本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.声音分类
使用数据集:URBANSOUND8K DATASET。共包含8732条语音(每条语音的长度均在4秒以内),被标记为10个类别:
1
2
3
4
5
6
7
8
9
10
0 = air_conditioner
1 = car_horn
2 = children_playing
3 = dog_bark
4 = drilling
5 = engine_idling
6 = gun_shot
7 = jackhammer
8 = siren
9 = street_music
我们在实际测试时只用到了上述数据集的一部分。我们使用librosa(一个python包)来处理声音。
👉载入包:
1
2
3
4
5
6
7
8
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import time
import librosa
from tqdm import tqdm
import random
👉定义参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# Parameters
# ==================================================
# Data loading params
# validation数据集占比
tf.flags.DEFINE_float("dev_sample_percentage", .2, "Percentage of the training data to use for validation")
# 父目录
tf.flags.DEFINE_string("parent_dir", "audio/", "Data source for the data.")
# 子目录
tf.flags.DEFINE_list("tr_sub_dirs", ['fold1/', 'fold2/', 'fold3/'], "Data source for the data.")
# Model Hyperparameters
# 第一层输入,MFCC信号
tf.flags.DEFINE_integer("n_inputs", 40, "Number of MFCCs (default: 40)")
# cell个数
tf.flags.DEFINE_integer("n_hidden", 300, "Number of cells (default: 300)")
# 分类数
tf.flags.DEFINE_integer("n_classes", 10, "Number of classes (default: 10)")
# 学习率
tf.flags.DEFINE_float("lr", 0.005, "Learning rate (default: 0.005)")
# dropout参数
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
# Training parameters
# 批次大小
tf.flags.DEFINE_integer("batch_size", 50, "Batch Size (default: 50)")
# 迭代周期
tf.flags.DEFINE_integer("num_epochs", 100, "Number of training epochs (default: 100)")
# 多少step测试一次
tf.flags.DEFINE_integer("evaluate_every", 50, "Evaluate model on dev set after this many steps (default: 50)")
# 多少step保存一次模型
tf.flags.DEFINE_integer("checkpoint_every", 500, "Save model after this many steps (default: 500)")
# 最多保存多少个模型
tf.flags.DEFINE_integer("num_checkpoints", 2, "Number of checkpoints to store (default: 2)")
# flags解析
FLAGS = tf.flags.FLAGS
FLAGS.flag_values_dict()
# 打印所有参数
print("\nParameters:")
for attr, value in sorted(FLAGS.flag_values_dict().items()):
print("{}={}".format(attr.upper(), value))
print("")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
Parameters:
ALSOLOGTOSTDERR=False
BATCH_SIZE=50
CHECKPOINT_EVERY=500
DEV_SAMPLE_PERCENTAGE=0.2
DROPOUT_KEEP_PROB=0.5
EVALUATE_EVERY=50
LOG_DIR=
LOGTOSTDERR=False
LR=0.005
N_CLASSES=10
N_HIDDEN=300
N_INPUTS=40
NUM_CHECKPOINTS=2
NUM_EPOCHS=100
ONLY_CHECK_ARGS=False
OP_CONVERSION_FALLBACK_TO_WHILE_LOOP=False
PARENT_DIR=audio/
PDB_POST_MORTEM=False
PROFILE_FILE=None
RUN_WITH_PDB=False
RUN_WITH_PROFILING=False
SHOWPREFIXFORINFO=True
STDERRTHRESHOLD=fatal
TEST_RANDOM_SEED=301
TEST_RANDOMIZE_ORDERING_SEED=
TEST_SRCDIR=
TEST_TMPDIR=/var/folders/qg/0r2bywpn6s16dsr8j9xyjnm80000gn/T/absl_testing
TR_SUB_DIRS=['fold1/', 'fold2/', 'fold3/']
USE_CPROFILE_FOR_PROFILING=True
V=-1
VERBOSITY=-1
XML_OUTPUT_FILE=
tf.flags的讲解见【Tensorflow基础】第十四课:CNN在自然语言处理的应用。
👉获得训练用的wav文件路径列表:
1
2
3
4
5
6
7
