本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.Introduction
寻找同一场景或物体的两幅图像之间的关系是许多计算机视觉应用的一部分。比如相机校正、3D重建、图像配准和物体识别等。这类工作通常可分为三个步骤。首先,在图像的不同位置找到一些感兴趣的特征点,比如角点等。这些点必须具备一个重要的特性,就是在不同的观察条件下,都可以找到相同的特征点。接下来,我们用一个特征向量表示特征点的邻域。这个特征向量必须具有独特性,并且对于噪声、误差以及形变具有鲁棒性。最后一步就是匹配不同图像之间的特征向量。两个特征向量之间的匹配程度可以由这两个向量之间的距离来衡量,比如欧氏距离。此外,特征向量的维度对算法耗时有着直接影响,因此应构建较低维度的特征向量。
我们的目标就是提出一种新的特征检测(detector)和特征描述(descriptor)的方法,即保证计算速度快又不牺牲性能。因此,我们既要减少特征向量的维度和复杂度,又要保证其独特性。
2.Related Work
👉Interest Point Detectors
使用最广泛的当属Harris角点检测。但是,Harris角点检测不具备尺度不变性。SIFT是用DoG来近似LoG(Laplacian of Gaussian)。
高斯二阶导数的卷积核通常被称为拉普拉斯(Laplacian)或拉普拉斯-高斯(LoG)卷积核。它是通过对高斯函数进行二阶导数计算得到的。该卷积核可用于进行边缘检测和特定特征的提取,因为它可以同时检测图像中的边缘和角点等特征。对图像应用拉普拉斯-高斯卷积核会使得图像中的边缘和特定特征点更加明显,有助于进一步的图像分析和处理。
LoG的操作有两种方式:
- 首先对图像进行高斯模糊,然后计算高斯模糊后的图像的拉普拉斯,即二阶导数。这样做的目的是在平滑后的图像上增强边缘信息,使边缘更容易检测。LoG可以用于检测图像中的边缘和角点等特征。
- 直接使用高斯二阶导数的卷积核和图像进行卷积操作。
相关博文链接:【OpenCV基础】第十七课:Laplace算子。
通过对已有研究的总结,得到如下结论:1)基于Hessian的检测器比基于Harris的检测器更稳定,更具有可重复性。2)通过对LoG进行近似,比如使用DoG,可以在尽量不牺牲性能的情况下提升速度。
👉Feature Descriptors
讨论了多个研究,结论就是SIFT仍然是目前最好的选择,但速度确实是慢。
👉Our approach
我们提出一种新的detector-descriptor机制,称为SURF(Speeded-Up Robust Features)。SURF的detector是基于Hessian矩阵。我们使用积分图来减少计算时间,因此我们将其称之为”Fast-Hessian” detector。descriptor描述了兴趣点邻域内的Haar小波响应分布。此外,只使用了64个维度,减少了特征计算和匹配的时间,同时提高了鲁棒性。我们还提出了一个新的基于拉普拉斯符号的索引步骤,它不仅提高了匹配速度,而且提高了descriptor的鲁棒性。
