本文为原创文章,未经本人允许,禁止转载。转载请注明出处。
1.INTRODUCTION
人类可以从多个来源获取数据并无缝集成它们。但大多数机器学习模型只能处理单一类型的任务。即使那些能处理多模态的模型也是如此。一种典型的方法是使用多个单模态输入的模型,比如2D ResNet用于CV,Transformer用于NLP,让这些模型独立的处理各自的输入,然后使用一个融合网络将它们集成,并以任务特定的方式读出结果。随着输入和输出变得更加多样化,这样的系统的复杂性可能会急剧增长。
多模态(multimodal)是一个涉及多种感官模式或信息来源的概念。在计算机科学、人工智能以及认知科学领域,多模态通常指的是在处理、分析和理解数据时,结合多种不同类型的信息源,如图像、文字、语音、视频等。
为每一组新的输入输出都建造一个新的模型,这一问题是否可以避免呢?如果有一个单一的神经网络框架可以处理各种输入模态以及输出任务,情况就会简单很多。在这项工作中,我们提出了一种框架,其最终目的是建立一个可以针对任意任务都轻松集成和转换任意信息的网络。我们基于之前的工作Perceiver,其可以在不改变网络框架的情况下处理多模态数据。Perceiver使用注意力机制将任意模态的输入映射到一个固定大小的latent space,该space会由完全的注意力网络进一步处理。该过程将网络的大部分处理和输入解耦,使其可以扩展到大型的多模态数据。
Perceiver:Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver: General perception with iterative attention. In Proceedings of International Conference on Machine Learning (ICML), 2021.
但Perceiver只能处理简单的输出space,比如分类。现实世界任务的复杂性很大程度上来自于其输出的多样性、规模以及结构,在这方面,原始的Perceiver是不能通用的。在这项工作中,我们开发了一种机制,其从Perceiver的latent space直接解码结构化的输出(比如语言、光流场、视听序列、symbolic unordered sets等),这使得模型可以处理大量新领域,并且不会牺牲领域无关处理所带来的好处。为此,我们使用一个output query来处理latent array,从而得到每个输出。例如,如果我们想让模型预测一个特定像素的光流,我们可以使用像素的xy坐标加上一个光流任务的embedding来生成一个query:模型将会使用这个query来生成单个的flow vector。因此,我们的框架可以产生许多任意形状和结构的输出,但框架中的latent features对于输出的形状和结构仍然是不可知的。
Perceiver IO是一个全注意力的读-处理-写框架:输入被编码到latent space(读),latent representation通过多层处理被细化(处理),latent space被解码得到输出(写)。该方法使用了Transformer。这种方法允许我们将用于大部分计算的元素的大小和输入输出的大小解耦。
Perceiver IO的解码过程使用注意力机制,使用query系统将latents映射到任意大小和结构的输出,该query系统可以灵活的指定输出所需的语义,包括dense和多任务设置。
我们所提出的框架的通用性是前所未有的。Perceiver IO可以替代BERT和AlphaStar中的Transformer。同时,Perceiver IO在Sintel光流benchmark上得到了SOTA的结果,在ImageNet图像分类上也得到了不错的结果。即使在处理高度多样化的多模态数据时,Perceiver IO也得到了非常不错的效果,比如在Kinetics中对视频、音频、标签的联合自动编码以及在AudioSet上对视频-音频的联合分类。Perceiver IO简化了pipeline并使得我们可以移除一些领域相关的假设。

Fig1:Perceiver IO可以在有着各种各样输入输出空间的不同领域内使用,包括多任务语言理解,dense的视觉任务(比如光流),dense/sparse混合的多模态任务(比如视频+音频+类别的自动编码),具有symbolic outputs的任务(比如《星际争霸Ⅱ》)。更多细节见表5和表6。
2.RELATED WORK
神经网络研究长期以来一直在寻找能够处理大型、任意结构的输入和输出的框架。
3.THE PERCEIVER IO ARCHITECTURE
Perceiver IO建立在Perceiver基础之上,后者假设输入是一个简单的2D byte array来实现跨领域的通用性:一组元素(可以是图像的像素或者patch、语言中的字符或者单词等)中的每个元素都用特征向量来描述。模型通过使用较少数量的latent特征向量和Transformer风格的注意力机制来对输入array进行编码,然后进行迭代处理,并最终聚合到类别标签。
与输出单个类别不同,Perceiver IO的目标是可以产生任意的输出array。我们可以使用所需输出元素特有的query特征向量来查询latent array,并使用另一个注意力模块来预测输出array中的每个元素。换句话说,我们定义了一个query array,其和所需输出有相同数量的元素。query可以是手工设计的,也可以是学习的embedding,或者是输入的一个简单函数。它们将产生所需形状的输出array。
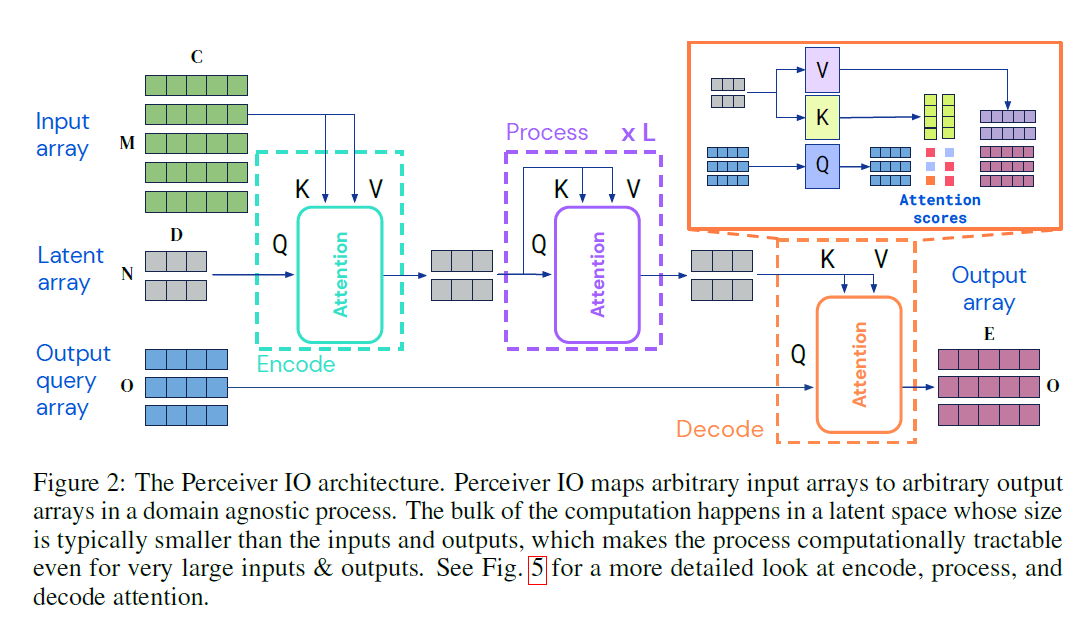
Fig2:Perceiver IO框架。Perceiver IO通过一些领域无关的处理将任意的输入array映射到任意的输出array。大部分计算发生在一个latent space中,该space的大小通常小于输入和输出,这使得即使面对非常大的输入和输出,该过程在计算上也很容易处理。更多细节见Fig5。
3.1.ENCODING, PROCESSING, AND DECODING
首先是编码(encode),通过一个注意力模块将输入array($x \in \mathbb{R}^{M \times C}$)映射到latent space中的array($z \in \mathbb{R}^{N \times D}$)。接下来是处理(process),通过一系列模块来处理latent中的$z$。最后是解码(decode),通过一个注意力模块将latent array映射到输出array($y \in \mathbb{R}^{O \times E}$)。$M,C,O,E$是任务数据的属性,可以非常大(见表5),而$N,D$是超参数,可以选择使模型计算易于处理。沿用Perceiver的设计,我们使用Transformer风格的注意力模块来构建模型框架。
对于每一个模块,都使用了全局的query-key-value(QKV)注意力操作,然后接一个MLP(multi-layer perceptron)。和Transformer风格的框架一样,我们将MLP独立的应用于index dimension中的每个元素。encoder和decoder都有两个输入array,第一个是用于key and value networks的输入,第二个是用于query network的输入。模块的输出和输入的query有着一样的index dimension(即相同数量的元素)。
Perceiver IO框架基于Transformer。为什么原始的Transformer不能提供我们所需要的全部?Transformer在计算和内存方面的扩展能力都很差(开销巨大)。因为Transformer在整个框架内均匀的部署注意力模块,使用其全部输入在每一层生成query和key。这意味每一层都需要平方复杂度使其在没有特定预处理的情况下,难以处理像图像这种高维数据。即使是在Transformer大放异彩的NLP领域,也经常需要预处理(比如tokenization)。Perceiver IO通过将输入映射到latent space,在latent space内进行处理,并解码到输出space这种方式来非均匀的使用注意力机制。这使得模型计算量不再依赖于输入输出的维度,encoder、decoder和注意力模块只需要线性计算复杂度,同时latent space中的注意力模块则独立于输入输出的大小。由于对计算和内存的需求减少,Perceiver IO可以扩展到更大的输入和输出。我们将Transformer能处理的典型序列长度从几千扩展到了几十万的量级。
我们的框架可以处理任何形状或空间布局的输入,包括具有不同空间结构(比如声音和视频)的输入或输出。与vision领域常用的latent space相比,我们的latent space没有明确的输入结构(空间或其他)。为了解码这些信息,我们使用交叉注意力机制来查询它们。
接下来说下自己对这个框架的理解。首先,这里说的交叉注意力机制指的就是下图中红圈的部分:
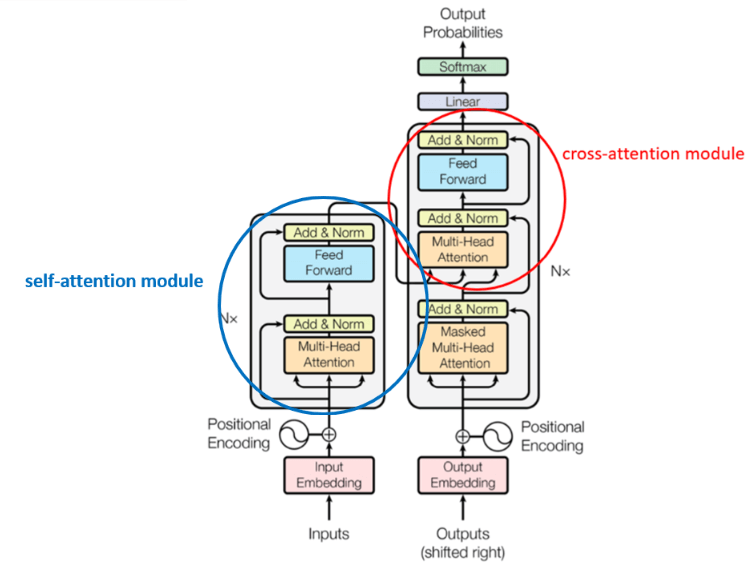
交叉注意力机制和普通的注意力机制的差异就是,交叉注意力机制的K,V来自外部(即input),Q来自上一个交叉注意力模块的输出(也就是说,交叉注意力模块的输出其实就是Q)。如Fig5所示,encode、process、decode三步的方式都差不多,这里以Fig5中的decode为例解释一下。计算其实和Transformer中是一模一样的,latent array分别乘上$W^V,W^K$得到Value矩阵和Key矩阵,然后将Query矩阵和Key矩阵相乘(还需要缩放)后经过softmax函数得到下图黑圈标识的部分:

