本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
人类只要看一眼图像立马就能知道图像里有几个object,分别是什么以及在哪里。人类的视觉系统是快速且准确的,可以让我们完成各种复杂的任务。一个快速且准确的目标识别算法可以在不借助传感器的前提下就能实现自动辅助驾驶。
现在的目标检测系统大多是先检测到目标的位置,然后通过一个分类器来确定目标的类别。比如DPM算法,其在整幅图像上进行滑动窗口,然后对每个窗口都进行分类。
DPM原文:P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010.。
最近的一些方法,比如R-CNN,先产生可能的proposal,然后再在这些proposed box上运行分类器。在分类完成后,还需要再对bounding box进行微调并去除重复的检测结果。整个流程很慢且难以优化(因为每个部分都得单独训练)。
我们将整个过程简化为one-stage,直接从图像得到bounding box和类别概率。即You Only Look Once(YOLO)。
YOLO的结构很简单,见Fig1。只依靠一个卷积网络就同时预测出多个bounding box及各box的类别概率。YOLO直接在full image上进行训练。和传统的目标检测方法相比,YOLO有多个优点。

Fig1展示了YOLO检测的过程:1)将输入图像resize到$448 \times 448$;2)运行一个CNN;3)根据模型置信度设立阈值并输出检测结果。
YOLO的第一个优点就是快。没有复杂的pipeline。在Titan X GPU上,我们的base network可以达到45fps,fast version甚至可以达到150fps。完全满足了实时性要求。并且,YOLO的平均精度是其他实时检测系统的两倍多。YOLO实时检测的一个demo:http://pjreddie.com/yolo/。
YOLO的第二个优点:YOLO在预测时,会对图像进行全局性的分析。和滑动窗口、region proposal-based的方法不同,YOLO在训练和测试时都能看到整幅图像并捕获到context信息。Fast R-CNN就是因为看不到更大的context,所以有时会误把背景当作object。而YOLO误将背景预测为object的情况比Fast R-CNN少了一半。
YOLO的第三个优点是其学到了object更为泛化的表达(generalizable representations)。比如在natural images上进行训练,而在artwork上进行检测,YOLO的表现远远优于其他顶级检测方法(比如DPM和R-CNN)。也就是说YOLO具有更好的泛化性能。
但是YOLO的精度还是不如一些SOTA的目标检测算法,虽然YOLO可以快速的识别出图像中的object,但是其定位可能不是特别准确,尤其是小的object。我们在实验中也探讨了速度和精度之间的权衡。
