本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
github官方repo:https://github.com/microsoft/Swin-Transformer。
计算机视觉领域的建模一直被CNN所主导。从AlexNet在ImageNet图像分类挑战上的优异表现开始,CNN通过更大的规模、更广泛的连接和更复杂的卷积形式变得越来越强大。以CNN为backbone的各种框架不断提升着其性能,促进了视觉领域的进步。
另一方面,NLP则是一条不同的道路,当今流行的框架是Transformer。其在NLP领域的巨大成功促使人们开始研究其在CV领域的适应性,最近在CV领域内的一些任务上,特别是图像分类和joint vision-language modeling,其展示了有希望的结果。
在本文中,我们探索了将Transformer作为CV任务通用backbone的可能性。我们认为将NLP领域内的高性能方法迁移到CV领域,所面临的挑战可被总结为两点不同。第一个不同是scale。NLP领域中,基本元素通常是word tokens,而在CV领域,基本元素的scale可以有很大区别,通常在目标检测任务中会碰到这样的问题。在目前已有的基于Transformer的模型中,tokens的scale都是固定的,这一特性不适合CV任务。第二个不同是,相比文本段落中的单词数量,图像中的像素分辨率要高得多。有些CV任务,比如语义分割,需要在像素级别上进行dense prediction,这在高分辨率图像上对于Transformer来说是很困难的,其计算复杂度和图像大小成平方关系。为了解决这些问题,我们提出了Swin Transformer,其构建了hierarchical feature maps,并且其计算复杂度与图像大小呈线性关系。如Fig1(a)所示,Swin Transformer构建了hierarchical representation,一开始是小尺寸的patch(灰色网格),随着Transformer layers的加深,逐渐合并成大尺寸的patch。有了这些hierarchical feature maps,Swin Transformer模型可以方便地利用现有先进的框架(比如FPN或U-Net)来进行dense prediction。线性计算复杂度由不重叠窗口(红色网格)内的局部自注意力计算来实现。每个窗口内的patch数量是固定的,所以复杂度和图像大小呈线性相关。这些优点使得Swin Transformer可以作为任何CV任务的通用backbone,而之前基于Transformer的框架只能产生单一分辨率的feature maps并且是二次方复杂度。
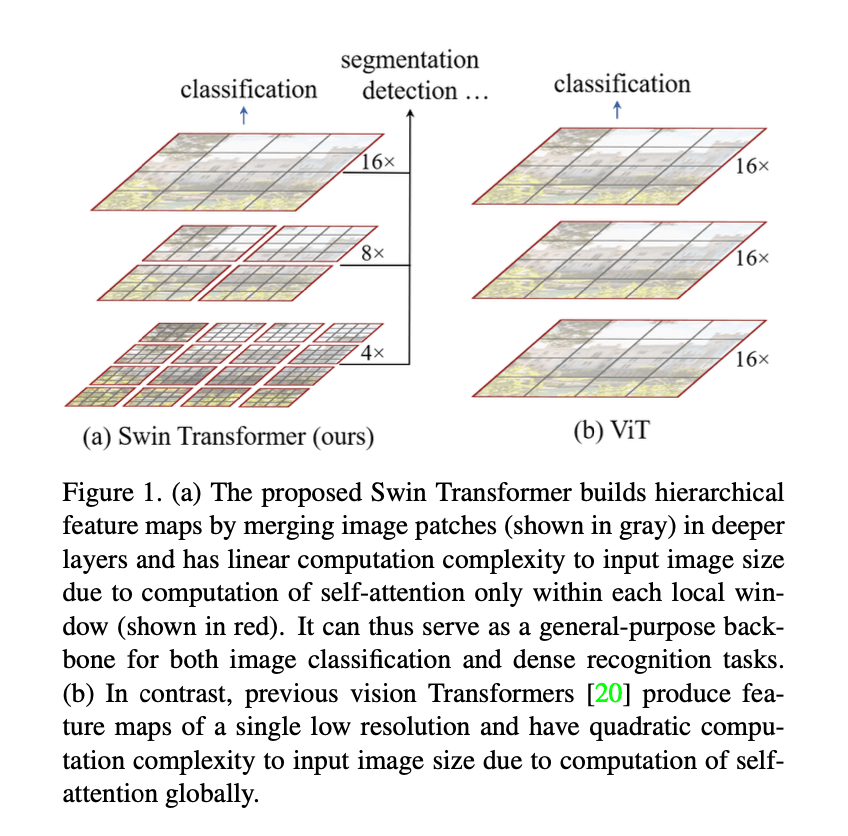
Fig1(a)展示了Swin Transformer所建立的hierarchical feature maps,即随着层数的加深,小patch逐渐被合并(灰色网格)。Fig1(b)展示了ViT所产生的单一低分辨率的feature maps,由于全局计算自注意力的缘故,其计算复杂度和图像大小呈二次方关系。
Swin Transformer的一个关键设计是shifted window,如Fig2所示。shifted window提供了前一层窗口之间的连接,这显著增强了建模能力(见表4)。这种策略同样也很有效率:一个窗口内所有patch的query共用同一个key。相比早期基于sliding window的自注意力方法,由于不同的query使用不同的key,所以其效率不高(因为共享权重的缘故,sliding window在CNN框架中很有效率,但是sliding window在自注意力机制中很难做到这一点)。我们的实验证明,shifted window比sliding window有更低的latency,并且二者建模能力相似(见表5和表6)。shifted window对所有MLP(Multi-Layer Perceptron)框架都是有益的。
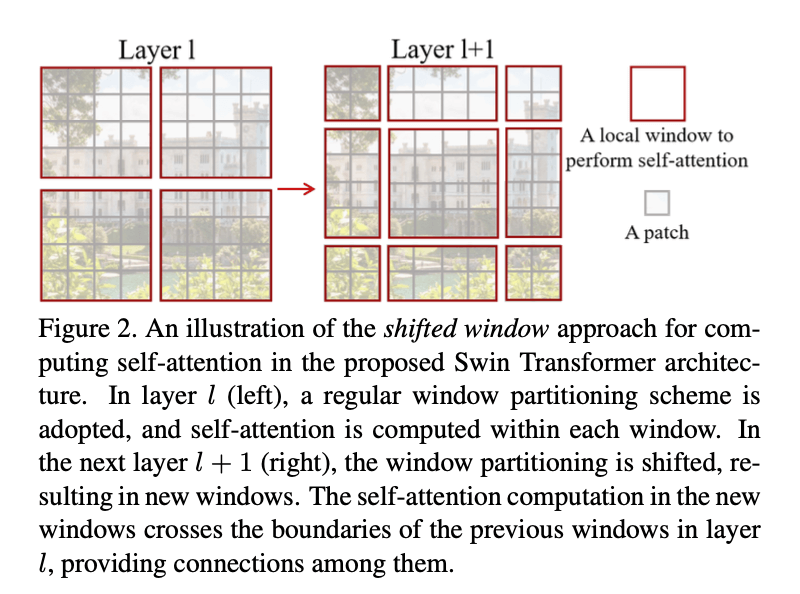
Fig2展示了shifted window方法。在第$l$层(Fig2左),采用了规则的划分方式,并在每个窗口内计算自注意力。在第$l+1$层(Fig2右)窗口向右下移动了2个patch,导致了新的窗口划分。新窗口的自注意力计算跨越了第$l$层窗口的边界,提供了它们之间的连接。shifted window更直观的解释:
Swin Transformer在图像分类、目标检测和语义分割等任务中都取得了很好的成绩。其表现显著优于ViT、DeiT以及ResNet,并且这些方法的latency接近。在COCO test-dev set上,Swin Transformer取得了58.7的box AP,比之前SOTA的Copy-paste(without external data)高了2.7个点;其还取得了51.1的mask AP,比之前SOTA的DetectoRS高了2.6个点。在ADE20K语义分割任务上,在val set上,Swin Transformer取得了53.5的mIoU,比之前SOTA的SETR提升了3.2。在ImageNet-1K图像分类任务中,Swin Transformer的top-1准确率为87.3%。
DeiT:Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve ́ Je ́gou. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.。