黑圈内位置1上的数值乘上Value矩阵的第一行加上位置2上的数值乘上Value矩阵的第二行,便可得到output array的第一行。同理,黑圈内位置3上的数值乘上Value矩阵的第一行加上位置4上的数值乘上Value矩阵的第二行,便可得到output array的第二行。位置5上的数值乘上Value矩阵的第一行加上位置6上的数值乘上Value矩阵的第二行,便可得到output array的第三行。其实也是个矩阵乘法。
3.2.DECODING THE LATENT REPRESENTATION WITH A QUERY ARRAY
给定大小为$N \times D$的latent representation,我们的目标是生成最终的输出array(大小为$O \times E$)。我们通过index dimension为$O$的query array来产生这种大小的输出。为了捕获输出space的结构,我们使用的query包含每个输出点的一些适当的信息,比如空间位置或模态。
我们将一组向量拼接成一个query vector,多个query vector又组成了query array,每个query vector都包含了output array对应行的一些相关信息。不同任务对应的query结构见Fig3。对于具有简单输出的任务(如分类),这些query可以在每个示例中被重复使用,并且可以从头开始学习。对于具有空间或序列结构的输出,我们要加入位置编码(比如,可被学习的位置编码或Fourier feature)来表示输出中需要被解码的位置。对于具有多任务或多模态结构的输出,我们为每个任务或每个模态学习一个query:这些信息允许网络将一个任务或模态的query与其他任务或模态区分开来,就像位置编码允许注意力将一个位置与另一个位置区分开来一样。对于其他任务,输出应反映在query位置上的输入内容:举个例子,对于流,我们发现在被查询的点加入输入特征是有帮助的,而对于《星际争霸Ⅱ》,我们使用单元信息来关联模型输出和对应的单元。我们发现非常简单的query特征也能产生良好的结果。
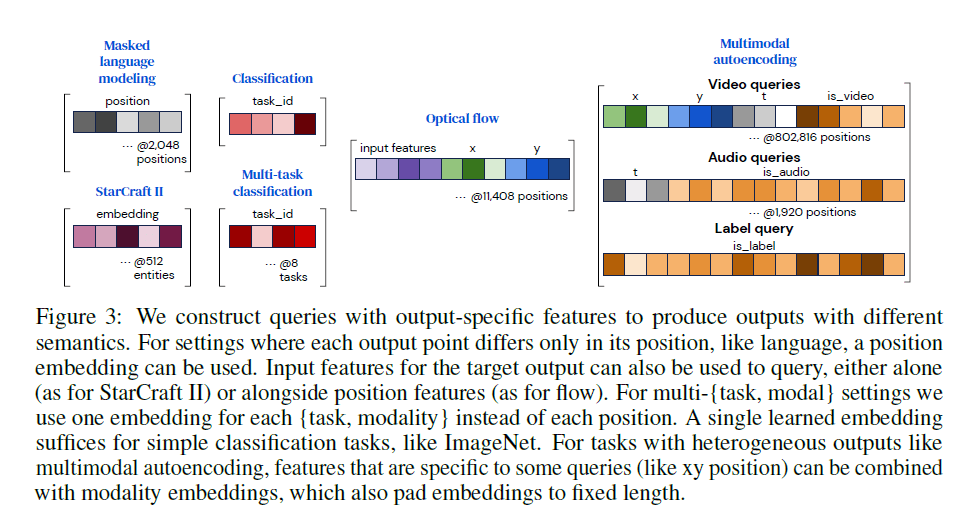
Fig3:我们根据输出构造特定的query,以生成具有不同语义的输出。对于每个输出点仅在位置上有不同的情况,比如语言,我们可以使用position embedding。输入特征也可以用于query,比如单独使用输入特征作为query的《星际争霸Ⅱ》,或结合位置特征一起作为query的光流。对于多任务多模态的情况,我们为每个任务每个模态都使用一个embedding,而不是针对每个位置。对于简单的分类任务(比如ImageNet),我们只需要一个可被学习的embedding就足够了。对于具有多种输出的任务,比如多模态自动编码,我们可以将一些query(比如xy位置)和模态embedding(padding到固定长度)相结合。
每个输出点仅取决于其query和latent array,这使得我们可以并行解码输出。例如,Kinetics由标签、视频体素和音频样本组成,这些加起来超过800,000个点(见表5),即使使用线性缩放,一次解码的成本也高的令人望而却步。因此,我们在训练阶段对输出array进行了下采样,在一个可负担的子集上计算loss。在测试阶段,我们批量生成输出,以产生完整的输出array。
4.EXPERIMENTS
为了探究Perceiver IO的通用性,我们在多个领域进行了评估,包括语言理解(Wikipedia+C4 masked language modeling),视觉理解(Sintel/KITTI光流和ImageNet分类),多模态(Kinetics自动编码和AudioSet分类)和多任务设置(多任务GLUE),游戏的symbolic representations(《星际争霸Ⅱ》)。
4.1.LANGUAGE
首先在NLP领域,我们比较了Perceiver IO和标准的Transformer。尽管Transformer一开始就是为语言处理设计的,但其平方复杂度使得其很难把没有经过tokenization的语言直接作为输入,tokenization通常可以把输入序列长度缩短约4倍。和基于Transformer的BERT或XLNet不同,Perceiver IO复杂度和输入序列长度呈线性关系。我们的实验表明,在masked language modeling(MLM)方面,Perceiver IO和Transformer一样好或更好,并且Perceiver IO还移除了tokenization。
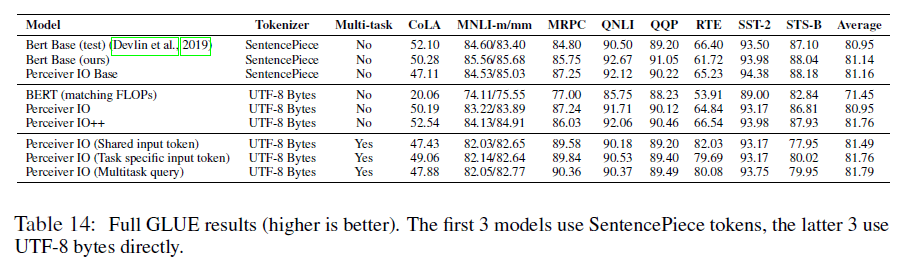
我们在给定FLOPs预算的情况下进行了比较,而不是在给定参数量的情况下进行的比较,因为前者随着序列长度平方增长,但后者是独立的(位置编码除外)。从实践角度来说,FLOPs比参数更重要,因为FLOPs与训练时间是直接相关的。我们在GLUE benchmark上进行了评估,结果见表1。我们发现,在给定FLOPs预算的情况下,没有使用tokenization的Perceiver IO和使用了SentencePiece tokenization的Transformer性能相当。
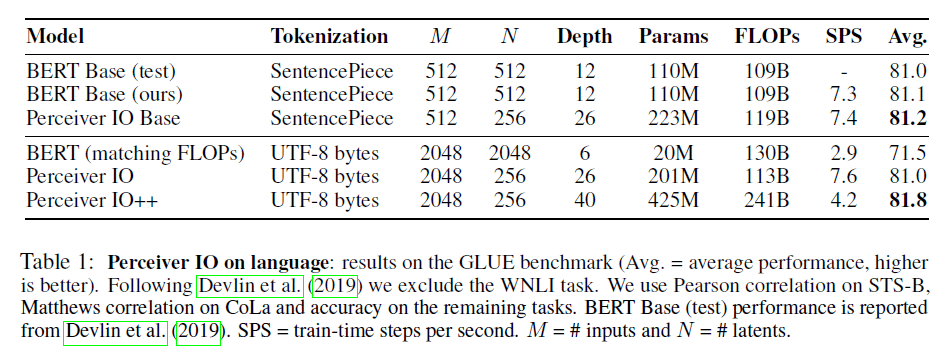
表1:Perceiver IO在语言处理中的表现:在GLUE benchmark上的结果(Avg.表示平均性能,越高越好)。
Pretraining.
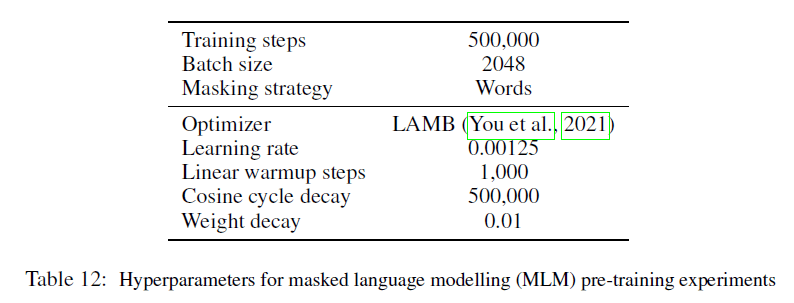
我们使用结合English Wikipedia和C4的大型文本语料库对MLM任务进行了预训练。对于SentencePiece和byte-level模型,我们都是mask掉了15%的单词,mask掉的单词被定义为空格。为了使输入文本的长度差不多:对于SentencePiece,输入序列长度为512个token;对于byte-level,输入序列长度为2048个UTF-8字节。对于SentencePiece模型,单词大小是32,000。对于byte-level模型,单词大小是256个字节和4个特殊的token([PAD],[MASK],[CLS],[SEP])。Perceiver IO通过一个可被学习的位置相关向量来查询最终latent处理层的输出,为每个masked input产生一个output vector。然后,我们在这些output vector上应用一个position-wise linear layer,并使用softmax交叉熵loss来训练模型,把原始的未被mask的input作为预测目标。更多细节见附录的第F.2部分。所学特征的分析和可视化结果见附录中的Fig7。
Finetuning.
我们在GLUE Benchmark上finetune了Perceiver IO,并报告了在dev set上的最佳性能。单独的任务结果和超参数见附录的第F.4部分。
Perceiver IO on SentencePiece tokens.
Perceiver IO略优于BERT(81.2 vs. 81.1)。与BERT Base相比,我们的框架更深(26层),但FLOPs基本相近。
Perceiver IO on UTF-8 bytes.
相比常规的Transformer,Perceiver IO可以处理更长的序列。我们的模型不使用固定的手工设计的单词,而是直接使用原始字节作为输入:输入输出都是UTF-8字节。在相同的FLOPs预算下,Perceiver IO明显优于BERT(并且虽然Perceiver IO有着更大的深度,但速度却比BERT快了2倍多)。和SentencePiece模型相比,基于byte的Perceiver IO依然有着不相上下的表现。如果增加FLOPs预算,Perceiver IO可以获得更好的性能,在GLUE benchmark上获得了81.8。
Multitask Perceiver IO.
我们使用第3.2部分介绍的多任务query,使用UTF-8 byte模型,在所有的8个GLUE任务上同时进行了finetune,结果见表2。我们将其与单个任务机制(在每个任务上独立训练)的结果进行了比较。我们还比较了一种类似于BERT中[CLS] token的方法,该方法在输入前准备一个特殊的token,并使用与该token对应的位置来查询task logits。我们通过在任务之间共享单个token(Shared input token)或使用任务特定的token(Token-specific input token)来实现这一点。在这两种情况下,我们都使用了两层任务特定的MLP head来为每个任务生成output logits。我们发现我们的多任务方法优于单任务方法。我们的方法更通用,因为其不依赖[CLS] token,将输入输出进行了解耦。

