本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
识别真实世界中的人类行为可以用于多个领域。但由于背景杂乱、遮挡、视角变换等原因,准确识别人类行为是非常具有挑战性的任务。
本文尝试将CNN应用于视频中的人类行为识别。提出使用3D卷积以捕获空间和时间维度上的特征。因此,我们提出了一种3D CNN框架。
3D CNN的开发基于TREC Video Retrieval Evaluation (TRECVID)数据集,该数据集是London Gatwick Airport的监控数据。
2.3D Convolutional Neural Networks
2D的卷积原理可表示为:
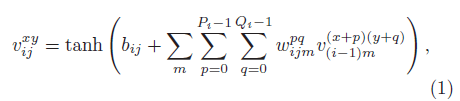
$v_{ij}^{xy}$表示第$i$层第$j$个feature map在$(x,y)$处的值。$tanh(\cdot)$是激活函数。$b_{ij}$是偏置项。$m$是第$(i-1)$层的feature map的索引。$w_{ijk}^{pq}$是作用于第$k$个feature map上的卷积核的$(p,q)$处的权值。$P_i$和$Q_i$分别是卷积核的height和width。
2.1.3D Convolution
对于视频流,我们希望可以从连续帧中捕获运动信息。3D卷积被应用在多帧堆叠在一起而形成的3D数据上。第$i$层第$j$个feature map在$(x,y,z)$处的值为:
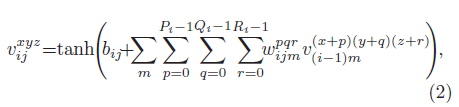
其中,$R_i$是3D卷积核沿着时间维度的大小,$w_{ijm}^{pqr}$是上一层第$m$个feature map所用的卷积核在$(p,q,r)$处的权值。2D卷积和3D卷积的比较见Fig1。
