【C++基础】系列博客为参考《C++ Primer中文版(第5版)》(C++11标准)一书,自己所做的读书笔记。
本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.无序容器
新标准定义了4个无序关联容器(unordered associative container)。这些容器不是使用比较运算符来组织元素,而是使用一个哈希函数(hash function)和关键字类型的==运算符。在关键字类型的元素没有明显的序关系的情况下,无序容器是非常有用的。在某些应用中,维护元素的序代价非常高昂,此时无序容器也很有用。
虽然理论上哈希技术能获得更好的平均性能,但在实际中想要达到很好的效果还需要进行一些性能测试和调优工作。因此,使用无序容器通常更为简单(通常也会有更好的性能)。
如果关键字类型固有就是无序的,或者性能测试发现问题可以用哈希技术解决,就可以使用无序容器。
1.1.使用无序容器
除了哈希管理操作之外,无序容器还提供了与有序容器相同的操作(find、insert等)。这意味着我们曾用于map和set的操作也能用于unordered_map和unordered_set。类似的,无序容器也有允许重复关键字的版本。
因此,通常可以用一个无序容器替换对应的有序容器,反之亦然。但是,由于元素未按顺序存储,一个使用无序容器的程序的输出(通常) 会与使用有序容器的版本不同。
1.2.管理桶
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。为了访问一个元素,容器首先计算元素的哈希值,它指出应该搜索哪个桶。容器将具有一个特定哈希值的所有元素都保存在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。因此,无序容器的性能依赖于哈希函数的质量和桶的数量和大小。
对于相同的参数,哈希函数必须总是产生相同的结果。理想情况下,哈希函数还能将每个特定的值映射到唯一的桶。但是,将不同关键字的元素映射到相同的桶也是允许的。当一个桶保存多个元素时,需要顺序搜索这些元素来查找我们想要的那个。计算一个元素的哈希值和在桶中搜索通常都是很快的操作。但是,如果一个桶中保存了很多元素,那么查找一个特定元素就需要大量比较操作。
无序容器提供了一组管理桶的函数,如表11.8所示。这些成员函数允许我们查询容器的状态以及在必要时强制容器进行重组。

1.3.无序容器对关键字类型的要求
默认情况下,无序容器使用关键字类型的==运算符来比较元素,它们还使用一个hash<key_type>类型的对象来生成每个元素的哈希值。标准库为内置类型(包括指针)提供了hash模板。还为一些标准库类型,包括string和智能指针类型定义了hash。因此,我们可以直接定义关键字是内置类型(包括指针类型)、string还是智能指针类型的无序容器。
但是,我们不能直接定义关键字类型为自定义类类型的无序容器。与容器不同,不能直接使用哈希模板,而必须提供我们自己的hash模板版本。