4.2.OPTICAL FLOW
光流任务是给定同一场景的两张图像(例如,视频的两个连续帧),需要估计第一张图像中每个像素的2D位移。光流的应用非常广泛。光流对于神经网络非常具有挑战性,有两个原因。第一个原因,光流依赖于找到对应关系:单帧图像无法提供光流信息,不同外观的图像可能会产生一样的光流。第二个原因,光流非常难标注,很少有数据集有高质量的GT。虽然生成大型合成数据集用于训练很简单,但仍存在很大的domain gap。
因此,光流算法必须学会从合成数据如何转移到真实数据。首先,算法必须找到点之间的对应关系。然后计算其offset。最后,它必须将流传播到大的空间区域,包括图像中没有对应纹理的部分。为了推广到真实数据,学习过程必须对训练数据中没有的目标和纹理也是work的。
这些问题导致光流相关的框架都非常复杂。比如目前比较好的一些算法:PWCNet、RAFT、GMA等。
Perceiver IO on Flow
与之前的方法不同,Perceiver IO采用了直接的方式处理流。我们沿着channel方向把帧concat起来,并在每个像素周围提取一个$3 \times 3$的patch(即每个像素对应有$3 \times 3 \times 3 \times 2 = 54$)个值。在这54个值之后,再concat一个固定的位置编码(见Fig3),然后喂给Perceiver IO。在解码阶段,我们使用输入编码来查询latent representation(个人理解:见下图,Input array和output query array是一样的)。
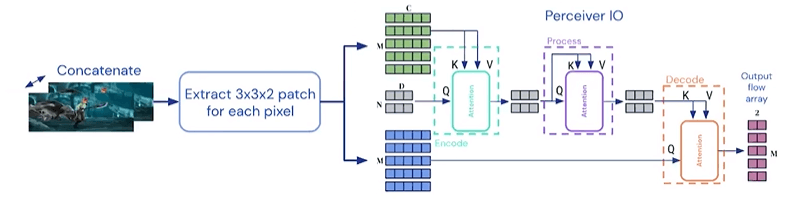
相关的前处理、后处理以及训练细节和结果,见附录的第H部分。我们还测试了卷积下采样和RAFT风格上采样的版本,其在优化计算时间方面表现稍差。
Results
结果见表3,遵循AutoFlow的训练标准。PWCNet和RAFT的baseline来自AutoFlow作者的训练。在Sintel数据集上,Perceiver IO稍好于RAFT,在KITTI数据集上,我们的方法明显优于PWCNet。我们在Sintel.final上取得了SOTA的结果。考虑到我们的方法和RAFT、PWCNet在框架上有很大的不同,并且我们没有针对任务去做很多的调整,能取得这一结果是令人惊讶的。我们没有使用之前方法的一些技巧,比如cost volume和warping,我们的latent representation甚至没有保持输入的2D layout。需要注意的是我们复用了一些RAFT的AutoFlow扩展参数。如附录中Fig8所示,Perceiver IO很擅长追踪目标边界,并且可以很好的处理没有纹理的区域。

4.3.MULTIMODAL AUTOENCODING
我们尝试在Kinetics-700-2020数据集上使用Perceiver IO进行audio-video-label的多模态自动编码。多模态自动编码的目标是学习一种模型,该模型通常是bottleneck结构,其可以准确的重建出多模态的输入。这个问题之前通常是使用Restricted Boltzmann Machines技术,但其使用的是更特定的、小规模的数据集。
Kinetics-700-2020包含视频、音频和类别标签。我们希望训练一个模型来同时重建所有模态。对于传统的自动编码模型,比如CNN风格的encoder-decoder模型,如何组合这些模态并不明显,因为每种模态的维度都不同——3D(视频)、1D(原始音频)、0D(类别标签)——并且元素数量也大不相同。在使用Perceiver IO时,我们将这些数据序列化为2D input array和query array。
我们的训练在视频数据方面,使用了大小为$224 \times 224$的16帧图像,并将其预处理为50k个$4\times 4$大小的patch(见Fig3,视频数据产生了$224 \times 224 \times 16 = 802816$个vector,一行为一个patch,即一个16-d的vector);在音频数据方面,一共有30k个原始音频样本,产生了1920个16-d的vector,外加一个700-d的one-hot编码的类别标签(视频和音频是16-d的,需要padding补齐到700-d)。我们直接解码得到像素、原始音频和一个one-hot标签,无需任何的后处理。为了防止模型将标签直接编码为潜在变量之一,我们在训练中有50%的可能性会mask掉标签。考虑到输入输出的规模,我们在训练中进行了下采样,每个输入只包含512个音频样本和512个像素点,以及一个类别标签,但在测试阶段,我们是完全解码的,没有下采样。这允许我们可以直接解码到视频大小的array。我们分别使用$512 \times 784$(512为通道数,即列数,784为latents数量,即行数)、$512 \times 392$、$512 \times 196$大小的latent array,分别对应88x、176x、352x的压缩比例(此处不知道作者是怎么计算的压缩比例,自己没计算出来一样的比例)。

Fig4:在88倍压缩下的视频-音频-标签多模态自动编码。输入是左图,重建的是右图。
结果见表4。通过在评估过程中屏蔽掉类别标签,我们的自动编码模型就成了一个Kinetics 700分类器。各模态之间共享latent variables。表4展示了一个折中方案,即以牺牲分类精度为代价来获得更好的PSNR。通过赋予class loss更大的权重,我们可以达到45%的top-1分类精度,同时保持视频的PSNR为20.7(见附录的第I部分)。这强有力的表明了Perceiver IO可以联合具有非常不同属性的模态。