Copy-paste:Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. arXiv preprint arXiv:2012.07177, 2020.。
DetectoRS:Siyuan Qiao, Liang-Chieh Chen, and Alan Yuille. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv preprint arXiv:2006.02334, 2020.。
SETR:Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. arXiv preprint arXiv:2012.15840, 2020.。
我们相信一个横跨CV和NLP领域的大一统模型框架有助于这两个领域的共同发展,并且这两个领域的建模知识可以更深入地共享。我们希望Swin Transformer的出现可以促进这方面的研究。
2.Related Work
👉CNN and variants
CNN通常作为CV领域的标准网络模型。虽然CNN已经存在了几十年,但是直到AlexNet的出现,CNN才开始发展成为主流。从那时起,人们提出了更多更深入且更有效的CNN框架,推动了深度学习在CV领域的进步,比如:VGG,GoogleNet,ResNet,DenseNet,HRNet以及EfficientNet等。除了网络框架上的进步,还有许多关于改进单个卷积层的工作,比如depth-wise convolution和deformable convolution。虽然CNN及其变体依然是CV领域内的主要backbone,但我们展示了Transformer框架在CV以及NLP领域之间统一建模的巨大潜力。我们的模型在几个基础的CV任务上都取得了非常好的表现。
👉Self-attention based backbone architectures
受到NLP领域内自注意力机制以及Transformer大获成功的启发,一些研究尝试将ResNet中的部分或所有卷积层替换为自注意力机制。在这些研究中,在每个local window内以像素为单位计算自注意力,以达到准确率和FLOPs之间的良好平衡。然而,它们高昂的memory access成本导致实际latency明显大于CNN网络框架。因此我们没有使用sliding windows,而是在连续层之间采用shift windows,使其在通用硬件中可以更高效的实现。
👉Self-attention/Transformers to complement CNNs
另一研究方向是使用自注意力机制或Transformer来加强标准的CNN框架。自注意力机制可被用于补充backbones或head networks。最近,Transformer中的encoder-decoder设计已被用于目标检测和实例分割。我们的研究对上述工作进行了进一步的扩展。
👉Transformer based vision backbones
和我们工作最相关的是ViT及其后续的衍生模型。ViT开创性的直接将Transformer框架应用于无重叠区域且中等尺寸的图像patch,从而执行图像分类任务。与CNN相比,ViT在图像分类任务中做到了速度和精度的良好平衡。虽然ViT需要大规模的训练数据集(比如JFT-300M)才能表现良好,但是其衍生模型DeiT通过引入多种训练策略,使得ViT使用较小的ImageNet-1K数据集也可以有不错的表现。ViT在图像分类任务上的结果令人鼓舞,但是由于其使用低分辨率的feature maps且计算复杂度随图像大小呈二次方增长,所以其结构不适合用作dense vision tasks的backbones,同时也不适用于输入图像分辨率较高的时候。有一些研究直接通过上采样或反卷积将ViT应用于目标检测和语义分割等dense vision tasks,但性能相对较低。还有一些研究通过修改ViT的结构来提升其在图像分类任务中的表现。与这些方法相比,在图像分类任务上,Swin Transformer实现了最佳的速度与精度之间的平衡,尽管我们的工作重点是通用性能而不是图像分类。还有一些研究也探索了在Transformer上构建多分辨率的feature maps。但是这些研究的计算复杂度仍然和图像大小呈二次方关系,而我们方法的计算复杂度是线性的,并且是局部操作。我们的方法即高效又有效,在COCO目标检测任务和ADE20K语义分割任务上均取得了SOTA的成绩。
3.Method
3.1.Overall Architecture
Swin Transformer的结构见Fig3,展示的是tiny version(即Swin-T)。首先,和ViT类似,将RGB图像分成无重叠区域的patch。每个patch都被看作是一个token,它的feature就是将原始的像素值展开。在我们的实现中,patch size为$4\times 4$,也就是说,每个patch的feature维度为$4\times 4\times 3 = 48$。通过一个线性embedding layer可以将特征映射到任意维度(假设为$C$)。
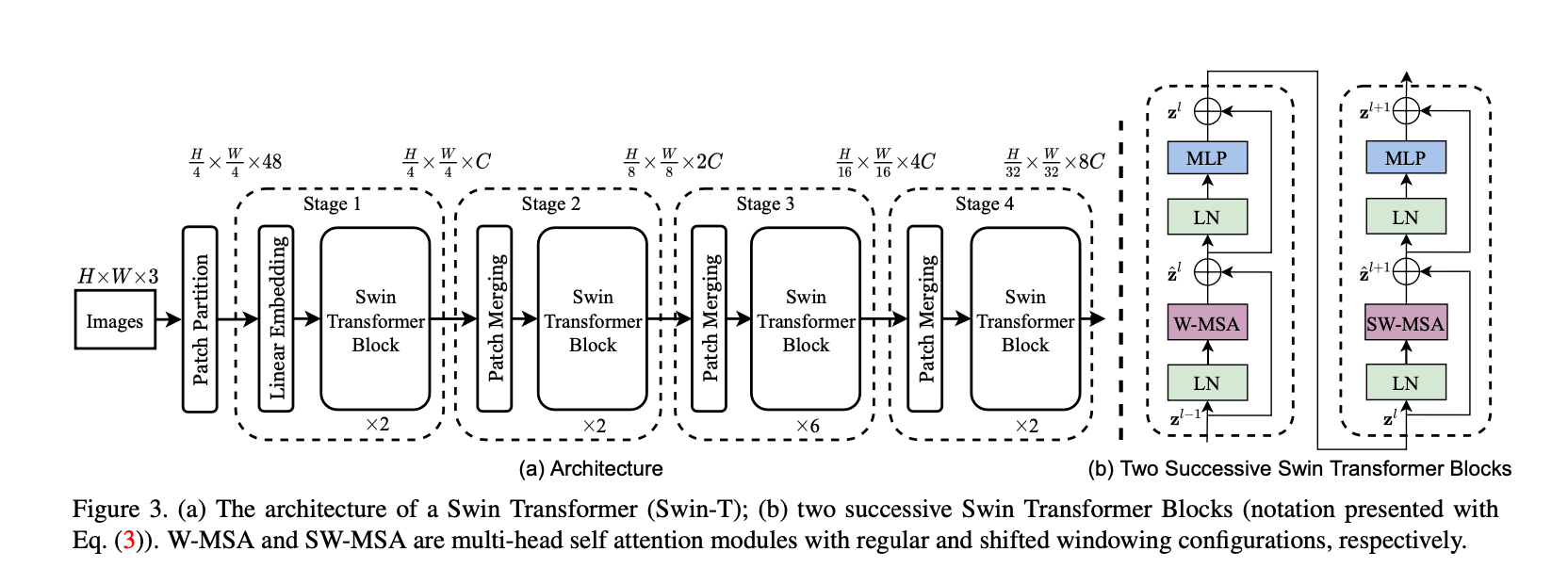
Fig3中的”Patch Partition”指的是将输入图像分割成patch,每个patch的大小为$4 \times 4$,那一共可得到$\frac{H}{4} \times \frac{W}{4}$个patch,每个patch的维度为$4\times 4\times 3=48$。因此经过Patch Partition之后,得到的feature map维度为$\frac{H}{4} \times \frac{W}{4} \times 48$。