3.Fast-Hessian Detector
我们的detector基于Hessian矩阵,因为它在计算时间和精度方面具有良好的性能。我们依赖于Hessian矩阵的行列式来选择location和scale。给定图像$\mathbf{I}$中的一点$\mathbf{x}=(x,y)$,则点$\mathbf{x}$在scale为$\sigma$处的Hessian矩阵$\mathcal{H}(\mathbf{x},\sigma)$可定义为:
\[\mathcal{H}(\mathbf{x},\sigma)=\begin{bmatrix} L_{xx}(\mathbf{x},\sigma) & L_{xy}(\mathbf{x},\sigma) \\ L_{xy}(\mathbf{x},\sigma) & L_{yy}(\mathbf{x},\sigma) \end{bmatrix} \tag{1}\]其中,$L_{xx}(\mathbf{x},\sigma)$是图像$\mathbf{I}$经过高斯卷积后在点$\mathbf{x}$处的二阶导$\frac{\partial ^2}{\partial x^2} g(\sigma)$,$L_{xy}(\mathbf{x},\sigma)$和$L_{yy}(\mathbf{x},\sigma)$的定义类似。
高斯对于scale-space分析是最优选择。通常情况下,高斯滤波器是连续的,但是在数字图像处理中,我们需要将其转换为离散形式以便在计算机上实现。此外,由于计算资源和图像边界等限制,滤波器通常需要裁剪为合适的大小(见Fig1左)。并且使用高斯滤波器,当对图像进行下采样(即降低图像分辨率)时,会发生混叠现象(aliasing)。作者认为高斯的重要性似乎被高估了,因此测试了一个更简单的替代方案。那就是使用盒式滤波器(box filters)来代替高斯滤波器(见Fig1右)。这些盒式滤波器可以使用积分图来快速计算。根据我们的测试结果,其和高斯滤波器效果相当。
混叠现象:
混叠(aliasing)是数字信号处理中一个常见的问题,也在数字图像处理中出现。它通常发生在信号或图像的采样过程中。
当我们对连续信号(例如声音波形、图像等)进行数字化处理时,需要对其进行采样,即在时间或空间上离散地获取一系列数据点。采样率是指每秒(或每单位距离)采集的数据点数量。采样率过低或不适当的情况下,可能会导致混叠问题。
在图像处理中,混叠指的是当图像中的高频信息(表示细节或变化较快的部分)超过了采样率的一半时,会出现错误的频率成分,从而导致图像失真。这些错误的频率成分会被错误地还原成低频信号,使得原本的高频信息被还原成错误的低频信息,从而出现了不真实的频率表示,也就是混叠。
以图像为例,假设图像中有一条非常细的黑白相间的直线。如果采样率过低,无法准确地捕捉到这条细线的每一个黑白交替的点,那么在还原图像时,就会产生不正确的频率成分,可能会将这条直线还原成更粗的黑白直线,从而出现混叠。
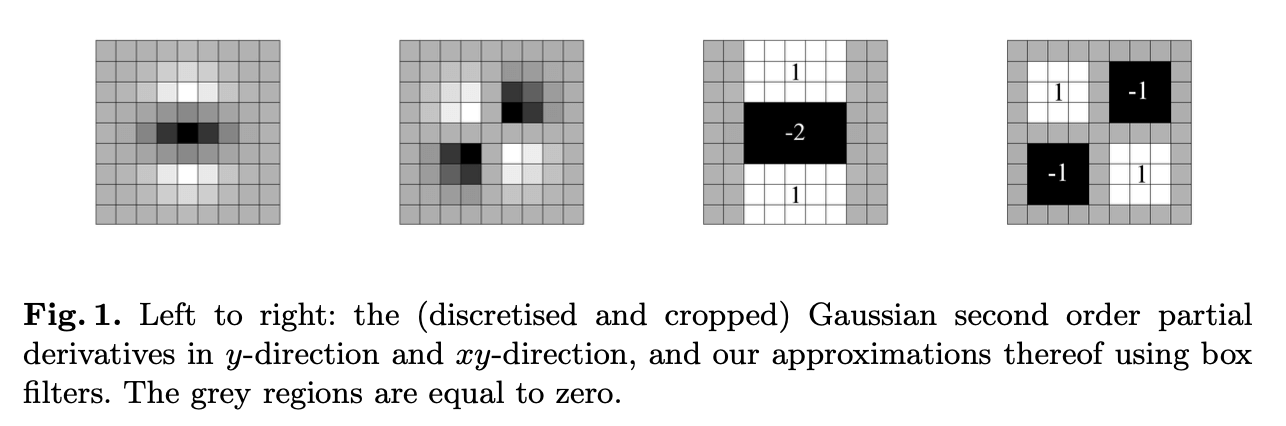
Fig1左边两张图是高斯二阶微分经过采样和离散化得到的结果。Fig1右边两张图是使用盒式滤波器得到的近似高斯二阶微分。灰色区域等于0。
Fig1中$9 \times 9$的盒式滤波器是对$\sigma=1.2$的高斯二阶导数卷积核的近似(1.2就是我们最小的scale,对应着最高的空间分辨率)。盒式滤波器计算得到的值表示为$D_{xx},D_{yy},D_{xy}$(分别是$L_{xx},L_{yy},L_{xy}$的近似)。即:
\[\mathcal{H}_{approx}=\begin{bmatrix} D_{xx} & D_{xy} \\ D_{xy} & D_{yy} \end{bmatrix}\]为了计算效率,矩形区域的权重保持简单,但我们需要进一步平衡Hessian矩阵行列式表达式中各项的相对权重,其中,
\[\frac{\lvert L_{xy} (1.2) \rvert_F \lvert D_{xx}(9)\rvert_F}{\lvert L_{xx} (1.2) \rvert_F \lvert D_{xy}(9)\rvert_F} = 0.912... \simeq 0.9\]$\lvert x \rvert_F$是F范数。行列式的计算可表示为:
\[\text{det}(\mathcal{H}_{approx}) = D_{xx} D_{yy} - (0.9 D_{xy})^2 \tag{2}\]此外,滤波器响应值都相对于mask大小进行了归一化。这保证了对于任何滤波器大小都能有恒定的F范数。
个人理解:$L_{xy} (1.2)$就是经过$\sigma=1.2$的高斯二阶导数卷积核处理后得到的图像,然后通过图像中每个像素点的值计算F范数。同理,$D_{xx}(9)$是经过$9 \times 9$盒式滤波器处理后得到的图像。
scale space通常通过图像金字塔来实现。步骤就是先高斯平滑,再下采样。但由于我们使用了盒式滤波器和积分图,我们就不必迭代地将相同的滤波器应用于先前滤波输出的结果,而是可以直接以相同的速度将任何大小的滤波器直接应用于原始图像,甚至并行应用(但此处并未使用并行)。因此,我们通过扩大滤波器的大小而不是迭代地减小图像大小来分析scale space。上述$9 \times 9$盒式滤波器的输出被视为初始尺度层,对应$\sigma = 1.2$的高斯尺度层。后续的层通过逐渐变大的滤波器尺寸来获得。我们使用的滤波器尺寸有$9\times 9,15\times 15,21\times 21,27\times 27$等。
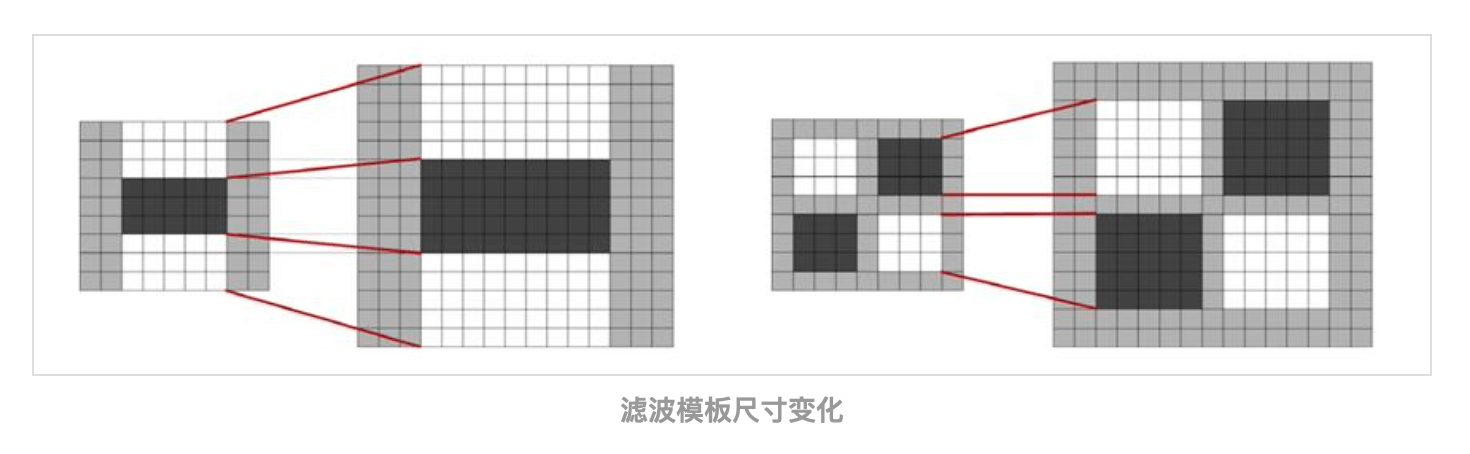
对于每个新的octave,滤波器大小的增长速度都会翻倍(比如从6到12,再到24)。同时,用于提取感兴趣点的采样间隔也可以加倍。
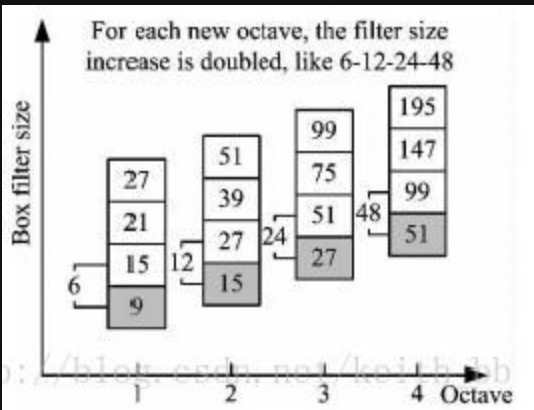
从上图中可以看到,第一个octave内,滤波器尺寸每次增加6;在第二个octave内,滤波器尺寸每次增加12;在第三个octave内,滤波器尺寸每次增加24。
在SIFT算法中,同一octave内的图像大小都是一样的,但尺度是不同的(即模糊程度是不同的),一个octave的图像大小是上一个octave的一半。但对于SURF来说,图像大小始终是不变的,变得是滤波器的尺寸。
由于我们的滤波器layout在缩放后比例保持不变,所以近似的高斯导数应该进行相应的缩放。比如,一个$27 \times 27$大小的盒式滤波器就相当于$\sigma = 3 \times 1.2 = 3.6 =s$。此外,因为我们的滤波器进行了归一化处理,所以其F范数保持不变。
为了定位感兴趣点,在$3 \times 3 \times 3$邻域内应用了非最大值抑制。并且我们通过插值来定位亚像素级别的感兴趣点。
Fig2左是我们“Fast-Hessian” detector检测感兴趣点的一个例子。

个人理解:为了更快的计算高斯二阶导数卷积核处理后得到的图像,使用haar滤波器进行近似,然后再用近似的Hessian矩阵行列式来表示图像中某一点的响应值。
4.SURF Descriptor
相比其他的一些descriptor,SIFT的效果是非常好的。它结合了粗略的局部信息和基于梯度的特征的分布,具有良好的独特性,同时在一定程度上抵御了局部误差。使用梯度的强度和方向可以减少光线变化的影响。
我们提出的SURF descriptor也基于类似的属性,但降低了其复杂性。第一步是基于兴趣点周围的圆形区域来确定一个方向。然后,我们构造一个与该方向对齐的正方形区域,并从中提取SURF descriptor。接下来会依次解释这两个步骤。此外,我们还提出了一个upright版本的SURF,称为U-SURF,U-SURF计算速度更快,但不具备旋转不变性,因此更适合基于保持水平的相机的应用。
4.1.Orientation Assignment
为了保证旋转不变性,我们为兴趣点确定了一个可被重复再现的方向。首先,我们以兴趣点为中心,在以$6s$($s$为兴趣点的scale)为半径的圆形范围内,计算图像在x方向和y方向上的小波响应(Haar-wavelet responses),见Fig2。采样步长也为$s$。图像的其他部分保持一致,也在当前尺度$s$下计算小波响应。同样的,尺度越大,小波滤波器的尺寸也越大。我们可以再次使用积分图进行快速滤波。仅需要6次运算便可以完成一次小波响应的计算。小波滤波器的边长为$4s$。

以兴趣点为中心,对计算得到的小波响应进行高斯($\sigma = 2.5s$)加权,这些响应被表示为空间中的向量(个人理解:每个响应都有x方向和y方向),水平响应强度沿着横坐标,垂直响应强度沿着纵坐标。和SIFT类似,我们也需要为兴趣点确定一个主方向,以兴趣点为中心,旋转一个张角为$\frac{\pi}{3}$的扇形区域。扇形区域内的水平方向(x方向)的小波响应值和垂直方向(y方向)的小波响应值会累加起来。这两个累加得到的响应值可以组成一个新的向量。最长的向量将会作为兴趣点的主方向。旋转的扇形区域的大小是通过实验确定的。扇形区域太小容易导致单个小波响应占据主导地位,区域太大得到的向量又不具备代表性。扇形区域太大或者太小都会导致主方向的不稳定。此外,需要注意的是,U-SURF会跳过这一步。

4.2.Descriptor Components
对于descriptor的提取,第一步是构建一个以兴趣点为中心,沿着其主方向的正方形区域。对于U-SURF来说,因为跳过了第4.1部分,没有主方向,所以直接沿x-y方向确定一个正方形区域就行。正方形区域的边长是$20s$。正方形区域的示例见Fig2。
这个正方形区域会被进一步划分为$4\times 4$个子区域。这样可以保留重要的空间信息。对于每个子区域,我们会间隔采样,只计算$5\times 5$个像素点在水平方向和垂直方向的haar小波特征。简单起见,我们将$d_x$称为水平方向上的haar小波响应,将$d_y$称为垂直方向上的haar小波响应(滤波器大小为$2s$)。此处的“水平”和“垂直”都是相对于主方向来说的。为了增加对几何形变和定位误差的鲁棒性,首先以兴趣点为中心对$d_x,d_y$进行高斯加权($\sigma = 3.3s$)。
然后,对于每个子区域,分别求$d_x,d_y$的和。此外,我们还求了响应的绝对值之和,即$\lvert d_x \rvert,\lvert d_y \rvert$的和。因此,每个子区域对应一个四维descriptor,即$\mathbf{v}=(\sum d_x, \sum d_y, \sum \lvert d_x \rvert, \lvert d_y \rvert)$。那么对于一个正方形区域,一共有$4\times 4$个子区域,最终得到的descriptor向量的长度就是64。小波响应不受照明变化的影响。对比度的不变性是通过将descriptor转换为单位向量来实现的。
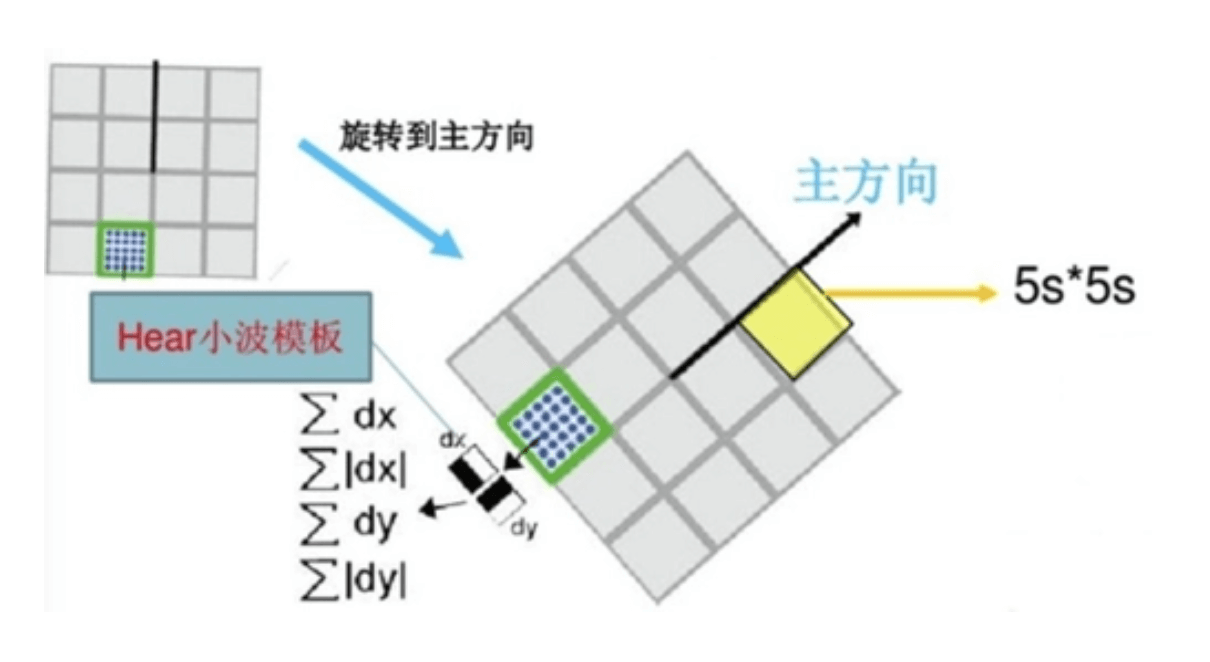
Fig3展示了子区域内不同图案的descriptor。我们可以想象得到,这种图案的组合,也能产生独特的descriptor。
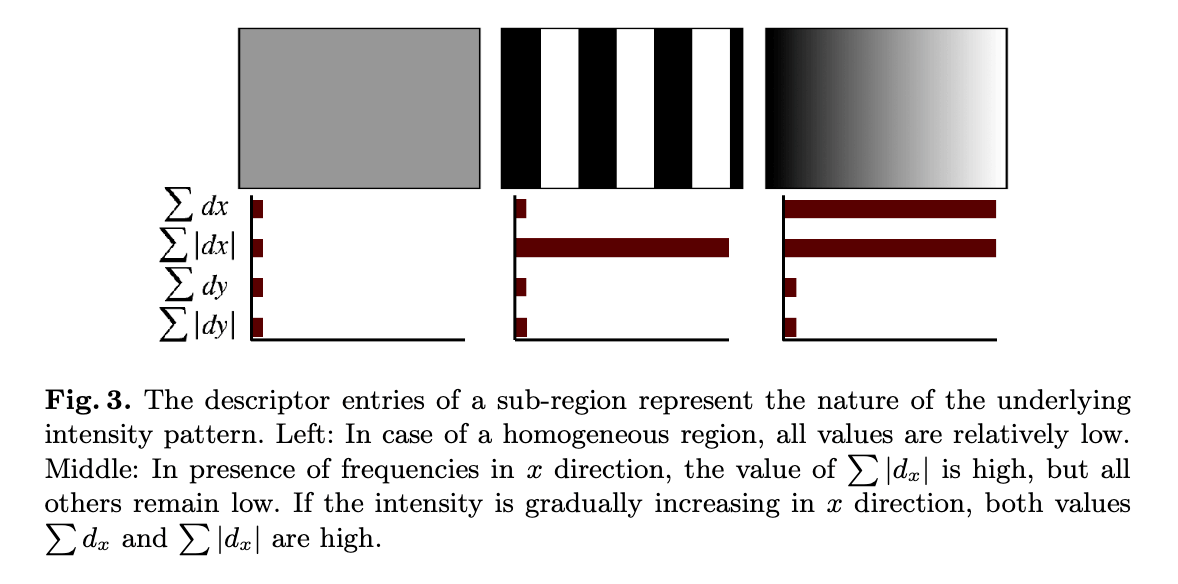
从Fig3中可以看出,子区域的descriptor可以反映底层的图案。Fig3左图:在均匀分布的区域中,所有值都比较低。Fig3中图:在x方向存在周期性变化,$\sum \lvert d_x \rvert$的值比较高,但其他值都低。但如果在x方向是渐变式变化(Fig3右图),则$\sum d_x$和$\sum \lvert d_x \rvert$的值都比较高。
此外,我们还测试了很多其他小波特征,比如使用$d_x^2$和$d_y^2$、higher-order小波、PCA、中值、平均值等。经过全面评估,我们提出的方案是最优的。然后,我们还测试了不同数量的采样点以及子区域数量。$4 \times 4$的子区域划分方案提供了最好的结果。更精细的划分鲁棒性不高,并且会增加匹配时间。另一方面,只有$3 \times 3$子区域划分的SURF-36表现更差,但其可以更快速的匹配,相对来说还可以接受。Fig4是一些比较结果。

Fig4中是不同方法的比较结果。兴趣点都是用我们的Fast-Hessian Detector检测的。需要注意的是,兴趣点不是仿射不变的。Fig4左图是基于相似度阈值的匹配策略。Fig4右图是最近邻比率的匹配策略。
我们还测试了SURF Descriptor的另一个版本:SURF-128。SURF-128还是使用之前的那些和,只不过对这些值进行了进一步的拆分。$d_x$和$\lvert d_x \rvert$的和通过$d_y <0$和$d_y \geqslant 0$进行拆分。类似的,$d_y$和$\lvert d_y \rvert$的和也通过$d_x$的正负来进行进一步的拆分。这样的descriptor更独特,计算速度也不慢,但由于维度更高,所以匹配速度比较慢。
Fig4评估所用的场景是数据集中最具有挑战性的,其包含多种形式的旋转和亮度变化。基于$4\times 4$子区域划分的SURF-128表现最好。此外,SURF(即SURF-64)表现也不错,处理速度更快。两者都优于现有的SOTA方法。
对于匹配阶段的快速索引,我们使用了Laplacian的符号(即Hessian矩阵的迹)。并且这没有引入额外的计算成本,因为在检测阶段已经进行了计算。在匹配阶段,只有当特征具有相同的Laplacian符号,我们才会对其进行比较。这加速了匹配过程,并略微提高了性能。
5.Experimental Results
首先,我们给出了detector和descriptor在标准评估集上的结果。接着,我们讨论其在现实世界的目标识别应用中的表现。比较所用的所有detector和descriptor都基于原作者的原始实现。
👉Standard Evaluation
我们使用Mikolajczyk提供的图像序列和测试软件(http://www.robots.ox.ac.uk/ ̃vgg/research/affine/)来测试我们的detector和descriptor。这些都是真实场景的图像。由于空间限制,我们无法展示所有序列的结果。对于detector的比较,我们选择了有两个视角变化的场景(Graffiti和Wall)、一个有缩放和旋转的场景(Boat)以及一个有照明变化的场景(Leuven)(见Fig6,下文会继续讨论)。对于descriptor的比较,我们展示了除Bark之外所有序列的结果(见Fig4和Fig7)。

对于detectors的评估指标,我们使用论文“Mikolajczyk, K., Tuytelaars, T., Schmid, C., Zisserman, A., Matas, J., Schaffal-itzky, F., Kadir, T., Van Gool, L.: A comparison of affine region detectors. IJCV 65 (2005) 43–72”提出的重复分数(repeatability score)。这个指标的意义是,两幅图像中都能检测到的兴趣点的数目,与总共能检测到的最少兴趣点的数目的比值(只考虑在两幅图像中都可见的兴趣点)。
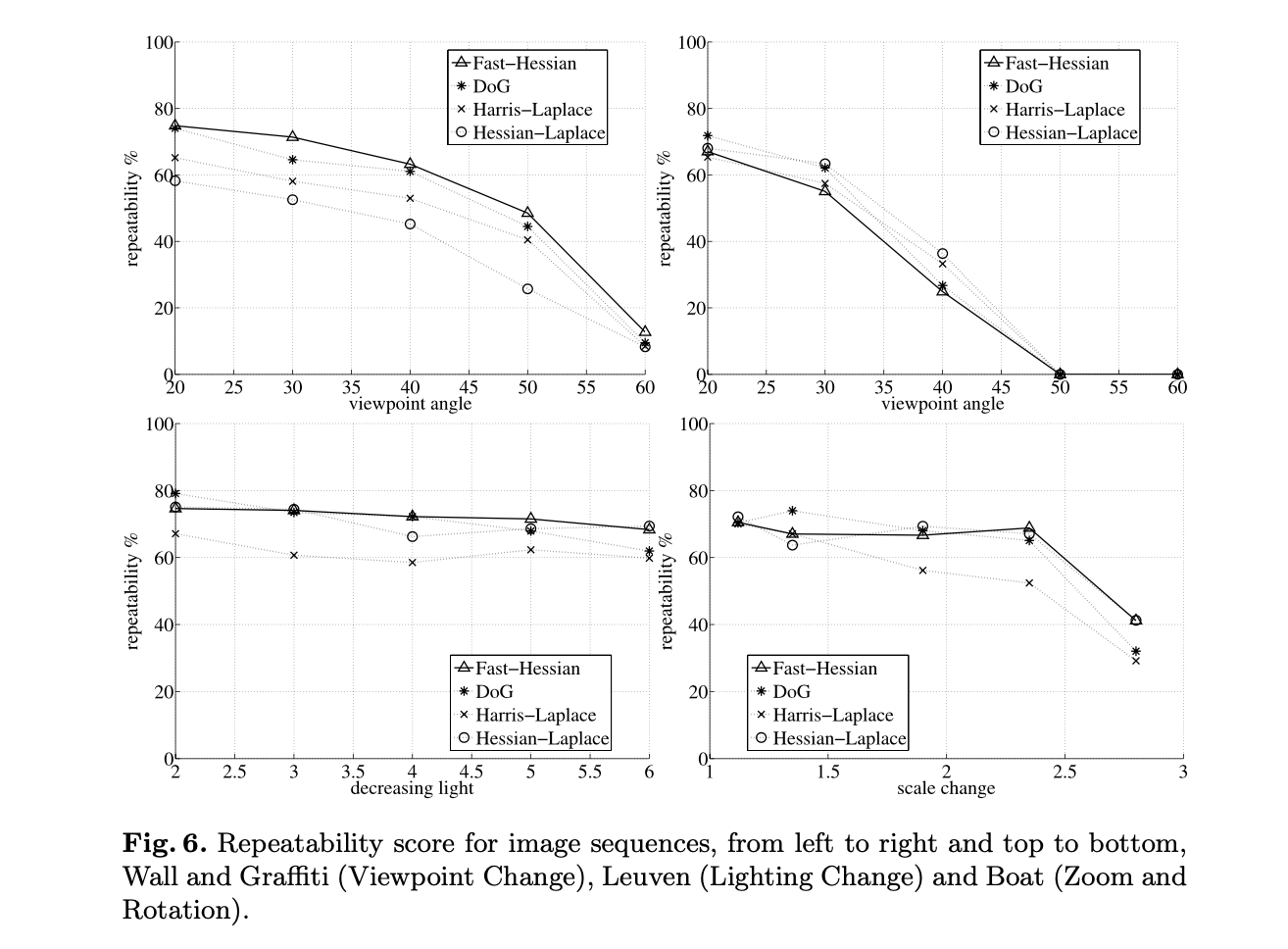
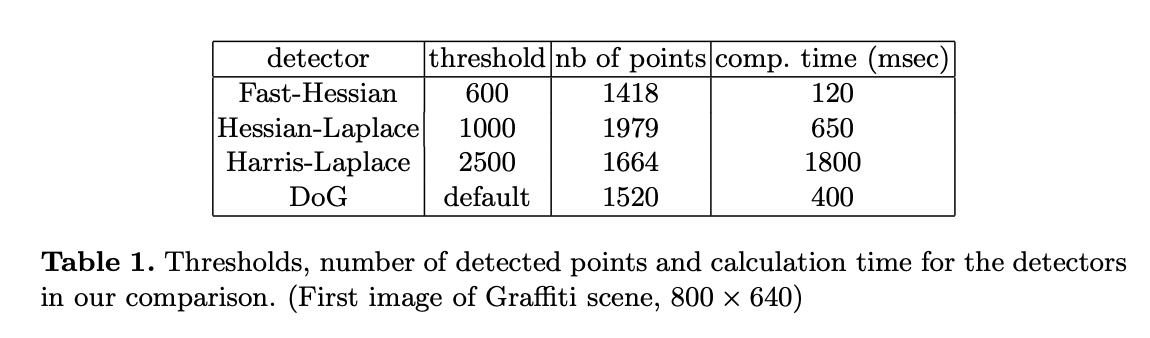
参与比较的detector有基于DoG的detector(见SIFT)、基于Harris-Laplace的detector和基于Hessian-Laplace的detector。参与比较的所有detector,检测到的平均兴趣点数量都比较接近。这一结论适用于所有图像,包括在目标识别任务上的测试,表1是一个例子。可以看到,Fast-Hessian比DoG快了3倍多,比Hessian-Laplace快了5倍。并且,我们所提出的detector的重复分数在一些场景中和竞争对手相当(比如Graffiti、Leuven、Boats),甚至在一些场景中优于竞争对手(比如Wall)。需要注意的是,Graffiti和Wall包含仿射变换,而比较所用的detector只有旋转不变性和比例不变性。因此,这种形变只能通过特征的整体鲁棒性来解决。
descriptors用recall-(1-precision)图来评估。对于每个评估,我们使用序列的第一张和第四张图像,除了Graffiti(使用第一张和第三张图像)和Wall(使用第一张和第五张图像),分别对应于30度和50度的视角变化。在Fig4和Fig7中,基于“Fast-Hessian” detector检测到的兴趣点,我们比较了SURF descriptor和GLOH、SIFT、PCA-SIFT。SURF几乎在所有比较中都优于其他descriptor。在Fig4中,我们使用两种不同的匹配策略对结果进行了比较,一种是基于相似度阈值,另一种基于最近邻比率(这两种策略的详细介绍请见论文:Mikolajczyk, K., Schmid, C.: A performance evaluation of local descriptors. PAMI 27 (2005) 1615–1630)。这对descriptor的好坏排名有影响,但SURF在两种策略下表现都是最好的。由于空间限制,Fig7只展示了基于相似度阈值的结果比较,因为该策略更适合表示descriptor在其特征空间的分布,并且用途也更广泛。
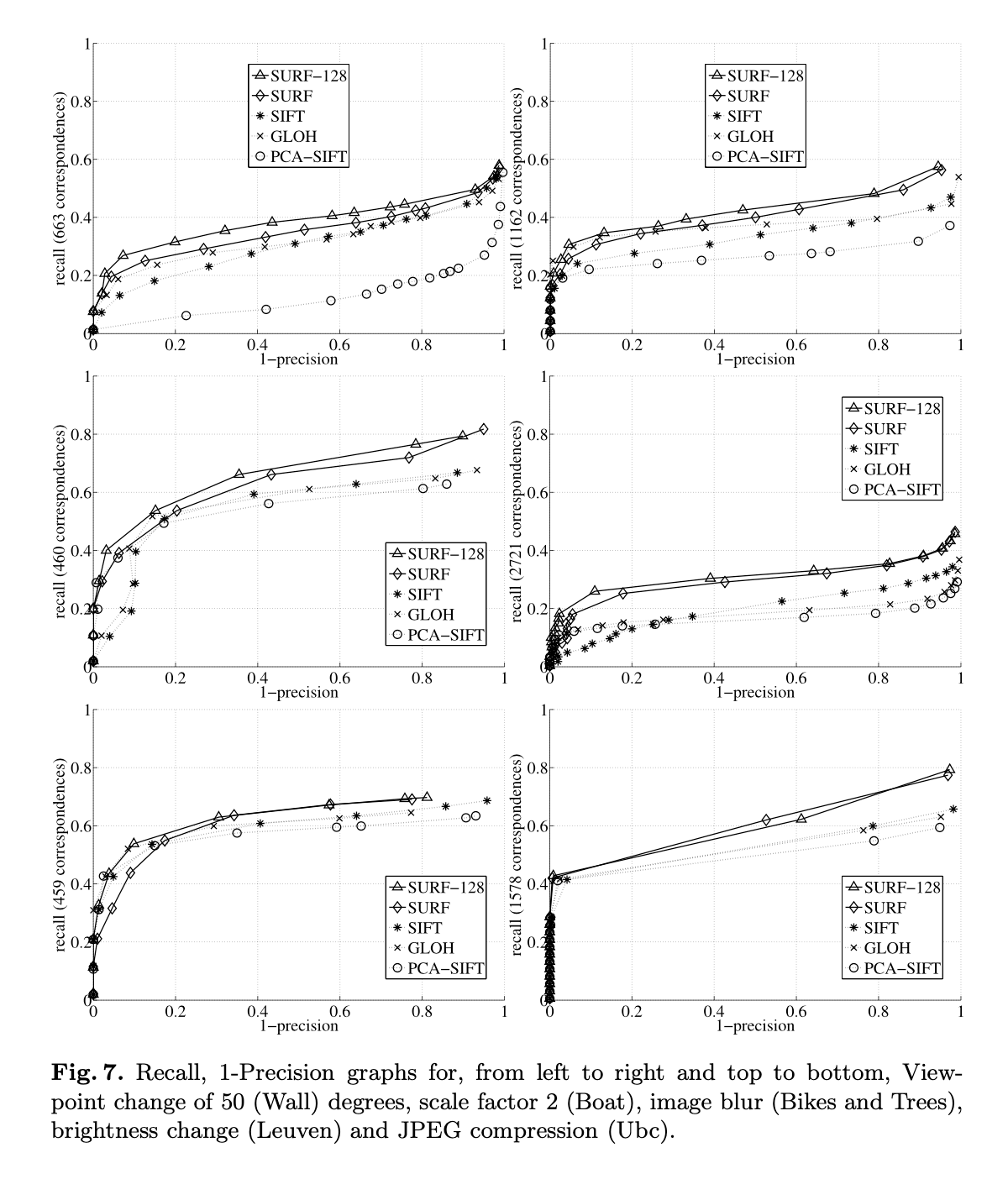
SURF descriptor在系统性和显著性方面优于其他descriptor,在相同precision水平下,有时将recall提高了10%以上。与此同时,SURF的计算速度更快(见表2)。SURF-128比常规SURF的结果稍好,但匹配速度较慢,不适合有速度要求的相关应用。

表2是detector-descriptor联合起来的执行时间,在Graffiti序列的第一张图像上进行的测试。通过调整阈值,以便所有方法检测到相同数量的兴趣点。这些相对速度也可以代表在其他图像上的测试结果。
需要注意的是,在整个论文中,包括目标识别实验,我们总是使用相同的参数和阈值(见表1)。对于速度的评估,都在标准的Linux PC(Pentium IV, 3GHz)上进行。
👉Object Recognition
我们还在实际应用中测试了这些new features,即识别博物馆中的艺术品。数据集包括216张图像,22个目标。测试集的116张图像是在各种条件下拍摄的,包括极端的照明变化、玻璃柜中反射的目标、视角变化、缩放、不同的图像质量等。此外,图像尺寸很小($320 \times 240$),因此对于目标识别来说更具挑战性,因为许多细节会丢失。
为了识别出数据集中的目标,我们进行了如下操作。我们将测试集中的图像和参考集(reference set)中的所有图像进行兴趣点的匹配。和参考图像上目标匹配度最高的测试图像上的部分就被识别为待检测目标。
匹配按如下方式进行。计算参考图像中兴趣点的descriptor向量和测试图像中兴趣点的descriptor向量之间的欧氏距离。如果测试图像中兴趣点1到其最近邻兴趣点2(参考图像)的距离是到其第二近邻兴趣点3(参考图像)的距离的0.7倍时,则说明兴趣点1和兴趣点2匹配成功。这就是最近邻比率匹配策略。显然,额外的几何约束可以减少误匹配的概率,但这可以在任何匹配器上完成。但出于比较的原因,这是没有意义的,因为这些可能会掩盖基本方案的缺点。使用平均识别率作为评估指标。SURF-128取得最高的识别率(85.7%),随后是U-SURF(83.8%)和SURF(82.6%)。其他descriptor的识别率分别为78.3%(GLOH)、78.1%(SIFT)和72.3%(PCA-SIFT)。
6.Conclusion
我们提出了一种快速且高性能的兴趣点检测方法,该方法在速度和准确性方面都优于现有技术。descriptor可以很容易被扩展到仿射不变性。未来我们会优化代码从而进一步提升速度。
7.原文链接
👽SURF:Speeded Up Robust Features