8
9
10
def get_wav_files(parent_dir, sub_dirs):
wav_files = []
for l, sub_dir in enumerate(sub_dirs):
wav_path = os.path.join(parent_dir, sub_dir)
for (dirpath, dirnames, filenames) in os.walk(wav_path):
for filename in filenames:
if filename.endswith('.wav') or filename.endswith('.WAV'):
filename_path = os.sep.join([dirpath, filename])
wav_files.append(filename_path)
return wav_files
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环中:
1
2
3
4
5
6
7
8
9
10
11
12
seasons=['Spring','Summer','Fall','Winter']
list(enumerate(seasons))
#output : [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list(enumerate(seasons,start=1)) #下标从1开始
#output : [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
seq=['one','two','three']
for i,element in enumerate(seq):
print(i,element)
#output :
#0 one
#1 two
#2 three
endswith()方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数“start”与“end”为检索字符串的开始与结束位置。语法为:
1
str.endswith(suffix,start,end)
- suffix为待匹配的后缀。
- start为匹配搜索的str开始位置,默认为0。
- end为匹配搜索的str结束位置,默认为str的最大长度。
举个例子:
1
2
3
4
5
6
7
8
9
str = "this is string example....wow!!!";
suffix = "wow!!!";
print str.endswith(suffix);
print str.endswith(suffix,20);
suffix = "is";
print str.endswith(suffix, 2, 4);
print str.endswith(suffix, 2, 6);
输出为:
1
2
3
4
True
True
True
False
os.sep是为了解决不同平台上文件路径分隔符差异问题,例如在windows平台上,路径分隔符为\;linux平台上为/;mac上是:。那么当在不同平台上使用os.sep时,对应的路径分隔符就分别是以上列举的几种。os.sep.join和os.path.join两个函数传入的参数类型不同,前者是列表(列表中的元素也必须是字符串),后者是多个字符串。两个函数实现的功能基本相同:
1
2
3
import os
os.sep.join(['hello','world']) #'hello/world'
os.path.join('hello','world') #'hello/world'
👉获取文件mfcc特征和对应标签:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def extract_features(wav_files):
inputs = []
labels = []
for wav_file in tqdm(wav_files):
# 读入音频文件
audio, fs = librosa.load(wav_file)
# 获取音频mfcc特征
# [n_steps, n_inputs]
mfccs = np.transpose(librosa.feature.mfcc(y=audio, sr=fs, n_mfcc=FLAGS.n_inputs), [1, 0])
inputs.append(mfccs.tolist())
# 获取label
for wav_file in wav_files:
label = wav_file.split('/')[-1].split('-')[1]
labels.append(label)
return inputs, np.array(labels, dtype=np.int)
我们使用librosa包来载入声音文件并提取mfcc特征(一种广泛使用的语音特征)。tqdm是一个可以显示python进度条的模块。np.transpose的用法见本文第2部分。
👉因为我们要使用GRU模型,因此把输入的每个特征序列都用0填充为统一长度:
1
2
3
4
5
6
7
8
9
10
11
12
# 计算最长的step
wav_max_len = max([len(feature) for feature in tr_features])
print("max_len:", wav_max_len) # 173
# 填充0
tr_data = []
for mfccs in tr_features:
while len(mfccs) < wav_max_len: # 只要小于wav_max_len就补n_inputs个0
mfccs.append([0] * FLAGS.n_inputs)
tr_data.append(mfccs)
tr_data = np.array(tr_data)
tr_features里有2685个feature,即2685条语音的特征序列,可以看作是2685个句子。每个句子里的单词数量(单词可以理解为语音拆分成的帧)不一样,最多的有173个单词,每个单词的词嵌入向量(即每一帧的特征向量)的长度为40,即n_inputs。
👉将数据集打乱并划分为训练集和测试集:
1
2
3
4
5
6
7
8
9
10
11
# Randomly shuffle data
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(tr_data)))
x_shuffled = tr_data[shuffle_indices]
y_shuffled = tr_labels[shuffle_indices]