Fig3中的”Linear Embedding”是一个线性映射层,将维度48映射到维度$C$,即经过Linear Embedding后的feature map维度为$\frac{H}{4} \times \frac{W}{4} \times C$。
Fig3中Swin Transformer blocks的层数都是偶数,因为每个block都包含两层,见Fig3(b)。Swin Transformer blocks不会改变feature map的维度。
Fig3中”Patch Merging”的解释见下图:
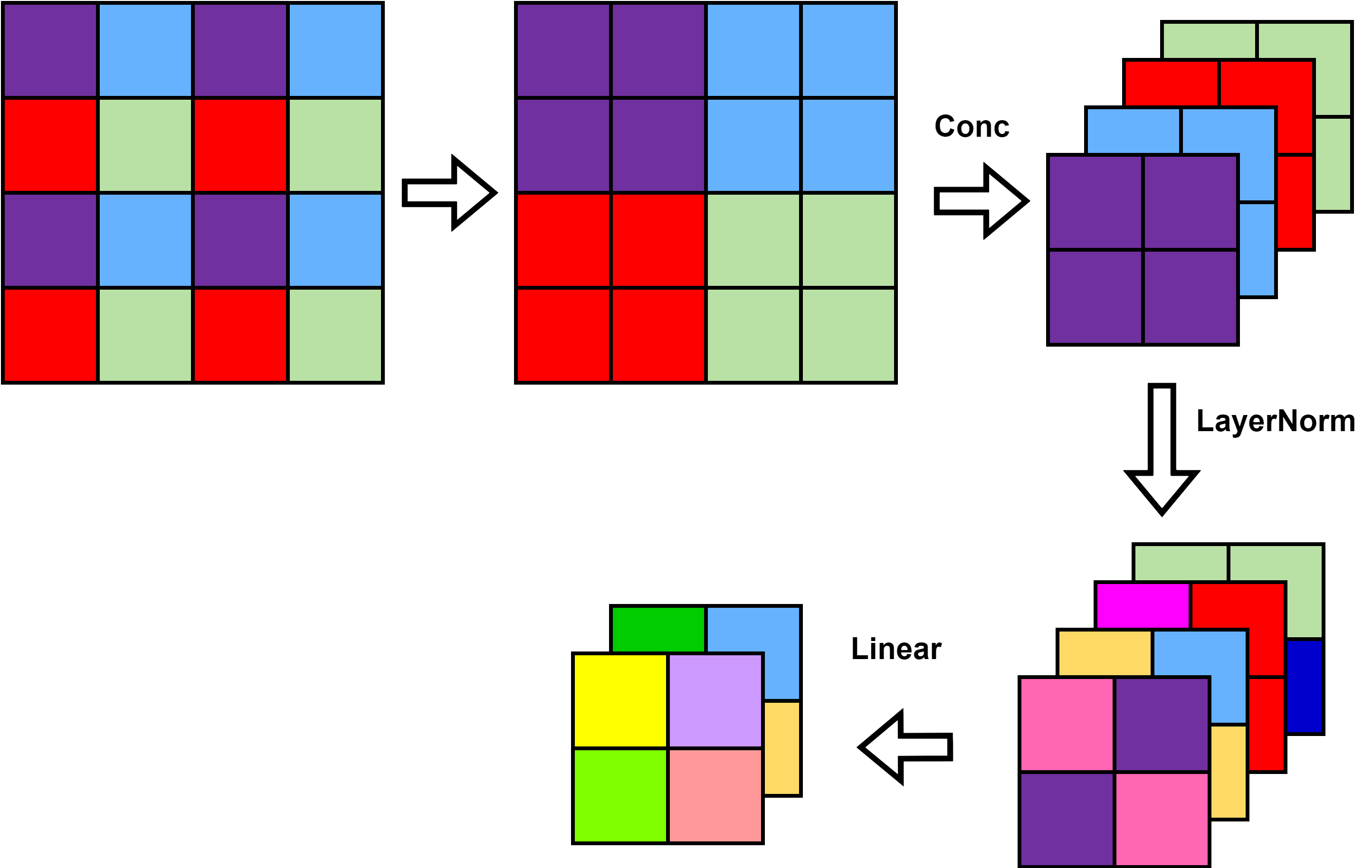
维度的变化:
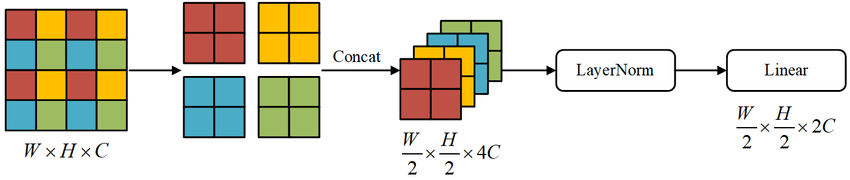
这些stages联合起来产生了hierarchical representation,和一些典型CNN网络(比如VGG和ResNet)的feature map有着一样的分辨率。因此,我们的方法可以方便的取代现有CV任务模型中的backbone。
👉Swin Transformer block
Swin Transformer将标准的multi-head self attention(MSA)模块替换为了基于shifted windows的MSA模块(详见第3.2部分),其他层保持不变。如Fig3(b)所示,Swin Transformer block包含一个基于shifted windows的MSA模块,后面跟一个2层的MLP(激活函数为GELU)。此外,在每个MSA模块和每个MLP之间还有一个LayerNorm层,并且每个模块之后还有残差连接。
3.2.Shifted Window based Self-Attention
无论是标准的Transformer框架还是ViT,都使用了全局自注意力,即计算了某一token和其他所有tokens之间的关系。全局计算使得计算复杂度和tokens数量呈二次相关,这导致它不适用于许多需要大量tokens进行dense prediction或使用高分辨率图像的CV任务。
👉Self-attention in non-overlapped windows
为了更有效率的建模,我们建议在local windows内计算自注意力。这些窗口均匀分布且无重叠区域。假设每个窗口包含$M\times M$个patch,一张图像一共有$h \times w$个patch,则全局MSA模块的计算复杂度见式(1),基于window的计算复杂度见式(2):
\[\Omega (MSA) = 4hwC^2 + 2(hw)^2C \tag{1}\] \[\Omega (W-MSA) = 4hwC^2 + 2M^2 hw C \tag{2}\]我们在确定复杂度时省略了SoftMax的计算。
当$M$固定时(默认$M=7$),式(1)的计算复杂度和patch数量($hw$)呈二次方关系,式(2)的计算复杂度和patch数量呈线性关系。当$hw$比较大时,全局自注意力的计算复杂度通常是无法负担的,而基于窗口的自注意力的计算成本是可接受的。
接下来简单推导一下式(1)和式(2)。下图是一个单头自注意力的标准计算过程,首先是一个输入,其分别乘上3个系数矩阵得到$q,k,v$,通过$q,k$相乘得到自注意力矩阵$A$,然后$A$和$v$进行相乘。我们将这些向量该有的维度也用红字标注在了下图中,假设有$a$个头且$q,k,v$的维度平均分为$\frac{C}{a}$(这个假设的原因是Transformer一文中第3.2.2部分提到“由于每个Head的维度降低,总的计算成本与全维度单头注意力的计算成本相似”)。此时用于计算$q,k,v$的3个系数矩阵都为$C\times \frac{C}{a}$大小,计算$q$的复杂度(仅统计乘法运算,后同)为$hw\frac{C^2}{a}$,$k,v$也一样,所以计算$q,k,v$的复杂度为$3hw\frac{C^2}{a}$。计算自注意力矩阵$A$的复杂度为$(hw)^2\frac{C}{a}$(忽略除以$\sqrt{q_k}$和SoftMax的计算量)。$A$和$v$相乘的计算复杂度也为$(hw)^2\frac{C}{a}$。将上述加总得到单头的计算复杂度为$\frac{1}{a} [ 3hwC^2 + 2(hw)^2 C ]$,那么一共$a$个头,需要计算$a$次。最后将单头的输出$hw \times \frac{C}{a}$拼接在一起维度为$hw \times C$,再乘上一个转化矩阵$W^O$(维度为$C\times C$),最终得到全局MSA模块的复杂度为:
\[a * \frac{1}{a} [ 3hwC^2 + 2(hw)^2 C ] + hwC^2\]即式(1)。
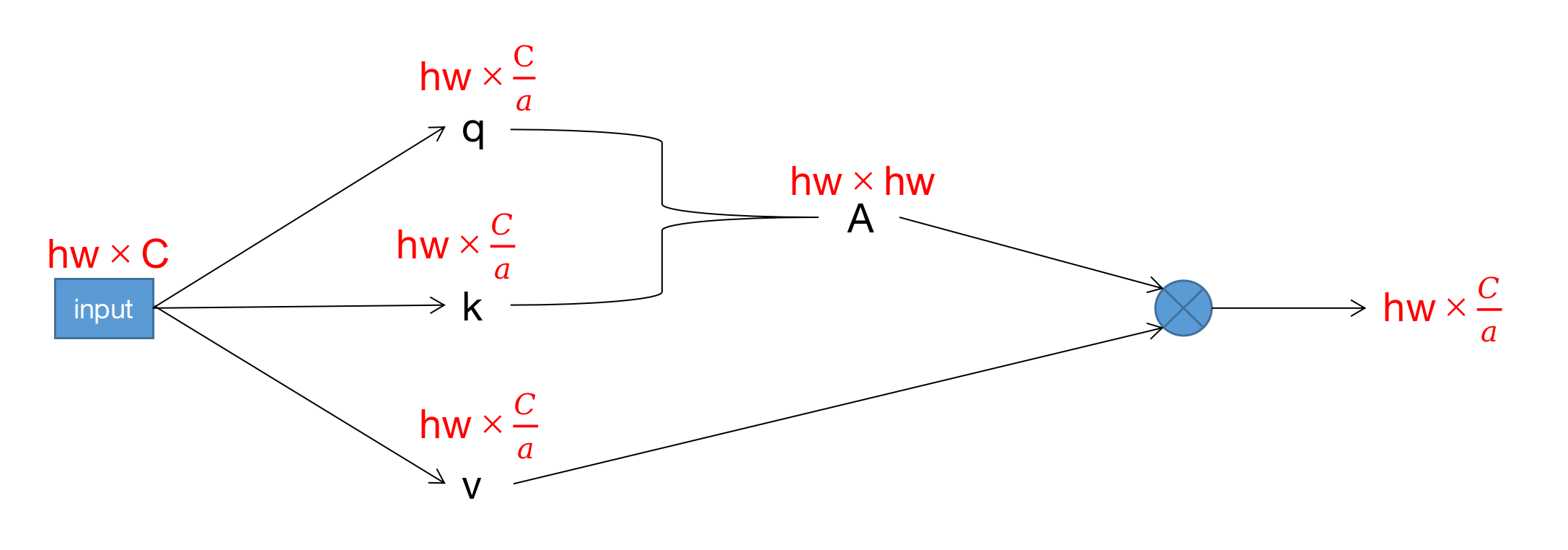
根据式(1)可得一个$M \times M$大小的窗口的MSA计算复杂度(即式(1)中有$h=w=M$)为:
\[4M^2C^2 + 2M^4C\]那么我们现在一共有$\frac{h}{M} \times \frac{w}{M}$个窗口,则所有窗口的总计算复杂度为:
\[\frac{h}{M} \times \frac{w}{M} \times (4M^2C^2 + 2M^4C)\]即式(2)。举个例子,如果$h=w=112,M=7,C=128$,那么W-MSA比MSA节省的计算量为40124743680FLOPs。
👉Shifted window partitioning in successive blocks
W-MSA模块缺少窗口之间的联系,这限制了建模能力。为了在保持无重叠区域窗口计算高效性的同时引入不同窗口之间的连接,我们提出了shifted window的方法。
如Fig2所示,第一个模块使用常规的窗口划分策略,将$8\times 8$大小的feature map划分为$2\times 2$个窗口,每个窗口的大小为$4\times 4$(即$M=4$)。然后在下一个模块中,将窗口向右下移动$(\lfloor \frac{M}{2} \rfloor,\lfloor \frac{M}{2} \rfloor)$。
Swin Transformer blocks的计算如下:
\[\hat{\mathbf{z}}^l = \text{W-MSA}( \text{LN} (\mathbf{z}^{l-1})) + \mathbf{z}^{l-1},\] \[\mathbf{z}^l = \text{MLP} (\text{LN} (\hat{\mathbf{z}}^l)) + \hat{\mathbf{z}}^l,\] \[\hat{\mathbf{z}}^{l+1} = \text{SW-MSA}( \text{LN} (\mathbf{z}^l)) + \mathbf{z}^l,\] \[\mathbf{z}^{l+1} = \text{MLP} (\text{LN} (\hat{\mathbf{z}}^{l+1})) + \hat{\mathbf{z}}^{l+1}, \tag{3}\]其中,$\hat{\mathbf{z}}^l$和$\mathbf{z}^l$分别表示第$l$层中(S)W-MSA模块或MLP模块的输出特征。W-MSA和SW-MSA分别表示基于常规窗口划分和基于shifted窗口划分的多头自注意力。
shifted window方法引入了前一层中相邻且非重叠窗口之间的连接,如表4所示,这一方法在图像分类、目标检测和语义分割任务中都很有效。
👉Efficient batch computation for shifted configuration
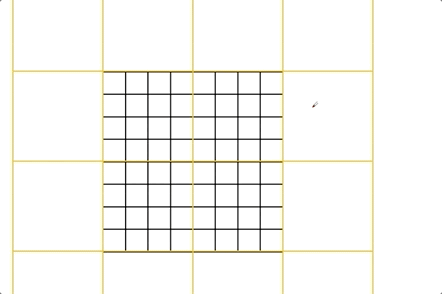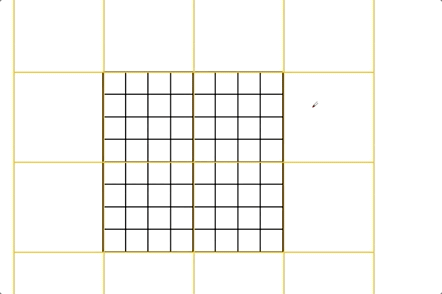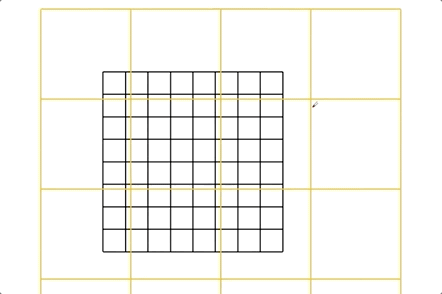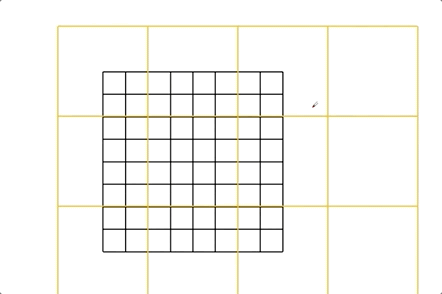
shifted window的一个问题就是会导致更多的窗口,如Fig2所示,窗口数目从$\lceil \frac{h}{M} \rceil \times \lceil \frac{w}{M} \rceil $增加至$(\lceil \frac{h}{M} \rceil +1)\times (\lceil \frac{w}{M} \rceil+1)$,并且部分窗口的大小会小于$M \times M$(为了使窗口大小$(M, M)$可以被feature map大小$(h,w)$整除,如果需要,可以在feature map的右下方进行padding)。一个简单的解决办法是将大小不足$M\times M$的窗口padding至$M\times M$,然后在计算注意力时mask掉padding添加的值。如果常规窗口划分策略得到$2\times 2$个窗口,那么shift之后,通过这种简单的解决办法,窗口会增加至$3\times 3$个,增加了2.25倍。因此,我们提出了一种更有效率的方法,见Fig4。按照Fig4所示的方法进行移位(作者称之为cyclic-shift)之后,一个新的窗口(即batched window)可能会包含多个原来并不相邻的子窗口,然后通过mask机制将自注意力计算限制在每个子窗口内。通过cyclic-shift,相比常规窗口划分策略,shifted window不再导致窗口数量的增加,保持了原有的效率。表5展示了这种方法的low latency。
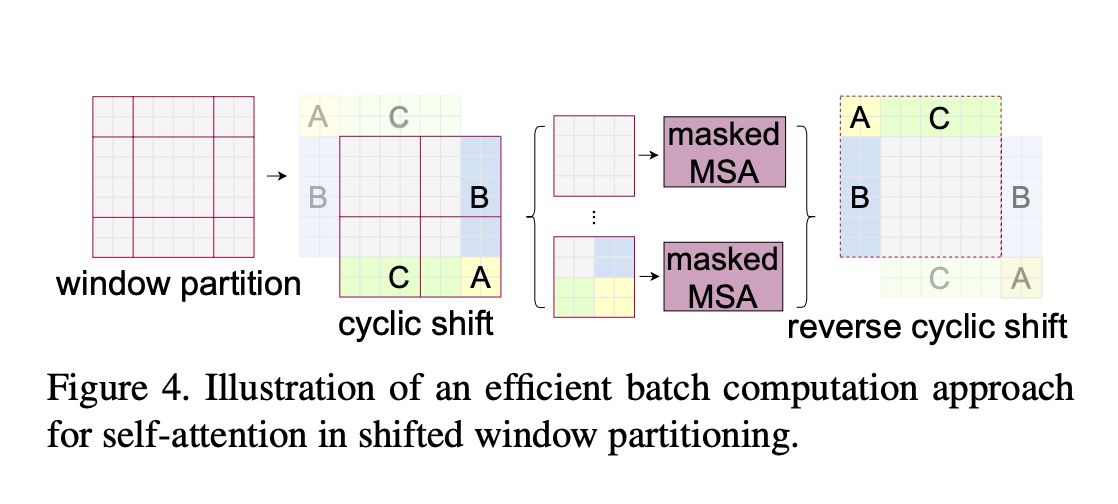
这里再继续详解一下shifted window。如Fig2所示,经过shifted window之后,窗口的数量变多了,并且每个窗口的大小都不一样,这就使得我们不能将其打包成一个batch快速处理,因为每个序列(即每个窗口)的token数量(即patch数量)都不一样,而Transformer需要输入的序列长度始终保持一致。可以很容易的想到一种简单粗暴的解决办法,就是将每个窗口都padding成$4\times 4$大小,但这样做就增加了大量的计算成本。那shifted window之后,怎么才能既保持4个窗口不增加又保证每个窗口大小一致呢?作者提出了一种基于mask和cyclic-shift的方式来解决这个问题。如Fig4左起第二张图所示,通过对A,B和C三个区域的循环移位,窗口数量又回到了4个且每个窗口的大小都是$4\times 4$。窗口的数量不变就意味着计算复杂度不变,即没有引起计算复杂度的增加。但这也导致了一个新的问题,即一个窗口内原本不相邻的区域之间不应该做自注意力。此时作者便引入了mask机制来解决这个问题,只用一次前向过程就计算出了所有区域的自注意力。算完所有区域的自注意力之后,最后一步便是把循环移位的区域还原到原来的位置,以保证原有语义信息的基本不变。
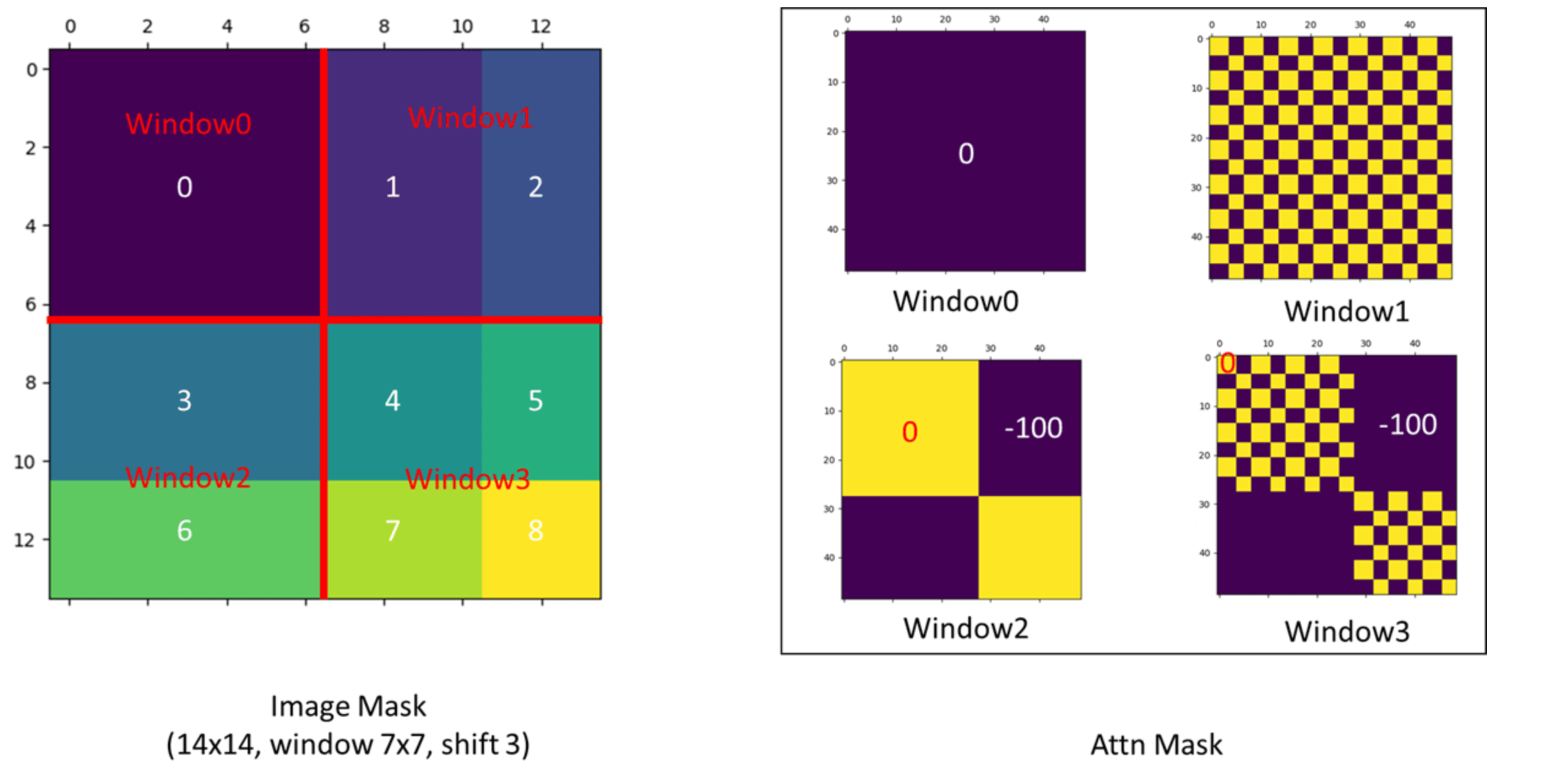
接下来来看下mask机制的具体实现。上图左就是经过循环移位后的窗口。比如,区域2+区域5就是Fig4中的B,区域6+区域7就是Fig4中的C,区域8就是Fig4中的A。上图右就是各个窗口对应的mask。因为窗口0内的patch原本就在一起,所以不需要mask操作,即mask的值都为0。以上图为例,feature map大小为$14 \times 14$,每个窗口的大小为$7\times 7$,shifted window是往右下移动了3个patch,从而可以推导出,区域3的大小是$4\times 7$,区域6的大小是$3\times 7$。我们先来计算窗口2的mask,将窗口2的patch按从左往右,从上往下的顺序依次拍扁放在一起,相当于是得到一个$49 \times C$的矩阵($C$为patch拍成一维后的长度),前28行为区域3,后21行为区域6。然后进行自注意力计算(这里不是真的矩阵相乘,只是简化表示自注意力的计算):

区域3和区域6之间的自注意力计算对应的mask部分(即灰色部分)会是一个很小的负数(比如-100,这样后续在经过SoftMax函数时就会接近于0)。masked MHSA模块的用法见链接,简单来说就是mask会加在自注意力计算的结果上。其他窗口的mask计算类似,不再赘述。此时就可以一个batch(包含4个窗口)一起进Transformer block的SW-MSA模块,然后经过循环移位、mask计算、复原等一系列操作后,在进入后面的MLP模块。
👉Relative position bias
在位置编码方面,Swin Transformer采用了Relative position bia的方式,具体实现见下(假设窗口大小$M=2$):
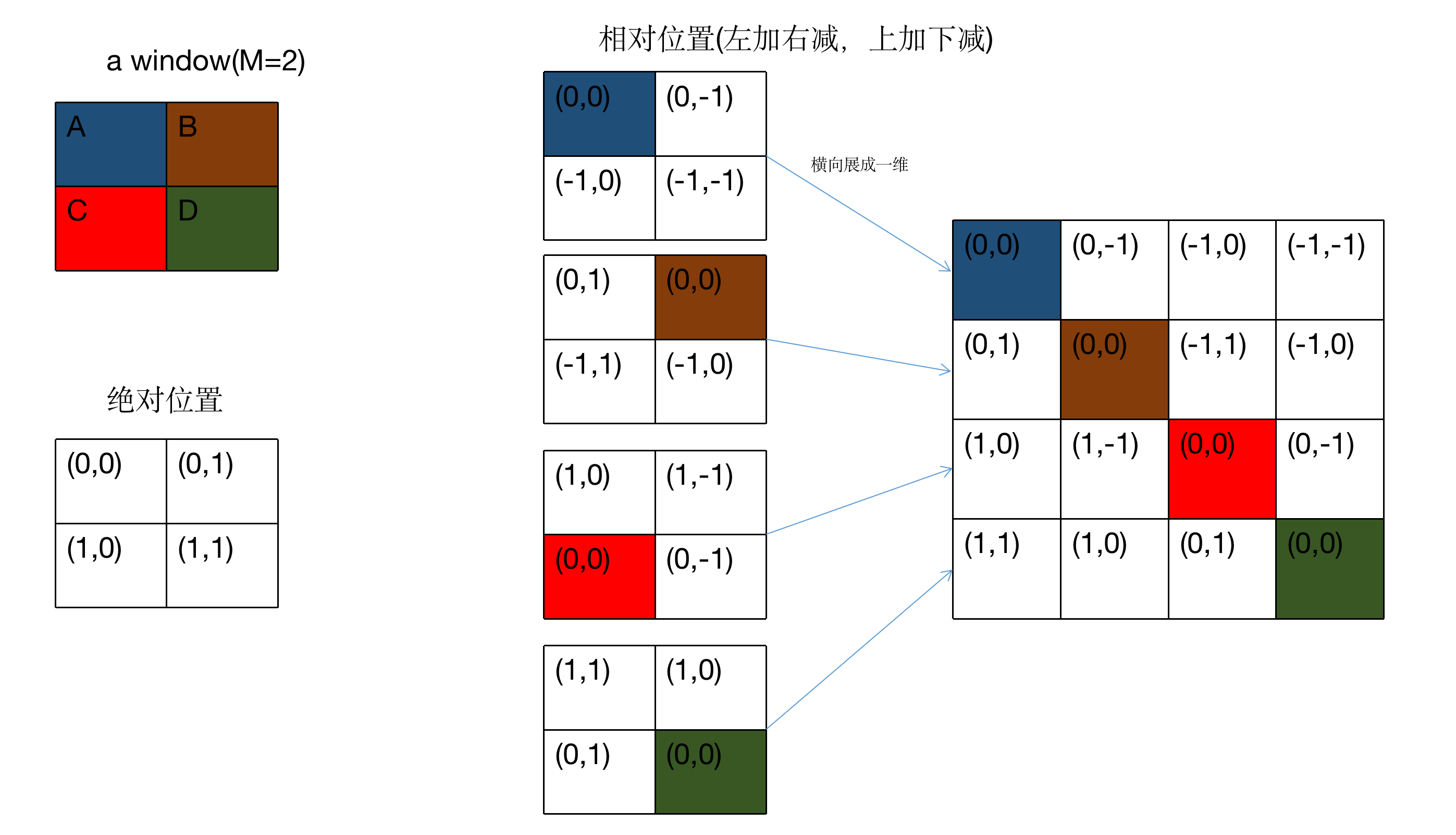
此时我们需要将相对位置矩阵中的二维坐标转换成一维,如果仅是通过横坐标加纵坐标的方法来转换会损失一定的相对位置信息,比如以蓝色区域A为$(0,0)$为例,其右边的区域B为$(0,-1)$,其下边的区域C也为$(-1,0)$,这两个区域的横纵坐标相加都是-1,这就无法区分这两个区域了。因此,作者的做法如下:

- 先将横纵坐标都加上$M-1$以保证坐标值没有负数(坐标值最小为0)。
- 仅将横坐标乘上$2M-1$。
- 横纵坐标相加,得到相对位置索引矩阵。
- 通过relative position bias table将相对位置索引矩阵中的相对位置索引替换为bias,得到最终的relative position bias(即下面公式中的$B$)。
在添加relative position bias之后,注意力的计算可表示为:
\[\text{Attention} (Q,K,V) = \text{SoftMax} (QK^T / \sqrt{d} + B) V \tag{4}\]其中,$Q,K,V$分别为query,key和value的矩阵,维度都是$M^2 \times d$($d$是query/key的维度,$M^2$是一个窗口内的patch数量),即:
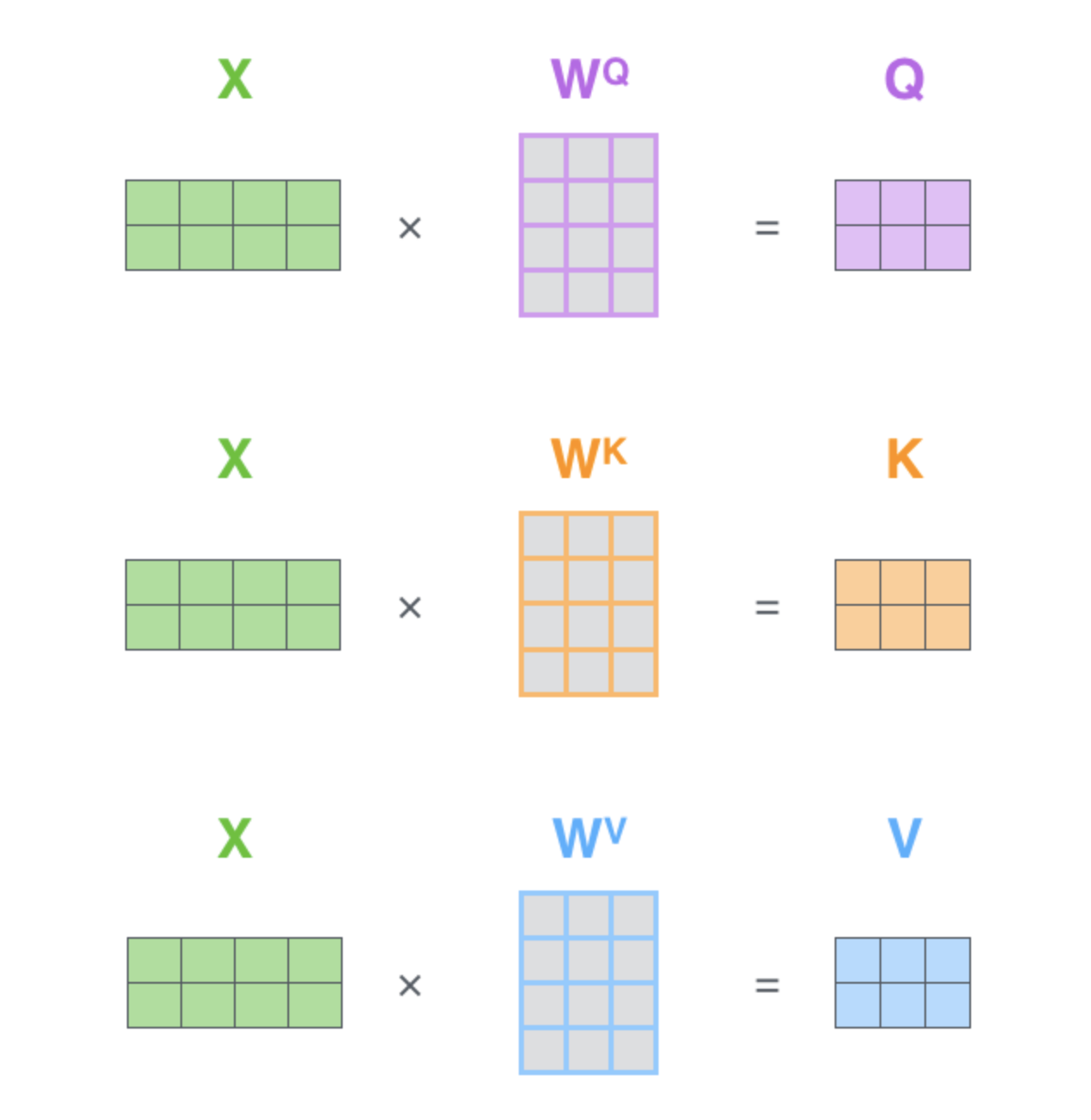
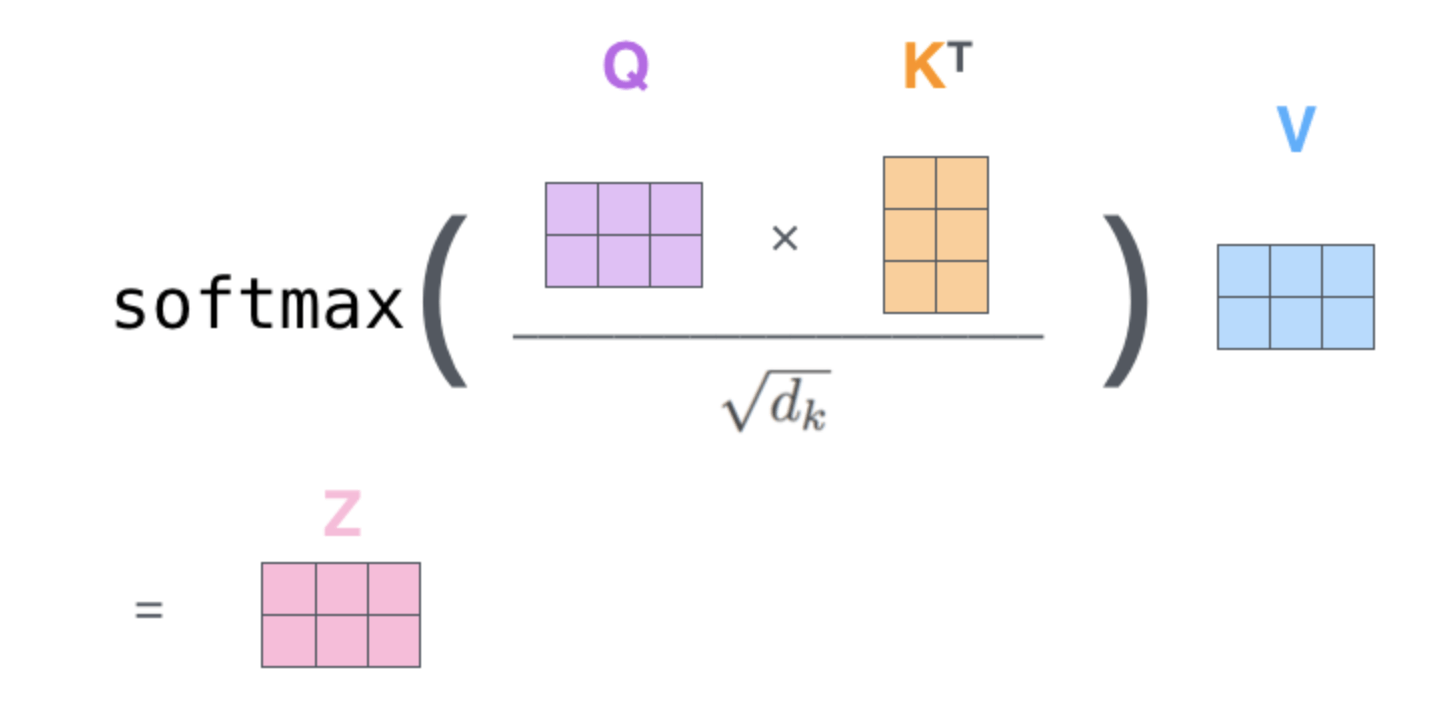
式(4)中矩阵$B$的维度为$M^2 \times M^2$。相对位置索引矩阵每个轴的维度都是$[-M+1,M-1]$,一旦窗口大小确定,相对位置索引矩阵就是固定的。我们用$\hat{B}$表示relative position bias table,其范围为$\hat{B} \in \mathbb{R} ^{(2M-1) \times (2M-1)} $,即例子中的0~8。$\hat{B}$是可学习的,是训练得到的。
如表4所示,与使用绝对位置或不使用bias相比,relative position bias对性能有明显改善。如果我们像ViT那样在输入上进一步添加absolute position embedding会导致性能的轻微下降,所以我们在最终的实现里没有使用absolute position embedding。
通过预训练学习到的relative position bias,在fine-tune时可以通过双三次插值(bi-cubic interpolation)来适应不同的窗口大小。
3.3.Architecture Variants
我们的base model称为Swin-B,其模型大小和计算复杂度与ViT-B/DeiT-B相当。此外,我们还提出了Swin-T,Swin-S和Swin-L,其模型大小和计算复杂度分别为Swin-B的0.25,0.5以及2倍。其中,Swin-T和Swin-S的复杂度分别和ResNet-50(DeiT-S)和ResNet-101相当。窗口大小默认为$M=7$。对于所有的实验,每个头的query维度都为$d=32$,后续的MLP层数均为$\alpha = 4$。这些模型变体的框架超参数见下:
- Swin-T:C=96,layer numbers={2,2,6,2}
- Swin-S:C=96,layer numbers={2,2,18,2}
- Swin-B:C=128,layer numbers={2,2,18,2}
- Swin-L:C=192,layer numbers={2,2,18,2}
$C$即为Fig3(a)中的$C$。表1列出了模型的大小以及理论计算复杂度(FLOPs),还有不同模型变体在ImageNet图像分类任务上的throughput(个人理解就是推理速度)。
4.Experiments
我们在ImageNet-1K图像分类任务,COCO目标检测任务以及ADE20K语义分割任务上都进行了实验。在这三个任务上,我们比较了Swin Transformer和之前SOTA的方法。此外,我们还总结了Swin Transformer的重要设计元素。
4.1.Image Classification on ImageNet-1K
👉Settings
ImageNet-1K包含1.28M张训练集图像,50K张验证集图像,共分为1000个类别。评价指标使用基于single crop的top-1准确率。我们考虑了两种训练设置:
- Regular ImageNet-1K training.