所有的训练和测试代码都是开源的。同时也提供预训练模型的下载。
2.Unified Detection
我们将目标检测中多个分离的component统一为一个神经网络。我们的网络使用由整幅图像得到的features来预测每个bounding box。这意味着我们的网络会对整幅图像以及整幅图像内所有的object进行全局推理。YOLO提供end-to-end的训练以及实时性的速度,average precision也维持在一个比较高的水平。
我们的算法将输入图像划分为$S \times S$的网格(grid)。如果某一object的中心落在了某一grid cell内,则该grid cell负责预测这个object。
每个grid cell可预测$B$个bounding box及其对应的confidence score。我们将confidence score定义为$\text{Pr}(\text{Object} ) * \text{IOU}_{\text{pred}}^{\text{truth}}$。如果cell内没有object,则confidence score应该为0。否则,我们希望confidence score等于predicted box和ground truth之间的IoU。
个人理解:也就是说如果cell内没有object,则$\text{Pr}(\text{Object} )=0$;如果cell内存在object,则$\text{Pr}(\text{Object} )=1$。
每个bounding box对应5个预测值:$x,y,w,h$和confidence。
每个grid cell还负责预测(属于该cell的)object属于各个类别(类别数量为$C$)的概率:$\text{Pr} ( \text{Class}_i \mid \text{Object} )$。这些概率是条件概率,是基于该cell包含object的概率基础上计算的。不管一个grid cell内包含几个bounding box,我们都只预测一组类别概率。 在test time,每个box属于某一类别的概率计算如下:
\[\text{Pr} ( \text{Class}_i \mid \text{Object} ) * \text{Pr}(\text{Object}) * \text{IOU}_{\text{pred}}^{\text{truth}} = \text{Pr} ( \text{Class}_i ) * \text{IOU}_{\text{pred}}^{\text{truth}} \tag{1}\]我们在PASCAL VOC上测试了YOLO,设置$S=7,B=2$。PASCAL VOC一共有20个带标签的类别(这20个类别不包含背景),所以有$C=20$。最终输出为$7\times 7 \times 30$的tensor。
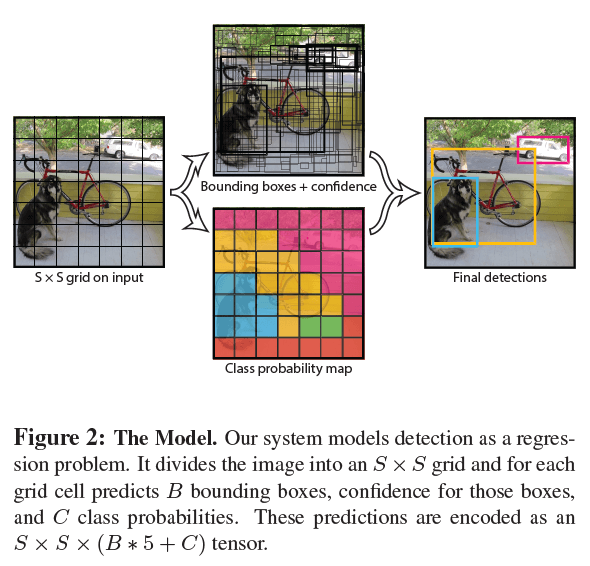
上述流程的示意图见Fig2。最终输出的维度为$S \times S \times (B * 5 + C)$。
