多少个region proposal)。我们的方法比R-CNN快了100倍以上。根据我们的实验:1)在计算卷积特征方面,SPP-net(基于R-CNN改造)比R-CNN快了30-170倍;2)整体来看,比R-CNN快了24-64倍,并且精度更高。我们通过单模型组合的方式在Pascal VOC 2007检测任务中取得了SOTA的结果(mAP=60.9%)。
2.Deep Networks with Spatial Pyramid Pooling
2.1.Convolutional Layers and Feature Maps
考虑常见的7层卷积网络(例如AlexNet和ZFNet)。前五层是卷积层(部分卷积层后跟有pooling)。其实pooling层也可以看作是一种特殊的卷积层。后两层是FC层,最后是一个N维的softmax输出(N代表类别数)。
这些网络都需要固定大小的输入图像,并且这个固定大小是因为FC层的存在才有了这个限制。也就是说卷积层对输入大小是无所谓的。因为卷积层使用滑动窗口的机制,所以feature map和输入有着大致相同的纵横比。
在Fig2中,我们可视化了第5个卷积层(记为$conv_5$)部分filter生成的feature map。例如Fig2左(b)下为第55个filter得到的feature map,其最能激活箭头所指点的图像见Fig2左(c)下(来自ImageNet数据集),可以看出基本都是一些圆形物体。而Fig2右上,最能激活箭头所指点的是^形结构,Fig2右下为v形结构。
我们生成这些feature map并没有限制输入的大小。并且这些feature map和传统方法(即限制固定大小输入的方法)生成的feature map很相似。
2.2.The Spatial Pyramid Pooling Layer
虽然卷积层可以接受任意大小的输入,但是其输出的大小同样也是不固定的。分类器(例如SVM或softmax)或FC层均需接受固定大小的输入。
我们将$pool_5$替换为spatial pyramid pooling layer,具体结构见Fig3。可以看出,该spatial pyramid有3层(第一层有$4\times 4$个spatial bin,第二层有$2\times 2$个spatial bin,第三层有$1\times 1$个spatial bin),对每一个spatial bin进行pooling操作(这里使用max pooling,其实spatial bin可以看做是执行pooling操作的filter)。spatial pyramid每层的大小和$conv_5$是一致的。假设$conv_5$的输出维度为$13 \times 13 \times 256$,那经过spatial pyramid第一层pooling后得到的输出维度为$4 \times 4 \times 256$,将维度拍扁即可得到$16\times 256$个神经元。剩余两层同理,最终我们可以得到固定的输出大小:$(16+4+1)\times 256$个神经元,此时便可与后续的FC层相连。

通过spatial pyramid pooling,输入的图像可以是任意大小的(任意的ratio和scale)。不同scale对深度网络的精度也是很重要的(作者的意思就是将原始图像resize成固定scale不利于网络的精度)。
2.3.Training the Network with the Spatial Pyramid Pooling Layer
理论上,上述网络结构可以使用标准的后向传播进行训练,无所谓输入图像的大小。但是GPU的实际执行(比如convnet或Caffe)更倾向于固定的输入大小。因此接下来介绍我们的解决办法。
Single-size training