- Pre-training on ImageNet-22K and fine-tuning on ImageNet-1K.
- 我们也尝试了在更大的数据集ImageNet-22K上进行预训练,该数据集包含14.2M张图像和22个类别。optimizer使用AdamW,90个epoch使用linear decay learning rate scheduler,5个epoch使用linear warm-up。batch size=4096,初始学习率为0.001,weight decay为0.01。然后在ImageNet-1K上进行fine-tune,一共fine-tune了30个epoch,batch size为1024,学习率恒为$10^{-5}$,weight decay为$10^{-8}$。
repeated augmentation:Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving generalization through instance repetition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8129–8138, 2020.。
EMA:Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992.。
👉Results with regular ImageNet-1K training

表1比较了在ImageNet-1K分类任务上,不同backbones的表现。Throughput的测评使用Github repo:Pytorch image models,基于V100 GPU,遵循论文“Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve ́ Je ́gou. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.”。
表1(a)使用regular ImageNet-1K training设置,比较了不同backbone(Transformer-based和ConvNet-based)的表现。
和之前Transformer-based的SOTA框架(比如DeiT)相比,Swin Transformers的表现要优于与其计算复杂度相似的DeiT框架:当输入大小为$224^2$时,相比DeiT-S(79.8%),Swin-T(81.3%)的准确率高出1.5%;当输入分别为$224^2/384^2$时,相比DeiT-B(81.8%/83.1%),Swin-B(83.3%/84.5%)的准确率分别高出1.5%/1.4%。
如果和SOTA的ConvNets框架相比,比如RegNet和EfficientNet,Swin Transformer有着更好的speed-accuracy trade-off。因为Swin Transformer是基于标准的Transformer构建的,其具有进一步改进的强大潜力。
RegNet:Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, and Piotr Dolla ́r. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10428– 10436, 2020.。
👉Results with ImageNet-22K pre-training
我们在ImageNet-22K上预训练了更大的模型Swin-B和Swin-L。在ImageNet-1K图像分类任务上的fine-tune结果见表1(b)。对于Swin-B,相比只在ImageNet-1K上从头开始训练,在ImageNet-22K上进行预训练的方式将准确率提升了1.8%~1.9%。和之前同样在ImageNet-22K上进行预训练的最好结果相比,我们的方法明显有着更好的speed-accuracy trade-offs:Swin-B和ViT-B/16在推理速度差不多的情况下(84.7 vs. 85.9 images/sec),Swin-B的top-1准确率为86.4%,比ViT-B/16高出2.4%,并且FLOPs更低(47.0G vs. 55.4G)。更大的Swin-L模型达到了87.3%的top-1准确率,比Swin-B还高出0.9%。
4.2.Object Detection on COCO
👉Settings
我们在COCO 2017上进行了目标检测和实例分割测试,该数据集包含118K训练图像,5K验证图像,20K test-dev图像。在验证集上进行了消融实验,在test-dev上进行了system-level的比较。对于消融实验,我们考虑了4种典型的目标检测框架(基于mmdetection):Cascade Mask R-CNN、ATSS、RepPoints v2和Sparse RCNN。对于这4种框架,我们使用一样的settings:
- multi-scale training。resize输入的大小,使短边位于480~800之间,长边最长不超过1333。
- AdamW optimizer。初始学习率为0.0001,weight decay为0.05,batch size=16。
- 3x schedule(36 epochs,分别在第27和33个epoch的时候,学习率衰减10倍)。
对于system-level的比较,我们采用了:
- 一种改进的HTC(表示为HTC++)+instaboost
- stronger multi-scale training(将输入的短边resize到400~1400之间,长边不超过1600)
- 6x schedule(72 epochs,分别在第63和69个epoch的时候,学习率衰减10倍)
- soft-NMS
- ImageNet-22K预训练
我们比较了Swin Transformer和标准的ConvNets(即ResNe(X)t)以及以前的Transformer框架(即DeiT)。比较的时候settings都一样,只是更换了backbones。需要注意的是,由于Swin Transformer和ResNe(X)t都有hierarchical feature maps,所以其可以直接应用于上述框架,而DeiT只能产生单一分辨率的feature maps,所以其不能直接应用。为了比较的公平性,我们按照论文“Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. arXiv preprint arXiv:2012.15840, 2020.”中的思路,通过反卷积层来使DeiT产生hierarchical feature maps。
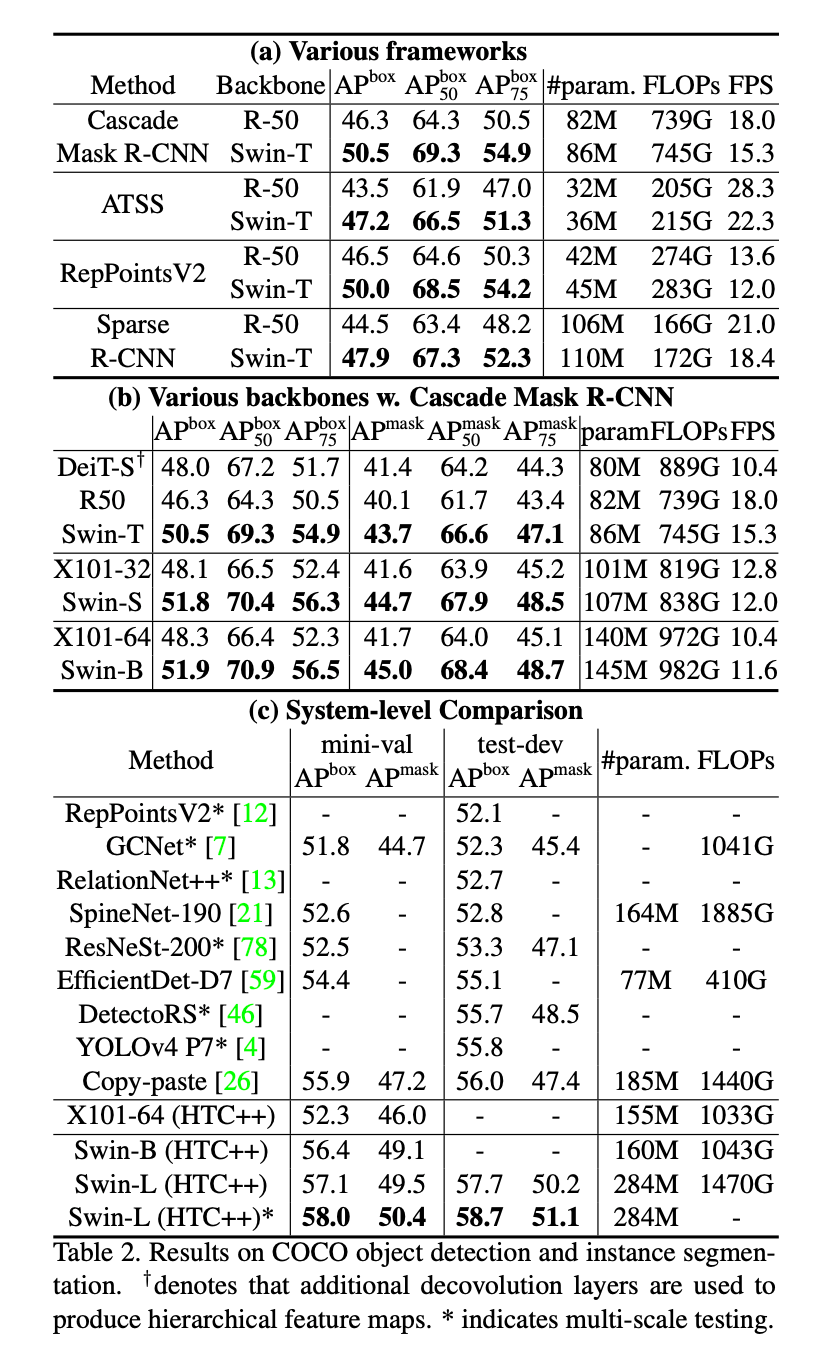
表2展示了在COCO目标检测和实例分割任务上的结果。
👉Comparison to ResNe(X)t
表2(a)列出了分别以Swin-T和ResNet-50为backbone的4种目标检测框架的结果。虽然Swin-T在模型大小、FLOPs以及latency方面比ResNet-50略高,但是其box AP比ResNet-50基本都能高出3.4~4.2个点。