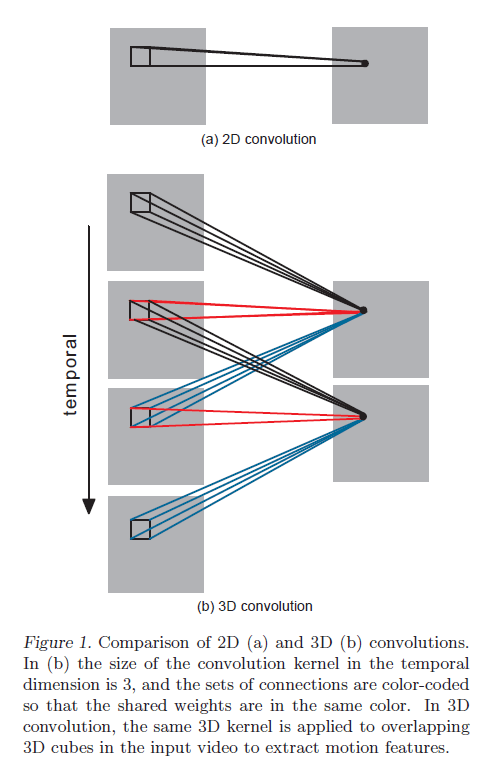
在Fig1(b)中,卷积核在时间维度的大小为3。相同颜色的卷积核表示共享权重。
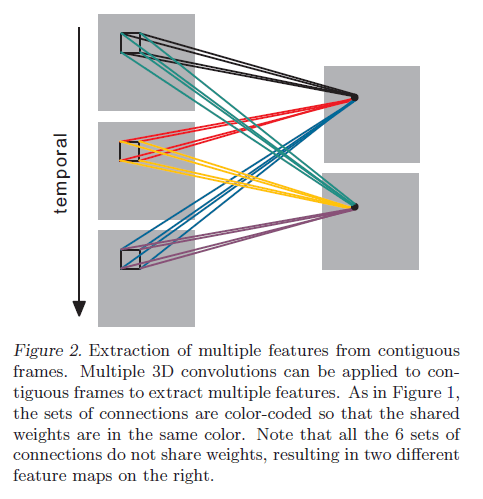
一种卷积核只能提取一种类型的特征,就像2D卷积一样,我们可以使用多个3D卷积核:
这里说一下几种卷积的区别。第一种是最常见也最简单的2D单通道卷积:
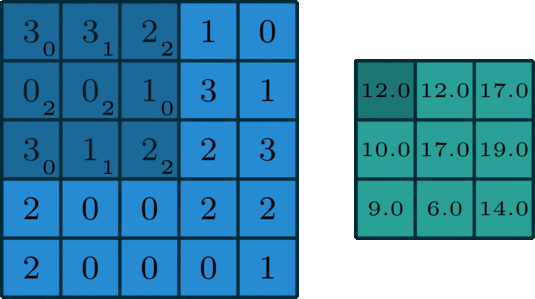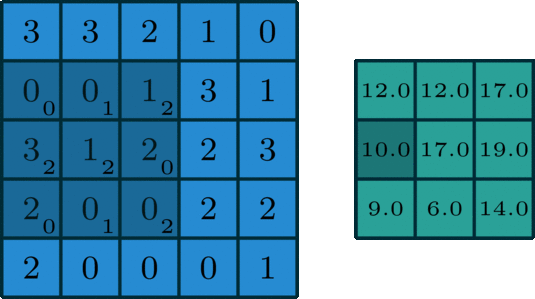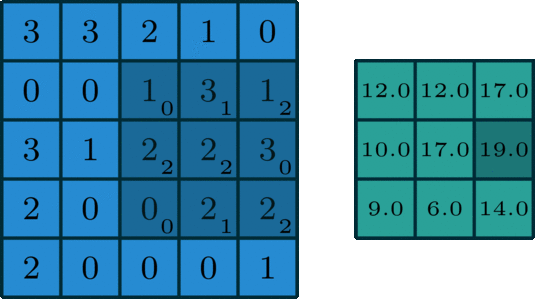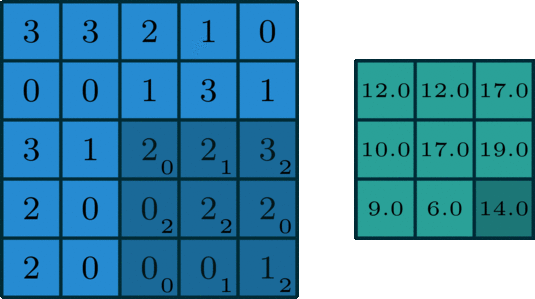
然后就是2D多通道卷积:
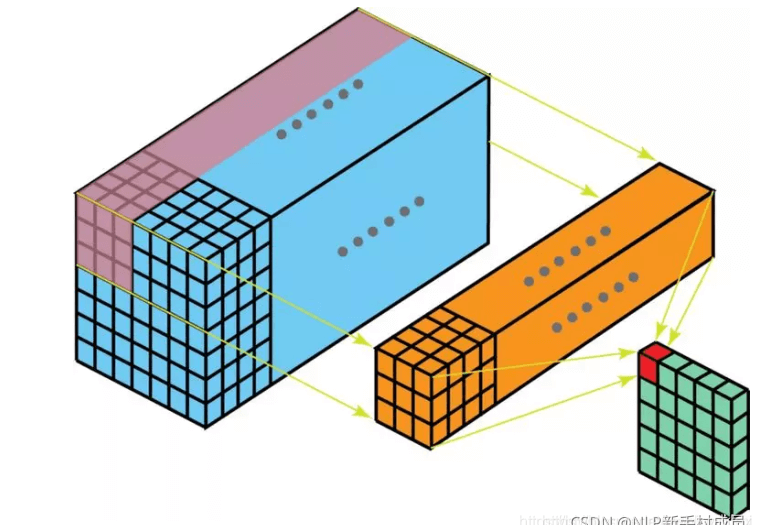
2D多通道卷积和3D卷积的区别就是,2D多通道卷积的卷积核的channel数量和feature map的channel数量必须是一样的,这样经过一个卷积核的卷积得到的结果是2维的。而3D卷积所用的卷积核的channel数量不是必须和feature map的channel数量一致的,其可以在3个方向上滑动,所以经过一个3D卷积核卷积得到的结果是3维的。下图是3D单通道卷积:
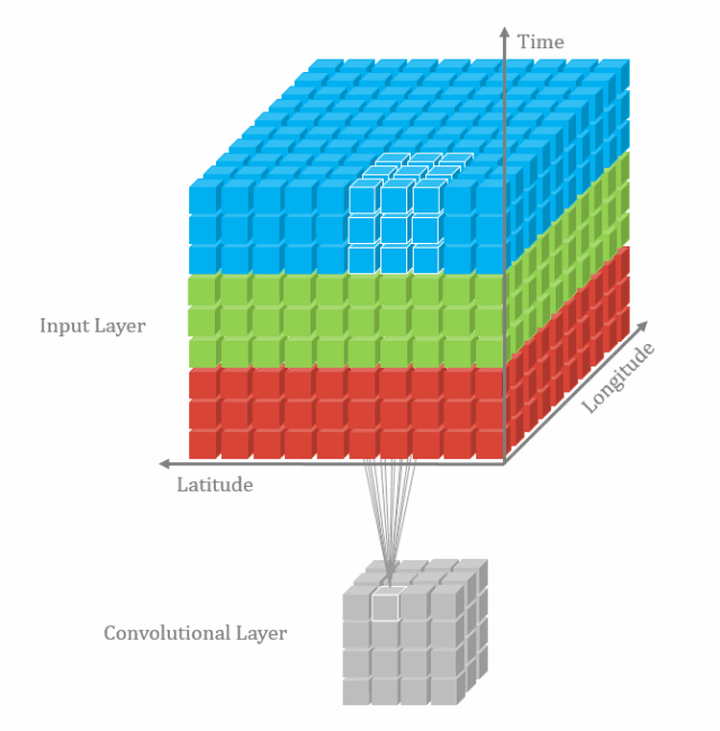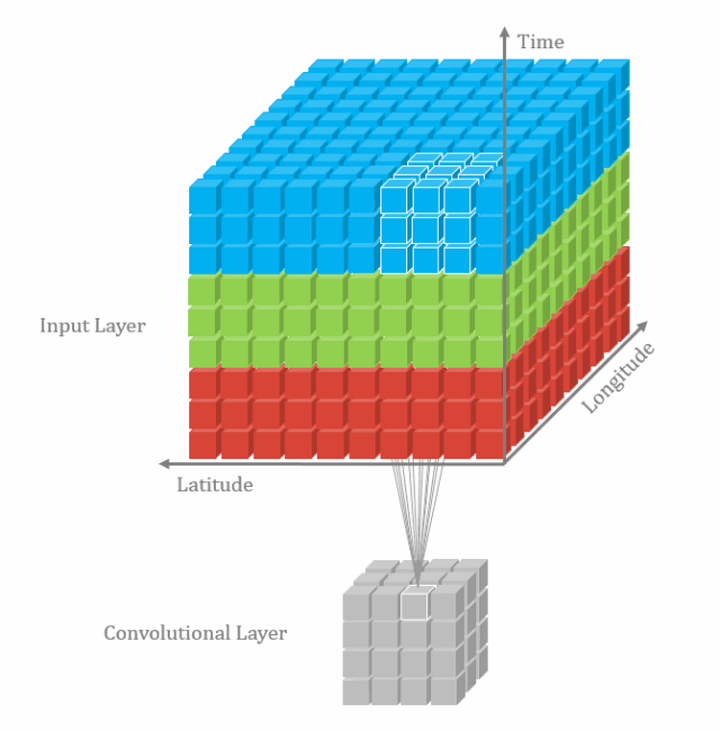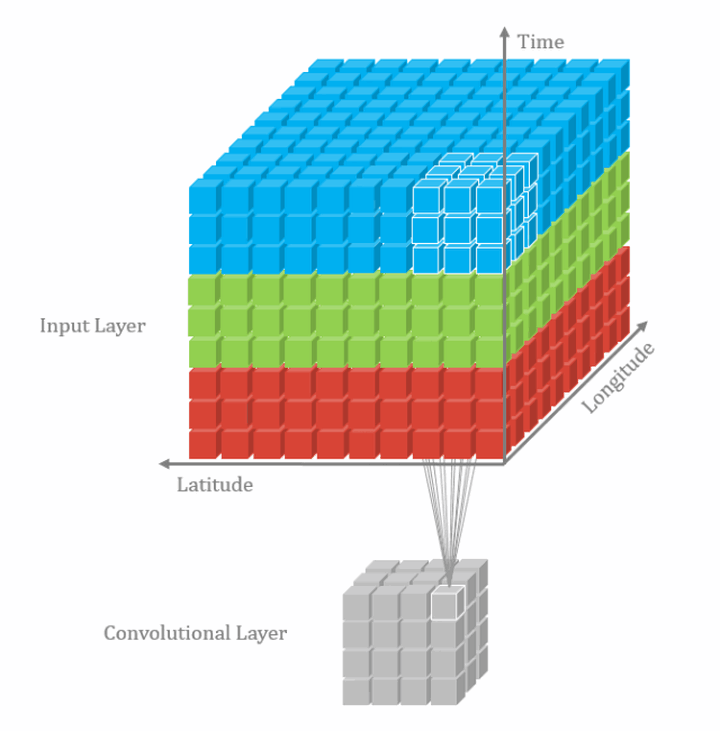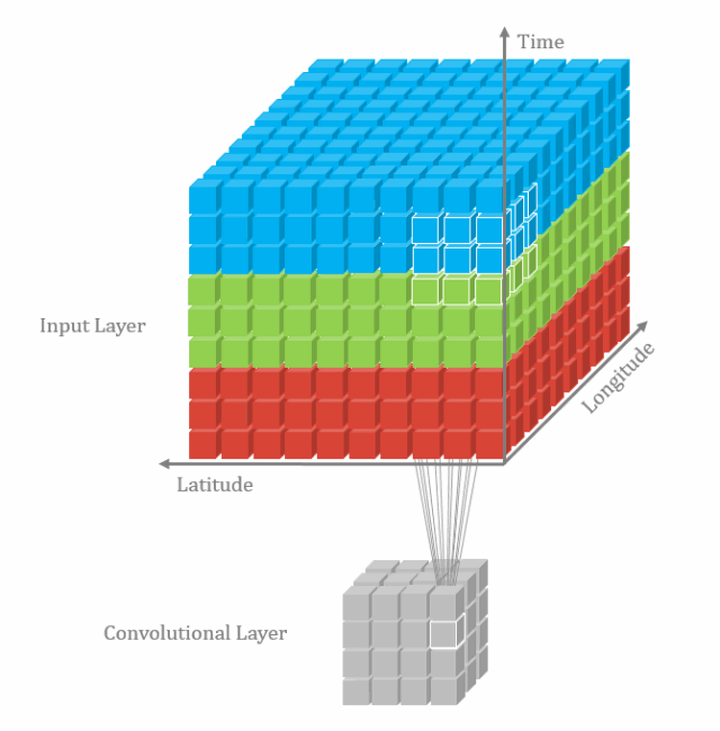
类似的,3D多通道卷积可表示为:
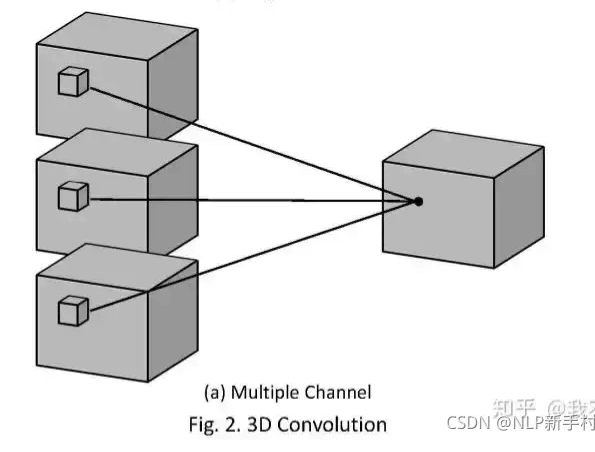
此时,3D卷积核的通道数就得和feature map的通道数一样。
2.2.A 3D CNN Architecture
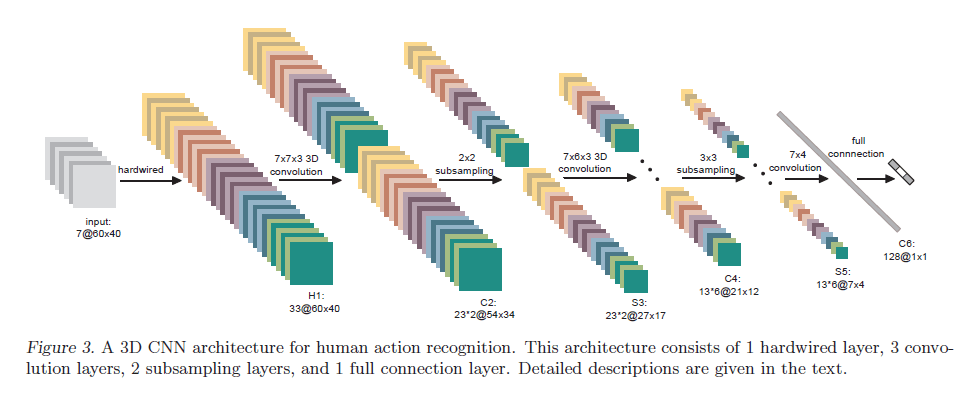
Fig3是我们提出的一个3D CNN的框架,用于在TRECVID数据集上进行人类行为识别。网络的输入是连续7帧的灰度图,每帧图像都是单通道,大小为$60 \times 40$。接下来通过hardwired操作将7张图像扩展为33个feature map(大小依然是$60 \times 40$),这一步并不是卷积。扩展方法为:
- 7张灰度图为7个feature map。
- 每张灰度图在x方向和y方向的梯度,共$7 \times 2 = 14$个feature map。
- 连续7张灰度图可以组成6个图像对($[0,1],[1,2],[2,3],[3,4],[4,5],[5,6]$),基于每个图像对可以得到一个光流估计结果(分成x方向和y方向),这个一共是$6 \times 2 = 12$个feature map。
加起来刚好是$7+14+12=33$个feature map。我们将这33个feature map视为5个不同的channel,并在每个channel上应用$7 \times 7 \times 3$的3D卷积(注意:每个channel应用的卷积核都是独立的,所以这里用了5个3D卷积核):
- 第一个channel为7张灰度图得到的7个feature map,大小为$7@60\times 40$,应用完卷积之后的大小为$5@54\times 34$(没有padding操作)。
- 第二个channel为7张灰度图在x方向的梯度,也是对应7个feature map,卷积后的大小也是$5@54\times 34$。
- 第三个channel为7张灰度图在y方向的梯度,同理,卷积后的大小为$5@54\times 34$。
- 第四个channel是x方向的光流结果,对应6个feature map,大小为$6@60\times 40$,应用完卷积之后的大小为$4@54\times 34$。
- 第五个channel是y方向的光流结果,同理,应用完卷积之后的大小为$4@54\times 34$。
上述加起来是$23@54\times 34$,这是一组3D卷积(5个3D卷积核)的结果。为了增加feature map的数量,我们使用了两组3D卷积(共10个3D卷积核),所以最终大小为$23*2@54\times 34$,即两组feature map。
这个类似于3D多通道卷积。
这一层($C2$)共有1480个可训练的参数:10个3D卷积核的参数量为$7\times 7 \times 3 \times 10=1470$,再加上每个卷积核对应的偏置项,刚好是1480个参数。在下一层$S3$中,我们使用了$2\times 2$下采样(仅在height和width方向下采样),feature map大小变为$23*2@27\times 17$。$S3$层共有92个可训练的参数,网络中的下采样就是pooling,通常情况下,max-pooling和average-pooling都是没有可训练参数的,这里作者可能使用了特殊的pooling方式,文中并没有详述。
$C4$的操作和$C2$类似,在$C4$中,我们使用$7 \times 6 \times 3$大小的卷积核,针对每组feature map,我们都使用了3组3D卷积,所以最后我们能得到6组feature map。以其中一组为例:
- 第一个channel经过卷积后,大小从$5@27\times 17$变为$3@21\times 12$。
- 第二个channel经过卷积后,大小从$5@27\times 17$变为$3@21\times 12$。
- 第三个channel经过卷积后,大小从$5@27\times 17$变为$3@21\times 12$。
- 第四个channel经过卷积后,大小从$4@27\times 17$变为$2@21\times 12$。
- 第五个channel经过卷积后,大小从$4@27\times 17$变为$2@21\times 12$。
所以一组feature map的大小为$13@21\times 12$。一共6组,就是$13*6@21\times 12$。$C4$层一共有3810个可训练参数:$7\times 6 \times 3 \times 5 \times 6 = 3780$个卷积核权值,再加上$5 \times 6 = 30$个偏置项。下一层$S5$也是仅在height和width方向上做$3\times 3$的下采样,得到的feature map大小为$13*6@7\times 4$。$S5$层的可训练参数有156个。接下来的$C6$层,直接使用128个$7 \times 4$大小的2D卷积(每个卷积核的通道数为$13 * 6 = 78$)把维度降到$128@1\times 1$。这一层一共有289536个可训练参数:128个卷积核共有$7 \times 4 \times 78 \times 128 = 279552$个参数,再加上$78 \times 128 = 9984$个偏置项。
我们在$C6$的128维向量上使用线性分类器进行动作分类。假设我们有3种动作类型,那么输出层就有3个输出单元,就需要3个线性分类器,此时输出层的可训练参数的数量为384。该3D CNN模型的总参数量为295458,参数都被随机初始化。我们也设计并评估了其他3D CNN框架,但结果表明这种框架结构是最优的。
3.Related Work
不再详述。
4.Experiments
我们在TRECVID 2008和KTH数据集上评估了该3D CNN模型在运动识别方面的表现。
4.1.Action Recognition on TRECVID Data
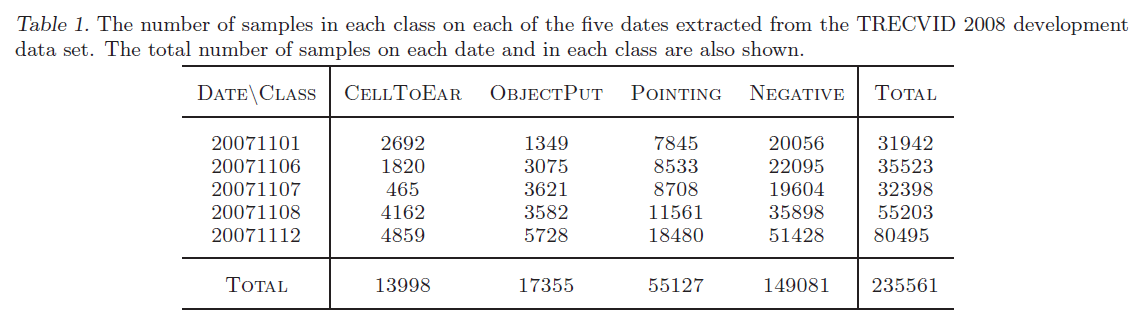
TRECVID 2008数据集包含长达49小时的视频数据,来自London Gatwick Airport的5个不同的摄像头,视频分辨率为$720 \times 576$,帧率为25FPS。其中4号摄像头因为拍摄到的事件过少而被排除在外。我们主要关注3个动作类别:CellToEar、ObjectPut、Pointing。我们使用的数据统计见表1。NEGATIVE表示负样本。
由于视频是在真实世界中录制的,所以每帧都包含多个人,因此我们使用了人脸检测模型来定位这些人。检测结果见Fig4。

基于人脸检测的结果,计算出每个人的bounding box。然后我们会抽取当前帧以及前后各3帧在同一bounding box(即当前帧的bounding box)位置上的patch作为3D CNN模型的输入。这些输入会被统一缩放至$60 \times 40$大小。在取帧的时候每隔2帧取一次,比如当前帧标记为0,那我们输入的7帧的序号应该为-6、-4、-2、0、2、4、6。