对于给定尺寸(即single-size)的输入图像(输入图像大小都一样),我们可以事先计算spatial pyramid pooling的bin size。例如通过$conv_5$我们得到的feature map大小为$a \times a$(比如$13\times 13$)。金字塔的某一层有$n\times n$个bin,我们使用滑动窗口进行pooling,窗口的大小为$win = \lceil a/n \rceil$,滑动步长为$str = \lfloor a/n \rfloor$。Fig4展示了3层pyramid pooling的结构。

Fig4中,假设最后一层卷积层为$conv_5$,得到的feature map大小为$13 \times 13$。$[pool3\times 3],[pool2\times 2],[pool1\times 1]$表示bin的数量。sizeX为滑动窗口的大小,stride为滑动窗口的步长(其实大概就是相当于对每个bin执行一次pooling)。
Multi-size training
我们希望SPP可以应用于不同尺寸的输入图像。为了解决不同尺寸图像的训练问题,我们考虑使用一组预先设定的尺寸。在本文中,我们使用两种尺寸($180\times 180$和$224\times 224$)。$180\times 180$不是通过$224 \times 224$裁剪得到的,而是通过$224 \times 224$直接resize得到的,这样就只是分辨率不同,而不会有content或layout的不同。也就是说,我们使用了两种预定输入尺寸训练了SPP网络。
Single-size training指的是使用单一输入尺寸来训练SPP,Multi-size training指的是使用多种不同输入尺寸来训练SPP。
为了降低不同尺寸来回切换造成的计算开销,我们一个epoch只使用一种尺寸(例如$224 \times 224$),然后下一个epoch再使用另一个尺寸(例如$180\times 180$)。并且通过实验发现,Single-size training和Multi-size training的收敛速度差不多。我们总共训练了70个epoch。
Multi-size training的主要目的是为了模拟不同尺寸的输入。理论上我们可以使用更多不同尺寸和长宽比的图像进行训练。
请注意,Single-size training和Multi-size training只针对训练阶段。在测试阶段,直接喂给SPP-net任意尺寸的图像即可。
3.SPP-net for Image Classification
3.1.Experiments on ImageNet 2012 Classification
我们使用ImageNet 2012分类数据集(1000个类别)训练了我们的模型。我们的训练细节基本和AlexNet、“A. G. Howard. Some improvements on deep convolutional neural network based image classification. ArXiv:1312.5402, 2013.”和ZFNet一样。先将训练图像resize为256,然后从中心和四个角截取$224 \times 224$大小的图像作为输入。图像扩展使用了水平翻转和颜色改变。在两个FC层使用了dropout。起始学习率为0.01,每次当loss不再下降时,将学习率除以10(一共除了两次)。使用GeForce GTX Titan GPU。
作者使用ZFNet作为baseline,见表1,分为fast版本和big版本(详见ZFNet原文的表2)。测试阶段和AlexNet一样,将测试图像扩展为10幅图像,将10幅图像的平均结果作为最终结果。作者自己重现的ZFNet的fast版本(e1)比原文结果(d1)更好。作者分析好的原因在于原文是在$256\times 256$大小的图像下进行$224 \times 224$大小的crop,而作者是在原始尺寸下进行$224 \times 224$大小的crop。
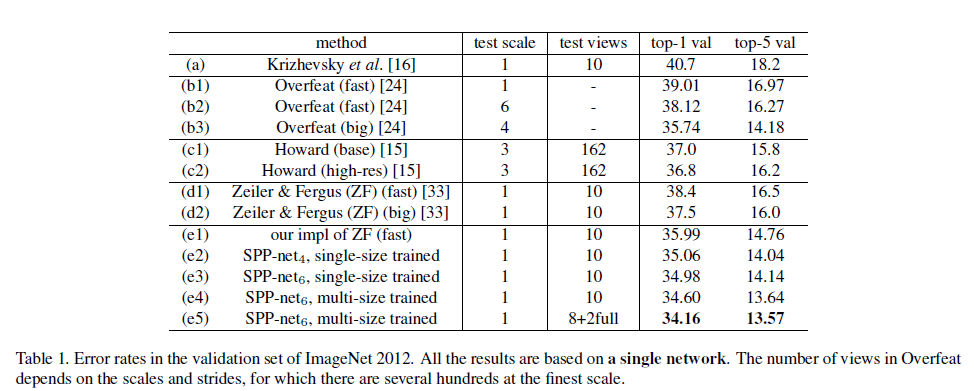
表1中的(e2)(e3)是SPP-net在Single-size training下得到的结果。训练和测试图像都是$224 \times 224$大小的。这两个模型都是基于ZFNet的fast版本实现的(只是添加了SPP layer)。(e2)使用了4层金字塔:$\{4\times 4,3\times 3,2\times 2,1\times 1 \}$(共计30个bin)。(e3)使用了4层金字塔:$\{6\times 6,3\times 3,2\times 2,1\times 1 \}$(共计50个bin)。和(e1)相比,(e2)和(e3)的结果有较大的提升,因为不同之处只有multi-level pooling,所以我们可以说性能的提升是由multi-level pooling造成的。并且,(e2)(FC6的输入为$30\times 256-d$)比(e1)(FC6的输入为$36\times 256-d$)的参数数量更少。因此,multi-level pooling对模型性能的提升并不简单的靠增加参数数量。这是因为multi-level pooling对目标形变和空间布局的变化更具有鲁棒性。
表1中的(e4)展示了multi-size training的结果。training size为224和180,testing size依旧是224。(e3)和(e4)有着一样的网络结构和测试方法,唯一不同的是训练方式,因此我们可以认为(e4)的性能提升是由multi-size training带来的。
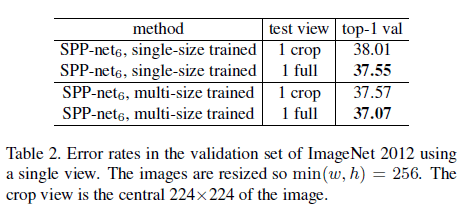
此外,在表2中我们尝试了使用不同size去测试SPP-net。在表2中,1 crop为中心裁剪得到的$224 \times 224$大小的测试图像,1 full为按原图短边resize到256得到的测试图像(长边等比例缩放)。相比1 crop,1 full的top-1错误率更低。相比single-size training,multi-size training的top-1错误率更低。
对于表1中(e5)的测试图像,我们将中心裁剪得到的2个crop换成了全图及其翻转图像。top-1和top-5错误率进一步降低。
3.2.Experiments on Pascal VOC2007 Classification
基于ImageNet数据集训练得到的模型(e5,见表1),我们计算VOC2007分类任务中训练图像的特征向量,并将其用于重新训练一个SVM模型。SVM的训练没有使用数据扩展。对提取到的特征向量进行了L2正则化,并将SVM的软间隔参数C固定为1。
Pascal VOC 2007分类任务包含9963张图像(其中训练集包含5011张图像),共20个类别。性能评估指标为mAP。测试结果见表3:
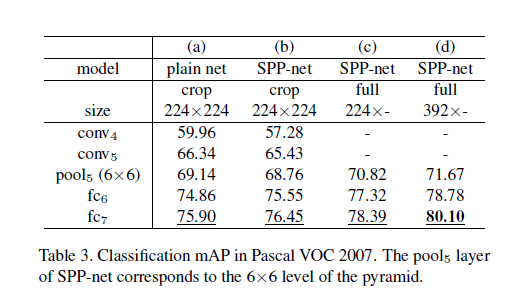
表3(a)为baseline,模型是表1(e1),这里称为plain net。为了使用这个模型,我们将图像的短边resize到224,然后裁剪出$224 \times 224$的区域。训练SVM所用的特征向量基于网络的某一层。从表3中可以看出,提取的特征向量基于的层数越深,效果越好。(b)列使用了SPP-net,并且从原始图像的中心裁剪出$224 \times 224$的区域作为网络输入。我们发现从FC层开始效果优于(a)列,这是由于multi-level pooling导致的。