在表2(b)中,基于Cascade Mask R-CNN框架,分别使用不同capacity的backbones。相比ResNeXt101-64x4d,Swin-B表现更好,取得了51.9的box AP(提升了3.6个点)和45.0的mask AP(提升了3.3个点),并且二者的模型大小、FLOPs以及latency相近。在表2(c)中,相比X101-64(HTC++)的表现(52.3的box AP和46.0的mask AP),Swin-B(HTC++)的表现更好,box AP提升了4.1个点,mask AP提升了3.1个点。关于推理速度,ResNe(X)t是基于高度优化的Cudnn函数构建的,而我们的模型仅仅使用内置的PyTorch函数实现,这些函数并没有完全优化。完全彻底的优化并不在本文的讨论范围之内。
👉Comparison to DeiT
在表2(b)中,相比DeiT-S,Swin-T和其有着相似的模型大小(86M vs. 80M),但表现更好,box AP提升了2.5个点,mask AP提升了2.3个点,并且推理速度也更快(15.3 FPS vs. 10.4 FPS)。DeiT推理速度慢主要是因为其计算复杂度和输入图像大小呈二次方关系。
👉Comparison to previous state-of-the-art
在表2(c)中,我们比较了我们最好的结果和之前的SOTA模型。在COCO test-dev上,我们最好的模型达到了58.7的box AP和51.1的mask AP,相比之前最高的box AP结果(Copy-paste without external data)还提升了2.7个点,比之前最高的mask AP结果(DetectoRS)提升了2.6个点。
4.3.Semantic Segmentation on ADE20K
👉Settings
ADE20K是一个广泛使用的语义分割数据集,包含150个语义类别。该数据集共包含25K张图像,其中20K用于训练,2K用于验证,3K用于测试。鉴于UperNet的高效性,我们将其作为比较的base framework,更多细节见Appendix。
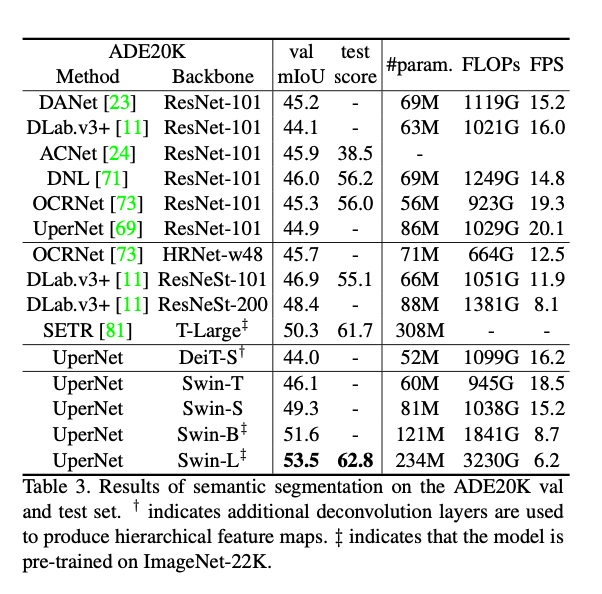
表3是在ADE20K验证集和测试集上的结果。
👉Results
表3列出了不同method/backbone pair的mIoU、模型大小(#para)、FLOPs以及FPS。可以看出,相比DeiT-S,Swin-S和其有着差不多的计算成本,但是mIoU高出了5.3个点(49.3 vs. 44.0)。此外,Swin-S的mIoU比ResNet-101高出4.4个点,比ResNeSt-101高出2.4个点。我们的Swin-L模型(经过ImageNet-22K预训练)在验证集上达到了53.5的mIoU,比之前的最好成绩(SETR的50.3 mIoU)高出3.2个点。
4.4.Ablation Study
在本节中,我们使用ImageNet-1K图像分类,COCO目标检测任务的Cascade Mask R-CNN以及ADE20K语义分割任务的UperNet,讨论了Swin Transformer中的一些重要设计元素。
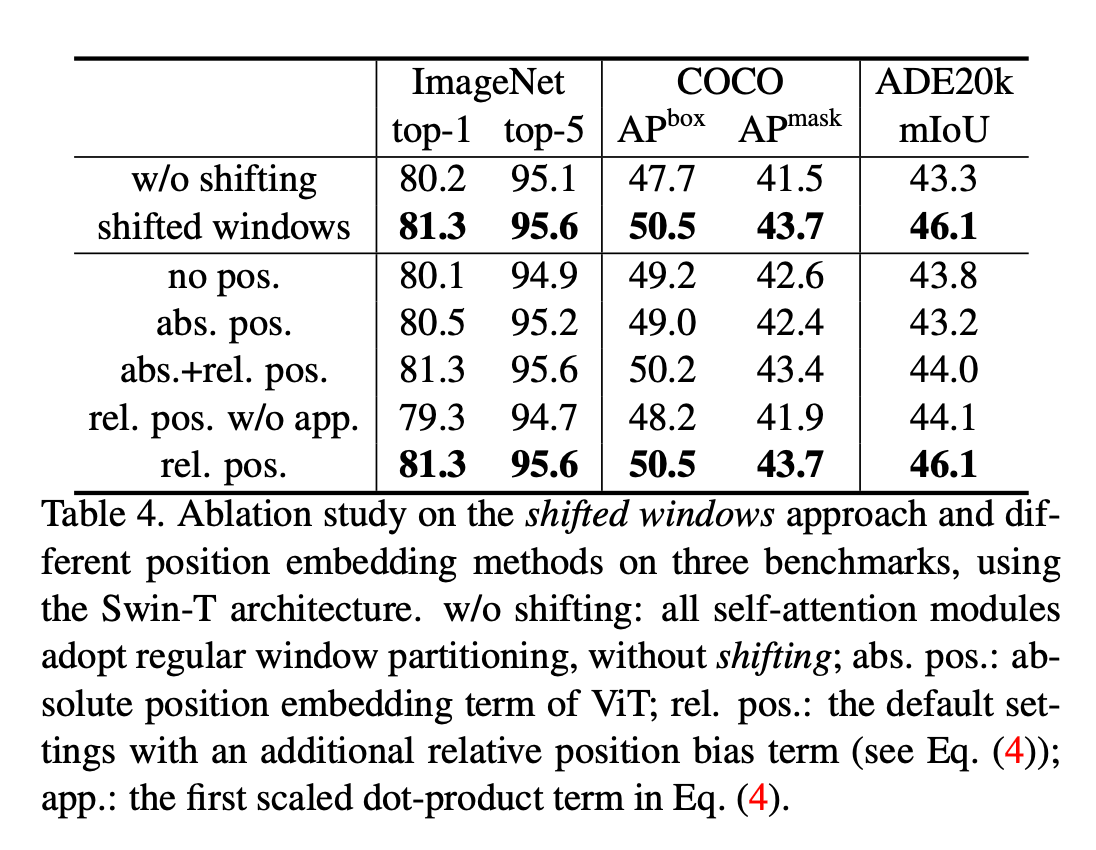
表4是基于Swin-T,做的关于shifted windows和不同position embedding的消融实验,用了3种benchmarks。表4中一些条目的解释:
- w/o shifting:所有自注意力模块都使用常规窗口划分,不使用shifting。
- abs. pos.:指的是ViT中所用的绝对位置编码(absolute position embedding)。
- rel. pos.:本文提出的相对位置编码,即公式(4)中的$B$。
- app.:式(4)中的$QK^T/\sqrt{d}$项。
👉Shifted windows
从表4中可以看出,基于Swin-T,相比常规窗口划分,shifted windows带来了性能的提升,在ImageNet-1K上,将top-1准确率提升了1.1个点;在COCO上,将box AP提升了2.8个点,mask AP提升了2.2个点;在ADE20K上,将mIoU提升了2.8个点。这些结果表明了shifted windows的有效性。并且,shifted windows的latency也很小,详见表5。
👉Relative position bias
相比不使用位置编码或使用绝对位置编码,使用相对位置编码给Swin-T带来了性能上的提升,在ImageNet-1K上,将top-1准确率提升了1.2%/0.8%;在COCO上,将box AP提升了1.3/1.5,将mask AP提升了1.1/1.3;在ADE20K上,将mIoU提升了2.3/2.9,以上结果说明了相对位置编码的有效性。并且需要注意的是,相比不使用位置编码,使用绝对位置编码仅仅提升了图像分类任务的准确率(+0.4%),但是却降低了在目标检测和语义分割任务上的表现(在COCO上,-0.2 box/mask AP,在ADE20K上,-0.6 mIoU)。
👉Different self-attention methods
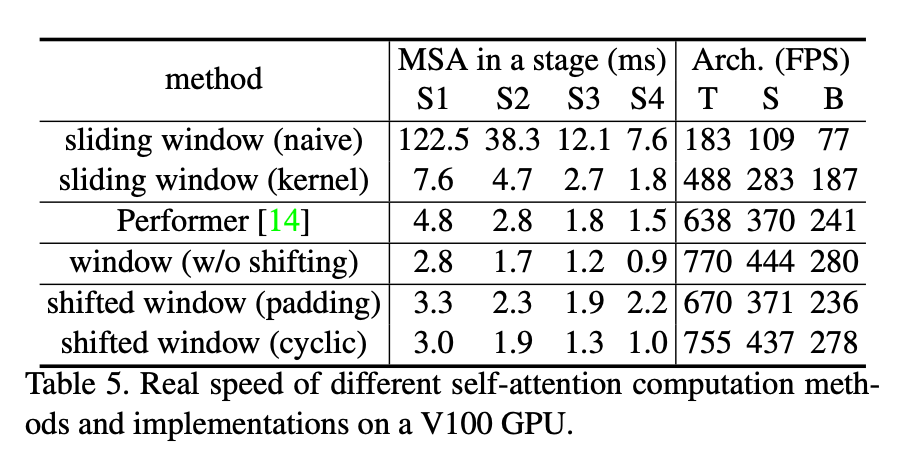
不同自注意力计算方式的real speed(基于V100 GPU)比较见表5。相比直接padding,我们提出的循环移位的方法更有效率,尤其是deeper stages的时候。总的来看,我们的方法将Swin-T、Swin-S和Swin-B分别提速了13%、18%和18%。
(755-670)/670=0.1268656716
(437-371)/371=0.1778975741
(278-236)/236=0.1779661017
对于每个stage,相比sliding windows(naive)和sliding windows(kernel),shifted window的效率分别是其的40.8/2.5,20.2/2.5,9.3/2.1,7.6/1.8倍。从推理速度上来看,对于Swin-T、Swin-S以及Swin-B,相比sliding windows(naive)和sliding windows(kernel),shifted window的推理速度分别是其的4.1/1.5,4.0/1.5,3.6/1.5倍。表6展示了它们在这3个任务上的准确率,可以看出,它们的准确率是差不多的。
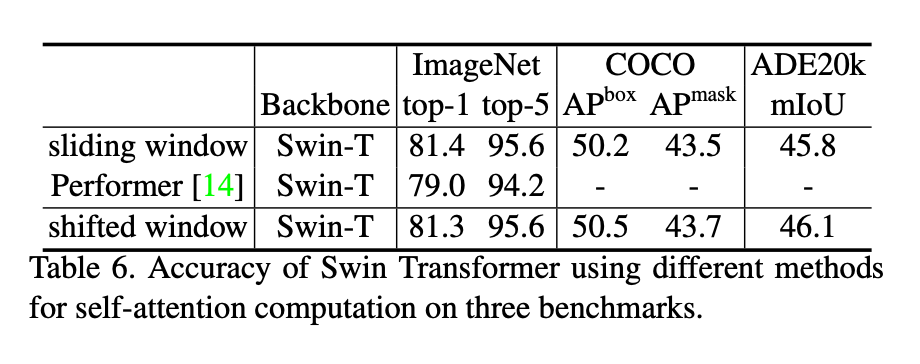
和Performer(最快的Transformer框架之一)进行比较,shifted window更快(见表5),且在ImageNet-1K上的top-1准确率更高(高出2.3%)。
5.Conclusion
本文提出了Swin Transformer,一种新的vision Transformer框架,可以产生hierarchical feature representation,计算复杂度和输入图像大小呈线性关系。在COCO目标检测和ADE20K语义分割任务上,Swin Transformer都达到了SOTA的水平。我们希望Swin Transformer在CV领域的优异表现可以促进CV和NLP的大一统建模。
基于shifted window的自注意力是Swin Transformer的一个关键元素,其在解决视觉问题上被证明是有效的,我们也期待着其在NLP中的应用。
6.A1.Detailed Architectures
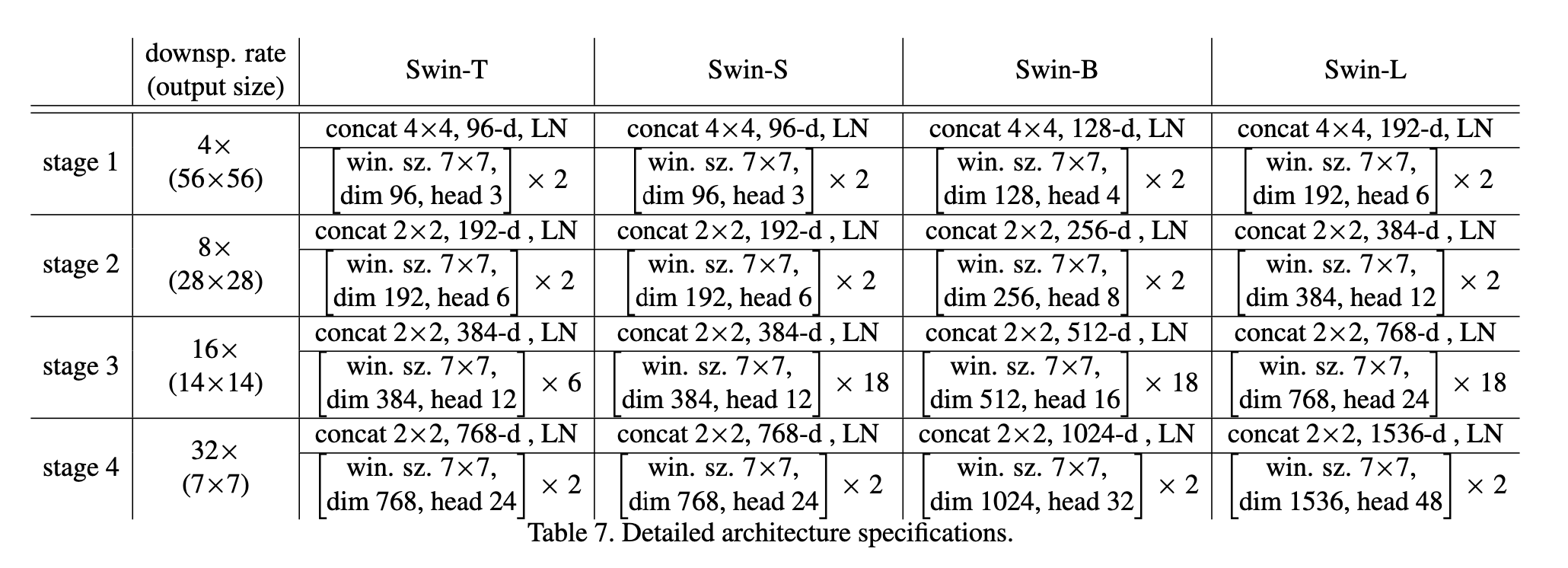