测试采用5折交叉验证的方式。4种方法的测试结果见表2。
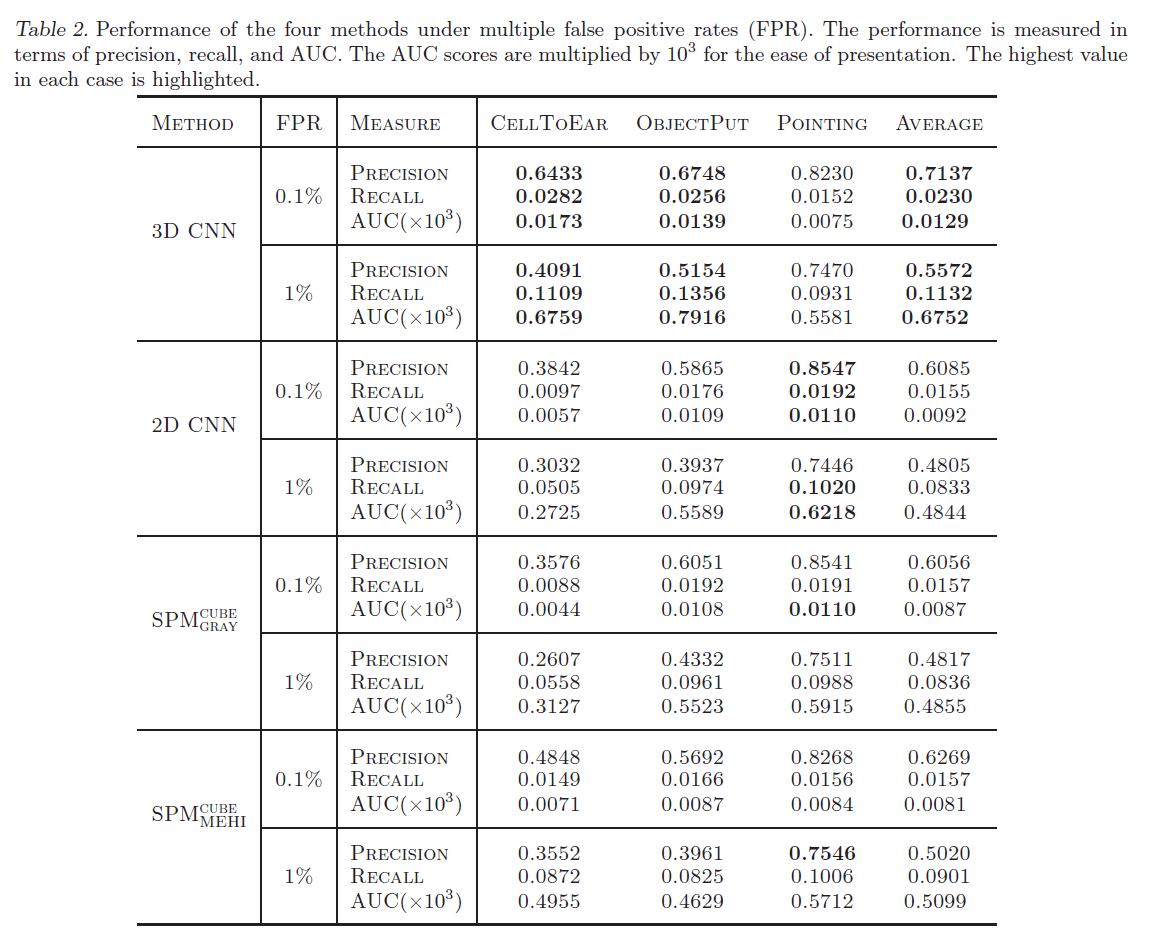
从表2中可以看到,3D CNN模型在CellToEar和ObjectPut两种动作类型上优于其他3种方法。但是在Pointing动作类型上,3D CNN模型稍差于另外3种方法。从表1中可以看到,Pointing类别的阳性样本数量远大于另外2种类别。因此,我们得到结论,在阳性样本较少的数据集上,3D CNN模型表现更优。此外,如果看平均性能的话,3D CNN模型依然是最好的。
4.2.Action Recognition on KTH Data
KTH数据集由25个人组成,共有6种动作类型。为了遵循HMAX模型,我们使用9帧作为输入并将前景提取出来。为了降低内存需求,我们将分辨率降到$80 \times 60$。模型框架依然和Fig3中基本一样,只是修改了卷积核大小和feature map数量。3个卷积层用的核大小分别为$9 \times 7$、$7 \times 7$和$6 \times 4$,两个下采样层的核大小都为$3 \times 3$。最后一层依然是128维的向量,输出为6个单元,对应6种动作类型。
我们使用16个人的数据作为训练,剩余9人的数据用于测试。比较结果见表3。

3D CNN的平均准确率高达90.2%,略低于HMAX的91.7%,但是HMAX需要手工设计特征并且所用分辨率是原始图像的4倍。
5.Conclusions and Discussions
我们证明了3D CNN模型在真实世界中的优越性能。未来将进一步探索3D CNN模型的无监督训练。
6.原文链接
👽3D Convolutional Neural Networks for Human Action Recognition
