本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction and Related Work
CNN浅层可以捕捉局部信息,深层可以捕捉全局信息。本文的目标是基于MRI数据分割出前列腺。这项任务非常具有挑战性,因为前列腺在不同扫描中的外观差异性非常大。此外,MRI图像质量也会影响分割效果。我们提出一种端到端的全卷积网络来处理MRI数据。
2.Method
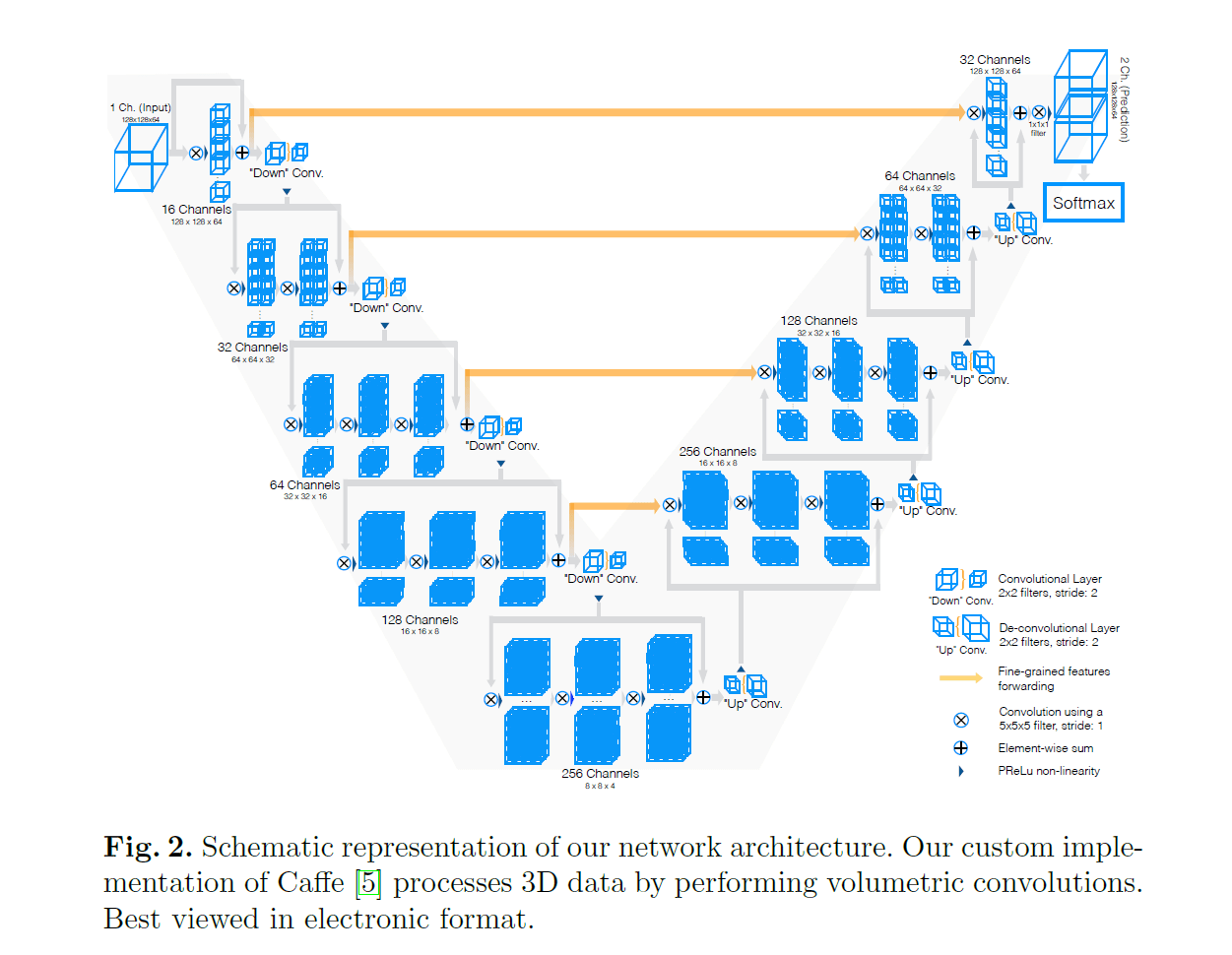
我们提出的网络框架V-Net见Fig2。网络执行的细节见下:
- 网络输入为$128 \times 128 \times 64$。
- 然后是16个大小为$5 \times 5 \times 5$的单通道3D卷积,使用了padding,得到的输出为$16@128 \times 128 \times 64$。
- 接着是一个element-wise的加法,维度从$16@128 \times 128 \times 64$变成$128 \times 128 \times 64$,并将输入的$128 \times 128 \times 64$通过残差连接也加在一起。
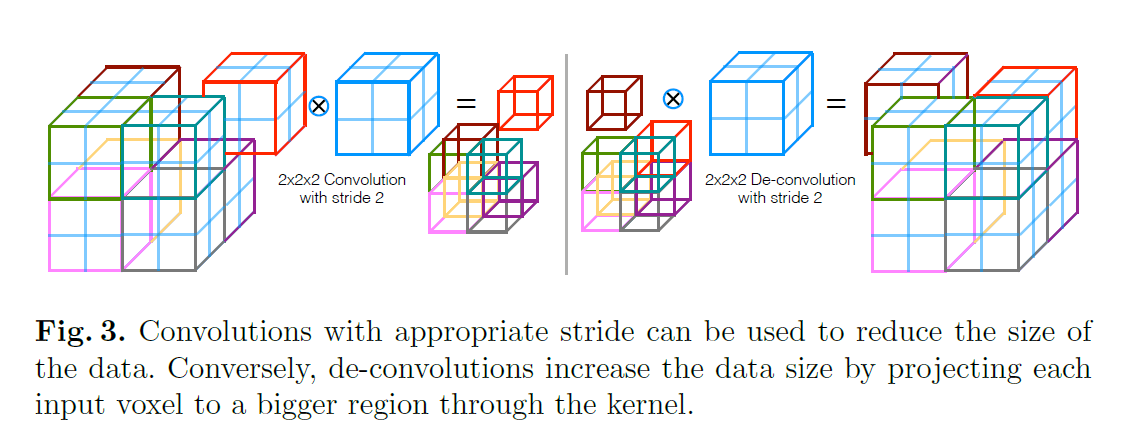
- 接着通过一个步长为2的$2\times 2 \times 2$卷积进行下采样,维度变为$64 \times 64 \times 32$。注意,这里下采样和上采样用的就是正常的卷积层,而不是pooling层。