# Split train/test set
# 数据集切分为两部分
dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y_shuffled)))
train_x, test_x = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
train_y, test_y = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]
np.random.permutation的用法见:【Tensorflow基础】第十四课:CNN在自然语言处理的应用。
👉网络的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# placeholder
x = tf.placeholder("float", [None, wav_max_len, FLAGS.n_inputs])
y = tf.placeholder("float", [None])
dropout = tf.placeholder(tf.float32)
# learning rate
lr = tf.Variable(FLAGS.lr, dtype=tf.float32, trainable=False)
# 定义RNN网络
# 初始化输出层的权值和偏置值
weights = tf.Variable(tf.truncated_normal([FLAGS.n_hidden, FLAGS.n_classes], stddev=0.1))
biases = tf.Variable(tf.constant(0.1, shape=[FLAGS.n_classes]))
# 多层网络
num_layers = 3
def grucell():
cell = tf.contrib.rnn.GRUCell(FLAGS.n_hidden)
cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout)
return cell
cell = tf.contrib.rnn.MultiRNNCell([grucell() for _ in range(num_layers)])
outputs, final_state = tf.nn.dynamic_rnn(cell, x, dtype=tf.float32)
# 预测值
prediction = tf.nn.softmax(tf.matmul(final_state[0], weights) + biases)
# labels转one_hot格式
one_hot_labels = tf.one_hot(indices=tf.cast(y, tf.int32), depth=FLAGS.n_classes)
# loss
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=one_hot_labels))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(cross_entropy)
# Evaluate model
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(one_hot_labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.contrib.rnn.GRUCell用于构建GRU单元,其参数为:
1
2
3
4
5
6
7
8
9
__init__(
num_units,
activation=None,
reuse=None,
kernel_initializer=None,
bias_initializer=None,
name=None,
dtype=None
)
大部分参数和tf.nn.rnn_cell.BasicLSTMCell一样,不再重复解释。参数kernel_initializer和参数bias_initializer可用于权重矩阵和偏置项的初始化。
tf.contrib.rnn.DropoutWrapper用于在RNN中应用dropout,其参数为:
1
2
3
4
5
6
7
8
9
10
11
__init__(
cell,
input_keep_prob=1.0,
output_keep_prob=1.0,
state_keep_prob=1.0,
variational_recurrent=False,
input_size=None,
dtype=None,
seed=None,
dropout_state_filter_visitor=None
)
参数详解:
cell:一个RNN单元,比如GRU单元或LSTM单元。input_keep_prob:对输入层执行dropout。output_keep_prob:对输出层执行dropout。state_keep_prob:这个是针对深层RNN来说的,在层与层之间使用dropout(纵向不是横向,即每层内的横向传播一般不使用dropout)。variational_recurrent:布尔类型。如果为False,则对所有的时间步都使用一样的dropout配置,即每个时间步都使用input_keep_prob、output_keep_prob和state_keep_prob的值。如果为True,则需要提供下一个参数input_size的值。input_size:可选参数,当variational_recurrent=True且input_keep_prob<1时需要提供该参数的值。该参数为一个可嵌套的tuple,个人理解就是放入每个时间步的dropout配置。dtype:可选参数。当variational_recurrent=True时需要提供该参数的值,作用是指定input tensor、state tensor和output tensor的类型。seed:可选参数,int类型,随机数种子。dropout_state_filter_visitor:可选参数。个人理解这个参数也是针对深层RNN,通过True和False控制是否要对某层执行dropout,dropout的概率则由state_keep_prob指定。
tf.contrib.rnn.MultiRNNCell是针对深层RNN的,用于定义每一层的cell。
tf.nn.dynamic_rnn的用法见链接。
👉定义batch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def batch_iter(data, batch_size, num_epochs, shuffle=True):
"""
Generates a batch iterator for a dataset.