2.1.Network Design
我们的网络结构受到了GoogLeNet的启发。我们的网络有24个卷积层和2个FC层。我们并没有使用GoogLeNet的Inception模块,我们只是简单的在$3\times 3$卷积层后接一个$1 \times 1$卷积层。网络结构见Fig3。

个人理解:先将$7 \times 7 \times 1024$的卷积层和$4096$的FC层相连,然后$4096$的FC层连接到一个$1470$的FC层,最后将这个$1470$的FC层再reshape成$7 \times 7 \times 30$。
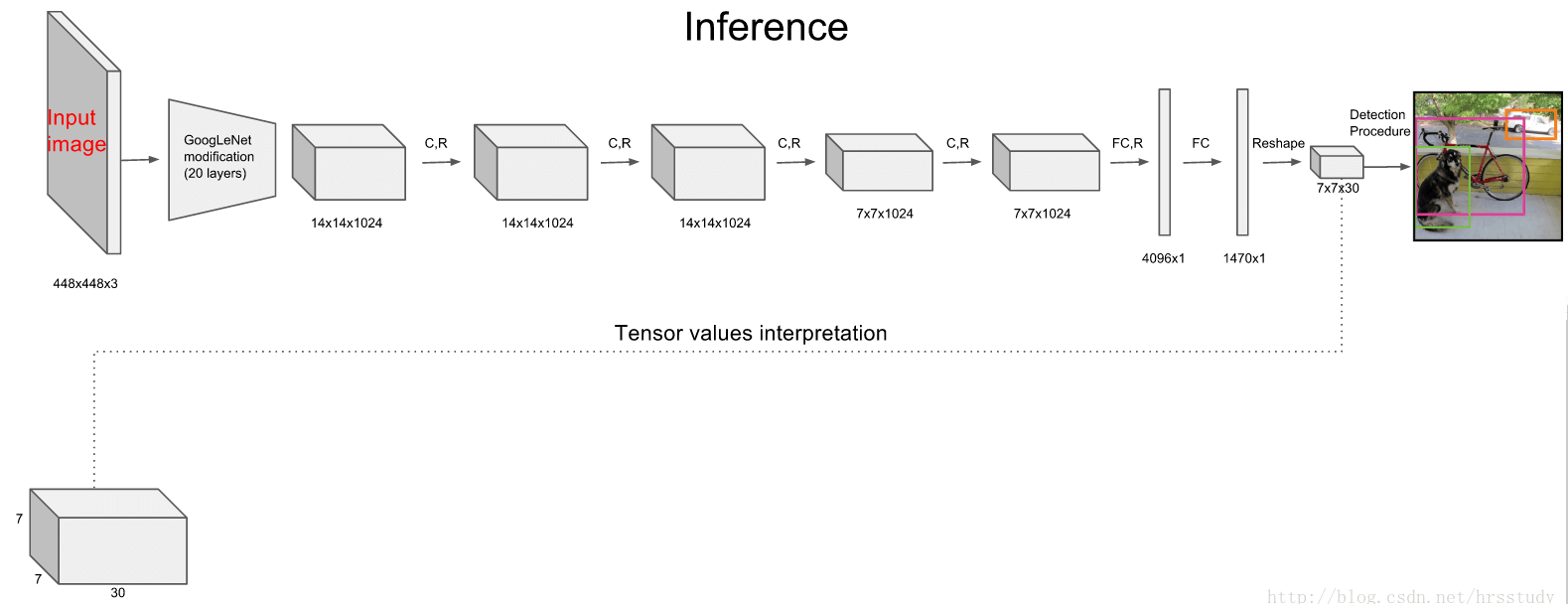
我们的模型在ImageNet上进行了pretrain。
我们还训练了一个fast version的YOLO,使用更少的卷积层(9个卷积层)和filter。除了size上的不同,Fast YOLO和YOLO的训练以及测试参数都是一样的。
2.2.Training
我们在ImageNet上pretrain了卷积层。预训练使用的网络结构为:YOLO的前20个卷积层+一个average-pooling层+一个FC层。我们训练了将近一周的时间,在ImageNet2012验证集上的single crop top-5准确率为88%。
然后我们在预训练网络的基础上进行结构优化,文献“S. Ren, K. He, R. B. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. CoRR, abs/1504.06066, 2015.”证实给预训练网络同时添加卷积层和全连接层有利于性能提升。因此,我们给预训练网络添加了4个卷积层和2个FC层(权重随机初始化)。检测通常需要细粒度(fine-grained)的视觉信息,因此我们将网络的输入分辨率从$224 \times 224$提升至$448 \times 448$。
我们用原始图像的width和height归一化了bounding box的width和height,使其范围都在0~1之间。bounding box的$x,y$为相对于其所在的grid cell的offset,范围同样也在0~1之间(个人理解:例如grid cell左上角为$(0,0)$,右下角为$(1,1)$,那么bounding box的$x,y$就可以用0~1范围内的数表示了)。
最后一层使用线性激活函数,其他所有层都使用Leaky ReLU:
\[\phi (x) = \begin{cases} x, & \text{if} \ x>0 \\ 0.1x, & \text{otherwise} \end{cases} \tag{2}\]我们使用平方和的形式来计算error。我们使用平方和误差(sum-squared error)是因为它容易被优化,但是它并不能满足我们最大化average precision的目标。它将localization error和classification error视为一样的权重。每一幅图像都存在大量的grid cell,其不包含任何object。这些grid cell的score都趋近于0,导致模型不稳定,训练不容易收敛。
为了解决这个问题,我们增加了bounding box坐标预测的loss,减少了对不包含object的box的置信度预测的loss。因此我们引入了两个参数:$\lambda_{coord}=5,\lambda_{noobj}=0.5$。
对于大box和小box,平方和误差平等对待,即赋予一样的权重。但实际上,大box对于小偏差的容忍度应该比小box要高。所以我们在计算loss时使用了bounding box的width和height的平方根以部分解决这个问题。
YOLO针对每个grid cell会预测多个bounding box。在训练阶段,和GT的IoU最大的bounding box为该grid cell所负责类别的预测box。
训练阶段,我们所用的loss function见下:

其中,$\mathbb{1}_i^{obj}$表示第$i$个grid cell内是否存在object(个人理解:存在为1,不存在为0)。$\mathbb{1}_{ij}^{obj}$表示第$i$个grid cell中的第$j$个bounding box被选择为该object的预测结果(个人理解:如果这个bounding box负责对该object的预测,则该项为1,否则为0)。
loss function的拆解见下:
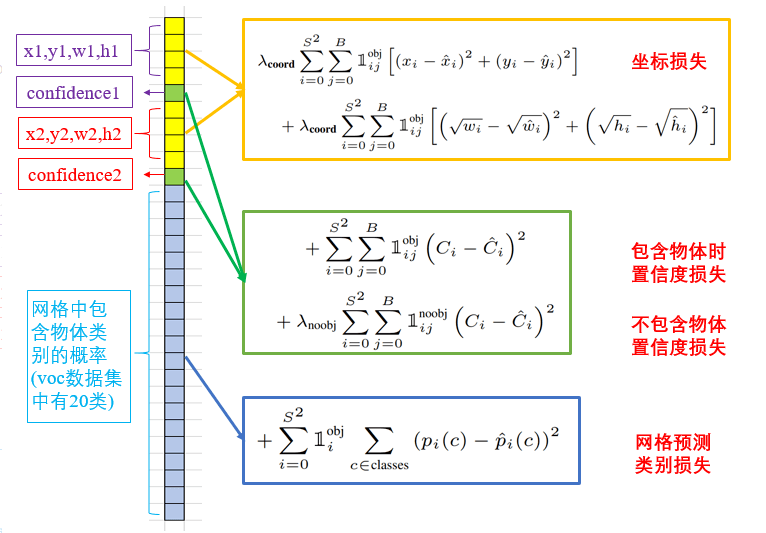
黄色框为localization loss,绿色框为confidence loss,蓝色框为classification loss。localization loss部分比较简单明了,每个grid cell,只考虑负责object预测的那个box。confidence loss部分,$C_i$就是该box可能包含object的概率再乘上一个和GT的IoU(见前文confidence score的定义),个人理解$\hat{C}_i$指的是如果存在object,该项就为1(这样就迫使$C_i$在预测是否有object的准确率上以及预测出来的box都朝着更准确的方向前进),否则就为0。classification loss部分,$p_i(c)$为该grid cell内的object属于每个类别的概率,$\hat{p}_i(c)$为GT,即只有一个类别为1,其他类别标记为0。
个人理解:YOLO-v1在网络结构上并没有什么突破,亮点在于loss function。
classification loss部分只考虑了grid cell内存在object的情况。localization loss部分只考虑了负责预测object的那个box。
我们在PASCAL VOC 2007+2012的训练集+验证集上一共训练了135个epoch。此外,在2012数据集上测试时,训练数据还额外添加了VOC 2007的测试集。训练时,batch size=64,momentum=0.9,decay=0.0005。
learning rate schedule为:在第一个epoch中,将学习率从$10^{-3}$缓慢提升至$10^{-2}$(如果我们一开始就使用较大的学习率,会因为梯度的不稳定而没有收敛趋势,因此我们选择在第一个epoch中缓慢的提升学习率)。接着用$10^{-2}$的学习率一共训练75个epoch,然后$10^{-3}$再训练30个epoch,最后$10^{-4}$训练30个epoch。
为了避免过拟合,我们使用了dropout和data augmentation。dropout rate=0.5。对于data augmentation,我们使用了随机缩放和平移。此外,还在HSV颜色空间中随机调整了图像的曝光度和饱和度,最大调整系数为1:5。
2.3.Inference
对于PASCAL VOC数据集,每幅图像可以预测出98个bounding box。
通常情况下,object落在哪个grid cell是清晰明了的,并且每个object只预测出一个box。然而有些时候,对于一些大型object或者object中点接近多个cell的边界时,可能会有多个cell都可以很好的预测这些object,此时可以使用NMS来进一步优化(个人理解:此时就不再是一个object属于一个cell了,一个object可能属于多个cell,最后这个object可能得到多个box预测结果,通过NMS得到最终的box)。虽然NMS对于YOLO的性能提升要小于R-CNN和DPM,但NMS依旧帮助YOLO将mAP提升了2-3%。
2.4.Limitations of YOLO
YOLO的局限性在于每个grid cell只能预测2个bounding box,且只能有一个类别。这种空间限制不利于YOLO检测非常近的一些object,比如一群小鸟(一个grid cell内不能存在多个object)。
因为YOLO从数据中学习预测bounding box,所以在面对一些具有不常见的或没在数据集中出现过的box长宽比或配置的object,YOLO的表现可能并不好。我们的模型还使用相对粗糙的特征来预测bounding box,因为我们的网络结构中有多个下采样层。
对于大bounding box和小bounding box,我们的loss functiong都是一样的处理。但是同样的小误差,对大bounding box的影响要比小bounding box小的多。我们错误的主要来源是错误的localizations(个人理解:分类错误应该不多)。
3.Comparison to Other Detection Systems
目标检测是CV领域内的一个核心问题。检测任务大多从提取输入图像的特征开始(例如Haar,SIFT,HOG,convolutional features)。然后使用这些特征,运行一个classifiers或localizers。这些classifiers或localizers有的是在全图上使用滑动窗口,有的是基于一系列的region。我们将YOLO和一些顶尖的检测方法进行了比较,分析了其之间的相似性和差异性。