- 然后进入下一阶段,通过32个$5 \times 5 \times 5$的单通道3D卷积,同样也使用padding,得到的输出为$32@64 \times 64 \times 32$。然后是32个$32@5 \times 5 \times 5$的多通道3D卷积,得到的输出依然是$32@64 \times 64 \times 32$。接着就是残差连接和下采样,和之前方式一样。
- 后续的阶段以及上采样过程都类似,不再赘述。
上采样和下采样的方式见Fig3:
激活函数用的都是PReLu。最后通过$1 \times 1 \times 1$卷积生成2个大小为$128 \times 128 \times 64$的feature map,并使用softmax函数将其转换为voxel属于前景和背景的概率。和U-Net类似,V-Net中也使用了横向连接(见Fig2黄线),这提高了模型性能并且加快了收敛速度。横向传递过来的feature map和上一层上采样拿到的feature map是concat在一起的。以第一次上采样为例,我个人理解此时concat后的feature map大小是$2@16 \times 16 \times 8$的,一个卷积核大小为$2@5\times 5 \times 5$,然后一个卷积核得到的结果是$16 \times 16 \times 8$,一共需要256个这样的卷积核,最终得到的feature map大小就是$256@16 \times 16 \times 8$。
我们计算了每层的感受野大小,见表1。

从表1中可以看出,网络内部的感受野已经超过了输入的大小,可以更好的感知全局信息。