模型框架的详细信息见表7,输入大小均为$224 \times 224$。
- “Concat $n\times n$”:表示下采样的比例。Fig3(a)中的”Patch Partition”+”Linear Embedding”可以看作是一个”Patch Merging”。
- “96-d”表示经过”Linear Embedding”或”Patch Merging”后的通道数。
- “LN”表示LayerNorm。
- “win. sz. $7\times 7$”表示用于计算多头自注意力的窗口大小为$7\times 7$。
6.A2.Detailed Experimental Settings
6.A2.1.Image classification on ImageNet-1K
在最后一个stage输出的feature map上应用一个全局平均池化,最后再接一个线性分类器来执行图像分类任务。我们发现这种策略和使用额外的class token(ViT和DeiT)的效果差不多。评估时使用single crop的top-1准确率。
👉Regular ImageNet-1K training
training settings大部分遵照论文“Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve ́ Je ́gou. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.”。对于所有的模型变体,我们默认输入图像分辨率为$224^2$。对于其他分辨率,比如$384^2$,我们会先在$224^2$分辨率上进行预训练,然后在$384^2$上fine-tune,这样做以减少GPU消耗。
除了第4.1部分中提到的训练细节外,还使用了gradient clipping(max norm=1)。在训练过程中,我们使用了大部分的augmentation和正则化策略,包括RandAugment、Mixup、Cutmix、random erasing和stochastic depth,但是没有使用repeated augmentation和Exponential Moving Average(EMA),因为这两种方法对提升性能没有帮助。模型越大,stochastic depth越大,比如Swin-T、Swin-S和Swin-B分别使用0.2、0.3和0.5。
当在更大的分辨率上进行fine-tune的时候,optimizer使用AdamW,训练30个epoch,学习率保持不变($10^{-5}$),weight decay为$10^{-8}$,使用和上一段中一样的augmentation和正则化策略,唯一不同的地方在于stochastic depth ratio设为0.1。
👉ImageNet-22K pre-training
训练分为两个阶段,在ImageNet-22K预训练阶段,输入大小为$224^2$。在ImageNet-1K上fine-tune阶段,输入大小为$224^2 / 384^2$。其余训练细节见本文第4.1部分。
6.A2.2.Object detection on COCO
详见第4.2部分的Settings。此外,在COCO上进行目标检测时,在最后一个stage的输出后面又接了一个全局的自注意力层。在ImageNet-22K上进行了预训练。对于所有的Swin Transformer模型,都使用了stochastic depth(ratio=0.2)。
6.A2.3.Semantic segmentation on ADE20K
在训练时,optimizer使用AdamW,初始学习率为$6\times 10^{-5}$,weight decay为0.01,linear learning rate decay,linear warmup(1500次迭代)。使用8块GPU,每块GPU处理2张图像,迭代160K次。至于augmentations,我们采用mmsegmentation中的默认设置,包括random horizontal flipping、random re-scaling within ratio range [0.5, 2.0]和random photometric distortion。对于所有的Swin Transformer模型,stochastic depth ratio都为0.2。Swin-T,Swin-S与之前的方法一样,在标准设置上进行训练,输入大小为$512 \times 512$。带有$\mathop{}_{+}^{+}$的Swin-B和Swin-L两个模型在ImageNet-22K上进行预训练,输入大小为$640 \times 640$。
在推理阶段,使用multi-scale test,即测试图像的分辨率分别调整为训练图像分辨率的$[0.5, 0.75, 1.0, 1.25, 1.5, 1.75]$倍。训练集和验证集被用于训练,在测试集上进行评估。
6.A3.More Experiments
6.A3.1.Image classification with different input size
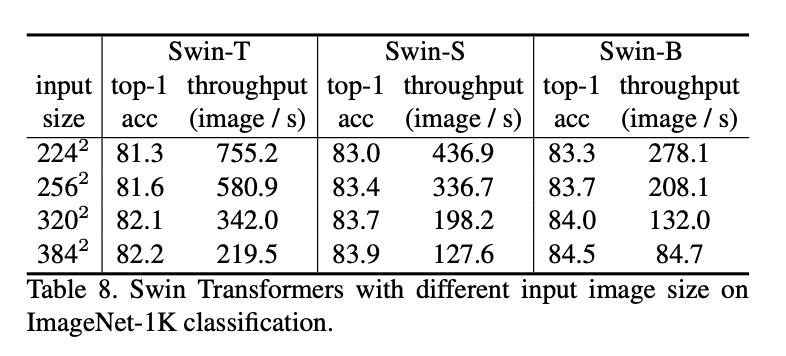
表8列出了Swin Transformers在不同输入分辨率上的性能表现(从$224^2$到$384^2$)。通常情况下,更大的输入分辨率意味着更高的top-1准确率和更低的推理速度。
6.A3.2.Different Optimizers for ResNe(X)t on COCO
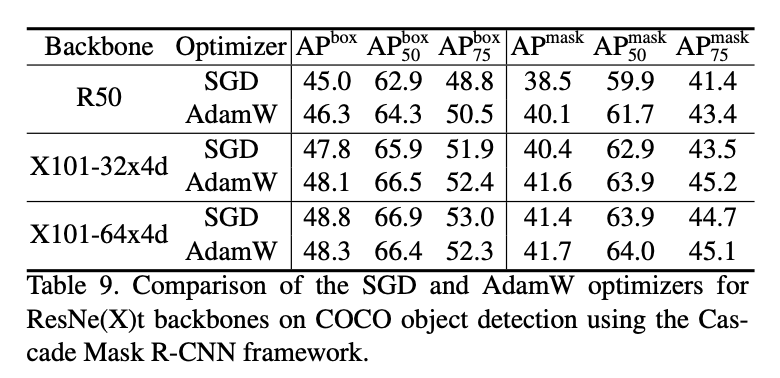
表9比较了在COCO目标检测任务中,以ResNe(X)t作为backbones时,AdamW和SGD之间的区别。比较基于Cascade Mask R-CNN框架。该框架默认的optimizer是SGD,但我们发现使用AdamW作为optimizer通常可以提升其性能,尤其是对于小一点的backbones。因此,在和Swin Transformer比较时,我们使用AdamW作为ResNe(X)t backbones的optimizer。
6.A3.3.Swin MLP-Mixer
我们将hierarchical design和shifted window应用于MLP-Mixer框架,并将其称为Swin-Mixer。在表10中,我们比较了Swin-Mixer和原始的MLP-Mixer,以及其后续变体ResMLP。Swin-Mixer-B/D24的表现明显优于MLP-Mixer-B/16,准确率更高(81.3% vs. 76.4%),计算成本更低(10.4G vs. 12.7G)。相比ResMLP,Swin-Mixer有着更好的speed accuracy trade-off。这些结果表明hierarchical design和shifted window是可推广的。
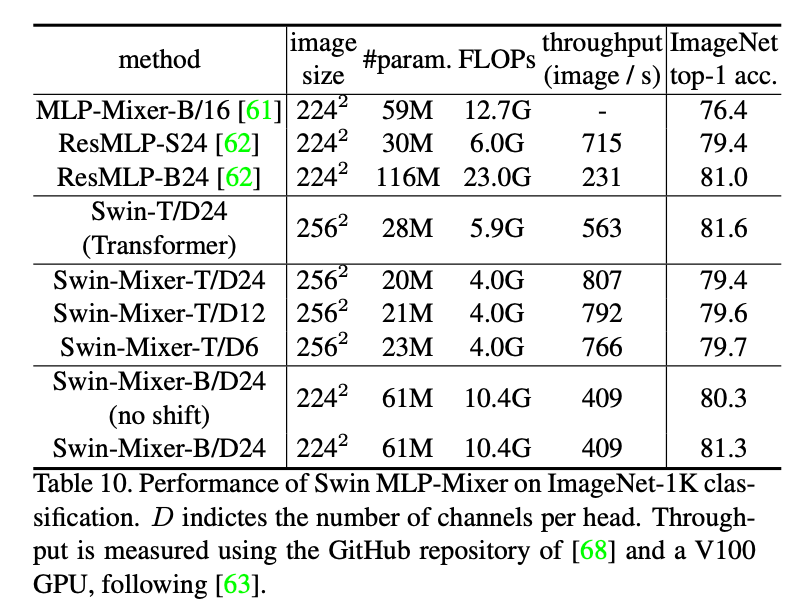
表10展示了Swin MLP-Mixer在ImageNet-1K图像分类任务上的表现。$D$表示每个头的通道数量(即token长度)。Throughput的测试基于Pytorch image models和一块V100 GPU。
7.原文链接
👽Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