作者将YOLO和DPM、R-CNN及其变体、Fast R-CNN、Faster R-CNN、Deep MultiBox、OverFeat、MultiGrasp进行了比较分析,在此不再赘述。
4.Experiments
首先,在PASCAL VOC 2007上,我们比较了YOLO和其他real-time的检测系统。为了更好的理解YOLO和R-CNN变体之间的差异,我们在VOC 2007上比较了YOLO和Fast R-CNN的errors。我们还展示了在VOC 2012上结果。最后,通过两个artwork数据集,我们展示了YOLO相比其他检测算法,具有更好的泛化性能。
4.1.Comparison to Other Real-Time Systems
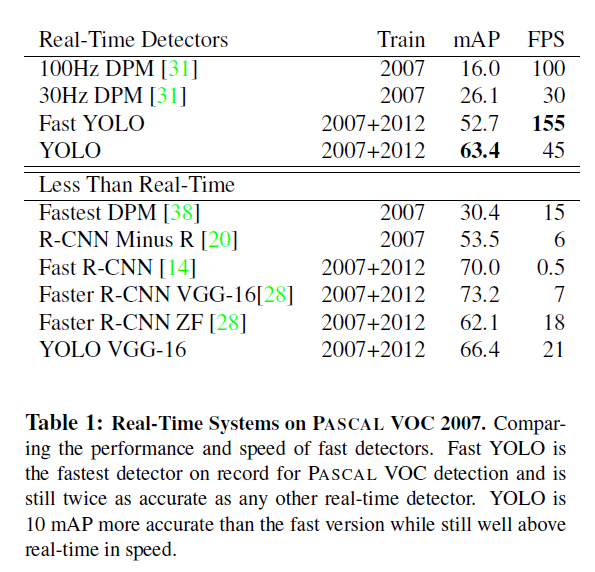
据我们所知,在PASCAL数据集上,Fast YOLO是最快的,并且mAP(52.7%)是其他real-time检测算法的两倍多。YOLO在保证real-time的前提下,将mAP提升至63.4%。
我们还测试了用VGG16来训练YOLO,精度更高但是速度会慢很多。但是仍比其他基于VGG16的非real-time检测模型要快的多。
4.2.VOC 2007 Error Analysis
基于VOC 2007,进一步对比了YOLO和Fast R-CNN,以进行错误分析。
每个类别,我们会看排名前$N$的预测结果。correct和不同error类型的定义见下:
- Correct(即正确的case):预测类别正确,IoU>0.5
- Localization(error类型:定位不准确):预测类别正确,0.1<IoU<0.5
- Similar(error类型:相似类别混淆):预测类别不正确(但是和正确类别相似),IoU>0.1
- Other(error类型:其他):预测类别错误,IoU>0.1
- Background(error类型:将background预测为object):IoU<0.1
20个类别的平均结果见Fig4:
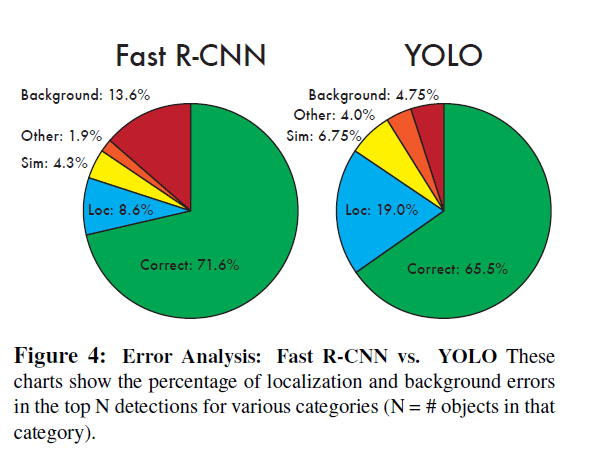
从Fig4中可以看出,YOLO在定位准确方面做的不好。Fast R-CNN的localization error比YOLO低,但是background error更高(假阳率高达13.6%,是YOLO(4.75%)的将近三倍)。
4.3.Combining Fast R-CNN and YOLO
相比Fast R-CNN,YOLO的background error更低。因此我们尝试借助YOLO来降低Fast R-CNN的background error。对于每一个由R-CNN预测出的box,我们都会检查YOLO是否也预测出了相似的box。如果是,那么这个预测结果的可信度就相应增大。基于这种集成策略,我们做了如下实验。
在VOC 2007 test set数据集上,最好的Fast R-CNN模型达到了71.8%的mAP。当结合YOLO后,mAP提升到了75.0%。我们也尝试和其他版本的Fast R-CNN进行了集成,mAP都有0.3%到0.6%的小幅提升。结果见表2:

然而,如果只将不同版本的Fast R-CNN集成却几乎得不到提升。正是因为YOLO和Fast R-CNN的错误类型分布不一样,和YOLO集成才能带来性能的提升。
这种集成策略,两个模型是各自独立运行的,所以耗时也是各算各的。
4.4.VOC 2012 Results
在VOC 2012 test set中,YOLO达到了57.9%的mAP,低于目前SOTA的方法,和R-CNN(VGG-16)的精度接近,见表3。和精度相近的一些方法比较,YOLO难以处理小的object。比如,在bottle、sheep、tv/monitor这三个类别中,相比R-CNN和Feature Edit,YOLO的mAP要低上8%-10%左右。但是在其他类别,比如cat和train,YOLO的精度更高。
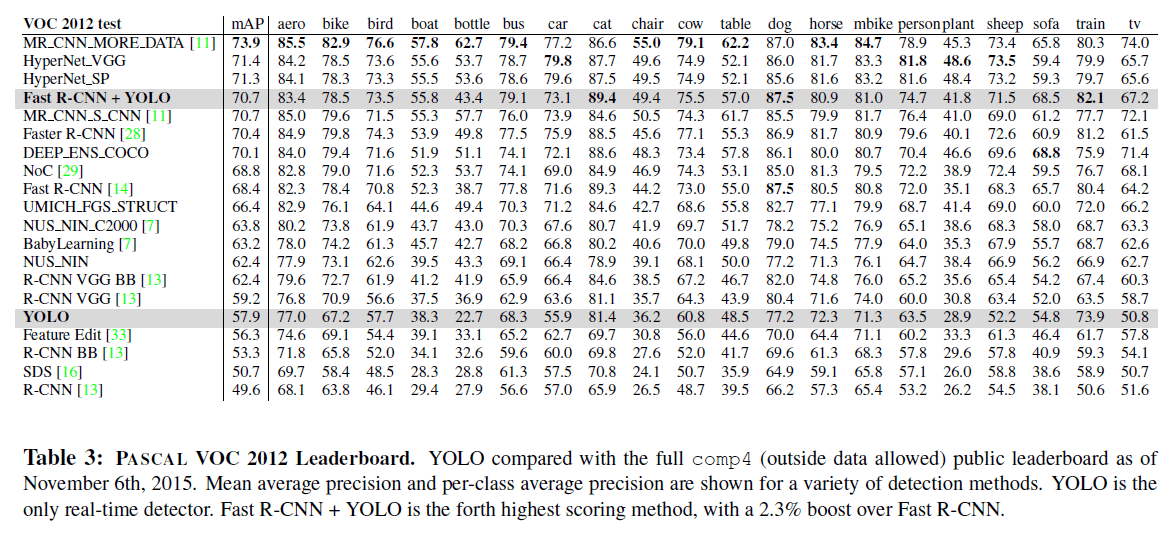
Fast R-CNN+YOLO的模型表现相当不错,mAP达到了70.7%。
4.5.Generalizability: Person Detection in Artwork
除了在真实环境中进行检测,我们还测试了在artwork上对不同object的检测。使用的数据集为the Picasso Dataset和the People-Art Dataset。
结果见Fig5。在Fig5(b)中的VOC 2007列,该列所有模型都只在VOC 2007 data上进行训练,该列只给出person类别的AP。Picasso列的模型都是在VOC 2012上训练的,People-Art列的模型都是在VOC 2010上训练的。
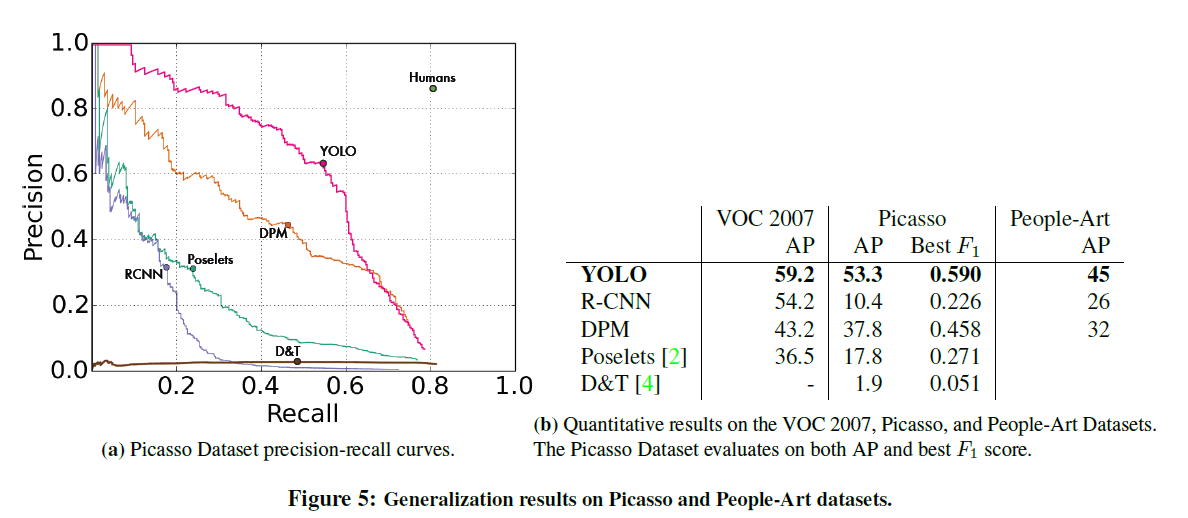
R-CNN在VOC 2007上的AP很高,但是其在artwork上的表现却很不好。DPM在artwork上的表现还不错。YOLO在VOC 2007上的表现也很不错,并且相比其他方法,YOLO在artwork上的表现是最好的,mAP没有过多的降低。

5.Real-Time Detection In The Wild
我们将YOLO连接到网络摄像头以验证其实时检测的能力。demo和源码见:http://pjreddie.com/yolo/。
6.Conclusion
我们介绍了YOLO,一个用于目标检测的模型。我们的模型结构简单且可以直接在full image上进行训练。不像其他classifier-based的方法,YOLO直接在一个loss function上进行训练。 此外,YOLO也推动了实时目标检测技术的发展。
7.原文链接
👽You Only Look Once: Unified, Real-Time Object Detection