4.4.IMAGENET, STARCRAFT II, AND AUDIOSET
详见附录的A、B、C部分。实验的一些亮点:(1)在ImageNet上,在JFT上预训练之后,Perceiver IO在不使用2D卷积的情况下超过了80%的top-1准确率(84.5%)。(2)使用Perceiver IO替代了AlphaStar的Transformer,降低了大约3.5倍的FLOPs,在仅仅3次实验运行后,就在《星际争霸Ⅱ》中取得了87%的胜率。(3)在多模态的视频+音频分类任务上,在相同训练策略下,Perceiver IO始终优于原始的Perceiver。
5.CONCLUSION
我们提出的Perceiver IO是一种通用性非常强的框架,可以处理多模态和多任务。
6.APPENDIX
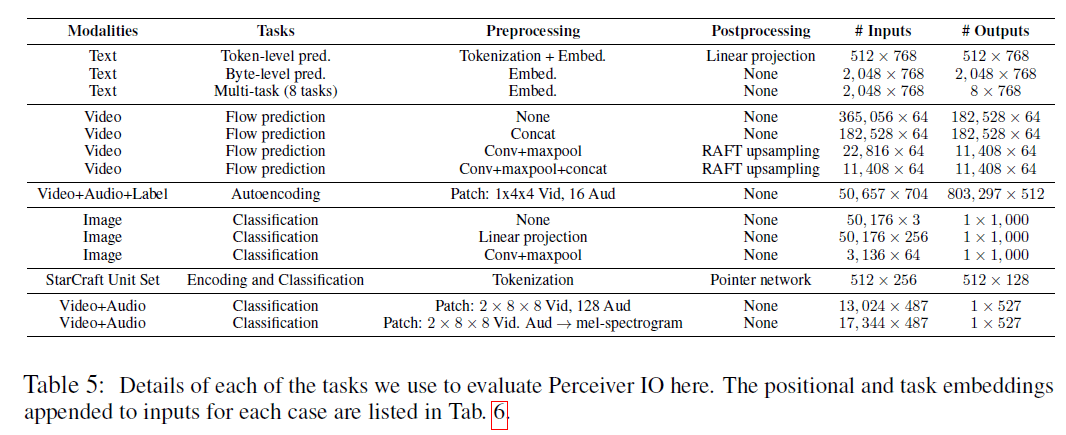
表5:用于评估Perceiver IO的每个任务的细节。表6列出了每种情况下附加到输入的位置和任务的embeddings。
在接下来的部分,我们展示了在ImageNet、《星际争霸Ⅱ》以及AudioSet上的实验,并提供了更多的细节。除《星际争霸Ⅱ》外,对于每个领域,我们都实验了多种不同的输入配置。这些结果证明了Perceiver IO前所未有的通用性。
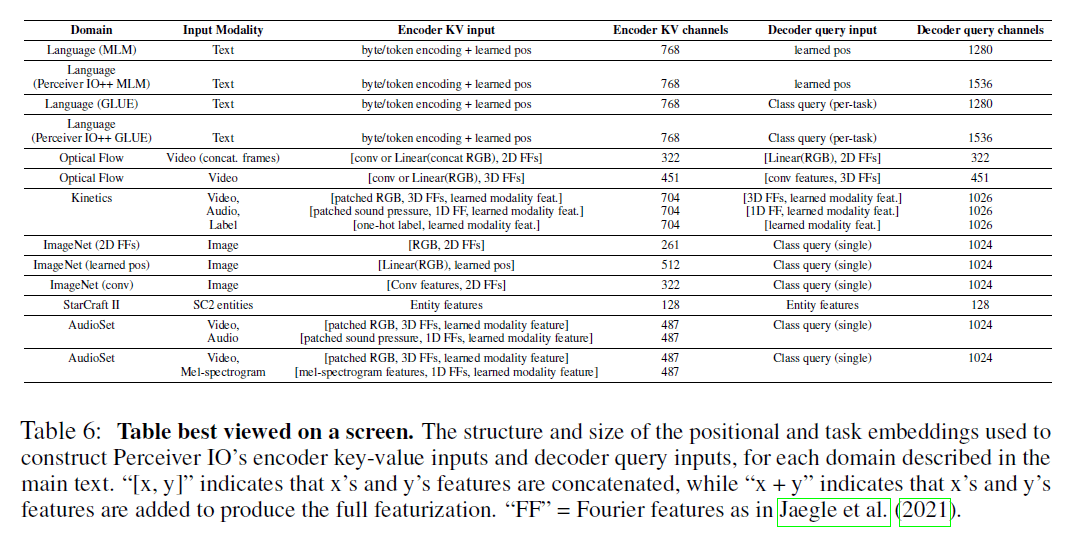
表6:位置和任务的embeddings被用于构造Perceiver IO编码器的key-value输入和解码器的query输入。表中”[x,y]”表示x特征和y特征被concat在一起,而”x+y”表示x特征和y特征加和在一起。”FF”表示在Perceiver一文中提到的Fourier特征。
6.A.IMAGE CLASSIFICATION
Perceiver就已经在ImageNet分类任务中表现的很好了,其在框架中没有使用2D结构,但使用了简单的平均和project decoder来生成class score(见附录第E.3部分和Fig6,说明两种解码器之间的差异)。
Results
结果见表7。Perceiver和Perceiver IO的解码器不同,默认情况下,两个模型都不使用卷积预处理。Perceiver IO的表现始终优于Perceiver。在JFT上预训练后,Perceiver IO的性能和专门针对图像分类任务所建立的模型的表现不相上下。即使不依赖2D卷积,Perceiver IO和ViT各种变体模型的性能差不多。通过添加2D卷积+maxpool形式的预处理,Perceiver IO的性能和效率得到进一步的提升。
虽然Perceiver和Perceiver IO在框架上没有使用任何2D空间结构,但它们使用了具有2D空间信息的位置特征(具体可参见Perceiver一文)。我们也可以完全学习一个位置编码而不使用2D位置特征,这样我们就可以在没有图像结构等先验信息下去学习一个图像分类模型。位置编码是一个大小为$50176 \times 256$的array,使用尺度为0.02的高斯分布进行随机初始化。使用这种位置编码的ImageNet模型没有得到关于图像的2D结构信息。对于这种实验,我们还额外使用一个1D卷积将每个点的RGB投影到256维,然后和可学习的位置编码concat在一起。结果见表7中的”w/learned position features”。据我们所知,在不使用2D框架或特征信息的情况下,我们得到的结果是最优的。

表7:在ImageNet分类任务上的top-1准确率。“-”表示我们在文献中找不到相关信息。我们没有为了提高图像分类的效率而过度的调整我们的模型——我们工作的重点是通用性,而不是分类速度——我们使用了和基于注意力的图像分类模型差不多的FLOPs,尤其是在JFT上预训练的配置B,其FLOPs更低。位置编码并没有明显的改变模型的FLOPs。
6.A.1.DETAILS OF IMAGENET TRAINING
对于ImageNet实验,我们使用了CutMix和MixUp正则化,以及RandAugment。这些方法对我们模型的性能只是略有改善。在所有实验中,我们使用4层magnitude为5的RandAugment和ratio为0.2的CutMix。在早期的实验中,我们发现更高的weight decay和适度的梯度裁剪有利于更好的泛化性:我们使用0.1的weight decay,并裁剪到10的最大全局梯度范数。我们没有使用dropout。我们还使用了权重共享机制:processing阶段一共有8个block,每个block有6个注意力模块,每个block内的模块共享权重。我们省略了Perceiver中使用的repeated encoder cross-attends,因为我们发现这些只能带来较小的性能提升,但会显著降低训练速度。所有ImageNet模型的FLOPs见表7,在64个TPU v3上的训练速度见表8。
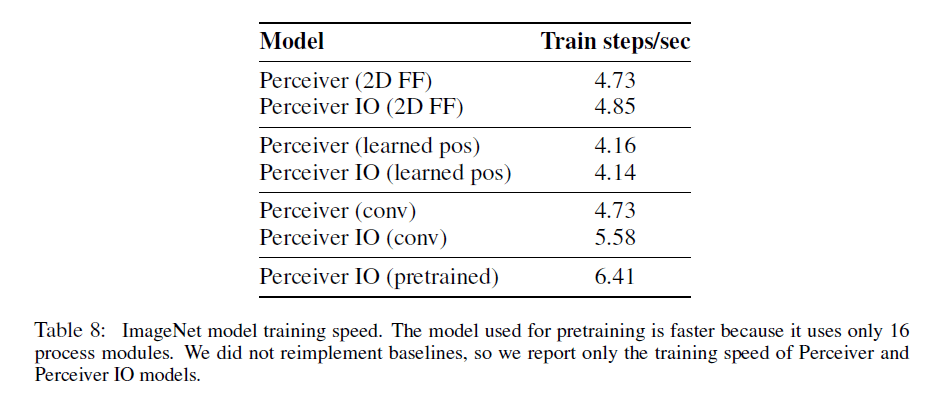
表8:ImageNet模型的训练速度。预训练速度更快,是因为其只使用了16个process模块。我们没有重新训练其他baseline,所以这里只列出了Perceiver和Perceiver IO的训练速度。
对于所有的ImageNet实验,我们都训练了110个epoch,batch size=1024,64个TPU。我们使用LAMB和一个简单的学习率schedule,前55个epoch的学习率都是$2 \times 10^{-3}$,后55个epoch在cosine decay schedule下,学习率逐渐降为0。相比Perceiver中使用的step decay schedule,我们发现cosine learning rate decay schedule更容易调整,并且在训练中途开始学习率的衰减可以在不引入不稳定性的情况下获得良好的性能。我们发现省略初始学习率的warm-up很重要,因为当我们使用LAMB时,warm-up通常会阻止我们的训练。
6.A.2.LARGE-SCALE PRETRAINING
Perceiver模型在没有正则化的情况下,很容易对ImageNet规模的数据集产生过拟合。因此,我们在JFT数据集上进行了预训练,JFT是一个大规模的多标签数据集,其包含3亿张图像,约18,000个类别。我们使用和ImageNet一样的分辨率($224 \times 224$)进行预训练,初始学习率为$3 \times 10^{-4}$,使用cosine decay schedule,经过14个epoch,学习率衰减为0。除了基础的crop、resize和左右翻转,我们没有使用其他data augmentation。weight decay=0.1。batch size=8192,使用了256个TPU。该数据集的图像有多个标签(multi-one-hot representation),因此我们使用交叉熵loss。与其他ImageNet实验不同,这里处理阶段的模块之间不共享权重,latent一共有16层。与其他ImageNet实验还有一个不同的地方是,处理阶段模块的MLP所用隐藏层的通道数(个人理解就是神经元数量)是其他实验的4倍。在预训练2D FF模型时,我们使用1D卷积网络将每个点的输入RGB映射到256维,并和位置编码(a 2D Fourier frequency positional encoding)concat起来。当预训练conv+maxpool模型时,我们使用第A.3部分描述的初始卷积预处理。
将预训练的模型在ImageNet上进行了fine-tune。我们只替换了解码器的最后一个线性层,以产生所需要的18,000个类别。对于2D FF模型的fine-tune,我们使用了和从头开始训练的ImageNet模型类似的optimizer和augmentation:1024的batch size,64个TPU,使用LAMB(共131K step,前70K step学习率稳定为0.002,后61K step学习率遵循cosine learning rate decay策略)。对conv+maxpool模型的fine-tune基本使用相同的设置,唯一的不同是将基本学习率设置为了0.0002,因为0.002的学习率是不稳定的。
6.A.3.2D CONVOLUTIONAL PREPROCESSING ON IMAGENET
我们可以选择性的使用简单的前处理或后处理来降低输入和输出的size。因为ImageNet数据集的图像大小相对较小(见表5),我们能够在没有卷积风格的前后处理下也能处理整张图像。因此,我们可以使用该数据集来探测模型对卷积预处理的敏感性。结合单个卷积+max pooling可以适度提高框架的性能:这并不令人惊讶,因为卷积预处理将有关图像的2D结构信息注入到框架中。相比之下,ViT首先使用一个2D卷积来对其输入进行下采样(ViT中称为“linear projection of flattened patches”)。在其他实验中,我们发现结合基于注意力的解码器(Perceiver IO)比对输出进行平均和池化(Perceiver)能获得更好的结果。使用卷积预处理可以适度减少模型的FLOPs(见表7),还能提升一些配置的训练速度(见表8)。经过预处理后,网络的输入从$224 \times 224$变为$56 \times 56$。
6.B.STARCRAFT II
为了进一步展示Perceiver IO在离散模态(discrete modalities)上的能力,我们将AlphaStar中的Transformer替换为了Perceiver IO。对于《星际争霸Ⅱ》这种实时策略游戏,AlphaStar的表现是SOTA的。
AlphaStar的核心思想是把游戏的单位变为一组离散且无序的符号。这些单位由属性向量表示,其包括单位类型、位置和健康状况。对于每个timestep,模型框架都使用一个实体编码器(entity encoder)对单位进行编码,这里的实体编码器就是一个普通的Transformer。
实体编码器将一组512个实体作为输入,其输出为每个实体的embedding(称为entity_embeddings),然后将所有实体的embedding降维为一个1D embedding(即embedded_entity)。这512个实体表示游戏的单位和其他实体:未使用的实体槽被屏蔽。将实体编码器的输出通过一个ReLU和一个256通道的1D卷积,从而便可得到entity_embeddings。对未屏蔽的实体编码器的输出做平均,并通过一个256个神经元的线性层和ReLU函数,便可得到embedded_entity。
在原始的AlphaStar系统中,实体编码器由一个具有3个注意力层的Transformer组成,每个注意力层有2个头,特征向量的长度为128。每个注意力层的输出被投影到256长度,然后接一个2层的MLP(隐藏层神经元数为1024),最后输出依旧是256长度。这一框架是通过大量调整过程得到的。
我们的结论是Perceiver IO可以取代经过well-tuned的Transformer作为符号处理engine。
我们将AlphaStar实体编码器中的Transformer替换为Perceiver IO来获得《星际争霸Ⅱ》的结果。使用的Perceiver IO的latent index dimension为32,保持输入和输出都为512个单位。除此之外,我们没有进行任何调整。

表9:二者的胜率是一样的。但Perceiver IO的FLOPs更低,并且基本上不需要调整,速度方面也没有落后。
Perceiver IO的其他超参数和ImageNet中所用的一样。
6.C.AUDIOSET
为了进一步证明基于注意力机制的解码器有助于分类任务,除了ImageNet,我们还在多模态AudioSet分类领域进行了验证。AudioSet是一个大规模的事件分类数据集,其包含170万个训练样本,每个样本由10秒长的视频和音频组成。一共有527个类别标签,每个样本可能会被标记多个标签。
模型训练了100个epoch,使用32-frame clips,在测试阶段,使用16个重叠的32-frame clips。和ImageNet实验一样,我们比较了Perceiver和Perceiver IO,二者只有解码器是不一样的(Perceiver的解码器为average+project,Perceiver IO的解码器为基于query的注意力机制,详见附录E.3部分和Fig6)。所有模型使用的框架都具有12个processor module,并且latent index dimension(即N的值)为512(我们省略了Perceiver IO中的cross-attends)。我们还比较了以mel-spectrogram+video作为输入的模型。对于表10中的四个模型,我们尝试了不同的latent channel(即D的值,分别取512和1024),我们在表10中列出了取得最好结果的D值。我们没有进行额外的调整。
所有实验结果见表10。和ImageNet的实验结果一样,基于注意力的解码器性能要比基于average+project的解码器性能要稍好一些。这证明了Perceiver IO是一个更加通用的模型。

表10:mAP越高,模型性能越好。所有模型尽管FLOPs不同,但runtime基本一样,这是因为瓶颈在于load数据和前处理,而不在模型的前向/后向传播。
6.D.FLOPS CALCULATION
在所有情况下,我们都提供了理论的FLOPs,乘法和加法都算作一次独立的运算。
6.E.ARCHITECTURAL DETAILS
Perceiver IO由GPT-2风格的Transformer注意力模块构成,其包含QKV注意力、MLP以及linear projection layers(以确保QKV和MLP的输入、输出具有预期的大小)。在encode阶段,QKV注意力的输入分为两个二维数组,一个是key-value的input array,大小为$X_{KV} \in \mathbb{R}^{M \times C}$,另一个是query input array(在encode阶段就是latent array),其大小为$X_Q \in \mathbb{R}^{N \times D}$,注意力模块输出的大小和latent array一样,即$X_{QKV} \in \mathbb{R}^{N \times D}$。$X_{QKV}$作为MLP的输入,MLP独立的作用于每个index dimension(即每一行各自通过MLP),其输出维度保持不变,即$X_{MLP} \in \mathbb{R}^{N \times D}$。
GPT-2原文:Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019.
在encode中,我们将注意力模块的输入分成了两部分,但在标准的Transformer中,一个注意力模块通常是将一个输入映射到相同大小的输出。我们所用的注意力包括cross-attention和self-attention。Perceiver IO对encoder和decoder中的注意力模块使用cross-attention,而对latent processing modules使用self-attention。详见Fig5。
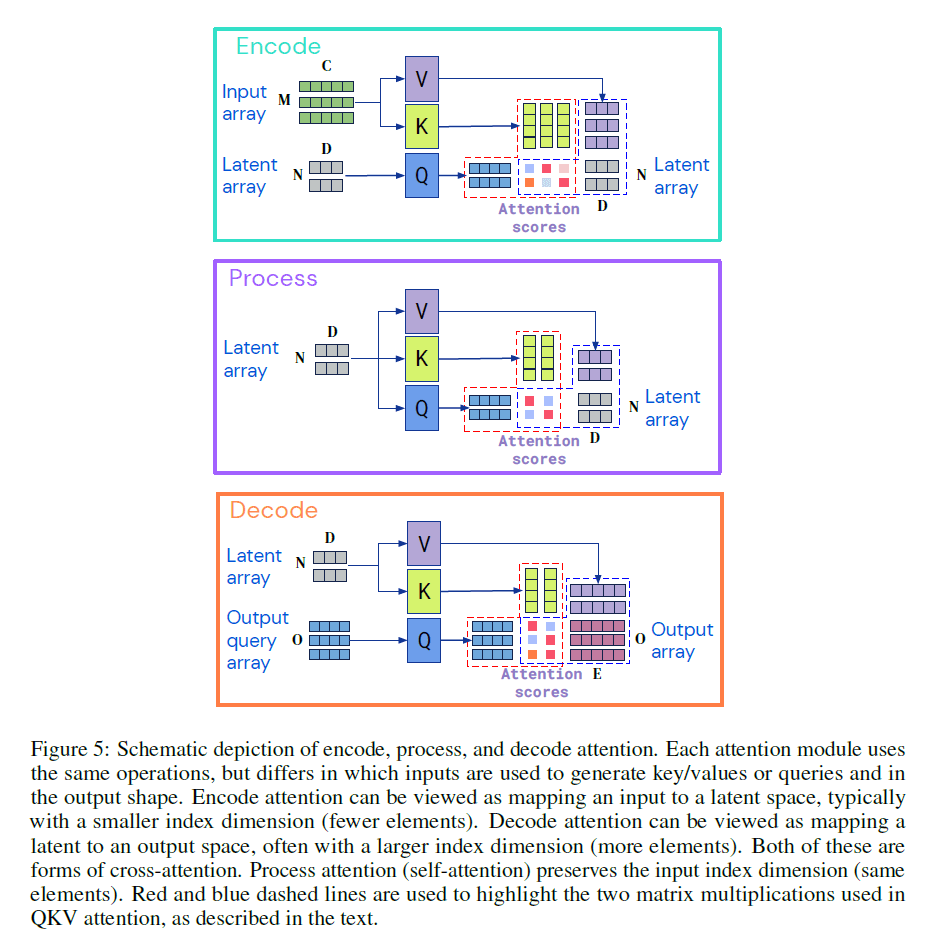
Fig5:encode、process、decode注意力机制示意图。每个注意力模块的操作都是一样的,只是输入和输出不同。encode注意力模块通常将输入映射到latent space(元素由多变少)。decode注意力将latent映射到output space(元素由少变多)。这两者都是cross-attention。process注意力保持维度不变(相同的元素数量),属于self-attention。
接下来详细介绍QKV注意力机制和MLP。
6.E.1.ATTENTION MODULE INTERNALS
QKV注意力的输入是两个二维数组,一个是query input $X_Q \in \mathbb{R}^{N \times D}$,一个是key-value input $X_{KV} \in \mathbb{R}^{M \times C}$。QKV注意力输出的也是一个数组,第一个维度(即index dimension)和query input一样(即$N$),第二个维度(即channel)取决于输出映射:
\[Q = f_Q(X_Q); K=f_K(X_{KV}); V = f_V(X_{KV}) \tag{1}\] \[X_{QK} = \text{softmax}(QK^T / \sqrt{F}) \tag{2}\] \[\text{Attn}(X_Q, X_{KV})=X_{QKV}=f_O(X_{QK}V) \tag{3}\]其中,$X_{QK} \in \mathbb{R}^{N \times M}$,$X_{QKV} \in \mathbb{R}^{N \times D}$。我们省略了batch操作和多头注意力。QKV注意力后跟两层MLP(激活函数为GELU)。整个模块的结构如下:
\[X_{QKV} = \text{Attn} ( \text{layerNorm}(X_Q),\text{layerNorm}(X_{KV})) \tag{4}\] \[X_{QKV}=X_{QKV}+X_Q \tag{5}\] \[X_{QKV}=X_{QKV}+\text{MLP}(\text{layerNorm}(X_{QKV})) \tag{6}\]对于decode注意力,我们会省略残差结构(即式(5))。如果保留残差结构可能会使训练增加不必要的困难。
说下Fig5中的维度:以encode为例,input array(即$X_{KV}$)的维度是$M\times C$,经过矩阵乘法,得到的$K$和$V$的维度分别是$M \times F_K$和$M \times F_V$。latent array(即$X_{Q}$)的维度是$N \times D$,经过矩阵乘法,得到的$Q$的维度为$N \times F_K$。然后$Q$和$K^T$进行矩阵乘法,得到的结果维度为$N \times M$,将这个结果与$V$相乘,得到最终结果维度为$N \times F_V$。显然,在encode中$F_V = D$。
6.E.2.COMPUTATIONAL COMPLEXITY
每个注意力模块的计算复杂度由两个矩阵乘法决定。仍然用encoder注意力作为例子,这两个矩阵乘法涉及的矩阵维度为$M \times F$、$N \times F$、$M \times N$、$N \times F$,计算复杂度为$O(MNF)$。$M,N,O$分别为input、latent、output的index dimension,为了简化分析,$F$为所有层的feature size(依旧以6.E.1部分最后的例子为例,即有$F = F_K = F_V$)。在encode中,$K,V$的维度都是$M \times F$,$Q$的维度是$N \times F$;在process中,$Q,K,V$的维度都是$N \times F$;在decode中,$K,V$的维度是$N\times F$,$Q$的维度是$O \times F$。$L$个latent attention block的计算复杂度为$O([M+O+LN]NF)$。换句话说,Perceiver IO的计算复杂度和输入输出大小呈线性关系,并且它将输入输出的大小和模型的depth(即$L$)解耦。这两个特性都有助于Perceiver IO的效率。更进一步的讨论见Perceiver原文的Sec. 2和Sec. A。
6.E.3.USING THE DECODER FOR CLASSIFICATION / REGRESSION
我们发现我们提出的attentional decoder比standard decoder(average+project)结果要好。我们在Fig6中进一步说明了这两种pooling方案。两种decoder都可以看作是先对latents做averaging,然后将其映射至目标形状,但是decoder attention更加的expressive。decoder attention不是对每个输入进行平等的加权,而是使用注意力分数作为每个输入点的权重(见Fig6的橙色字体和橙色方框)。并且decoder attention不是将原始的平均后的输入直接映射到目标维度,而是使用了MLP。此外,decoder attention还可以很容易的推广到dense output(通过增加query的数量),并且复用了和encode、process一样的框架结构。

Fig6:左图是Perceiver IO用于分类任务的single-query attention decoder,右图是Perceiver所用的标准的average+project decoder。两个decoder都可以看作是先通过加权平均的方式来聚合latents(attention decoder的权重是学到的、依赖于数据的,而average+project decoder的权重则是平均的),然后将其映射到目标输出维度(attention decoder用的方法是linear value projection+MLP,而average+project decoder用的方法只是简单的线性映射)。相比average+project decoder,attention decoder更加expressive,且使用和encode、process一样的框架模板。
6.F.LANGUAGE: ADDITIONAL DETAILS
6.F.1.OTHER TOKENIZER-FREE MODELS
Perceiver IO对语言的处理是byte级别的。
6.F.2.ARCHITECTURE DETAILS
在不同实验中所用的Perceiver IO的模型超参数和训练速度见表11。

6.F.3.MLM PRETRAINING
我们在C4+English Wikipedia的混合数据集上预训练了所有的模型,其中70%的训练tokens采样自C4数据集,剩余30%来自Wikipedia。我们在SentencePiece和byte-level实验中使用一样的mask策略:每个单词被独立的mask,被mask概率为15%,通过空格对单词进行划分。
预训练的超参数见表12。和FLOPs相当的BERT模型(trained on bytes)相比,我们将model width从768降低到了512,feed-forward hidden size从3072降低到了2048,层数从12降到了6,注意力的head数量从12降到了8。这个模型在处理序列长度为2048 bytes的FLOPs和BERT Base model在处理序列长度为512 tokens的FLOPs相当。
对于decode,我们所用的learned query和input array的维度一样(见表11)。此外,output query的维度和input是一样的,以便能预测句子中所有被mask掉的token($M=O$)。
为了深入了解所学到的query,我们在一个小段落上可视化了第一个cross attention层的注意力权重(见Fig7)。我们发现该模型已经学会了基于位置和内容的查找。基于位置的查找可以是稀疏且精确的,也可以是分散和周期性的。第二种模式出现的频率更低,但效率更高,因为同时处理的数据更多,但也更分散。基于内容的查找主要关注句法元素,如大写字母和标点符号。可能是因为这些都是很好的单词分隔符,可以帮助模型减少预测的不确定性。

Fig7:在初始cross-attention层对一些query的注意力权重的可视化。权重越大,颜色越明显。(a)基于位置的注意力非常敏锐;(b)基于位置的更高效、更分散的周期性注意力;(c)基于内容的注意力集中在标点符号和大写字母等句法元素上。
6.F.4.GLUE FINETUNING
我们指定了一个固定大小的超参数网格,每个任务独立测试,通过在dev数据集上的最佳表现来确定超参数(见表12、表13,个人理解:类似【深度学习基础】第二十二课:超参数调试)。结果见表14。

6.F.5.ABLATION ON THE NUMBER OF LATENTS
给定FLOPs budget,在latent数量$N$和latent width $D$之间可以做一个trade off。实验结果见表15。我们相应的调整latent的维度以匹配FLOPs budget。

6.G.POSITIONAL ENCODINGS FOR IMAGE AND AUDIO EXPERIMENTS
对于所有的图像实验(除了使用可学习位置的ImageNet实验外,见附录A.1部分),我们使用2D Fourier feature positional encoding。
6.H.OPTICAL FLOW: ADDITIONAL DETAILS AND RESULTS
表16列出了几种不同大小patch的比较。“Concat. frames”一列中,Yes就是取连续两帧concat在一起,No就是两帧不concat在一起,即input array行数会翻一倍,这种情况下,如果patch大小还是$1 \times 1$,那就相当于是没有任何的前处理,每个像素都是一个单独的元素,没有上下文信息。

如果“Downsample”列是Yes,则意味着先对输入和query通过$7\times 7$卷积+max pooling的方式进行4倍下采样,随后借鉴RAFT中的方式再对其进行上采样。“Depth”列就是自注意力模块的数量。“Latents”列就是latent array中的元素数量。
我们发现,在更困难的Sintel.final和KITTI数据集上,concat连续帧带来了不小的性能改进。说明空间上下文信息是有用的。卷积下采样和RAFT上采样为输入特征和query提供了更多的空间上下文信息,但这并不能弥补分辨率的损失,总体性能比使用全分辨率略差。
在GPU上,Perceiver IO的速度比RAFT慢,但在TPU上,Perceiver IO更快。我们在$1088 \times 436$大小的图像上比较了推理速度。我们最昂贵的模型在2017 TITAN Xp上达到了0.8帧每秒,轻量级的模型(卷积下采样+RAFT上采样)达到了3.3帧每秒,而RAFT可以达到每秒10帧。在公开可用的TPU v3上,我们最昂贵的模型在单个TPU核上达到了4.4帧每秒,轻量级模型则是达到了17.8帧每秒。RAFT的高效tensorflow实现在相同的硬件上仅实现了1.6帧每秒。
Fig8是在Sintel.final数据集上的一些结果。可以看到,该算法可以处理严重的遮挡以及纹理很少的大区域。并且,我们的模型还可以处理非常大的运动和非常小的物体。

Fig8:光流的定性结果。对于每个图像对,上面为两帧的图像,下面左为光流估计结果,下面右为GT。在左边的例子中,我们看到一个人在严重遮挡下,正确的光流被传播到一个几乎没有细节的区域。前景中的另一个人的衣服纹理很少,模糊度很高,但该算法可以将光流传播到整个区域。在中间的例子中,人和龙都有很大的运动,但光流检测的效果依然很好。在右边的例子中,可以看到我们的算法对微小的目标(被圈出的目标)的检测也很好。
最后,为了验证Perceiver IO在真实世界数据上也可以表现良好,尽管我们只在人工合成图像上进行了训练,因此我们在10个真实视频(来自www.gettyimages.com)上进行了测试。Perceiver IO通常可以表现的很好,但有时也会受到阴影和无纹理区域的干扰。Perceiver IO可以捕捉到非常小的物体。
Implementation details
对每个像素或者patch来说,我们使用sine and cosine position encoding(即2D Fourier feature positional encoding),对X和Y都是64 bands,再加上原始的X、Y值,一共会有258长度的feature被concat到像素或patch值的后面。如果不把两帧concat在一起,我们还需要用位置编码对一个额外的时间维度进行编码,这会导致高度冗余。对于input和query,我们将concat的特征映射到64维再喂给transformer。如果不另作说明,我们使用的latent array都是有2048个elements(即$N$)和512个channels(即$D$),24个自注意力模块(16个头)。卷积下采样和RAFT上采样的设置基本相同,我们没有使用额外的投影,因为卷积网络的输出已经是64通道了。对于这些实验,perceiver解码器的输出为64通道,然后其被送入RAFT风格的上采样操作中。对于基于像素和基于patch的模型,一幅$368 \times 496$图像的前向传播过程中的总计算复杂度为987 billion FLOPs,大约有27.9 million个参数。
对于所有的case,我们都在AutoFlow数据集上进行训练,该数据集包括400,000个图像对,训练了480个epoch,使用cosine learning rate schedule,初始学习率为$4e-4$。batch size为512。使用LAMB优化器。还使用了AutoFlow的默认curriculum,即随着时间的推移,会加强数据扩展的程度。此外,在一个batch中,一对图像会被提供两次,一次正向排列(正向流),一次反向排列(反向流)。
用于评估的数据集具有不同的分辨率,因此我们使用tiled的方式,使用6个evenly-spaced tiles(个人理解就是将每个图像分成6个相同间隔的块)。如果一个像素被多个块覆盖,那么我们会对预测结果进行加权平均,越靠近块边缘,权重越小(因此我们认为更靠近边缘的预测可能会不准)。将Perceiver IO对输入形状的不变性研究留到未来的工作中。
6.I.MULTIMODAL AUTOENCODING: ADDITIONAL DETAILS
对于多模态自动编码实验,我们对图像和音频进行了patch处理,并将标签转换成one-hot形式。对于视频图像来说,patch size为$1 \times 4 \times 4$;对于音频来说,patch size为16。音频的采样频率为48kHz,即每帧1920个采样。decoder输出有512个channel,每个channel的形式如Fig3右所示,第一部分有$16 \times 224 \times 224$行,每行对应一个像素,第二部分有$16 \times 1920 / 16$行,每行对应一个音频patch,第三部分只有1行,对应分类标签。然后这些会被线性投影到适当的通道数量:视频对应3个通道,音频对应16个通道,分类对应700个通道(对应Kinetics700中的700个类别)。最后对音频进行un-patch以获得最终输出音频。需要注意的是,我们直接在时间域内读取并生成音频波形;我们并不将其首先转换为声谱图。
对于每个输入视频patch,我们使用387维的3D Fourier position embedding,对于每个音频patch,我们使用385维的1D Fourier position embedding。此外,我们使用表示模态的可学习向量来padding输入元素;来自相同模态的输入共享相同的token。对于视频元素,我们添加了317维的模态embedding,对于音频元素,我们添加了319维的模态embedding,对于标签,我们添加了4维的模态embedding,这样所有元素的长度都是704维。
解码器的query由视频和音频的Fourier position embeddings以及标签的可学习的positional embedding构建而成:视频对应长度为387的特征,音频对应长度为385的特征,标签对应长度为1024的可学习特征。对于每种模态,我们使用不同的可学习向量来对query进行padding,最终使得query的特征长度为1026。
我们在Kinetics700上进行了训练。batch size为1024,学习率为$1e-3$。training loss是视频的L1 loss、音频的L1 loss以及标签的交叉熵损失的加权平均。其中,视频loss的权重为0.03,音频loss的权重为1,标签loss的权重为0.0001;权重设置不平衡,更加倾向于音频。我们也尝试了不同的权重(视频0.03、音频1、标签1),这样能获得更高的分类精度。更多的模型细节见表17。

为了帮助验证Perceiver IO在真实世界数据上的输出质量,我们将其应用于少量带有音频的真实视频(~10),数据来自Getty Images。Perceiver IO能够捕获输入的视频和音频的结构。该模型还为视频和音频引入了模糊性:这部分兴许要归因于预处理。尽管解码可以并行进行,但Perceiver IO就需要同时对所有点进行编码。解决这个限制是未来的一个重要工作方向。
7.原文链接
👽PERCEIVER IO:A GENERAL ARCHITECTURE FOR STRUCTURED INPUTS & OUTPUTS