表3(c)列展示了SPP-net在全图上的结果。直接将原图的短边resize到224(不再裁剪)作为网络的输入。全图输入带来了显著的性能提升(78.39% vs. 76.45%)。
我们还尝试了将原图的短边resize到不同的值(s)。表3(d)列即为s=392的结果。将224调为392,这主要是因为检测目标在VOC 2007中占据较小的区域,但在ImageNet中占据较大的区域。这一调整使得结果进一步提升。
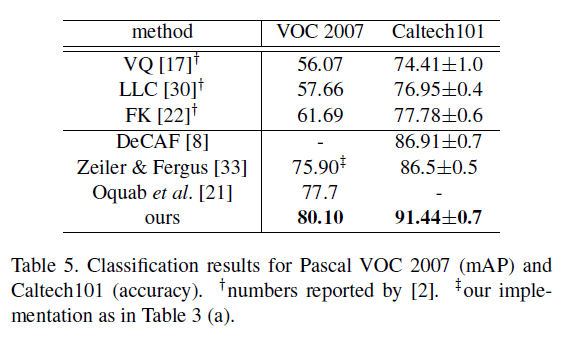
表5展示了我们的方法和先前SOTA方法的比较。VQ、LLC和FK三种方法都是基于spatial pyramids matching,而DeCAF、ZFNet和Oquab则是基于深度学习网络。我们的方法是最优的。Oquab每张图使用了500个view才达到77.7%,而我们只用一张全图view就能达到80.10%。如果再加上数据扩展、multi-view testing和fine-tune,我们的结果会更好。
3.3.Experiments on Caltech101
Caltech101数据集包含9144张图像,共102个类别(其中一类为背景)。每个类别随机挑选30张图像作为训练集,每个类别随机挑选50张图像作为测试集。我们做了10次实验,结果取平均。结果见表4。
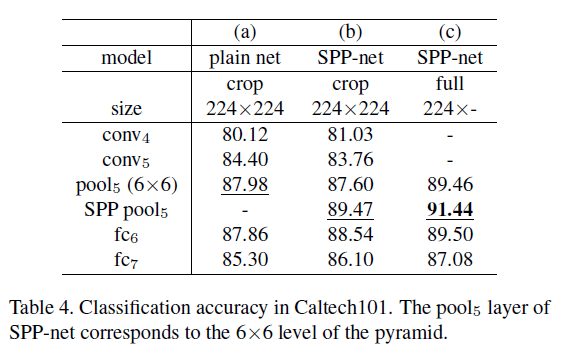
在Caltech101上的测试结果和Pascal VOC 2007上有一些共同点:SPP-net比plain net表现要好,full-view要比crop好。但是二者也有不同的地方:在Caltech101上,FC层的结果不是最优的,$pool_5$和SPP layer的结果更好。这可能是因为Caltech101中的目标与ImageNet相似性较低,而更深的FC层更有针对性。full-view的结果是最优的,scale到$224$是因为Caltech101中的目标和ImageNet中的都比较大。
表5总结了在Caltech101数据集上,我们的方法和先前SOTA方法的比较。我们的方法是最优的。
4.SPP-net for Object Detection
对于目前SOTA的目标检测算法R-CNN,对2000个候选区域分别进行卷积会非常耗时。
而我们的SPP-net也可以应用于目标检测。我们对整图只进行一次特征提取。但是只对候选区域进行spatial pyramid pooling(见Fig5)。因为只进行了一次卷积运算,所以我们的方法相比R-CNN会快很多。
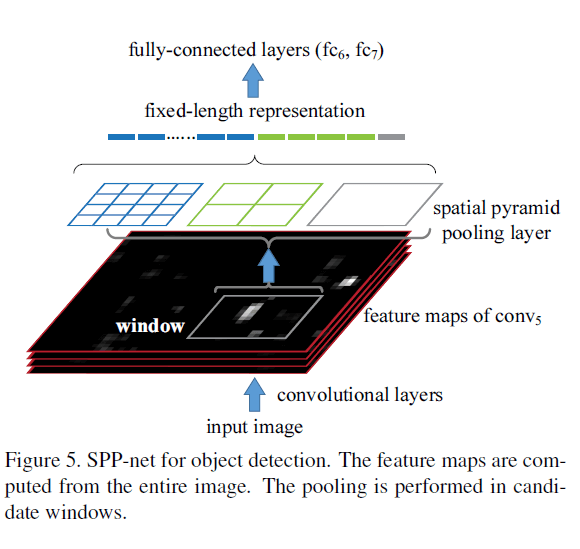
对于Fig5,我们需要找到备选区域在$conv_5$对应的区域,然后只对这一小块区域进行spatial pyramid pooling。
4.1.Detection Algorithm
使用selective search算法产生大约2000个候选区域。然后将输入图像的短边resize到s,通过$conv_5$提取整幅图像的特征向量。我们使用预训练过的表1(e3)中的模型。提取到的特征向量有12800个神经元($256 \times 50$),并将其传给FC层。最后基于网络的输出特征向量也训练了SVM分类器。
SVM分类器的训练按照R-CNN。将GT视为正样本,与GT的IoU低于30%的视为负样本。如果某一负样本与其他负样本的IoU超过70%,则该负样本会被遗弃。我们使用标准的hard negative mining来训练SVM(只迭代一次)。训练20个类别只用了不到1个小时。对最终的预测结果使用NMS(阈值为30%)。
可以通过multi-scale feature extraction来提升模型性能。针对不同大小的输入图像,我们只挑选一个s(s指的是将图像的短边resize到$s=\{ 480,576,688,864,1200 \}$),该s使得备选区域在$conv_5$ feature map上对应部分的大小最接近于$224 \times 224$。因此,相当于是对于每一个s,我们都只是针对全图做了一次卷积运算。
我们按照R-CNN中所用的方式fine-tune了pre-trained的网络。但我们只fine-tune了FC层。添加第8个FC层作为输出,一共有21个神经元,代表21个类别。使用$\sigma=0.01$的高斯分布来初始化$fc_8$的权重。fine-tune时学习率设为$1e-4$,(loss不再降低时)调整为$1e-5$。和GT的IoU在$[0.5,1]$之间的视为正样本,在$[0.1,0.5)$之间的视为负样本。在每一个mini-batch中,有25%为正样本。我们使用$1e-4$的学习率训练了250k个mini-batch,使用$1e-5$的学习率训练了50k个mini-batch。因为我们只fine-tune了三个FC层,所以耗时很短,在GPU上跑两个小时就结束了。并且,我们也使用了bounding box回归,回归所用的同样也是从$conv_5$提取到的特征。和同一GT的IoU超过50%的bounding box将用于回归训练。
4.2.Detection Results
我们使用Pascal VOC 2007检测任务的数据集来评估我们的方法。结果见表6(更详细的结果见表7)。1-sc表示我们只使用一个s(=688);5-sc表示我们使用5个s。如果网络只到$pool_5$(即后面没有$fc_6,fc_7$,直接跟21个神经元的输出层),我们的方法优于R-CNN(44.9% vs. 44.2)。但是如果到$fc_6$,则我们的结果差于R-CNN。但是如果我们fine-tune了$fc_6$(即$ftfc_6$),我们的结果依然优于R-CNN。我们最终最优的mAP是59.2,略优于R-CNN的58.5%。表8展示了每一种类别的结果。我们的方法在11个类别上的结果优于R-CNN,有2个类别和R-CNN表现一样。Fig6展示了在VOC 2007测试集上的结果。
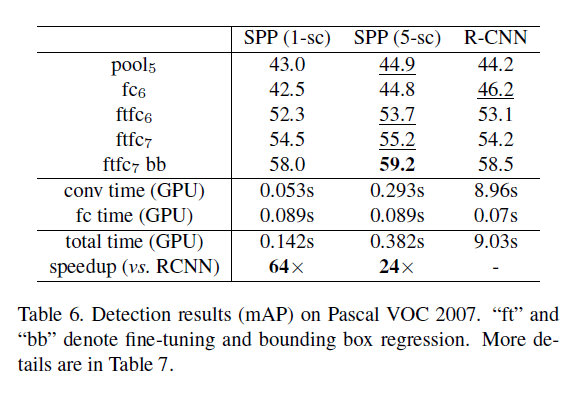
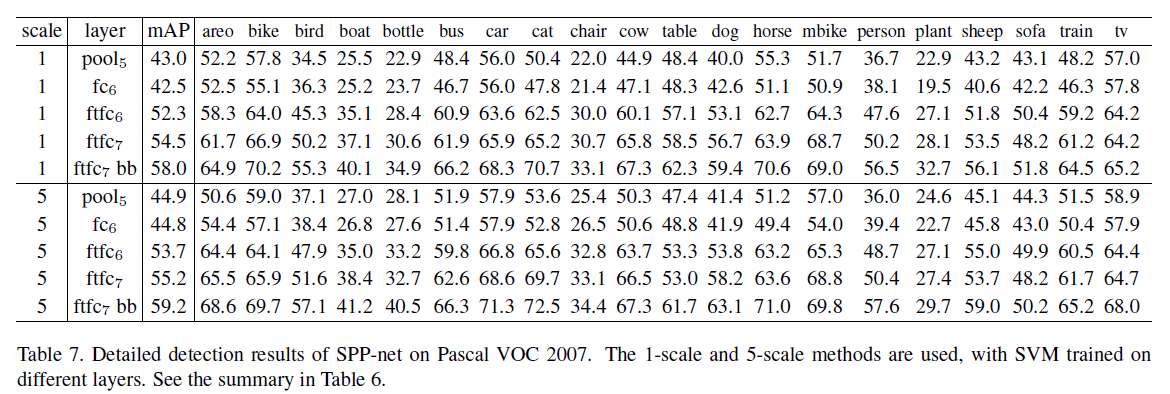
Fig6是SPP-net ftfc7 bb在Pascal VOC 2007测试集上的结果展示(mAP=59.2%)。所有得分大于0的window都显示出来了。

在表8中,我们还与其他方法进行了比较。

4.3.Complexity and Running Time
尽管我们的方法和R-CNN在mAP方面没有特别大的差异,但是我们算法的推理速度远快于R-CNN。算法推理时间的比较结果见表6。在表6中,我们没有考虑生成备选区域的时间。
4.4.Model Combination for Detection
接下来考虑多模型集成。在ImageNet上预训练了另外一个模型(即表9中的SPP-net(2)),该模型结构和本部分所用模型一模一样,训练方式也一模一样,唯一不同在于随机初始化的权重。结果见表9。

集成策略是:将两个模型的结果放在一起进行NMS。因为两个模型具有一定的互补关系,所以集成的结果有了进一步的提升。
5.Conclusion
对全文的总结,不再赘述。
6.原文链接
👽Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