3.Dice loss layer
网络输出包括2个和Input一样大小的volume,在经过softmax之后得到一个和Input大小一样的volume,里面保存着每个voxel属于前景的概率。对于医学volume数据来说,感兴趣的区域只占整体数据的一小部分是很常见的。这通常会导致网络学习过程陷入损失函数的局部最小值,从而产生一个预测强烈偏向背景的网络。这就导致前景经常被漏掉或者只被检测到部分。之前的一些方法只是通过简单的加权,使得在学习过程中,前景区域比背景区域更重要。在本文中,我们提出一种新的基于dice系数的目标函数,dice系数的取值范围在0到1之间,我们的目标是最大化这个目标函数。两个二值volume之间的dice系数$D$可以表示为:
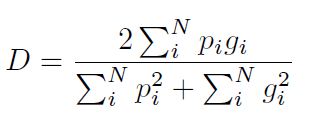
两个volume,每个都有$N$个voxel,$p_i \in P$是预测分割结果的二值volume,$g_i \in G$是GT的二值volume。这个公式的梯度计算为:
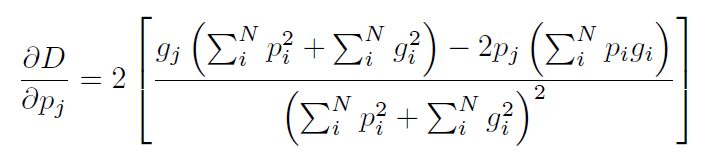
使用这个公式,我们不再需要为不同类别的样本分配权重,并且训练得到的网络性能也比通过加权方式训练得到的网络性能要更好(见Fig6)。
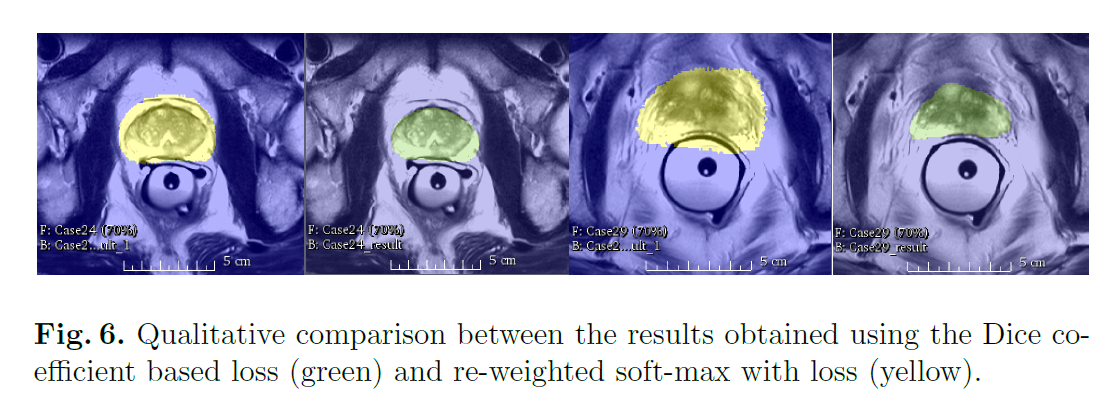
在Fig6中,绿色是基于Dice系数的loss得到的分割结果,黄色是基于加权softmax的loss得到的分割结果。
3.1.Training
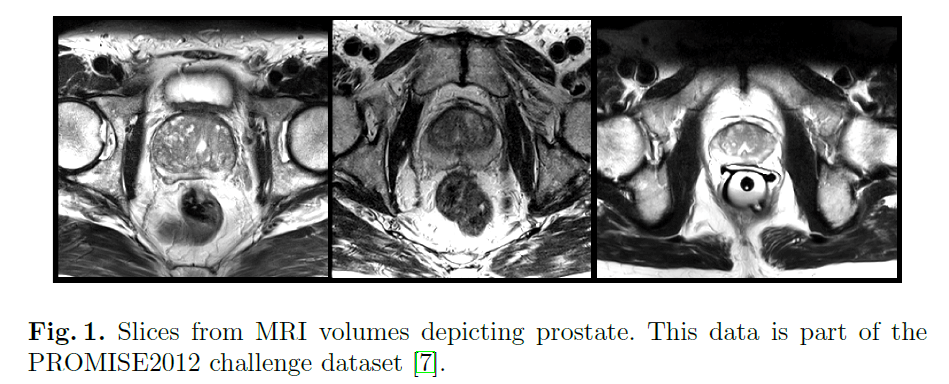
我们的网络在前列腺MRI数据上进行了端到端的训练。数据形式见Fig1。所有数据的大小都是$128 \times 128 \times 64$,分辨率均为$1mm \times 1mm \times 1.5mm$。
在训练的每次迭代,输入图像都会被施加随机形变作为数据扩展。此外,还会调整输入数据的像素值分布。
3.2.Testing
本部分比较简单,不再赘述。
4.Results
我们在50组MRI数据上进行了训练。由于内存限制,一个mini-batch包含两个volume。momentum=0.99,初始学习率为0.0001,每25K次迭代,学习率降低一个数量级。我们在30组前列腺MRI数据上测试了V-Net。测试结果见表2和Fig5。
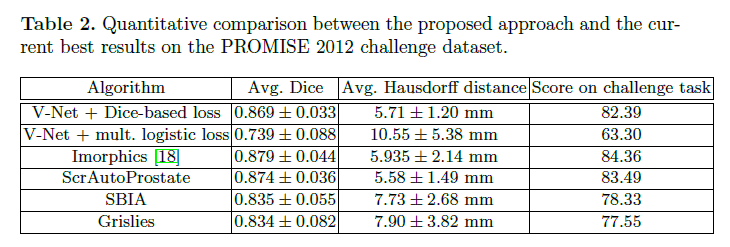
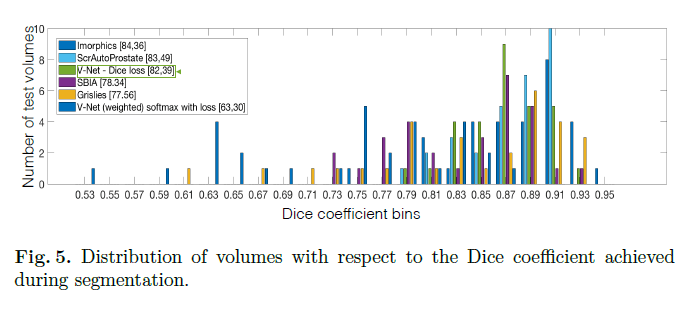
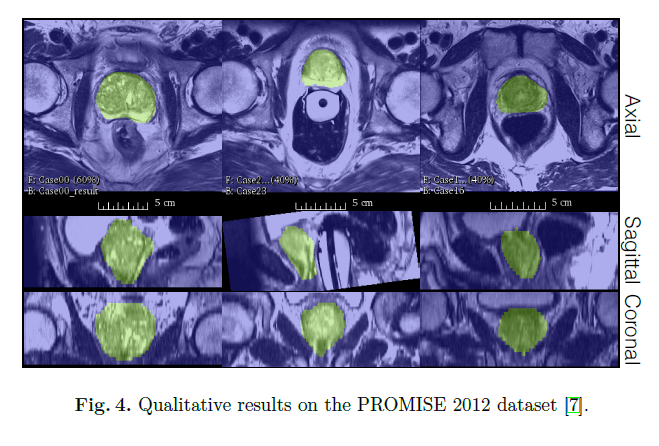
我们使用python语言和Caffe框架。共训练了30K次迭代(使用一块8GB的Nvidia GTX 1080 GPU)。定性结果见Fig4。
官方实现见:https://github.com/faustomilletari/VNet。
5.Conclusion
对全文的总结,不再详述。
6.原文链接
👽V-Net:Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