我们不使用默认的hash,而是使用另一种方法,类似于为有序容器重载关键字类型的默认比较操作。为了能将Sales_data用作关键字,我们需要提供函数来替代==运算符和哈希值计算函数。我们从定义这些重载函数开始:
1
2
3
4
5
6
7
8
size_t hasher(const Sales_data &sd)
{
return hash<string>()(sd.isbn());
}
bool eqOp(const Sales_data &lhs, const Sales_data &rhs)
{
return lhs.isbn() == rhs.isbn();
}
针对hash<key_type>的使用再举个例子:
1
2
3
4
5
size_t stringToHash(string str) {
std::hash<std::string> hash_fn;
size_t hash = hash_fn(str);
return hash;
}
我们的hasher函数使用一个标准库hash类型对象来计算ISBN成员的哈希值,该hash类型建立在string类型之上。类似的,eqOp函数通过比较ISBN号来比较两个Sales_data。
我们使用这些函数来定义一个unordered_multiset:
1
2
3
using SD_multiset = unordered_multiset<Sales_data, decltype(hasher)*, decltype(eqOp)*>;
//参数是桶大小、哈希函数指针和相等性判断运算符指针
SD_multiset bookstore(42, hasher, eqOp); //构造函数
如果我们的类定义了==运算符,则可以只重载哈希函数:
1
2
//使用FooHash生成哈希值;Foo必须有==运算符
unordered_set<Foo, decltype(FooHash)*> fooSet(10, FooHash);
2.哈希函数
散列函数(hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
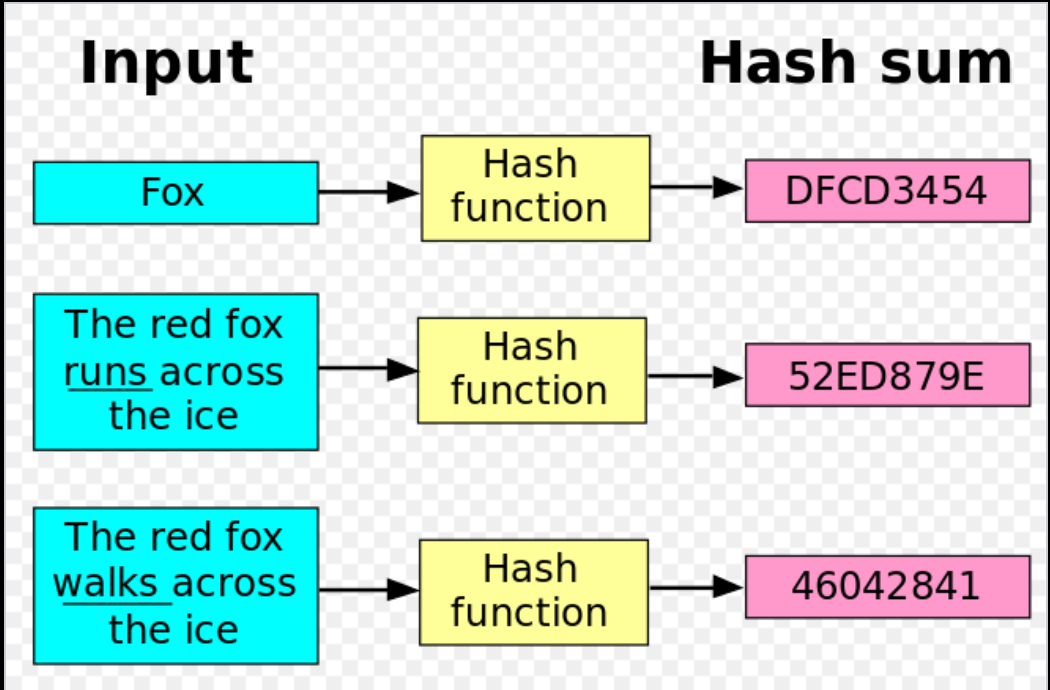
目前常见的散列算法:
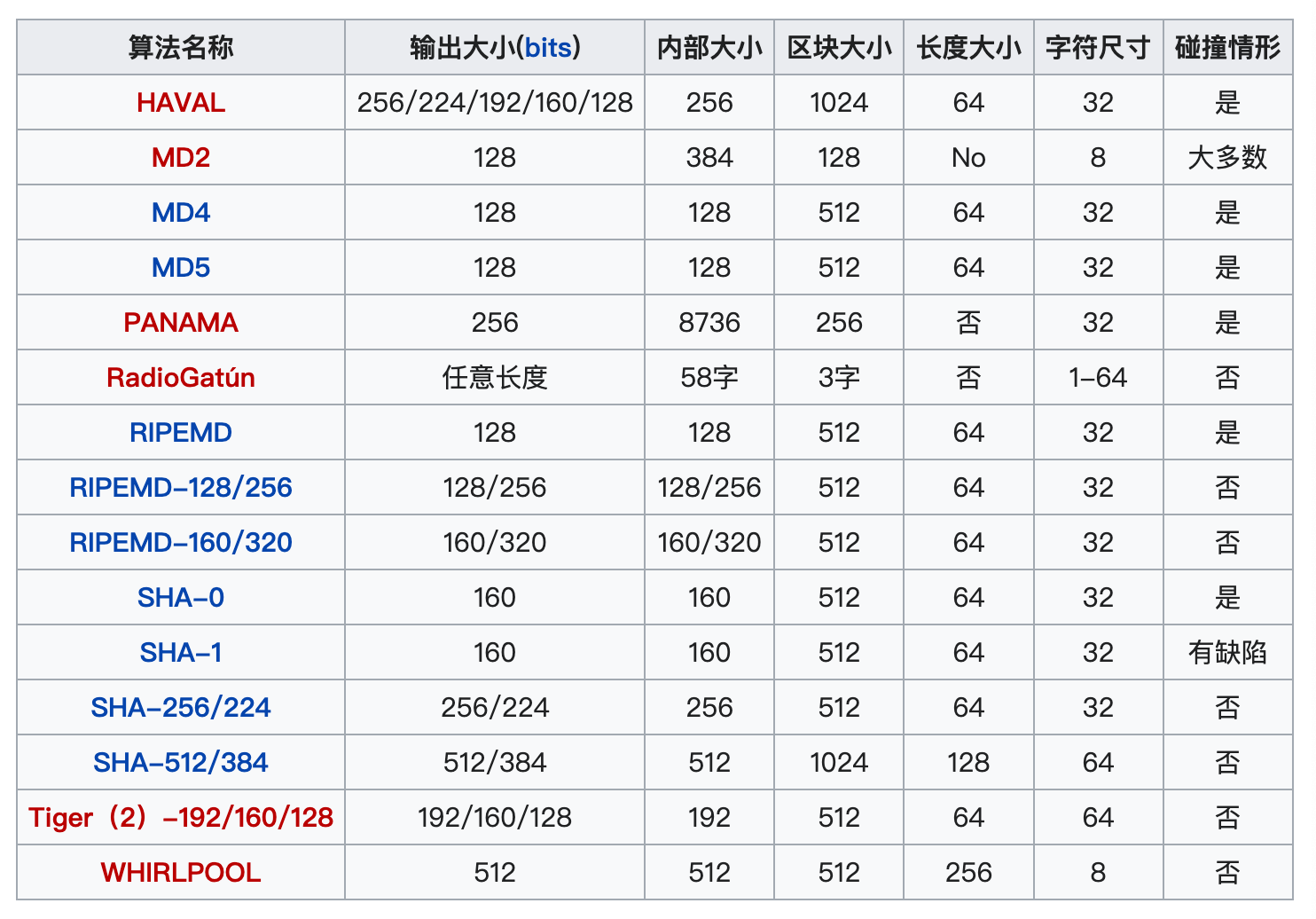
哈希函数的一些性质:
- 哈希函数可以接受任意长度的输入,一般会设定一个非常长的长度上限。
- 产生固定长度的输出。
- 不可逆性。已知哈希函数和哈希值,无法逆向演算回原本的数值。因此可以有效的保护密码。
- 对于特定的哈希函数,只要输出值不变,那么输入值也是唯一不变的。
- 哈希函数的计算时间不应过长。
- 无冲突性,即不能存在多个输入的输出是一样的。
- 即使修改了输入值的一个比特位,也会使得输出值发生巨大变化。
- 哈希函数产生的映射应当保持均匀,即不要使得映射结果堆积在小区间的某一块区域。