"""
data = np.array(data)
data_size = len(data)
# 每个epoch的num_batch
num_batches_per_epoch = int((len(data) - 1) / batch_size) + 1
print("num_batches_per_epoch:", num_batches_per_epoch)
for epoch in range(num_epochs):
# Shuffle the data at each epoch
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_indices]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
yield shuffled_data[start_index:end_index]
该函数和我们在【Tensorflow基础】第十四课:CNN在自然语言处理的应用中使用的一样,在此不再赘述。
👉模型的训练,测试以及保存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Initializing the variables
init = tf.global_variables_initializer()
# 定义saver
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
# Generate batches
batches = batch_iter(list(zip(train_x, train_y)), FLAGS.batch_size, FLAGS.num_epochs)
for i, batch in enumerate(batches):
i = i + 1
x_batch, y_batch = zip(*batch)
sess.run([optimizer], feed_dict={x: x_batch, y: y_batch, dropout: FLAGS.dropout_keep_prob})
# 测试
if i % FLAGS.evaluate_every == 0:
sess.run(tf.assign(lr, FLAGS.lr * (0.99 ** (i // FLAGS.evaluate_every))))
learning_rate = sess.run(lr)
tr_acc, _loss = sess.run([accuracy, cross_entropy], feed_dict={x: train_x, y: train_y, dropout: 1.0})
ts_acc = sess.run(accuracy, feed_dict={x: test_x, y: test_y, dropout: 1.0})
print("Iter {}, loss {:.5f}, tr_acc {:.5f}, ts_acc {:.5f}, lr {:.5f}".format(i, _loss, tr_acc, ts_acc,
learning_rate))
# 保存模型
if i % FLAGS.checkpoint_every == 0:
path = saver.save(sess, "sounds_models/model", global_step=i)
print("Saved model checkpoint to {}\n".format(path))
2.np.transpose
np.transpose用于完成矩阵的转置操作。例如,x=np.arange(4).reshape((2,2)),x为:
1
2
array([[0, 1],
[2, 3]])
x.transpose()为:
1
2
array([[0, 2],
[1, 3]])
np.transpose还能指定交换的维度。例如一个三维数据t = np.arange(1,17).reshape(2, 2, 4):
1
2
3
4
array([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8]],
[[ 9, 10, 11, 12],
[13, 14, 15, 16]]])
t.shape为(2,2,4),对应每个维度的大小:第0维对应第一个2,第1维对应第二个2,第2维对应4。我们将其可视化表示:
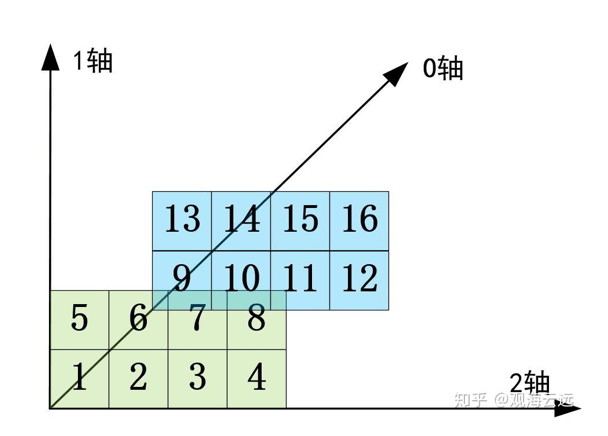
此时如果运行t1 = t.transpose(1, 0, 2),则t1为:
1
2
3
4
array([[[ 1, 2, 3, 4],
[ 9, 10, 11, 12]],
[[ 5, 6, 7, 8],
[13, 14, 15, 16]]])
相当于交换第0维和第1维,第2维保持不变: